p2p storage system - university of california,...
TRANSCRIPT

P2P Storage System
Presented by:
Aakash Therani, Ankit Jasuja & Manish Shah

What is a P2P storage system?
•Peer-to-Peer(P2P) storage systems leverage the combinedstorage capacity of a network of storage devices(peers)contributed typically by autonomous end-users as acommon pool of storage space to store and share content.
•ApplicationsDistributed file systems
Content sharing
Back-up & archival storage
Peer data management systems

What is a P2P storage system?
•Peer-to-Peer(P2P) storage systems leverage the combinedstorage capacity of a network of storage devices(peers)contributed typically by autonomous end-users as acommon pool of storage space to store and share content.
•ApplicationsDistributed file systems
Content sharing
Back-up & archival storage
Peer data management systems

Designing P2P Storage Systems
Factors to keep in mind while designing p2p storage systems
•Persistent Storage
•Availability- in the presence of network partitions
•Durability- against failure and attack
•Security Issues
•Access control
•Protection against content pollution
•Transactions
•Concurrency Control
•Fault Tolerance

Cloud Storage v/s P2P Storage
•When data is stored at server clusters within the internet, this kindof data storage is referred to as cloud storage.
•Cloud Storage Products• Amazon S3- Amazon S3 (Simple Storage Service) is a web service that offers cloudstorage through a simple HTTP-based interface.
• Dropbox- Dropbox is a cloud storage provider and file synchronization tool usingthe Amazon S3 storage facility as a back-end.
•When relying on the members of a group storing each other’sdata, it is called peer-to-peer (p2p) storage.
•P2P Storage Products
• Wuala- Wuala [37] is a commercial, distributed storage service that allows users
to trade storage capacity in a P2P way

Classification of Storage Products
Products can be classified based on the types of storage needs:-
1) Backup- Using the service as a backup facility for files stored locally on a computer(which is part of the peer network). This may involve keeping track of versions of files,as they change over time.
2) File Synchronization- Keeping the same file tree that exists on a number ofdifferent computers in sync. When one file is changed on one computer, the copy ofthat file on the other computers is automatically updated. This type of functionalitymust deal with conflicts, e.g., in case the same file is changed on multiple computers atthe same time.
3) Distributed file system-The online storage capacity is used to implement adistributed file system. One or more computers access the storage in a manner that isvery similar to local file systems .
4) Content Sharing-Parts of the file tree stored online are used to share data withother people. By providing credentials to others, they can use the storage facility to readthe part of the tree they were granted access to .

OceanStore: An Architecture for Global-Scale Persistent Storage

OceanStore: A True Data Utility
•Utility model: consumers pay a monthly fee in exchange foraccess to persistent storage
•Highly available data from anywhere
•Automatic replication for disaster recovery
•Strong security
•Providers would buy and sell capacity among themselves formobile users
•Deep archival storage: use excess of storage space to ease datamanagement
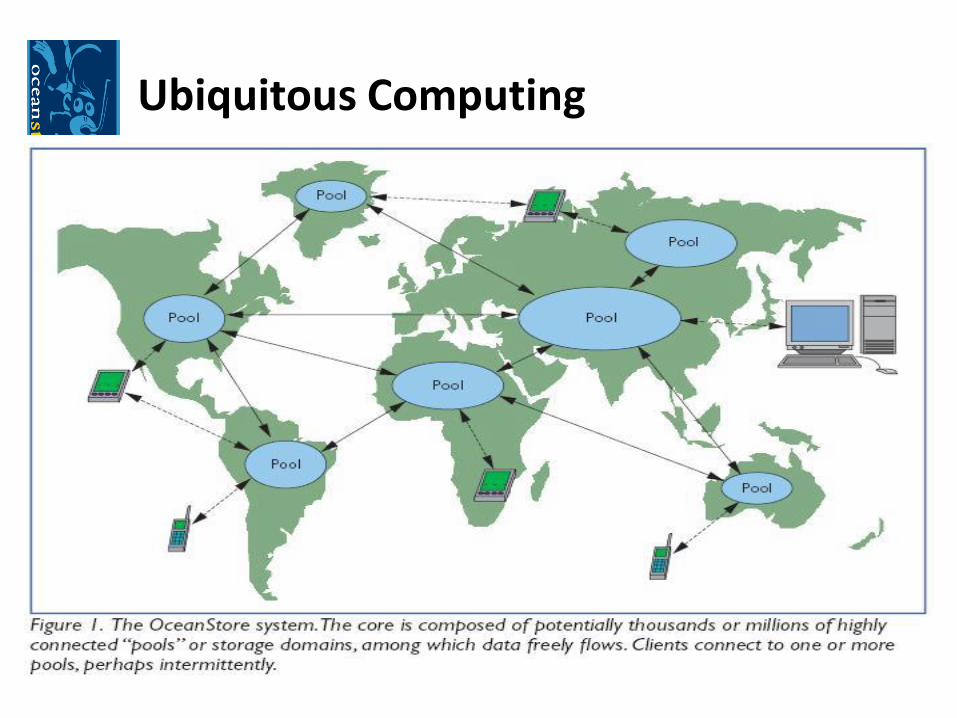
Ubiquitous Computing

Two Unique Goals
1) Ability to be constructed from an untrusted infrastructure
• Servers may crash without warning
• All information entering the infrastructure must be encrypted
• Servers participate in protocols for distributed consistencymanagement
2) Support for Nomadic Data
• Locality is of utmost importance
• Promiscuous Caching: Data can be cached anywhere, anytime
• Continuous introspective monitoring to manage caching &locality

System Overview
•Persistent object: The fundamental unit in OceanStore
•Each object is named by a Globally Unique Identifier (GUID)
•Objects are replicated and stored on multiple servers
•Floating replicas: Replicas are independent of the server
•Two mechanisms to locate a replica
1) A fast, probabilistic algorithm to find the object near the requesting machine
2) If (1) fails, then it is located through a slower, deterministic algorithm

Underlying Technologies
• Naming
• Access Control
• Data Location and Routing
• Data Update
• Deep Archival Storage
• Introspection

Naming
GUID: psuedo-random, fixed-length bit string
• Decentralized & resistant to attempts by adversaries
• Self-certifying path names
• GUID=hash(owner’s key, filename)
GUID of a server is a secure hash of its key
GUID of a data fragment is a secure hash of the data content

Access Control
OceanStore supports two primitive types of access controls
1) Reader Restriction
• Encrypt non-public data and distribute the key to userswith read access
• Problem: There is no way to make a reader forget whathe has read
2) Writer Restriction
• Through ACLs specified for each object by its owner
• Each user has a signing key, ACLs use that key forgranting access
Note: Reads are restricted at clients via key distribution, whilewrites are restricted at servers by ignoring unauthorized updates

Data Location and Routing
•Objects can reside on any of the OceanStore servers
•Use query routing to locate objects
•Every object is identified by one or more GUIDs
•Different replicas of the same object has the same GUID
•OceanStore messages are labeled with
•A destination GUID (built on top of IP)
•A random number
•A small predicate

Distributed Routing in OceanStore
•Routing is a two phase process.
•Data location and routing combined
•Advantage being we avoid multiple round trip time
•Routing itself is 2 tiered
•Fast probabilistic algorithm and slow reliable hierarchical method.

Bloom Filters
•Based on the idea of hill-climbing
•If a query cannot be satisfied by a server, local information is useto route the query to a likely neighbor
- Via a modified version of a Bloom filter

Attenuated Bloom Filters
•An attenuated Bloom filter of depth D is an array of D normalBloom filters
•ith Bloom filter is the union of all the Bloom filters for all of thenodes at a distance i
•One filter per network edge
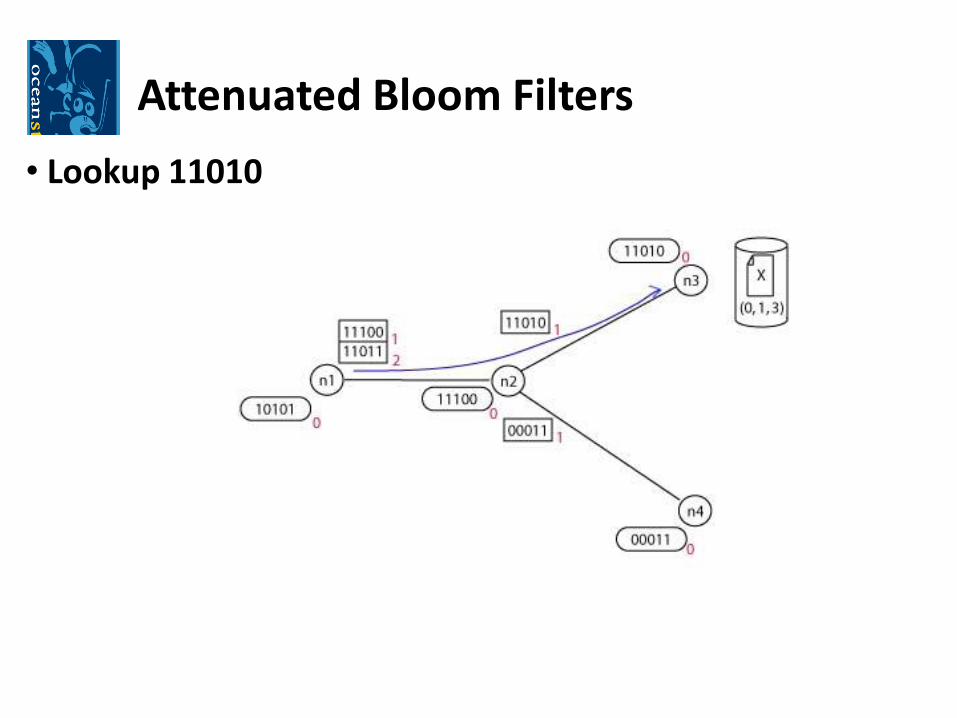
Attenuated Bloom Filters
• Lookup 11010

The Global Algorithm: Wide-Scale Distributed Data Location
• Plaxton’s randomized hierarchical distributed data structure
• Resolve one digit of the node id at a time
•Links form a series of random embedded trees, with each node as the root of one of these trees.
•Neighbor links can be used to route from anywhere to a given node
•If information about the GUID (such as its location) were stored at its root, then anyone could find this information simply by following neighbor links until they reached the root node for the GUID.
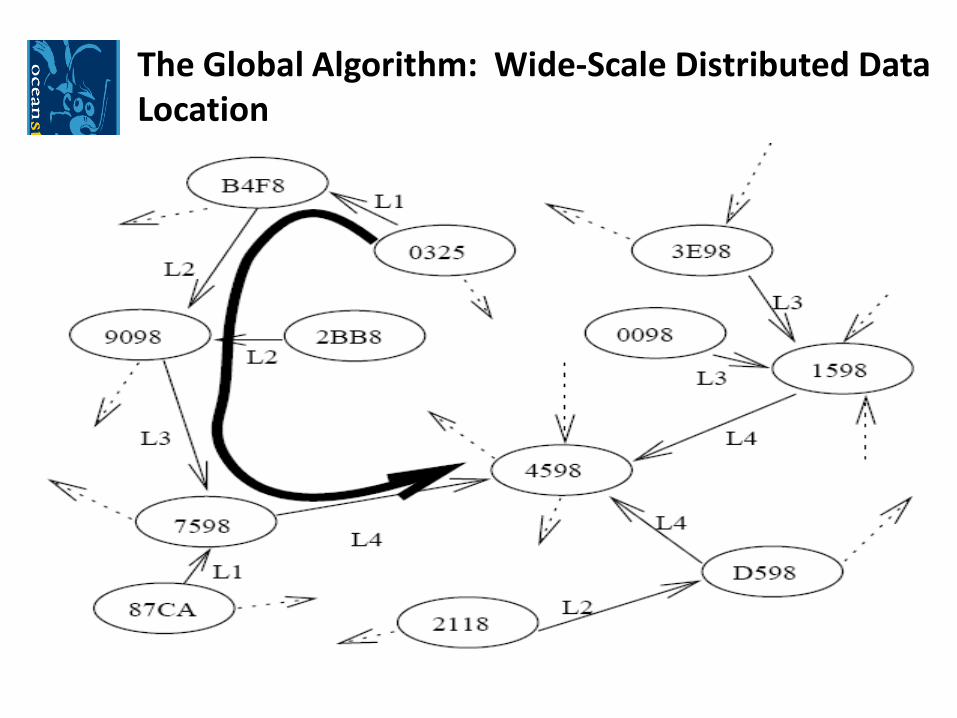
The Global Algorithm: Wide-Scale Distributed Data Location

Achieving Locality
•When a replica is placed somewhere in the system, its location is “published” to the routing infrastructure.
•The publishing process works its way to the object’s root and deposits a pointer at every hop along
the way.
•Each new replica only needs to traverse O(log(n)) hops to reach the root, where n is the number of the servers
•When someone searches for information, they climb the tree until they run into a pointer, after which they route directly to the object.

Achieving Fault Tolerance
•Avoid failures at roots
•Each root GUID is hashed with a small number of different salt values
•Make it difficult to target a single GUID for DoS attacks
•If failures are detected, just jump to any node to reach the root
•OceanStore continually monitors and repairs broken pointers

Advantages of Distributed Information
•Redundant paths to roots
•Scalable with a combination of probabilistic and global algorithms
•Easy to locate and recover failed components
•Plaxton links form a natural substrate for admission controls and multicasts

Achieving Maintenance-Free Operation
• Recursive node insertion and removal
• Replicated roots
• Use beacons to detect faults
• Time-to-live fields to update routes
• Second-chance algorithm to avoid false diagnoses of failed components
• Avoid the cost of recovering lost nodes
• Automatic reconstruction of data for failed servers

Update: Format and Semantics
• An update: a list of predicates associated with actions
• A set of predicates is evaluated in order
• The actions of the earliest true predicate are atomically applied
• Update is logged if it commits or aborts.
• Predicates: compare-version, compare-block, compare-size, search
• Actions: replace-block, insert-block, delete-block, append

Serializing Updates in an Untrusted Infrastructure
• Use a small primary tier of replicas to serialize updates
• Runs Byzantine agreement protocol
• Minimize communication
• Meanwhile, a secondary tier of replicas optimistically propagate updates among themselves
• Final ordering from primary tier is multicasted to secondary replicas
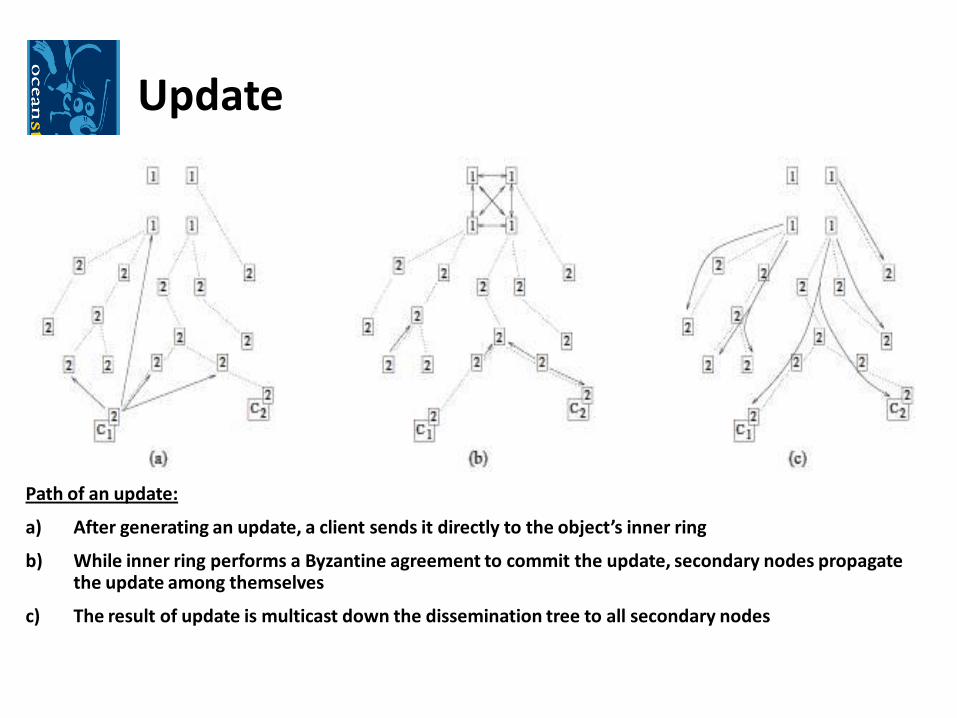
Update
Path of an update:
a) After generating an update, a client sends it directly to the object’s inner ring
b) While inner ring performs a Byzantine agreement to commit the update, secondary nodes propagate the update among themselves
c) The result of update is multicast down the dissemination tree to all secondary nodes
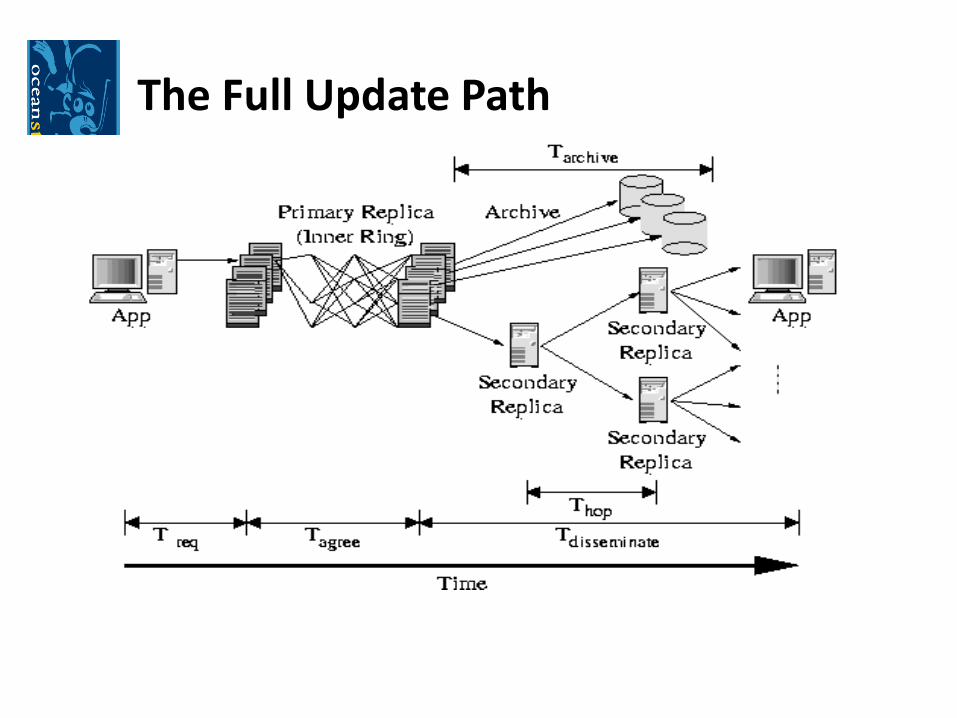
The Full Update Path

Update commitment
• Fault tolerance:
• Guarantees fault tolerance if less than one third of the servers in the inner ring is malicious
• Secondary nodes do not participate in the Byzantine protocol, but receive consistency information

A Direct Path to Clients and Archival Storage
•Updates flow directly from a client to the primary tier, where they are serialized and then multicast to the secondary servers down the dissemination tree
•Updates are tightly coupled with archival
•Archival fragments are generated at serialization time, signed, encoded and distributed with updates

Deep Archival Storage
• Data is fragmented
• Each fragment is an object
• Erasure coding is used to increase reliability
• Administrative domains are ranked by their reliability and trustworthiness
• Avoid locations with correlated failures
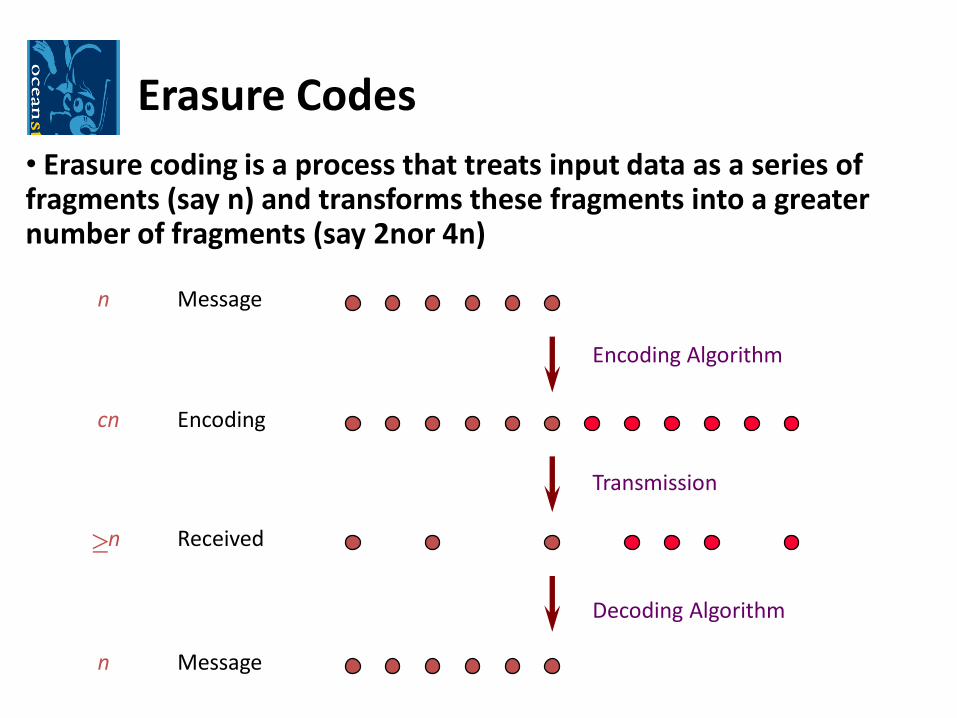
Erasure Codes
• Erasure coding is a process that treats input data as a series of fragments (say n) and transforms these fragments into a greater number of fragments (say 2nor 4n)
Message
Encoding
Received
Message
Encoding Algorithm
Decoding Algorithm
Transmission
n
cn
n
n
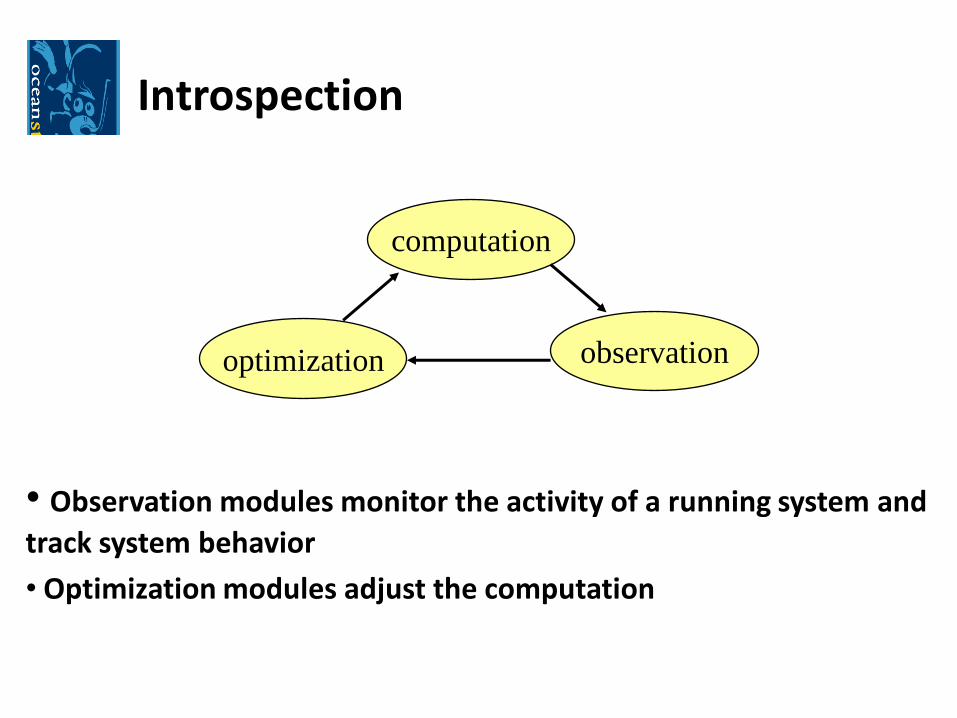
Introspection
• Observation modules monitor the activity of a running system and
track system behavior
• Optimization modules adjust the computation
computation
observationoptimization
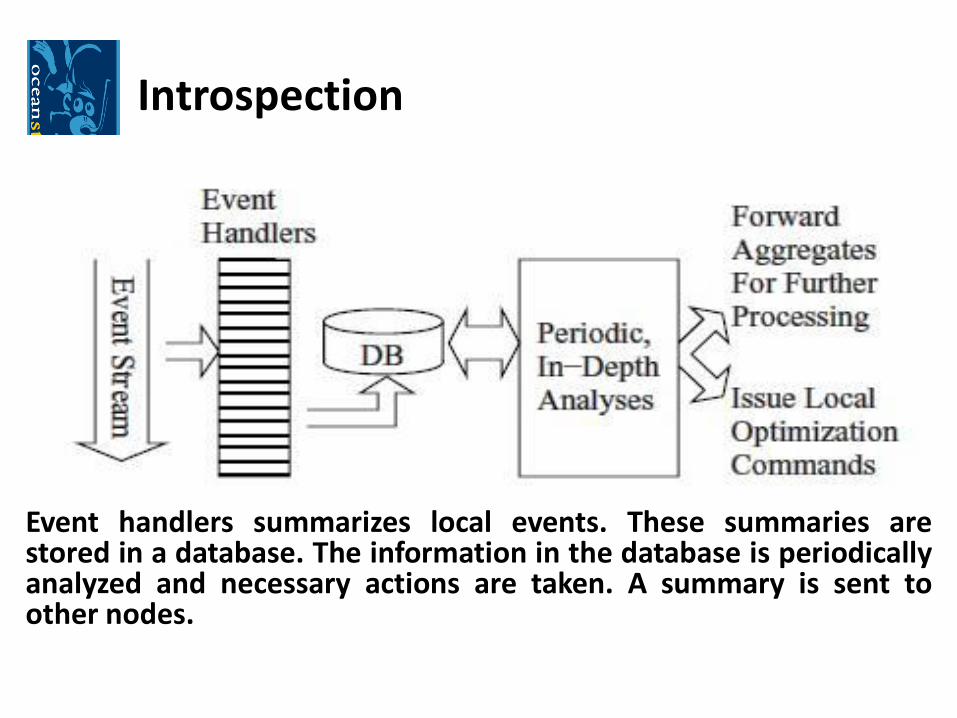
Introspection
Event handlers summarizes local events. These summaries arestored in a database. The information in the database is periodicallyanalyzed and necessary actions are taken. A summary is sent toother nodes.

Uses of Introspection
• Cluster recognition
• Identify related files
• Replica management
• Adjust replication factors
• Migrate floating replicas

Introspection
• If a replica becomes unavailable:
• Clients will receive service from a more distant replica
• This produces extra load on distant replicas
• Introspective mechanism detects this and new replicas are created
• Above actions provide fault tolerance and automatic repair

Applications
• Groupware applications
• Personal information management tools
• Contact lists
• Calendars
• Distributed design tools

Conclusion
Different from other systems :
• Utility model
• Untrusted infrastructure
• Truly nomadic data
• Use of introspection
• Prevention of denial of service attacks
• Rapid response to regional outages
• Analysis of access patterns

Dynamo: Amazon’s Highly Available Key-value Store

Motivation
Build a distributed storage system:
• Scale
• Simple: key-value
• Highly available
• Guarantee Service Level Agreements (SLA)
Service Level Agreements (SLA)
• Application can deliver its functionality in abounded time: Every dependency in the platform needs to deliver its functionality with even tighter bounds.
• Example: service guaranteeing that it will provide a response within 300ms for 99.9% of its requests for a peak client load of 500 requests per second.

Design Consideration
1) Sacrifice strong consistency for availability
2) Conflict resolution is executed during read instead of write, i.e. “always writeable”.
3) Other principles:
• Incremental scalability.
• Symmetry.
• Decentralization.
• Heterogeneity.

Partition Algorithm
• Consistent hashing: the output range of a hash function is treated as a fixed circular space or ring.
• Virtual Nodes: Each node can be responsible for more than one virtual node.
• Advantages of using virtual nodes
• If a node becomes unavailable the load handled by this node is evenly dispersed across the remaining available nodes.
• When a node becomes available again, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes.
• The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.

Data Versioning & Vector Clock
• A put() call may return to its caller before the update has been applied at all the replicas
• A get() call may return many versions of the same object.
• Challenge: an object having distinct version sub-histories, which the system will need to reconcile in the future.
• Solution: uses vector clocks in order to capture causality between different versions of the same object.
• A vector clock is a list of (node, counter) pairs.
• Every version of every object is associated with one vector clock.
• If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten.

Execution1) Read / Write request on a key
• Arrives at a node (coordinator)• Ideally the node responsible for the particular key• Else forwards request to the node responsible for that key and that node will become
the coordinator• The first N healthy and distinct nodes following the key position are considered for the
request• Quorums are used
• R – Read Quorum• W – Write Quorum• R+W>N
2) Writes• Requires generation of a new vector clock by coordinator• Coordinator writes locally• Forwards to N nodes, if W-1 respond then the write was successful
3) Reads• Forwards to N nodes, if R-1 respond then forwards to user• Only unique responses forwarded• User handles merging if multiple versions exist

FreeNet: A Distributed Anonymous Information Storage and Retrieval System

FreeNetIntroduction:
P2P network for anonymous publishing and retrieval of data
•Decentralized
•Nodes collaborate in storage and routing
•Data centric routing
•Adapts to demands
•Addresses privacy & availability concerns
Features:•Anonymity for producers and consumers•Deniability for information stores•Resistance to denial attacks•Efficient storing and routing•Does NOT provide
Permanent file storageLoad balancing Anonymity for general n/w usage
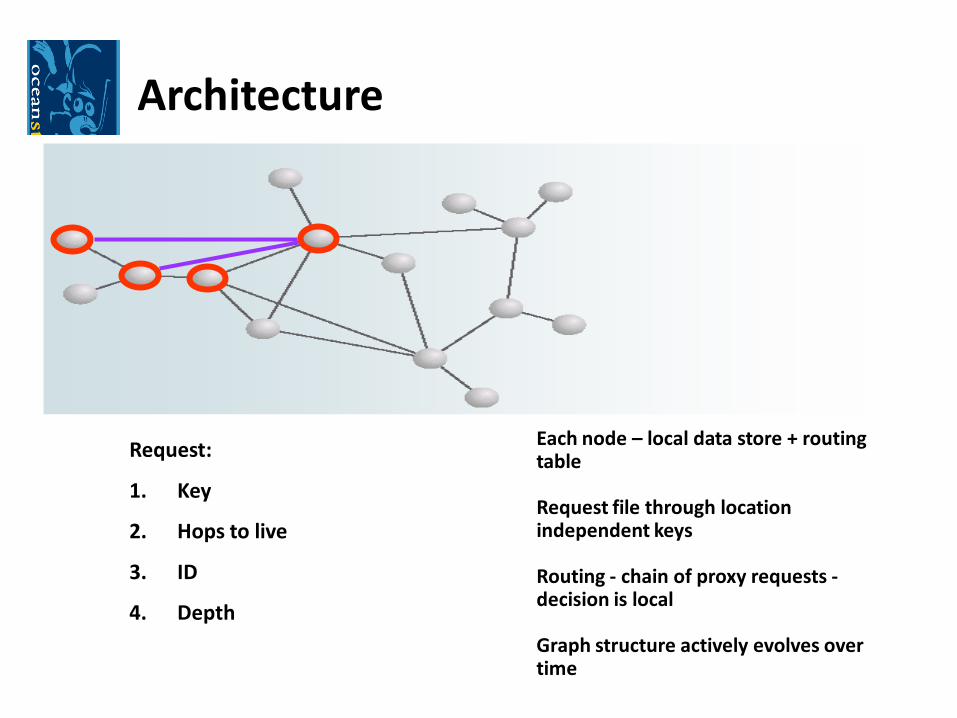
Architecture
Each node – local data store + routing table
Request file through location independent keys
Routing - chain of proxy requests -decision is local
Graph structure actively evolves over time
Request:
1. Key
2. Hops to live
3. ID
4. Depth

Keys and Searching
Problems with SSK - updating, versioning
Content Hash Keys (CHK)
Encrypted by a random encryption key
Publish CHK + decryption key
CHK + SSK easily updateable files
2 step process – publish file, publish pointer
Results in pointers to newer version
Older versions accessed thru CHK
Can be used for splitting files
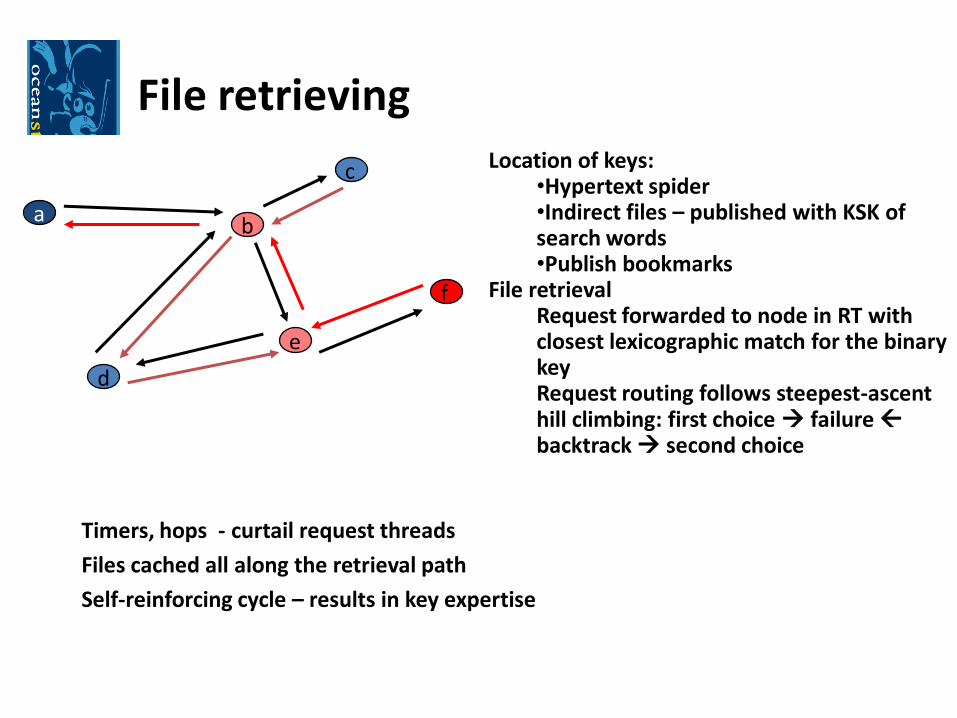
File retrievingLocation of keys:
•Hypertext spider •Indirect files – published with KSK of search words•Publish bookmarks
File retrievalRequest forwarded to node in RT with closest lexicographic match for the binary keyRequest routing follows steepest-ascent hill climbing: first choice failure backtrack second choice
c
a
d
b
e
f
Timers, hops - curtail request threads
Files cached all along the retrieval path
Self-reinforcing cycle – results in key expertise

Data Management
• Finite data stores - nodes resort to LRU
• Routing table entries linger after data eviction
• Outdated (or unpopular) docs disappear automatically
• Bipartite eviction – short term policy
New files replace most recent files
Prevents established files being evicted by attacks

Protocol and Security
PROTOCOL• Nodes with frequently changing IPs use ARKs
• Return address specified in requests – threat?
• Messages do not always terminate when hops-to-live reaches 1
• Depth is initialized by original requestor to arbitrarily small value
• Request state maintained at each node – timers – LRU
SECURITY
• File integrity - KSK vulnerable to dictionary attacks
• DOS attacks – Hash Cash to slow down
• Attempts to displace valid files are constrained by the insert procedure

Thank You..!!!