playing with natural language ― in a friendly way
TRANSCRIPT

Playing with Natural Language― in a friendly way
ML/DM Monday2013/01/28

我是誰✓ 蔡家琦 (Tsai, Chia-Chi)
✓ ID : Rueshyna (Rues)
✓ 工作 : Ruby on Rails
✓ Machine Learning & Text Mining

什麼是NLP?

Natural language processing

Natural language processing
自然語言處理

Natural language processing
自然語言處理人類語言

ML/DM + 語言學

分析層次

文字
文法
語意
問題

讓電腦瞭解人類的語言

什麼是NLTK?

Natural Language ToolKit

Python 函式庫
Natural Language ToolKit

Python 函式庫快速處理 NLP 的問題
Natural Language ToolKit

Python 2 or 3?

Python3目前沒有標準版

但有開發版還在努力中...

Python2標準版



安裝pip install pyyaml nltk

Natural Language議題

斷句Today many historians think that only about twenty percent of the colonists supported Britain. Some colonists supported whichever side seemed to be winning.
-- from VOA

斷句Today many historians think that only about twenty percent of the colonists supported Britain. Some colonists supported whichever side seemed to be winning.
-- from VOA
•Today many historians think that only about twenty percent of the colonists supported Britain.
•Some colonists supported whichever side seemed to be winning.
利用“.”

斷句
Iowa-based political committee in 2007 and has grown larger since taking a leading role now against Mr. Hagel. “Postelection we have new battle lines being drawn with the president; he kicks it off with these nominations and it made sense for us.”
-- from New York Times

斷句Iowa-based political committee in 2007 and has grown larger since taking a leading role now against Mr. Hagel. “Postelection we have new battle lines being drawn with the president; he kicks it off with these nominations and it made sense for us.”
-- from New York Times利用“.”
•Iowa-based political committee in 2007 and has grown larger since taking a leading role now against Mr.
•Hagel. •“Postelection we have new battle lines being drawn with the president; he kicks it off with these nominations and it made sense for us.
•”

分詞(tokenization)
Today is a beautiful day

分詞(tokenization)
Today is a beautiful day
[Today] [is] [a] [beautiful] [day]利用空白

分詞(tokenization)
Today is a beautiful day利用空白
beautiful day.$50
for youths;
“Who knows?”
industry’s
[Today] [is] [a] [beautiful] [day]

分詞(tokenization)
Today is a beautiful day利用空白
beautiful day.$50
for youths;
“Who knows?”
industry’s?[Today] [is] [a] [beautiful] [day]

詞性(pos)Pierre Vinken , 61 years old , will join the board as a nonexecutive director Nov. 29 .

詞性(pos)
Pierre/NNPVinken/NNP61/CDyears/NNS,/, old/JJ will/MD
join/VBthe/DTboard/NNas/INa/DTnonexecutive/JJdirector/NN
Nov./NNP29/CD./.
Pierre Vinken , 61 years old , will join the board as a nonexecutive director Nov. 29 .
penn treebank tag

剖析樹 (parsed tree)
W.R. Grace holds three of Grace Energy's seven board seats .

剖析樹 (parsed tree)
W.R. Grace holds three of Grace Energy's seven board seats .

剖析樹 (parsed tree)
W.R. Grace holds three of Grace Energy's seven board seats .

剖析樹 (parsed tree)
W.R. Grace holds three of Grace Energy's seven board seats .

剖析樹 (parsed tree)
W.R. Grace holds three of Grace Energy's seven board seats .

Corpus✓ Treebank✓ 純文字、詞性標記、剖析樹
✓ Brown✓ 純文字、詞性標記、剖析樹
✓ 路透社(Reuters)✓ 純文字

Demo

#!/usr/bin/env python
import nltkfrom urllib import urlopenurl="http://www.voanews.com/articleprintview/1587223.html"html = urlopen(url).read()raw = nltk.clean_html(html)
#nltk.download(‘punkt’)sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)pos = nltk.pos_tag(token)
Demo1
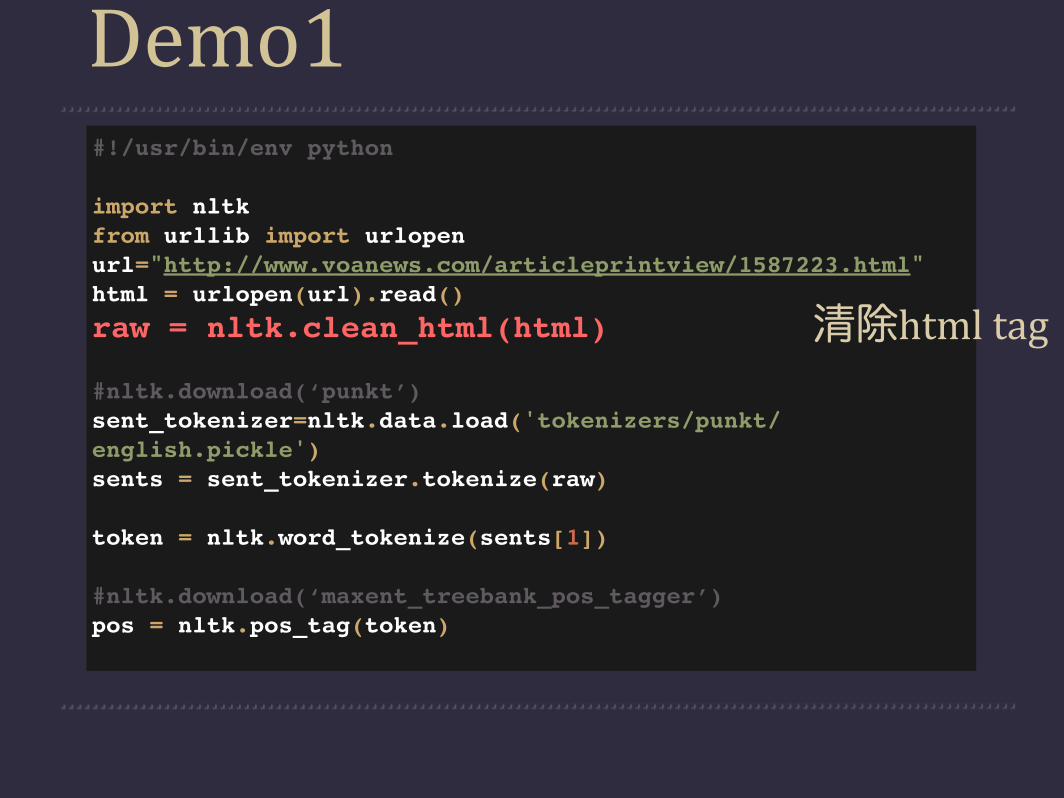
#!/usr/bin/env python
import nltkfrom urllib import urlopenurl="http://www.voanews.com/articleprintview/1587223.html"html = urlopen(url).read()
raw = nltk.clean_html(html)
#nltk.download(‘punkt’)sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)pos = nltk.pos_tag(token)
Demo1
清除html tag

#!/usr/bin/env python
import nltkfrom urllib import urlopenurl="http://www.voanews.com/articleprintview/1587223.html"html = urlopen(url).read()raw = nltk.clean_html(html)
#nltk.download(‘punkt’)sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')
sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)pos = nltk.pos_tag(token)
Demo1
斷句

#!/usr/bin/env python
import nltkfrom urllib import urlopenurl="http://www.voanews.com/articleprintview/1587223.html"html = urlopen(url).read()raw = nltk.clean_html(html)
#nltk.download(‘punkt’)sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)pos = nltk.pos_tag(token)
Demo1
分詞

#!/usr/bin/env python
import nltkfrom urllib import urlopenurl="http://www.voanews.com/articleprintview/1587223.html"html = urlopen(url).read()raw = nltk.clean_html(html)
#nltk.download(‘punkt’)sent_tokenizer=nltk.data.load('tokenizers/punkt/english.pickle')sents = sent_tokenizer.tokenize(raw)
token = nltk.word_tokenize(sents[1])
#nltk.download(‘maxent_treebank_pos_tagger’)
pos = nltk.pos_tag(token)
Demo1
詞性標記

#!/usr/bin/env python#nltk.download(‘treebank’)
import nltkfrom nltk.corpus import treebankfrom nltk.grammar import ContextFreeGrammar, Nonterminalfrom nltk.parse import ChartParser
productions = set( production for sent in treebank.parsed_sents()[0:9] for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])# print parsed_tree
Demo2

#!/usr/bin/env python#nltk.download(‘treebank’)
import nltkfrom nltk.corpus import treebankfrom nltk.grammar import ContextFreeGrammar, Nonterminalfrom nltk.parse import ChartParser
productions = set( production for sent in treebank.parsed_sents()[0:9] for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])# print parsed_tree
Demo2
treebank production

#!/usr/bin/env python#nltk.download(‘treebank’)
import nltkfrom nltk.corpus import treebankfrom nltk.grammar import ContextFreeGrammar, Nonterminalfrom nltk.parse import ChartParser
productions = set( production for sent in treebank.parsed_sents()[0:9] for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])# print parsed_tree
Demo2
encoder grammar

#!/usr/bin/env python#nltk.download(‘treebank’)
import nltkfrom nltk.corpus import treebankfrom nltk.grammar import ContextFreeGrammar, Nonterminalfrom nltk.parse import ChartParser
productions = set( production for sent in treebank.parsed_sents()[0:9] for production in sent.productions())
grammar = ContextFreeGrammar(Nonterminal('S'),productions)
parser = ChartParser(grammar)
parsed_tree = parser.parse(treebank.sents()[0])# print parsed_tree
Demo2
產生parser

#!/usr/bin/env python#nltk.download(‘reuters’)
import nltkfrom nltk.probability import FreqDistfrom nltk.probability import ConditionalFreqDistfrom nltk.corpus import reutersfrom nltk.corpus import brown
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))#fd.tabulate(10)#fd.plot()
cdf = ConditionalFreqDist((corpus, word) for corpus in ['reuters', 'brown'] for word in eval(corpus).words() if word in map(str,range(1900,1950,5)))#cdf.conditions()#cdf['brown']['1910']#cdf.tabulate()#cdf.plot()
Demo3

#!/usr/bin/env python#nltk.download(‘reuters’)
import nltkfrom nltk.probability import FreqDistfrom nltk.probability import ConditionalFreqDistfrom nltk.corpus import reutersfrom nltk.corpus import brown
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))#fd.tabulate(10)#fd.plot()
cdf = ConditionalFreqDist((corpus, word) for corpus in ['reuters', 'brown'] for word in eval(corpus).words() if word in map(str,range(1900,1950,5)))#cdf.conditions()#cdf['brown']['1910']#cdf.tabulate()#cdf.plot()
Demo3
詞頻統計

#!/usr/bin/env python#nltk.download(‘reuters’)
import nltkfrom nltk.probability import FreqDistfrom nltk.probability import ConditionalFreqDistfrom nltk.corpus import reutersfrom nltk.corpus import brown
fd = FreqDist(map(lambda w : w.lower(), brown.words()[0:50]))#fd.tabulate(10)#fd.plot()
cdf = ConditionalFreqDist((corpus, word) for corpus in ['reuters', 'brown'] for word in eval(corpus).words() if word in map(str,range(1900,1950,5)))#cdf.conditions()#cdf['brown']['1910']#cdf.tabulate()#cdf.plot()
Demo3
不同條件的詞頻統計(Conditions and Events)

Thanks!!