processing 11 billions events a day with spark - percona facts 10m photos added daily 21m daily...
TRANSCRIPT

Processing 11 billions events a day
with SparkAlexander Krasheninnikov

Badoo facts
10MPhotos
added
daily
21Mdaily
active
users
320Mregistered
users
3000+servers
46languages
190countries
2data-centers
350Mmessages
daily

What is this talk about?
✦Necessity of measuring product’s metrics
✦What tools you can use for it
✦Our solution’s design for this purpose

Why to measure?

“ IF YOU WANT TO IMPROVE SOMETHING, YOU OUGHT TOMEASURE IT FIRST
— one good engineering principle

Product metrics
✦ Registrations
✦ UGC
✦ User actions (likes, messages, votes)
✦ UX (interaction with service)
✦ etc.

Processing specialty

Large sliding windows
Aggregation of data within
1 hour or 1 day – millions of events

Heterogeneous events
Di=erent events has their own
set of attributes and aggregation
instructions

Di=erent dimensions
As consequence – aggregation
is performed on di=erent
grouping ?elds

Reaction needed ASAP
Event’s aggregation results
should be available in reasonable
time (every 2-5 minutes)

Our ?rst approach

StatsCollector
✦ In-house MySQL-based event processing
system
✦ Each event has it’s own host + table with
appropriate column set
✦ Sharding by time periods/column value
✦ Aggregation support (increment-only counter)

System Daws

Complex shardingbased on event rate and target host load
System Daws

Complex shardingbased on event rate and target host load
No complex typesDat events with lot’s of columns
System Daws

Complex shardingbased on event rate and target host load
Aggregation Zooeach event if analyzed and visualized with it’s own logic and code
No complex typesDat events with lot’s of columns
System Daws

Complex shardingbased on event rate and target host load
Aggregation Zooeach event if analyzed and visualized with it’s own logic and code
No complex typesDat events with lot’s of columns
System Daws
Lack of centralized event de?nition language for events

We need to go deeper...

Requirements
✦ Distributed processing
scalability, reliability, fault-tolerance
✦ Single codebase for events aggregation
write less code to collect stats, do more
✦ Formalized de?nition of events

Hadoop
Distributed storage (HDFS)
built-in replication
Resource Management and work control (YARN)
fault-tolerance, tasks restart
Support for programming (Map/Reduce)
Has built-in tools for SQL-like aggregations (Hive)

Event delivery to Hadoop
Applicationhosts(>2k)
AGGhosts
(2 per DC)
AggregationFramework(1 instance)

Event delivery to Hadoop
✦ Produce event on application host
✦ Write it into ?le on HDD
✦ Forward to several agg hosts (logrotate style
aggregation)
✦ Compress
✦ Upload to HDFS

Event de?nition

Event De?nition Language (EDL)
✦ Google Protobuf-based de?nition
✦ Formalized structure and aggregation instructions
✦ Code generation for producing events
✦ Glossary of all events

Event de?nition example

Let’s start aggregation!

Naive solution - Hive
✦ Popular engine for SQL operations over
data in Hadoop
✦ Our event’s aggregation instructions can
be exposed with SQL!
✦ Got stuck on 1d window and
1B of single-type event
(>15 minutes of processing)

Complex solution - Spark
✦ Map/Reduce Framework on top of Hadoop
✦ Several times faster than Hive on some operations
Key bene?ts for us:
✦ Possibility to program aggregation rules
✦ Processing event stream

System overview - Spark
✦ Spark Streaming
● Each N minutes – ?nd new ?les in HDFS directory
● For each event – perform aggregations
● Save intermediate result into HDDS

System overview - agg
✦ Badoo aggregation framework
● Find aggregation instructions for event
● Extract ?elds for aggregation
● Expand event
(GROUP BY GROUPING SETS SQL analog)

Aggregation overview
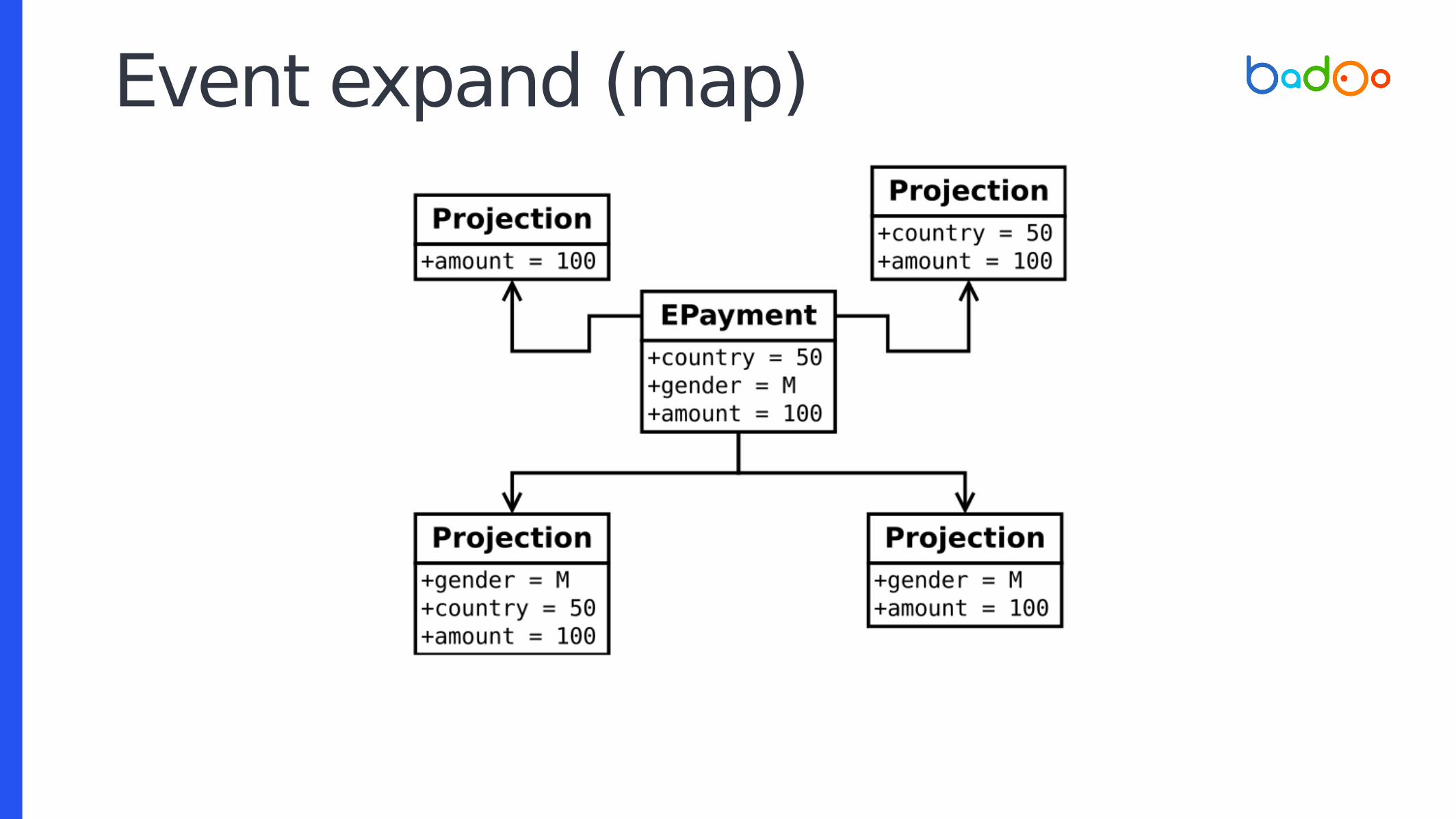
Event expand (map)

Event aggregation (reduce)

Code (Java API)
// API entrypoint – Spark contextcontext = new JavaStreamingContext("yarn-client", // using YARN cluster"Streaming", // name of the applicationDurations.seconds(30) // batch size
);
// monitor HDFS directory for new fileslines = context.textFileStream("hdfs://streaming/");
// parse each line into event// flatMap transforms 1 input row into [0,N] new elementsparsedEvents = lines.flatMap(new BadooParseFunction());

Code (Java API)
// API entrypoint – Spark contextcontext = new JavaStreamingContext("yarn-client", // using YARN cluster"Streaming", // name of the applicationDurations.seconds(30) // batch size
);
// monitor HDFS directory for new fileslines = context.textFileStream("hdfs://streaming/");
// parse each line into event// flatMap transforms 1 input row into [0,N] new elementsparsedEvents = lines.flatMap(new BadooParseFunction());

Code (Java API)
// API entrypoint – Spark contextcontext = new JavaStreamingContext("yarn-client", // using YARN cluster"Streaming", // name of the applicationDurations.seconds(30) // batch size
);
// monitor HDFS directory for new fileslines = context.textFileStream("hdfs://streaming/");
// parse each line into event// flatMap transforms 1 input row into [0,N] new elementsparsedEvents = lines.flatMap(new BadooParseFunction());

Code (Java API)
// each event has N cubes of aggregationexpandedEvents = parsedEvents.flatMapToPair(new ExpandFunction());
// aggregate data into 2 minutes intervalswindowSize = Durations.minutes(2);
windowAggregates = expandedEvents.reduceByKeyAndWindow(new EventReduceFunction(), windowSize, windowSize);

Code (Java API)
// each event has N cubes of aggregationexpandedEvents = parsedEvents.flatMapToPair(new ExpandFunction());
// aggregate data into 2 minutes intervalswindowSize = Durations.minutes(2);
windowAggregates = expandedEvents.reduceByKeyAndWindow(new EventReduceFunction(), windowSize, windowSize);

Code (Java API)
// save 2 minute data as serialized objectswindowAggregates.foreach((metric, time) -> { metric
.saveAsObjectFile("hdfs://output/" + formatTime(time));});
// start computation processcontext.start();context.awaitTermination();

Supported agg functions
✦ COUNT
✦ MIN/MAX/AVG
✦ SUM
✦ COUNT DISTINCT (using HyperLogLog)
✦ PERCENTILES (using QDigest)

Large windows aggregation
✦ 2016-10-05/
● 00 – 02/
● 02 – 04/
● …………
● 58 – 00/
1 hour

Large windows aggregation
1) Take N of 2 minutes aggregation results from HDFS
2) Perform reduceByKey operation
3) Save in format, suitable for timeseries DB, or
reporting (we use JSON)
4) Called “Divide and conquer principle”
5) Serialized agg results consumes 30-50 times less
memory than raw data

Maintenance

Recovery
✦ Re-start using Spark checkpoint mechanism
✦ If application goes down, it is restarted, using
metadata snapshot, stored in HDFS
✦ Metadata: list of processed ?les, time of last
computation

Monitoring
✦ Heartbeats, using separate stream processing
✦ Event rate is pre-de?ned and near-constant

Tools

Backstage - debug
✦ Tail/grep utility (web-socket servers on agg
hosts)

Backstage – SQL access
✦ Each event type has it’s own directory in HDFS
✦ A Hive table is de?ned over each event type
✦ Presto (Facebook Hadoop SQL engine) is used
for interactive querying events
✦ Hive is used for ETL batch jobs

Let’s summarize

Facts
✦ Event stream RPS: >190 K/sec
✦ Over 350 di=erent event types
✦ 133K metrics/per sec - aggregation result
✦ 1TB of GZIP’ed raw events a day
✦ 100 cores and 200 GB of memory for stream
processing needs

Summary
✦ Stream processing of heterogeneous events is
possible!
✦ But it need some coding – map/reduce
aggregation di=ers from SQL
✦ Near-realtime processing can be boosted with
“divide and conquer” principle

Links
✦ techblog.badoo.com
our archive of di=erent articles
✦ spark.apache.org
Apache Spark project homepage
✦ github.com/twitter/algebird
Twitter’s library with algebra, applicable for
map/reduce aggregations (HyperLogLog, QDigest)

Thank you!