reinders siggraph 2017 as presented - … · – not fortran, c, c++, java, c#, perl, python, ruby...
TRANSCRIPT

!"#$%&'$()*$'%+")*,&-()+
!.$&-.)/%.)+!$00&-"(1+
0-.'(")&2(12$-%3$'/$'+#"'1()&*$&-"%"+
!"#$%$&'()*%+,-./'-0%1")#-(..(2$14.)%5-1")1&6'$1('$*&()1$-7*(%)$,&")(#"1(.)*(%)$,&")(#"1(.)%(*$089(8"'"51.*$%:
;<=>?@A?<=Theater 411!BCD&EA+&;FAG

Agenda2:00pm - 2:40pm: Multithreading Introduction and Overview
James Reinders
2:40pm - 3:25pm: Parallel Processing and Multi-Process Evaluation in a Host ApplicationAndy Lin and Joe Longson
3:25pm: Break
3:35pm - 4:05pm: Threading SOPs in HoudiniJeff Lait
4:05pm - 4:35pm: Building a Scalable Evaluation Engine for PrestoFlorian Zitzelsberger
4:35pm - 5:15pm: Parallel Evaluation of Animated Maya CharactersMartin De Lasa

!"#$% &%'()*+,-.
///0"#$% &%'()*+&12*1+,-.03(2
!"#$%&%'()*+&,-./0(.1&2#*$.3//)4%25

“Think Parallel”

“Think Parallel”– Parallelism is almost never effective to
“stick in” at the last minute in a program– Think about everything
in terms of how to do in parallelas cleanly as possible

Motivation
456789:5;*")<5=)&1+)(<:5#<)+5/&%'5>)("&<<&3105'%%>?@@$3%<3-A3()<0A3"
!"#$%&'($!&#)*$+
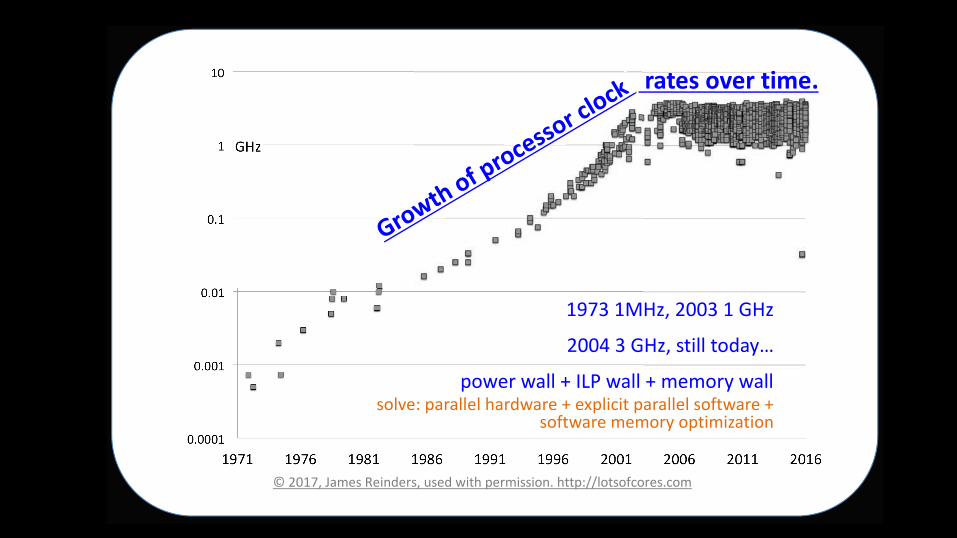
8B9C58DEF:5677C585GEF
677H5C5GEF:5<%&$$5%3+*IJ
>3/)(5/*$$5K5LMN5/*$$5K5")"3(I5/*$$<3$,)?5>*(*$$)$5'*(+/*()5K5).>$&A&%5>*(*$$)$5<3-%/*()5K5
<3-%/*()5")"3(I53>%&"&F*%&31

456789:5;*")<5=)&1+)(<:5#<)+5/&%'5>)("&<<&3105'%%>?@@$3%<3-A3()<0A3"

O3()5*1+5P'()*+5O3#1%< Q&+%'
R&12$)5A3():5<&12$)5%'()*+:5(#$)+5-3(5+)A*+)<0D#$%&%'()*+?52(3/5+&)5*()*5<"*$$5S5-3(5*++&%&315'*(+/*()5%'()*+T<U5<'*(&125()<3#(A)<0D#$%&A3()@D*1I5O3()?5877S5+&)5*()*5-3(5*++&%&31*$5'*(+/*()5%'()*+5/&%'3#%5<'*(&12:
456789:5;*")<5=)&1+)(<:5#<)+5/&%'5>)("&<<&3105'%%>?@@$3%<3-A3()<0A3"
V*%*5>*(*$$)$&<"?5'*1+$&125"3()5+*%*5*%531A):"#$%&WI%):5"#$%&/3(+:5"*1I5/3(+<0

456789:5;*")<5=)&1+)(<:5#<)+5/&%'5>)("&<<&3105'%%>?@@$3%<3-A3()<0A3"
N*(*$$)$5'*(+/*()5+)<&21<5A*15W)
"3() )--&A&)1%5&-5%')I5A*15*<<#")5%'*%
>(32(*"<5/&$$5#<)5<A*$&125-3(5>)(-3("*1A)5/)$$0

Task• Key thing to know:
– Program in TASKS not THREADS.
http://tinyurl.com/threadsYUCK

Task• Key thing to know:
– Program in TASKS not THREADS.
This means:– Programmer’s job: identify (lots) of tasks to do– Runtime’s job: map tasks onto threads at runtime

James’ BIG 3 REASONSto avoid programming to specific hardware mechanisms
1. Portability is impaired severely when coding “close to the hardware”
2. Nested parallelism is IMPORTANT(nearly impossible to manage well using“mandatory parallelism” methods such as threads)
3. Other parallelism mechanisms (e.g., vectorization) need to be considered and balanced.

Parallel Programming• No widely used (popular) programming language
was designed for expressing parallel programming.– Not Fortran, C, C++, Java, C#, Perl, Python, Ruby
• This creates many challenges• Fundamental question of all programming
languages: level of abstraction

Programming Model Ideal Goals• Performance
– achievable, scalable, predictable, tunable, portable• Productivity
– expressive, composable, debugable, maintainable• Portability
– functionality & performance acrossoperating systems, compilers, targets

Level of Abstraction: Parallelism• There is no “perfect” answer (one size fits all)
• Higher level programming (more abstract):– Desired benefits:
More portable, more performance portable, better investment preservation over time.
• Lower level programming (less abstract):– Desired benefits:
More control for the programmer.

Level of Abstraction: Parallelism• There is no “perfect” answer (one size fits all)
• Higher level programming (more abstract):– Desired benefits:
More portable, more performance portable, better investment preservation over time.
• Lower level programming (less abstract):– Desired benefits:
More control for the programmer.
TBB,OpenMP*
OpenCL*,CUDA*
*Thirdpartymarksmaybeclaimedasthepropertyofothers.

Advancing C and C++

KKKRC9=476:53IG:>6:53I>BF;@RB=3! #RVI&<R<BCNL&4dd&NZVILNSIJRP! hJPORUVi! -JPBci! #NS&.%i 8! 8ZRc&EjF! %RCNLJVi! 0LMM3%*i! (PIMC&<LRSMVVRLV! "#*&<LRSMVVRLV! %9"'4&<LRSMVVRLV! (3#&<LRSMVVRLV! R<MP&VRBLSM! VINPONLO&SR==JIIMM&VBZ=JVVJRPV
The most used method to parallelize C++ programs.Z Y%')(51*")<5*1+5W(*1+<5"*I5W)5A$*&")+5*<5%')5>(3>)(%I53-53%')(<0
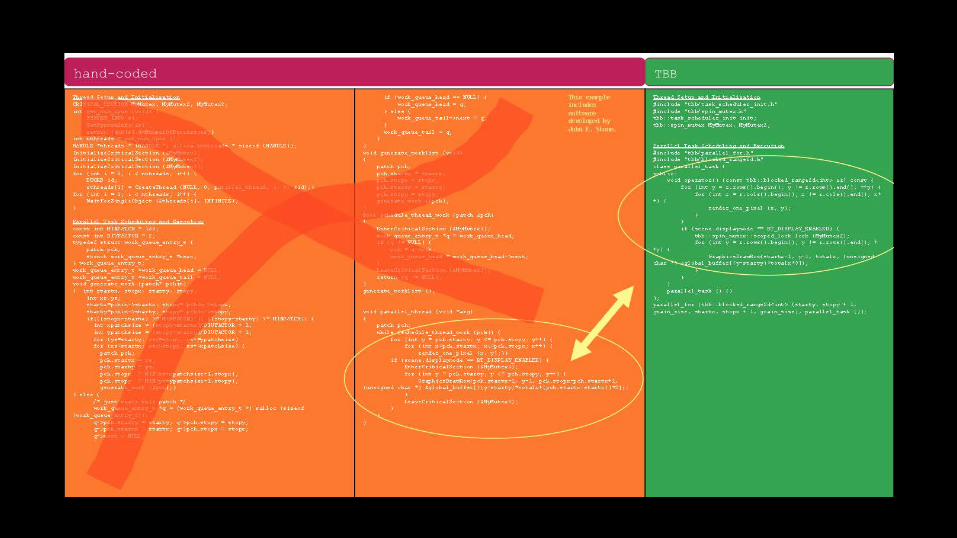
Easiertomaintain,scalesbetter,easiertodebug(getcorrect)

Work StealingThreaddeque
mailbox
Threaddeque
mailbox
Threaddeque
mailbox
Threaddeque
mailbox
CacheAffinity2.Stealtaskadvertisedinmailbox
Loadbalance3.Stealoldesttaskfromrandomvictim
Locality1.Takeyoungesttaskfrommydeque

Work Depth First; Steal Breadth First
L1
L2
victimthread
Bestchoicefortheft!• bigpieceofwork• datafarfromvictim’shotdata.
Secondbestchoice.

1F7>4-.B=K7=6-%5C4>U-$9=476:53-NG:>6:53-N>BF;@-VRW-@F7>4@-4XF4HC:B57>>J-K4>>%5C4>U-$9=476:53-NG:>6:53-N>BF;@-VRW-@F7>4@-4XF4HC:B57>>J-K4>>
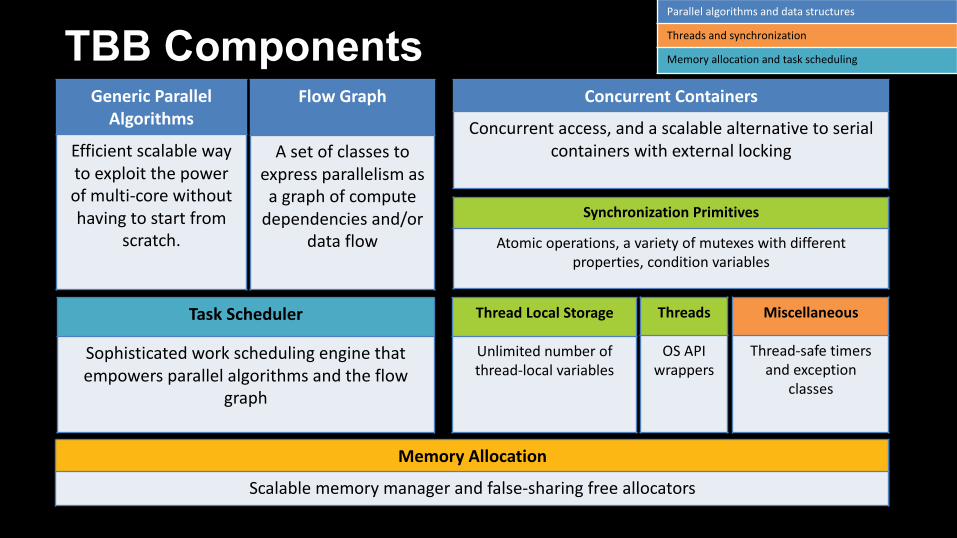
TBB ComponentsGenericParallelAlgorithms
Efficientscalablewaytoexploitthepowerofmulti-corewithouthavingtostartfrom
scratch.
Concurrent Containers
Concurrentaccess,andascalablealternativetoserialcontainerswithexternallocking
TaskScheduler
Sophisticatedworkschedulingenginethatempowersparallelalgorithmsandtheflow
graph
Threads
OSAPIwrappers
Miscellaneous
Thread-safe timersandexception
classes
MemoryAllocation
Scalablememorymanagerandfalse-sharingfreeallocators
SynchronizationPrimitives
Atomicoperations,avarietyofmutexes withdifferentproperties,conditionvariables
FlowGraph
Asetofclassestoexpressparallelismasagraphofcomputedependenciesand/or
dataflow
Parallelalgorithmsanddatastructures
Threadsandsynchronization
Memoryallocationandtaskscheduling
ThreadLocalStorage
Unlimitednumberofthread-localvariables

without lambda, code has to go in a classclass ApplyABC {public:
float *a;float *b;float *c;ApplyABC(float *a_,float *b_,float *c_):a(a_), b(b_), c(c_) {}void operator()(const blocked_range<size_t>& r) const {
for(size_t i=r.begin(); i!=r.end(); ++i) a[i] = b[i] + c[i];
}};
void ParallelFoo( float* a, float *b, float *c, int n ) {parallel_for(blocked_range<size_t>(0,n,10000),ApplyABC(a,b,c) );
puttingcodeinaclassisannoying

doing with lambdas support is more natural
void ParallelApplyFoo(size_t n, int x) {parallel_for( blocked_range<size_t>(0,n,1000),
[&]( const blocked_range<size_t>& r ) -> void{
for( size_t i=r.begin(); i!=r.end(); ++i )a[i] = b[i] + c[i];
});}
mucheasiertoteach/readwithlambdas

Intel® TBB Class Graph: ComponentsInteresting “new” aspect since TBB 4.0 Release (2011)
• Graphobject– Containsapointertotheroottask– Ownstaskscreatedonbehalfofthegraph– Userscanwaitforthecompletionofalltasksof
thegraph
• Graphnodes– Implementsender and/orreceiver interfaces– Nodesmanagemessagesand/orexecute
functionobjects
• Edges– Connectpredecessorstosuccessors
Graphobject==graphhandle
Graphnode
Edge

TBB• Reasons it might matter:
– Everywhere (ports, open source)– Forever (commercial and open source)– Performance Portable
• Problems:– C++ not C
threadingbuildingblocks.org

Cilk™ Plus• Reasons it might matter:
– Space/time guarantees– Performance Portable– C++ and C– Keywords bring compiler into the “know”– “Parent stealing”– Vectorization help too (array notations, elem. func, simd)
• Problems:– Requires compiler changes– Not feature rich– Only in Intel and gcc compilers (and some in Clang/LLVM)– Standards adoption still “future”
cilkplus.org

OpenMP*• Reasons it might matter:
– Everywhere (all major compilers)– Solutions for Tasking, vectorization, offload– Performance Portable
• Problems:– C and Fortran, not so much C++– Not composable– Not always in-sync with language standards
*Thirdpartymarksmaybeclaimedasthepropertyofothers.
openmp.org

OpenCL*• Reasons it might matter:
– Explicit heterogeneous controls– Everywhere (ports)– Non-proprietary– Underpinning for tools and libraries
• Problems:– Low level– Not performance portable
*Thirdpartymarksmaybeclaimedasthepropertyofothers.
khronos.org/opencl

Choice is Good• Our favorite programming languages were
NOT DESIGNED for parallelism.
• They need HELP.
• Multiple approaches and options are NEEDED.

Vectorization: Who, What, Why, When

A moment of clarity
task parallelismdoesn’t matter
without data parallelism
(James’ observation about whatAmdahl and Gustafson were ultimately pointing out)

Parallel first
Vectorize second

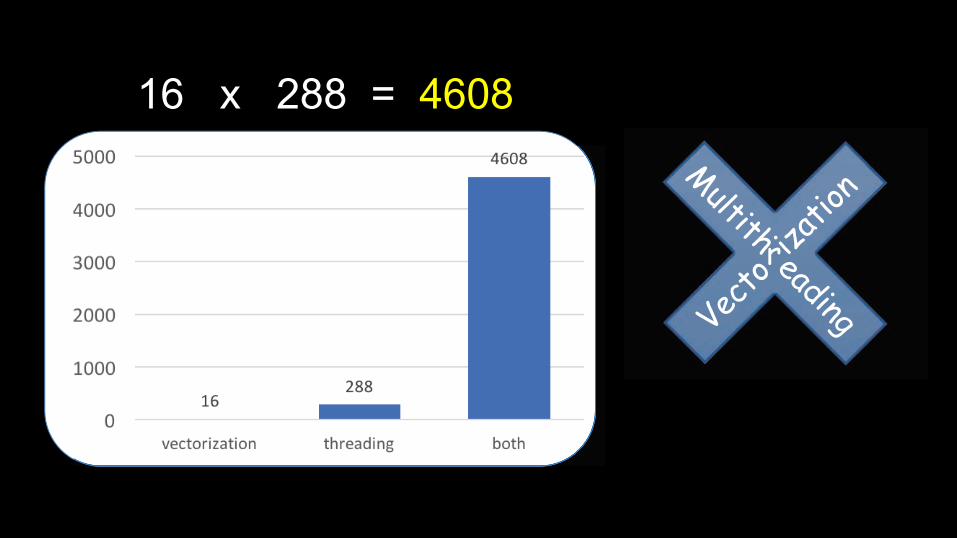
#BCIJIKLMNOJPQ JV =RLM<RUMLYBC IKNP TMSIRLJ[NIJRP\ ZD VJ=<CM =NIK@\a UND YLR= TMSIRLJ[NIJRP[bb-UND&YLR=IKLMNO&<NLNCCMCJV=
Aj c ;nn o HjFn
r

vector data operations:data operations done in parallel
void v_add (float *c,float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}

D4FCB=-67C7-BH4=7C:B5@P67C7-BH4=7C:B5@-6B54-:5-H7=7>>4>
void v_add (float *c,float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
M33>?80 MY\V5*f&g5bh5=*60 MY\V5Wf&g5bh5=WC0 \VV5=*:5=W bh5=AH0 RPY=a5=A bh5Af&gi0 \VV5& K585bh5&

D4FCB=-67C7-BH4=7C:B5@P67C7-BH4=7C:B5@-6B54-:5-H7=7>>4>
void v_add (float *c,float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
M33>?80 MY\V5*f&g5bh5=*60 MY\V5Wf&g5bh5=WC0 \VV5=*:5=W bh5=AH0 RPY=a5=A bh5Af&gi0 \VV5& K585bh5&
float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
M33>?80 MY\V,H5*f&?&KCg5bh5=,*60 MY\V,H5Wf&?&KCg5bh5=,WC0 \VV,H5=,*:5=,W bh5=,AH0 RPY=a,H5=,A bh5Af&?&KCgi0 \VV5& K5H5bh5&

D4FCB=-67C7-BH4=7C:B5@P67C7-BH4=7C:B5@-6B54-:5-H7=7>>4>
void v_add (float *c,float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
M33>?80 MY\V5*f&g5bh5=*60 MY\V5Wf&g5bh5=WC0 \VV5=*:5=W bh5=AH0 RPY=a5=A bh5Af&gi0 \VV5& K585bh5&
float *a,float *b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
M33>?80 MY\V,H5*f&?&KCg5bh5=,*60 MY\V,H5Wf&?&KCg5bh5=,WC0 \VV,H5=,*:5=,W bh5=,AH0 RPY=a,H5=,A bh5Af&?&KCgi0 \VV5& K5H5bh5&
Q)5A*$$5%'&<5j,)A%3(&F*%&31k

vector data operations:data operations done in parallel
void v_add (float *c, float *a, float *b){
for (int i=0; i<= MAX; i++)c[i]=a[i]+b[i];
}
PROBLEM:This LOOP is NOT LEGAL to (automatically) VECTORIZE in C / C++ (without more information).• Arrays not really in the language• Pointers are, evil pointers!

vectorization solutions1. auto-vectorization (let the compiler do it when legal)
– sequential languages and practices gets in the way2. give the compiler hints
– C99 “restrict” keyword (implied in FORTRAN since 1956)– Traditional pragmas like “#pragma IVDEP”– Cilk Plus #pragma simd– OpenMP 4.0 #pragma omp simd
3. code differently– simd instruction intrinsics– Cilk Plus array notations– Cilk Plus __declspec (vector)– OpenMP 4.0 #pragma omp declare simd– OpenCL / CUDA kernel functions

D4FCB=:`7C:B5-@B>GC:B5@A^ NBIR>TMSIRLJ[NIJRP&6CMI&IKM&SR=<JCML&OR&JI&;1%!'$%<)$7
\ VMfBMPIJNC&CNPQBNQMV&NPO&<LNSIJSMV&QMIV&JP&IKM&UND;^ QJTM&IKM&SR=<JCML&KJPIV
\ 4qq&aLMVILJSIb&XMDURLO&6J=<CJMO&JP&0.'1'")&VJPSM&Aq?j7\ 1LNOJIJRPNC&<LNQ=NV&CJXM&ae<LNQ=N&(m*$9b\ 4JCX&9CBV&e<LNQ=N&VJ=O\ .<MP#9&H^F&e<LNQ=N&R=<&VJ=O
E^ SROM&OJYYMLMPICD\ VJ=O JPVILBSIJRP&JPILJPVJSV\ 4JCX&9CBV&NLLND&PRINIJRPV\ 4JCX&9CBV&rrOMSCV<MS 6TMSIRL7\ .<MP#9&H^F&e<LNQ=N&R=<&OMSCNLM&VJ=O\ .<MP4-&l&45*"&XMLPMC&YBPSIJRPV
L15*$$5A*<)<:5<%#+I&12j,)A%3(&F*%&31()>3(%<k5A*15W)A3")*5/*I53-5$&-)0

2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
C99 “restrict” keywordvoid v_add (float *restrict c,
float *restrict a,float *restrict b)
{for (int i=0; i<= MAX; i++)
c[i]=a[i]+b[i];}
2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions

2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
IVDEPvoid v_add (float *c,
float *a,float *b)
{#pragma IVDEP
for (int i=0; i<= MAX; i++)c[i]=a[i]+b[i];
}
2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions

2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
simdvoid v_add (float *c,
float *a,float *b)
{#pragma simd
for (int i=0; i<= MAX; i++)c[i]=a[i]+b[i];
}
2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions

2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
omp simdvoid v_add (float *c,
float *a,float *b)
{#pragma omp simd
for (int i=0; i<= MAX; i++)c[i]=a[i]+b[i];
}
2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions

2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
omp simdvoid v_add (float *c,
float *a,float *b)
{#pragma omp simd
for (int i=0; i<= MAX; i++)c[i]=a[i]+b[i];
}
2.givethecompilerhintsC99“restrict”keywordTraditionalpragmaslike“#pragmaIVDEP”CilkPlus#pragmasimdOpenMP4.0#pragmaompsimd
3.codedifferentlysimd instructionintrinsicsCilkPlusarraynotationsCilkPlus__declspec (vector)OpenMP4.0#pragmaompdeclaresimdOpenCL/CUDAkernelfunctions
Manychoices…Irecommend:

Data Layout: AoS vs. SoA
Structureofarrays(SoA)canbeeasilyalignedtocacheboundariesandisvectorizable.
Arrayofstructures(AoS)tendstocause cachealignmentproblems,andishardtovectorize.

Data Layout: Alignment
51
Array of Structures (AoS), padding at end.
Array of Structures (AoS), padding after each structure.
Structure of Arrays (SoA), padding at end.
Structure of Arrays (SoA), padding after each component.

Think Parallel– Parallelism does NOT work well if
“added” at the last minute in a program
– think about every thing“how to do in parallel cleanly”

'%%>?@@///0"#$%&%'()*+&12*1+,-.03(2@ 7 +08,$0*+2.&,4$#+).9*%)(&*$./(09.%0+*:678H?5D#$%&%'()*+&125-3(5m&<#*$5a--)A%<a.>*1<&3153-5"*%)(&*$5A3,)()+5&15%'&<5%#%3(&*$5>$#<5<3")5).%(*<03,-$&2'
6779?5L1%)$5P'()*+&125X#&$+&125X$3A]<=)"*&1<5*15).A)$$)1%5&1%(3+#A%&315%35PXXo51)/)(5-)*%#()<5*()513%5A3,)()+3,-$&2';.<'&,)2);.=*>*,)2);.?0()*,
'%%>?@@%'()*+&12W#&$+&12W$3A]<0A3"%'()*+&12W#&$+&12W$3A]<0A3"%'()*+&12W#&$+&12W$3A]<0A3"
6786?5R%(#A%#()+5N*(*$$)$5N(32(*""&12a.A)$$)1%5%).%5-3(5)<<)1%&*$<53-5>*(*$$)$5>(32(*""&125-3(5O@OKK3,-$&2';.=*>*,)2)
'%%>?@@>*(*$$)$W33]0A3"8)@2&%).'*2./()).%)*4'&,-.9*%)(&*$2 '%%>?@@$3%<3-A3()<0A3"
E&2'5N)(-3("*1A)5N*(*$$)$&<"678i5JN)*($<5m3$#")5P/3678H5JN)*($<5m3$#")5Y1)3,-$&2'
678p?5L1%)$q5r)315N'&s5N(3A)<<3(E&2' N)(-3("*1A)5N(32(*""&12t1&2'%5M*1+&125a+&%&31555555555553,-$&2'

!"#$% &%'()*+,-.
///0"#$% &%'()*+&12*1+,-.03(2
!"#$%&%'()*+&,-./0(.1&2#*$.3//)4%25
$975;-JBGd

Agenda2:00pm - 2:40pm: Multithreading Introduction and Overview
James Reinders
2:40pm - 3:25pm: Parallel Processing and Multi-Process Evaluation in a Host ApplicationAndy Lin and Joe Longson
3:25pm: Break
3:35pm - 4:05pm: Threading SOPs in HoudiniJeff Lait
4:05pm - 4:35pm: Building a Scalable Evaluation Engine for PrestoFlorian Zitzelsberger
4:35pm - 5:15pm: Parallel Evaluation of Animated Maya CharactersMartin De Lasa