orthogonal persistenc ine a heterogeneous distributed … · into cluster tso encapsulate...
TRANSCRIPT

Orthogonal Persistence in a HeterogeneousDistributed Object-Oriented EnvironmentPEDRO SOUSA, ANDRE ZUQUETE, NUNO NEVES AND JOSE ALVES MARQUES
INESC—IST, Rua Alves Redol 9, 1000 Lisboa, Portugal
This paper describes the major issues in the design and implementation of orthogonal persistence in IK. Asingle and uniform programming paradigm is used to manipulate objects in a persistent and distributedenvironment. Object references can be freely passed during remote invocations or stored persistently. IKsupports orthogonal persistence with type inheritance. Objects are stored persistently when reachablefrom an Eternal Root, regardless of their type. For programmers, objects are created and manipulateduniformly, independently of the time they persist. Persistent objects are dynamically grouped at run-timeinto clusters to encapsulate fine-grain language level objects into coarser-grain entities. We present anovel approach to integrate object clustering, naming and garbage collection in persistent systems, andpresent experimental results.
Received April, 1994
1. INTRODUCTIONObject orientation has been explored in many projects tohandle distribution (Jul et al., 1988, Black and Artsy,1989) and persistence (Richardson and Carey, 1989,Chase et al., 1989) of fine-grained objects. We feel thesetwo dimensions should be addressed together providingdistribution and persistency of fine-grained objects in auniform model, where object references can be freelypassed in remote invocations or stored persistently.
IK (Marques and Guedes, 1989, Sousa et al., 1993) isan object-oriented platform which intends to simplify thedevelopment of distributed and persistent applications.IK follows the general architecture and model denned inthe ESPRIT project Comandos (Marques et al., 1988,Cahill et al., 1993). It generalizes the view of volatile andpersistent data by considering all objects to bemaintained by the system while being part of thetransitive closure of an Eternal Root. From theprogrammer's point of view, objects are created andmanipulated uniformly, independently of their type andthe length in time they persist. This paper highlights thekey points in the design and implementation oforthogonal persistence, and presents some results fromexperience.
IK is mainly targeted to cooperative applicationsexecuting in a local network comprising a few tens ofworkstations under a common administration policy.Applications are written in EC + + (Sequeira andMarques, 1991, Sousa et al., 1993), a languagesyntactically similar to C + + , but with some semanticextensions and restrictions. The programming environ-ment is based on a version of the ET + + (Gamma et al.,1988) library ported to our platform, providing aframework for application development. The currentversion of the system runs in user mode on a network ofheterogeneous UNIX machines—Suns (3 and SPARC-stations with SunOS/Solaris), Bull DPX/2 (B.O.S.) and
i386-based machines running the Mach 3.0 micro-kernel(Castro et al., 1993).
The next section overviews the major decisionsconcerning the persistence model and system design.Then, we present the related work in Section 3. InSection 4 we discuss the naming mechanisms used in IK.Clustering techniques are presented in Section 5 and inSection 6 we explain the implementation of the persistentstore. Garbage collection is addressed in Section 7.Finally, we draw our conclusions in Section 8.
2. MAJOR DECISIONS
2.1. The persistence model
We followed the concept of orthogonal persistence, asdescribed by Atkinson et al. 1983). Three principlesunderly the concept of orthogonal persistence:
• Persistence independence. Object persistence is inde-pendent of the way objects are created and manipu-lated. Object I/O is transparent to the programmer.
• Type orthogonality. Any object can be persistentregardless of its type, including code.
• Persistence identification. The mechanism to distin-guish persistent objects from non-persistent ones isindependent of the type system and computationalmodel.
In IK all objects are created and accessed in a singleand uniform manner. Persistence is a dynamic attributeof all objects, and orthogonal to their types. Objects aremaintained by the system while reachable (either directlyor indirectly) from an Eternal Root. Objects areautomatically discarded when no longer reachable fromthis root.
Programmers do not need to know which objects areactually persistent, nor when they are retrieved ordiscarded, nor how object data is actually stored.
THE COMPUTER JOURNAL, VOL. 37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

532 P . SOUSA et al.
Computing Node
Application
GRT 4
Operating System (Unix)
Distributed file
access (NFS)
Storage Node
ss Storage server
SS Partition
Local file access
Application
GRT NS
4 1
i Operating System (Unix)
Network
F I G U R E 1. Simplified architecture of IK.
Persistency is controlled simply by registering the roots of object graphs in the Eternal Root .
A fundamental aspect concerns with the visibility of object clustering policies at the programming level. One m a y argue abou t the flexibility of user defined grouping policies, where p rogrammers can specify if two objects should be placed in the same cluster or in different ones. W i t h or thogona l persistence, p rogrammers often do not k n o w exactly which objects will be stored, and consequent ly , in which cluster they should belong to. Therefore, we chose to hide the assignment of objects to clusters from the p rogrammer . The system first decides which objects go to which clusters and then where objects should be placed within the corresponding cluster.
2.2. System architecture
In our model every object can be referenced by every o ther object in the system uniformly. Such feature requires, at least at the architectural level, a global object space where objects are identified with global, un ique and long lived names.
Figure 1 shows a simplified d iagram of the architecture of IK . The persistent s tore 1 is supported by a set of Storage Servers (SS). A generic run-time library ( G R T ) l inked with each applicat ion cooperates with the persistent store to suppor t the global object space. We distinguish two types of nodes in the system: computing nodes and storage nodes . The former may have low availability, while the later must be highly available. Appl icat ions can execute in any node , but storage servers only run in storage nodes.
T h e G R T handles objects within a process address space. It includes, a m o n g others , a remote invocation mechanism, a garbage collector of volatile objects, a dynamic linker, an object clustering mechanism and an
Secondary storage in the Comandos architecture.
upcall mechanism to invoke methods in a language independent manner.
The platform also includes a N a m e Service (NS) to assign and de-assign user-defined names (readable character strings) to global names, thus allowing users to refer to stored object graph with friendly names. The collection of <user-name, global name> tuples constitute the Eternal Root .
2.3. Design issues
The first major issue was related to the support of the global object space defined in the architecture. A virtual address space shared by all applications could be used to implement such object space, as in Amber (Chase et al., 1989). W e decided otherwise because the 32 bit architectures of existing machines is clearly insufficient to support it and it would be difficult to implement it among heterogeneous machines. The object space in IK is independent of the virtual address space, and is supported by the persistent store together with the multiple and disjunct applications' address space.
A second major issue was related with the implementation of the persistence model. Although it does not distinguish between volatile and persistent objects, we wanted to explore their different characteristics. Volatile objects are expected to die young and to be known only within the scope of a single application. Persistent objects normally live much longer and are known by many entities in the system. Thus, volatile objects do not require a global name nor a persistent region, whereas, in principle, persistent objects require both. So, we decided to create every object as volatile, and promote them to persistent on demand. Object promotion occurs when a reference is inserted in another persistent object, or when it is sent to other applications during remote invocations.
We also wanted a global name space to allow each object to refer uniformly any other object. However, we
T H E C O M P U T E R J O U R N A L , V O L . 37, N o . 6 , 1 9 9 4
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

ORTHOGONAL PERSISTENCE IN A HETEROGENEOUS DISTRIBUTED OO ENVIRONMENT 533
do not want to waste global names with persistentobjects that are only being referenced by closely relatedobjects. In other words, we want to store objects in thepersistent store without having to assign a global nameto each one and still maintain the ability to refer objectsuniformly. This lead to a new approach in the definitionof clusters. The main idea is to use clusters as amechanism that encapsulates referenced objects withinreferencing ones. If encapsulated objects are onlyreferenced from the encapsulating ones, only the toplevel object requires a global name, and it is the onlyobject 'seen' by the persistent store.
Another important decision concerns with the objectlocation mechanism. Rather than keep track of objects,storage servers simply remember the applications towhich objects have been delivered. Once an applicationretrieves an object from a storage server, it becomes'responsible' for that object, i.e. it has to save the objectback to the persistent store, and proceed with incomingremote invocations to the object. This responsibility endswhen the object is stored back to the persistent store orwhen the application explicitly delegates the responsi-bility to another application, by notifying the persistentstore. Such an approach allows applications to chose thegranularity of object migration they are willing to handleand avoid third party dependencies imposed by thesystem.
3. RELATED WORK
Most persistent systems fail to offer orthogonalpersistence because they distinguish persistent objectson an allocation basis rather than on a reachability basis(Kim et al., 1989, Richardson and Carey, 1989, Andrewset al., 1990). In these systems objects are persistent ifcreated as such, either by being explicitly declared aspersistent or by being created in a default persistentregion. Therefore, programmers must worry aboutpersistent objects containing references to volatileobjects (dangling references). They also lose someflexibility because they cannot decide about the long-evity of objects that already exist. Another commonlimitation of persistent systems (often caused byallocation-based persistence) is to make persistence anexclusive property of some types. Even though pro-grammers can define their own persistent types, theyeither make all instances of that type persistent or noneat all.
Some systems do not distinguish between volatile andpersistent objects, and simply make the entire addressspace persistent, as in Casper (Vaughan et al., 1992).Here, the persistent store provides an abstraction similarto a stable distributed shared memory, with all clientssharing the same address space. We promote indepen-dence between applications' address space and thus theglobal object space must be independent of applications'address space.
Outside the Comandos project, GemStone (Bretl et al.,
1989) and Emerald (Black et al., 1986) are probably thesystems closer to IK, since they support fine-grainedobjects uniformly. GemStone provides the extensions toSmalltalk-80 (Goldberg and Robson, 1983) that areneeded in an Object-Oriented DBMS, i.e. support of amulti-user and persistent environment, data integrityand a large object space. However, the architecture isbased on a central entity that manages the whole objectspace, somewhat similar to Casper's architecture. Inthese architectures object space is defined as the set ofobjects known by the persistent store only. In IK, theobject space includes the objects in the persistent storeand all the other objects that exist within applicationaddress spaces. This provides an higher degree offlexibility, because applications can interchange refer-ences to objects not kept in the persistent store.
Even though Emerald (Black et al, 1986) does notsupport orthogonal persistence, it provides a uniformparadigm and was particularly important in the defini-tion of our computational model. A significant differenceis that, in Emerald, types are classified at compile timeand all objects of the same type are either global or local.In IK, objects are promoted individually to globalobjects at run-time. Emerald exploits the call-by-moveparameter passing mode. However, much of the work isleft to the Emerald compiler as it must decide whichobjects are passed using the call-by-move mode. Wewanted to keep the decisions generic and independent ofthe language.
Within the Comandos project, Guide (Baiter et al.,1991), Amadeus (Cahill et al., 1993) and IK share thesame model and general architecture; however, theydiffer both at the language and implementation levels.Guide followed an integrated approach in which a newlanguage and the run-time were developed together. IKand Amadeus chose C + + as main programminglanguage. However Amadeus add new keywords to thelanguage to express persistence and distribution, whereaswe decided to use C + + inheritance and retain theoriginal language syntax. In Guide, all objects areallocated in memory shared by all applications within anode and invocations can proceed locally. In thisapproach, the compiler must prevent applications fromdamage the entire set of shared objects, which is hard toachieve in the case of application crashes. Both IK andAmadeus chose to keep applications' address spaceprivate and forward invocations between applications.
In Guide, since all objects are created in sharedmemory, they all receive a global name and becomepersistent. In IK and Amadeus, global names areassigned to objects when their references are sentbetween applications. IK goes a step further by group-ing objects in such a way object graphs cross addressspaces under a single global name.
The current version of IK does not implement the fullComandos architecture, in particular it does not supportthe notion of Atomic objects (Mock et al., 1992) existingin the Amadeus implementation.
THE COMPUTER JOURNAL, VOL. 37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

534 P. SOUSA et al.
4. OBJECT NAMINGThis section addresses the different levels of objectnaming in IK. We first describe how global names arecreated and managed in the system, and then the defaultobject location mechanism. We then discuss how andwhen global names are converted to and from languagespecific object references, and finally we present theimplementation of the Eternal Root.
4.1. Global names
In centralized systems, global names can be generatedbased on local counters. In decentralized systems asolution is to assign a globally unique tag to each node,which can then be combined with locally generatedvalues to create globally unique identifiers (Needham,1989). The way local and global unique values arecombined must also be commonly agreed.
One could use existing communication addresses, suchas IP addresses, as globally unique tags for each node,and allow each and every node to generate global names.However, since in most situations global names are onlyuseful with some location information, we decided to usethe unique tag also as a hint to the location where theobject is most probably found, as in Appolo Domain(Leach et al., 1983). This does not bind the object to anyphysical location, it simply avoids the use of other hintswhen the one embedded in the global name is valid.
In a persistent environment, the storage server wherean object will eventually be stored is a good location hint,because it remains true until the object migrates toanother storage server2. This approach allow us to assignglobally unique tags only to storage servers, but itrequires application's GRT to request global names fromthe storage servers where objects will eventually bestored. In the current implementation, the choice of astorage server is an administrative issue and depends onthe user running the application. The advantages of sucharchitecture are twofold:
• The management and assignment of unique tags isgreatly simplified, since only well-known and stablestorage nodes are uniquely tagged.
• The tag in objects' global name is a valid location hintas long as objects do not migrate to another storageserver, which is expected to be the common case.
If an object migrates from the default server to anotherstorage server, a forward pointer is left behind. To allowphysical servers to be replaced or migrated within thenetwork, as often required by performance or adminis-trative reasons, unique tags are logical values whoseassociation with physical servers is variable over time.Bindings between unique tags and storage serveraddresses are kept in system files and globally accessiblethrough the UNIX NIS service.
In the current version of IK, global names are 64 bit
wide, and are formed by a 16 bit storage server tag (SSid)and a 48 bit local value. Local values are neverinterpreted outside the storage server where they weregenerated, allowing each server to implement differentalgorithms for name generation and object location.
4.2. Object Location
The location algorithm finds objects given their globalname. Objects can be found either locally, mapped in theaddress space of other applications or in the persistentstore. We wanted to solve efficiently the common cases,but also avoid the complexity of a complete decentralizedalgorithms as in (Fowler, 1985, Black and Artsy, 1989),and third party dependencies of centralized solutions. Todetermine the common cases, we trace early applicationsand IK releases and found out that:
• An object is mostly found where it was invoked before.• If a reference for an object was obtained as a
parameter in a cross-context invocation, then thelocation hint existing in the invoking GRT is mostprobably valid.
• If a reference was retrieved from the persistent store,then the object it refers to is probably also in thepersistent store, and not mapped in some application.
The first observation shows that object migration israre compared with object invocation and the GRTshould cache the location of remotely invoked objects.The second states that it is worthwhile to pass locationhints along with global names when these are sent asparameters of remote invocations. Finally, the thirdobservation shows that it is not worth to storepersistently location hints (together with global names)to applications where objects are currently mapped.
The location algorithm is a protocol between applica-tions' GRT and storage servers. First the GRT tries toaccess the object using the cached location hint. Locationhints are updated when new ones are received in incomingremote invocations. In the current implementation, ifdifferent hints exist for the same object, we merely chose thelast one received. We could improve hint hit ratio byassociating counters to them, as in (Fowler, 1985).
If the location hint does not exist, or it is obsolete, theGRT asks the storage server bound to the SSid tag in theglobal name for the object. In the common case, theobject is in the persistent store and the storage serverretrieves it, keeping a handle to the application thatreceived the object. If the object was already mapped byan application, the storage server returns the applica-tion's handle instead and the request is forward to it. Thesame procedure is carried out when a forwarding pointerto another storage server is found instead.
If the storage server has no knowledge of the object3, it
2 We are only concerned with long term validity. Hints may betemporarily invalid when objects are mapped in applications.
3 The most common situation happens when the global namecorresponds to an object that has never left the memory of theapplication where it was created, and therefore has never been stored inthe persistent storage.
T H E C O M P U T E R J O U R N A L , V O L . 3 7 , N o . 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

ORTHOGONAL PERSISTENCE IN A HETEROGENEOUS DISTRIBUTED OO ENVIRONMENT 535
forwards the request to the application that allocated itsglobal name. This requires storage servers to rememberthe global names allocated by each application. In thecurrent implementation this information is minimized byfurther dividing the 48 bit local value of the global nameinto a 32 bit application identifier {SSgn), and a 16 bitcounter (GRTgn) left for applications private use.Applications allocate global names in chunks of 216
names, maintaining a reasonable tradeoff betweenefficiency and usage of global name space.
Applications are free to migrate objects on their ownas long as they are able to locate them, because storageservers do not keep track of the current location ofobjects, but instead the applications that are responsiblefor them. If the responsible application crashes or doesnot answer within a bounded time, the system assumesthe current object state is lost and the last committedstate is available under warning. This state is either thestate the object had before being mapped in the faultyapplication or a newer one if it has been explicitlyflushed.
Although the location mechanism provided by thesystem to locate an object is centralized on a givenstorage server, it allows a potentially high level ofoptimizations because applications can actually chosethe granularity of object movements to be handled by thesystem. In particular, short-term migration of objects,such as the ones implied in call-by-move (Jul et al., 1988)parameter passing semantics, can be handled by theapplications, without system knowledge.
4.3. Object References
Unique identifiers are expensive entities and should beavoided in distributed systems. Whenever possible,cheaper object references should be used instead ofglobal names. The determination of the necessary andsufficient referencing mechanisms in the system is acritical step in its design. In our system we distinguishedthree different situations where specific referencemechanisms are useful: within a single address space, inthe persistent store and in cross-context invocationmessages.
Manipulation of language level references is part ofthe application's algorithm and has an immediate impactin its performance. Since these references only need to bevalid within the applications' address space, virtualpointers can be used to achieve an inexpensive referen-cing mechanism. In the persistent store it is important tokeep references as small as possible to reduce both theoverall size of stored objects and the cost of object I/O.Since objects are stored in clusters, references can besmall if their scope is restricted to the cluster where theyare stored. On the other hand, the size of referencespassed during remote invocation is not a critical factor,but they must be valid in the entire system.
In IK, language level references are virtual memorypointers to generic object headers. These headers are
used to represent local, unmapped or remotelymapped objects. If a language level reference is sentas parameter in a remote invocation, a global name isallocated to the object (if it did not have one already)and sent instead, along with a location hint. If areference is stored persistently it is swizzled into acluster-wide offset.
Pointer swizzling can be implemented in two basicways. Global identifiers are converted to pointers justbefore being used by the application {on demand) orimmediately after being mapped {on mapping). Conver-sion on demand has been used in several systems(Atkinson et al. 1983, Black et al., 1986, Richardsonand Carey, 1989), where a software check precedes eachpointer dereference. If the pointer is a global identifier,the object, or a surrogate, is mapped and the globalidentifier is replaced with the local pointer. In contrast,conversion on mapping ensures that only local pointersare seen by applications, avoiding the checks on pointerdereference. A major disadvantage of conversion onmapping is the need to follow pointers extensively duringpointer swizzling. This forces the complete mapping ofobject trees, leading to immediate and unnecessaryconversion of references. Such mapping and conversionwave can be bounded to the size of pages (Wilson, 1991),which may still lead to a significant amount ofunnecessary conversions, because pages are muchlarger than the fine-grained objects we support.
We wanted both to hide global names from applica-tion code and to minimize unnecessary conversionsbetween local and global references. Therefore, wedecided to convert references on a per object basis, thefirst time an object is invoked in a context. The strictencapsulation enforced by the model ensures that objectinstance variables are not seen by the application beforethe first invocation to the object. Therefore, by trappingthe object's first invocation, references can be swizzledand always appear to be in the local format toapplications code.
4.4. The eternal root
As mentioned in Section 2, the Eternal Root is acollection of <user-name, global name> tuples. Sincewe did not want to implement a name server, we use theunderlying file system as one. User-defined names arenames of the underlying file system. The associationbetween an user-defined name and a global name is alsomaintained in the file system, by creating an symboliclink from the user-defined name to a (unexisting) filewhose name derives from the global name. To laterretrieve a global name given the user-defined name, theNS looks for that name in a set of directories, either givenexplicitly by applications or defined by environmentvariables. The use of links rather than small databases tohold <user-name, global name> pairs allows users to seeobject names as normal file names in their workingdirectories.
THE COMPUTER JOURNAL, V O L . 3 7 , No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

536 P. SOUSA et al.
5. OBJECT CLUSTERING
In the Comandos model, all objects reachable from theEternal Root are maintained by the system. This doesnot mean that all objects reachable from the EternalRoot have a representation on the persistent store. Infact, reachability from the roots is computed only atsome points in time, normally when applications exit orwhen explicitly demanded.
Since we are dealing with a potentially large number offine-grained objects, clustering techniques are of greatimportance because they increase locality of reference byco-locating related objects, reducing the number of pagefaults and disk I/O. Such technics have been extensivelystudied in the scope of Object Oriented Data Bases(Tsangaris and Naughton, 1992), and they try to find thebest placement for objects within a cluster. However, theassignment of objects to clusters has been left forprogrammer. As explained in Sections 2.1 and 2.3, wedecided to assign objects to clusters at run-time and hideas much as possible object's graph under a single globalname.
The assignment of objects to clusters is done in such away that:
• Clusters have only a single globally known object,called head object.
• The body of the cluster is composed by all objects thatare only reachable through the head object, i.e. thereare no references outside the cluster for the clusterbody, only for its head object.
Therefore, objects belonging to the cluster body do notneed a global name because they are only referencedwithin the cluster and the whole cluster can be identifiedby the global name of its head object.
Since there are no references to the objects encapsu-lated in a cluster, no special addressing mechanism isrequired to locate these objects. With this approach, thesystem can benefit from the encapsulation provided bysuch clusters and consider the whole cluster body asprivate data of the head object. This organizationminimizes the number of globally known entities,allowing an entire object graph to enter or leave addressspaces with a single global name. It simplifies garbagecollection within clusters, because the head object is theonly root to be considered. It also scales down theproblem of global garbage collection since clusters arethe entities to be recycled.
In IK, objects are clustered when they leave theapplication's address space, either to be saved in thepersistent store or migrated to other applications. Acluster is mapped upon invocation of its head object.When that happens the GRT maps the whole cluster(using a memory-mapped file) and unfolds the headobject4: converts its data to the current machine format
4 Object unfolding is not actually done by the GRT. Instead it upcallsthe language specific run time to perform such operation.
and swizzles its references. The other objects will beunfolded only when invoked. This way we delay objectunfold until they are accessed and also defer touchingcluster pages until necessary.
5.1. Assigning objects to clusters
As mentioned before, at some point in time theapplication's GRT must detect the objects reachablefrom the Eternal Root among those existing in theiraddress space and save them in the persistent store. Ingeneral it is difficult to known exactly which objects arethese, because references to them may have been passedto other applications, and their usage is unknown. Thus,we take a conservative approach and consider that allobjects with a global name must be saved. The GRTkeeps track of all global names known by the applicationin a table called globally Known Object Table (KOT).
In a first phase we consider each object in the KOT asthe head of a new cluster. The graph of each head objectis traversed and visited objects are tagged with the markof the head object. The traversal does not propagate toobjects in the KOT, because they will be the startingpoint of new traversals. If an object is tagged withdifferent marks, meaning that it is reachable fromdifferent cluster heads, it is promoted to a new clusterhead: a global name is assigned to it and inserted in theKOT, to be traversed next. The entries in the KOT thatrefer to objects already unmapped or mapped remotelyare ignored.
After marking all objects reachable from the KOTwith a cluster head mark, objects with the same mark aregrouped together. The head object is inserted first, andthe others are appended to the cluster. Objects are foldedas they are being inserted into the cluster: references areswizzled to indexes in the corresponding cluster table andtheir data is translated into a well known format (XDR:eXtern Data Representation format). There are twotables in a cluster: one holding outgoing references(global names) and another holding offsets of objectswithin the cluster. Within the cluster object references areindexes of these tables.
Applying the algorithm to the example of Figure 2would result in four clusters. Objects A and B are globallyknown and are registered in the KOT. Objects C and Dcannot be hidden in A or B private subgraphs and arepromoted to cluster head objects. The figure alsoillustrates the cluster created to store object D and itsprivate subgraph.
If an object in the KOT is the head of a cluster mappedfrom the persistent store, than many objects of thatcluster may still be on disk, since objects are loaded ondemand. Thus, we must consider the pros and cons ofrebuilding the cluster from scratch or simply appendingnew objects to its end. Rebuilding the whole cluster mayrequire the loading of many objects, to save them backagain. On the other hand, adding new objects to thecluster is easy, since they can be placed at the end of it.
THE COMPUTER JOURNAL, VOL.37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

ORTHOGONAL PERSISTENCE IN A HETEROGENEOUS DISTRIBUTED O O ENVIRONMENT 537
Cluster D
Private Sub-Graph
F I G U R E 2. Definition of clusters from object graphs.
However, this does not recycle garbage objects in the cluster, wasting disk space, spreading live objects among garbage ones and reducing locality of reference. Scanning the whole cluster may prevent us from saving garbage, but requires us to read and write back the whole cluster. Currently the decision to rebuild a cluster is based on the percentage of objects that remain folded. If the number is higher than a threshold percentage, the traversal of the object graph stops whenever it reaches an object still folded. New objects are appended to the cluster, and old ones are saved in their original positions5. If most of the objects in the cluster are already unfolded, we simply scan the whole graph as when creating new clusters.
5.2. Arranging objects within clusters
There are two basic types of algorithms for ordering objects within clusters: trace-based and graph-based. Trace-based algorithms create a weighted graph of objects and references using application traces. Objects with (and related by) higher weights are placed together. Weights can be simply proportional to the number of invocations (Hudson and King, 1989), computed using Markov chains (Tsangaris and Naughton, 1992), or can be tunned using 'attraction' and 'repulsion' forces (Grourhant et al., 1987). The effort is paid back in disk intensive applications with fairly constant access patterns to the graph of objects in the persistent store, such as in Object Oriented Data Management Systems
The decision to append new objects to a cluster produces a positive feedback, since the number of garbage objects in the cluster tends to increase each time the cluster is stored without being traversed, therefore increasing the probability that the same decision is taken on future cluster storages. The cycle is broken when clusters are garbage collected, as explained in section 7.
(Tsangaris and Naughton, 1992). Graph-based algorithms traverse the object graph in a depth-first or breadth-first manner and group objects as they are reached. These algorithms are simpler, and tend to group objects poorly than trace-based, since they only see instantaneous objects relations rather than access patterns. In a system with orthogonal persistence each and every object can potentially be clustered and saved persistently. To use a trace-based approach, one must gather information about invocations on all objects. Since most objects are in fact recycled by the local garbage collector, most of the information gathered would be useless, and the whole process too costly. Therefore, we chose a graph-based approach with the descendants traversal ordering defined at compile time. Graphs are scanned using a depth-first algorithm because of its simplicity and because it showed the best behavior among several graph-based algorithms (Stamos, 1982).
5.3. Considerations on object flushing
IK offers object flushing for checkpoint purposes. Applications can flush objects and recover back the flushed state, by explicitly calling the GRT primitives. Upon termination of an application, objects are saved and the flushed state is overwritten. If the application crashes before saving the object, the flushed state becomes automatically available. The clustering algorithm used for object flushing differs from the one used for object saving, because:
• We expect flushing to be a much more frequent operation than recovering, since the first occurs in the due course of the application execution and the second occurs as the result of error recovery.
THE COMPUTER JOURNAL, VOL. 3 7 , N o . 6 , 1 9 9 4
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

538 P. SOUSA et al.
• Flushed objects remain mapped in the application,and therefore the image sent to disk remains invisibleto other applications.
Under these conditions, we decided to simplify theflushing and traverse only the graph of the object beingflushed, rather than traverse all objects in the KOT asbefore. The objects visited during the traversal that arenot in the KOT, are copied6 into the cluster body. If thegraph reaches an object in the KOT, it is recursivelyflushed. The control returns to the application when allclusters have been successfully flushed.
6. THE PERSISTENT STORE
This section describes the implementation of thepersistent store on top of the NFS distributed filesystem. There are two basic approaches to deal withobject storage: direct file access from contexts todatabases or plain files, as in the E language(Richardson and Cary, 1989), or interaction withservers responsible for managing centralized or distrib-uted databases, as in GemStone (Bretl et al., 1989) andOntos (Andrews et al., 1990). In IK we adopted a mixedmodel that provides direct access from applications toobject storage (files) and servers to control the aspectsrelated with protection and synchronization. Direct fileaccess optimizes data transfers between the persistentstore and the applications, and allows the use ofmemory-mapped files to lazily and efficiently loadcluster pages into applications7. The use of serversallow us to keep object protection independent from filesystem protections. As applications have direct access tothe object storage, we use a simple manipulation of fileprotections to give temporary access to applications. Bydefault, containers are readable and writable only by thestorage server. When an application wants to map acluster the server changes the protection and group of therespective container, giving read or read/write access tothe application. There is a well known group per user tobe used in these cases.
Next, we had to decide the way clusters are allocatedamong files, i.e. if there is one or many per each file. Sincewe did not know what would be the average size ofclusters, we decided to start with the simpler solution: useone file (container) per cluster (or class). Storage serversdo not impose any internal structure for containers, theyare simply data segments identified by a global name.Containers are protected files, with a name deriving fromtheir global names, and are stored in globally accessibledirectories (SS Partitions). Global access is achievedusing NFS. There is one storage server per SS Partition,and its status is maintained in log files.
Memory-mapped files are used to map clusters into
6 During the copy, references are swizzled, the data converted toXDR format and the object is tagged with the mark of the cluster headobject.
7 Also possible using servers as external pagers like in Mach basedoperating systems as in [Vaughan et al., 1992].
application's address space. However, to ensure theconsistency of the original image of clusters in disk, wemust prevent the operating system (e.g. Mach) to swapout memory-mapped containers to themselves during thenormal execution of applications. Therefore, modifiedblocks must be explicitly written using the usual UNIXI/O interface.
Normally, applications update the data of a containeroverwriting its contents. As this operation is not atomic,a cluster may become inconsistent if the applicationcrashes while saving the it. We decided to support alsoatomic update of individual clusters. Basically, we relayon the 'atomic' update of UNIX directories to updateclusters atomically. Before storing a cluster an applica-tion requests the storage server to create a new container.After updating its contents on disk, the applicationrequests the storage server to substitute the old containerby the new one. Future accesses to the cluster use the newcontainer.
7. GARBAGE COLLECTION
To simplify the problem of garbage collecting objects in apersistent and distributed system, we use three indepen-dent collectors: one to recycle objects within an applic-ation's address space, a second one to recycle objectswithin a cluster, and a third one to eliminate clusters thatare no longer reachable from the Eternal Root.
Local objects are recycled using a generation scaven-ging algorithm (Ferreira, 1991). In our environment, forlocal collections to proceed autonomously, it is alsonecessary to consider the entries KOT as local roots.When a cluster is mapped, clustered objects areconsidered to belong to the oldest generation.
Cluster-wide garbage collection recycles dead objectswithin each cluster. As was explained in Section 5, someclusters are stored without being fully traversed and maycontaing garbage. Since the cluster head is the onlyglobally known object in the cluster, clusters can begarbage collected autonomously: any object in thecluster not reachable from the head object is certainlygarbage. Clusters are garbage collected off-line, by aprocess running continuously on each storage node.Clusters are locked while are being recycled, forcingapplications to wait until the cluster is saved back.
Finally, a system-wide garbage collector deletesclusters in the persistent store that are no longerreachable from the Eternal Root. Currently, thiscollector is a straightforward implementation of themark-and-sweep algorithm. It is comprehensive, centra-lized, non-robust and the whole system must stop forgarbage collection. It is mentioned here because it had animportant role in the conclusions.
8. EVALUATION AND CONCLUSIONS
8.1. The persistence model
Orthogonal persistence provides an high level oftransparency, hiding from programmers all non-
THE COMPUTER JOURNAL, VOL. 37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

ORTHOGONAL PERSISTENCE IN A HETEROGENEOUS DISTRIBUTED OO ENVIRONMENT 539
relevant aspects. The usual question is to what extent canthis be done without sacrificing other attributes,particularly performance. In systems where data mustbe stored explicitly, programmers tend to store only thelong-term information (i.e. required to survive betweenapplication runs); no transient information is stored.With orthogonal persistence, selection is based onreachability criteria, and programmers must keep thisin mind during the design of their applications. Theyshould be aware that:
• Objects should contain either long-term or transientinformation.
• Objects with long-term information should not referto objects with transient information. They should bekept in different graphs, otherwise the system canunnecessarily save a potentially large amount oftransient information.
The first point is not an issue in well designedapplications. In fact, our measurements have shownthat only 2% of the instance data of objects containinglong-term information is transient. We are thus led to theconclusion that good application structuring tends toseparate persistent and transient information in differentobjects. The second point has no simple solution sincegraphs with long-term information often need to refer tographs with transient information. We use upcalls tosolve this problem. The GRT upcalls the beforeUnmapmethod on an object before traversing its references.Through the redefinition of this method, programmerscan clear the references to transient graphs, while long-term graphs are saved. Similarly, the GRT upcalls theafterMap after having unfolded an object, allowing theprogrammer to reinitialize the references to transientinformation.
A different source of problems, not directly related tothe model but rather to the implementation, occurs whenprogrammers use language level object references(virtual memory pointers) as numeric values, forexample, to implement hash functions. Since swizzlingglobal names into local references yields different valueson different application runs, the contents of a languagelevel reference changes between application runs. Thisprevents programmers from using language levelreferences for other purposes than pointer dereferenceand equality tests. Offering a generic primitive to returnthe global name of an object was not a feasible solutionbecause most objects never become globally known, andso no global name is assigned to them.
8.2. Object clustering
The evaluation of the clustering mechanism is based onthe applications built on top of IK. Some of theapplications are a cooperative calendar manager thatallows several users to schedule and negotiate meetings, acooperative graphical editor that supports multiple usersconcurrently, a browser and an inspector for application
'< 1 5
l i -n-n.l-.I64 256 1'K 4K ' 16K ' 64K ' 256K '
Cluster size (bytes)1M
I™6 clusters I I Dead dusters"!
FIGURE 3. Distribution of Cluster Population.
development and a tool for the analysis and design ofdistributed applications. The applications and theET + + library all together comprise 452 classes and6216 methods, a number we consider sufficient for aminimal evaluation of the platform. The average size ofobjects in clusters is approximately 42 bytes.
In Figure 3 we present the distribution of clusterpopulation according to their size. Bars represent thepercentage of clusters whose size is between twoconsecutive powers of 2. White bars refer to garbageclusters and dark ones refer to clusters reachable fromthe Eternal Root. Approximately 70% of alive clustersare larger than 4 Kbytes, most of them containingbetween 500 and 1000 of objects. They result fromapplications that handle information in a hierarchicalfashion, where nodes of the graph are not exportedoutside the graph. The remaining 30% of alive clustersconsist of very small graphs containing only a fewobjects. Typically, such clusters are generated whengraphs are traversed remotely. In fact, some of ourapplications do tend to fragment clusters completely,because they scan lists mapped remotely, forcing thesystem to promote each visited element to a cluster. This isprobably the main drawback of our clustering approach.However, such applications tend to perform poorly giventhe large number of cross-context invocations. Some ofthese applications have been changed to improveperformance, mainly by reducing the amount of cross-context invocations. They were redesigned to hold localreplicas of frequently accessed objects, being able tocompute with a reduced number of remote invocations.The reduction of clustering fragmentation was noticeable.
Analysis of the population of dead clusters hasrevealed that about 80% of the clusters are smallerthan IK bytes. They contain mainly transient informa-tion used during the communication between the variouscomponents of distributed applications. In most cases,such objects become globally known when references tothem are sent as parameters in remote invocations. Ourconservative approach, in considering that all referencessent to other contexts are reachable from the EternalRoot, promotes these objects to cluster heads and saves
THE COMPUTER JOURNAL, VOL.37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from
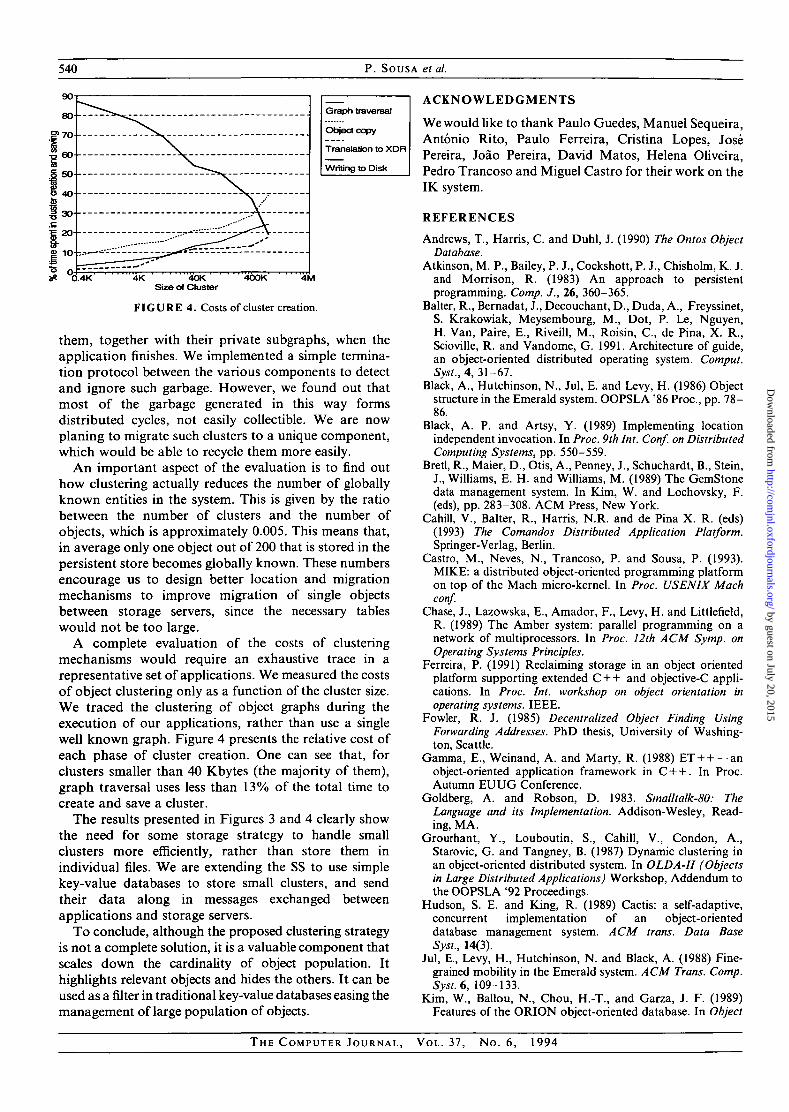
540 P. SOUSA et al.
Graph traversal
Object copy
Translation to XDR
Writing to Disk
4K 4OKSize of Cluster
4O0K 4M
FIGURE 4. Costs of cluster creation.
them, together with their private subgraphs, when theapplication finishes. We implemented a simple termina-tion protocol between the various components to detectand ignore such garbage. However, we found out thatmost of the garbage generated in this way formsdistributed cycles, not easily collectible. We are nowplaning to migrate such clusters to a unique component,which would be able to recycle them more easily.
An important aspect of the evaluation is to find outhow clustering actually reduces the number of globallyknown entities in the system. This is given by the ratiobetween the number of clusters and the number ofobjects, which is approximately 0.005. This means that,in average only one object out of 200 that is stored in thepersistent store becomes globally known. These numbersencourage us to design better location and migrationmechanisms to improve migration of single objectsbetween storage servers, since the necessary tableswould not be too large.
A complete evaluation of the costs of clusteringmechanisms would require an exhaustive trace in arepresentative set of applications. We measured the costsof object clustering only as a function of the cluster size.We traced the clustering of object graphs during theexecution of our applications, rather than use a singlewell known graph. Figure 4 presents the relative cost ofeach phase of cluster creation. One can see that, forclusters smaller than 40 Kbytes (the majority of them),graph traversal uses less than 13% of the total time tocreate and save a cluster.
The results presented in Figures 3 and 4 clearly showthe need for some storage strategy to handle smallclusters more efficiently, rather than store them inindividual files. We are extending the SS to use simplekey-value databases to store small clusters, and sendtheir data along in messages exchanged betweenapplications and storage servers.
To conclude, although the proposed clustering strategyis not a complete solution, it is a valuable component thatscales down the cardinality of object population. Ithighlights relevant objects and hides the others. It can beused as a filter in traditional key-value databases easing themanagement of large population of objects.
ACKNOWLEDGMENTS
We would like to thank Paulo Guedes, Manuel Sequeira,Antonio Rito, Paulo Ferreira, Cristina Lopes, JosePereira, Joao Pereira, David Matos, Helena Oliveira,Pedro Trancoso and Miguel Castro for their work on theIK system.
REFERENCES
Andrews, T., Harris, C. and Duhl, J. (1990) The Ontos ObjectDatabase.
Atkinson, M. P., Bailey, P. J., Cockshott, P. J., Chisholm, K. J.and Morrison, R. (1983) An approach to persistentprogramming. Comp. J., 26, 360-365.
Baiter, R., Bernadat, J., Decouchant, D., Duda, A., Freyssinet,S. Krakowiak, Meysembourg, M., Dot, P. Le, Nguyen,H. Van, Paire, E., Riveill, M., Roisin, C, de Pina, X. R.,Scioville, R. and Vandome, G. 1991. Architecture of guide,an object-oriented distributed operating system. Comput.Syst., 4, 31-67.
Black, A., Hutchinson, N., Jul, E. and Levy, H. (1986) Objectstructure in the Emerald system. OOPSLA '86 Proa, pp. 78-86.
Black, A. P. and Artsy, Y. (1989) Implementing locationindependent invocation. In Proc. 9th Int. Conf. on DistributedComputing Systems, pp. 550—559.
Bretl, R., Maier, D., Otis, A., Penney, J., Schuchardt, B., Stein,J., Williams, E. H. and Williams, M. (1989) The GemStonedata management system. In Kim, W. and Lochovsky, F.(eds), pp. 283-308. ACM Press, New York.
Cahill, V., Baiter, R., Harris, N.R. and de Pina X. R. (eds)(1993) The Comandos Distributed Application Platform.Springer-Verlag, Berlin.
Castro, M., Neves, N., Trancoso, P. and Sousa, P. (1993).MIKE: a distributed object-oriented programming platformon top of the Mach micro-kernel. In Proc. USENIX Machconf.
Chase, J., Lazowska, E., Amador, F., Levy, H. and Littlefield,R. (1989) The Amber system: parallel programming on anetwork of multiprocessors. In Proc. 12th ACM Symp. onOperating Systems Principles.
Ferreira, P. (1991) Reclaiming storage in an object orientedplatform supporting extended C + + and objective-C appli-cations. In Proc. Int. workshop on object orientation inoperating systems. IEEE.
Fowler, R. J. (1985) Decentralized Object Finding UsingForwarding Addresses. PhD thesis, University of Washing-ton, Seattle.
Gamma, E., Weinand, A. and Marty, R. (1988) ET++—anobject-oriented application framework in C++. In Proc.Autumn EUUG Conference.
Goldberg, A. and Robson, D. 1983. Smalltalk-80: TheLanguage and its Implementation. Addison-Wesley, Read-ing, MA.
Grourhant, Y., Louboutin, S., Cahill, V., Condon, A.,Starovic, G. and Tangney, B. (1987) Dynamic clustering inan object-oriented distributed system. In OLDA-II (Objectsin Large Distributed Applications) Workshop, Addendum tothe OOPSLA '92 Proceedings.
Hudson, S. E. and King, R. (1989) Cactis: a self-adaptive,concurrent implementation of an object-orienteddatabase management system. ACM trans. Data BaseSyst., 14(3).
Jul, E., Levy, H., Hutchinson, N. and Black, A. (1988) Fine-grained mobility in the Emerald system. ACM Trans. Comp.Syst. 6, 109-133.
Kim, W., Ballou, N., Chou, H.-T., and Garza, J. F. (1989)Features of the ORION object-oriented database. In Object
THE COMPUTER JOURNAL, VOL. 37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from

ORTHOGONAL PERSISTENCE IN A HETEROGENEOUS DISTRIBUTED OO ENVIRONMENT 541
Oriented Concepts, Databases, and Applications. ACM Press,New York.
Leach, P. J., Levine, P. H., Douros, B. P., Elton, J. A. H.,Nelson, D. L. and Stumpf, B. L. (1983) The arquitecture ofan integrated local network. IEEE J. Selected AreasCommun., 1(5), 00-00.
Marques, J. A. and Guedes, P. (1989) Extending the operatingsystem to support and object-oriented environment. InOOPSLA 89.
Marques, J. A., Baiter, R., Cahill, V., Guedes, P., Harris, N.,Horn, C, Krakoviak, S., Kramer, A., Slattery, J. andVandome, G. (1988) Implementing the COMANDOSArchitecture. In Proc. ESPRIT technical week, Brussels,Belgium.
Mock, M., Kroeger, R. and Cahill, V. (1992) Implementingatomic objects with the RelaX transaction facility. Comput.Syst., 5, 259-304.
Needham, R. M. (1989) Names. In: Distributed Systems.Mullender, S. (ed), ACM Press, New York.
Richardson, J. E. and Carey, M. J. (1989) Persistence in the E
language: issues and implementation. Software—Practiceand Experience, 19, 1115-1150.
Sequeira, M. and Marques, J. A. (1991) Can C + + be used forprogramming distributed and persistent objects? In Proc. Int.Workshop on Object Orientation in Operating Systems. IEEE.
Sousa, P., Sequeira, M., Ziiquete, A., Ferreira, P., Lopes, C ,Pereira, J., Guedes, P. and Marques, J. A. (1993) Distributionand persistence in the IK platform: overview and evaluation.USENIX Comput. Syst., 6, 391-424.
Stamos, J. W. (1982) A Large Object-Oriented Virtual Memory:Grouping Strategies, Measurements, and Performance. Tech-nical Report. SCG-82-2. Xerox PARC, Palo Alto, CA.
Tsangaris, M. M., & Naughton, J. F. (1992) On Performance ofObject Clustering Techniques. Technical report 1090-1992,University of Wisconsin-Madison, WI.
Vaughan, F., Basso, T., Dearie, A., Marlin, C. and Barter, C.(1992) Casper: a cached architecture supporting persistence.Comput. Syst., 5, 337-359.
Wilson, P. R. (1991) Operating system support for smallobjects. In Proc. of Int. Workshop on Object Orientation inOperating Systems.
THE COMPUTER JOURNAL, VOL. 37, No. 6, 1994
by guest on July 20, 2015http://com
jnl.oxfordjournals.org/D
ownloaded from