quantitative analysis ii pubpol 528c spring 2017 … in evidence-based policy design and...
TRANSCRIPT

1
Quantitative Analysis II
PUBPOL 528C
Spring 2017
Instructor: Brian Dillon Meeting time: W 5:30-8:20
Email: [email protected] Class location: Parrington 108
Phone: 206.221.4601 TA: Austin Sell
Office: Parrington 209G TA email: [email protected]
Sections (Par 106): CA: Tuesday 4:30-5:20
CB: Friday 12:30-1:20
Instructor office hours: T 3:30-4:30 and Th 4:00-5:00 (sign up on Doodle), and by
appointment. Also 1 electronic OH I will explain in class.
TA office hours (Par 124E): M 4:00-6:00 and W 4:30-5:20, and by appointment
Textbook: A.H. Studenmund, Using Econometrics: A Practical Guide, 6th Ed. (not the 7th)
Website: http://www.canvas.uw.edu
Course Objectives
The goals of this course are to deepen your understanding of regression analysis and statistical modeling,
and to develop your skills in applying these techniques to public policy and management issues. We will
focus on choosing the right statistical framework for a particular question, estimating the relationship
between multiple factors and an outcome of interest, and determining when and why statistical estimates
can be interpreted as “causal.” Real world data will be used in most applications. Your aim should be
to develop an understanding of both the underlying statistical theory and the practical applications of the
course material.
For better or worse, in recent years the public discourse in many policy arenas has become increasingly
interested in evidence-based policy design and quantitative analysis. A mastery of basic econometrics
and a firm understanding of how to apply these ideas to real problems are essential for your forward
progress, both in the MPA program and in your careers to follow.
Software
We will use Stata for all problem sets and data assignments in this course. I will not presume that you
have any prior experience with the program. If you would like to buy a copy of Stata for your computer,
a 6-month license costs $75. Details are here (be sure to buy “Stata IC”, not “small Stata”):
http://www.stata.com/order/new/edu/gradplans/student-pricing/. Stata is available in the Parrington Hall
computer lab. You can also access Stata remotely through the Evans School Terminal Server or through
the UW Center for Studies in Demography and Ecology (CSDE). Instructions for remotely accessing
Stata will be posted before the course begins.
Excel might be useful for some of the assignments and for data manipulation.
Prerequisites

2
This course is only open to students who have successfully completed PBAF 527. Substitute
prerequisites from students outside of the Evans School will be considered on a case-by-case basis.
Reading
The schedule below gives an approximation of the reading schedule for the course. As the term
progresses, I will give more specific guidance on exactly which parts of which chapters are relevant for
each week. While the material in the lectures, quiz sections and problem sets is your best guide to what
will be on the quizzes and exams, all of the material in the assigned chapters is fair game on any
assessment. I will provide supplemental readings as the course progresses. These will be posted to the
course website.
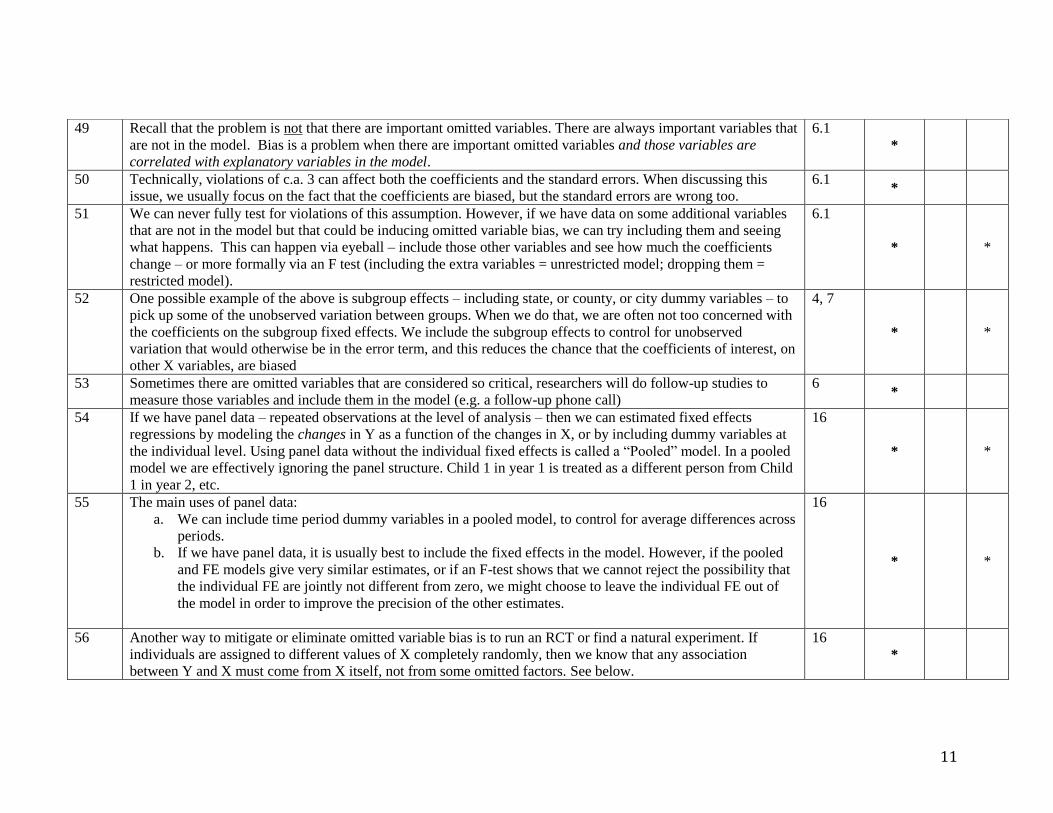
Grading and Assignments
Your grade will be based on 3 problem sets, 3 quizzes, a data analysis assignment, a written final exam
during finals week, and completion of the pre-class questionnaire. Due dates are posted on the timeline
below. Late work will receive a score of zero.
Problem sets will be posted roughly one week before they are due. Group work is allowed and
encouraged. However, working through the problem sets on your own is essential for doing well in this
course. Even if you work with others, you must generate your own answers to submit. Each problem set
is worth 10% of your final grade. Additional, non-graded problem sets may be provided. The 3 quizzes
will be roughly similar to each other, although I cannot guarantee that they will all have the same number
of questions or be of equal difficulty. Quizzes will be given in lecture. Each quiz is worth 10% of your
final grade. Make-up quizzes will not be offered, but I will drop your lowest score from the 6 problems
sets and quizzes, so missing one quiz does not have to affect your grade. Your final grade in this course
will be based on the following:
Pre-class Questionnaire (due by Tuesday, March 28, 11:59pm) 5%
Problem sets and Quizzes (6 x 10%, drop the lowest) 50%
Data Analysis Exam (take home, due May 30 at 11:59pm) 20%
Final Exam (June 6, 5:30-7:20, Par 108) 25%
I will not curve individual quizzes, problem sets, or exams, but I will curve your final scores if necessary.
My goal will be to ensure that the distribution of grades in the course is roughly similar to the recent
historical distribution of grades in PBAF 528.
Academic Integrity
UW and the Evans School expect students to adhere to the highest standards of academic integrity and
honesty. A student found to be cheating on a quiz or exam will receive a zero for that test. A second
offense will lead to a zero for the course.
Enrollment, Attendance, Absences
Check the University Calendar for the policy on incompletes and withdrawals. We will adhere to the
university dates and policies. If you are going to miss a class, talk to a classmate beforehand and arrange
to get a copy of her/his notes. Office hours are not intended as a time to repeat material because of a

3
class absence. If you have a scheduling conflict for the final exam, you must contact me prior to the
exam. Students who fail to do so will be given a zero for the exam and will forfeit the right to a make-
up. If you need to leave class early, please tell me before class and choose a seat near the exit. Finally,
when we have brief stretch breaks during class, please don’t leave the room.
Special Accommodations
If you have an arrangement with UW DRS for exam or quiz accommodations, please email me after the
first class so that we can set up a meeting and discuss the best way to proceed.
Communication
I want you to succeed in this course so we will be as available as possible to answer your questions and
support your progress. That said, here are a few rules to help us organize communication:
i. The best ways to contact me are in office hours, before/after class, or over email.
ii. Use the discussion board for STATA or OFFICE HOUR questions. I will explain this in class.
iii. If you email me, I will get back to you within 48 hours. Except emails sent on Friday, which
might not be answered until Monday.
iv. I only answer emails that contain a greeting that includes my name and/or title, and a signature
that includes your name.
Course Schedule
All dates other than the quizzes, final, and data analysis exams are subject to revision. Weekly reading
assignments should be completed prior to the lecture, in case we move more quickly than expected. See
below for more guidance on reading. For the first three weeks, quiz sections will be in the Language
Learning Center, Denny Hall, room 157 (Tuesday) or 156 (Friday).
Week # Class Dates Important Events Rough guide
to reading
1 3/29 Sections in computer lab. Tuesday: Denny Hall 157; Friday:
Denny Hall 156
Ch. 1-2
2 4/5 Sections in computer lab. Tuesday: Denny Hall 157; Friday:
Denny Hall 156; PS 1 due Sunday, April 9 at 11:59pm
Ch. 3-5
3 4/12 Sections in computer lab. Tuesday: Denny Hall 157; Friday:
Denny Hall 156; Quiz 1 in lecture
Ch. 6
4 4/19 Ch. 7
5 4/26 PS 2 due Sunday, April 30 at 11:59pm
6 5/3 Quiz 2 in lecture Ch. 8-10
7 5/10
8 5/17 PS 3 due Sunday, May 21 at 11:59 pm Ch. 13
9 5/24 Quiz 3 in lecture Ch. 16
10 5/31 Data Analysis Exam due Tuesday, May 30 at 11:59 pm
Ch. 11
Finals Final exam in Par 108 on Tuesday, June 6, 5:30-7:20

4
Topic List
In the matrix below I have listed most of the topics that we will cover this term. I will likely add to this,
or choose not to cover some of these points. Before each lecture I will post an announcement listing the
topic numbers that I expect to cover that week. You will notice that the location in the book of some
content will not always line up with the reading schedule in the previous table (hence the above table is
just a “rough guide”). Also, a few concepts are given only brief or partial coverage in the book. If you
look in the book for details on a topic and cannot find them, you can assume that I will provide the details
in class or will give additional readings.
I have also given an indication in the table of which content you will be expected to calculate or work
out by hand (“do the math”) and which content you will need to work with in Stata (by writing code,
interpreting Stata output, or both). All of that is subject to change.

5
You are expected
to…
# Concept Loca
tio
n i
n
book
Un
der
sta
nd
/
exp
lain
/
inte
rpre
t
Do t
he
ma
th
Use
in
Sta
ta
Main analytical framework
1 Central objective: associate the variation in some outcome of interest – the dependent variable, Y – with the
variation in some other variable or variables (the independent variables, X).
1 *
2 For example, X might be a variable indicating participation in a program, and Y is the outcome that the program
is supposed to impact.
1 *
3 The variance of a variable is a measure of its dispersion around the mean. The covariance and the correlation of
variables X and Y measure the extent to which they tend to move together around their respective means.
2.2,
17.1 * * *
4 We never observe the real process that generates the data. 1 *
5 We can write down a statistical model that relates the dependent variable Y to the independent variables, the Xs.
One example of such a model is:
(1) 𝑌𝑖 = 𝛼 + 𝛽1𝑋1𝑖 + 𝛽2𝑋2𝑖 + ⋯ + 𝛽𝐾𝑋𝐾𝑖 + 𝜀𝑖
In this model, 𝛼 is the intercept coefficient, 𝛽1 … 𝛽𝐾 are the slope coefficients, and 𝜺 is a statistical error term
that accounts for all of the variation in 𝒀 that is not explained by the Xs. The i subscript refers to a single
observation. If we have N observations, then i=1,…,N.
1
* * *
6 This is a statistical model, rather than a deterministic model, because we do not know the values of the
coefficients with certainty. That is, we never observe reality, and we also never observe the exact coefficients of
our model.
1
*
7 Instead, we estimate two objects for each coefficient/parameter in the above model. In the case of 𝑋1, we estimate
the coefficient, �̂�1, which is our “best guess” at the value of the true coefficient, and the estimated standard error,
SE(�̂�1), is a measure of how confident we are in that guess. We will define “best” later.
1, 4.2
* *
8 Because we generally only observe a sample, not the entire population of interest, slight differences in the sample
composition can lead to differences in �̂�1 and SE(�̂�1) (even if we were to repeat the estimation on randomly
generated samples). The smaller are the samples, the more likely it is that the estimated coefficients will be
different. The distribution of coefficient estimates for different samples of the same size is called the sampling
distribution. The estimated coefficient �̂�1 is the mean of the sampling distribution, and the estimated standard
error, SE(�̂�1), is the standard deviation of the sampling distribution.
4.2
*

6
Once we have estimated the coefficients, the predicted value of the outcome variable for each observation i is
given by
�̂�𝑖 = �̂� + �̂�1𝑋1𝑖 + �̂�2𝑋2𝑖 + ⋯ + �̂�𝐾𝑋𝐾𝑖
1.3, 1.4
* * *
9 The residual, 𝑒𝑖 , is the difference between the predicted value and the actual value: 𝑒𝑖 = 𝑌𝑖 − �̂�𝑖 1.3 * * *
Ordinary Least Squares (OLS)
10 There are infinite ways to (i) Model the relationships between Y and the Xs, and (ii) Choose values for the
coefficients, once we have decided on a specification for the model (by “specification” we mean “equation”)
1 *
11 Of all possible ways to model the relationships between Y and the Xs, we are focused on those that are linear in
the coefficients
4.1 * *
Of all possible ways to choose the values of the coefficients, OLS turns out to be the best way to “estimate the
model” (i.e., estimate the coefficients) under certain circumstances (see the Gauss-Markov Theorem).
2, 4 *
12 OLS chooses the values of �̂� and �̂�1 … �̂�𝐾 that minimize the sum of squared residuals (RSS): 𝑅𝑆𝑆 = ∑ 𝑒𝑖2𝑁
𝑖=1 2.1 * *
13 By minimizing the sum of squared residuals, rather than the sum of residuals, OLS (1) penalizes larger residuals
more than smaller residuals, and (2) avoids having positive and negative residuals cancel each other out
2.1 *
14 In the bivariate case, with only one X variable, the OLS estimate of the slope coefficient is �̂�1 =𝑐𝑜𝑣(𝑋,𝑌)
𝑣𝑎𝑟(𝑋), where
𝑐𝑜𝑣(𝑋, 𝑌) = ∑ (𝑋𝑖−𝑋)(𝑌𝑖−𝑌)𝑁
𝑖=1
𝑁−1 and 𝑣𝑎𝑟(𝑋) =
∑ (𝑋𝑖−𝑋)2𝑁𝑖=1
𝑁−1. Note that it would also be Ok to write the covariance
and the variance with N in the denominator – the difference depends on a minor point that is beyond our scope.
The intuitive interpretation for an OLS coefficient is that it is a ratio of a covariance to a variance – a measure of
how much X and Y move together, normalized by how much X is just varying around on its own.
2.1
* *
15 In the bivariate case, the OLS estimate of the intercept coefficient is α̂ = 𝑌 − �̂�1𝑋. By choosing the intercept this
way, we ensure that the mean of the residuals is zero.
2.1 * *
16 In the multivariate case, the formulas are more complicated, because they account for the relationships between
each X and Y, but also take into account the correlation between the Xs.
2.2 *
17 The interpretation of an OLS coefficient from a multivariate regression is “A 1-unit increase in Xk is associated
with a �̂�𝐾 increase in Y, controlling for [list the other explanatory variables]”
2.2 *
18 To “estimate a model” we need to find two objects – the coefficients, and the standard errors. These should
always be thought of together. In a statistical model, uncertainty is a key part of the modeling process. The
coefficient estimate is essentially useless if it is not accompanied by a measure of how confident we are about the
estimate (a standard error).
1, 4.2
* *

7
Testing
19 Under most circumstances, the coefficients estimated by OLS follow the Student’s t distribution with N-k-1
degrees of freedom. For large N, the t distribution is essentially the normal distribution.
5 *
20 A two-tailed test of hypothesis 𝐻0: 𝛽𝑘 = 𝑆 has the test statistic 𝑡 = (�̂�𝑘 − 𝑆) 𝑆𝐸(�̂�𝑘),⁄ which we compare to a
table of critical values for some level of confidence α/2 with degrees of freedom N-k-1. We construct two-sided
confidence intervals for 𝛽𝑘 as [�̂�𝑘 ± 𝑆𝐸(�̂�𝑘)𝑡𝛼
2,𝑁−𝑘−1]
5
* * *
21 We might be interested in other tests based on the estimated coefficient and standard error. If the test of interest is
1-sided (e.g., we want to specifically test whether a program made people worse off), we run a 1-tailed test:
a. The hypothesis can never be rejected (at conventional levels of significance) if the sign of the coefficient
is the same as that under the null hypothesis. E.g., if �̂�𝑘 is positive, we can never reject 𝐻0: 𝛽𝑘 ≥ 0
b. If the sign of the coefficient is the opposite of that under the null hypothesis, then the test statistic is the
same as for a 2-tailed test, but the rejection region is larger (it is determined by α rather than α/2).
5
* * *
22 An F-test is a general approach to testing whether multiple hypotheses are true simultaneously. The standard form
of the test:
a. Ignore the null hypothesis and estimate the model. This is the “unrestricted model.” Retain the RSS.
b. Impose the restrictions and re-estimated the model. This is the “restricted model.” Retain the RSS.
c. Form the test statistic and compare to a table of F-distribution critical values with q degrees of freedom in
the numerator and N-k-1 degrees of freedom in the denominator, where q is the number of constraints
(restrictions).
5.6
* * *
How “good” is the model?
23 The RSS is one part of the decomposition of the variance of Y. The other part is the explained sum of squares, or
ESS, which is defined as 𝐸𝑆𝑆 = ∑ (�̂�𝑖𝑁𝑖=1 − 𝑌). ESS + RSS = TSS, where 𝑇𝑆𝑆 = ∑ (𝑌𝑖
𝑁𝑖=1 − 𝑌). Note that TSS is
like the variance of Y, except that it is not divided by (N-1).
2.2
* * *
24 Because the goal of this modeling exercise is to explain the variation in Y, the TSS is a measure of how much
variation there actually is to explain. The more that the Yi are spread around the mean of Y – i.e., the more that
they vary – the higher is the TSS.
2.2
*
25 R2 = ESS/TSS gives the proportion of the variation in Y that is explained by the model. R2 always lies between 0
and 1. That is, the model can never explain more of the variation than there is to explain. R2 is fine as a rough
measure of how much of the variation in Y we are explaining, for this specific sample. It is not a very useful tool
2.4
* * *

8
for determining how good the model is, because adding meaningless variables to the model can increase R2, but
can never decrease it. So a high R2 is not necessarily evidence of a good model.
26 Adjusted R2 corrects for that final problem by incorporating a penalty for every variable that is added to the
model. Adding an explanatory variable to the model can decrease adjusted R2, if the explanatory power of the
new variable is not sufficient to offset the penalty for adding a term. Adjusted R2 can be negative.
2.4
* * *
27 An F-test for overall significance is a standard, theoretically-grounded way to evaluate the goodness-of-fit 5.6 * * *
Explanatory variables / Alternative specifications
28 A categorical variable is a variable that assigns each observation to one of a list of possible categories using
numerical codes (e.g., 1=US citizen, 2=Permanent resident, 3=Visa holder, 4=Other)
7 *
29 A categorical variable cannot be entered directly in a model, because the numerical categories do not have any
real meaning. If we used a different numbering scheme – which would not change the category data in any
meaningful way – we would get different OLS results. Clearly not ideal.
7
*
30 Instead, to account for between-group differences, we construct separate dummy variables for each group, where
the dummy variable takes a value of 1 if the observation is a member of the group, and 0 otherwise. When we
include dummy variables, one must always be excluded. That is the “reference group” or the “excluded group”
against which the others are compared
7
* *
31 For example, if we want to model the outcome Y as a function of the residency status categorical variable from
part 4a, we could build separate dummy variables for each category and estimate the following:
(2) 𝑌𝑖 = 𝛼 + 𝛽1𝐶𝐼𝑇𝐼𝑍𝐸𝑁𝑖 + 𝛽2𝑃𝐸𝑅𝑀𝑖 + 𝛽3𝑉𝐼𝑆𝐴𝑖 + 𝜀𝑖
Then the predicted values are:
�̂�𝑖 = �̂� + �̂�1(1) + �̂�2(0) + �̂�3(0) = �̂� + �̂�1 for an i with CITIZENi=1
�̂�𝑖 = �̂� + �̂�1(0) + �̂�2(1) + �̂�3(0) = �̂� + �̂�2 for an i with PERMi=1
�̂�𝑖 = �̂� + �̂�1(0) + �̂�2(0) + �̂�3(1) = �̂� + �̂�3 for an i with VISAi=1
�̂�𝑖 = �̂� + �̂�1(0) + �̂�2(0) + �̂�3(0) = �̂� for an i with OTHERi=1
7
* * *
32 In the above case, each subgroup has its own intercept. If there were additional continuous variables in the model,
without any additional interactions, then the slope coefficients would be the same for all subgroups. Only the
intercepts are different, in this case.
7
*
33 We can construct interactions between dummy variables to allow more specific subgroups to have their own
intercepts. For example, we could add gender dummy variables to model (2), and then interact the gender dummy
variables with the residency variables if we believe that the relationship between residency status and Y might
differ across genders.
7
* *

9
34 We can also add interaction terms between dummy variables and continuous variables, to allow each subgroup to
have its own slope coefficient. In that case, we always include in the model the dummy variable, the continuous
variable, and the interaction (never include the interaction without including each interacted variable on its own).
7
* *
35 If some of the variables in our data are nested – e.g., we have data on kids in schools, and every child in school A
is in county B, and every child in county B is in State C, etc. – then we can only include dummy variables for one
level of subgroup effects (also called group effects, or “[GROUP] fixed effects”, or “controls for [GROUP]”).
The lower the level, the more we control for unobserved differences between groups. But the lower we go, the
more variables we are including in the model, which reduces statistical power and tends to increase standard
errors.
7
* *
36 We can use OLS as long as we stick to models that are linear in the coefficients. A model can be linear in the
coefficients but still allow for non-linear relationships between Y and the X variables.
7 *
37 Ways to model non-linear relationships between Y and X:
i. Include higher-order X terms, such as X2, X3, etc., as explanatory variables. This is useful if we think that the
marginal association between X and Y is different at different values of X.
ii. Use log transformations, such as
Semi-log: log 𝑌𝑖 = 𝛼 + 𝛽1𝑋1𝑖 + 𝜀𝑖
Log-log: log 𝑌𝑖 = 𝛼 + 𝛽1 log 𝑋1𝑖 + 𝜀𝑖
7
* *
38 Logged variables should be interpreted in percentage terms. The estimated coefficient from the semi-log
specification gives the percentage increase in Y associated with a 1-unit increase in X .
7 * *
39 The estimated coefficient from the log-log specification gives the percentage increase in Y associated with a 1
percent increase in X (i.e., the elasticity of Y with respect to X).
7 * *
The Gauss-Markov Theorem and the classical assumptions
40 The Gauss-Markov Theorem states that among all possible ways to estimate a model, OLS is the Best, Linear,
Unbiased, Estimator (OLS is BLUE) when the classical assumptions are true.
4 *
41 Best = minimum variance, where variance refers to the “variance of the regression.” You can think of “Best” as
“Smallest standard errors, without introducing bias”
4 *
42 Unbiased: refers to the estimated �̂� coefficients. An estimator (or estimation method) is unbiased if it is correct on
average. That is, if we could draw many different samples and estimate the coefficients for each sample, on
average they would be equal to the true values of the coefficients. Note that you cannot know this for a specific
empirical example, because you never observe the true model. Instead, statisticians have worked out through
theory and simulations that if the classical assumptions hold, OLS will be unbiased.
4
*

10
43 Linear: linear in the coefficients. Other ways to modeling Y and X might have lower standard errors than OLS
and be unbiased, but they would have to be non-linear in the coefficients, which goes beyond our scope.
4 * *
44 OLS is BLUE when the 6 classical assumptions hold. Because they are assumptions, they are never fully testable.
But it is possible to run some tests that give an indication of whether the classical assumptions hold.
4 *
45 The assumptions that we will not spent a lot of time on:
a. Linear, correctly specified, additive error. We only use linear models with additive errors. Whether
the model is “correctly specified” is a slightly vague term, because it can refer to whether we have
modeled the relationships in the right way, e.g. by using logs or higher order powers of X when
appropriate, and it can also refer to whether there are important omitted variables. For us, the latter
issue is more of a classical assumption 3 issue. But you might see people referring to the issue of
possible omitted variables as a specification problem.
b. Error is mean zero. Because of how we estimate the intercept, this is true by definition in OLS.
c. No perfect multicollinearity. We will talk about this briefly. None of the X variables can be an exact
linear function of the others. This is why we must always exclude one dummy variable. It can also be
problematic to interpret coefficients if we include many, highly collinear variables in the model.
4
* *
Violations of classical assumption 3
46 Classical assumption 3 states that the X variables cannot be correlated with the error term. When this is violated,
it is a case of “omitted variable bias.” A more specific type of omitted variable bias is “selection bias,” in which
some units in the data are selecting into a situation that changes both X and Y. For example, if X is a dummy
variable for participating in a program, and program eligibility requires attending sessions 3 weekdays in a row at
2pm, then only people who are unemployed or can take off of work to attend the sessions will enroll in the
program. These people are selecting into participation, and they might have different outcomes from non-
participants for reasons not caused by the program itself. Something unobserved about these people could be
affecting both X and Y. But because we don’t know what that is and it is not in the model, it introduces bias into
the estimate coefficient on the X variable (and possibly on the other coefficient estimates, too).
6.1,
17.2
*
47 Selection bias and other forms of omitted variable bias are some of the main reasons that we cannot generally
view our estimates as causal estimates. If X and Y are varying together because of other factors, we don’t know
what proportion of their co-movement is due those other factors, and what is due to X itself.
6.1,
16.1,
17.2 *
48 There is surely always a little bit of correlation between X and epsilon. But the more there is, the more likely it is
that the coefficients are biased.
4, 6.1 *
11
49 Recall that the problem is not that there are important omitted variables. There are always important variables that
are not in the model. Bias is a problem when there are important omitted variables and those variables are
correlated with explanatory variables in the model.
6.1
*
50 Technically, violations of c.a. 3 can affect both the coefficients and the standard errors. When discussing this
issue, we usually focus on the fact that the coefficients are biased, but the standard errors are wrong too.
6.1 *
51 We can never fully test for violations of this assumption. However, if we have data on some additional variables
that are not in the model but that could be inducing omitted variable bias, we can try including them and seeing
what happens. This can happen via eyeball – include those other variables and see how much the coefficients
change – or more formally via an F test (including the extra variables = unrestricted model; dropping them =
restricted model).
6.1
* *
52 One possible example of the above is subgroup effects – including state, or county, or city dummy variables – to
pick up some of the unobserved variation between groups. When we do that, we are often not too concerned with
the coefficients on the subgroup fixed effects. We include the subgroup effects to control for unobserved
variation that would otherwise be in the error term, and this reduces the chance that the coefficients of interest, on
other X variables, are biased
4, 7
* *
53 Sometimes there are omitted variables that are considered so critical, researchers will do follow-up studies to
measure those variables and include them in the model (e.g. a follow-up phone call)
6 *
54 If we have panel data – repeated observations at the level of analysis – then we can estimated fixed effects
regressions by modeling the changes in Y as a function of the changes in X, or by including dummy variables at
the individual level. Using panel data without the individual fixed effects is called a “Pooled” model. In a pooled
model we are effectively ignoring the panel structure. Child 1 in year 1 is treated as a different person from Child
1 in year 2, etc.
16
* *
55 The main uses of panel data:
a. We can include time period dummy variables in a pooled model, to control for average differences across
periods.
b. If we have panel data, it is usually best to include the fixed effects in the model. However, if the pooled
and FE models give very similar estimates, or if an F-test shows that we cannot reject the possibility that
the individual FE are jointly not different from zero, we might choose to leave the individual FE out of
the model in order to improve the precision of the other estimates.
16
* *
56 Another way to mitigate or eliminate omitted variable bias is to run an RCT or find a natural experiment. If
individuals are assigned to different values of X completely randomly, then we know that any association
between Y and X must come from X itself, not from some omitted factors. See below.
16
*

12
Violations of classical assumptions 4 and/or 5
57 The general term for the problem of a non-constant variance of 𝜀 is “heteroskedasticity” or heteroskedastic errors.
When there is no violation of this assumption, we say that the errors are homoskedastic.
10 *
58 OLS assumes homoskedasticity when it constructs the standard errors. So if the assumption is wrong, so are the
standard errors. Usually, but not always, the standard errors are biased downwards (too small). That leads to
inflated t-statistics and an unjustifiably high probability of rejecting the null hypothesis in a t-test
10
* *
59 Heteroskedasticity does not bias the estimated coefficients. 10 *
60 To detect heteroskedasticity: White’s test 10 * * *
61 To correct for general (unspecific) forms of heteroskedasticity: use “robust” standard errors n/a * *
62 If we have reason to believe that the variance of 𝜀 is different for members of certain subgroups, or that the errors
for members of a subgroup might be correlated, then we have a second possible violation of the classical
assumptions. The fix for this: cluster the standard errors. This is only an option if we have a theory about the
subgroups within which the errors might be correlated or within which the variance of 𝜀 might be constant. If we
have multiple options for clustering, the higher level (e.g. state instead of county) is more cautious. But theory
should be the guide – clustering at a very high level just to be cautious is not advisable, because it can inflate the
standard errors to correct for a problem that does not exist. However, if you are unsure of the appropriate level,
cluster at a higher level, to be safe.
n/a
* *
Moving from “associations” to “causation”
63 The selection problem 16 *
64 Randomization solves the selection problem (often implementd via randomized, controlled trials, or RCTs) 16 *
65 There are still challenges to interpretation of RCT results:
1. How representative is the experimental sample for the population as a whole?
2. How successful was the experimenter at inducing compliance?
3. Could there be spillovers or interactions between the Treatment and Control groups?
4. Will outcomes change if a small program is implemented at larger scale?
5. Can we properly identify the causal mechanism?
16
*
66 Other approaches to causal modeling (a preview of PUBPOL 529):
1. Natural experiments
2. Instrumental variables
3. Matching
14.3,
16 *