redefine ship in cloud
TRANSCRIPT

REDEFINE SHIP IN
CLOUD
Adhish PendharkarPivotal
1

Disclaimer2
MapReduce is one of the parallel processing frameworks, the reader is advised to look at other parallel processing frameworks / architectures.
RDBMS offer real advantages over Hadoop or unstructured data products, if you are looking for performance over schema / structure you are better off on RDBMS.
NoSQL databases are gaining ground, however the underline data they target is purely analytical. Transactional data should be left in RDBMS.

Target Audience
Merchant Shipping Staff
Technical Ship Managers / Masters (Capt.) /
Engineers who understand vessel.
Data Engineers / Scientist who would like to
look at this USE CASE as a old legacy
transformation exercise.
[POJO] Poor Old Java Orchestrators
Cloud Enthusiast
(www.cloudappreciationsociety.org)
3

Challenges
Regulations – merchant shipping industry is one of the most heavily regulated industry. International Maritime Organization (IMO / ILO)
Lloyds / DNV
Safety Of Life At Sea (SOLAS)
Equipment Manufacturers Regulations
Flag / Country / Port / Cargo….
Undefined Design Standards – Ship Building is regulated however there are no constrains on how the ship is build, it is up to the Naval Architect. Major Challenge for Data Architects.
Every Ship is a designer product – (exception Sister Ship) it is built only once so every ship is unique.
Too many unique data points – nightmare for data architects, data models tend to be built on exception than norm.
4
Prerequisite – (Optional)
Understanding of Hadoop or any other Cloud
based unstructured data.
Understanding of Pivotal Stack (www.pivotal.io/big-
data/pivotal-hd)
Greenplump
HAWQ
Data Lake (Sqoop / Flume)
Eclipse IDE
5
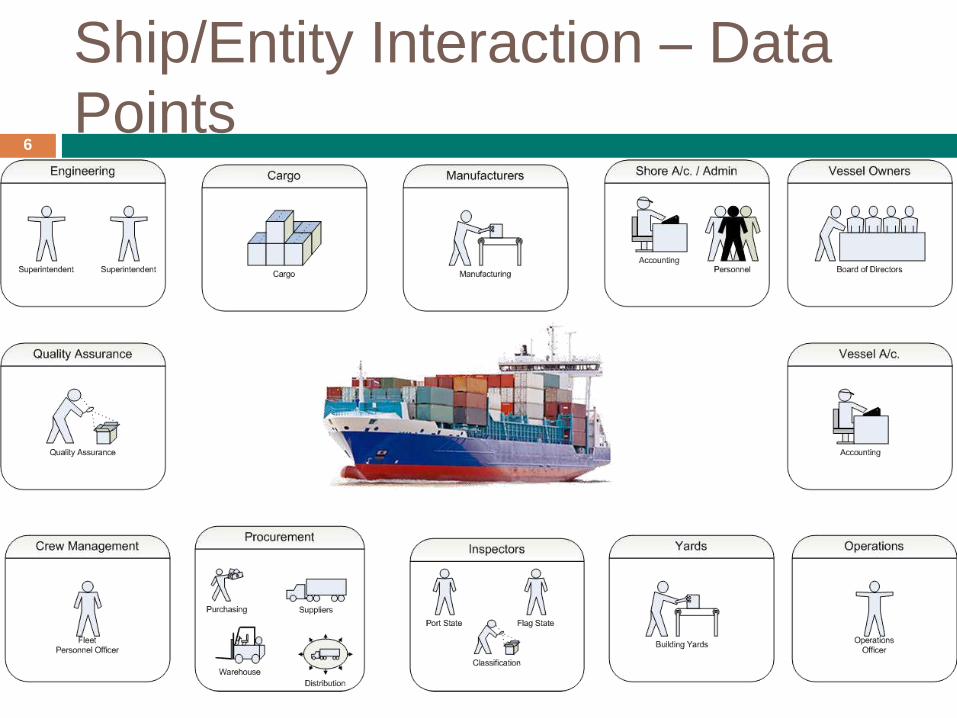
Ship/Entity Interaction – Data
Points6

Answer to life universe and
everything7
The answer to the ultimate question of Life, the Universe, and Everything is
42! The Hitchhiker’s Guide to Galaxy by Douglas Adams
Hull
Meta
Data
Bridge
Outer Forward Structure
Hull
Structure
Tank
StructureAccommodatio
n
Shell Plating - Top Side
Port, Top Side SB, Boot Top
Port, Boot Top SB
Data Points
Value
Attributes
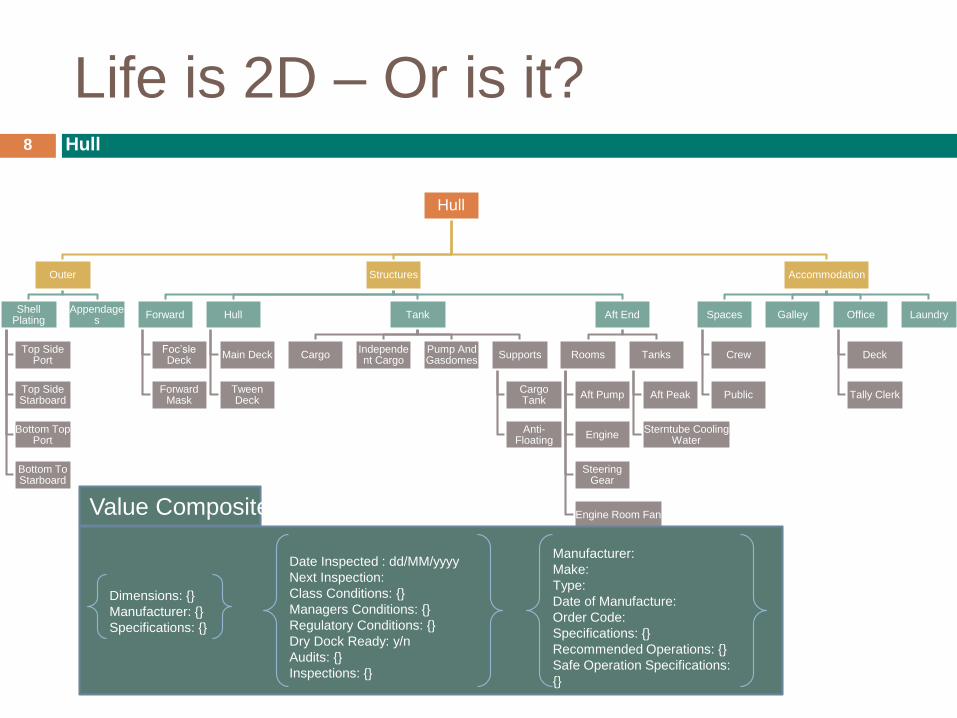
Hull
Outer
Shell Plating
Top Side Port
Top Side Starboard
Bottom Top Port
Bottom To Starboard
Appendages
Structures
Forward
Foc’sleDeck
Forward Mask
Hull
Main Deck
TweenDeck
Tank
CargoIndependent Cargo
Pump And Gasdomes
Supports
Cargo Tank
Anti-Floating
Aft End
Rooms
Aft Pump
Engine
Steering Gear
Engine Room Fan
Tanks
Aft Peak
Sterntube Cooling Water
Accommodation
Spaces
Crew
Public
Galley Office
Deck
Tally Clerk
Laundry
Life is 2D – Or is it?8 Hull
Date Inspected : dd/MM/yyyy
Next Inspection:
Class Conditions: {}
Managers Conditions: {}
Regulatory Conditions: {}
Dry Dock Ready: y/n
Audits: {}
Inspections: {}
Dimensions: {}
Manufacturer: {}
Specifications: {}
Value Composite
Manufacturer:
Make:
Type:
Date of Manufacture:
Order Code:
Specifications: {}
Recommended Operations: {}
Safe Operation Specifications:
{}
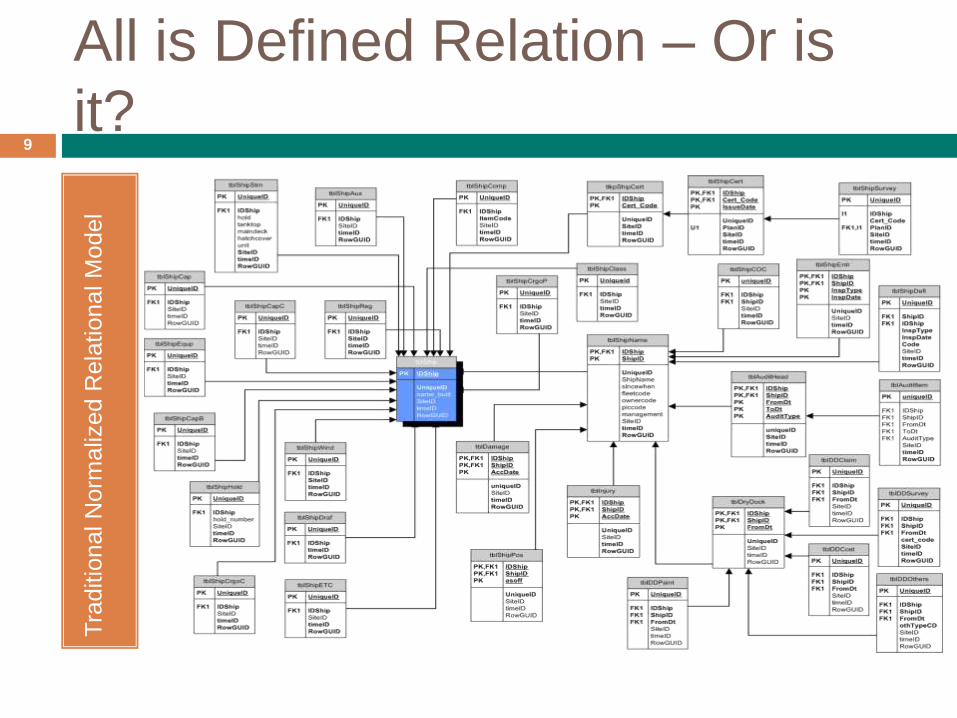
All is Defined Relation – Or is
it?9
Tra
ditio
nal N
orm
aliz
ed R
ela
tional M
odel

Recap or the beginning? 10
Every Ship is unique – The underline data
model was based on best guess approach.
No Child Left Behind Constrains – To maintain
FK relations phantom data needed to be
created.
Data Analysis – Roll ups STAR Schema turned
into Snow Flakes turned into complex
DIMENSION Queries.
Rippled effects – Changes into core structures
where only a dream

Putting on the Cloud Glasses11
@Entity
Ship/Entity{ ShipMap1({..}),
ShipMap2({..})..}
@Component
ShipMap(Key, Values({Hull{..},
Deck{..},
Cargo{..},
Machinery{..},
Bridge{..},
Financial{..},… }));
@Service
ShipReduce(Key, ShipMap[]());
Domain
Logical Data Model (LDM)
Data Values

@Column(name="ship_keel_laid")
private Date shipKeelLaid;
public Date getShipKeelLaid() {
return this.shipKeelLaid;
}
@Transient
private Set<Hull> shipHull = new HashSet<Hull>();
public Set<Hull> getShipHull() {
/*
* Fetch the data first time
*/
return this.shipHull;
}
The Ship Entity - PoJo12
public class Ship implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name=“shipid")
private String shipId;
public String getId() {
return this.shipId;
}
@Column(name="ship_name_built")
private String shipNameBuilt;
public String getShipNameBuilt() {
return shipNameBuilt;
}
public void setShipNameBuild(String lShipNameBuilt) {
this.shipNameBuilt = lShipNameBuilt;
}
@Column(name="ship_hull_number")
private String shipHullNumber;
public String getShipHullNumber() {
return shipHullNumber;
}
public void setShipHullNumber(String lShipHullNumber) {
this.shipHullNumber = lShipHullNumber;
}

Map & Reduce – Map<K,V>13
protected void map(LongWritable Id, ShipInputWritable value, Context context) {
try {
String[] keys = value.getshipHull().getOuterHull().ManufactureNames;
for (String key : keys) {
context.write(new Text(key), one);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public class ShipHullDbReducer extends
Reducer<Text, TextWritable, ShipOutputWritable, NullWritable> {
protected void reduce(Text key, Iterable<TextWritable> values, Context ctx) {
String names = “”;
for (TextWritable value : values) {
names += value.get()+”;”;
}
try {
ctx.write(new ShipOutputWritable(key.toString(), names),NullWritable.get());
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}

Creating the HAWQ Tables14
CREATE TABLE speakerseriese.ship
(
shipid integer,
ship_name_built varchar(50),
ship_hull_number varchar(15),
ship_keel_laid date,
ship_date_expected date,
ship_date_delivered date,
ship_imo_number varchar(15),
) WITH (appendonly=true, compresstype=quicklz) DISTRIBUTED RANDOMLY;

Is that all? – Or is it?15
User Story
As a Superintendent, I want to be notified daily for
the fuel consumptions of my fleet within a
deviation of ±30%.
As a fleet Manager, I want to see fuel
consumption trending for the entire fleet.
The above code samples are just a very high level to indicate how to model relational
schemas into unstructured storage. The power starts when the business starts to
analyze!!

Fuel Consumption User Story16
Engine Logbook
Vessel,date,hoME,doME,goME,hoAE,doAE,goAE
m.v. ship1,01/01/2014,5.2,3.0,0.5,1.2,3.2,2.0
m.v. ship2,01/01/2014,1.2,1.1,1.5,1.2,3.2,2.0
m.v. ship3,01/01/2014,4.2,2.1,2.5,1.2,3.2,2.0
m.v. ship1,02/01/2014,0.2,3.3,2.5,1.2,3.2,2.0
m.v. ship2,02/01/2014,1.2,1.0,1.7,1.2,3.2,2.0
m.v. ship3,02/01/2014,4.2,6.2,3.5,1.2,3.2,2.0
m.v. ship1,03/01/2014,2.2,0,1.0,1.2,3.2,2.0
m.v. ship2,03/01/2014,3.2,0,0.5,1.2,3.2,2.0
m.v. ship3,03/01/2014,5.2,0,0.5,1.2,3.2,2.0
Raw Date (sample)
CREATE external table enginelogbook (shipname text, hoME double, doME double, goME double, hoAE double, doAE
double, goAE double) location (‘pxf://namenode:<port>/job/target/path/Job-ID?
FRAGMENTER=HdfsDataFragmenter&ACCESSOR=DataLoaderAvroFileAccessor&RESOLVER=TextResolver’) FORMAT ‘TEXT’
(DELIMITER=“,”);
SELECT madlib.linregr_train(‘enginelogbook’,’enginelogbook_linregr’, ’hoME’, ‘ARRAY[1,doME,goME]’);
Get the Trend using Liner Regression on the greenplum/HAWQ data set.
Greenplum is a trademark of EMC.

Conclusions17
There is still a lot of misconceptions about BigData and Cloud.
Using HAWQ and MADlib it is very easy to do in-data analysis. This traditionally was impossible without building a Data Warehouse.
Using Cloud enabled data analysis brings in additional benefits of distributed data, traditionally this was expensive and required huge pluming for data replication strategies.
Pivitol Stack is one of its kind that gives a one stop solution from Developers, Data Scientist to Business.