reconfigurable supercomputing: hurdles and chances reiner hartenstein tu kaiserslautern dresden,...
Post on 19-Dec-2015
218 views
TRANSCRIPT

Reconfigurable
Supercomputing: Hurdles
and Chances
Reiner Hartenstein
TU Kaiserslautern
Dresden, Gemany, June 28 - 30, 2006
International Supercomputer Conference
http://hartenstein.de

© 2006, [email protected] http://hartenstein.de2
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions

© 2006, [email protected] http://hartenstein.de3
TU KaiserslauternPreface
The talk illustrates why behind the success of FPGAs there is a hidden paradigm shift
My talk does not really cover the performance of bulk storage, discs, etc.
My talk highlights the supercomputing paradigm trapand the fully ignored early solution

© 2006, [email protected] http://hartenstein.de4
TU Kaiserslautern
The Pervasiveness of Reconfigurable Computing (RC)
162,000
127,000
158,000113,000
171,000194,000
# of hits by Google
1,620,000
915,000
398,000
272,000
647,000
1,490,000
# of hits by Google
“FPGA and ….” FPGAs are used everywhere
>10 m
io
Nov. 2005
~150 conferences~150 conferences

© 2006, [email protected] http://hartenstein.de5
TU Kaiserslautern
An Example: FPGAs in Oil and Gas ....
Saves more than $10,000 in electricity bills per year (7¢ / kWh) - .... per 64-processor 19" rack
„Application migration [from supercomputer] has resulted in a 17-to-1 increase in performance"
[Herb Riley, R. Associates]
… 25% of Amsterdam‘s electric energy consumption goes into server farms ?
… a quarter square-kilometer of office floor space within New York City is occupied by server farms ?
did you know …

© 2006, [email protected] http://hartenstein.de6
TU Kaiserslautern
Oil and Gas as a strategic issue
It should be investigated, how far the migrational achievements obtained for computationally intensive applications, can also be utilized for servers
You know the amount of Google’ s electricity bill?

© 2006, [email protected] http://hartenstein.de7
TU Kaiserslautern
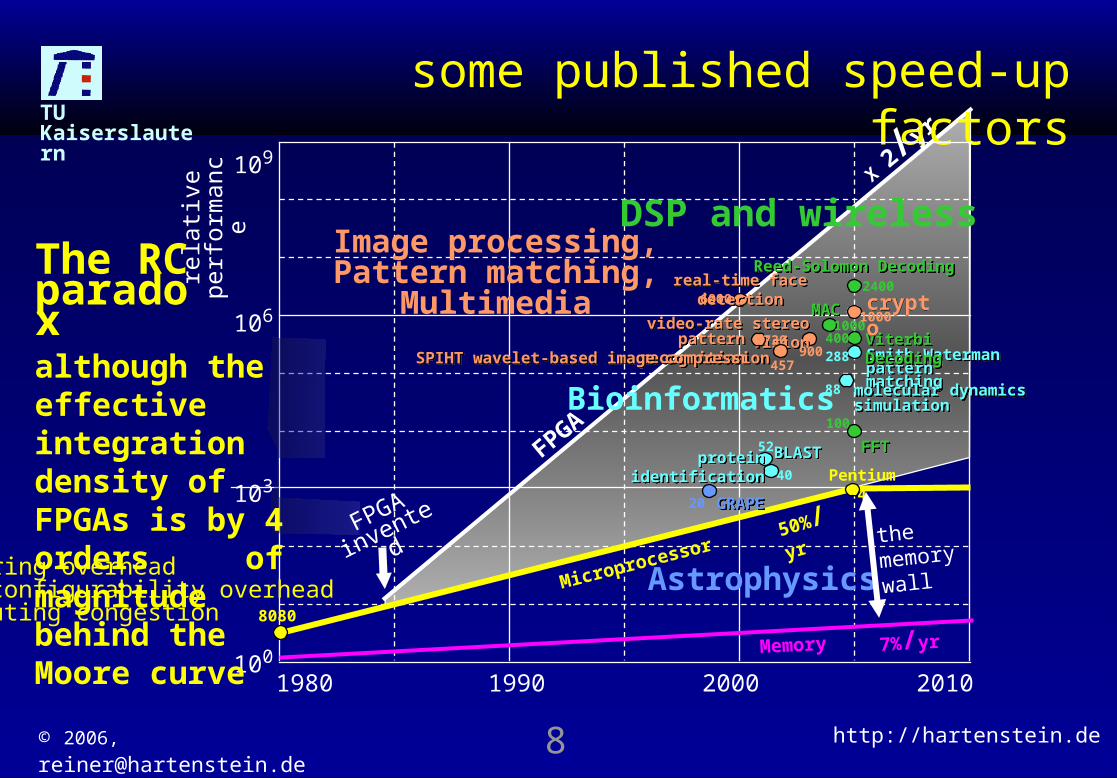
15 GigaFLOPs on a single FPGA chip
15 GigaFLOPs on single chip for matrix computations
A surprize: much less memory needed than expected
Last night I met Stamatis Vassiliadis (TU Delft)
© 2006, [email protected] http://hartenstein.de8
TU Kaiserslautern
X 2/yr
FPGA
some published speed-up factors
1980 1990 2000 2010100
103
106
109
8080
Pentium 4
7%/yr
50%/yr
real-time face detectionreal-time face detection6000
video-rate stereo vision
video-rate stereo vision
900pattern
recognitionpattern
recognition730
SPIHT wavelet-based image compressionSPIHT wavelet-based image compression 457Smith-Waterman pattern matching
Smith-Waterman pattern matching
288
BLASTBLAST52protein identificationprotein identification
40
molecular dynamics simulationmolecular dynamics simulation
88
Reed-Solomon Decoding
Reed-Solomon Decoding2400
Viterbi DecodingViterbi Decoding
400
FFTFFT
100
1000MA
CMA
C
DSP and wirelessImage processing,Pattern matching,
Multimedia
Bioinformatics
GRAPEGRAPE20
AstrophysicsMicroprocessor
rela
tive
perf
orm
anc
e
Memory
cryptocrypto
1000
although the effective integration density of FPGAs is by 4 orders of magnitude behind the Moore curvewiring overheadreconfigurability overheadrouting congestion
The RC paradox
the memor
y wall
FPGA
invented

© 2006, [email protected] http://hartenstein.de9
TU KaiserslauternEducational Deficits
Transdisciplinary fragmentation: each application domain uses its own trick boxes
Too many sophisticated very clever architecturesWe need a fundamental model with a methodology which all application domains have in common
Educational deficits have stalled Reconfigurable Computing (RC) as well as classical supercomputing
Transdisciplinary education & basic research needed

© 2006, [email protected] http://hartenstein.de10
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions

© 2006, [email protected] http://hartenstein.de11
TU KaiserslauternThe basic model paradigm
trap
High performance computing stalled for decades by the von Neuman paradigm trap
stolen from Bob Colwell
CPU
For decades the right roadmap was hidden by another paradigm trap
most systems are extremely
unbalanced

© 2006, [email protected] http://hartenstein.de12
TU Kaiserslautern
Computer Science not prepared
Transdisciplinary Education?
for decades: the Hardware / Software chasm
Lacking intradisciplinary cohesion between the mind sets of:
•Hardware
People
•Theoreticians (Math
background)
•Software People (Application Development)
turns into the Configware / Software chasm
•Embedded Syst. Designers•Computer Architects
© 2006, [email protected] http://hartenstein.de13
TU Kaiserslautern
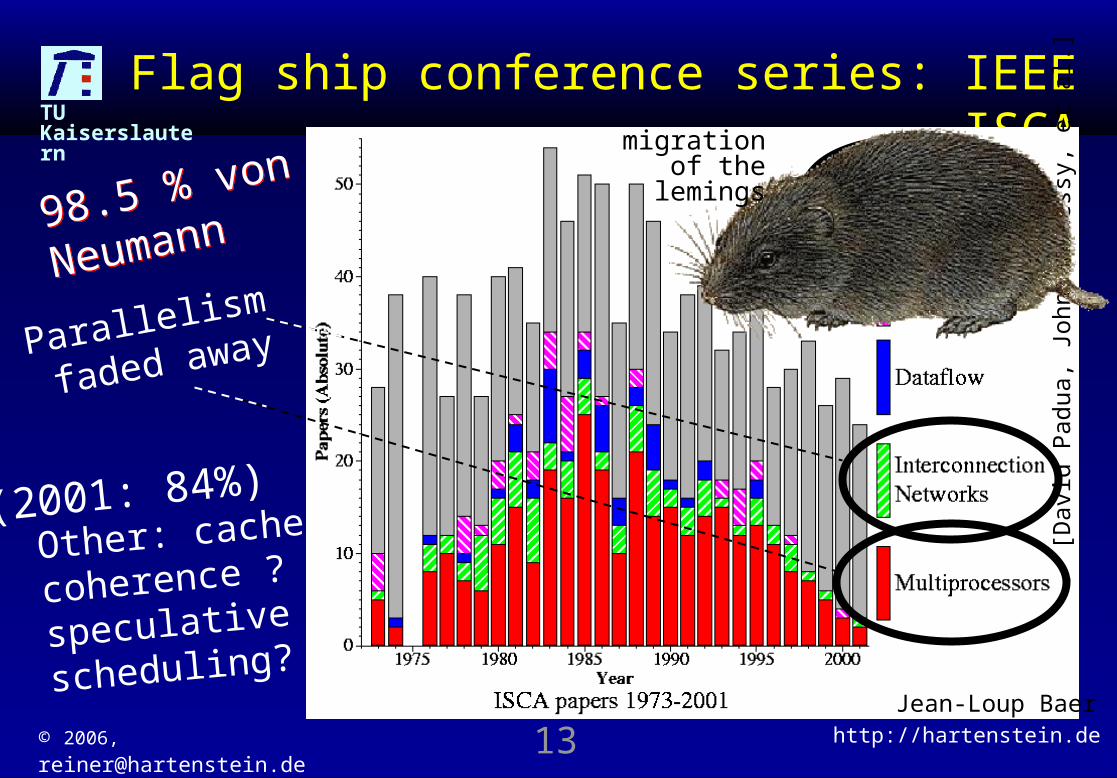
Flag ship conference series: IEEE ISCA
Parallelism
faded away
98.5 % von
Neumann98.5 % von
Neumann
[Dav
id P
adua
, Joh
n He
nnes
sy, e
t al.]
Other: cache
coherence ?
speculative
scheduling?
(2001: 84%)
Jean-Loup Baer
migration of the
lemings

© 2006, [email protected] http://hartenstein.de14
TU Kaiserslautern
The Dead Supercomputer Society
•ACRI •Alliant •American Supercomputer •Ametek •Applied Dynamics •Astronautics •BBN •CDC•Convex•Cray Computer •Cray Research •Culler-Harris •Culler Scientific •Cydrome •Dana/Ardent/ Stellar/Stardent
•DAPP •Denelcor •Elexsi •ETA Systems •Evans and Sutherland•Computer•Floating Point Systems •Galaxy YH-1 •Goodyear Aerospace MPP •Gould NPL •Guiltech •ICL •Intel Scientific Computers •International Parallel Machines •Kendall Square Research •Key Computer Laboratories•MasPar
Research 1985 – 1995 [Gordon Bell, keynote ISCA 2000]
•Meiko •Multiflow •Myrias •Numerix •Prisma •Tera •Thinking Machines •Saxpy •Scientific Computer•Systems (SCS) •Soviet Supercomputers •Supertek •Supercomputer Systems •Suprenum •Vitesse Electronics
49: died just in 1 decade

© 2006, [email protected] http://hartenstein.de15
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions
© 2006, [email protected] http://hartenstein.de16
TU Kaiserslautern
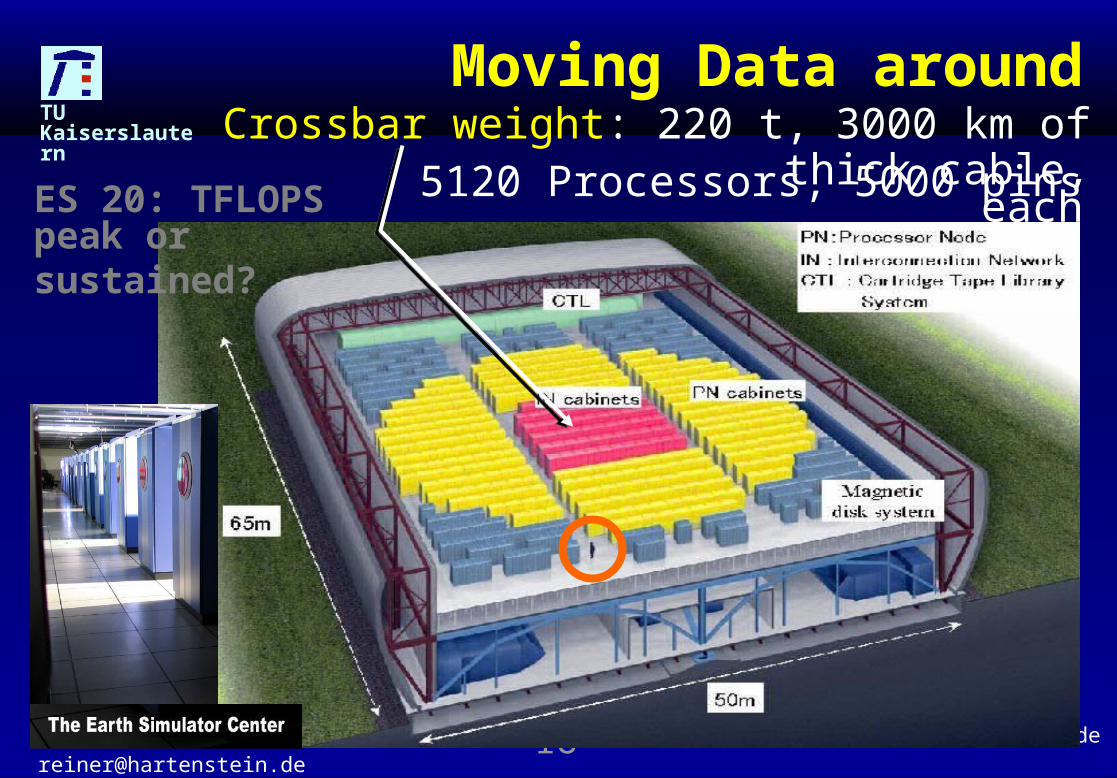
Moving Data around
5120 Processors, 5000 pins eachCrossbar weight: 220 t, 3000 km of thick cable,
ES 20: TFLOPSpeak or sustained?

© 2006, [email protected] http://hartenstein.de17
TU KaiserslauternThe Memory Wall (1)
Moving data to the processor:

© 2006, [email protected] http://hartenstein.de18
TU KaiserslauternData meeting the Processing Unit
(PU)
by Software
byConfigware
routing the data by memory-cycle-hungry instruction streams
placement of the execution locality
We have 2 choices
optimize a pipe network: place PU in data stream
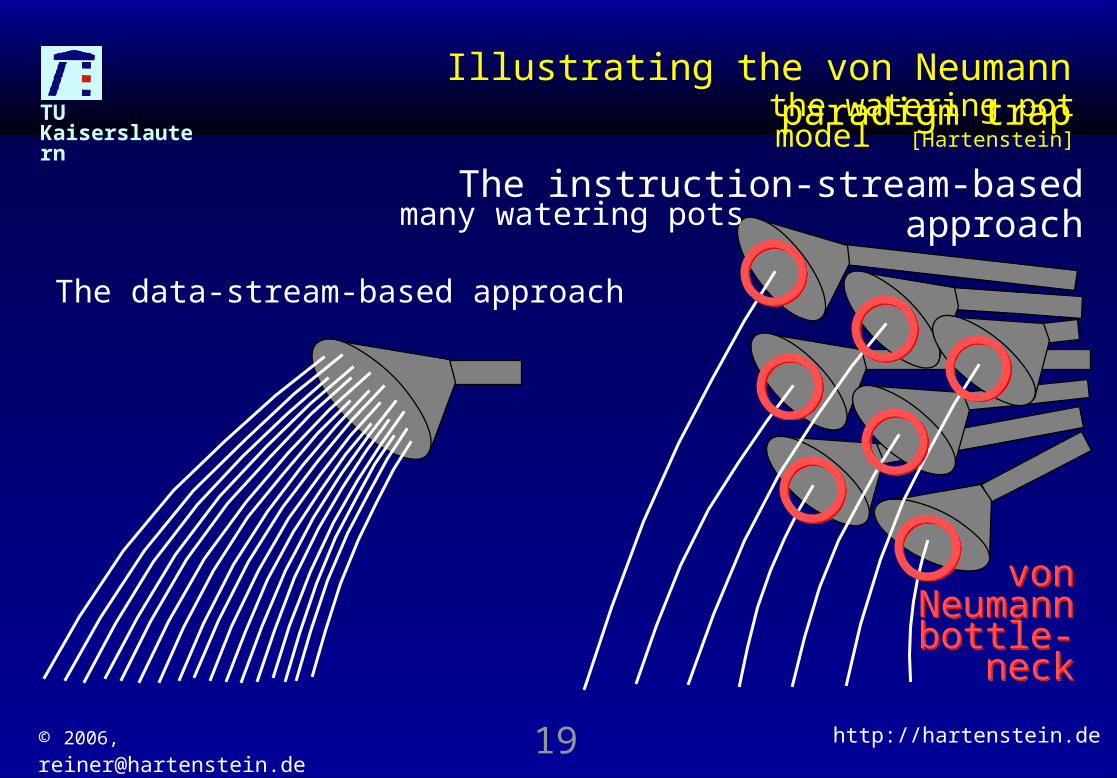
© 2006, [email protected] http://hartenstein.de19
TU Kaiserslautern
Illustrating the von Neumann paradigm trap
The data-stream-based approach
The instruction-stream-based approach
von Neuman
n bottle-
neck
von Neuman
n bottle-
neck
the watering pot model [Hartenstein]
many watering pots

© 2006, [email protected] http://hartenstein.de20
TU KaiserslauternThe Memory Wall (2)
Supercomputing urgently needs a fundamentally different approach
toward interconnect efficiency.
Key problem is the inefficiency and complexity of moving data, not processor performance.
Tear down this Wall !
Most important goal is the minimization of the number of main memory cycles.

© 2006, [email protected] http://hartenstein.de21
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions
© 2006, [email protected] http://hartenstein.de22
TU Kaiserslautern
xxx
xxx
xxx
|
||
x x
x
x
x
x
x x
x
- -
-
input data stream
xx
x
x
x
x
xx
x
--
-
-
-
-
-
-
-
-
-
-
xxx
xxx
xxx
|
|
|
|
|
|
|
|
|
|
|
|
|
|output data streams
time
port #
time
time
port #time
port #
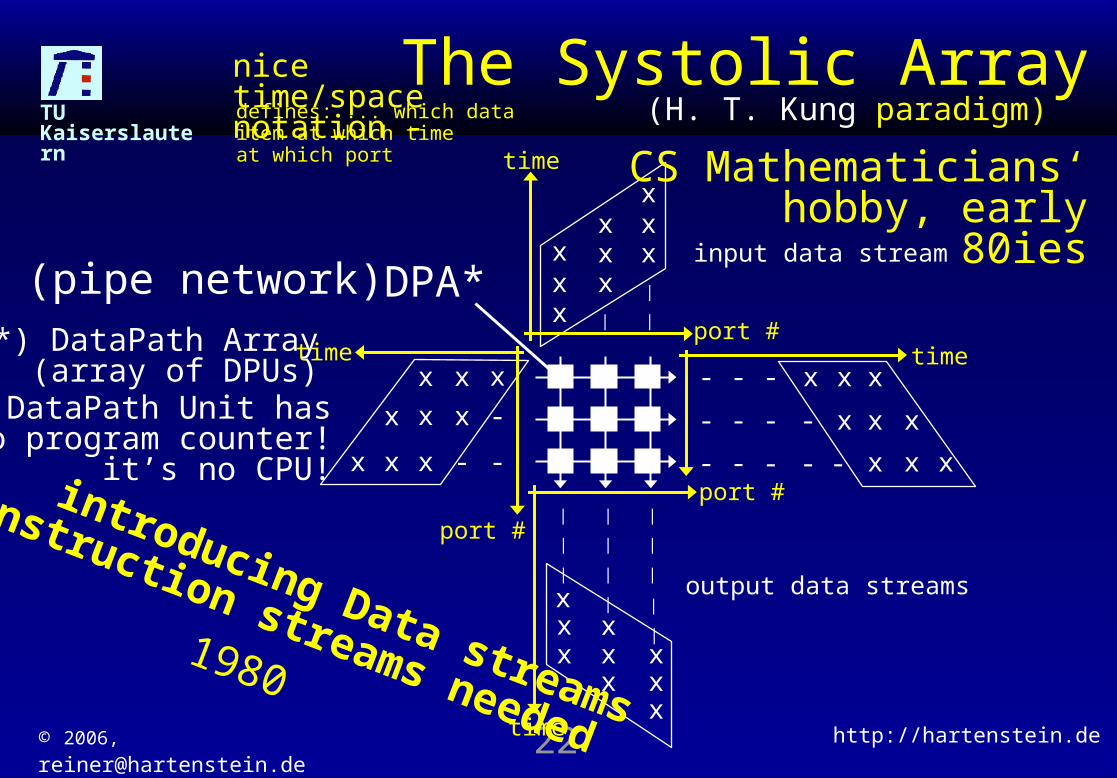
defines: ... which data item at which time at which port
(H. T. Kung paradigm)
CS Mathematicians‘ hobby, early 80ies
DPA*(pipe network)*) DataPath Array
(array of DPUs)
The Systolic Array
1980
introducing Data streams
no instruction streams needed
DataPath Unit hasno program counter!
it’s no CPU!
nice time/space notation -

© 2006, [email protected] http://hartenstein.de23
TU KaiserslauternTerminology
termprogra
m counter
execution triggered
byparadigm
CPUyes instructio
n fetchinstruction-stream-based
DPU** no data arrival*
data-stream-based
DPU
programcounter
DPUCPUCPU
*) “transport-triggered”**) does not have a program counter

© 2006, [email protected] http://hartenstein.de24
TU Kaiserslautern
The new paradigm: how the data are traveling
An old hat: transport-triggered
pipeline, or chaining
super systolic array
better not by instruction executionbetter not by instruction execution
DPU DPU DPU
vN Move Processor
instruction-driven
+ instruction-driven
[Jack Lipovski, EUROMiCRO, Nice, 1975]
P&R: move locality of operation, not data !
© 2006, [email protected] http://hartenstein.de25
TU Kaiserslautern
No Memory Wall
DPA
xxx
xxx
xxx
|
||
x x
x
x
x
x
x x
x
- -
-
input data streams
xx
x
x
x
x
xx
x
--
-
-
-
-
-
-
-
-
-
-
xxx
xxx
xxx
|
|
|
|
|
|
|
|
|
|
|
|
|
|output data streams
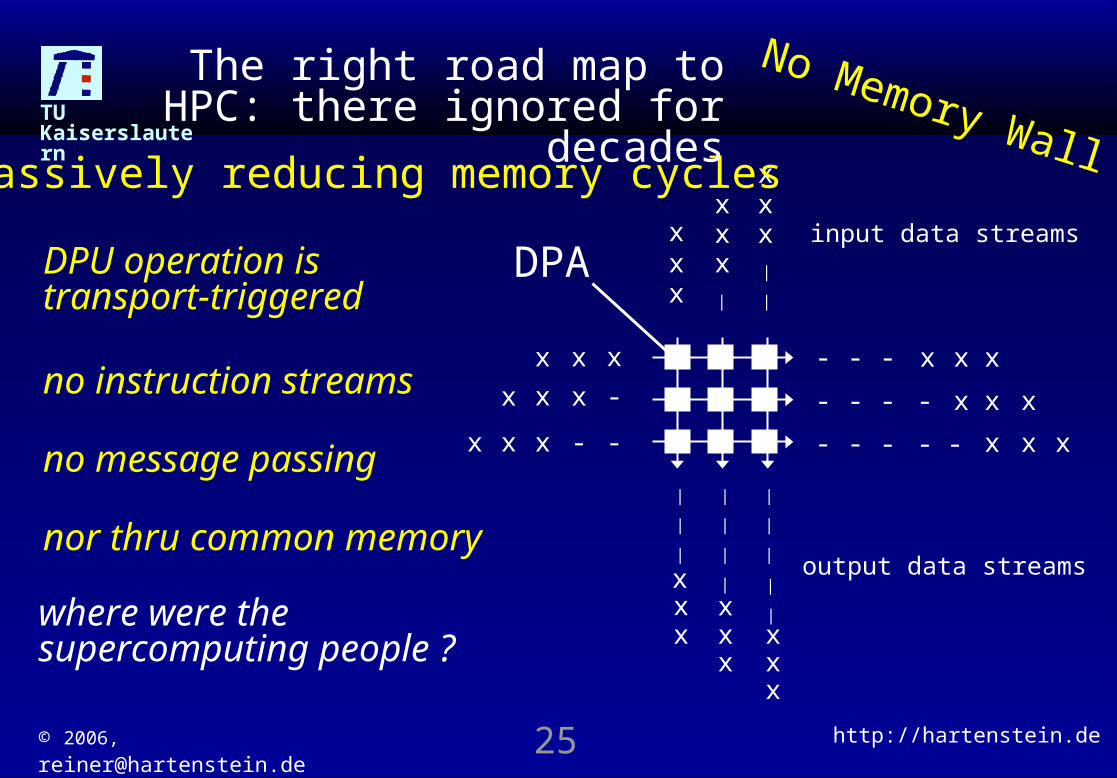
DPU operation is transport-triggered
no instruction streamsno message passing
nor thru common memory
where were the supercomputing people ?
massively reducing memory cycles
The right road map to HPC: there ignored for
decades

© 2006, [email protected] http://hartenstein.de26
TU Kaiserslautern
Mathematicians X-ing
Systolic Synthesis
Mathematicians like the beauty and elegance of Systolic Arrays. Due to a lacking intra-disciplinary view, their efforts yielded poor synthesis algorithms.
Reiner Hartenstein

© 2006, [email protected] http://hartenstein.de27
TU Kaiserslautern
of course, algebraic !Synthesis Method?
Algebraic means linear projection, restricted to uniform arrays, only with linear pipes
useful only for applications with strictly regular data dependencies:
Mathematicians caught by their own paradigm trap for more than a decade
Rainer Kress discarded their algebraic synthesis methods and replaced it by simulated annealing.
Generalization* by a transdisciplinary hardware guy:
rDPA:
1995*) super-systolic
the specialist trap
© 2006, [email protected] http://hartenstein.de28
TU KaiserslauternGenerating the Data Streams
DPA
xxx
xxx
xxx
|
||
x x
x
x
x
x
x x
x
- -
-
input data streams
xx
x
x
x
x
xx
x
--
-
-
-
-
-
-
-
-
-
-
xxx
xxx
xxx
|
|
|
|
|
|
|
|
|
|
|
|
|
|output data streams
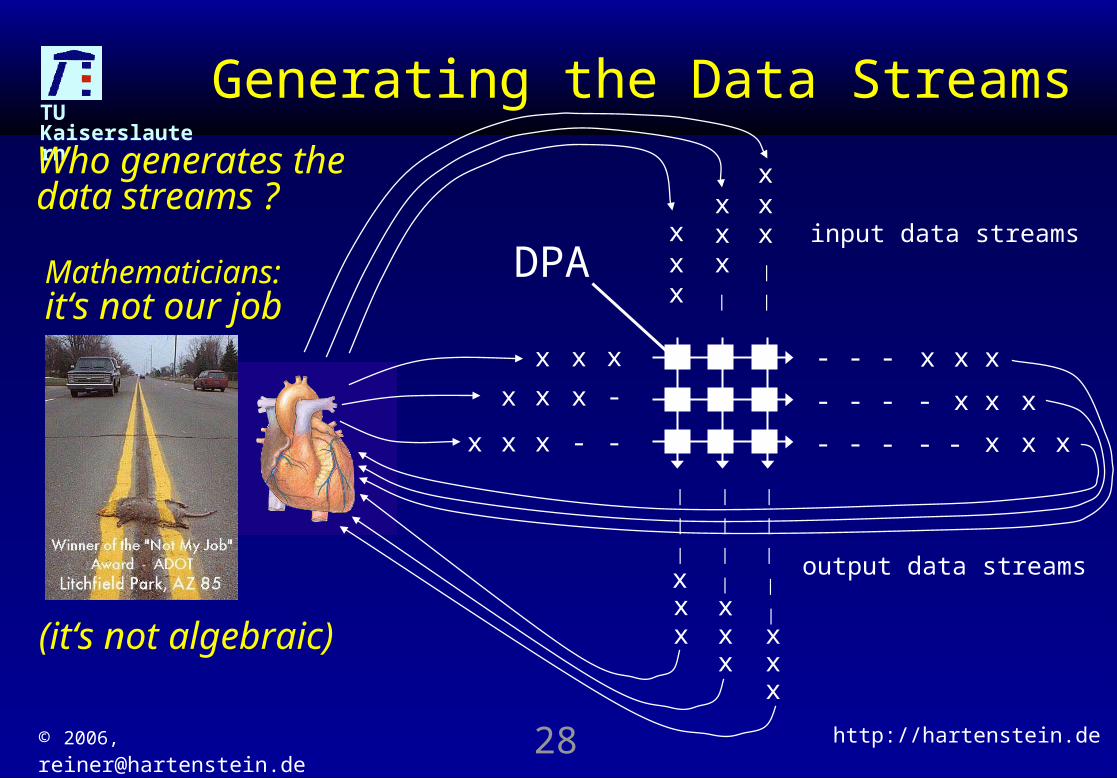
Mathematicians: it‘s not our job
Who generates the data streams ?
(it‘s not algebraic)
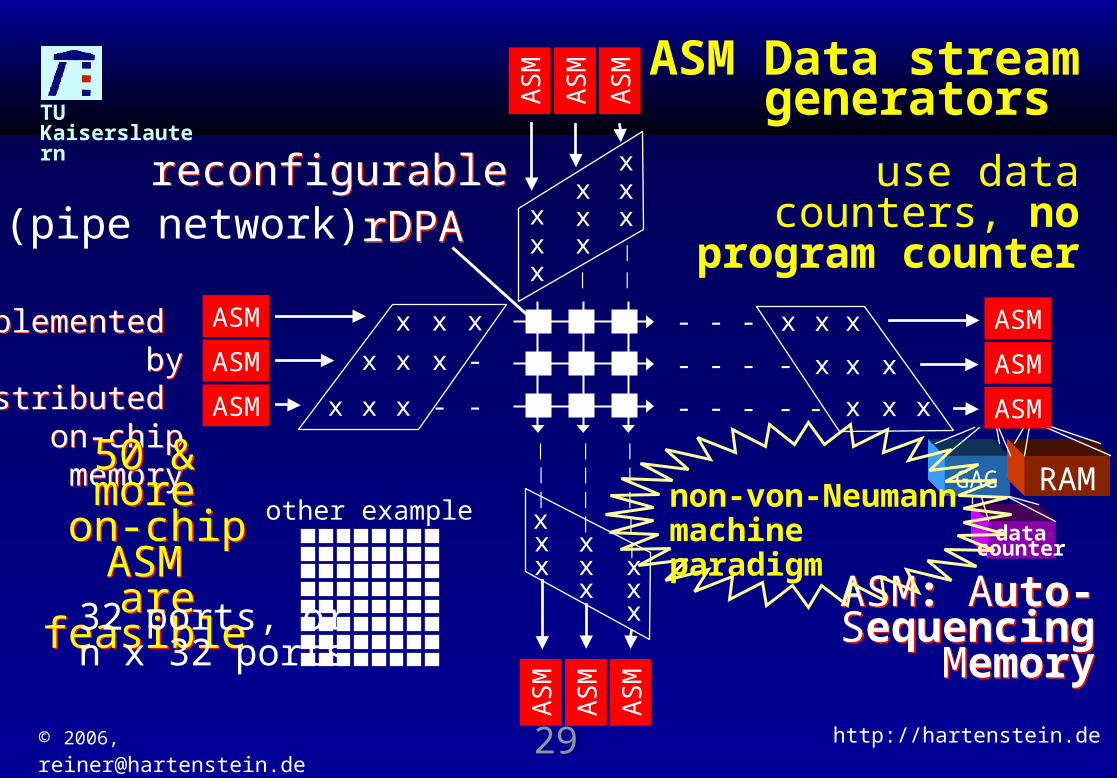
© 2006, [email protected] http://hartenstein.de29
TU Kaiserslautern
datacounter
GAG RAM
ASM: Auto-Sequencing
Memory
ASM: Auto-Sequencing
Memory
use data counters, no program
counter
rDPArDPA
x x
x
x
x
x
x x
x
- -
-
xx
x
x
x
x
xx
x
--
-
-
-
-
-
-
-
-
-
-
ASM Data stream generators
(pipe network)
xxx
xxx
xxx
|
||
xxx
xxx
xxx
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ASM
ASM
ASM
ASM
ASM
ASM
AS
M
AS
M
AS
M
AS
M
AS
M
AS
M
implemented by distributed on-
chip memory
implemented by distributed on-
chip memory
50 & more on-chip ASM are feasible
50 & more on-chip ASM are feasible
reconfigurablereconfigurable
32 ports, orn x 32 ports
other example non-von-Neumannmachine paradigm
© 2006, [email protected] http://hartenstein.de30
TU Kaiserslautern
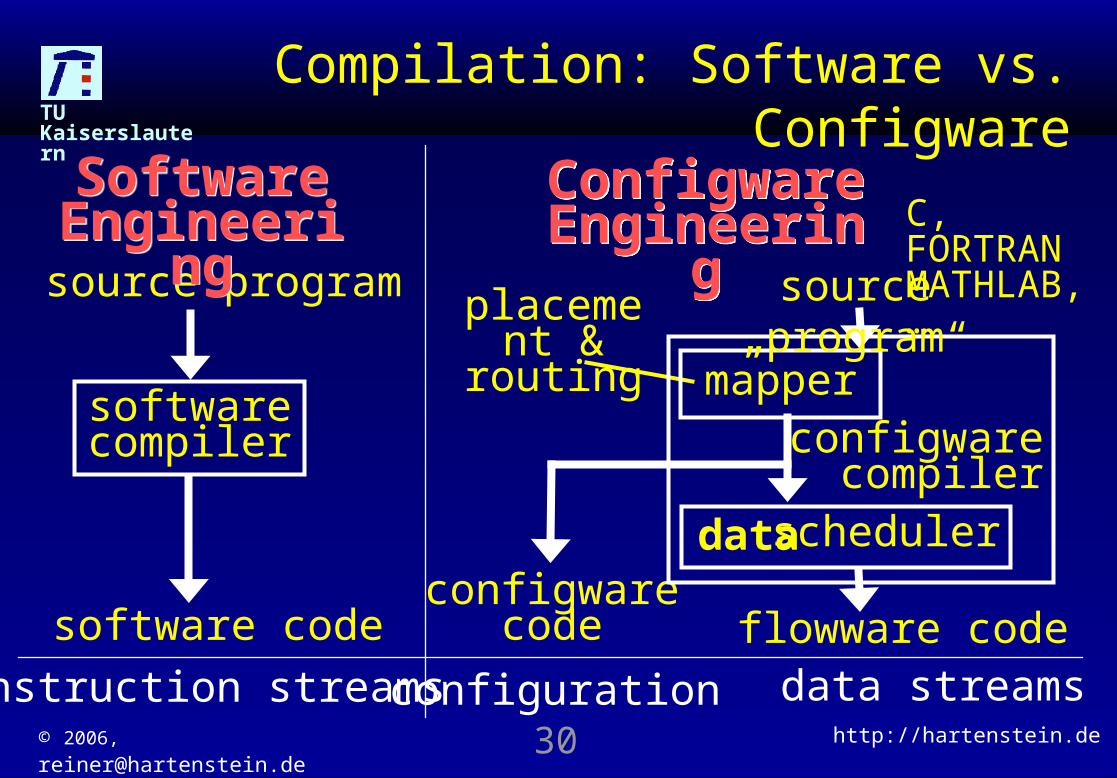
Compilation: Software vs. Configware
source program
softwarecompiler
software code
Software Engineeri
ng
Software Engineeri
ng
Configware
Engineering
Configware
Engineeringplaceme
nt & routing
scheduler
flowware code
data
C, FORTRANMATHLAB, …
instruction streams data streamsconfiguration
configware code
mapperconfigware
compiler
source „program“

© 2006, [email protected] http://hartenstein.de31
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions
© 2006, [email protected] http://hartenstein.de32
TU Kaiserslautern
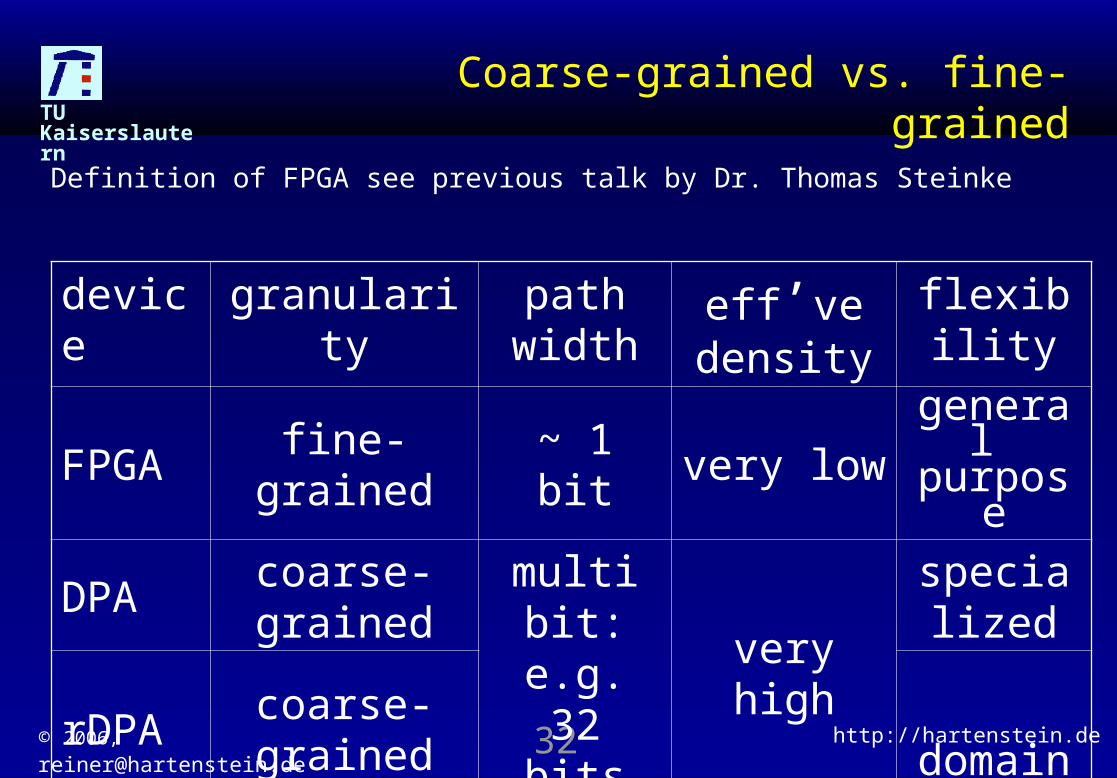
Coarse-grained vs. fine-grained
Definition of FPGA see previous talk by Dr. Thomas Steinke
device granularity path width eff’ve density
flexibility
FPGA fine-grained ~ 1 bit very low general purpose
DPA coarse-grained multi bit: e.g. 32 bits very high
specializedrDPA coarse-grained
domain-specificplatform
FPGAfine-grained &
embedded hdw. mixed high
© 2006, [email protected] http://hartenstein.de33
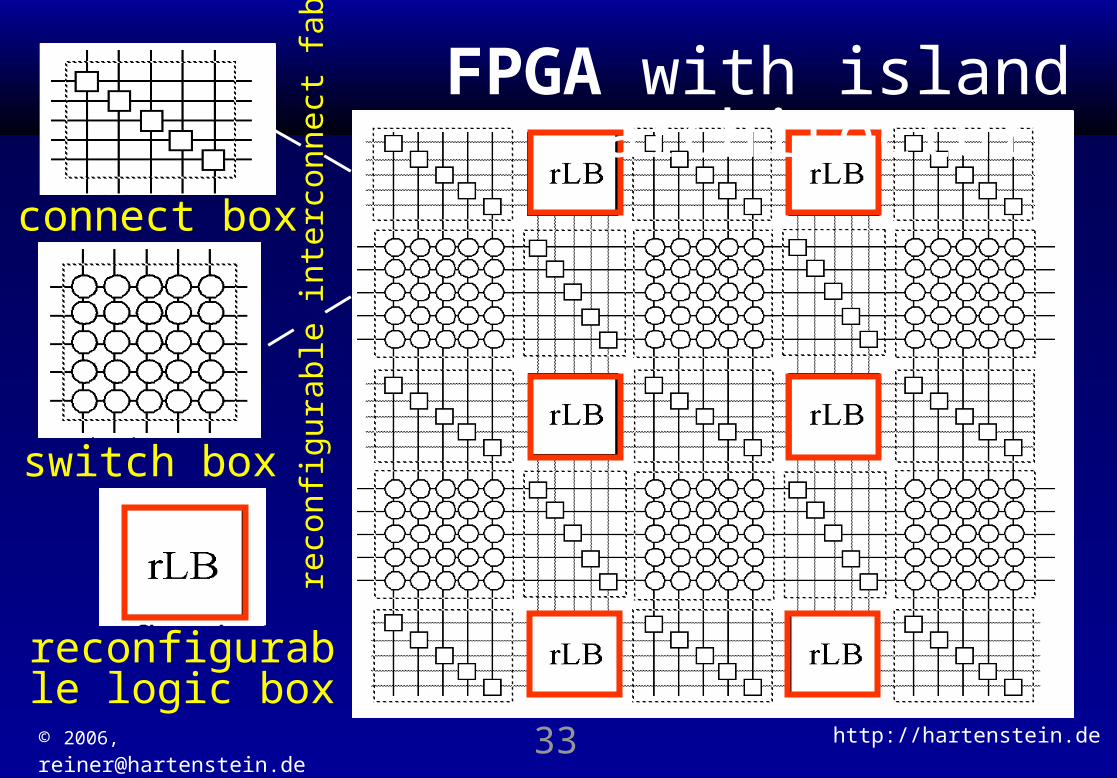
TU KaiserslauternFPGA with island architecture
reconfigurable logic box
switch box
connect box
reco
nfig
urab
le in
terc
onne
ct fa
brics
© 2006, [email protected] http://hartenstein.de34
TU Kaiserslautern
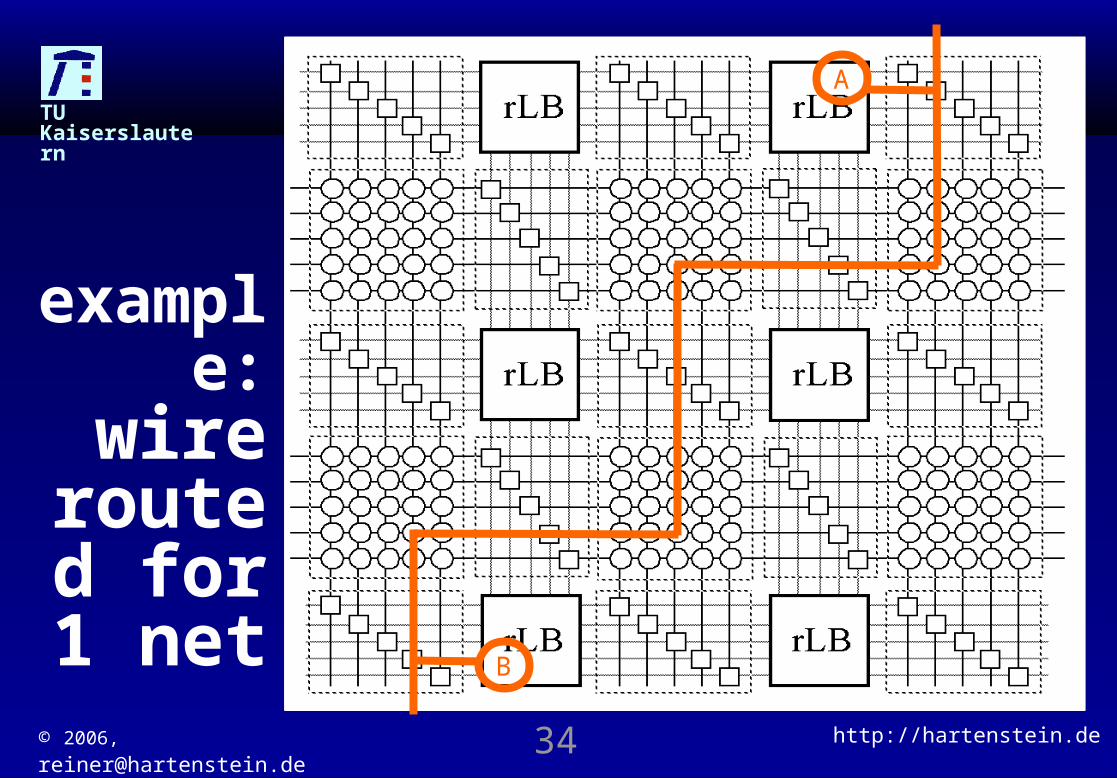
A
B
example: wire
routed for 1 net
© 2006, [email protected] http://hartenstein.de35
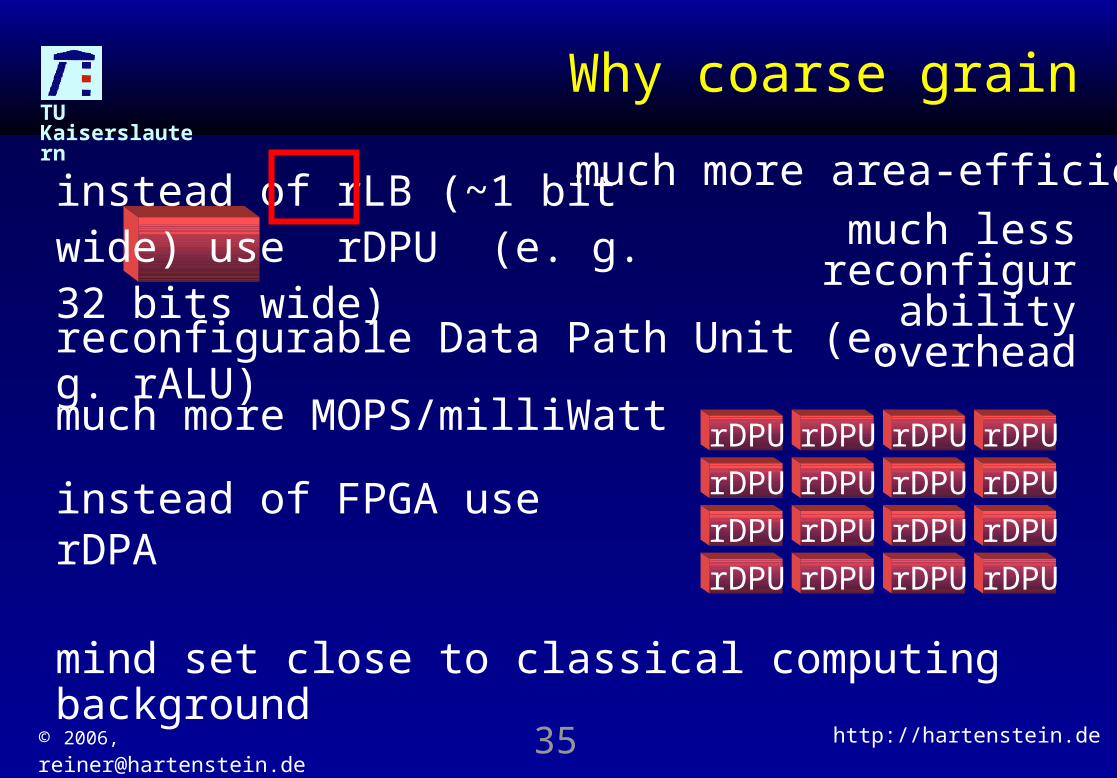
TU KaiserslauternWhy coarse grain
much more MOPS/milliWatt
reconfigurable Data Path Unit (e. g. rALU)
mind set close to classical computing background
instead of rLB (~1 bit wide) use rDPU (e. g. 32 bits wide)
instead of FPGA use rDPA
rDPU rDPU rDPU rDPUrDPU rDPU rDPU rDPUrDPU rDPU rDPU rDPUrDPU rDPU rDPU rDPU
much more area-efficientmuch less
reconfigurability overhead
© 2006, [email protected] http://hartenstein.de36
TU Kaiserslautern
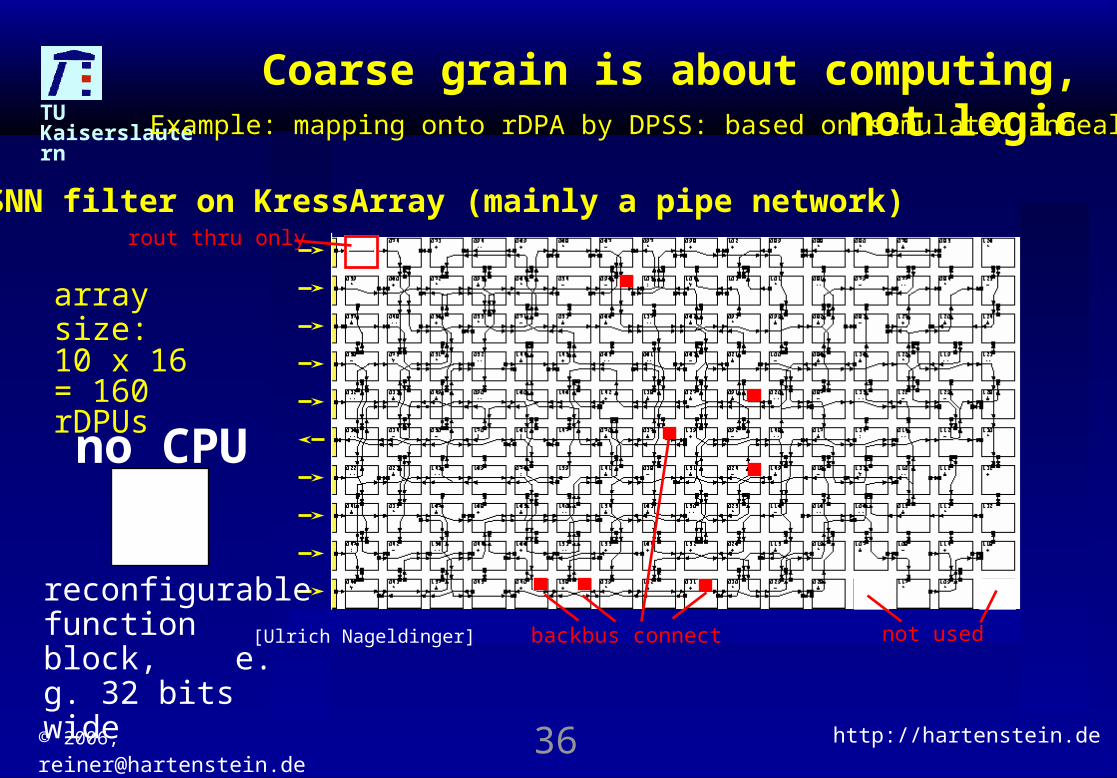
rDPU not used used for routing only operator and routing port location markerLegend: backbus connect
array size: 10 x 16 = 160 rDPUs
Coarse grain is about computing, not logic
rout thru only
not usedbackbus connect
SNN filter on KressArray (mainly a pipe network)
[Ulrich Nageldinger]
Example: mapping onto rDPA by DPSS: based on simulated annealing
reconfigurable function block, e. g. 32 bits wide
no CPU
© 2006, [email protected] http://hartenstein.de37
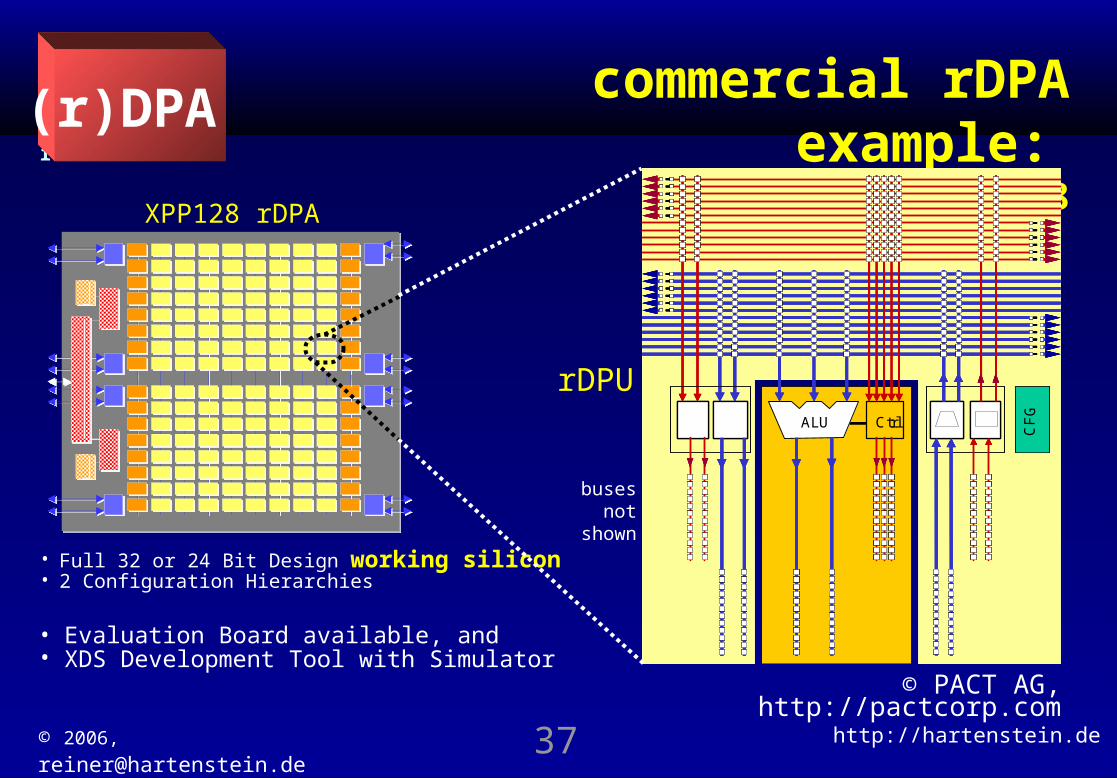
TU Kaiserslauterncommercial rDPA
example:
PACT XPP - XPU128XPP128 rDPA
• Evaluation Board available, and • XDS Development Tool with Simulator
buses not
shown
rDPU
CF
G
PAE
core
ALU CtrlALU
CF
GC
FG
PAE
core
CF
GC
FG
PAE
core
PAE
core
ALU CtrlALUALU CtrlALU
CF
GC
FG
CF
GC
FG
• Full 32 or 24 Bit Design working silicon • 2 Configuration Hierarchies
© PACT AG, http://pactcorp.com
(r)DPA
© 2006, [email protected] http://hartenstein.de38
TU Kaiserslautern
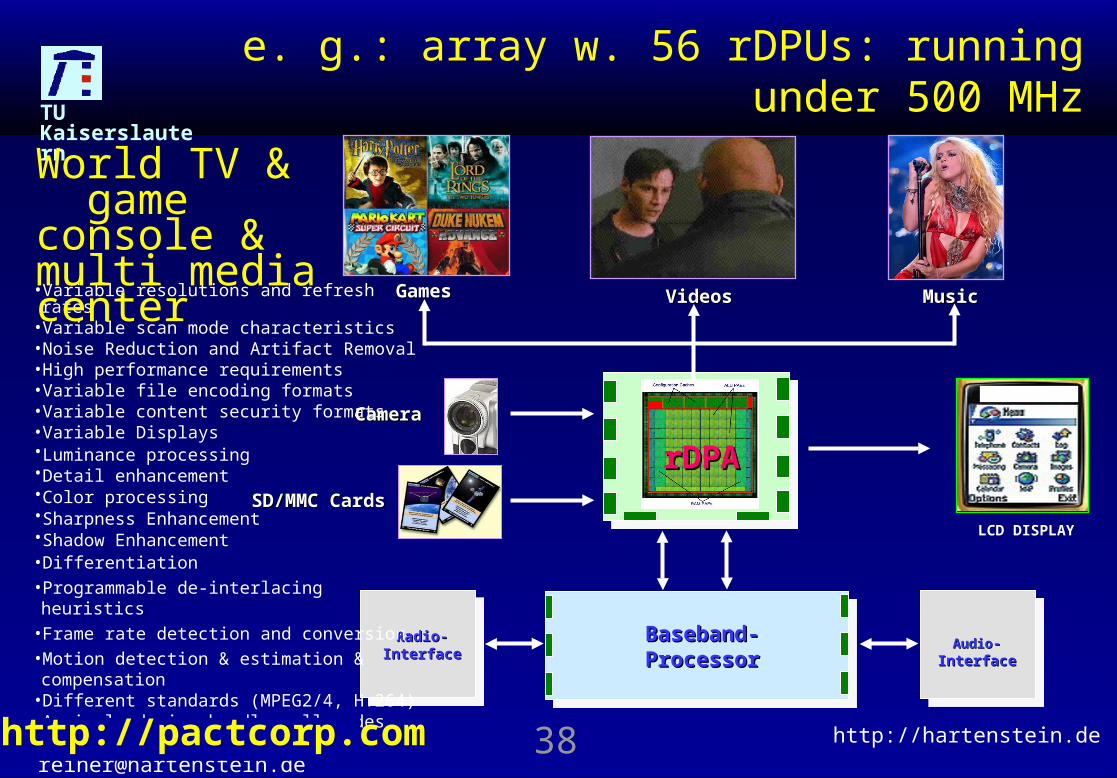
e. g.: array w. 56 rDPUs: running under 500 MHz
GamesGames MusicMusicVideosVideos
SMeXPPSMeXPP
CameraCamera
Baseband-Baseband-ProcessorProcessor
Radio-Radio-InterfaceInterface
AudioAudio--InterfaceInterface
SD/MMC CardsSD/MMC Cards
LCD DISPLAY
rDPArDPA
• Variable resolutions and refresh rates• Variable scan mode characteristics• Noise Reduction and Artifact Removal• High performance requirements• Variable file encoding formats• Variable content security formats• Variable Displays• Luminance processing• Detail enhancement• Color processing• Sharpness Enhancement• Shadow Enhancement• Differentiation • Programmable de-interlacing heuristics• Frame rate detection and conversion• Motion detection & estimation & compensation• Different standards (MPEG2/4, H.264)• A single device handles all modes
World TV & game console & multi media center
http://pactcorp.com
© 2006, [email protected] http://hartenstein.de39
TU Kaiserslautern
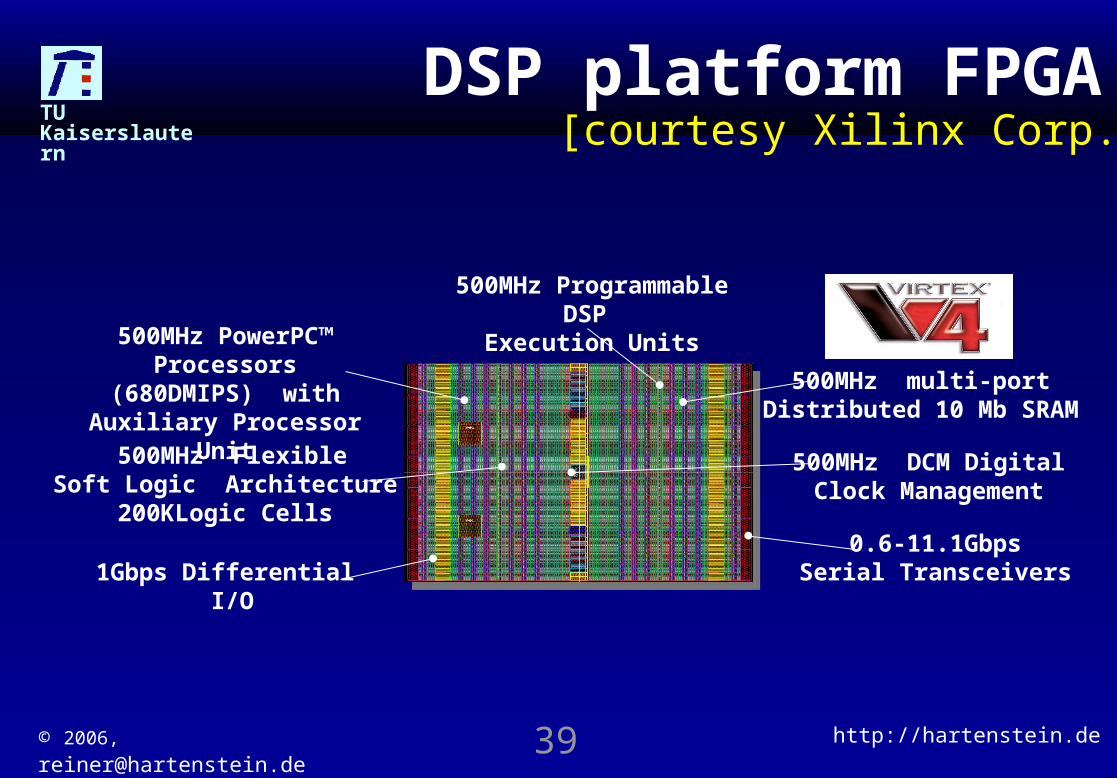
500MHz FlexibleSoft Logic Architecture
200KLogic Cells
500MHz Programmable DSP Execution Units
0.6-11.1GbpsSerial Transceivers
500MHz PowerPC™ Processors(680DMIPS) with
Auxiliary Processor Unit
1Gbps Differential I/O
500MHz multi-portDistributed 10 Mb SRAM
500MHz DCM DigitalClock Management
DSP platform FPGA[courtesy Xilinx Corp.]

© 2006, [email protected] http://hartenstein.de40
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions

© 2006, [email protected] http://hartenstein.de41
TU Kaiserslautern
Computing Curricula 2004fully ignores
Reconfigurable Computing
Joint Task Force for
FPGA & synonyma: 0 hits
not even here
(Google: 10 million hits)
Curricula ?
© 2006, [email protected] http://hartenstein.de42
TU Kaiserslautern
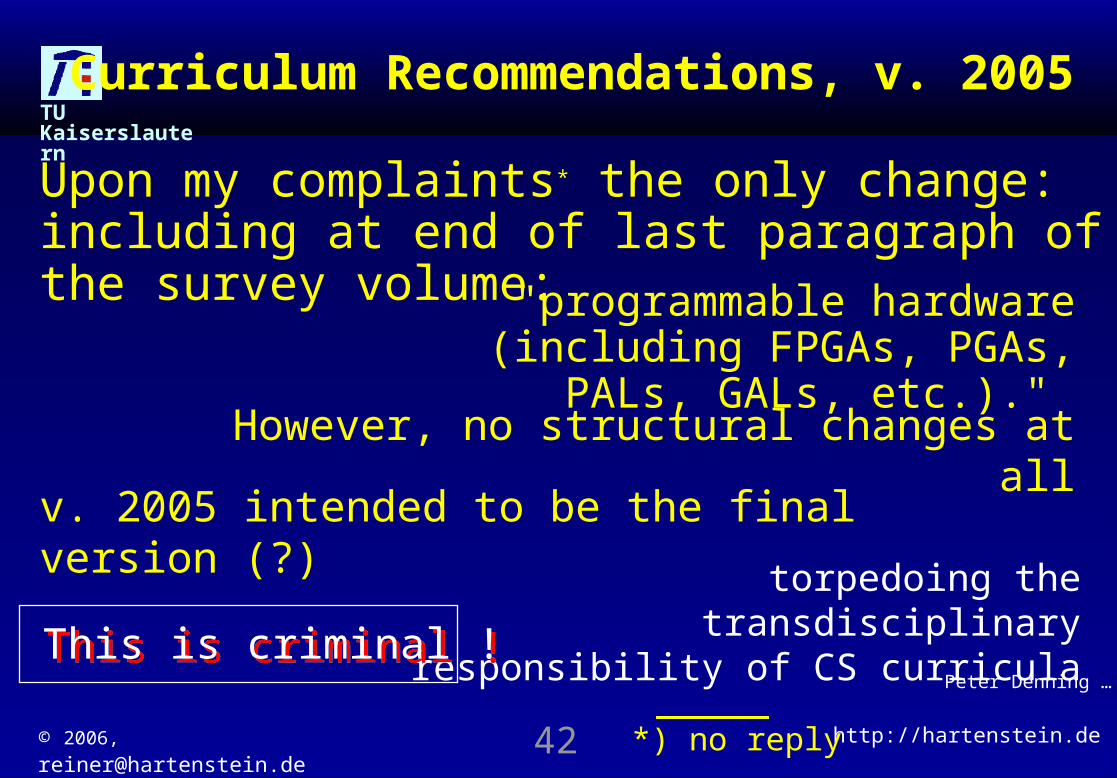
Upon my complaints* the only change: including at end of last paragraph of the survey volume:
Curriculum Recommendations, v. 2005
"programmable hardware (including FPGAs, PGAs, PALs,
GALs, etc.)." However, no structural changes at all
v. 2005 intended to be the final version (?) torpedoing the transdisciplinary
responsibility of CS curriculaThis is criminal !This is criminal !
Peter Denning …
*) no reply

© 2006, [email protected] http://hartenstein.de43
TU Kaiserslautern
Here is the common model
data-stream-based
instruction-stream-
based
software code
accelerator reconfigurable
accelerator hardwired
configware code
CPU
it’s not von Neumann
wagging the dog
the tail is
most accumulated
MIPS have been migrated here
most accumulated
MIPS have been migrated here mainly just
for running legacy code etc.
mainly just for running legacy code etc.
© 2006, [email protected] http://hartenstein.de44
TU Kaiserslautern
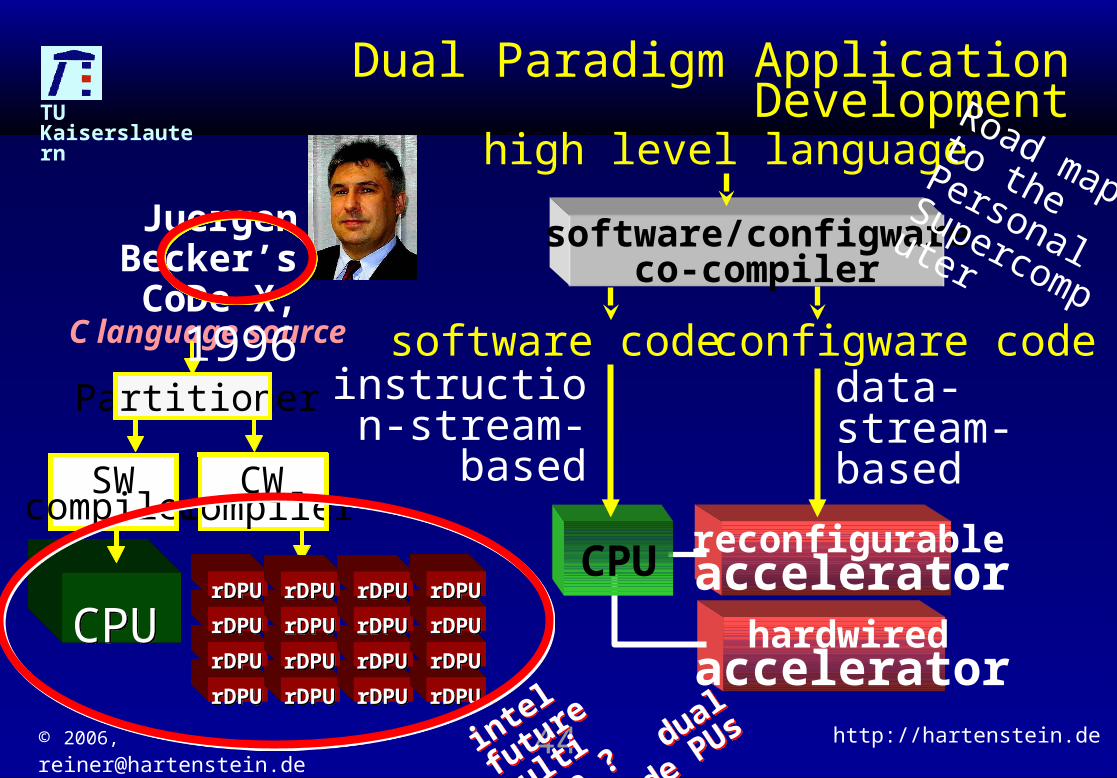
Dual Paradigm Application Development
instruction-stream-
based
software code
accelerator reconfigurable
accelerator hardwired
configware codedata-stream-based
CPU
software/configwareco-compiler
high level language
CPUCPU
SWcompiler
CWcompiler
C language source
Partitioner
rDPUrDPU rDPUrDPU rDPUrDPU rDPUrDPU
rDPUrDPU rDPUrDPU rDPUrDPU rDPUrDPU
rDPUrDPU rDPUrDPU rDPUrDPU rDPUrDPU
rDPUrDPU rDPUrDPU rDPUrDPU rDPUrDPU
Juergen Becker’s CoDe-X, 1996
Road map to the Personal
Supercomputer
intel future
multi core ?
intel future
multi core ?
dual mode
PUsdual m
ode
PUs
© 2006, [email protected] http://hartenstein.de45
TU Kaiserslautern
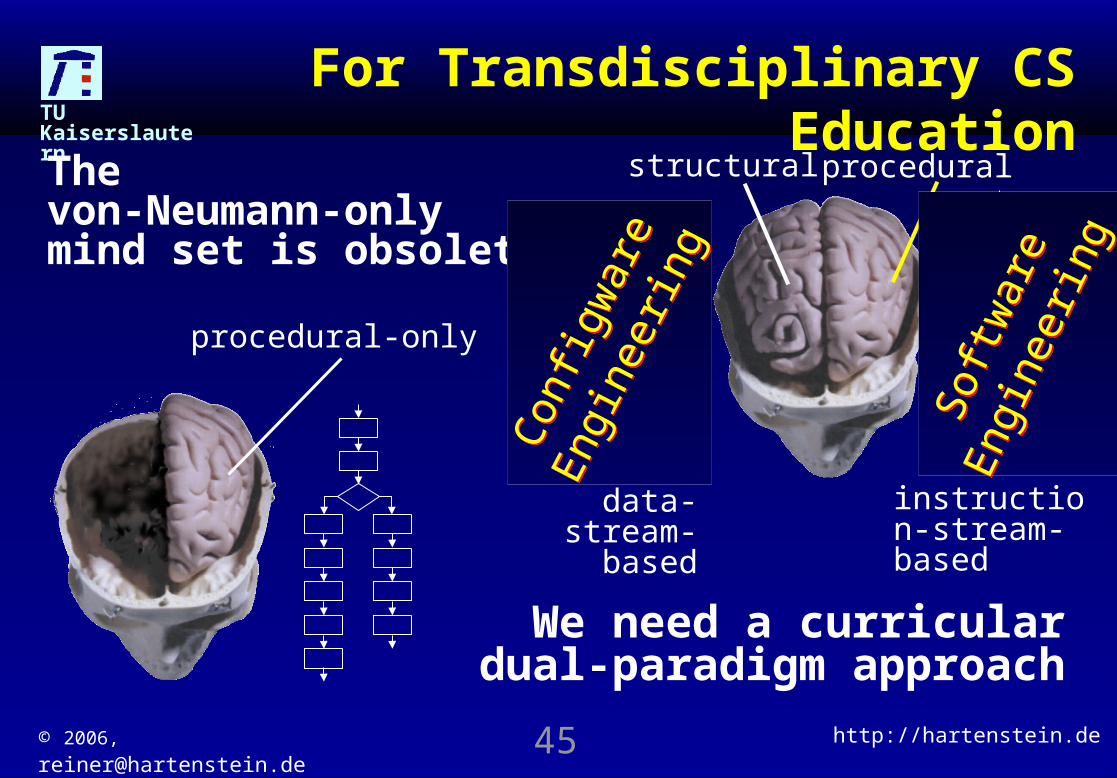
We need a curricular dual-paradigm approach
structural procedural
instruction-stream-based
data-stream-
based
For Transdisciplinary CS Education
procedural-only
The von-Neumann-only mind set is obsolete
Soft
war
e En
gine
erin
g
Soft
war
e En
gine
erin
g
Con
figw
are
Engi
neer
ing
Con
figw
are
Engi
neer
ing

© 2006, [email protected] http://hartenstein.de46
TU Kaiserslautern>> Outline <<
http://www.uni-kl.de
•Preface
•The von Neumann paradigm trap
•Supercomputing: the wrong Road Map
•The Solution ignored for decades
•Fine-grained vs. coarse-grained
•The wrong Road Map for CS Curricula
•Conclusions

© 2006, [email protected] http://hartenstein.de47
TU Kaiserslautern
Taxonomy of Algorithm Migration (1)
(Instruction-stream-based algorithm taxonomy: partially existing, not really systematic)Algorithms migrated to time-space domain (for RC): a taxonomy is not existing
Steadily coming and going data streams are best candidates
Computationally intensive applications are the best candidates for migration to FPGA
bulk data bases might be subject of FPGA usage to avoid memory cycles for address computation
A few algorithms (e. g. Turbocode or Viterbi) require a massive amount of interconnect

© 2006, [email protected] http://hartenstein.de48
TU Kaiserslautern
Taxonomy of Algorithm Migration (2)
Migration efficiency (reducing memory cycles):Servers: to be investigated - for sure is: •loop transformations: efficient, deterministic•caches: indeterministic and energy guzzlers•much less local memory needed•secondary data memory: distributed on-chip memory architectures highly promising
•address computations: efficient migration

© 2006, [email protected] http://hartenstein.de49
TU KaiserslauternConclusions
highly promising for servers
excellent results proven for computationally intensive applications
improvements likely for bulk data & storage applications
tool and language scenario needs an urgent transdisciplinary clean-up



© 2006, [email protected] http://hartenstein.de53
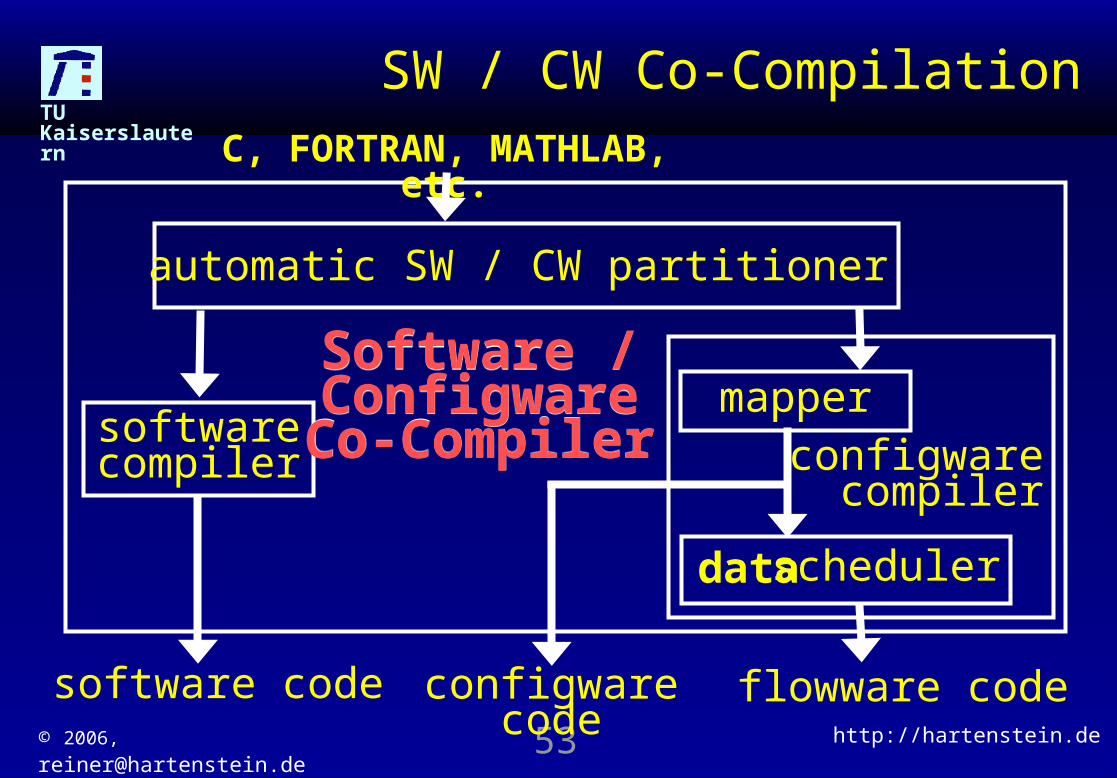
TU Kaiserslautern
SW / CW Co-Compilation
softwarecompiler
software code
Software / Configware Co-Compiler
Software / Configware Co-Compiler
configware code
mapperconfigware
compiler
scheduler
flowware code
data
C, FORTRAN, MATHLAB, etc.
automatic SW / CW partitioner

© 2006, [email protected] http://hartenstein.de54
TU Kaiserslautern
configware resources: variable
Why 2 different Codes needed ? Nick Tredennick’s Paradigm Shifts
2 programming sources needed
flowware algorithm: variable
Configware EngineeringConfigware Engineering
Software EngineeringSoftware Engineering
1 programming source needed
algorithm: variable
resources: fixedsoftware
CPU

© 2006, [email protected] http://hartenstein.de55
TU Kaiserslautern
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
rDPU rDPU rDPU rDPU
S
+
for demo: a tiny section of the pipe networkinter-rDPU-communication: no memory cycles needed
configware solution: computing in space
© 2006, [email protected] http://hartenstein.de56
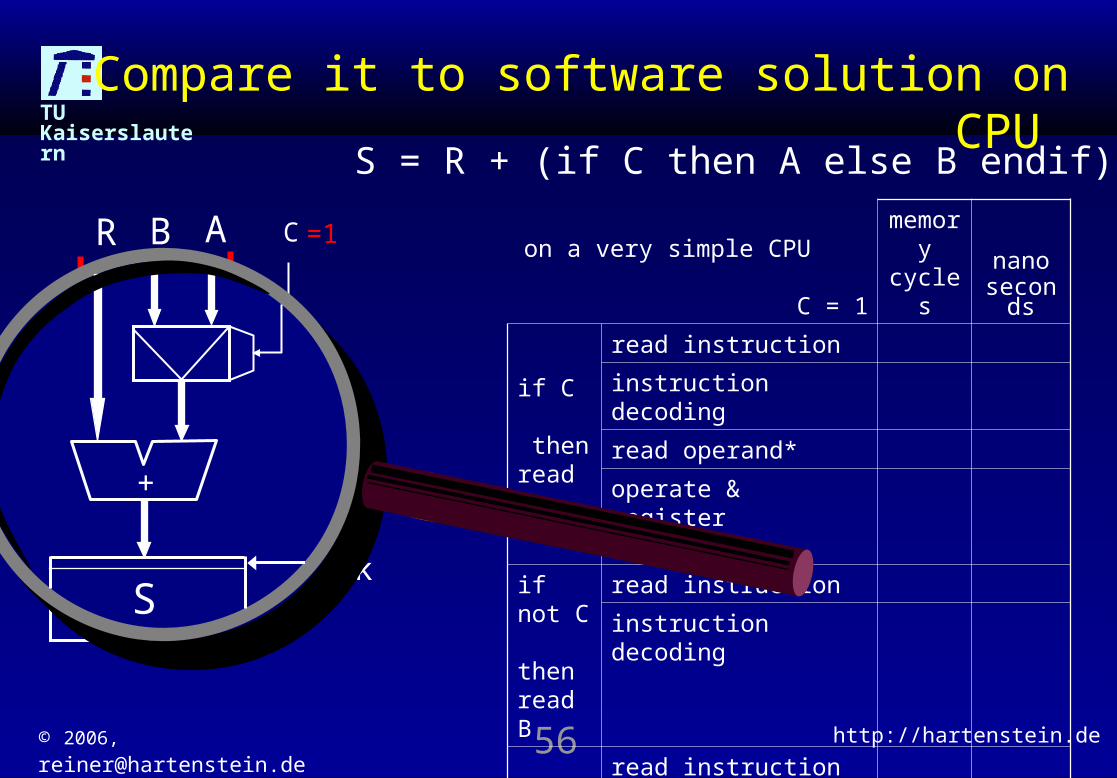
TU KaiserslauternCompare it to software solution on CPU
on a very simple CPU C = 1
memory cycles
nanoseconds
if C then read A
read instruction
instruction decoding
read operand*
operate & register transfers
if not C then read B
read instruction
instruction decoding
add & store
read instruction
instruction decoding
operate & register transfers
store result
total
S = R + (if C then A else B endif);
S
+
ABR C
Clock200
=1
S
+

© 2006, [email protected] http://hartenstein.de57
TU Kaiserslautern
hypothetical branching example to illustrate software-to-configware
migration
*) if no intermediate storage in register file
C = 1simple conservative CPU example
memory cycles
nanoseconds
if C then read A
read instruction 1 100instruction decoding
read operand* 1 100operate & reg. transfers
if not C then read B
read instruction 1 100instruction decoding
add & store
read instruction 1 100instruction decoding
operate & reg. transfers
store result 1 100
total 5 500
S = R + (if C then A else B endif);
S
+
ABR C
clock200 MHz(5 nanosec)
=1
sect
ion
of a
maj
or p
ipe
netw
ork
on rD
PU
no m
emor
y cy
cles
:
no m
emor
y cy
cles
:
spee
d-up
fac
tor
= 1
00
spee
d-up
fac
tor
= 1
00

© 2006, [email protected] http://hartenstein.de58
TU Kaiserslautern
The wrong mind set ....
S = R + (if C then A else B endif);
=1
+
ABR C
section of a very large pipe network:
decision
not knowing this solution:symptom of the hardware / software chasm
and the configware / software chasm
„but you can‘t implement decisions!“
© 2006, [email protected] http://hartenstein.de59
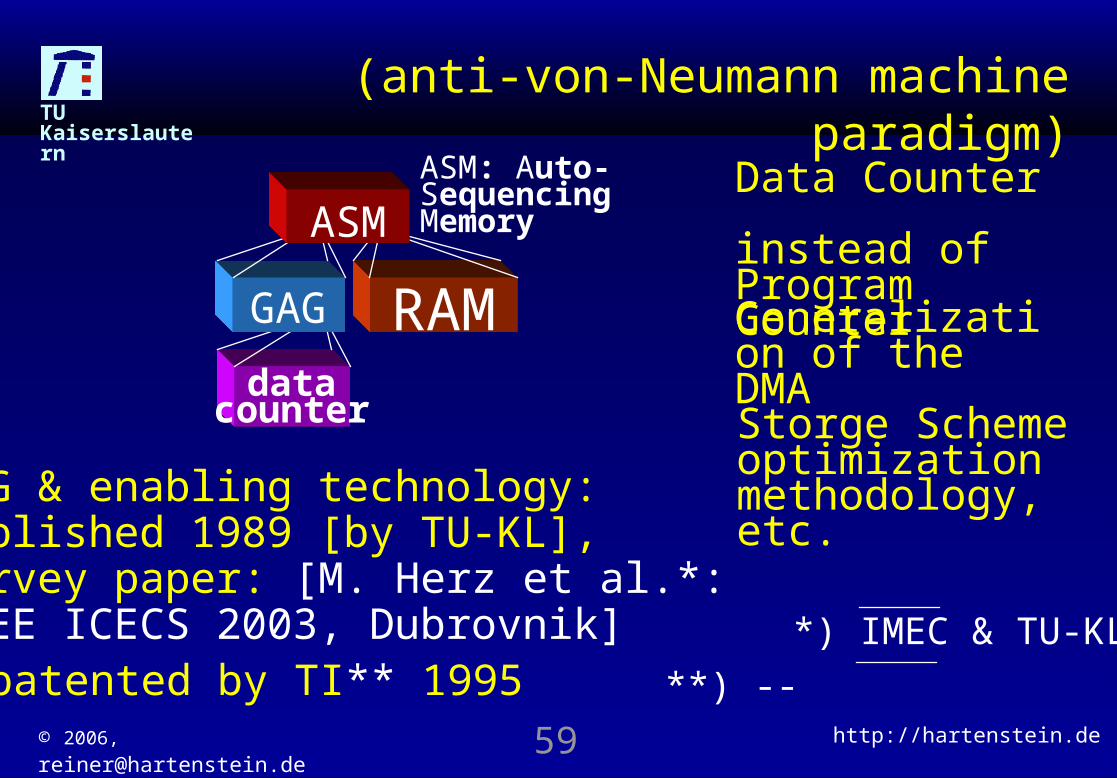
TU Kaiserslautern(anti-von-Neumann machine
paradigm)Data Counter instead of Program CounterGeneralization of the DMA
datacounter
GAG RAM
ASM: Auto-Sequencing MemoryASM
GAG & enabling technology:published 1989 [by TU-KL],Survey paper: [M. Herz et al.*: IEEE ICECS 2003, Dubrovnik] *) IMEC & TU-KL
**) -- patented by TI** 1995
Storge Scheme optimization methodology, etc.

© 2006, [email protected] http://hartenstein.de60
TU Kaiserslautern
Xputer Lab at Kaiserslautern: MoM I and II1986: