sgd on hadoop for big data & huge models
DESCRIPTION
SGD on Hadoop for Big dATA & Huge Models. Alex Beutel Based on work done with Abhimanu Kumar, Vagelis Papalexakis , Partha Talukdar , Qirong Ho, Christos Faloutsos , and Eric Xing. Outline. When to use SGD for distributed learning Optimization Review of DSGD SGD for Tensors - PowerPoint PPT PresentationTRANSCRIPT

SGD ON HADOOPFOR BIG DATA & HUGE MODELSAlex Beutel
Based on work done with Abhimanu Kumar, Vagelis Papalexakis, Partha Talukdar, Qirong Ho, Christos Faloutsos, and Eric Xing

Outline
1. When to use SGD for distributed learning
2. Optimization• Review of DSGD• SGD for Tensors• SGD for ML models – topic modeling, dictionary learning, MMSB
3. Hadoop1. General algorithm
2. Setting up the MapReduce body
3. Reducer communication
4. Distributed normalization
5. “Always-On SGD” – How to deal with the straggler problem
4. Experiments

When distributed SGD is useful
Collaborative FilteringPredict movie preferences
Topic ModelingWhat are the topics of webpages,
tweets, or status updatesDictionary Learning
Remove noise or missing pixels from images
Tensor DecompositionFind communities in temporal graphs
300 Million Photos uploaded to Facebook per day!
1 Billion users on Facebook
400 million tweets per day
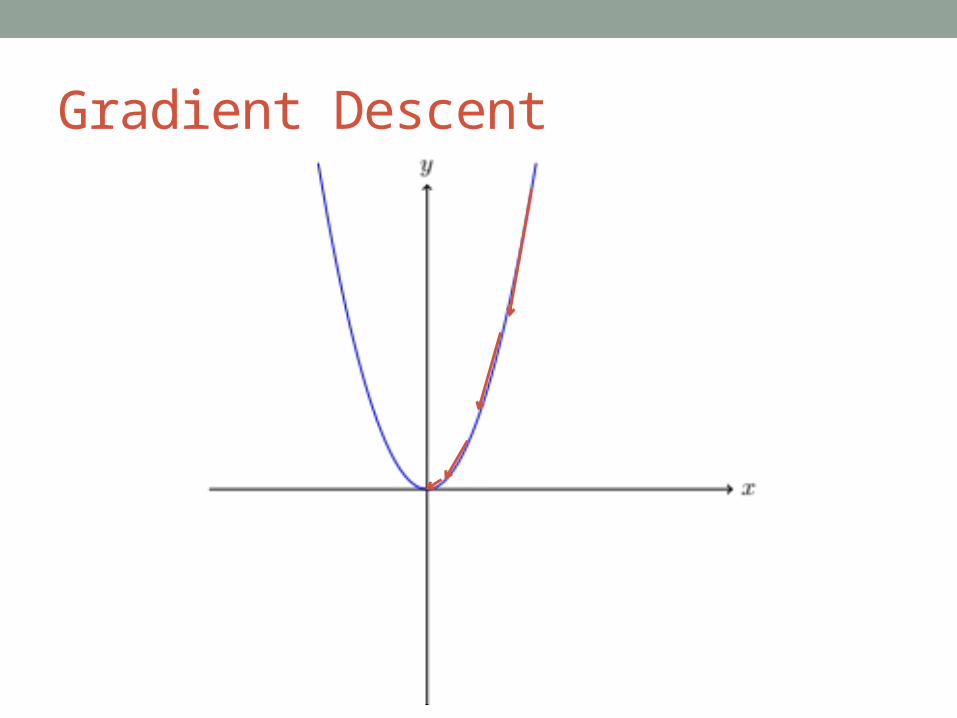
Gradient Descent
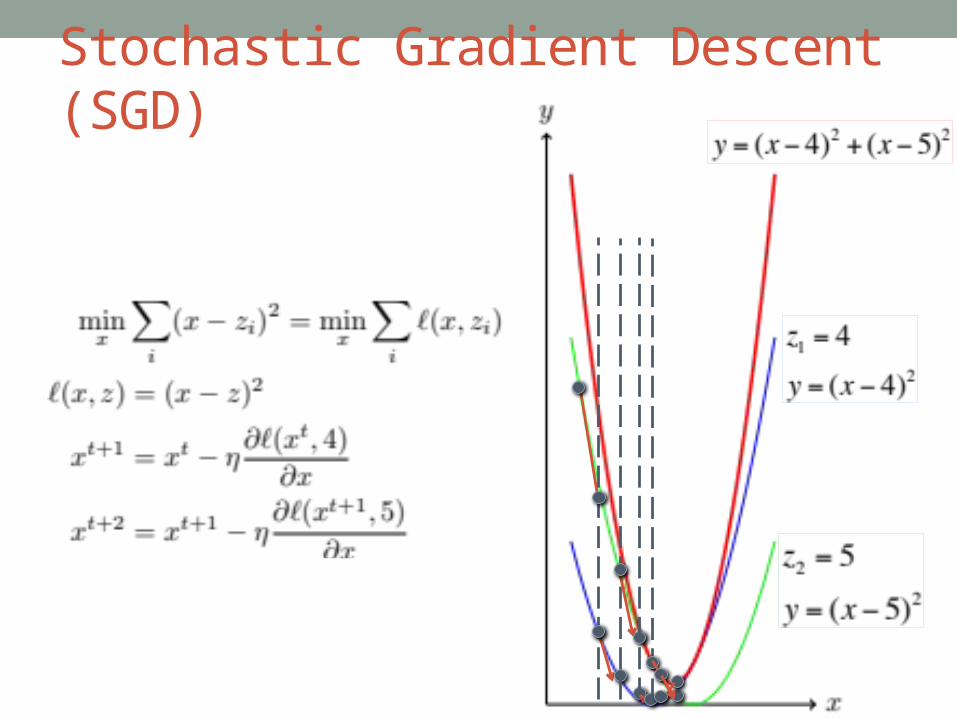
Stochastic Gradient Descent (SGD)

Stochastic Gradient Descent (SGD)

DSGD for Matrices (Gemulla, 2011)
XU
V
≈Users
Movies
Genres

DSGD for Matrices (Gemulla, 2011)
XU
V
≈Independent!

DSGD for Matrices (Gemulla, 2011)
Independent Blocks

DSGD for Matrices (Gemulla, 2011)
Partition your data & model into d × d blocks
Results in d=3 strata
Process strata sequentially, process blocks in each stratum in parallel

TENSORS

What is a tensor?• Tensors are used for structured data > 2 dimensions• Think of as a 3D-matrix
Subject
Verb
Object
For example:
Derek Jeter plays baseball

Tensor Decomposition
≈U
V
W
X

Tensor Decomposition
≈U
V
W
X

Tensor Decomposition
≈U
V
W
X
Independent
Not Independent
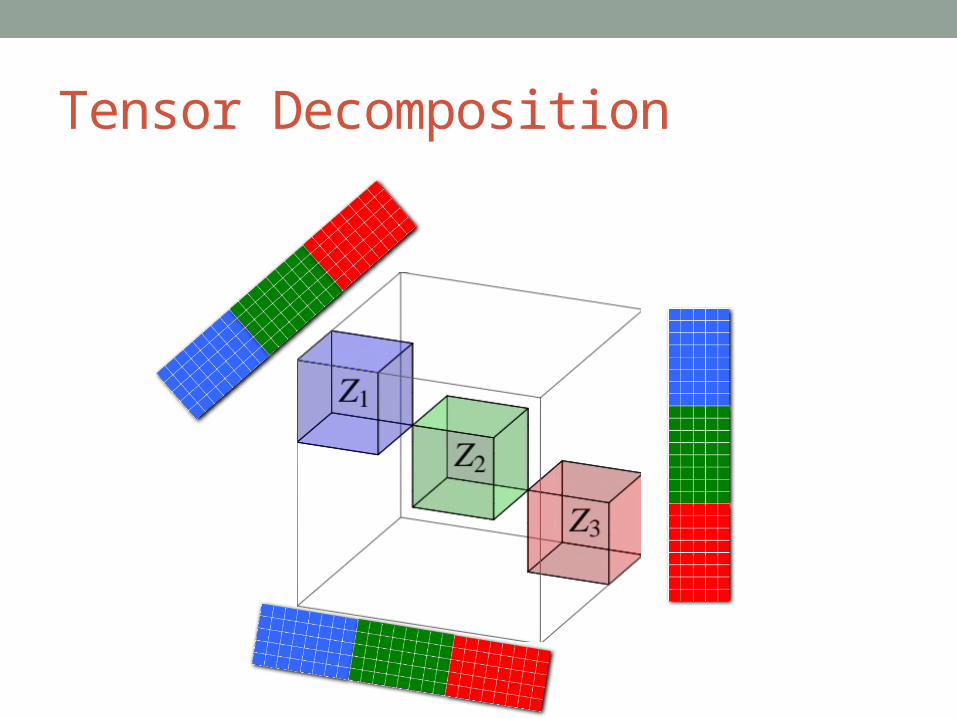
Tensor Decomposition

For d=3 blocks per stratum, we require d2=9 strata
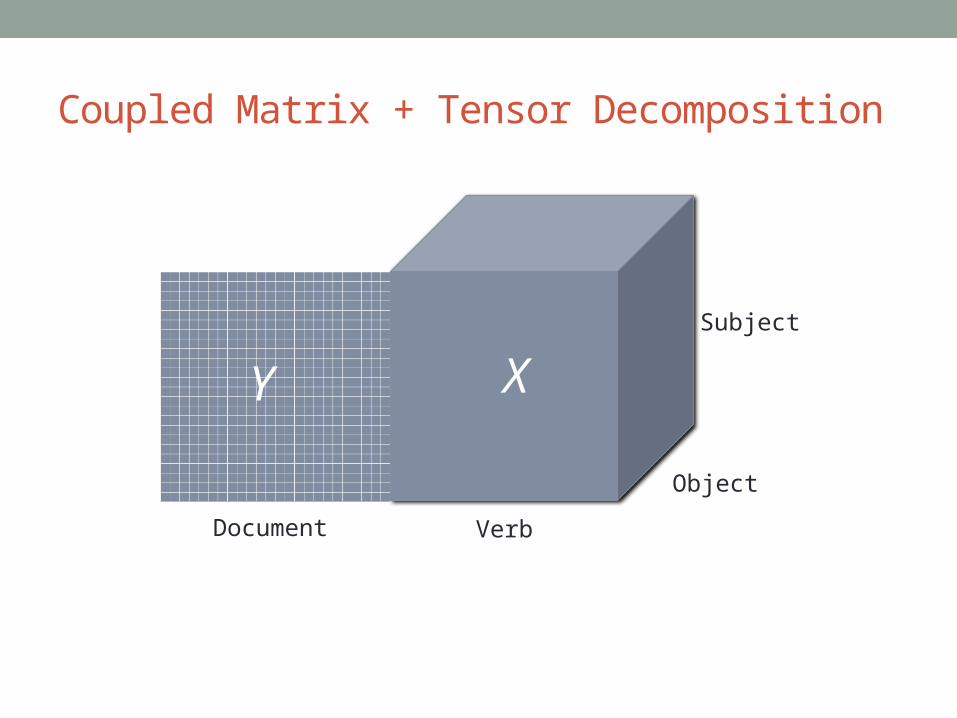
Coupled Matrix + Tensor Decomposition
XY
Subject
Verb
Object
Document

Coupled Matrix + Tensor Decomposition
≈U
V
W
XY
A
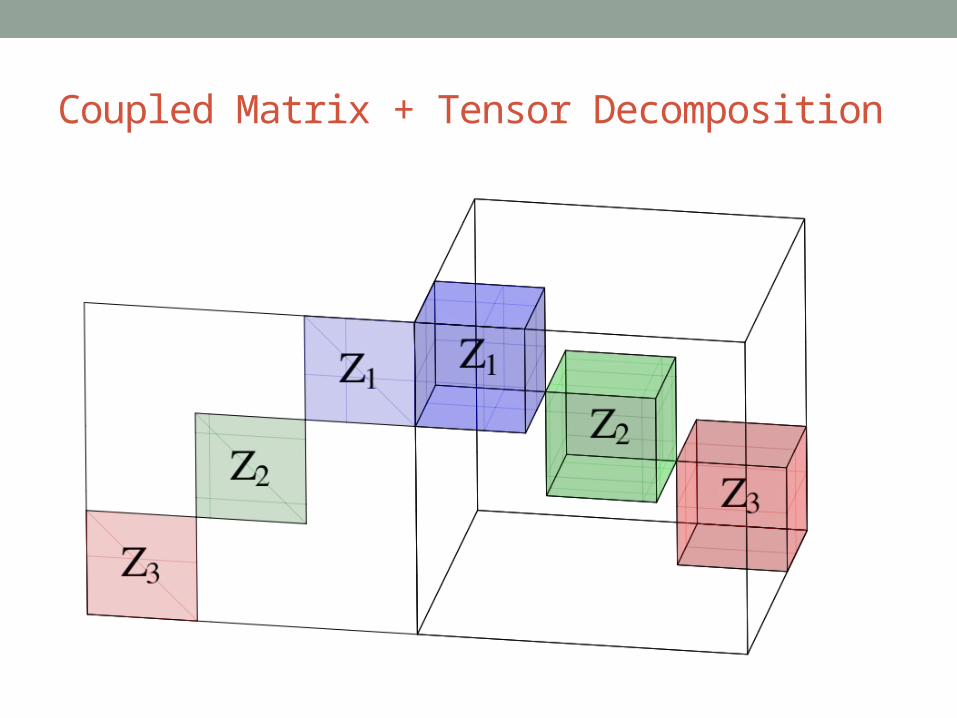
Coupled Matrix + Tensor Decomposition

CONSTRAINTS & PROJECTIONS

Example: Topic Modeling
Documents
Words
Topics

Constraints
• Sometimes we want to restrict response:• Non-negative
• Sparsity
• Simplex (so vectors become probabilities)
• Keep inside unit ball
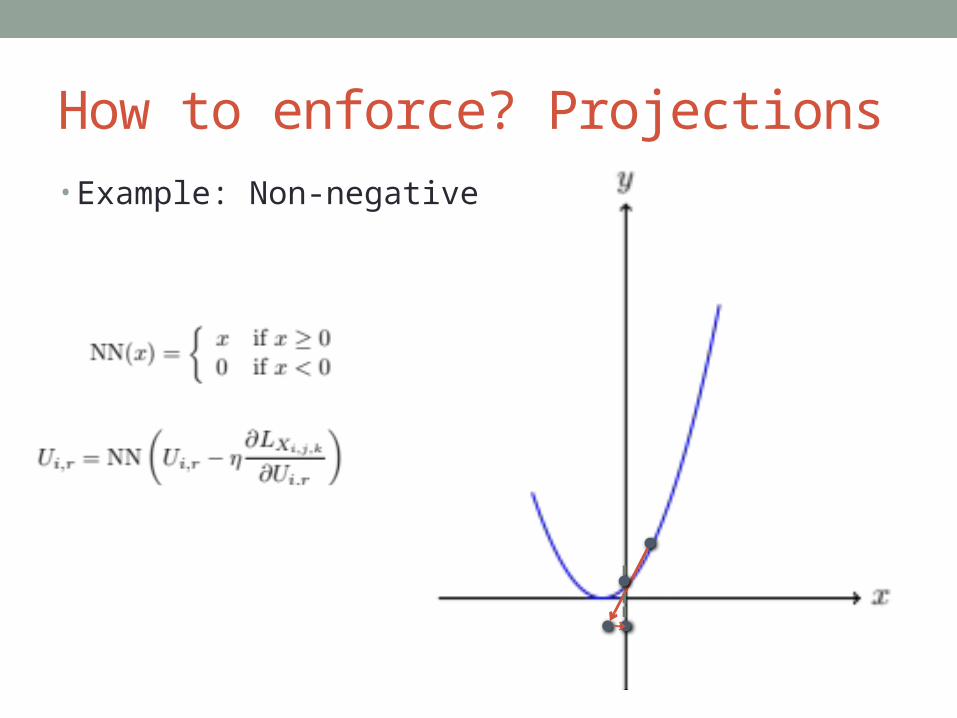
How to enforce? Projections• Example: Non-negative

More projections• Sparsity (soft thresholding):
• Simplex
• Unit ball

Dictionary Learning• Learn a dictionary of concepts and a sparse
reconstruction• Useful for fixing noise and missing pixels of images
Sparse encoding
Within unit ball

Mixed Membership Network Decomp.
• Used for modeling communities in graphs (e.g. a social network)
Simplex
Non-negative

IMPLEMENTING ON HADOOP
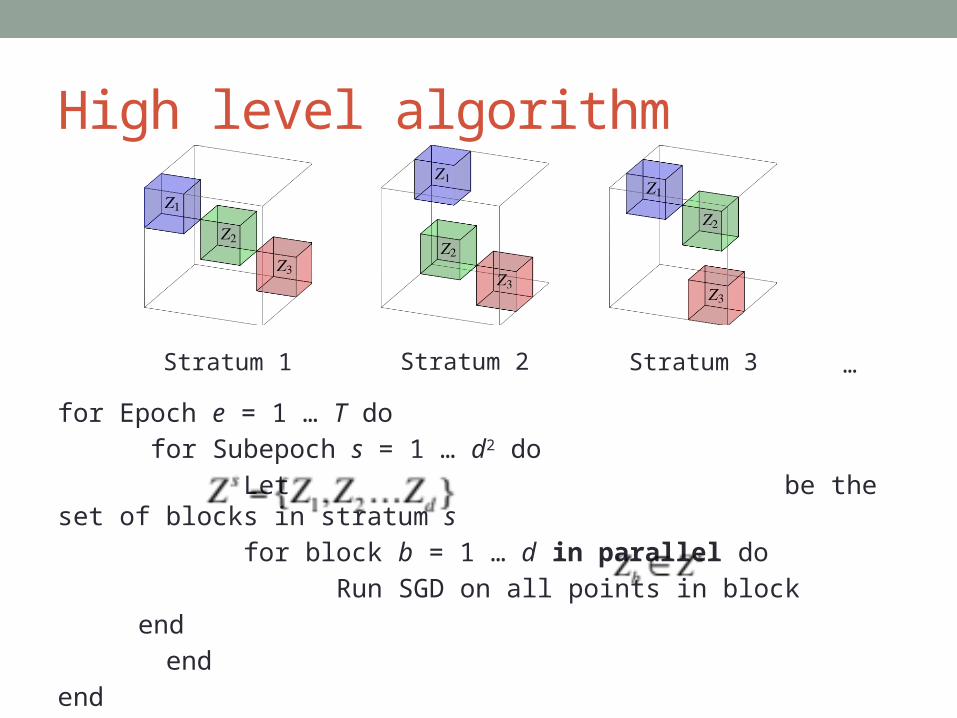
High level algorithm
for Epoch e = 1 … T do
for Subepoch s = 1 … d2 do
Let be the set of blocks in stratum s
for block b = 1 … d in parallel do
Run SGD on all points in block
end
end
end
Stratum 1 Stratum 2 Stratum 3 …
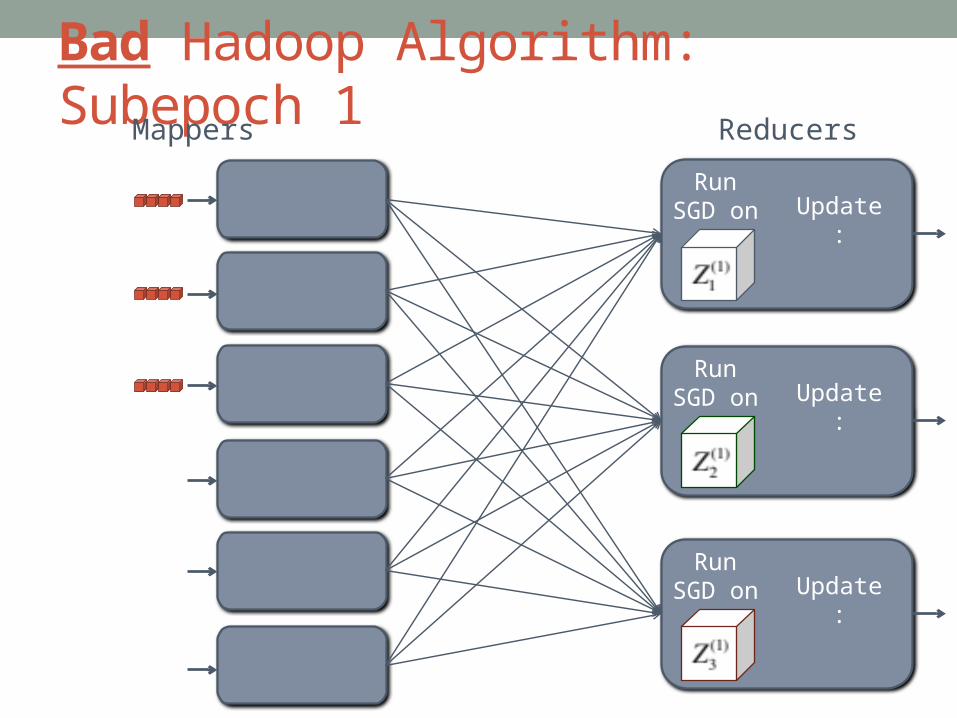
Bad Hadoop Algorithm: Subepoch 1
Run SGD on Update:
Run SGD on Update:
Run SGD on Update:
ReducersMappers
U2 V1 W3
U3 V2 W1
U1 V3 W2
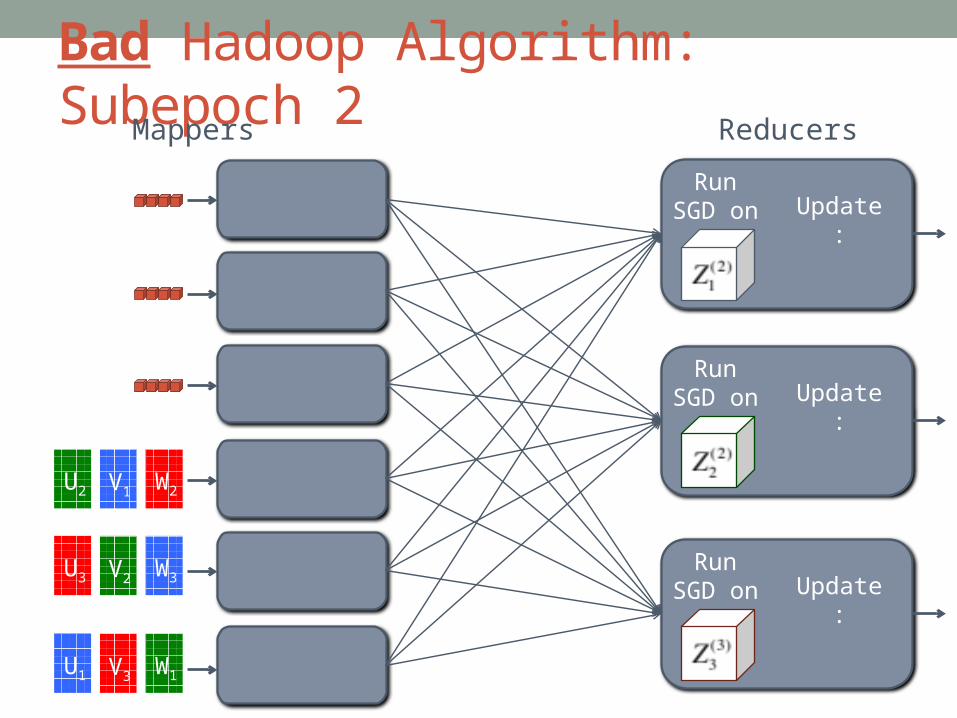
Bad Hadoop Algorithm: Subepoch 2
Run SGD on Update:
Run SGD on Update:
Run SGD on Update:
ReducersMappers
U2 V1 W2
U3 V2 W3
U1 V3 W1

Hadoop Challenges• MapReduce is typically very bad for iterative algorithms
• T × d2 iterations
• Sizable overhead per Hadoop job• Little flexibility
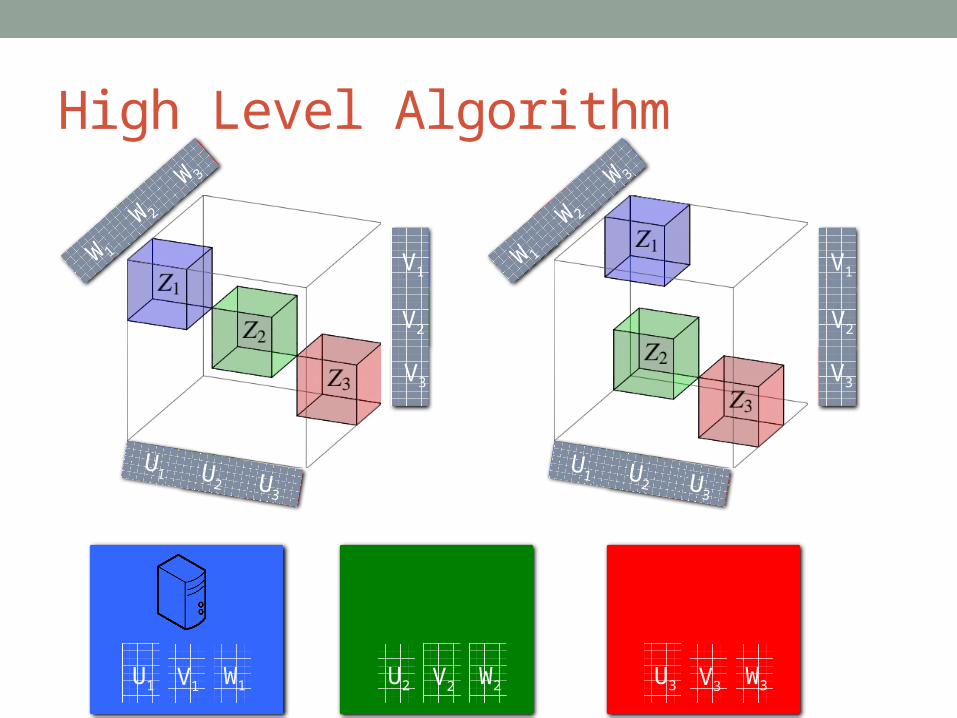
High Level Algorithm
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
U1 V1 W1 U2 V2 W2 U3 V3 W3
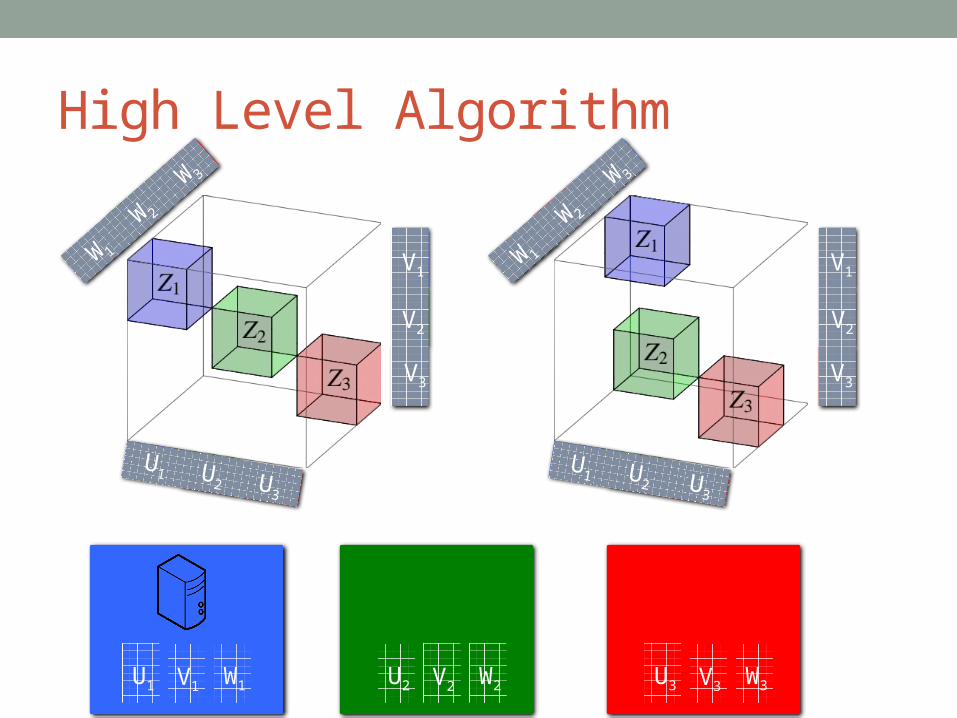
High Level Algorithm
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
U1 V1 W1 U2 V2 W2 U3 V3 W3
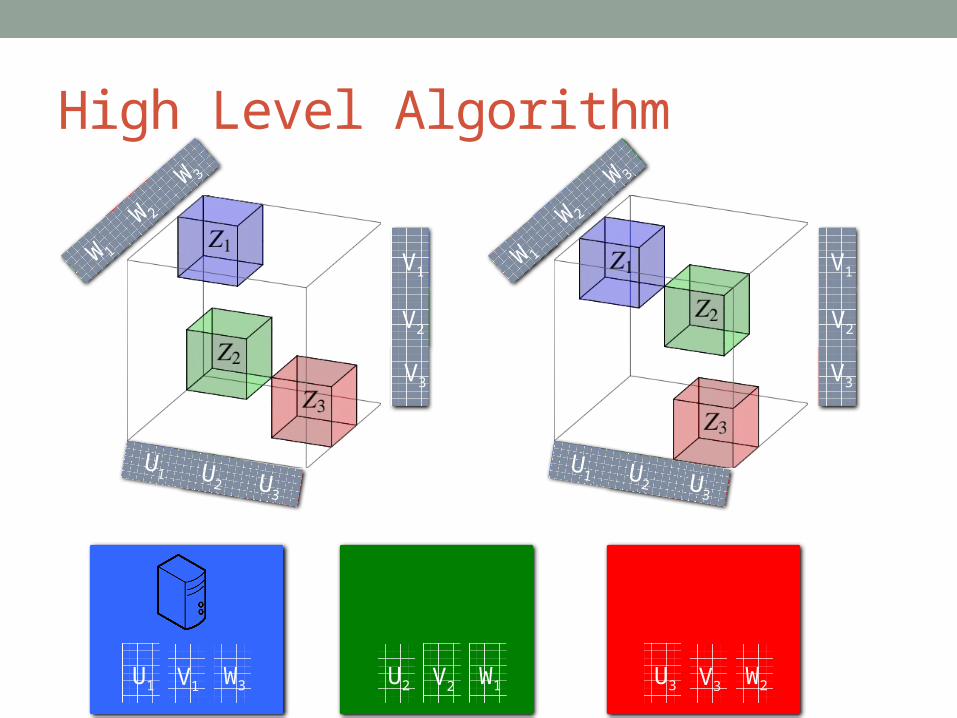
High Level Algorithm
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
U1 V1 W3 U2 V2 W1 U3 V3 W2

High Level Algorithm
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
V1
V2
V3
U1 U
2 U3
W 1
W 2
W 3
U1 V1 W2 U2 V2 W3 U3 V3 W1
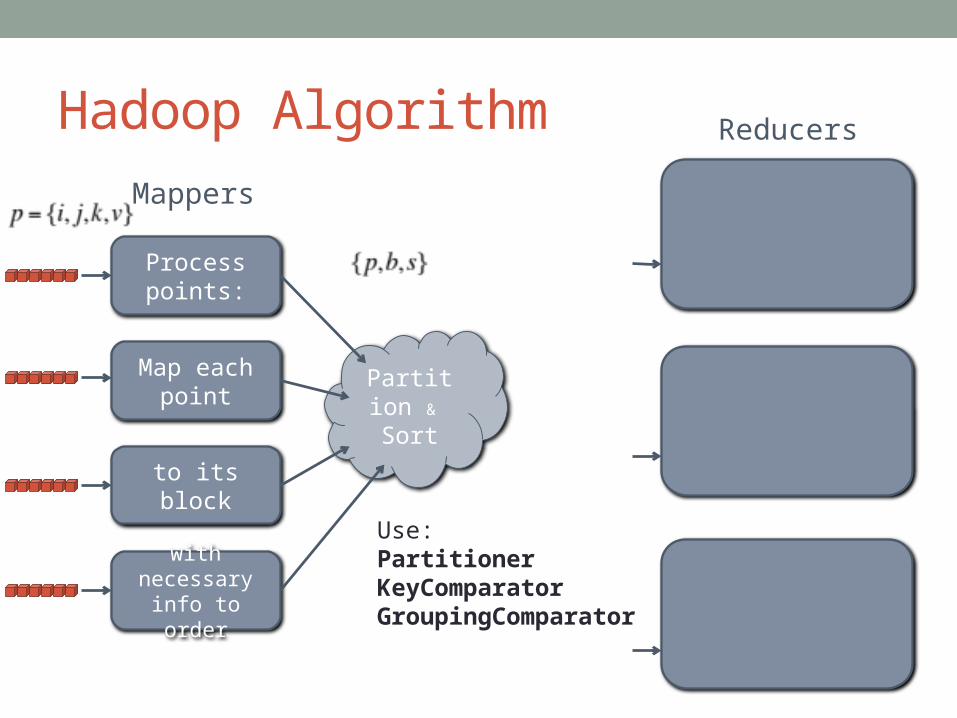
Hadoop Algorithm
Process points:
Map each point
to its block
with necessary info to order
Reducers
Mappers
Partition &
Sort
Use:PartitionerKeyComparatorGroupingComparator
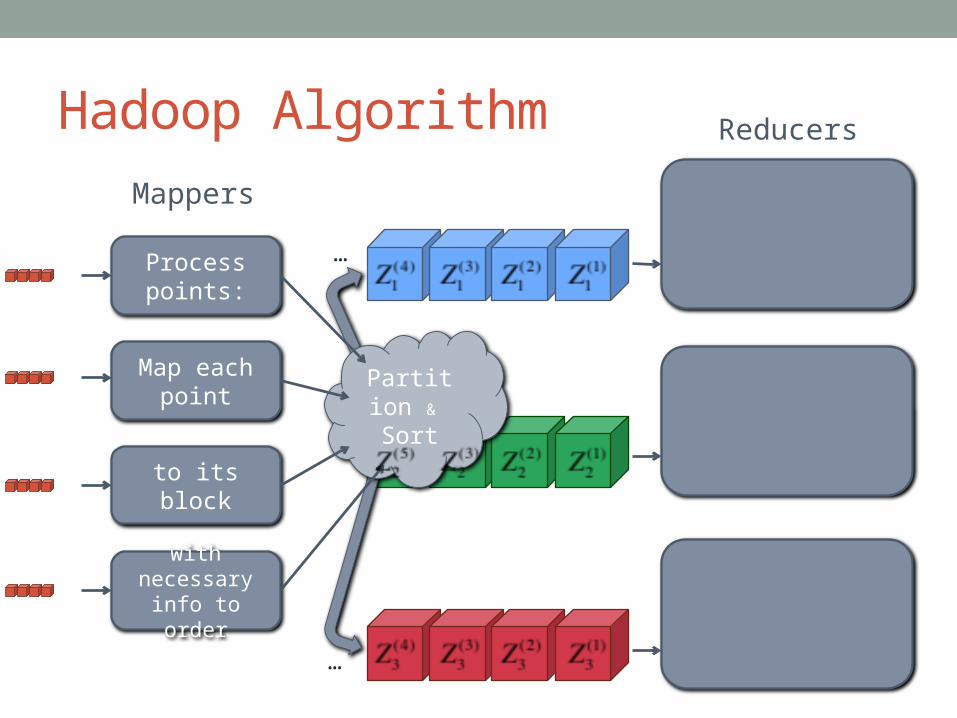
Hadoop Algorithm
Process points:
Map each point
to its block
with necessary info to order
Reducers
Mappers
Partition &
Sort
…
…
Hadoop Algorithm
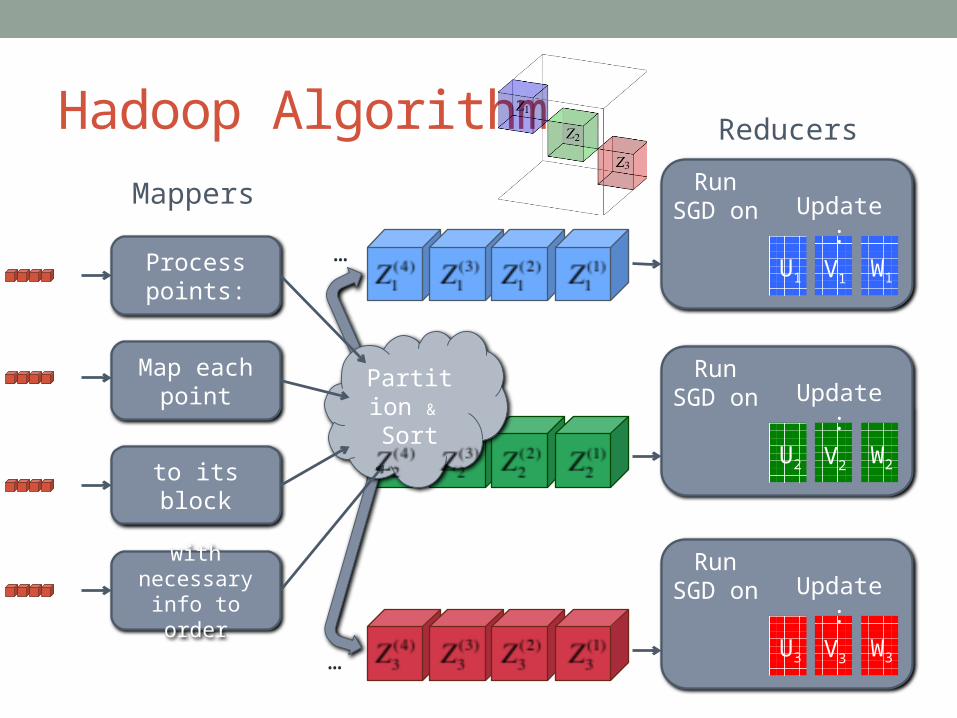
Process points:
Map each point
to its block
with necessary info to order
U1 V1 W1
Run SGD on Update:
U2 V2 W2
Run SGD on Update:
U3 V3 W3
Run SGD on Update:
Reducers
Mappers
…
…
Partition &
Sort
Hadoop Algorithm
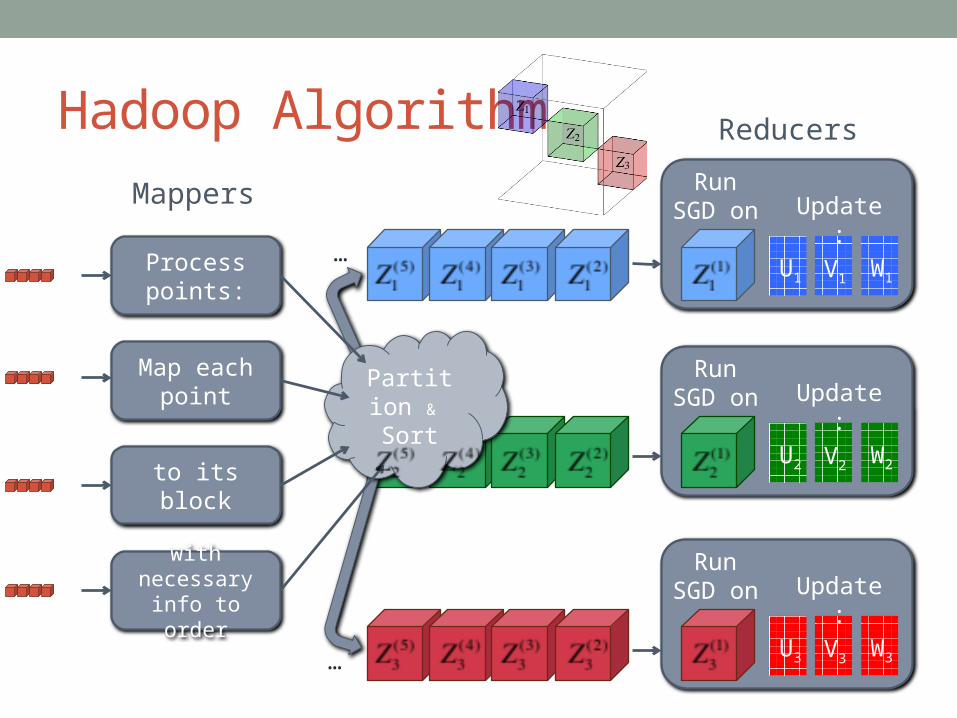
Process points:
Map each point
to its block
with necessary info to order
U1 V1 W1
Run SGD on Update:
U2 V2 W2
Run SGD on Update:
U3 V3 W3
Run SGD on Update:
Reducers
Mappers
Partition &
Sort
…
…
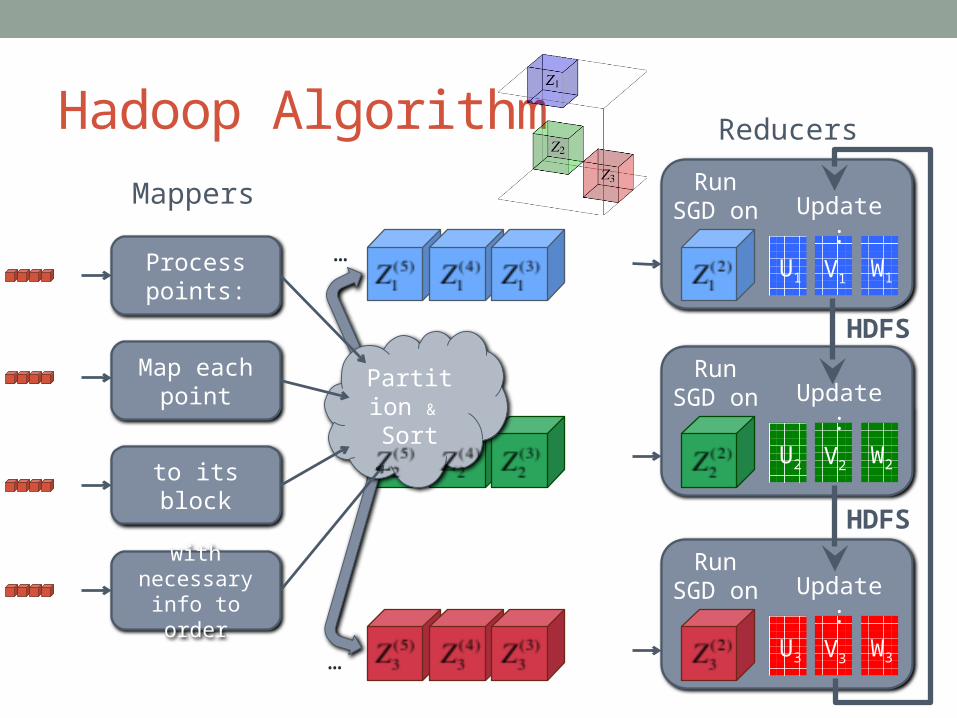
Hadoop Algorithm
Process points:
Map each point
to its block
with necessary info to order
U1 V1
Run SGD on Update:
U2 V2
Run SGD on Update:
U3 V3
Run SGD on Update:
Reducers
Mappers
Partition &
Sort
…
…
HDFS
HDFS
W2
W1
W3

Hadoop Summary
1. Use mappers to send data points to the correct reducers in order
2. Use reducers as machines in a normal cluster
3. Use HDFS as the communication channel between reducers

Distributed Normalization
Documents
Words
Topics
π1 β1
π2 β2
π3 β3

Distributed Normalization
π1 β1
π2 β2π3 β3
σ(1)
σ(2)
σ(3)
σ(b) is a k-dimensional vector, summing the terms of βb
σ(1)
σ(1)
σ(3)
σ(3)
σ(2) σ(2)
Transfer σ(b) to all machinesEach machine calculates σ:
Normalize:
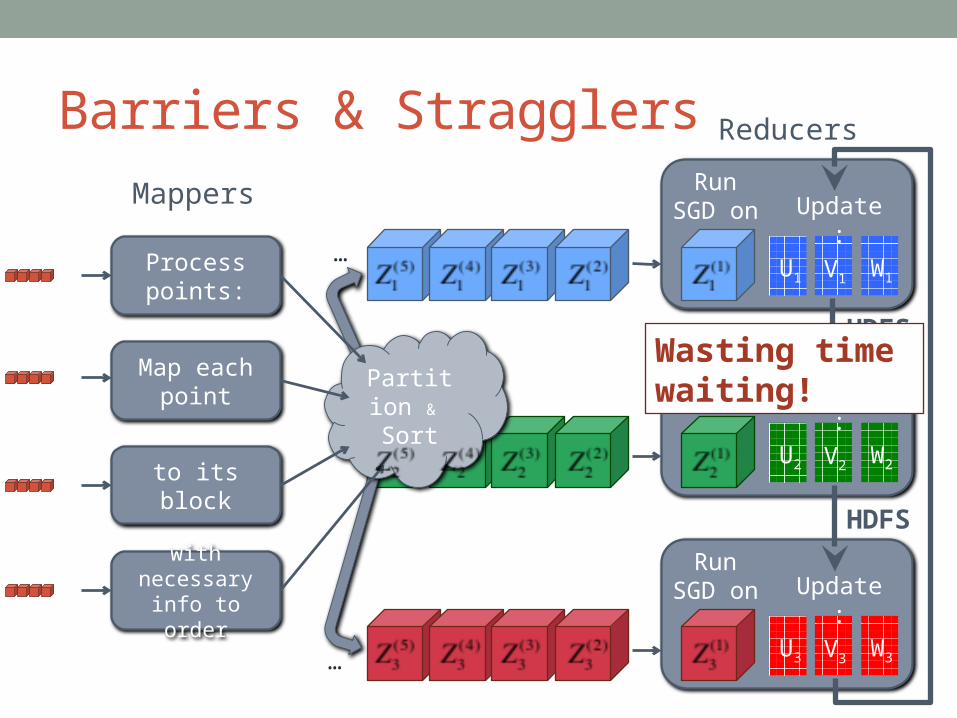
Barriers & Stragglers
Process points:
Map each point
to its block
with necessary info to order
Run SGD on
Run SGD on
Run SGD on
Reducers
Mappers
Partition &
Sort
…
…U1 V1
Update:
U2 V2
Update:
U3 V3
Update:
HDFS
HDFS
W2
W1
W3
Wasting time waiting!
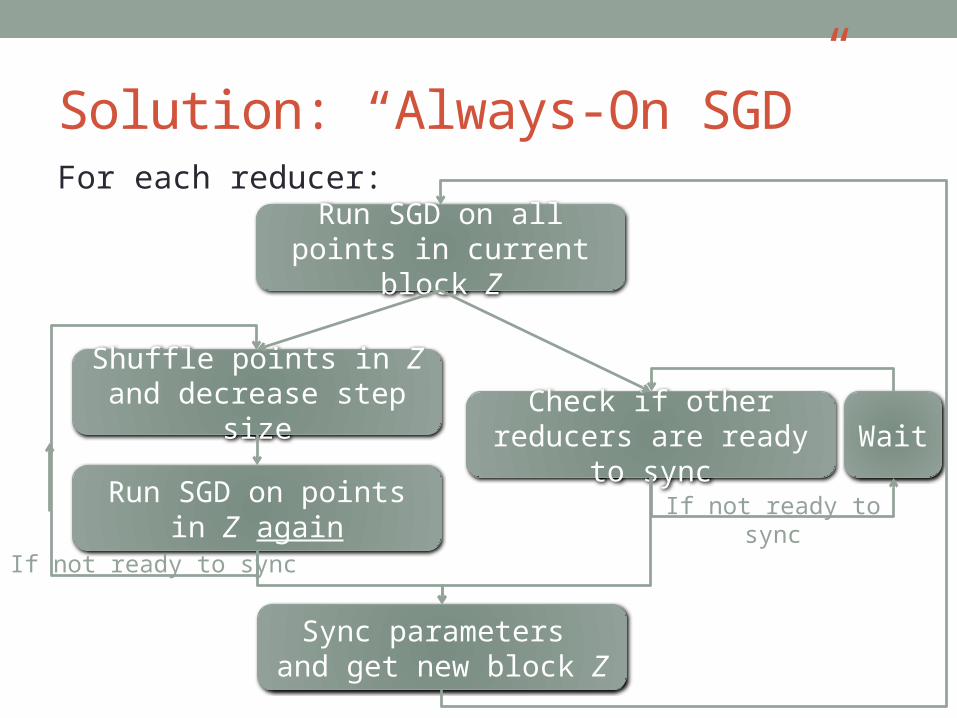
Solution: “Always-On SGD”For each reducer:
Run SGD on all points in current block Z
Shuffle points in Z and decrease step size Check if other reducers
are ready to syncRun SGD on points in Z
againIf not ready to sync
Wait
If not ready to sync
Sync parameters and get new block Z
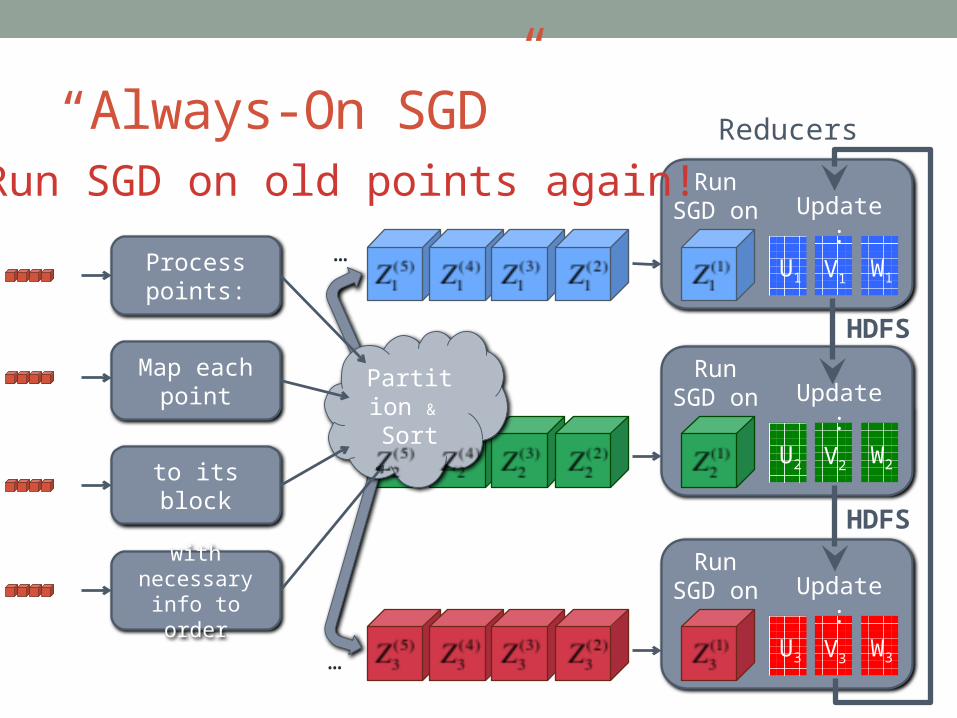
“Always-On SGD”
Process points:
Map each point
to its block
with necessary info to order
Run SGD on
Run SGD on
Run SGD on
Reducers
Partition &
Sort
…
…U1 V1
Update:
U2 V2
Update:
U3 V3
Update:
HDFS
HDFS
W2
W1
W3
Run SGD on old points again!
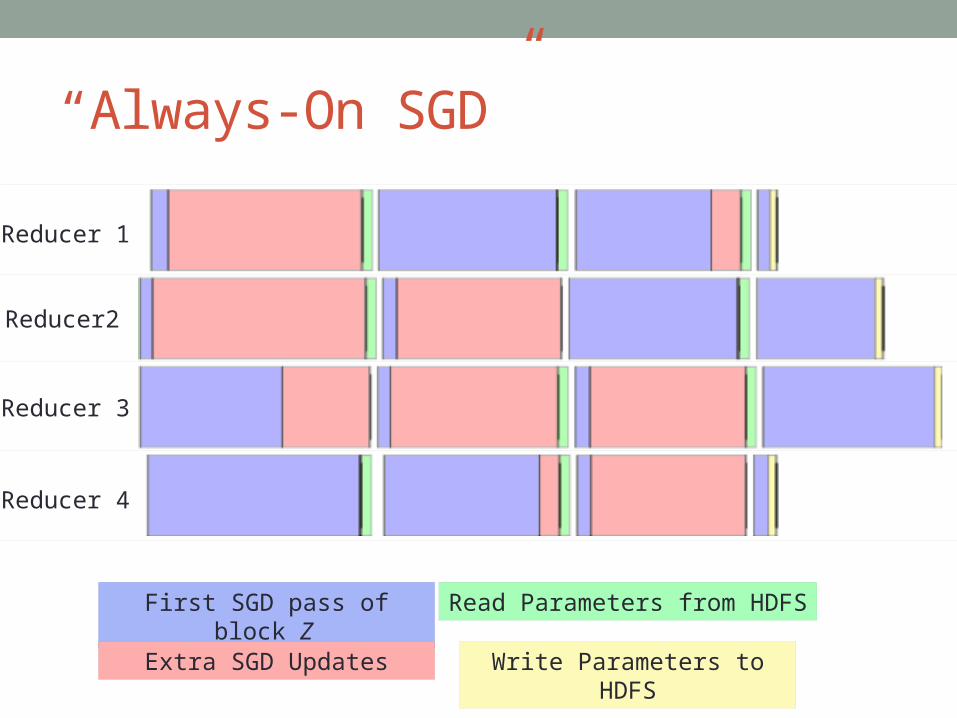
“Always-On SGD”
First SGD pass of block Z
Extra SGD Updates
Read Parameters from HDFS
Write Parameters to HDFS
Reducer 1
Reducer2
Reducer 3
Reducer 4

EXPERIMENTS
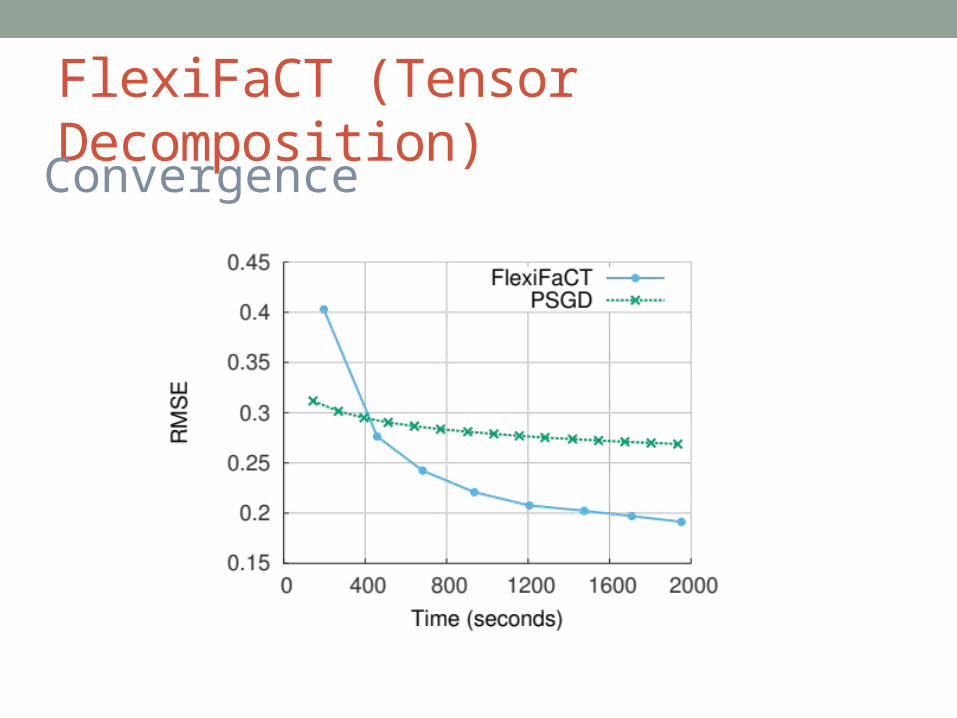
FlexiFaCT (Tensor Decomposition)Convergence

FlexiFaCT (Tensor Decomposition)Scalability in Data Size

FlexiFaCT (Tensor Decomposition)Scalability in Tensor Dimension
Handles up to 2 billion parameters!
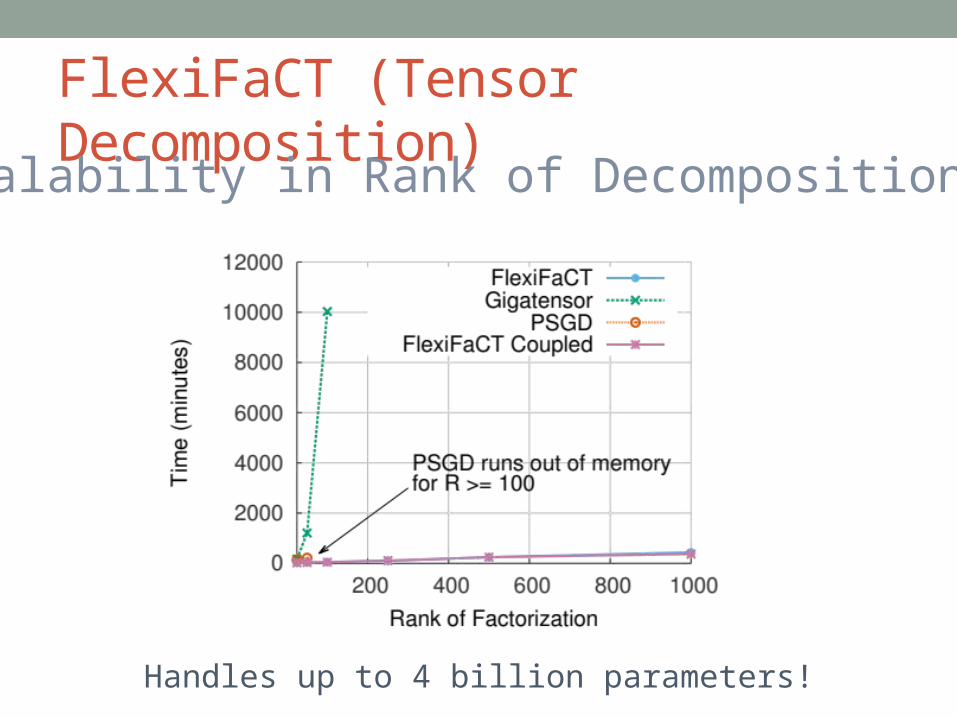
FlexiFaCT (Tensor Decomposition)Scalability in Rank of Decomposition
Handles up to 4 billion parameters!

FlexiFaCT (Tensor Decomposition)Scalability in Number of Machines

Fugue (Using “Always-On SGD”)Dictionary Learning: Convergence
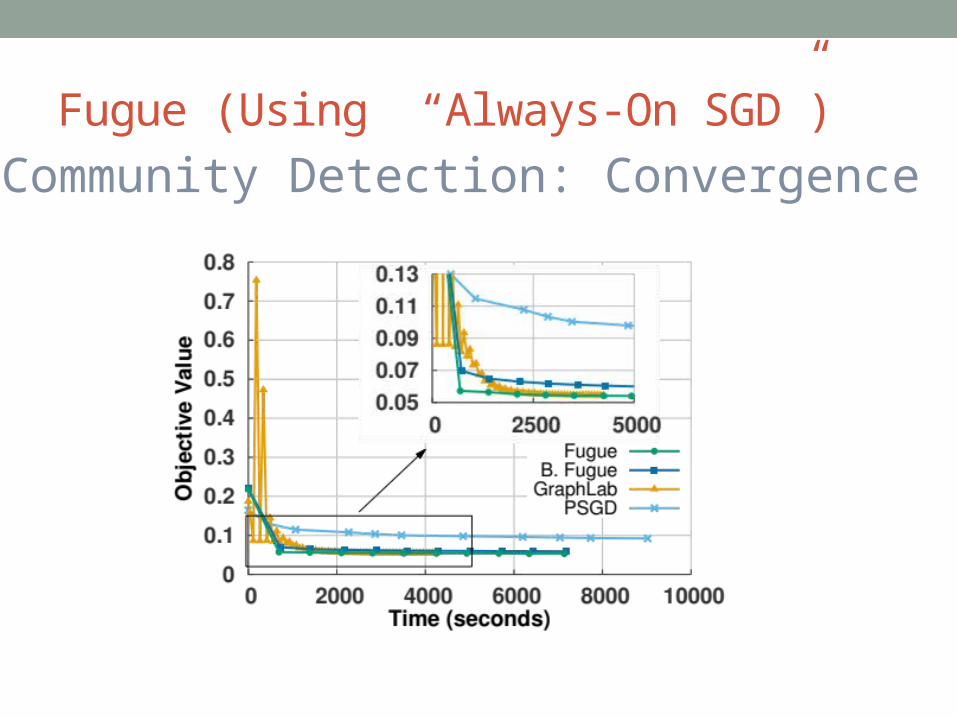
Fugue (Using “Always-On SGD”)Community Detection: Convergence
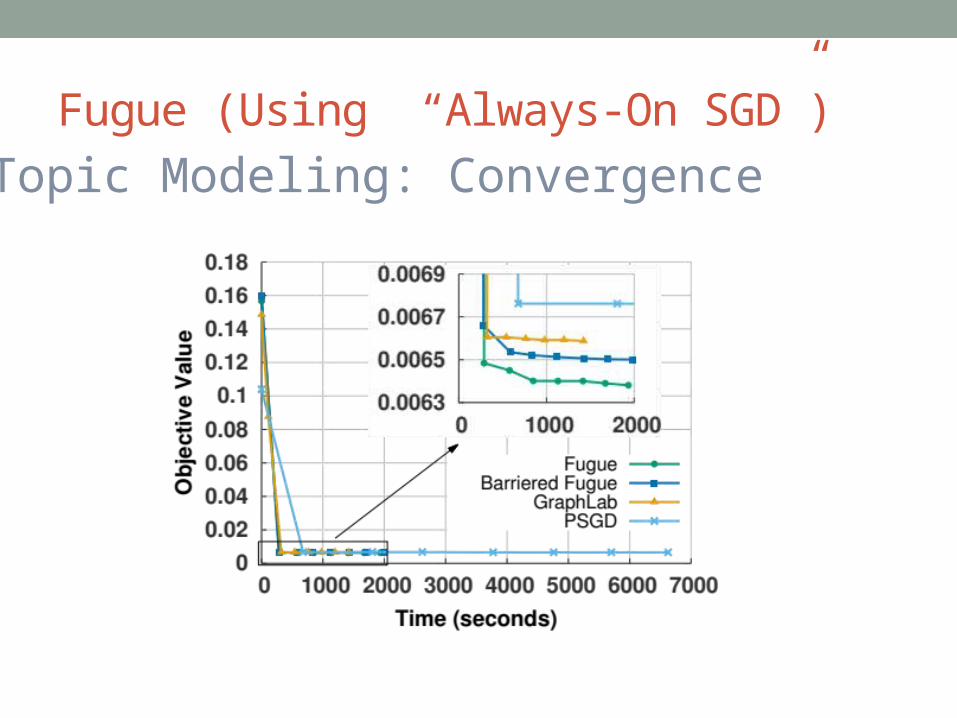
Fugue (Using “Always-On SGD”)Topic Modeling: Convergence
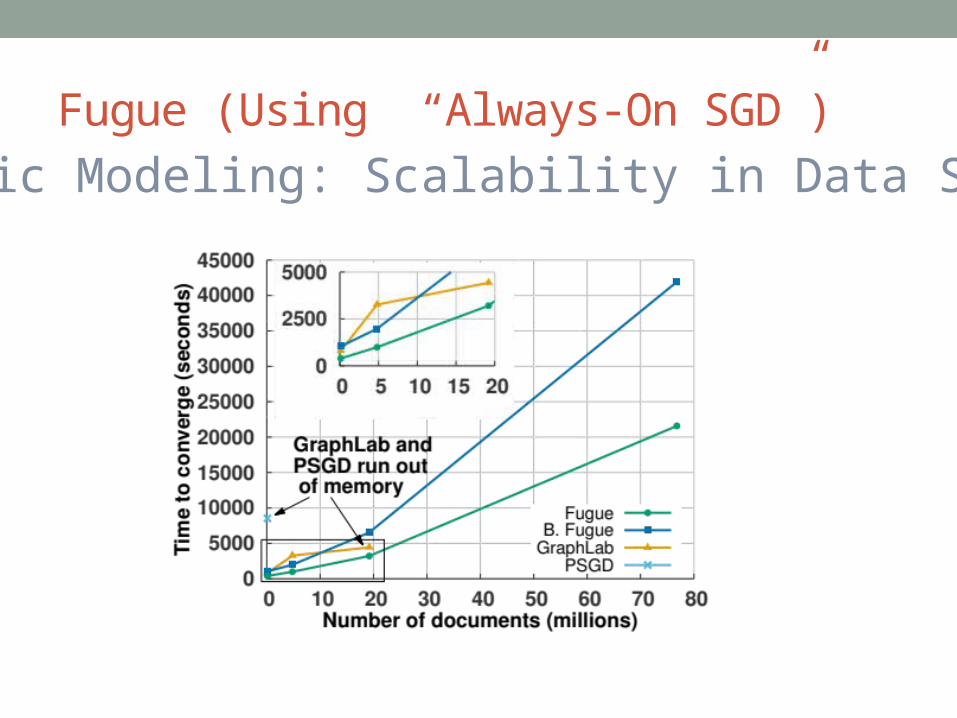
Fugue (Using “Always-On SGD”)Topic Modeling: Scalability in Data Size
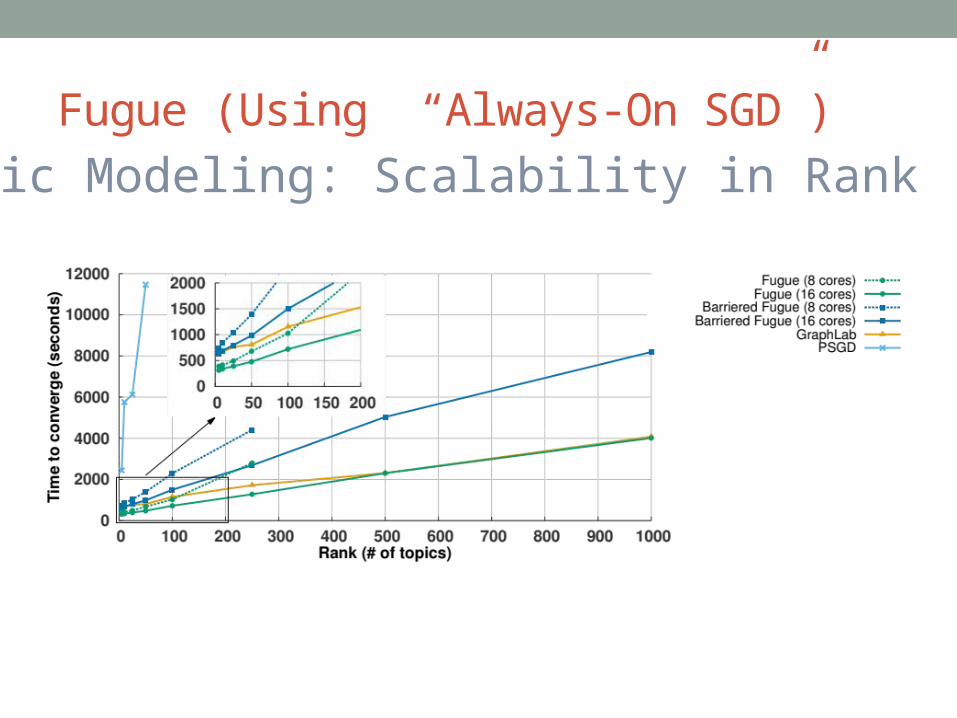
Fugue (Using “Always-On SGD”)Topic Modeling: Scalability in Rank
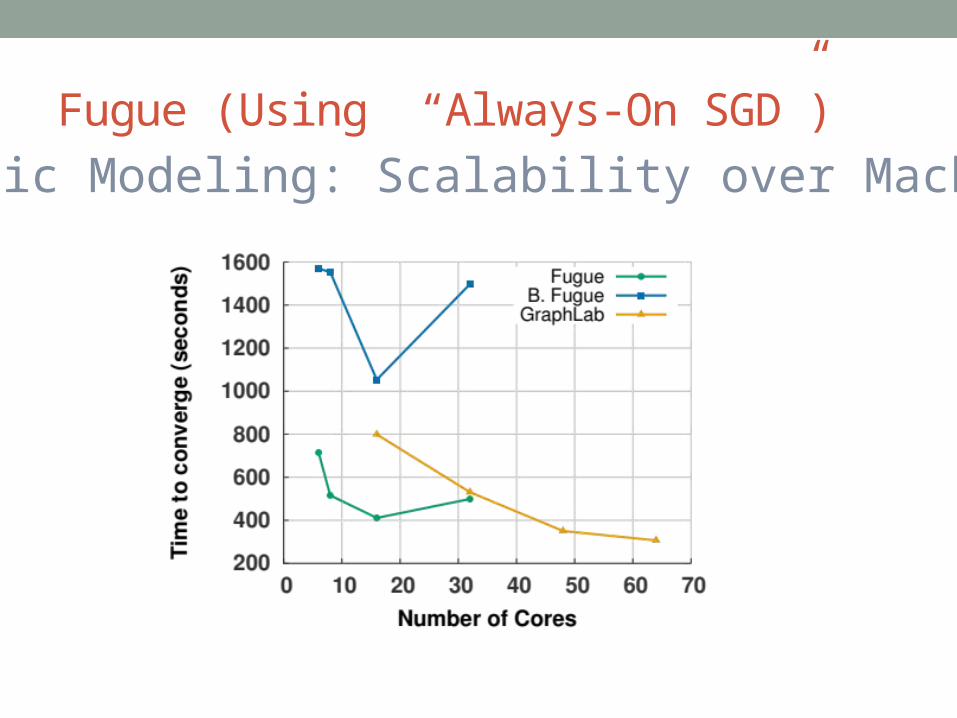
Fugue (Using “Always-On SGD”)Topic Modeling: Scalability over Machines

Fugue (Using “Always-On SGD”)Topic Modeling: Number of Machines
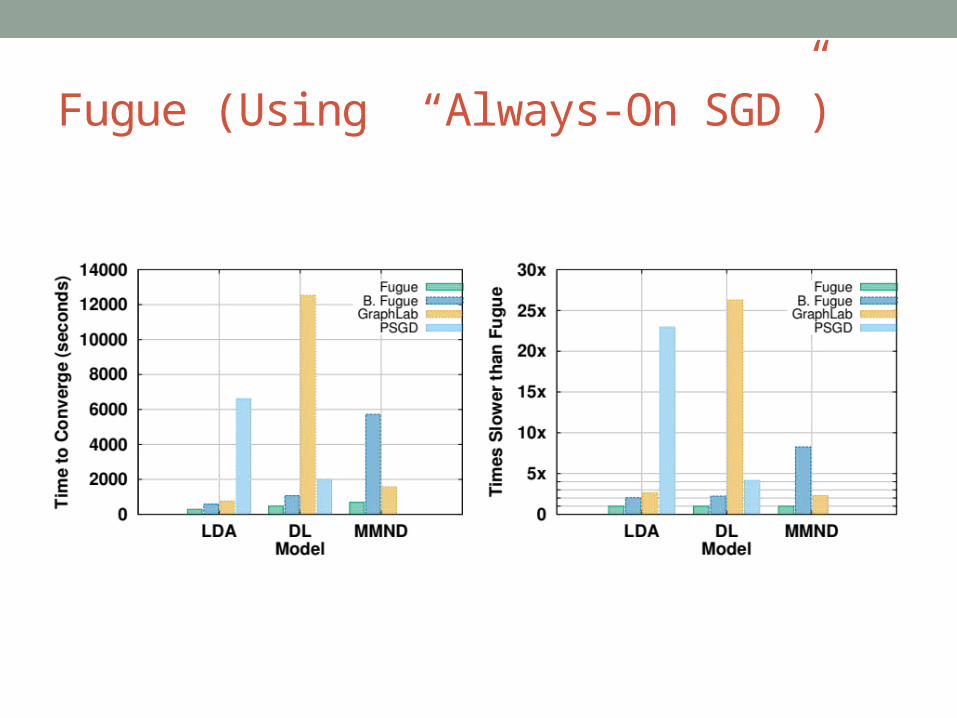
Fugue (Using “Always-On SGD”)

Key Points• Flexible method for tensors & ML models• Can use stock Hadoop through using HDFS for
communication• When waiting for slower machines, run updates on old
data again
