object detection using deep cnns trained on … application. the design of refrigerator remains same...
TRANSCRIPT

Object Detection Using Deep CNNs Trained on Synthetic Images
P. S. RajpuraDepartment of Electrical Engineering
Indian Institute of TechnologyGandhinagar, Gujarat, India 382355
Email:[email protected]
H. BojinovInnit Inc.
Redwood City, CA 94063,USAEmail:[email protected]
R. S. HegdeDepartment of Electrical Engineering
Indian Institute of TechnologyGandhinagar, Gujarat, India 382355
Email:[email protected]
Abstract—The need for large annotated image datasets fortraining Convolutional Neural Networks (CNNs) has been asignificant impediment for their adoption in computer visionapplications. We show that with transfer learning an effectiveobject detector can be trained almost entirely on syntheticallyrendered datasets. We apply this strategy for detecting pack-aged food products clustered in refrigerator scenes. Our CNNtrained only with 4000 synthetic images achieves mean averageprecision (mAP) of 24 on a test set with 55 distinct products asobjects of interest and 17 distractor objects. A further increaseof 12% in the mAP is obtained by adding only 400 real imagesto these 4000 synthetic images in the training set. A high degreeof photorealism in the synthetic images was not essential inachieving this performance. We analyze factors like trainingdata set size and 3D model dictionary size for their influenceon detection performance. Additionally, training strategies likefine-tuning with selected layers and early stopping which affecttransfer learning from synthetic scenes to real scenes areexplored. Training CNNs with synthetic datasets is a novelapplication of high-performance computing and a promisingapproach for object detection applications in domains wherethere is a dearth of large annotated image data.
Keywords-Convolutional Neural Networks (CNN); Deeplearning; Transfer learning; Synthetic datasets; Object Detec-tion; 3D Rendering
I. INTRODUCTION
The field of Computer Vision has reached new heightsover the last few years. In the past, methods like DPMs [1],SIFT [2] and HOG [3] were used for feature extraction,and linear classifiers were used for making predictions.Other methods [4] used correspondences between templateimages and the scene image. Later works focused on class-independent object proposals [5] using segmentation andclassification using hand crafted features. Today methodsbased on Deep Neural Networks (DNNs) have achievedstate-of-the-art performance on image classification, objectdetection, and segmentation [6], [7]. DNNs been success-fully deployed in numerous domains [6], [7]. ConvolutionalNeural Networks (CNNs), specifically, have fulfilled thedemand for a robust feature extractor that can generalizeto new types of scenes. CNNs were initially deployed forimage classification [6] and later extended to object detec-tion [8]. The R-CNN approach [8] used object proposalsand features from a pre-trained object classifier. Recently
published works like Faster R-CNN [9] and SSD [10] learnobject proposals and object classification in an end-to-endfashion.
The availability of large sets of training images has beena prerequisite for successfully training CNNs [6]. Manualannotation of images for object detection, however, is atime-consuming and mechanical task; what is more, in someapplications the cost of capturing images with sufficientvariety is prohibitive. In fact the largest image datasets arebuilt upon only a few categories for which images can befeasibly curated (20 categories in PASCAL VOC [11], 80in COCO [12], and 200 in ImageNet [13]). In applicationswhere a large set of intra-category objects need to bedetected the option of supervised learning with CNNs is eventougher as it is practically impossible to collect sufficienttraining material.
There have been solutions proposed to reduce annotationefforts by employing transfer learning or simulating scenesto generate large image sets. The research community hasproposed multiple approaches for the problem of adaptingvision-based models trained in one domain to a differentdomain [14]–[18]. Examples include: re-training a modelin the target domain [19]; adapting the weights of a pre-trained model [20]; using pre-trained weights for featureextraction [21]; and, learning common features betweendomains [22].
Attempts to use synthetic data for training CNNs to adaptin real scenarios have been made in the past. Peng et. al.used available 3D CAD models, both with and withouttexture, and rendered images after varying the projectionsand orientations of the objects, evaluating on 20 categories inthe PASCAL VOC 2007 data set [23]. The CNN employedfor their approach used a general object proposal module [8]which operated independently from the fine-tuned classifiernetwork. In contrast, Su and coworkers [24] used the ren-dered 2D images from 3D on varying backgrounds for poseestimation. Their work also uses an object proposal stageand limits the objects of interest to a few specific categoriesfrom the PASCAL VOC data set. Georgakis and cowork-ers [25] propose to learn object detection with synthetic datagenerated by object instances being superimposed into realscenes at different positions, scales, and illumination. They
arX
iv:1
706.
0678
2v2
[cs
.CV
] 1
8 Se
p 20
17

Figure 1. Overview of our approach to train object detectors for real images based on synthetic rendered images.
propose the use of existing object recognition data sets suchas BigBird [26] rather than using 3D CAD models. Theylimit their synthesized scenes to low-occlusion scenarioswith 11 products in GMU-Kitchens data set. Gupta et. al.generate a synthetic training set by taking advantage of scenesegmentation to create synthetic training examples, howeverthe goal is text localization instead of object detection [21].Tobin et. al. perform domain randomization with low-fidelityrendered images from 3D meshes, however their objectiveis to locate simpler polygon-shaped objects restricted to atable top in world coordinates [27]. In [28], [29], the Unitygame engine is used to generate RGB-D rendered imagesand semantic labels for outdoor and indoor scenes. Theyshow that by using photo-realistic rendered images the effortfor annotation can be significantly reduced. They combinesynthetic and real data to train models for semantic segmen-tation, however the network requires depth map informationfor semantic segmentation.
None of the existing approaches to training with syntheticdata consider the use of synthetic image datasets for traininga general object detector in a scenario where high intra-classvariance is present along with high clutter or occlusion. Ad-ditionally, while previous works have compared the perfor-mance using benchmark datasets, the study of cues or hyper-parameters involved in transfer learning has not receivedsufficient attention. We propose to detect object candidatesin the scene with large intra-class variance compared to anapproach of detecting objects for few specific categories. Weare especially interested in synthetic datasets which do notrequire extensive effort towards achieving photorealism. Inthis work, we simulate scenes using 3D models and use therendered RGB images to train a CNN-based object detector.We automate the process of rendering and annotating the2D images with sufficient diversity to train the CNN end-to-end and use it for object detection in real scenes. Ourexperiments also explore the effects of different parameterslike data set size and 3D model repository size. We alsoexplore the effects of training strategies like fine-tuningselective layers and early stopping [30] on transfer learning
from simulation to reality. The rest of this paper is organizedas follows: our methodology is described in section II,followed by the results we obtain reported in section III,finally concluding the paper in section IV.
II. METHOD
Given a RGB image captured inside a refrigerator, ourgoal is to predict a bound-box and the object class categoryfor each object of interest. In addition, there are few objectsin the scene that need to be neglected. Our approach isto train a deep CNN with synthetic rendered images fromavailable 3D models. Overview of the approach is shown inFigure 1. Our work can be divided into two major partsnamely synthetic image rendering from 3D models andtransfer learning by fine-tuning the deep neural network withsynthetic images.
A. Synthetic Generation of Images from 3D Models
We use an open source 3D graphics software namedBlender. Blender-Python APIs facilitate to load 3D modelsand automate the scene rendering. We use Cycles RenderEngine available with Blender since it supports ray-tracingto render synthetic images. Since all the required annotationdata is available, we use the KITTI [31] format with bound-box co-ordinates, truncation state and occlusion state foreach object in the image.
Real world images have lot of information embed-ded about the environment, illumination, surface materials,shapes etc. Since the trained model, at test time must beable to generalize to the real world images, we take intoconsideration the following aspects during generation ofeach scenario:
• Number of objects• Shape, Texture, and Materials of the objects• Texture and Materials of the refrigerator• Packing pattern of the objects• Position, Orientation of camera• Illumination via light sources

Figure 2. Overview of the training dataset. a) Snapshots of the few 3D models from the ShapeNet database used for rendering images. We illustratethe variety in object textures, surface materials and shapes in 3D models used for rendering. b) Rendered non-photo realistic images with with varyingobject textures, surface materials and shapes arranged in random, grid and bin packed patterns finally captured from various camera angles with differentilluminations. c) Few real images used to illustrate the difference in real and synthetic images. These images are subset of the real dataset used forbenchmarking performance of model trained with synthetic images.
In order to simulate the scenario, we need 3D models,their texture information and metadata. Thousands of 3DCAD models are available online. We choose ShapeNet [32]database since it provides a large variety of objects ofinterest for our application. Among various categories fromShapeNet like bottles, tins, cans and food items, we selec-tively add 616 various object models to object repository(R0) for generating scenes. Figure 2a shows few of themodels in R0. The variety helps randomize the aspect ofshape, texture and materials of the objects. For the refriger-ator, we choose a model from Archive3D [33] suitable forthe application. The design of refrigerator remains same forall the scenarios though the textures and material propertiesare dynamically chosen.
For generating training set with rendered images, the3D scenes need to be distinct. The refrigerator model with5-25 randomly selected objects from R0 are imported ineach scene. To simulate the cluster of objects packed inrefrigerator like real world scenarios, we use three patternsnamely grid, random and bin packing for 3D models. Thegrid places the objects in a particular scene on a refrigeratortray top at predefined distances. Random placements dropthe objects at random locations on refrigerator tray top.Bin packing tries to optimize the usage of tray top areaplacing objects very close and clustered in the scene to
replicate common scenarios in refrigerator. The light sourcesare placed such that illumination is varied in every scene andthe images are not biased to a well lit environment sincerefrigerators generally tend to have dim lighting. Multiplecameras are placed at random location and orientation torender images from each scene. The refrigerator textureand material properties are dynamically chosen for everyrendered image. Figure 2b shows few rendered images usedas training set while Figure 2c shows the subset of real worldimages used in training.
B. Deep Neural Network Architecture, Training and Evalu-ation
Figure 3 provides the detailed illustration of networkarchitecture and work-flow for the training and valida-tion stages. For neural network training we use NVIDIA-DIGITSTM -DetectNet [34] with Caffe [35] library in back-end. During training, the RGB images with resolution (inpixels) 512 x 512 are labelled with standard KITTI [31]format for object detection. We neglect objects truncated orhighly occluded in the images using appropriate flags in theground truth label generated while rendering. The dataset islater fed into a fully convolutional network (FCN) predictingcoverage map for each detected class. The FCN networkrepresented concisely in Figure 4 has the same structure

Figure 3. Work-flow for the major steps of the system. a) Using annotated images, the FCN generates a coverage map and bound-box co-ordinates. Thetraining loss is a weighted sum of coverage and bound-box loss. b) At validation time, coverage map and bound boxes are generated from the FCN.
as GoogLeNet [7] without the data input layers and outputlayers. For our experiments, we use pre-trained weights onImageNet to initialize the FCN network which has earlierbeen helpful for transfer learning [25].
Figure 4. The Fully Convolutional Network architecture used in thedetector. Each bar represents a layer. Convolution layer includes Convo-lution, ReLU activation and Pooling. Inception Layer includes the moduleas described in GoogleNet [7].
The bound-box regressor predicts bound-box corner pergrid square. We train the detector through stochastic gradientdescent with Adam optimizer using standard learning rateof 1e−3. The total loss is the weighted summation of thefollowing losses:
• L2 loss between the coverage map estimated by the
network and ground truth
1
2N
N∑i=1
∣∣coverageti − coveragepi∣∣2 (1)
where coveraget is the coverage map extracted fromannotated ground truth and coveragep is the predictedcoverage map while N denoting the batch size.
• L1 loss between the true and predicted corners ofthe bounding box for the object covered by each gridsquare.
1
2N
N∑i=1
[∣∣xt1−xp
1
∣∣+ ∣∣yt1−yp1∣∣+ ∣∣xt
2−xp2
∣∣+ ∣∣yt2−yp2∣∣]
(2)where (xt
1, yt1, x
t2, y
t2) are the ground-truth bound box
co-ordinates while (xp1, y
p1 , x
p2, y
p2) are the predicted
bound box co-ordinates. N denotes the batch size.For the validation stage, we threshold the coverage map
obtained after forward pass through the FCN network,and use the bound-box regressor to predict the corners.Since multiple bound-boxes are generated, we finally clusterthem to refine the predictions. For evaluation, we computeIntersection over Union (IoU) score. With a threshold hyper-parameter, predicted bound boxes are classified as TruePositives (TP), False Positives (FP) and False Negatives(FN). Precision (PR) and Recall (RE) are calculated usingthese metrics and a simplified mAP score is defined by theproduct of PR and RE [36].

III. RESULTS AND DISCUSSION
We evaluate our object detector trained exclusively withsynthetically rendered images using manually annotatedcrowd-sourced refrigerator images. Figure 8 illustrates thevariety in object textures, shapes, scene illumination andenvironment cues present in the test set. The real scenariosalso include other objects like vegetables, fruits, etc. whichneed to be neglected by the detector. We address them asdistractor objects.
All the experiments were carried on workstationwith IntelR CoreTM i7-5960X processor accelerated byNVIDIAR GEFORCETM GTX 1070. NVIDIA-DIGITSTM
(v5.0) tool was used to prepare and manage the databasesand trained models. Hyper-parameters search on learningrate, learning rate policy, training epochs, batch-size wereperformed for training all neural network models.
The purpose of our experiments was to evaluate theefficacy of transfer learning from rendered 3D models onreal refrigerator scenarios. Hence we divide this section intotwo parts:
• Factors affecting Transfer Learning: Here, we analyzethe factors which we experimented with to achievethe best detection performance via transfer learning.We study following factors affecting overall detectionperformance:
– Training Dataset Size: The variety in training im-ages used determines the performance of neuralnetworks.
– Selected Layer Fine-tuning: Features learned ateach layer in CNNs have been distinct and foundto be general across domains and modalities. Fine-tuning of the final fully-connected linear classifi-cation layers has been used in practice for transferlearning across applications. Hence, we extend thisidea to train several convolutional as well as linearlayers of the network and evaluate the resultingperformance.
– Object Dictionary Size: The appearance of anobject in image in static environment is a functionof its shape, texture and surface material property.Variance in objects used for rendering has beenobserved to increase detection performance signif-icantly [24].
• Detection Accuracy: Here, we represent the analysis ofthe performance on real dataset achieved with the bestdetector model1.
A. Factors affecting transfer learning
Considering other parameters like object dictionary sizeand fine-tuned network layers, we vary the training data sizefrom 500-6000. We observe an increase in mAP up to 4000
1Trained network weights and synthetic dataset are available at https://github.com/paramrajpura/Syn2Real
images followed by a light decline in performance as shownin Figure 5. Note that the smaller dataset is a subset ofthe larger dataset size i.e. we have incrementally added newimages to train dataset. After an extent, we observe declinein accuracy as we increase the dataset size suggesting over-fitting to synthetic data with increase in dataset size.
Figure 5. Detection results for the validation image-set for the trainingiterations.
Figure 6. Neurons in layers of CNN learn distinct features. Networkweights were fine-tuned by freezing layers sequentially. The figure repre-sents the performance with weights fine-tuned till mentioned layers.
We use GoogleNet FCN architecture with 11 differenthierarchical levels with few inception modules as single level(Figure 4). mAP vs. number of epochs chart is presented inFigure 6 for models with different layers selected for fine-tuning. Starting from training just the final coverage andbounding-box regressor layers we sequentially open deeperlayers for fine-tuning. We observe that fine-tuning all theinception modules helps transfer learning from syntheticimages to real images in our application. The results showthat selection of the layers to fine-tune proves to be importantfor detection performance.
To study the relationship of variance in 3D models withperformance, we incrementally add distinct 3D models to thedictionary starting from 10 to 400. We observe an increase
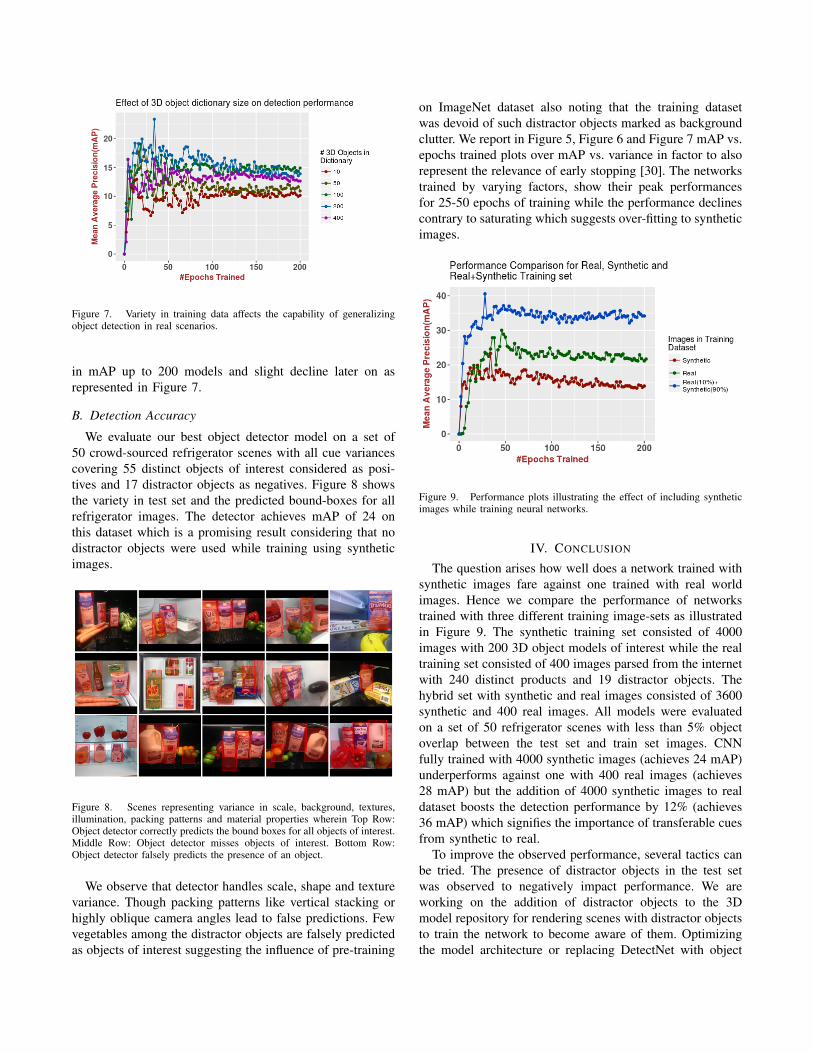
Figure 7. Variety in training data affects the capability of generalizingobject detection in real scenarios.
in mAP up to 200 models and slight decline later on asrepresented in Figure 7.
B. Detection Accuracy
We evaluate our best object detector model on a set of50 crowd-sourced refrigerator scenes with all cue variancescovering 55 distinct objects of interest considered as posi-tives and 17 distractor objects as negatives. Figure 8 showsthe variety in test set and the predicted bound-boxes for allrefrigerator images. The detector achieves mAP of 24 onthis dataset which is a promising result considering that nodistractor objects were used while training using syntheticimages.
Figure 8. Scenes representing variance in scale, background, textures,illumination, packing patterns and material properties wherein Top Row:Object detector correctly predicts the bound boxes for all objects of interest.Middle Row: Object detector misses objects of interest. Bottom Row:Object detector falsely predicts the presence of an object.
We observe that detector handles scale, shape and texturevariance. Though packing patterns like vertical stacking orhighly oblique camera angles lead to false predictions. Fewvegetables among the distractor objects are falsely predictedas objects of interest suggesting the influence of pre-training
on ImageNet dataset also noting that the training datasetwas devoid of such distractor objects marked as backgroundclutter. We report in Figure 5, Figure 6 and Figure 7 mAP vs.epochs trained plots over mAP vs. variance in factor to alsorepresent the relevance of early stopping [30]. The networkstrained by varying factors, show their peak performancesfor 25-50 epochs of training while the performance declinescontrary to saturating which suggests over-fitting to syntheticimages.
Figure 9. Performance plots illustrating the effect of including syntheticimages while training neural networks.
IV. CONCLUSION
The question arises how well does a network trained withsynthetic images fare against one trained with real worldimages. Hence we compare the performance of networkstrained with three different training image-sets as illustratedin Figure 9. The synthetic training set consisted of 4000images with 200 3D object models of interest while the realtraining set consisted of 400 images parsed from the internetwith 240 distinct products and 19 distractor objects. Thehybrid set with synthetic and real images consisted of 3600synthetic and 400 real images. All models were evaluatedon a set of 50 refrigerator scenes with less than 5% objectoverlap between the test set and train set images. CNNfully trained with 4000 synthetic images (achieves 24 mAP)underperforms against one with 400 real images (achieves28 mAP) but the addition of 4000 synthetic images to realdataset boosts the detection performance by 12% (achieves36 mAP) which signifies the importance of transferable cuesfrom synthetic to real.
To improve the observed performance, several tactics canbe tried. The presence of distractor objects in the test setwas observed to negatively impact performance. We areworking on the addition of distractor objects to the 3Dmodel repository for rendering scenes with distractor objectsto train the network to become aware of them. Optimizingthe model architecture or replacing DetectNet with object

proposal networks might be another alternative. TrainingCNNs for semantic segmentation using synthetic images andthe addition of depth information to the training sets is alsoexpected to help in the case of images with high degree ofocclusion.
ACKNOWLEDGMENT
We acknowledge funding support from Innit Inc. con-sultancy grant CNS/INNIT/EE/P0210/1617/0007 and HighPerformance Computing Lab support from Mr. SudeepBanerjee. We thank Aalok Gangopadhyay for the insightfuldiscussions.
REFERENCES
[1] D. Forsyth, “Object detection with discriminatively trainedpart-based models,” Computer, vol. 47, no. 2, pp. 6–7, feb2014.
[2] D. G. Lowe, “Distinctive image features from scale-invariantkeypoints,” International Journal of Computer Vision, vol. 60,no. 2, pp. 91–110, nov 2004.
[3] N. Dalal and B. Triggs, “Histograms of oriented gradientsfor human detection,” in Proceedings - 2005 IEEE ComputerSociety Conference on Computer Vision and Pattern Recog-nition, CVPR 2005, vol. I. IEEE, 2005, pp. 886–893.
[4] S. Ekvall, F. Hoffmann, and D. Kragic, “Object recognitionand pose estimation for robotic manipulation using colorcooccurrence histograms,” in Proceedings 2003 IEEERSJInternational Conference on Intelligent Robots and SystemsIROS 2003 Cat No03CH37453, vol. 2, no. October. IEEE,2003, pp. 1284–1289.
[5] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W.Smeulders, “Selective search for object recognition,” Inter-national Journal of Computer Vision, vol. 104, no. 2, pp.154–171, sep 2013.
[6] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNetclassification with deep convolutional neural networks,” inInternational Conference on Neural Information ProcessingSystems. Curran Associates Inc., 2012, pp. 1097–1105.
[7] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov,D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeperwith convolutions,” in Proceedings of the IEEE ComputerSociety Conference on Computer Vision and Pattern Recog-nition, vol. 07-12-June. IEEE, jun 2015, pp. 1–9.
[8] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Region-Based Convolutional Networks for Accurate Object Detectionand Segmentation,” IEEE Transactions on Pattern Analysisand Machine Intelligence, vol. 38, no. 1, pp. 142–158, jan2016.
[9] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN:Towards Real-Time Object Detection with Region ProposalNetworks,” IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, vol. 39, no. 6, pp. 1137–1149, jun 2017.
[10] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y.Fu, and A. C. Berg, “SSD: Single shot multibox detector,”in Lecture Notes in Computer Science (including subseriesLecture Notes in Artificial Intelligence and Lecture Notes inBioinformatics), 2016, vol. 9905 LNCS, pp. 21–37.
[11] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I.Williams, J. Winn, and A. Zisserman, “The Pascal VisualObject Classes Challenge: A Retrospective,” InternationalJournal of Computer Vision, vol. 111, no. 1, pp. 98–136,2014.
[12] T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra-manan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: Com-mon objects in context,” Lecture Notes in Computer Science(including subseries Lecture Notes in Artificial Intelligenceand Lecture Notes in Bioinformatics), vol. 8693 LNCS, no.PART 5, pp. 740–755, 2014.
[13] Jia Deng, Wei Dong, R. Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “ImageNet: A large-scale hierarchical image database,”in 2009 IEEE Conference on Computer Vision and PatternRecognition. IEEE, jun 2009, pp. 248–255.
[14] W. Li, L. Duan, D. Xu, and I. W. Tsang, “Learning withaugmented features for supervised and semi-supervised het-erogeneous domain adaptation,” in IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 36, no. 6,jun 2014, pp. 1134–1148.
[15] J. Hoffman, E. Rodner, J. Donahue, T. Darrell, and K. Saenko,“Efficient Learning of Domain-invariant Image Representa-tions,” in ICLR, jan 2013, pp. 1–9.
[16] J. Hoffman, S. Guadarrama, E. Tzeng, R. Hu, J. Donahue,R. Girshick, T. Darrell, and K. Saenko, “LSDA: Large ScaleDetection Through Adaptation,” in Proceedings of the 27thInternational Conference on Neural Information ProcessingSystems. MIT Press, 2014, pp. 3536–3544.
[17] B. Kulis, K. Saenko, and T. Darrell, “What you saw is notwhat you get: Domain adaptation using asymmetric kerneltransforms,” in Proceedings of the IEEE Computer SocietyConference on Computer Vision and Pattern Recognition.IEEE, jun 2011, pp. 1785–1792.
[18] M. Long, Y. Cao, J. Wang, and M. I. Jordan, “LearningTransferable Features with Deep Adaptation Networks,” inProceedings of the 32nd International Conference on Inter-national Conference on Machine Learning - Volume 37, 2015,pp. 97–105.
[19] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How trans-ferable are features in deep neural networks?” in Proceedingsof the 27th International Conference on Neural InformationProcessing Systems. MIT Press, 2014, pp. 3320–3328.
[20] Y. Li, N. Wang, J. Shi, J. Liu, and X. Hou, “Revisit-ing Batch Normalization For Practical Domain Adaptation,”Arxiv Preprint, vol. 1603.04779, no. 10.1016/B0-7216-0423-4/50051-2, mar 2016.
[21] A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic Datafor Text Localisation in Natural Images,” Arxiv Preprint, vol.1604.06646, no. 10.1109/CVPR.2016.254, apr 2016.

[22] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell,“Deep Domain Confusion: Maximizing for Domain Invari-ance,” Arxiv Preprint, vol. 1412.3474, dec 2014.
[23] X. Peng, B. Sun, K. Ali, and K. Saenko, “Learning deepobject detectors from 3D models,” Proceedings of the IEEEInternational Conference on Computer Vision, vol. 2015 Inter,pp. 1278–1286, dec 2015.
[24] H. Su, C. R. Qi, Y. Li, and L. J. Guibas, “Render forCNN: Viewpoint estimation in images using CNNs trainedwith rendered 3D model views,” Proceedings of the IEEEInternational Conference on Computer Vision, vol. 2015 Inter,pp. 2686–2694, may 2015.
[25] G. Georgakis, A. Mousavian, A. C. Berg, and J. Kosecka,“Synthesizing Training Data for Object Detection in IndoorScenes,” Arxiv Preprint, vol. 1702.07836, feb 2017.
[26] A. Singh, J. Sha, K. S. Narayan, T. Achim, and P. Abbeel,“BigBIRD: A large-scale 3D database of object instances,”in Proceedings - IEEE International Conference on Roboticsand Automation. IEEE, may 2014, pp. 509–516.
[27] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, andP. Abbeel, “Domain Randomization for Transferring DeepNeural Networks from Simulation to the Real World,” ArxivPreprint, vol. 1703.06907, mar 2017.
[28] G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M.Lopez, “The SYNTHIA Dataset: A Large Collection of Syn-thetic Images for Semantic Segmentation of Urban Scenes,”in 2016 IEEE Conference on Computer Vision and PatternRecognition (CVPR). IEEE, jun 2016, pp. 3234–3243.
[29] A. Handa, V. Patraucean, V. Badrinarayanan, S. Stent,and R. Cipolla, “SceneNet: Understanding Real World In-door Scenes With Synthetic Data,” Arxiv Preprint, vol.1511.07041, no. 10.1109/CVPR.2016.442, nov 2015.
[30] Y. Yao, L. Rosasco, and A. Caponnetto, “On early stoppingin gradient descent learning,” Constructive Approximation,vol. 26, no. 2, pp. 289–315, aug 2007.
[31] Sharp and Toby, Computer Vision and Pattern Recognition(CVPR), 2012 IEEE Conference on : date, 16-21 June 2012.IEEE, 2012.
[32] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan,Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su,J. Xiao, L. Yi, and F. Yu, “ShapeNet: An Information-Rich3D Model Repository,” Arxiv Preprint, vol. 1512.03012, no.10.1145/3005274.3005291, dec 2015.
[33] A. 3D, “Archive 3D,” 2015. [Online]. Available: http://archive3d.net/
[34] J. Barker, S. Sarathy, and A. T. July, “De-tectNet : Deep Neural Network for ObjectDetection in DIGITS,” pp. 1–8, 2016. [On-line]. Available: https://devblogs.nvidia.com/parallelforall/detectnet-deep-neural-network-object-detection-digits/
[35] M. P. Vlastelica, S. Hayrapetyan, M. Tapaswi, and R. Stiefel-hagen, “Kit at MediaEval 2015 - Evaluating visual cuesfor affective impact of movies task,” in CEUR WorkshopProceedings, vol. 1436. New York, New York, USA: ACMPress, 2015, pp. 675–678.
[36] D. Hoiem, Y. Chodpathumwan, and Q. Dai, “Diagnosing errorin object detectors,” in Lecture Notes in Computer Science(including subseries Lecture Notes in Artificial Intelligenceand Lecture Notes in Bioinformatics). Springer, Berlin,Heidelberg, 2012, vol. 7574 LNCS, no. PART 3, pp. 340–353.