programming language syntax and analysiscompiler.sangji.ac.kr/lecture/plt/2017/lecture03.pdf ·...
TRANSCRIPT

Programming Language Syntax and Analysis
2017
Kwangman Ko
(http://compiler.sangji.ac.kr, [email protected])
Dept. of Computer Engineering, Sangji University

Introduction
Syntax
• the form or structure of the expressions, statements, and program units
Semantics
• the meaning of the expressions, statements, and program units
Syntax and semantics provide a language’s definition
• Users of a language definition
• Other language designers
• Implementers
• Programmers (the users of the language)
2

The General Problem of Describing Syntax: Terminology
Sentence
• a string of characters over some alphabet
Language
• a set of sentences
Lexeme• the lowest level syntactic unit of a language (e.g., *, sum, begin)
Token
• a category of lexemes (e.g., identifier)
3

Formal Definition of Languages
Recognizers• A recognition device reads input strings over the alphabet of the language and decides
whether the input strings belong to the language
• Example: syntax analysis part of a compiler
- Detailed discussion of syntax analysis appears in Chapter 4
Generators• A device that generates sentences of a language
• One can determine if the syntax of a particular sentence is syntactically correct by comparing it to the structure of the generator
4

BNF and Context-Free Grammars
Context-Free Grammars
• Developed by Noam Chomsky in the mid-1950s
• Language generators, meant to describe the syntax of natural languages
• Define a class of languages called context-free languages
Backus-Naur Form (1959)
• Invented by John Backus to describe the syntax of Algol 58
• BNF is equivalent to context-free grammars
5

BNF Fundamentals
In BNF, abstractions• used to represent classes of syntactic structures• syntactic variables
• nonterminal symbols, terminals
Terminals• lexemes or tokens
A syntax rule• a left-hand side (LHS), which is a nonterminal• a right-hand side (RHS), which is a string of terminals and/or nonterminals
6

BNF Fundamentals (continued)
Nonterminals are often enclosed in angle brackets
• Examples of BNF rules:
<ident_list> → identifier | identifier, <ident_list>
<if_stmt> → if <logic_expr> then <stmt>
Grammar• a finite non-empty set of rules
A start symbol• a special element of the nonterminals of a grammar
7

BNF Rules
Nonterminal symbol
• can have more than one RHS
<stmt> <single_stmt>
| begin <stmt_list> end
8

Describing Lists
Syntactic lists
• described using recursion
<ident_list> ident
| ident, <ident_list>
A derivation
• is a repeated application of rules
• starting with the start symbol
• ending with a sentence (all terminal symbols)
9

An Example Grammar
<program> <stmts>
<stmts> <stmt> | <stmt> ; <stmts>
<stmt> <var> = <expr>
<var> a | b | c | d
<expr> <term> + <term> | <term> - <term>
<term> <var> | const
10

An Example Derivation
<program> => <stmts> => <stmt>
=> <var> = <expr>
=> a = <expr>
=> a = <term> + <term>
=> a = <var> + <term>
=> a = b + <term>
=> a = b + const
11

Derivations
Every string of symbols in a derivation is a sentential form
A sentence is a sentential form that has only terminal symbols
A leftmost derivation
• one in which the leftmost nonterminal in each sentential form is the one that is expanded
A derivation may be neither leftmost nor rightmost
12

Parse Tree
A hierarchical representation of a derivation
13
<program>
<stmts>
<stmt>
const
a
<var> = <expr>
<var>
b
<term> + <term>

Extended BNF
Optional parts are placed in brackets [ ]
<proc_call> -> ident [(<expr_list>)]
Alternative parts of RHSs are placed inside parentheses and separated via vertical bars
<term> → <term> (+|-) const
Repetitions (0 or more) are placed inside braces { }
<ident> → letter {letter|digit}
14

BNF and EBNF
BNF
<expr> <expr> + <term>
| <expr> - <term>
| <term>
<term> <term> * <factor>
| <term> / <factor>
| <factor>
EBNF
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
15

Chap. 4 : Syntax Analysis

Syntax Analysis
The syntax analysis portion of a language processor nearly always consists of two parts:
• A low-level part called a lexical analyzer (mathematically, a finite automaton based on a regular grammar)
• A high-level part called a syntax analyzer, or parser (mathematically, a push-down automaton based on a context-free grammar, or BNF)
17

Advantages of Using BNF to Describe Syntax
Provides a clear and concise syntax description
The parser can be based directly on the BNF
Parsers based on BNF are easy to maintain
18

Reasons to Separate Lexical and Syntax Analysis
Simplicity
• less complex approaches can be used for lexical analysis; separating them simplifies the parser
Efficiency
• separation allows optimization of the lexical analyzer
Portability
• parts of the lexical analyzer may not be portable, but the parser always is portable
19

Lexical Analysis
A lexical analyzer
• is a pattern matcher for character strings
• “front-end” for the parser
Identifies substrings of the source program that belong together - lexemes• Lexemes match a character pattern, which is associated with a lexical
category called a token• sum is a lexeme; its token may be IDENT
20

Lexical Analysis (continued)
The lexical analyzer
• usually a function that is called by the parser when it needs the next token
Three approaches to building a lexical analyzer:
• Write a formal description of the tokens and use a software tool that constructs a table-driven lexical analyzer from such a description
• Design a state diagram that describes the tokens and write a program that implements the state diagram
• Design a state diagram that describes the tokens and hand-construct a table-driven implementation of the state diagram
21

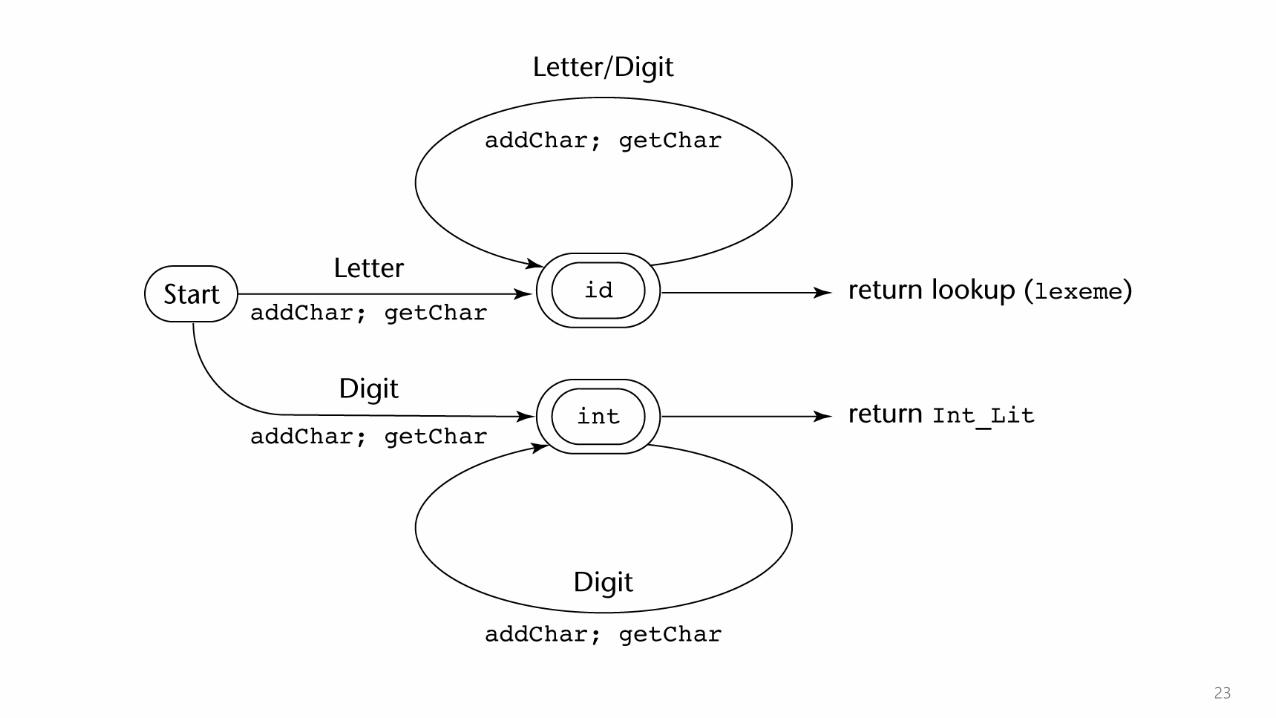
State Diagram Design
A naïve state diagram
have a transition from every state on every character in the source language
such a diagram would be very large!
22
23

Implementation: SHOW front.c (pp. 185-190)
Following is the output of the lexical analyzer offront.c when used on (sum + 47) / total
Next token is: 25 Next lexeme is (
Next token is: 11 Next lexeme is sum
Next token is: 21 Next lexeme is +
Next token is: 10 Next lexeme is 47
Next token is: 26 Next lexeme is )
Next token is: 24 Next lexeme is /
Next token is: 11 Next lexeme is total
Next token is: -1 Next lexeme is EOF
24

The parsing Problem
Goals of the parser, given an input program:
• Find all syntax errors; for each, produce an appropriate diagnostic message and recover quickly
• Produce the parse tree, or at least a trace of the parse tree, for the program
25

The Parsing Problem (continued)
Two categories of parsers
• Top down - produce the parse tree, beginning at the root
• Order is that of a leftmost derivation
• Traces or builds the parse tree in preorder
• Bottom up - produce the parse tree, beginning at the leaves
• Order is that of the reverse of a rightmost derivation
Useful parsers look only one token ahead in the input
26

Top-down Parsers
• Given a sentential form, xA,
• the parser must choose the correct A-rule to get the next sentential form in the leftmost derivation
• using only the first token produced by A
The most common top-down parsing algorithms:
• Recursive descent - a coded implementation
• LL parsers - table driven implementation
27

Bottom-up parsers
• Given a right sentential form, ,
• determine what substring of is the right-hand side of the rule in the grammar that must be reduced to produce the previous sentential formin the right derivation
• The most common bottom-up parsing algorithms are in the LR family.
28

Recursive-Descent Parsing
There is a subprogram for each nonterminal in the grammar,
• which can parse sentences that can be generated by that nonterminal
EBNF is ideally suited for being the basis for a recursive-descent parser, because EBNF minimizes the number of nonterminals
29

A grammar for simple expressions:
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
<factor> id | int_constant | ( <expr> )
30

/* Function expr arses strings in the languagegenerated by the rule:<expr> → <term> {(+ | -) <term>}
*/
void expr() {
/* Parse the first term */
term();
/* As long as the next token is + or -, call
lex to get the next token and parse the
next term */
while (nextToken == ADD_OP ||
nextToken == SUB_OP){
lex();
term();
}
31

Trace of the lexical and syntax analyzers on (sum + 47) / total
Next token is: 25 Next lexeme is ( Next token is: 11 Next lexeme is total
Enter <expr> Enter <factor>
Enter <term> Next token is: -1 Next lexeme is EOF
Enter <factor> Exit <factor>
Next token is: 11 Next lexeme is sum Exit <term>
Enter <expr> Exit <expr>
Enter <term>
Enter <factor>
Next token is: 21 Next lexeme is +
Exit <factor>
Exit <term>
Next token is: 10 Next lexeme is 47
Enter <term>
Enter <factor>
Next token is: 26 Next lexeme is )
Exit <factor>
Exit <term>
Exit <expr>
Next token is: 24 Next lexeme is /
Exit <factor>
32

Pairwise Disjointness Test:
• For each nonterminal, A, in the grammar that has more than one RHS,
• for each pair of rules, A i and A j, it must be true that
FIRST(i) ⋂ FIRST(j) =
Example:
A a | bB | cAb
A a | aB
33

Bottom-up Parsing
The parsing problem is finding the correct RHS in a right-sentential form
• to reduce to get the previous right-sentential form in the derivation
Shift-Reduce Algorithms
• Reduce is the action of replacing the handle on the top of the parse stack with its corresponding LHS
• Shift is the action of moving the next token to the top of the parse stack
34

Advantages of LR parsers:
• They will work for nearly all grammars that describe programming languages.
• They work on a larger class of grammars than other bottom-up algorithms, but are as efficient as any other bottom-up parser.
• They can detect syntax errors as soon as it is possible.
• The LR class of grammars is a superset of the class parsable by LL parsers.
35

An LR configuration stores the state of an LR parser
(S0X1S1X2S2…XmSm, aiai+1…an$)
36

LR parsers are table driven, where the table has two components, an ACTION table and a GOTO table
• The ACTION table specifies the action of the parser, given the parser state and the next token
• Rows are state names; columns are terminals
• The GOTO table specifies which state to put on top of the parse stack after a reduction action is done
• Rows are state names; columns are nonterminals
37
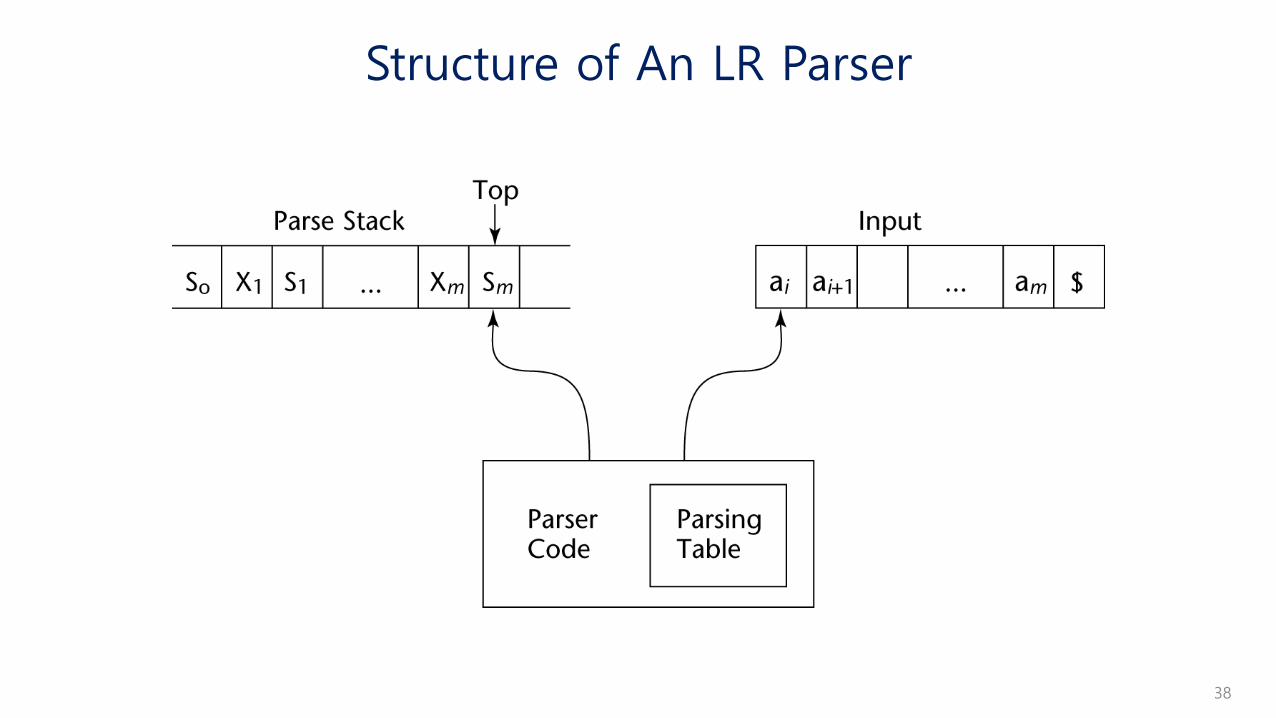
Structure of An LR Parser
38

Parser actions:
• For a Shift, the next symbol of input is pushed onto the stack, along with the state symbol that is part of the Shift specification in the Action table
• For a Reduce,
• remove the handle from the stack, along with its state symbols.
• Push the LHS of the rule.
• Push the state symbol from the GOTO table, using the state symbol just below the new LHS in the stack and the LHS of the new rule as the row and column into the GOTO table
39

• For an Accept,
• the parse is complete and no errors were found.
• For an Error,
• the parser calls an error-handling routine.
40
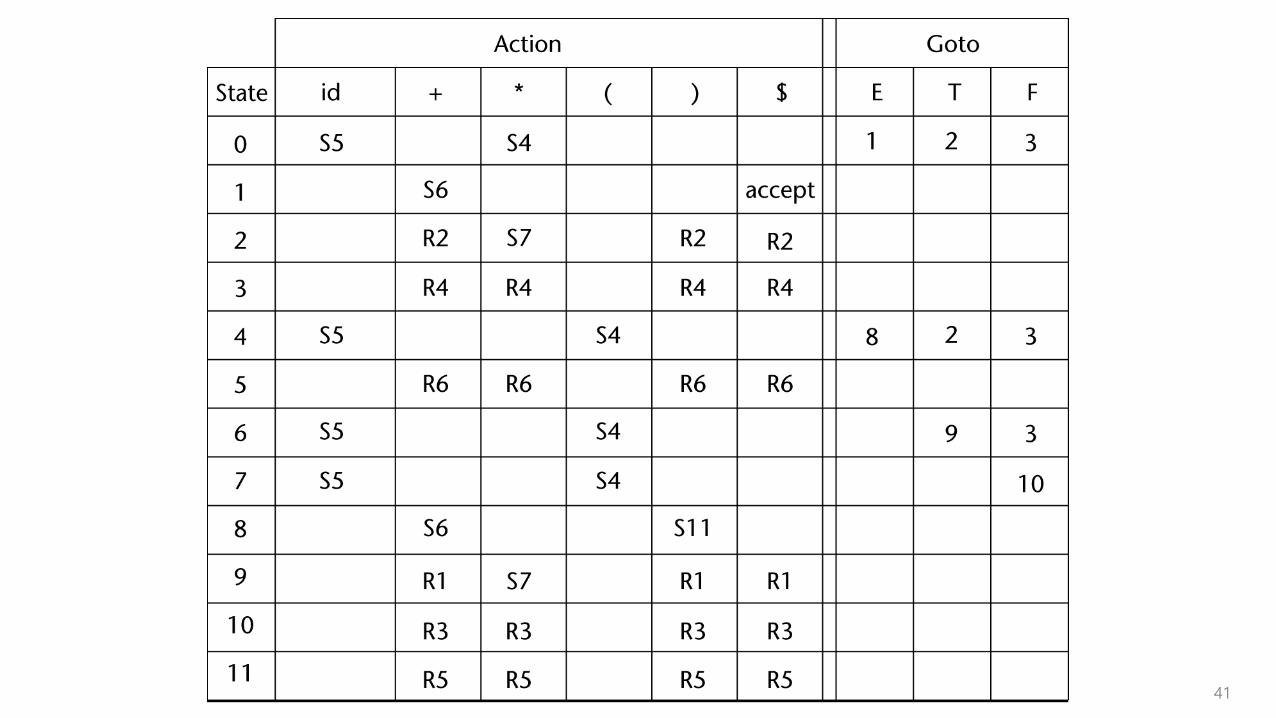
41
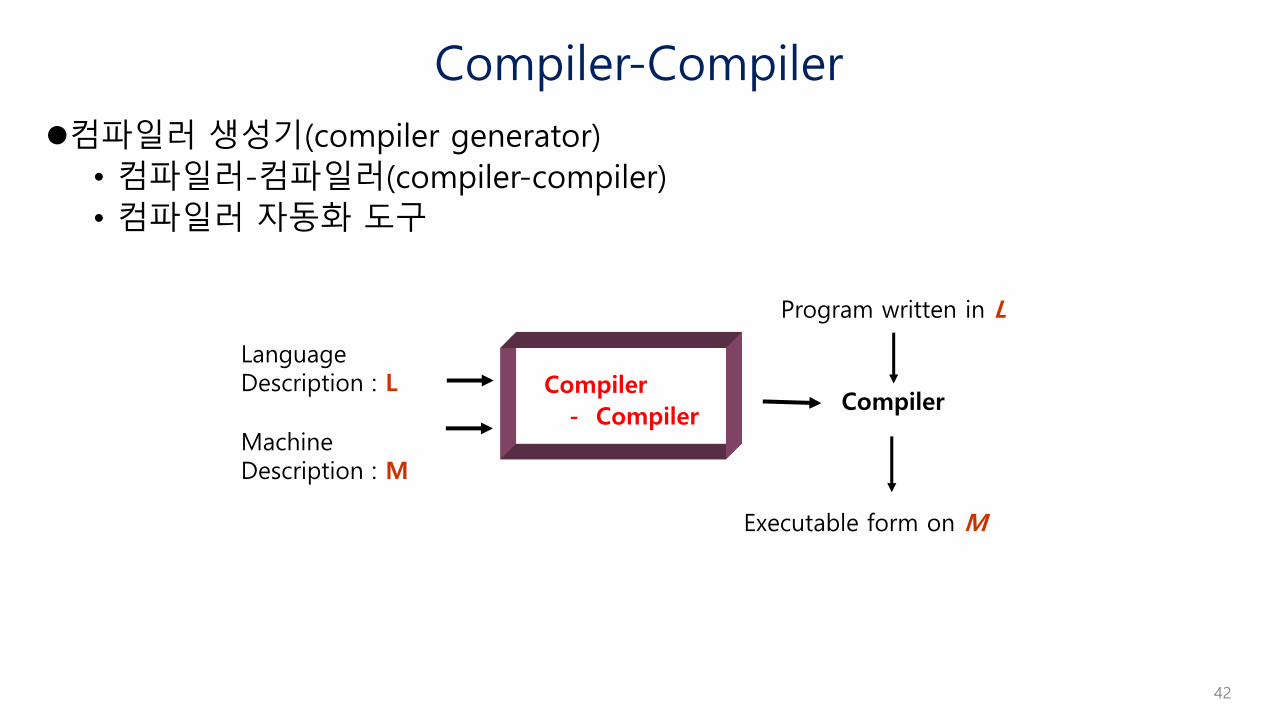
Compiler-Compiler
컴파일러 생성기(compiler generator)
• 컴파일러-컴파일러(compiler-compiler)
• 컴파일러 자동화 도구
42
LanguageDescription : L
CompilerCompiler
- CompilerMachineDescription : M
Program written in L
Executable form on M
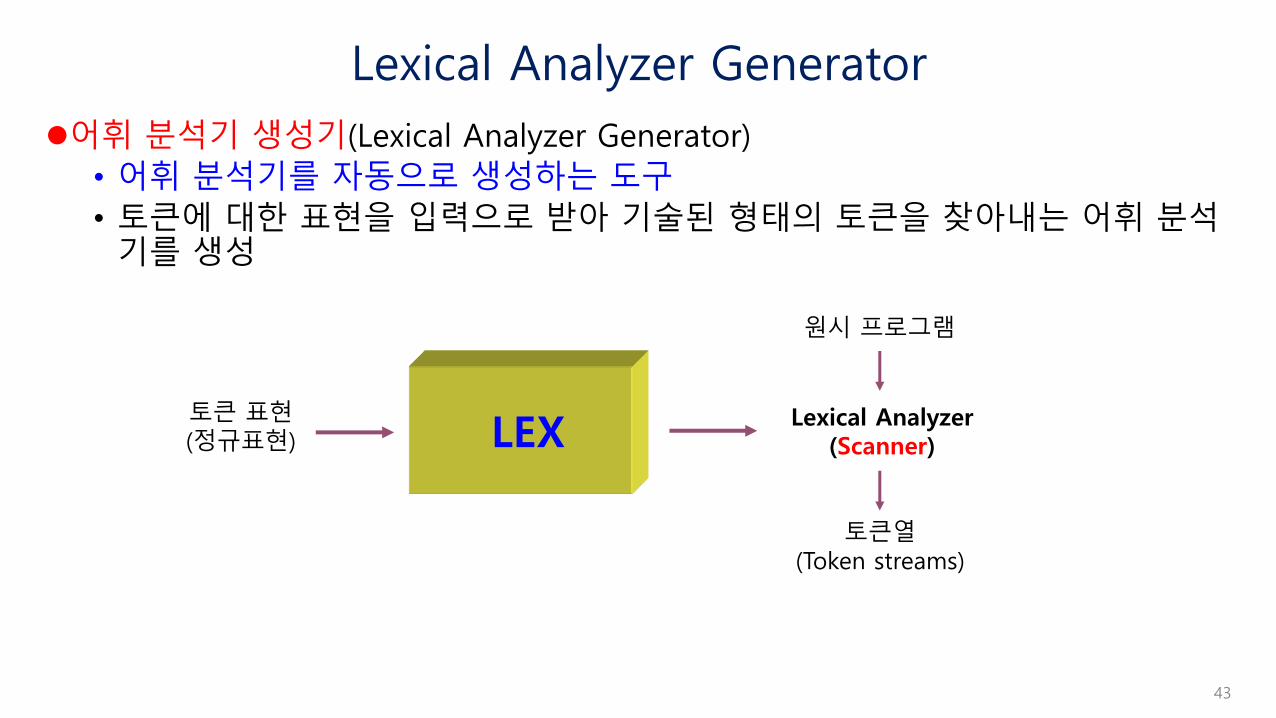
Lexical Analyzer Generator
어휘 분석기 생성기(Lexical Analyzer Generator)
• 어휘 분석기를 자동으로 생성하는 도구
• 토큰에 대한 표현을 입력으로 받아 기술된 형태의 토큰을 찾아내는 어휘 분석기를 생성
43
토큰 표현(정규표현)
Lexical Analyzer(Scanner)LEX
원시 프로그램
토큰열(Token streams)

LEX
정의 및 특징
• Lesk & Schmidt(Bell lab., 1975)
• 토큰의 형태를 묘사한 정규 표현들과 각 정규 표현이 매칭되었을 때 처리를 나타내는 수행 코드로 구성된 입력 받아 어휘 분석의 일을 처리하는 프로그램을출력
44
lex
lex.yy.c
정규표현 +수행 코드
원시프로그램
일련의토큰

Parser Generator
정의
• 언어의 문법 표현으로부터 파서를 자동으로 생성하는 도구 : Parser Generating System; PGS
파서 생성기의 기능
• 파서 생성기 입력 : 문법 표현(context-free 문법)
• 파서 생성기 출력 : 파서를 제어하는 테이블
• 파서
• 주어진 문장에 대한 문법 검사
• 컴파일러 다음 단계에서 필요한 정보 생성
45
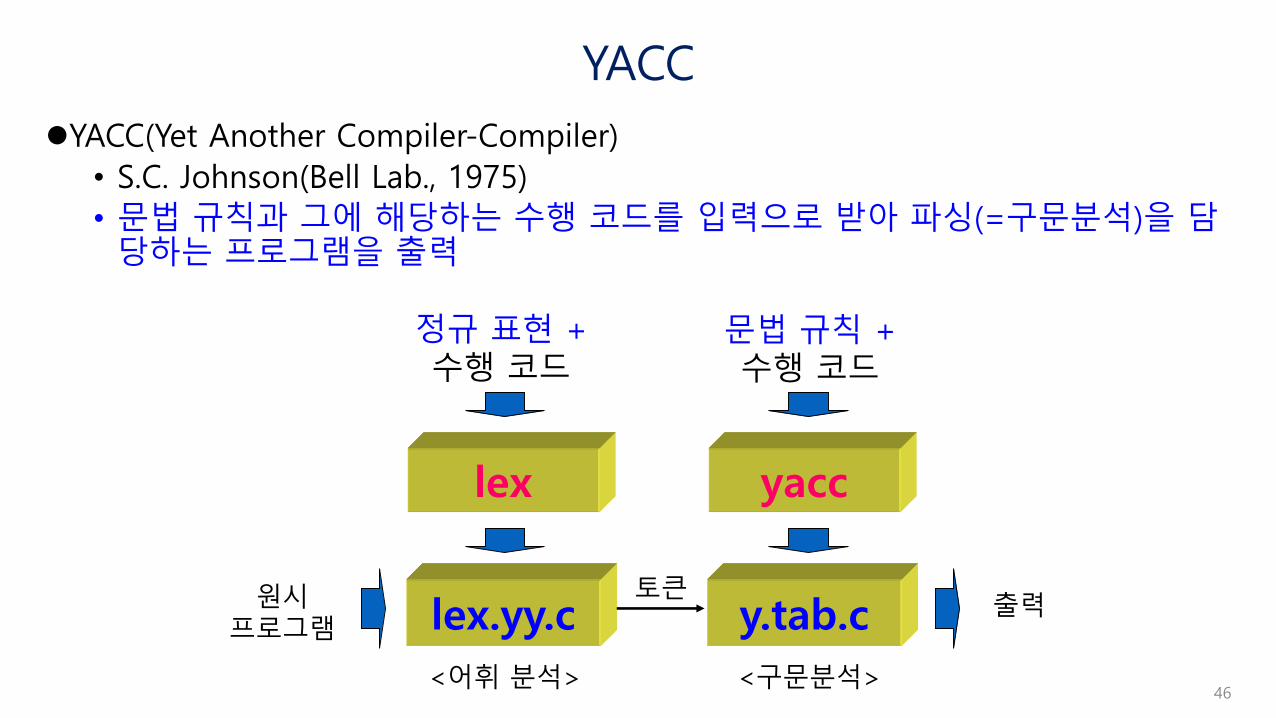
YACC
YACC(Yet Another Compiler-Compiler)
• S.C. Johnson(Bell Lab., 1975)
• 문법 규칙과 그에 해당하는 수행 코드를 입력으로 받아 파싱(=구문분석)을 담당하는 프로그램을 출력
46
lex
lex.yy.c y.tab.c
yacc
정규 표현 +수행 코드
문법 규칙 +수행 코드
원시프로그램
<어휘 분석> <구문분석>
출력토큰
