regresión con errores normal-asimétricos: una...
TRANSCRIPT

Regresión con Errores Normal-asimétricos: UnaAplicación en Selección Genómica
Rocío Guadalupe Acosta-Pech 1
Paulino Pérez-Rodríguez2
José Crossa 3
1Universidad Autónoma de Yucatán 2Colpos-México 3CIMMyT-México
2◦ Encuentro Nacional de Jóvenes Investigadores en Matemáticas, 2018 .

Contenido
1 Motivación
2 Distribución Normal Asimétrica
3 Regresión con errores normal-asimétricos
4 Aplicación con datos reales
5 Conclusiones
6 Referencias

Motivación
Un modelo simple usado a menudo en mejoramiento de plantas y animalesindica que el valor fenotípico de un individuo (P) puede expresarse como lasuma de un valor genético (G) y un residual (E):
P = G + E , (1)
donde G incluye efectos aditivos, de dominancia y epistáticos.

Continuación...
Figura 1: Genes y cromosomas, bases nitrogenadas.

Marcadores moleculares
Definición (Marcador Molecular (MM))
Un MM es un fragmento de ADN con una ubicación definida (locus) en uncromosoma. Un MM puede ser un gen o simplemente una sección de ADNsin función conocida.
Generalmente los segmentos de ADN contiguos en un cromosoma seheredan juntos, así los MM pueden usarse para rastrear genes. Existendiferentes tipos de marcadores, por ejemplo:
AFLP (Amplified Fragment Length Polymorphism).SNPs.Microsatélites (SSR o STR).DArT.GBS.
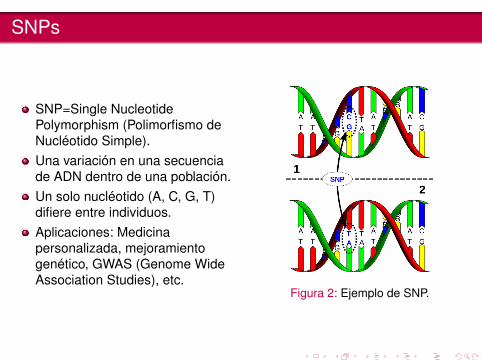
SNPs
SNP=Single NucleotidePolymorphism (Polimorfismo deNucléotido Simple).Una variación en una secuenciade ADN dentro de una población.Un solo nucléotido (A, C, G, T)difiere entre individuos.Aplicaciones: Medicinapersonalizada, mejoramientogenético, GWAS (Genome WideAssociation Studies), etc.
Figura 2: Ejemplo de SNP.

Continuación...
Figura 3: Esquema de selección genómica (Desta y Ortiz, 2014).

Modelos
Los valores genéticos son aproximados usando regresión lineal (Meuwissenet al., 2001), es decir:
yi = gi + ei = β0 +
p∑j=1
xijβj + ei (2)
Figura 4: Relación entre marcadores (x1i : 0y 1) y fenotipos (yi ).

Problemas y alternativas
Problemas:1 Generalmente p >> n (maldición de dimensionalidad).2 Los modelos de regresión existentes suponen que la distribución de la
VR es normal.3 Existen aplicaciones en los que la VR exhibe distribuciones asimétricas.
Alternativas:1 Regresión penalizada, enfoque Bayesiano.2 Modelos más generales.3 Transformaciones.

Distribución Normal Asimétrica
Una variable aleatoria continua U se dice que tiene una distribuciónnormal-asimétrica, con parámetro de forma λ ∈ R y se denota por SN(λ) sisu función de densidad está dada por:
fU(u;λ) = 2φ(u)Φ(λu)I(−∞,∞)(u),
donde φ(·) y Φ(·) denotan las funciones de densidad y distribución de unavariable aleatoria normal estándar respectivamente.
Sea Y = ξ + ωU entonces Y ∼ SND(ξ, ω, λ). La función de densidad de Yestá dada por:
f (y |ξ, ω, λ) = 21ωφ
(y − ξω
)Φ
[λ
(y − ξω
)]
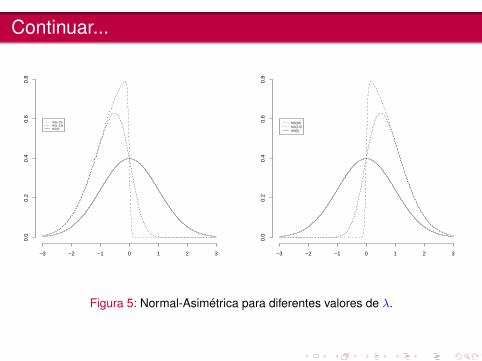
Continuar...
−3 −2 −1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
NS(−20)NS(−2.5)NS(0)
−3 −2 −1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
NS(20)NS(2.5)NS(0)
Figura 5: Normal-Asimétrica para diferentes valores de λ.

Regresión con errores normal asimétricos
Azzalini y Capitanio (1999); Russell y González-Farías (2002) propusieron unmodelo de regresión lineal simple con los términos del error, eiindependientes e idénticamente distribuidos SND(0, ω, λ). El modelo es:
yi = β0 +
p∑j=1
xijβj + ei
por las propiedades de la distribución normal-asimétrica,yi ∼ SND(β0 +
∑pj=1 xijβj , ω, λ).
Problemas con estimación de λ, puntos de inflexión con λ = 0, matrizHessiana singular, etc. En general la parametrización Directa no esrecomendable para realizar inferencia.¿Caso n << p?

Parametrización Centrada
Azzalini y Capitanio (1999) proponen reparametrizar de (ξ, ω, λ) a (µ, σ2e , γ1).
1 U ∼ SND(λ), E(U) =√
2π
λ√1+λ2
, Var(U) = 1− 2π
λ2
1+λ2 .
2 Sea Y = µ+ σe
(U−E(U)√
Var(U)
).
3 Y ∼ SNC(µ, σ2e , γ1), con γ1 el coeficiente de asimetría de U,
γ1 = [E(U)]3
[Var(U)]3/2 .
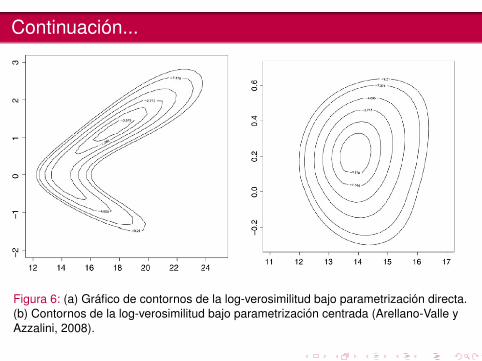
Continuación...
Figura 6: (a) Gráfico de contornos de la log-verosimilitud bajo parametrización directa.(b) Contornos de la log-verosimilitud bajo parametrización centrada (Arellano-Valle yAzzalini, 2008).

Continuación...
En el contexto del modelo de regresión, se tiene :
yi = β0 +
p∑j=1
xijβj + ei , ei ∼ SNC(0, σ2e , γ1),
1 E(yi ) = β0 +∑p
j=1 xijβj = β0 + x ′iβ.2 Var(yi ) = σ2
e .3 yi ∼ SNC(β0 + x ′iβ, σ
2, γ1).
La función de verosimilitud está dada por:
p(β0,β, σ2e , γ1|y) =
n∏i=1
SNC(yi |β0 + x tiβ, σ
2e , γ1)

Truncamiento oculto
Sea V y W dos variables aleatorias cuya distribución conjunta es como sigue:(VW
)∼ N2
((00
),
(1 ρρ 1
)),
ρ ∈ (−1,1) y se define la variable U como sigue:
U = W si V ≥ 0
entonces U ∼ SN(λ), con λ =ρ√
1− ρ2(Arnold y Beaver, 2000; Liseo y
Parisi, 2013).
Esta representación permite escribir la función de verosimilitud aumentadacomo si, se hubiera observado el valor Z = V > 0.

Continuación...
La distribución condicional de U|Z = z es N(ρz,1− ρ2) y Z ∼ TN(0,1,0,∞).
La distribución conjunta de U y Z es:
fU|Z (u|z, ρ)fZ (z) = f (u, z|ρ).
Esto es:
fU,Z (u, z; ρ) = 1√2π√
1−ρ2exp
{− 1
2(1−ρ2)(u − ρz)2
}× 2√
2πexp
{− 1
2 z2}
I(0,∞)(z); u ∈ R(3)

Continuación...
Considere la siguiente transformación:
Y = µ+ σe
(U − E(U)√
Var(U)
)T = Z
La densidad conjunta de Y y Z es:
fY ,Z (y , z|µ, σ2e , ρ) = ζ√
2πexp
{ζ2
2
(y − µ− σe
SUρz + σe
SU
)2}
× 2√2π
exp{− 1
2 z2}
I(0,∞)(z),(4)
donde ζ = SU
σe
√1−ρ2
.

Continuación...
En el contexto de regresión µ representa el valor esperado de la variablerespuesta, esto es, µi = β0 + xt
iβ.
La verosimilitud aumentada es:
L(θ|y, z,X) =
n∏i=1
2√
2π√
1− ρ2
Su
σeexp
{− 1
2(1− ρ2)
[(yi − µi
σe
)Su + Eu − ρzi |
]2}
(5)
× 1√2π
exp{−1
2z2
i
}

Distribuciones a priori
β0|σ2β0∼ N(0, σ2
β0),
β|σ2β ∼ NM(0, σ2
βI),
σ2e |Se,dfe ∼ χ−2(Se,dfe),
σ2β|Sβ,dfβ ∼ χ−2(Sβ,dfβ),
p(ρ|a0,b0) ∝(
1− ρ2
)a0−1(1− 1− ρ
2
)b0−1
.
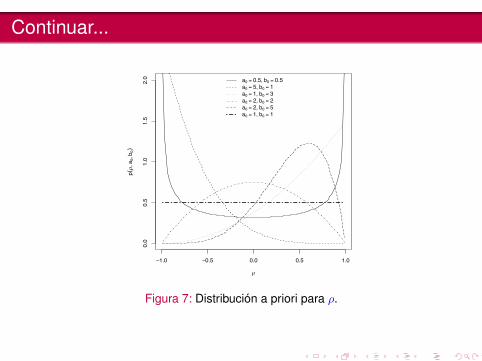
Continuar...
−1.0 −0.5 0.0 0.5 1.0
0.0
0.5
1.0
1.5
2.0
ρ
p(ρ,
a0,
b0)
a0 = 0.5, b0 = 0.5a0 = 5, b0 = 1a0 = 1, b0 = 3a0 = 2, b0 = 2a0 = 2, b0 = 5a0 = 1, b0 = 1
Figura 7: Distribución a priori para ρ.

Continuación...
Aplicando el teorema de Bayes la distribución posterior, después de agregarla variable latente, queda expresada como:
p(θ|y , z ,X ) ∝∏n
i=11
2π√
1−ρ2
Suσe
×exp{− 1
2(1−ρ2)S2
u
(yi − µi − σe
Suρzi + σe
SuEu
)2}
× 1√2π
exp{− 1
2 z2i
} 1√2πσ2
β0
exp{− 1σ2β0
β20
}×N(β|0, σ2
β I)χ−2(σ2e |dfe,Se)χ−2(σ2
β|dfβ ,Sβ)p(ρ|a0,b0)
(6)
Se obtuvieron las distribuciones condicionales completas de los parámetros,y en el caso de (β0,β, σ
2β , z) fue posible reconocer el núcleo de su
distribución, pero en el caso de (σ2e , ρ) no.

Distribución Condicional de β0
β0|resto ∼ N
β0;
∑i=1 y∗i
n + (1−ρ2)σ2e
S2uσ
2β0
,(1− ρ2)σ2
e
S2u
(n + (1−ρ2)σe2
S2uσ
2β0
) .
y∗i = yi − xtiβ −
σeSuρzi + σe
SuEu.
Distribución Condicional de βj , j = 1, . . . ,p
βj |resto ∼ N
∑ni=1 xijy∗i∑n
i=1 x2ij + (1−ρ2)σ2
eS2
uσ2β
,(1− ρ2)σ2
e
S2u
[∑ni=1 x2
ij + (1−ρ2)σ2e
S2uσ
2β
] .
y∗i = yi − β0 − xti,−jβ−j − σe
Suρzi + σe
SuEu.

Distribución condicional de las variables latentes
p(zi |resto) ∝ exp{− 1
2(1−ρ2)(y∗i − ρzi )
2}
exp{− 1
2 z2i
}= exp
{− 1
2(1−ρ2)(−2y∗i ρzi + z2
i )}
= exp{− 1
2(1−ρ2)(zi − ρy∗i )2
}I(0,∞)(zi ), i = 1, . . . ,n.
Entonces:zi ∼ NT (µ = ρy∗i , σ
2e = 1− ρ2,a = 0,b =∞),
donde y∗i =(
yi−β0−xti β
σe
)Su + Eu.

Distribución condicional de σ2β
σ2β |resto ∼ χ−2(dfβ + p,βtβ + Sβ).
Distribución condicional de ρ
p(ρ|resto) ∝ exp
{− 1
2(1− ρ2)σ2e
S2u
[(yi − β0 − xt
iβ −σe
Suρzi +
σe
SuEu
)2]}
×(
1−ρ2
)a0−1 (1− 1−ρ
2
)b0−1(
Su√1−ρ2
)n
I(−1,1)(ρ).

Se propone utilizar la transformación de Fisher (1915) para ρ definida como
ϑ =12
log(
1 + ρ
1− ρ
)= tanh−1(ρ), el soporte de ϑ está en R.
p(ϑ|resto) ∝ p(ρ|resto)× tanh(ϑ).
a. Muestrear ϑ, ϑ = ϑk + V donde V ∼ N(0, ν2)
b. Muestrear u, U ∼ U(0,1)
c. Si u <p(ϑ|resto)
p(ϑk |resto)) entonces ϑk+1 = ϑ, de otro modo ϑk+1 = ϑk .
Una vez que se ha obtenido ϑk+1, calcular ρ = tanh(ϑk+1). El parámetro ν2 sepuede modificar para obtener una tasa de aceptación óptima.

Distribución Condicional de σ2e
p(σ2e |resto) ∝(
σ2e)(− dfe+n
2 +1)×
exp{− 1
2(1−ρ2)σ2eS2
u
[∑ni=1
(yi − β0 − xt
iβ −σeSuρzi + σe
SuEu
)2+ (1−ρ2)
S2u
Se
]}.

Aplicación con datos reales
El conjunto de datos proviene del proyecto de Maíz de Tolerancia a laSequía del Programa Global de Maíz de CIMMyT (cimmyt.org).Los datos genotípicos consisten en información de 300 líneasendogámicas tropicales que fueron genotipadas utilizando 1,152 SNPs(Single Nucleotide Polymorphisms).El rasgo analizado es la mancha gris de plomo (GLS) causada por elhongo Cercospora zeae-maydis evaluada en 3 ambientes.

Continuación...
Figura 8: Mancha gris.
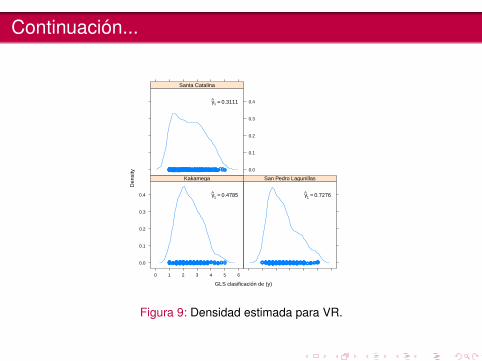
Continuación...
GLS clasificación de (y)
Den
sity
0.0
0.1
0.2
0.3
0.4
0 1 2 3 4 5 6
● ● ●● ●● ● ●●● ● ● ●● ● ●● ●●● ●●●●● ●● ●● ●● ● ●● ● ●●● ●●● ●●● ●● ●●●
● ● ●●● ●● ●● ●● ● ●● ● ●● ● ●● ● ●● ●● ● ●● ●●● ● ●●● ● ●● ● ●●● ●● ●● ●● ● ●●●● ●●●● ●● ● ●●●● ●● ●●●●● ●●● ●●●● ●●● ●● ●● ●● ●● ●●● ●●●●● ●● ●● ● ●●● ● ●● ● ●●● ●● ●● ● ● ●●● ●●●● ●● ●● ● ● ●●● ● ●●● ● ● ●● ●● ●● ●● ●● ● ● ●● ●● ● ●● ● ●● ● ● ●●●● ●●● ●●●● ●● ●● ●●● ●● ●●●●● ● ●●● ●●●● ●●●●● ●● ●● ● ●●● ●● ●● ●● ●●● ●●●
Kakamega
●● ●●●●● ● ●● ●● ●●● ●● ● ●● ●●● ●● ●● ●● ●● ●●●● ●●● ●
● ● ●● ●● ●● ● ●●● ●● ●● ●● ●●●●●●● ●● ●●● ●●● ●● ●● ●●●● ●● ●● ●● ● ●●●● ●● ●●● ●●●
●●●● ●●●●● ●● ●●●● ●●● ●● ● ●●●● ●●●● ●● ●●● ●●● ●● ●● ●● ●● ●● ● ●● ●● ●● ● ●● ●●● ●● ● ● ●● ●●● ● ● ●●● ● ●●●●● ●
● ●●● ●● ● ● ●● ●● ● ●● ●● ●●●● ●● ● ●●● ●●●● ●●●●● ●● ● ●●● ●● ● ●● ● ●●● ●● ●●● ● ●● ● ●●●● ● ●● ●● ● ●● ●●
San Pedro Lagunillas
0.0
0.1
0.2
0.3
0.4
● ●● ●●● ●● ●● ●● ●●● ●● ● ●● ● ●●●●● ● ●● ●● ● ●● ● ● ●● ●●● ●● ●● ●● ●● ●●● ● ●●● ●● ● ●●● ●● ●● ● ● ●●●●● ●●● ● ●●● ●●●● ●●● ● ● ●● ●●●● ●●● ● ●●● ●●● ● ●● ●●● ●● ●● ●●● ●● ●● ●● ●● ● ●● ● ●● ●●●● ●● ●●●●●● ●● ●● ●●● ●●● ●● ●
● ●● ●● ● ●● ●● ● ●●● ●●●● ● ● ●●●●●● ●●●● ●● ●●●● ●●●● ●● ●●● ●●● ●●●
●● ●● ●● ●●● ● ●●● ● ●● ● ●● ●● ● ●● ● ●● ●● ● ●●● ● ●●●
●● ●●● ●● ● ● ● ● ●● ● ●●●● ● ●●● ●●●
Santa Catalina
γ̂1 = 0.4785
γ̂1 = 0.3111
γ̂1 = 0.7276
Figura 9: Densidad estimada para VR.
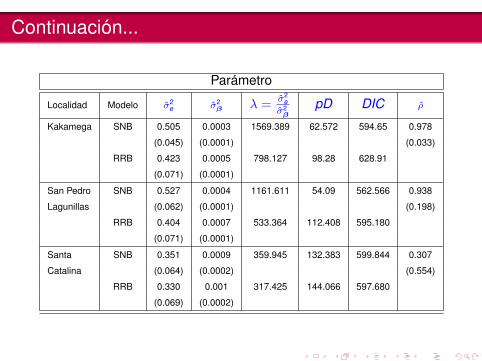
Continuación...
Parámetro
Localidad Modelo σ̂2e σ̂2
β λ =σ̂2
eσ̂2β
pD DIC ρ̂
Kakamega SNB 0.505 0.0003 1569.389 62.572 594.65 0.978
(0.045) (0.0001) (0.033)
RRB 0.423 0.0005 798.127 98.28 628.91
(0.071) (0.0001)
San Pedro SNB 0.527 0.0004 1161.611 54.09 562.566 0.938
Lagunillas (0.062) (0.0001) (0.198)
RRB 0.404 0.0007 533.364 112.408 595.180
(0.071) (0.0001)
Santa SNB 0.351 0.0009 359.945 132.383 599.844 0.307
Catalina (0.064) (0.0002) (0.554)
RRB 0.330 0.001 317.425 144.066 597.680
(0.069) (0.0002)

Continuación...
Predicción de GLS con SNB
Pre
dicc
ión
de G
LS c
on R
RB
1
2
3
4
2 3 4
●●
●
●
●
●● ●●
●
●●
●
●
●●
●●●
●
●
●
●●●
●
●●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
● ●
●●●
●
●
●
●
●●●●●●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●● ●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●●
●
●
●●
● ●●
●
●●
●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●●
●
●
●
●●
●●
●
●
●
●
●●
●●
●
●
●●
●
●●
●
●
●●●
●●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●●
Kakamega
●
●
●
●
●
●●
●
●
●
●●
●●●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
● ●
●●●
●
●
●
●
●
●
●
●
●
San Pedro Lagunillas1
2
3
4
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
Santa Catalina
Figura 10: Predicciones de BRR vs BSN para GLS.
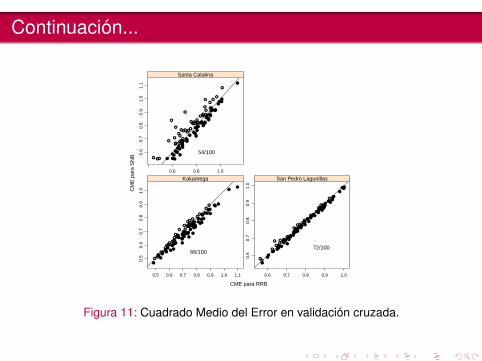
Continuación...
CME para RRB
CM
E p
ara
SN
B
0.5
0.6
0.7
0.8
0.9
1.0
0.5 0.6 0.7 0.8 0.9 1.0 1.1
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●●
●
66/100
Kakamega
0.6
0.7
0.8
0.9
1.0
0.6 0.7 0.8 0.9 1.0
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
72/100
San Pedro Lagunillas
0.6
0.7
0.8
0.9
1.0
1.1
0.6 0.8 1.0
●
●
●
●
● ●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●●●
●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
54/100
Santa Catalina
Figura 11: Cuadrado Medio del Error en validación cruzada.
Continuación...
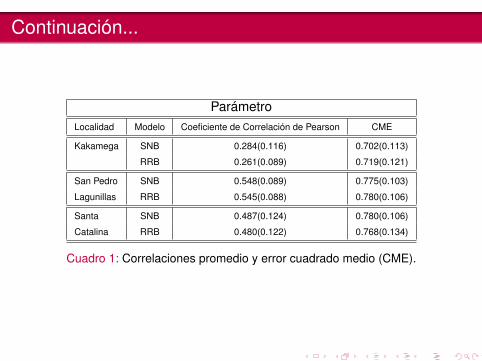
ParámetroLocalidad Modelo Coeficiente de Correlación de Pearson CME
Kakamega SNB 0.284(0.116) 0.702(0.113)
RRB 0.261(0.089) 0.719(0.121)
San Pedro SNB 0.548(0.089) 0.775(0.103)
Lagunillas RRB 0.545(0.088) 0.780(0.106)
Santa SNB 0.487(0.124) 0.780(0.106)
Catalina RRB 0.480(0.122) 0.768(0.134)
Cuadro 1: Correlaciones promedio y error cuadrado medio (CME).

Conclusiones
Se propuso una alternativa que permite ajustar modelos de regresióncuando la VR tiene distribución asimétrica.El modelo propuesto es un caso general del modelo de regresión linealmúltiple usual.El modelo puede utilizarse con datos altamente dimensionales p >> n.El poder predictivo del modelo propuesto es igual o superior al delmodelo de regresión usual con errores normales.

Referencias
Azzalini, A. y Capitanio, A. (1999).Statistical applications of the multivariate skew normal distribution.Journal of the Royal Statistical Society , 61:579-601.
Fisher, R.A. (1915).Frequency distribution of the values of the correlation coefficient insamples from an indefinitely large population.Biometrical ,10:507-521.
Kim, H.J.(2005).Bayesian Estimation for Skew Normal Distributions Using DataAugmentation.Communications for Statistical Applications and Methods , 12:323-333.
Meuwissen, T.H.E., Hayes, B.J. y Goddard, M.E. (2001).Prediction of Total Genetic Value Using Genome-Wide Dense MarkerMaps.Genetics , 157:1819-1829.