scalable peer-to-peer substrates: a new foundation for distributed applications?
DESCRIPTION
Scalable peer-to-peer substrates: A new foundation for distributed applications?. Peter Druschel, Rice University Antony Rowstron, Microsoft Research Cambridge, UK Collaborators: Miguel Castro, Anne-Marie Kermarrec, MSR Cambridge - PowerPoint PPT PresentationTRANSCRIPT

Scalable peer-to-peer substrates: A new foundation for distributed
applications?
Peter Druschel, Rice University
Antony Rowstron, Microsoft Research Cambridge, UK
Collaborators:Miguel Castro, Anne-Marie Kermarrec, MSR CambridgeY. Charlie Hu, Sitaram Iyer, Animesh Nandi, Atul Singh,
Dan Wallach, Rice University

Outline
• Background
• Pastry
• Pastry proximity routing
• PAST
• SCRIBE
• Conclusions

Background
Peer-to-peer systems
• distribution
• decentralized control
• self-organization
• symmetry (communication, node roles)

Peer-to-peer applications
• Pioneers: Napster, Gnutella, FreeNet• File sharing: CFS, PAST [SOSP’01]• Network storage: FarSite [Sigmetrics’00], Oceanstore
[ASPLOS’00], PAST [SOSP’01]• Web caching: Squirrel[PODC’02]• Event notification/multicast: Herald [HotOS’01], Bayeux
[NOSDAV’01], CAN-multicast [NGC’01], SCRIBE [NGC’01], SplitStream [submitted]
• Anonymity: Crowds [CACM’99], Onion routing [JSAC’98]
• Censorship-resistance: Tangler [CCS’02]

Common issues• Organize, maintain overlay network
– node arrivals
– node failures
• Resource allocation/load balancing• Resource location• Network proximity routing
Idea: provide a generic p2p substrate
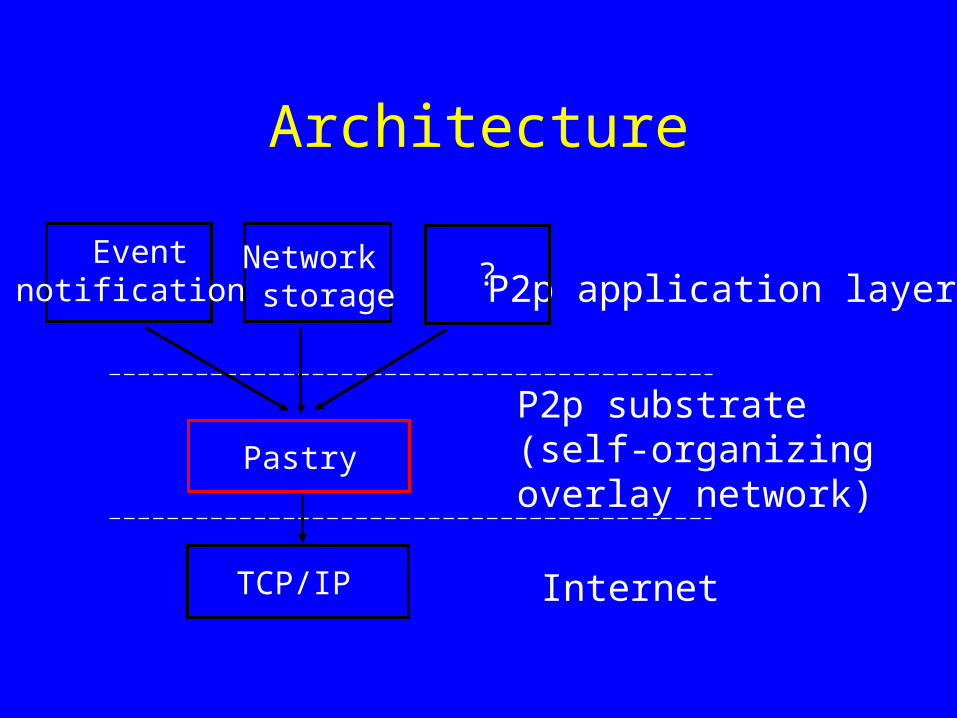
Architecture
TCP/IP
Pastry
Network storage
Event notification
Internet
P2p substrate (self-organizingoverlay network)
P2p application layer?

Structured p2p overlays
One primitive:
route(M, X): route message M to the live node with nodeId closest to key X
• nodeIds and keys are from a large, sparse id space
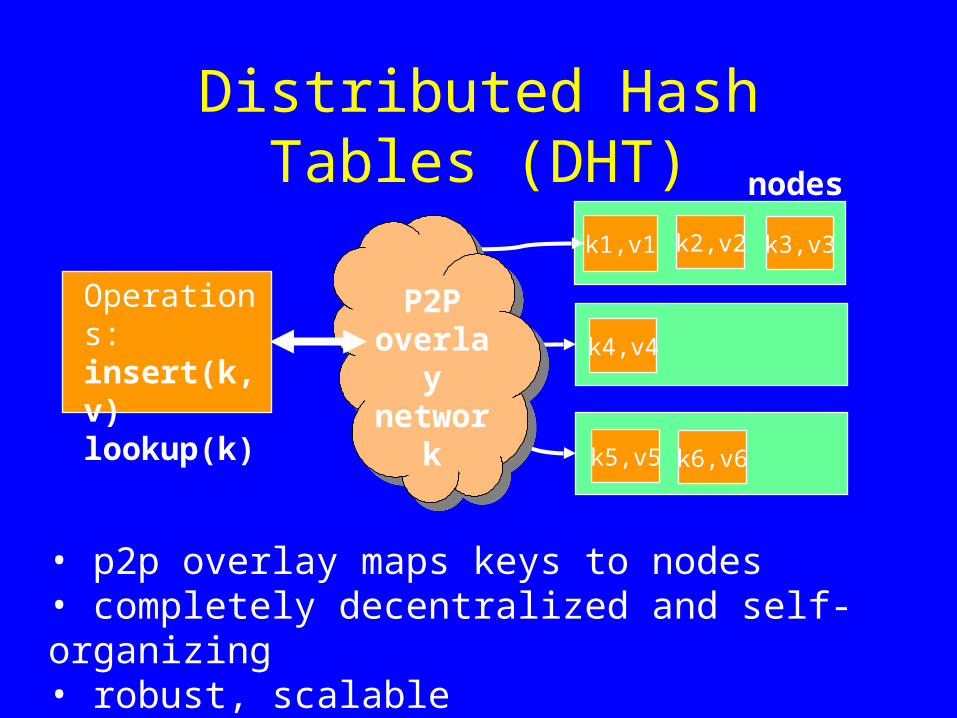
Distributed Hash Tables (DHT)
k6,v6
k1,v1
k5,v5
k2,v2
k4,v4
k3,v3
nodes
Operations:insert(k,v)lookup(k)
P2P overlay networ
k
P2P overlay networ
k
• p2p overlay maps keys to nodes• completely decentralized and self-organizing• robust, scalable

Why structured p2p overlays?
• Leverage pooled resources (storage, bandwidth, CPU)
• Leverage resource diversity (geographic, ownership)
• Leverage existing shared infrastructure• Scalability• Robustness• Self-organization

Outline
• Background
• Pastry
• Pastry proximity routing
• PAST
• SCRIBE
• Conclusions

Pastry: Related work
• Chord [Sigcomm’01]• CAN [Sigcomm’01]• Tapestry [TR UCB/CSD-01-1141]
• PNRP [unpub.]• Viceroy [PODC’02]• Kademlia [IPTPS’02]• Small World [Kleinberg ’99, ‘00]• Plaxton Trees [Plaxton et al. ’97]

Pastry: Object distribution
objId
Consistent hashing [Karger et al. ‘97]
128 bit circular id space
nodeIds (uniform random)
objIds (uniform random)
Invariant: node with numerically closest nodeId maintains object
nodeIds
O2128-1

Pastry: Object insertion/lookup
X
Route(X)
Msg with key X is routed to live node with nodeId closest to X
Problem:
complete routing table not feasible
O2128-1

Pastry: Routing
Tradeoff
• O(log N) routing table size
• O(log N) message forwarding steps

Pastry: Routing table (# 65a1fcx)0x
1x
2x
3x
4x
5x
7x
8x
9x
ax
bx
cx
dx
ex
fx
60x
61x
62x
63x
64x
66x
67x
68x
69x
6ax
6bx
6cx
6dx
6ex
6fx
650x
651x
652x
653x
654x
655x
656x
657x
658x
659x
65bx
65cx
65dx
65ex
65fx
65a0x
65a2x
65a3x
65a4x
65a5x
65a6x
65a7x
65a8x
65a9x
65aax
65abx
65acx
65adx
65aex
65afx
log16 Nrows
Row 0
Row 1
Row 2
Row 3

Pastry: Routing
Properties• log16 N steps • O(log N) state
d46a1c
Route(d46a1c)
d462ba
d4213f
d13da3
65a1fc
d467c4d471f1

Pastry: Leaf sets
Each node maintains IP addresses of the nodes with the L/2 numerically closest larger and smaller nodeIds, respectively.
• routing efficiency/robustness
• fault detection (keep-alive)
• application-specific local coordination

Pastry: Routing procedureif (destination is within range of our leaf set)
forward to numerically closest memberelse
let l = length of shared prefix let d = value of l-th digit in D’s addressif (Rl
d exists)
forward to Rld
else forward to a known node that (a) shares at least as long a prefix(b) is numerically closer than this node

Pastry: Performance
Integrity of overlay/ message delivery:• guaranteed unless L/2 simultaneous failures of
nodes with adjacent nodeIds
Number of routing hops:
• No failures: < log16 N expected, 128/b + 1 max
• During failure recovery:– O(N) worst case, average case much better

Pastry: Self-organization
Initializing and maintaining routing tables and leaf sets
• Node addition
• Node departure (failure)
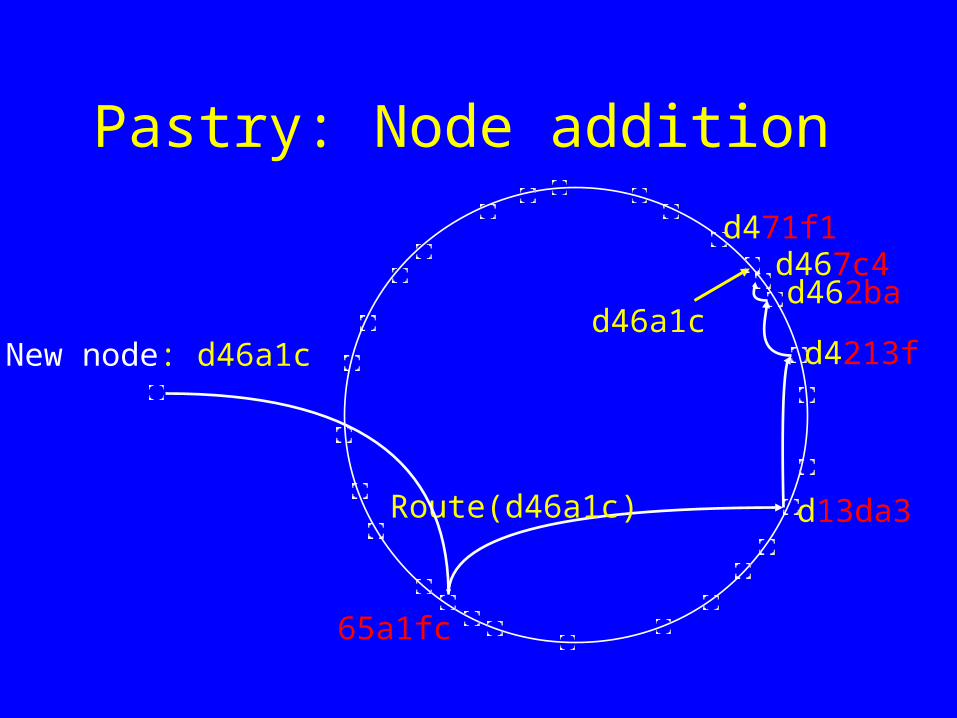
Pastry: Node addition
d46a1c
Route(d46a1c)
d462ba
d4213f
d13da3
65a1fc
d467c4d471f1
New node: d46a1c

Node departure (failure)
Leaf set members exchange keep-alive messages
• Leaf set repair (eager): request set from farthest live node in set
• Routing table repair (lazy): get table from peers in the same row, then higher rows

Pastry: Experimental results
Prototype
• implemented in Java
• emulated network
• deployed testbed (currently ~25 sites worldwide)

Pastry: Average # of hops
L=16, 100k random queries
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1000 10000 100000
Number of nodes
Ave
rag
e n
um
ber
of
ho
ps
Pastry
Log(N)
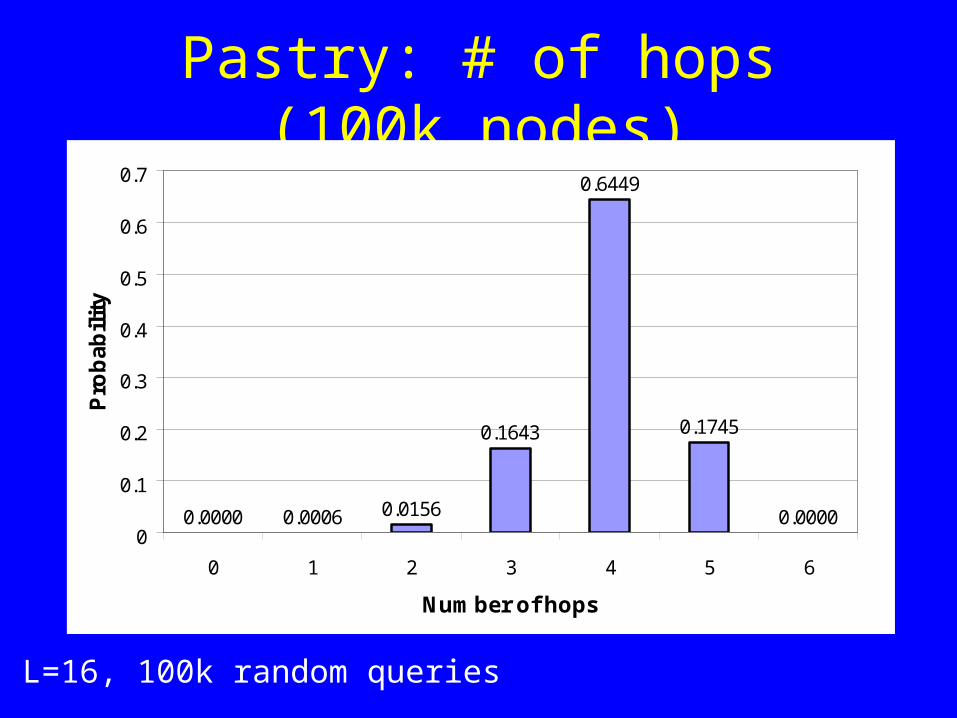
Pastry: # of hops (100k nodes)
L=16, 100k random queries
0.0000 0.0006 0.0156
0.1643
0.6449
0.1745
0.00000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 1 2 3 4 5 6
Number of hops
Pro
bab
ilit
y
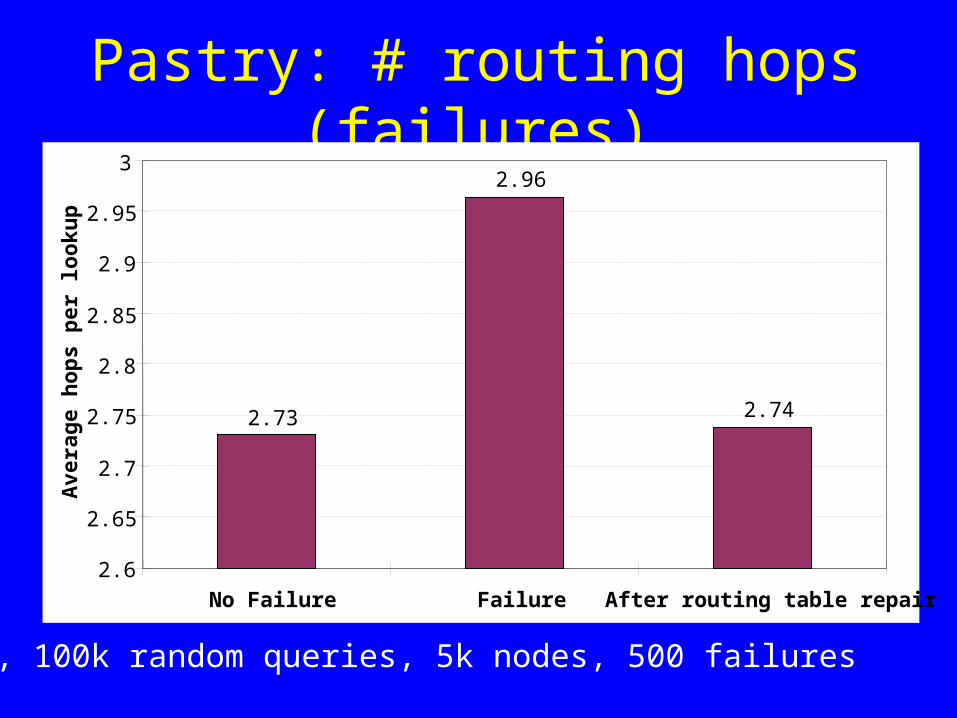
Pastry: # routing hops (failures)
L=16, 100k random queries, 5k nodes, 500 failures
2.73
2.96
2.74
2.6
2.65
2.7
2.75
2.8
2.85
2.9
2.95
3
No Failure Failure After routing table repair
Ave
rag
e h
op
s p
er lo
oku
p

Outline
• Background
• Pastry
• Pastry proximity routing
• PAST
• SCRIBE
• Conclusions

Pastry: Proximity routing
Assumption: scalar proximity metric
• e.g. ping delay, # IP hops
• a node can probe distance to any other node
Proximity invariant:
Each routing table entry refers to a node close to the local node (in the proximity space), among all nodes with the appropriate nodeId prefix.
Locality-related route qualities:
• Distance traveled
• Likelihood of locating the nearest replica

Pastry: Routes in proximity space
d46a1c
Route(d46a1c)
d462ba
d4213f
d13da3
65a1fc
d467c4d471f1
NodeId space
d467c4
65a1fcd13da3
d4213f
d462ba
Proximity space
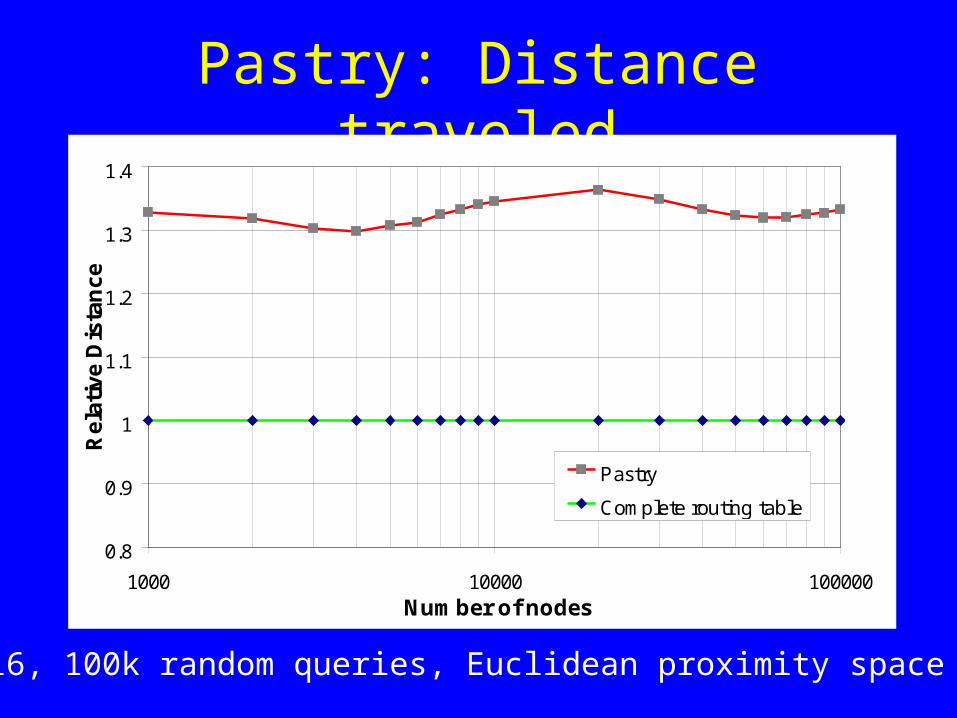
Pastry: Distance traveled
L=16, 100k random queries, Euclidean proximity space
0.8
0.9
1
1.1
1.2
1.3
1.4
1000 10000 100000Number of nodes
Rel
ativ
e D
ista
nce
Pastry
Complete routing table

Pastry: Locality properties
1) Expected distance traveled by a message in the proximity space is within a small constant of the minimum
2) Routes of messages sent by nearby nodes with same keys converge at a node near the source nodes
3) Among k nodes with nodeIds closest to the key, message likely to reach the node closest to the source node first

d467c4
65a1fcd13da3
d4213f
d462ba
Proximity space
Pastry: Node addition
New node: d46a1c
d46a1c
Route(d46a1c)
d462ba
d4213f
d13da3
65a1fc
d467c4d471f1
NodeId space

Pastry delay vs IP delay
0
500
1000
1500
2000
2500
0 200 400 600 800 1000 1200 1400
Distance between source and destination
Dis
tan
ce t
ravele
d b
y P
astr
y m
essag
e
Mean = 1.59
GATech top., .5M hosts, 60K nodes, 20K random messages

Pastry: API
• route(M, X): route message M to node with nodeId numerically closest to X
• deliver(M): deliver message M to application
• forwarding(M, X): message M is being forwarded towards key X
• newLeaf(L): report change in leaf set L to application

Pastry: Security
• Secure nodeId assignment
• Secure node join protocols
• Randomized routing
• Byzantine fault-tolerant leaf set membership protocol

Pastry: Summary
• Generic p2p overlay network
• Scalable, fault resilient, self-organizing, secure
• O(log N) routing steps (expected)
• O(log N) routing table size
• Network proximity routing

Outline
• Background
• Pastry
• Pastry proximity routing
• PAST
• SCRIBE
• Conclusions

PAST: Cooperative, archival file storage and distribution
• Layered on top of Pastry
• Strong persistence
• High availability
• Scalability
• Reduced cost (no backup)
• Efficient use of pooled resources

PAST API
• Insert - store replica of a file at k diverse storage nodes
• Lookup - retrieve file from a nearby live storage node that holds a copy
• Reclaim - free storage associated with a file
Files are immutable

PAST: File storage
fileId
Insert fileId
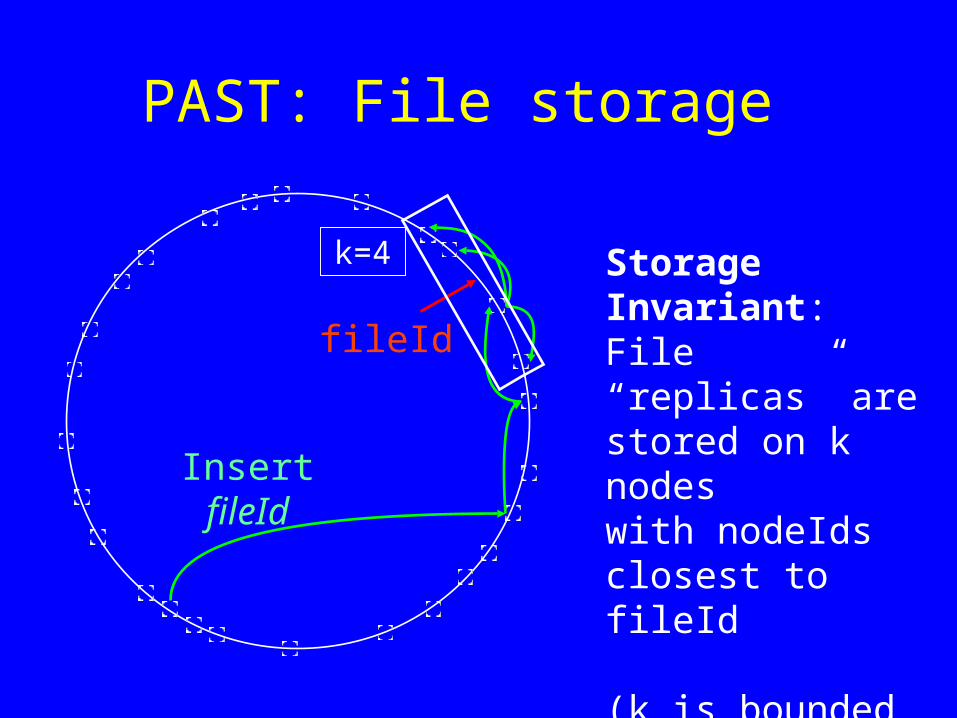
PAST: File storage
Storage Invariant: File “replicas” are stored on k nodes with nodeIdsclosest to fileId
(k is bounded by the leaf set size)
fileId
Insert fileId
k=4

PAST: File Retrieval
fileId file located in log16 N steps (expected)
usually locates replica nearest client C
Lookup
k replicasC

PAST: Exploiting Pastry
• Random, uniformly distributed nodeIds
– replicas stored on diverse nodes
• Uniformly distributed fileIds – e.g. SHA-1(filename,public key, salt)– approximate load balance
• Pastry routes to closest live nodeId– availability, fault-tolerance

PAST: Storage management
• Maintain storage invariant
• Balance free space when global utilization is high– statistical variation in assignment of files to
nodes (fileId/nodeId)– file size variations– node storage capacity variations
• Local coordination only (leaf sets)

Experimental setup
• Web proxy traces from NLANR– 18.7 Gbytes, 10.5K mean, 1.4K median, 0 min,
138MB max
• Filesystem– 166.6 Gbytes. 88K mean, 4.5K median, 0 min,
2.7 GB max
• 2250 PAST nodes (k = 5)– truncated normal distributions of node storage
sizes, mean = 27/270 MB

Need for storage management
• No diversion (tpri = 1, tdiv = 0):
– max utilization 60.8%
– 51.1% inserts failed
• Replica/file diversion (tpri = .1, tdiv = .05):
– max utilization > 98%
– < 1% inserts failed

PAST: File insertion failures
0
524288
1048576
1572864
2097152
0 20 40 60 80 100Global Utilization (%)
Fil
e s
ize
(B
yte
s)
0%
5%
10%
15%
20%
25%
30%
Fa
ilu
re r
ati
o
Failed insertion
Failure ratio

PAST: Caching
• Nodes cache files in the unused portion of their allocated disk space
• Files caches on nodes along the route of lookup and insert messages
Goals:
• maximize query xput for popular documents
• balance query load
• improve client latency

PAST: Caching
fileId
Lookup topicId

PAST: Caching
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
Utilization (%)
Glo
bal C
ache
Hit
Rat
e
0
0.5
1
1.5
2
2.5
Ave
rage
num
ber
of r
outin
g ho
ps
GD-S: Hit RateLRU : Hit RateGD-S: # HopsLRU: # HopsNone: # Hops
None: # Hops
LRU: Hit RateGD-S : Hit Rate
LRU: # Hops
GD-S: # Hops

PAST: Security
• No read access control; users may encrypt content for privacy
• File authenticity: file certificates
• System integrity: nodeIds, fileIds non-forgeable, sensitive messages signed
• Routing randomized

PAST: Storage quotas
Balance storage supply and demand
• user holds smartcard issued by brokers– hides user private key, usage quota– debits quota upon issuing file certificate
• storage nodes hold smartcards– advertise supply quota– storage nodes subject to random audits within
leaf sets

PAST: Related Work
• CFS [SOSP’01]
• OceanStore [ASPLOS 2000]
• FarSite [Sigmetrics 2000]

Outline
• Background
• Pastry
• Pastry locality properties
• PAST
• SCRIBE
• Conclusions

SCRIBE: Large-scale, decentralized multicast
• Infrastructure to support topic-based publish-subscribe applications
• Scalable: large numbers of topics, subscribers, wide range of subscribers/topic
• Efficient: low delay, low link stress, low node overhead

SCRIBE: Large scale multicast
topicId
Subscribe topicId
Publish topicId

Scribe: Results
• Simulation results
• Comparison with IP multicast: delay, node stress and link stress
• Experimental setup– Georgia Tech Transit-Stub model– 100,000 nodes randomly selected out of .5M– Zipf-like subscription distribution, 1500 topics

Scribe: Topic popularity
1
10
100
1000
10000
100000
0 150 300 450 600 750 900 1050 1200 1350 1500
Group Rank
Gro
up
Siz
e
gsize(r) = floor(Nr -1.25 + 0.5); N=100,000; 1500 topics

Scribe: Delay penalty
0
300
600
900
1200
1500
0 1 2 3 4 5
Delay Penalty
Cu
mu
lati
ve G
rou
ps
RMD
RAD
Relative delay penalty, average and maximum
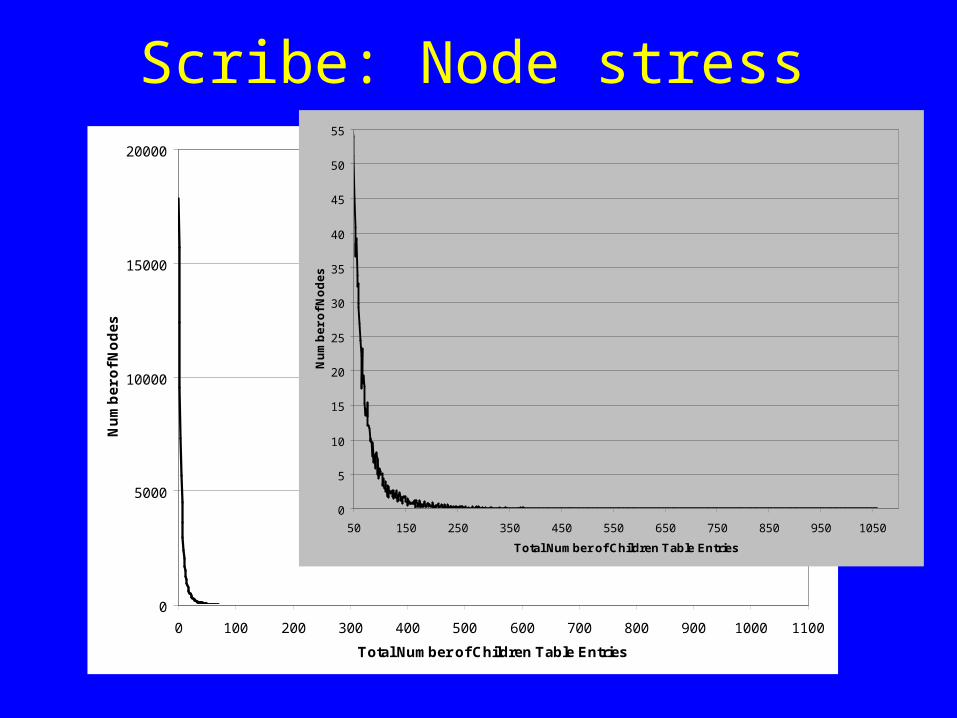
Scribe: Node stress
0
5000
10000
15000
20000
0 100 200 300 400 500 600 700 800 900 1000 1100
Total Number of Children Table Entries
Nu
mb
er
of
No
de
s
0
5
10
15
20
25
30
35
40
45
50
55
50 150 250 350 450 550 650 750 850 950 1050
Total Number of Children Table Entries
Nu
mb
er
of
No
de
s

Scribe: Link stress
0
5000
10000
15000
20000
25000
30000
1 10 100 1000 10000
Link Stress
Nu
mb
er
of
Lin
ks
Scribe
IP Multicast
Maximum stress
One message published in each of the 1,500 topics

Related works
• Narada
• Bayeux/Tapestry
• CAN-Multicast

Summary
Self-configuring P2P framework for topic-based publish-subscribe
• Scribe achieves reasonable performance when compared to IP multicast– Scales to a large number of subscribers
– Scales to a large number of topics
– Good distribution of load

Status
Functional prototypes• Pastry [Middleware 2001]• PAST [HotOS-VIII, SOSP’01]• SCRIBE [NGC 2001, IEEE JSAC]• SplitStream [submitted]• Squirrel [PODC’02]
http://www.cs.rice.edu/CS/Systems/Pastry

Current Work• Security
– secure routing/overlay maintenance/nodeId assignment
– quota system
• Keyword search capabilities• Support for mutable files in PAST• Anonymity/Anti-censorship• New applications• Free software releases

Conclusion
For more information
http://www.cs.rice.edu/CS/Systems/Pastry