nature-inspired meta-heuristics on modern gpus: state of the art and brief survey of selected...
TRANSCRIPT

Int J Parallel ProgDOI 10.1007/s10766-013-0292-3
Nature-Inspired Meta-Heuristics on Modern GPUs:State of the Art and Brief Survey of Selected Algorithms
Pavel Krömer · Jan Platoš · Václav Snášel
Received: 21 July 2013 / Accepted: 21 October 2013© Springer Science+Business Media New York 2013
Abstract Graphic processing units (GPUs) emerged recently as an exciting new hard-ware environment for a truly parallel implementation and execution of Nature andBio-inspired Algorithms with excellent price-to-power ratio. In contrast to commonmulticore CPUs that contain up to tens of independent cores, the GPUs represent amassively parallel single-instruction multiple-data devices that can nowadays reachpeak performance of hundreds and thousands of giga floating-point operations per sec-ond. Nature and Bio-inspired Algorithms implement parallel optimization strategies inwhich a single candidate solution, a group of candidate solutions (population), or mul-tiple populations seek for optimal solution or set of solutions of given problem. Geneticalgorithms (GA) constitute a family of traditional and very well-known nature-inspiredpopulational meta-heuristic algorithms that have proved its usefulness on a plethora oftasks through the years. Differential evolution (DE) is another efficient populationalmeta-heuristic algorithm for real-parameter optimization. Particle swarm optimization(PSO) can be seen as nature-inspired multiagent method in which the interaction ofsimple independent agents yields intelligent collective behavior. Simulated annealing(SA) is global optimization algorithm which combines statistical mechanics and com-binatorial optimization with inspiration in metallurgy. This survey provides a briefoverview of the latest state-of-the-art research on the design, implementation, andapplications of parallel GA, DE, PSO, and SA-based methods on the GPUs.
P. Krömer (B) · J. Platoš · V. SnášelIT4Innovations and Department of Computer Science, VŠB-Technical Universityof Ostrava, 17. listopadu 15, 708 33 Poruba, Ostrava, Czech Republice-mail: [email protected]
J. Platoše-mail: [email protected]
V. Snášele-mail: [email protected]
123

Int J Parallel Prog
Keywords Graphic processing units · Genetic algorithms · Differential evolution ·Particle swarm optimization · Simulated annealing · Survey
1 Introduction
The Graphic processing units (GPUs) have become a major force in scientific andhigh performance computing in the last few years. The single-instruction multiple-data hardware found in the modern day GPUs supports parallel execution of hundredsof threads at the same time and software drivers and runtime libraries allow efficientscheduling of tens of thousands of threads. The general-purpose computing on graphicsprocessing units (GPGPU computing) can use either commodity hardware such as theGPUs used primarily for computer graphics and entertainment, or GPU co-processors(accelerators) designed to perform massively parallel floating-point computations inthe first place.
The recent years have witnessed an increased interest in the design, implementa-tion, and application of GPU-powered high performance computing to nature-inspiredmeta-heuristic algorithms. The majority of most used nature-inspired algorithms wasaffected by this phenomenon and the wide availability, excellent performance, andsuperb performance-to-price ratio achieved by the present day GPUs attracted theattention of a growing number of researchers in the area of nature-inspired optimiza-tion.
Many algorithms from the wide families of evolutionary algorithms (EA), swarmintelligence (SI), and other nature-inspired methods were recently implemented onthe GPUs, usually in multiple different ways and often with different main objectives(e.g. design of a generic GPU-powered solvers in the scope of a software library vs. ahighly specialized and optimized solvers of particular application). This work providesa brief survey of recent studies dealing with GPU-powered GA, DE, PSO, and SA andthe applications of these algorithms to both research and real-world problems. It is anextended version of authors’ earlier survey summarizing the research on DE on theGPUs [52] and it is intended as a guide to the vast and quickly growing literature onselected GPU-powered meta-heuristics. This survey also aims to complement previousreviews such as those by Arenas et al. [4] who reviewed the use of GPUs to solvescientific problems, and those by Alba et al. [1] describing different parallelizationstrategies and communication patterns of meta-heuristics on the GPUs.
The rest of this paper is organized in the following way: the basic principles ofGPU computing are outlined in Sect. 2. A brief description of the nature-inspiredalgorithms considered in this study is given in Sect. 3. A survey of their recent designsand implementations on the GPUs is provided in Sect. 4. Finally, concluding remarksare drawn in Sect. 5.
2 GPU Computing
Modern graphics hardware has gained an important role in the area of parallel andhigh performance computing. Graphic cards have been used to power gaming and 3Dgraphics applications, but recently, they have been used to accelerate general compu-
123

Int J Parallel Prog
tations as well. The complex architecture of the GPUs is suitable for vector and matrixoperations, which leads to the wide use of GPUs in the area of scientific computing withapplications in information retrieval, data mining, image processing, data compres-sion and so on. Nowadays, GPGPU application developers do not have to be expertsin graphics hardware because of the availability of various Application ProgrammingInterfaces (APIs) that help to implement parallel applications with ease. Nevertheless,it is still crucial to follow the basic principles of data parallel programming in orderto write efficient GPGPU code.
Four main GPGPU APIs exist today. The first two are vendor specific, i.e. they weredeveloped by the two main GPU manufacturers—AMD and nVidia—and apply to theirproducts. The API developed by AMD is called AMD APP (previously ATI Stream,ATI FireStream) and the API developed by nVidia is called nVidia CUDA. The tworemaining APIs are universal. The first one, called OpenCL (Open Computing Lan-guage), was designed by the Khronos Group and the second one, called Direct Com-pute, was designed by Microsoft as a part of the DirectX. OpenCL is supported by bothAMD APP and nVidia CUDA and it can be used to develop highly portable GPGPUapplications. NVidia CUDA on the other hand has become a prominent GPGPU pro-gramming language in the field of supercomputing and high performance computing.Nevertheless, all the APIs use similar concepts as they apply to devices with similarhardware architecture. They provide a general purpose parallel computing environ-ments that exploit the parallel computation engines in the GPUs [12].
The main advantage of the GPUs is their massively data parallel architecture. Stan-dard central processing units (CPUs) contain usually 1–16 complex computationalcores, memory registers and large cache memory. The GPUs contain up to thousandsof simplified execution cores grouped into so-called multiprocessors. Every SIMDmultiprocessor drives multiple arithmetic logic units (ALUs) which process data, thuseach ALU of a multiprocessor executes the same operations on different chunks ofdata, stored in the registers or device memory. In contrast to standard CPUs which canre-schedule operations (out-of-order execution), current GPUs are an example of anin-order architecture. The limitations of the architecture are compensated by the largenumber of available cores [36].
Many traditional methods and algorithms are nowadays redesigned for the executionon GPUs with the aim to utilize their massive parallelism and excellent price-to-performance ratio whereas the improving APIs, libraries, and software developmentkits simplify the development of parallel applications. In the following, we summarizethe main features of nVidia CUDA-C but the architecture and principles of OpenCLare very similar.
CUDA’s native CUDA-C language [68] is an extension to the C programminglanguage that allows development of GPU routines called kernels. Each kernel definesa sequence of instructions that are executed on the GPU by many threads at the sametime following the data parallel SIMD model. The threads are organized into so calledthread groups (or thread blocks) that can benefit from GPU features including parallelexecution, fast shared memory, atomic data manipulation, and synchronization.
The CUDA runtime takes care of scheduling and execution of the thread groups withrespect to available hardware. The set of thread groups required to execute a kernel isin the CUDA terminology called grid. Each kernel can use several types of memory:
123
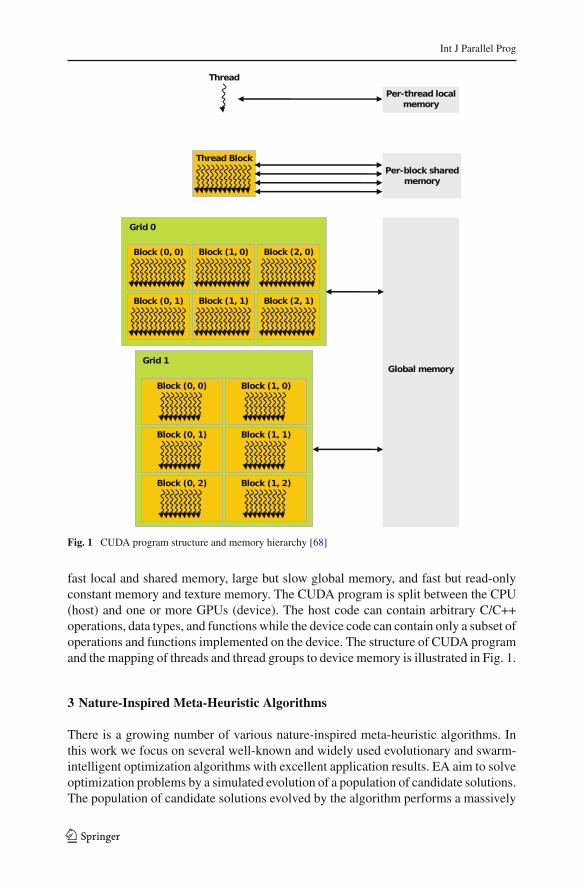
Int J Parallel Prog
Fig. 1 CUDA program structure and memory hierarchy [68]
fast local and shared memory, large but slow global memory, and fast but read-onlyconstant memory and texture memory. The CUDA program is split between the CPU(host) and one or more GPUs (device). The host code can contain arbitrary C/C++operations, data types, and functions while the device code can contain only a subset ofoperations and functions implemented on the device. The structure of CUDA programand the mapping of threads and thread groups to device memory is illustrated in Fig. 1.
3 Nature-Inspired Meta-Heuristic Algorithms
There is a growing number of various nature-inspired meta-heuristic algorithms. Inthis work we focus on several well-known and widely used evolutionary and swarm-intelligent optimization algorithms with excellent application results. EA aim to solveoptimization problems by a simulated evolution of a population of candidate solutions.The population of candidate solutions evolved by the algorithm performs a massively
123

Int J Parallel Prog
parallel search through the problem domain towards globally optimal solutions. Thecandidate solutions can be seen as individual points on the fitness landscape of thesolved problem that are iteratively and in multiple directions at once moved towardspromising regions of the fitness landscape.
Swarm intelligence (SI), on the other hand, is a research area dealing with thedesign of multiagent systems inspired by the intelligent behavior of social insects,animals, human groups, and other societies. It is concerned with models of globalbehavioral patterns rather than with the design of sophisticated controllers that wouldgovern the application. A swarm consists of many unsophisticated agents (candidatesolutions) that cooperate in order to achieve desired behavior [24,29]. Also here, thepopulation of candidate solutions maintained by the algorithm performs a massivelyparallel search through the problem domain seeking globally optimal solutions.
The implicit parallelism, multiagent nature, and rather simple operations of bothtypes of algorithms make them quite interesting for an implementation on a mas-sively parallel hardware platform. This section provides a brief overview of the basicprinciples of considered nature-inspired meta-heuristics.
3.1 Genetic Algorithms
Genetic algorithms (GA) are a well known population-based meta-heuristic soft opti-mization method [62]. GAs solve complex optimization problems by programmaticevolution of an encoded population of candidate problem solutions. The solutionsare ranked using a problem specific fitness function. The artificial evolution is imple-mented by iterative application of genetic operators and leads to discovery of aboveaverage solutions.
The basic workflow of the standard generational GA is shown in Algorithm 1.
Define objective (fitness) function and problem encoding;1Encode initial population P of possible solutions as fixed length strings;2Evaluate chromosomes in initial population using objective function;3while Termination criteria not satisfied do4
Apply selection operator to select parent chromosomes for reproduction: sel(Pi ) → parent1,5sel(Pi ) → parent2;
Apply crossover operator on parents with respect to crossover probability to produce new6chromosomes: cross(pC, parent1, parent2) → {of f spring1, of f spring2};Apply mutation operator on offspring chromosomes with respect to mutation probability:7mut (pM, of f spring1) → of f spring1, mut (pM, of f spring2) → of f spring2;
Create new population from current population and offspring chromosomes:8migrate(of f spring1, of f sprig2, Pi ) → Pi+1;
end9
Algorithm 1: A summary of genetic algorithm
Problem encoding is an important part of the genetic search. It translates candidatesolutions from the problem domain (phenotype) to the encoded search space (geno-type) of the algorithm and defines the internal representation of the problem instancesused during the optimization process. The representation specifies chromosome data
123

Int J Parallel Prog
structure and a decoding function [25]. The data structure defines the actual searchspace, its size and shape.
Crossover operator is the main operator of genetic algorithms distinguishing it fromother population based stochastic search methods [62]. Its role in the GA process hasbeen intensively investigated and its avoidance is expected to affect the efficiencyof a GA solution negatively. Crossover is primarily a creative force in the evolu-tionary search process. It is supposed to propagate building blocks (low order, lowdefining-length schemata with above average fitness) from one generation to anotherand create new (higher order) building blocks by combining low order building blocks.It is intended to introduce to the population large changes with small disruption ofbuilding blocks [105]. In contrast, mutation is expected to insert new material to thepopulation by random perturbation of chromosome structure. By this, however, canbe new building blocks created or old disrupted [105].
Genetic algorithms have been successfully used to solve non-trivial multimodaloptimization problems. They inherit the robustness of emulated natural optimizationprocesses and excel in browsing huge, potentially noisy problem domains. Their clearprinciples, ease of interpretation, intuitive and reusable practical use and significantresults have made genetic algorithms the method of choice for industrial applica-tions, while their carefully elaborated theoretical foundations attract the attention ofacademics.
3.2 Differential Evolution
The DE is a versatile and easy to use stochastic evolutionary optimization algo-rithm [72]. It is a population-based optimizer that evolves a population of real encodedvectors representing the solutions to given problem. The DE was introduced by Stornand Price in 1995 [88,89] and it quickly became a popular alternative to the moretraditional types of EA. It evolves a population of candidate solutions by iterativemodification of candidate solutions by the application of the differential mutation andcrossover [72]. In each iteration, so called trial vectors are created from current popu-lation by the differential mutation and further modified by various types of crossoveroperator. At the end, the trial vectors compete with existing candidate solutions forsurvival in the population.
The DE starts with an initial population of N real-valued vectors. The vectors areinitialized with real values either randomly or so, that they are evenly spread over theproblem space. The latter initialization leads to better results of the optimization [72].
During the optimization, the DE generates new vectors that are scaled perturbationsof existing population vectors. The algorithm perturbs selected base vectors with thescaled difference of two (or more) other population vectors in order to produce thetrial vectors. The trial vectors compete with members of the current population withthe same index called the target vectors. If a trial vector represents a better solutionthan the corresponding target vector, it takes its place in the population [72].
There are two most significant parameters of the DE [72]. The scaling factor F ∈[0,∞] controls the rate at which the population evolves and the crossover probabilityC ∈ [0, 1] determines the ratio of bits that are transferred to the trial vector from its
123

Int J Parallel Prog
opponent. The size of the population and the choice of operators are another importantparameters of the optimization process.
The basic operations of the classic DE can be summarized using the followingformulas [72]: the random initialization of the i th vector with N parameters is definedby
xi [ j] = rand(
bLj , bU
j
), j ∈ {0, . . . , N − 1} (1)
where bLj is the lower bound of j th parameter, bU
j is the upper bound of j th parameterand rand(a, b) is a function generating a random number from the range [a, b]. Asimple form of the differential mutation is given by
vti = vr1 + F (vr2 − vr3) (2)
where F is the scaling factor and vr1, vr2 and vr3 are three random vectors from thepopulation. The vector vr1 is the base vector, vr2 and vr3 are the difference vectors, andthe i th vector in the population is the target vector. It is required that i �= r1 �= r2 �= r3.
The uniform crossover that combines the target vector with the trial vector is givenby
l = rand(0, N − 1) (3)
vti [m] =
{vt
i [m] if(rand(0, 1) < C) or m = l
xi [m] (4)
for each m ∈ {1, . . . , N }. The uniform crossover replaces with probability 1 − C theparameters in vt
i by the parameters from the target vector xi .The outline of the classic DE according to [29,72] is summarized in Algorithm 2.
Initialize the population P consisting of M vectors using Equation 1;1Evaluate an objective function ranking the vectors in the population;2while Termination criteria not satisfied do3
for i ∈ {1, . . . , M} do4
Differential mutation: Create trial vector vti according to Equation 2;5
Validate the range of coordinates of vti . Optionally adjust coordinates of vt
i so, that vti is valid6
solution to given problem;
Perform uniform crossover. Select randomly one parameter l in vti and modify the trial vector7
using Equation 3;
Evaluate the trial vector.;8
if trial vector vti represent a better solution than population vector vi then9
add vti to Pt+110
else11
add vi to Pt+112
end13
end14
end15
Algorithm 2: A summary of classic Differential Evolution
123

Int J Parallel Prog
The DE is a successful EA designed for continuous parameter optimization drivenby the idea of scaled vector differentials. That makes it an interesting alternative tothe wide spread genetic algorithms that are designed to work primarily with discreteencoding of the candidate solutions. As well as GA, it represents a highly parallelpopulation based stochastic search meta-heuristic. In contrast to the GA, the differ-ential evolution uses the real encoding of candidate solutions and different operationsto evolve the population. It results in different search strategy and different directionsfound by DE when crawling a fitness landscape of the problem domain.
3.3 Particle Swarm Optimization
The PSO algorithm is a global population-based search and optimization algorithmbased on the simulation of swarming behavior of birds within a flock, schools of fishand even human social behavior [24,29,48]. PSO uses a population of motile candidateparticles characterized by their position xi and velocity vi inside the n-dimensionalsearch space they collectively explore. Each particle remembers the best position (interms of fitness function) it visited yi and knows the best position discovered so far bythe whole swarm y. In each iteration, the velocity of particle i is updated accordingto [29]:
vt+1i = vt
i + c1r t1(yi − xt
i ) + c2rr2
(yt − xt
i
)(5)
where c1 and c2 are positive acceleration constants and r1 and r2 are vectors of randomvalues sampled from uniform distribution. Vector yt
i represents the best position knownto particle i in iteration t and vector yt is the best position visited by the swarm at timet .
The position of particle i is updated by [29]:
xt+1i = xt
i + vt+1i (6)
The basic (gbest) PSO according to [29,48] is summarized in Algorithm 3.
Create population of M particles with random position and velocity;1Evaluate an objective function f ranking the particles in the population;2while Termination criteria not satisfied do3
for i ∈ {1, . . . , M} do4Set personal and global best position:5if f (xi ) < f (yi ) then6
yi = xi7end8if f (xi ) < f (y) then9
y = xi10end11Update velocity of i by (5) and position of i by (6);12
end13end14
Algorithm 3: Summary of gbest PSO
123

Int J Parallel Prog
Particle swarm optimization (PSO) is useful for dealing with problems in which thesolution can be represented as a point or surface in an n-dimensional space. Candidatesolutions (particles) are placed in this space and provided with an initial (random)velocity. Particles then move through the solution space and are evaluated using somefitness function after each iteration. Over time, particles are accelerated towards thoselocations in the problem space which have better fitness values.
The gbest PSO yields good results in some application domains. Besides that, thereis a number of alternative PSO versions including self-tuning PSO, niching PSO, andmultiple-swarm PSO that were developed in order to improve the algorithm or to solvedifficult problems [24,29].
3.4 Simulated Annealing
Simulated annealing (SA) is global optimization algorithm which combines statisticalmechanics and combinatorial optimization. It was developed by Kirkpatrick et al. [50]in 1983 and Cerný [17] in 1985. Its major advantage is that it is able to find globaloptima even in very large search spaces. The name of the algorithm originates formthe metallurgy process of annealing, a technique involving heating and controlledcooling of material to increase the size of its crystals and reduce their defects. Theheat causes the atoms to become released from their initial positions (a local minimumof the internal energy) and wander randomly through states of higher energy; the slowcooling gives them more chances to find configurations with lower internal energythan the initial one.
The basic SA algorithm consist of set of all possible solutions S, a real-valued costfunction J defined on S, a non-increasing function T called cooling schedule. T (t),where t ∈ N , is called temperature in time t . A set of solutions S(i) exists for eachsolution i ∈ S and is called a set of neighbors. Each neighbor j ∈ S(i) has assignedcoefficient qi j which is 1 when i is neighbor of j and j is neighbor of i and 0 otherwise.At the beginning, an initial state x0 ∈ S is selected [9]. The algorithm proceeds asfollows. In the current state xt which is a solution i select a neighbor j according theprobability derived from the coefficients qi j of all possible neighbors. Then the newstate of the system xt+1 is set according to:
xt+1 ={
j if J ( j) ≤ J (i)
j with prob. exp −J ( j)−J (i)T (t) otherwise xt+1 = i if J ( j) > J (i)
(7)
Due to the cooling schedule, the temperature is decreasing when the time increases andthat decreases the probability that a worse solution will be accepted. A comprehensiveoverview of the algorithm may be found in [81].
123

Int J Parallel Prog
4 Nature-Inspired Meta-Heuristics on the GPUs
This section provides the actual survey of the research on GPU-based parallelizationof selected meta-heuristics with the emphasis on recent research trends and latestadvances in the field.
4.1 Genetic Algorithms
Candidate solution evaluation (fitness function computation) is in vast majority ofcases the most time consuming part of a GA computation [5]. When dealing withcomplex real world problems (see e.g. [55]) millions of candidates might need to beevaluated in each generation or in course of the evolution. A common strategy totackle this problem is to parallelize or distribute the computations. There are multiplehigh-level approaches to GA parallelization as summarized e.g. in [1,2,20,47,93,95].
Most of the parallel approaches introduced during the last decades dealt with par-allel GA for clusters of workstations. More recently, parallelization attempts havebeen focusing on the GPUs. There are different traditional ways of exploiting paral-lelism in GAs including [15]: master-slave models, fine-grained models [103], islandmodels [59], and hybrid models [63].
Previous investigations have focused on two evaluation approaches [7]: populationparallel and fitness parallel methods can exploit the parallel architecture of the GPU.In the fitness parallel approach, all the fitness cases (instances in the training dataset)are processed in parallel with only one individual being evaluated at a time. This canbe considered an SIMD approach. Multicore CPU versus many-core GPU was studiedby Chitty [22]. Cano et al. [14] evaluated three differing approaches to parallelizationof a GA variant called Genetic Programming (GP) using both a multicore CPU andtwo GPUs.
In the population parallel approach, multiple individuals are evaluated simultane-ously. These investigations have proved that for smaller datasets or population sizes,the overhead introduced by uploading individuals to the device for evaluation is largerthan the increase in computational speed [21]. In these cases there is little or no benefitin executing the evaluation on a GPU. Therefore, the larger the population size or thelarger the number of instances, the better the potential speedup obtained by a GPUimplementation.
One of the early works on a GPU-based GP implementation is due to Chitty andMalvern [21]. The improvement in the performance of GP on a single processorarchitectures was also demonstrated. Harding and Banzhaf [38] reported how exactlythe evaluation of individuals on GP could be accelerated; both mentioned proposalswere variants of the population parallel approach. Several other approaches to GAacceleration by the GPU were demonstrated also in [16,108,104].
One of the most promising variants of GPU-powered parallel GA is the islandmodel [45,71]. Island models can fully exploit the computing power of coarse-grainedparallel computers. The population is divided into a few subpopulations, and each ofthem evolves separately utilizing different thread or group of threads. Island popula-tions are free to converge toward different suboptima. The migration operator that is
123

Int J Parallel Prog
used to transfer candidate solutions across different islands is supposed to mix goodfeatures that emerge locally into different subpopulations.
Robilliard et al. [80] proposed a parallelization scheme to exploit the performanceof the GPU on a small training sets. To optimize with a modest-sized training set,instead of sequentially evaluating the GP solutions parallelizing the training cases, theparallel capacity of the GPU was shared by the GP programs and data. Thus, differentGP chromosomes (programs) were evaluated in parallel, and a cluster of elementaryprocessors was assigned to each of them to treat the training cases in parallel. A simi-lar technique, but using an implementation based on the single program multiple data(SPMD) model, was proposed by Langdon and Harrison [54]. They implemented theevaluation process of GP trees for bioinformatics purposes using GPGPUs, achievinga speedup of around 8×. The use of SPMD instead of SIMD allows the opportunityto achieve increased speedups since, for example, one cluster can interpret the i fbranch of a test while another cluster treats the else branch independently. On theother hand, performing the same computation inside a cluster was also possible, butthe two branches were processed sequentially in order to respect the SIMD constraint:this is called divergence and is, of course, less efficient. Moreover, Maitre et al. [61]presented an implementation of a GA which computed the fitness function using aGPU. However, they had a training function instead of a training set, which they runin parallel over different individuals. Classification fitness computation was based onlearning from a training set within the GPU device which implies memory occupancy,while other proposals use a mathematical representation function as the fitness func-tion. A comparison of SIMD and GPU implementation of GA was presented in [44].
Franco et al. [32] introduced a fitness parallel method for computing fitness in anevolutionary learning systems using the GPU. Their proposal achieved speedups ofup to 52× in certain datasets, performing a reduction function [42] over the results toreduce the memory occupancy. However, this proposal did not scale to multiple devicesand its efficiency and its spread to other algorithms or to more complex problemscould have been improved. These works were focused on parallelizing the evaluationof multiple individuals or training cases and many of these proposals were limited tosmall datasets due to memory constraints imposed by the GPU architecture.
Recently, Hofmann et al. [40] performed comprehensive experiments to find outhow well particular tasks of the GA perform on the GPUs. The authors suggested that,starting with the Fermi architecture, all parts of a GA should be efficiently carried outon the graphics card instead of some parts of it only.
4.1.1 Other Sources of Information
Although NVIDIA is a commercial company, the CUDA environment and a hugeamount of documentation is freely available. They also host a large number of on-linedeveloper resources and forums [68]. OpenCL is an alternative to CUDA and is alsofreely available. While supposedly able to support computing across a wide range ofparallel hardware, most of currently active researches appear to be focused on nVidiaGPUs. However, Apple (MAC OS), IBM, AMD ATI as well as nVidia have publiclycommitted to OpenCL. Other useful Internet-based sources of information includegpgpu.org [35], Simon Harding’s web page [39], and Jaroš’s website [43]. Compre-
123

Int J Parallel Prog
hensive information on GPU programming can be also found in [102]. Langdon [56]covered almost all aspects of GP on the GPU. A couple of examples and hints ongetting started with GPU programming are also included in the mentioned studies.
4.2 Differential Evolution
Due to the simplicity of its operations, wide adoption of the algorithm, and real encod-ing of candidate solutions, the DE is suitable for data parallel implementation on theGPUs. In the DE, each candidate solution is represented by a vector of real num-bers (parameters) and the population as a whole can be seen as a real valued matrix.Moreover, both the mutation operator and the crossover operator can be implementedeasily as straightforward vector operations. In the remainder of this section we pro-vide a survey of recent works dealing with GPU-powered differential evolution. Thesurvey includes studies focusing on efficient and optimized implementation of the DEon GPUs as well as studies emphasizing the application and results rather than thealgorithm used to achieve them.
The efforts to parallelize DE predate the inception of general purpose GPUs. Forexample in 2004, Tasoulis et al. [94] proposed an algorithm to parallelize DE using aring-network topology. The results showed that the extent of information sent throughthe network is very significant for the performance of the algorithm, but not all mutationstrategies are equally sensitive to this parameter. The proposed implementation did notuse GPU parallelism, but it utilized a group of heterogeneous computers connectedthrough a network with ring topology where each sub-population lived on one node.The DE was parallelized in its simplest form, but several mutation strategies wereevaluated on several traditional benchmarks.
The first implementations of the DE on general purpose GPUs were introducedin 2010 by de Veronese and Krohling [27], Zhu [110], and Zhu and Li [111]. TheDE in [27] was implemented using the CUDA-C language and it achieved 19–34-foldspeedup in execution time when compared to a CPU-based implementation on a setof benchmarking functions. Zhu [110], and Zhu and Li [111] implemented the DEin CUDA-C as a part of a differential evolution-pattern search algorithm for boundconstrained optimization problems and as a part of a differential evolutionary Markovchain Monte Carlo method (DE-MCMC) respectively. In both cases, the performanceof the algorithms was demonstrated on a set of continuous benchmarking functions.
The early works on CUDA-based DE had to deal with the imperfections and lackof features of the pre-3.0 nVidia CUDA SDK that included (among others) the lack ofreally efficient GPU-powered random number generation. The generation of randomnumbers was usually implemented using the Mersenne Twister example from CUDASDK and some tasks (e.g. selection of random trial vectors) were in some casescompletely offloaded to the host. In the first implementations, single candidate vectorwas processed by a single thread.
Still in 2010, a comparison of several EA implemented with the support of mas-sive parallelism was provided by Desell et al. [28]. Three different algorithms—Genetic Search, Differential Evolution and Particle Swarm Optimization were testedusing a Milkyway@home computation environment with several testing functions.
123

Int J Parallel Prog
Milkyway@home project is part of the BOINC platform for distributed computationon the Web using many different client computers. One of the main goals of theresearch was to test highly parallel distributed, heterogeneous and asynchronous ver-sion of the algorithms with support of GPU acceleration. The experiments revealedthat all investigated algorithms were suitable for such an architecture and the achievedspeedup promised up to super-linear performance increases.
A couple of studies addressing some of the problems encountered by previousGPU-based DE implementations and focusing on the application of GPU-poweredDE to optimization problems have emerged in 2011. Krömer et al. [53] introduced afine-grained implementation of the DE for the GPU in CUDA-C language. The imple-mentation used many threads and aimed at increasing the utilization and occupancy ofthe GPUs. The DE implementation utilized the latest features of the then-new nVidiaSDK 3.0 such as the cuRAND library for on-GPU random number generation. It wastested on combinatorial optimization problems [51,53] and selected benchmarkingfunctions [53]. The authors have reported a 1.4–9.7-fold speedup for the linear order-ing problem and 2.2–12.5-fold speedup for the independent task scheduling problem.
Simonsen et al. [85] used a GPU-accelerated guided DE for high-accuracy molec-ular docking. The guided DE utilized additional information about the problem underinvestigation (i.e. cavities in proteins) to improve the performance of the algorithm. Thework introduced a data parallel CUDA-C version of the MolDock algorithm and com-pared the performance of a singlethreaded CPU version of MolDock, multithreadedMolDock and GPU-powered manythreaded MolDock. The multithreaded CPU ver-sion was found on a quad core CPU 3.9 times faster than the sequential implementationand the GPU version performed on a GPGPU with 122 cores was 27.4 times fasterthan the sequential implementation. The GPU speedup was affected by the amount ofwork executed on the device, allowing to reach up to a 37.5-fold speedup when boththe DE and pose evaluation was executed by the GPU.
Xiao and Quiming [106] used a GPU-powered DE to accelerate the 3D-point dataregistration task. They used a CUDA-based implementation and an advanced DE withadaptive C and F parameters. The execution of the algorithm on a GPU with 16 blocksper 256 threads resulted in a 3.3–4.0-fold speedup over a CPU-based implementation.Ramirez-Chavez et al. [76] implemented in the CUDA-C language a DE to solve thegene regulatory network model inference problem. The most computationally inten-sive part of the algorithm was in this case fitness function evaluation and the authorsfocused on its efficient SIMD parallelization. The data parallel DE was implementedwith one thread launched for each candidate vector and the authors reported a 1.06–144.83-fold speedup over a CPU-based implementation for different population sizesand different number of generations processed.
In 2012, Qin et al. [74], presented an improved CUDA-C implementation of theDE for GPUs called cudaDEi . The authors analyzed previous efforts in the designof DE for GPGPUs and proposed a series of improvements including aggregation ofconsecutive kernels into a single kernel, automated determination of kernel executionparameters (block size, grid size etc.), and utilization of streams for a fully concurrentkernel execution whenever possible. The solution was compared to some previousGPU-based DE implementations and found fastest for small problem dimensions andsmall population sizes on a collection of benchmarking functions. It was also reported
123

Int J Parallel Prog
to scale well with growing population sizes and to perform comparably with earlierimplementations for large problem dimensions and large population sizes.
The work of Arabas et al. [3] is an example of a development of DE within a moregeneral framework for evolutionary computation on the GPUs. The authors prepareda DE template for their Easy Specification of Evolutionary Algorithms (EASEA)framework in order to enable a rapid development of DE-based solutions to variousproblems powered by the GPUs. The users of the framework are required to providejust the implementation of fitness function in an extended C++ language and theframework generates optimized source code of the final program. The users do nothave to care about the details and implementation of common operations such asselection, migration between islands etc. The ease of use and efficiency of generatedsolutions was demonstrated on a use case implementing the /DE/rand/1/bin DE forthe search of function minima.
A similar approach describing the results obtained with the help of a library ofGPU-powered populational meta-heuristic algorithms is due to Ugolotti et al. [96]and Nashed et al. [64,65]. In [96], the authors used a GPU-powered DE along withsome other GPU-accelerated meta-heuristic algorithms to detect and classify roadsigns at real time. The DE was in the study used to detect the presence of a road signin a video frame. The accuracy of the detection by DE was compared to the accuracyobtained by a GPU-powered PSO. As the study was problem-focused, not many detailsabout the DE implementation were revealed. The authors have used multiple kernelsto implement DE in their system and achieved a 70 % successful classification at 17.5FPS. The DE was shown to provide a higher number of detections than the PSO. Thestudies [64,65] presented software library called libCudaOptimize that was used also inthe previous use case in more details. Besides DE, it implements PSO, Scatter Search,and Solis&Wets local search. The library was object-oriented and the interface withclient code was realized via theIOptimizer andSolutionSet classes. End userswere required to provide a fitness function implementation and allowed to provide theirown parallel enhancements to the algorithms. The library implemented different DEflavours including DE/rand/1, DE/best/1, and DE/target-to-best/1. It also utilized thecuRAND library for random number generation. In [65], the performance of differentalgorithms implemented within libCudaOptimize was tested on a set of benchmarkingfunctions. The study provided an interesting overview of the different performanceand different results obtained by the algorithms implemented using the same codingstandards and parallelization strategies. The DE was found the most successful ofthe investigated algorithms finding best solution of the test problem in 35 out of 40experiments. A model-based object detection algorithm based on PSO and DE wasproposed by Ugolotti et al. [97]. The algorithm used both optimization methods forlocalization of objects in 2D images with success. The CUDA-C implementationaccelerated both algorithms by the GPU.
A co-evolutionary variant of the DE for max-min optimization problems wasrecently implemented in CUDA-C by Fabris and Krohling [30]. The co-evolutionaryDE maintained 2 populations that were evolved in a synchronized manner. One pop-ulation evolved variable vectors while the other maintained Lagrangian multipliervectors. At each point of time, only one population was evolved while the other wasfixed (frozen) in its latest state. The authors achieved a 4.19–13.45-fold speedup on
123

Int J Parallel Prog
the GPU using co-evolutionary DE/rand/1/bin and 2.37–6.33-fold speedup using co-evolutionary DE/best/1/bin and reported a good quality of solutions evolved on theGPU. Another data parallel version of the DE was proposed recently by Tagawa [91].Even though not implemented directly on the GPU, the principles used by the sequen-tial DE make it a good candidate for a GPU-based implementation.
Wang et al. [101] proposed a DE-based method to forecast the development of thedegree of hydration of Portland cement. The manual modeling of the hydration degreeof Portland cement is not easy because it is a very complex process. The proposedevolutionary method was used on two experimental data sets and the DE was foundsignificantly better than solutions based on PSO and Genetic Algorithms in both cases.
Leskinen and Périaux [57] developed a framework for distributed evolutionaryalgorithms with Nash games on GPGPUs. The framework was applied to the Compu-tational fluid dynamics problem from aeronautic. The authors proposed a replacementof single-objective evolutionary optimization by a multi-objective optimization withsearch for Nash equilibria. The proposed framework was accelerated by the GPUs andthe problem investigated in the study was successfully solved. The speedup achievedon the GPU depended on the density of problem mesh. The speedup factor for the sim-plest problems was between 2.3 and 3.3. For more complex problems it was more than20 and the GPU implementation was able to outperform a fully optimized 20-threadedCPU version (running on a 20-core server).
In 2013, Wang et al. [100] implemented a data parallel DE with self-adaptingparameters utilizing the principles of general opposition-based learning for solv-ing high-dimensional optimization problems. The proposed algorithm called GOjDE(an extension of the earlier GODE algorithm) employed a careful adaptive parame-ter tuning strategy and focused on high-dimensional problems. It implemented theDE/rand/1/exp DE known to perform well for high-dimensional optimization andutilized the opposition-based learning. Opposition-based learning follows a simpleprinciple by which it with each candidate solution x explores also an opposite solu-tion x∗. The implementation utilized a number of kernels and it was evaluated onhigh-dimensional (up to 1000D) benchmarking functions. The speedup obtained bythe GPU-based implementation ranged from 1.29 to 7.84 for a population with 128candidate vectors processed by 128 parallel threads. With the population size 4096and 4096 parallel threads, the reported speedup was between 12.23 and 75.03.
4.3 Particle Swarm Optimization
The design and development of PSO algorithms for general purpose GPUs has fol-lowed shortly after the inception of the platform. The fast-paced development ofGPGPU hardware and software has, however, initiated a similarly quick develop-ment of new PSO algorithms and applications trying to maximize the utilization oflatest GPUs. This section provides an overview of the latest works published in thearea of GPU-powered PSO.
Rabinovich et al. [75] presented in 2012 a parallel implementation of a multiple-swarm PSO called Gaming PSO for the GPUs. Gaming PSO is an example of multiple-swarm algorithm in which several independent swarms cooperate in order to find global
123

Int J Parallel Prog
optima of investigated problem. The Gaming PSO is terminated when all swarms findthe same solution. The algorithm was implemented in CUDA-C and used as a radiofrequency resource allocation optimizer. The authors have used a fine-grained parallelversion of the PSO implemented in a single kernel. The kernel was launched with onethread for every dimension of every particle. The pseudo-random numbers neededby the algorithm were generated by an optimized version of the Mersenne Twistergenerator. The implementation used one generator per thread. The authors achieved afivefold speedup on an nVidia GTX456 GPU when compared to a Quad Core AMDCPU.
Roberge and Tarbouchi [78] developed a GPU-powered algorithm called CUDA-PSO for real-time computation of optimal switching angles for multilevel inverterswith several DC inputs while minimizing 50th first harmonics. The authors used aGPU with the nVidia Fermi architecture, curand library for generation of pseudoran-dom numbers and global memory for data storage. The CUDA implementation of themultiple-swarm PSO utilized several kernels that were launched with one thread perparticle and one thread block per independent swarm. The performance of the solu-tion was first evaluated on the Rosenbrock function for which it achieved a 215-foldspeedup when compared to a sequential implementation running on the CPU. Theoptimization of switching angles on the GPU was running 115 times faster than thesequential variant. Another application of the same algorithm was presented in [79].The parallel PSO was used for 3D pose estimation of a bomb in free fall and achieveda 140-fold speedup over a sequential implementation. The algorithm with a largenumber of particles and iterations still managed to reach small error.
Kilic et al. [49] proposed in 2012 a GPU-powered PSO algorithm for the opti-mization of electromagnetic devices modeling. The GPU was in this research usedfor simultaneous acceleration of PSO steps and fitness function evaluation (whichincluded full wave method operations). The proposed PSO was used to optimize thedesign of a patch antenna and of an antireflexive surface. The authors used Matlabwith the Jacket library [73] to employ the GPUs and evaluated the performance ofthe algorithm with the use of single GPU and multiple GPUs respectively. The PSOfor patch antenna design was with the help of a single GPU 10 times faster than amultithreaded Matlab implementation run on the CPU and 32 times faster when using4 GPUs. The antireflexive surface design was accelerated 4 times by a single GPU and10 times by 4 GPUs.
Zhang and Seah [107] implemented a niching PSO as a part of complex compu-tationally intensive algorithm for volumetric reconstruction of real-world dynamicscenes and body pose tracking in 3D. The hybrid multilayer algorithm included sceneflow estimation, stochastic search via PSO, and local search. The acceleration by GPUwas applied at several stages of the algorithm and enabled a real-time scene reconstruc-tion at high voxel resolutions. The PSO was implemented in multiple kernels and usedto solve a 48-dimensional optimization task during the reconstruction. The algorithmlaunched one thread block per particle and 64 threads per block. The fitness functionevaluation required evaluation of log likelihoods of 3 hypotheses each of which wasimplemented in a separate kernel and launched on the GPU with 128 threads. Thework reported a 11–30-fold speedup obtained by the GPU with respect to used voxelresolution.
123

Int J Parallel Prog
A recent work of Nobile et al. [67] utilized a GPU-accelerated PSO for the estima-tion of parameters of reaction constants in stochastic models of biological systems.The authors used a multiple-swarm PSO to analyze the data. Each swarm was set upwith different experimental conditions and they cooperated in order to find a set ofkinetic values that would satisfy all experimental conditions as much as possible. Oneiteration of the algorithm on an nVidia Tesla GPU took 6 s in comparison with 392 son the CPU. The details of swarm cooperation used in the algorithm were described inmore detail in [66]. The swarms exchanged at fixed intervals the gbest particles eitherfollowing a fixed (ring) communication topology or a dynamic communication topol-ogy randomly chosen at each migration step. The gbest particle received from a donorswarm replaced in the receiving swarm its weakest particle. The GPU implementationused one thread per particle and achieved a 24-fold speedup over a corresponding CPUimplementation.
A high-performance PSO powered by the GPU for ground control point-basednonlinear registration of airborne pushbroom imagery is due to Reguera-Salgado andMartin-Herrero [77]. The authors implemented in CUDA (with Thrust library) an algo-rithm that utilized the GPU to generate orthoimages, project them on a digital terrainmodel and create geometrically correct georeferenced orthophoto maps. The GPUaccelerated implementation managed to finish orthorectification of an orthoimage in<4 min.
Datta et al. [26] used a GPU-powered PSO in a related field to implement geophys-ical inversion. The authors processed different kinds of geophysical data and usedseveral different algorithm configurations. The reported speedup obtained by the GPUranged from 14 to 22. The solutions found by the GPU yielded the same precision asthe solution obtained by a sequential implementation of the inversion algorithm.
Wachowiak and Foster [99] implemented on the GPU an asynchronous version ofparallel PSO. The authors proposed a medium grained PSO parallelization designedto mitigate the common issues related to GPU implementation (e.g. limited commu-nication bandwidth). In the proposed implementation, the GPU threads ran indepen-dently for a number of iterations and performed synchronization at specified intervals.The algorithm was used to solve 3 realistic problems with different characteristicsincluding toy protein folding, logistic function (regression benchmarking problem)optimization, and the disequilibrium problem.
Cagnoni et al. [13] developed a fine-grained implementation of PSO in OpenCLwith the aim to provide a fair comparison of the performance obtained by a modernmulticore CPU and GPU. The authors remarked that majority of research works tendto compare a highly optimized (low-level) GPU implementation with a possibly lessoptimized (high-level) CPU implementation. They selected OpenCL as a universal par-allel platform supporting both GPUs and multicore CPUs and developed a single PSOcode that was compiled and executed on both types of devices. The implementationused a fine-grained parallelization launching one thread for each dimension of eachparticle, synchronous (multiple-kernel) and asynchronous (single kernel) approach,and the well known real optimization test functions as test problems. The experimentsconducted by the authors suggested that the speedup achieved on the GPU is only 2–6-fold (i.e. less than an order of magnitude) when comparing to a parallel implementationrun on a multicore CPU.
123

Int J Parallel Prog
Sharma et al. [83] used a modified PSO on the GPU for portfolio management.The algorithm used a normalized c1 equal to lbest
gbest and obtained good (<2 %) errorwhen compared to a conventional option pricing model. The PSO was implemented inCUDA-C and the speedup in option exercising on the GPU reached up to 40. Furtherdetails about the algorithm described in [84] revealed that the PSO was initialized onthe CPU to achieve uniform initial distribution of particles over problem domain andPSO iterations were executed by the GPU until termination conditions were met. Theimplementation launched one thread per particle and an own implementation of linearcongruential pseudo-random number generator.
A GPU-accelerated PSO for the Latin Hypercube design called LaPSO was pre-sented by Chen et al. [19] in 2012. The objective of the research was to find a space-filling Latin Hypercube with good coverage of defined space. LaPSO included a setof modifications used to improve the traditional PSO with respect to the discretenature of the search space. The GPU implementation used CUDA-C, multiple ker-nels, and launched one thread per PSO particle. The authors reported 17–51-foldspeedup depending on the number of particles and iterations used.
Zhao et al. [109] used a parallel PSO as a part of a more complex hybrid applicationfor converter gass system parameter optimization in steel industry. The applicationwas designed to allow prediction of future system states for scheduling, planning,and utilization optimization. The PSO implemented in this work used a single masterswarm with a set of sub-swarms within which the particles exchanged information andaffected each other during velocity updates. The research used the CUDA platformand launched one thread block for every sub-swarm and one thread for each particle.
Platoš et al. [69] used in 2012 a GPU-accelerated PSO for document classifica-tion. The authors implemented the algorithm in CUDA-C and presented two variantsof GPU-based fitness function evaluation which involved computationally intensiveoperations with large matrices. The algorithm was tested on several well-known datamining collections and the study reported a 2.5–10-fold speedup on the GPU whencompared to a single thread CPU implementation. The accuracy of the classificationwas, however, varying for different test data sets. A PSO implementation as a part ofa library of GPU-powered meta-heuristic algorithms is due to Ugolotti et al. [96,97]and Nashed et al. [64,65]. The studies compared the performance of PSO to someother algorithms including the DE and they were discussed in detail in Sect. 4.2.
In [41] was proposed a GPU-accelerated PSO (GPSO) algorithm that used a threadpool model and implemented GPSO on a real GPU. Numerical results showed that theGPU architecture matches the PSO framework well by reducing computational timing,achieving high parallel efficiency and finding better optimal solutions by using a largenumber of particles. While solving the 100-dimensional test problems with 65,536particles, GPSO has achieved up to 280X and 83X speedups on a NVIDIA TeslaC1060 1.30 GHz GPU relative to an Intel Xeon-X5450 3.00 GHz CPU running insingle- and quad-core mode, respectively.
Souza et al. [86] implemented in 2013 a multiple-swarm Evolutionary PSO. Evo-lutionary PSO uses a set of operations known from evolutionary strategies such asreplication, mutation, and selection to improve the algorithm. The GPU implementa-tion by Souza et al. used one master swarm and multiple slave swarms cooperating tosolve given problem. The master swarm shared its gbest particle with slave swarms
123

Int J Parallel Prog
to stimulate their evolution but no direct communication between slave swarms tookplace. The algorithm was implemented in CUDA-C and used to solve several engineer-ing problems including minimization of the weight of a tension/compression spring,welded beam design, and speed reducer design. The experiments suggested that theproposed algorithm was able to find better solutions than some other bio-inspiredalgorithms.
In another recent work, Valdez et al. [98] implemented on the GPU a set of meta-heuristic methods including the PSO designed to minimize complex mathematicalfunctions and compared the performance and results of the GPU-based solutions withthe performance and results of CPU powered implementations.
4.4 Simulated Annealing
The parallelization of SA was studied since its development due to the high compu-tation complexity of the algorithm. Many studies on parallel SA were published andthis text mentions only a few. An early study on computational aspects of parallel SAis due to Jayaraman and Darema in 1988 [46]. The authors investigated the problem ofSA error tolerance with respect to its parallelization because the experiments showedthat the SA tolerated such errors to some extent only. The authors also defined a paral-lelism factor for illustration of the comparative effect of the configuration parameters.Their study was experimentally tested on a chip placement problem in a grid.
A VLSI cell placement by SA was studied by Banerjee et al. [8] in 1990. Theauthors proposed and evaluated two different algorithms and their variants in orderto solve this problem on a hypercube multiprocessor with distributed memory andmessage passing. The authors proved that proposed algorithms may be scaled up to avery large number of processors.
Gallego et al. [34] addressed a different problem in 1997. The proposed parallelalgorithm did not alter the basic principle of serial SA, but used parallel processors toperform a subset of trials. It did not affect any of the good properties of the classicalSA and significantly improved the speed of the algorithm. But, of course, the actualbest solution of the problem had to be broadcasted to the rest of the processors in orderto enable an efficient problem solving.
Chen et al. [18] proposed an innovative approach which combined GA and SAinto a hybrid algorithm called Genetic Simulated Annealing. The advantage of sucha design was that any serial optimization of the SA could have been incorporatedinto the parallel algorithm without the need of any modifications. The experimentsprovided in the study suggested that the algorithm for two test problems—a 100 cityTraveling Salesman Problem and 12-bit error correction code design problem—wasable to scale up linearly with the number of used processors.
A different combination of SA and GA was proposed by Mahfoud and Gold-berg [60]. Their approach retained the asymptotic convergence property of SA andacquired the power of recombination of GA. The proposed algorithm iterated overa population of solutions instead of working with a single solution. The evaluationperformed on a test function suggested that the algorithm was able to speed up with
123

Int J Parallel Prog
increasing number of processors up to a certain limit. For some problems a maximumnumber of useful processors may be found.
The parallelization of SA for the GPUs, however, is a different task than paral-lelization for general multicore architectures presented above. An early (pre-GPGPU)acceleration of parallel SA by GPU is due to Frishman and Tal [33] in 2007. They useda GPU to compute force layout of a directed graph. The authors designed a generalmulti-level scheme which should be able to be implemented on the GPUs as well ason other multicore systems. The SA algorithm was used as a part of an algorithm toimprove the positions of graph nodes by minimization of a cost function or energy.The parallelization resulted in a 5.5-fold speedup when compared to a CPU version.
One of the first studies which presented a GPGPU version of SA was published in2010 by Choong et al. [23]. The authors improved SA for chip placement in FPGAdesign to accommodate GPUs in order to improve the speed of the algorithm. Thestandard move in chip placement which was used in the single-threaded version wasreplaced by two steps. In the first step a new subset of solutions was generated andin the second phase a parallel annealing was applied to this subset of solutions. Theparallel annealing was designed so that any solution from the subset was processedby different multiprocessor. The experiments showed that the average speed-up ofthe proposed algorithm was between 10 and 20 in comparison with standard single-threaded algorithm. The computational experiments were performed on a GPU with280 computation cores.
A completely different problem was solved by GPU-powered SA in the work ofStivala et al. [87]. The SA was used as a pre-filtering method for search in very largeProtein Databases. More precisely, the SA was used for Tableau search with proteinstructures. The SA was parallelized in two steps. Every run of the comparison of twoprotein structures was done in parallel and also each comparison of the query andmultiple protein structures in the database was executed in parallel. The GPU versionof the algorithm achieved a 34-fold speedup when compared to a single CPU on aGPU with 280 computation cores.
A study dealing with the practical aspects of GPU-parallelization of SA was pre-sented by Han et al. [37]. The authors used the SA to solve floor planning for VLSIintegrated circuits and studied several properties which affect the performance of theGPU implementation such as local and global memory usage, shared memory uti-lization, texture and constant memory usage, decomposition of the whole problembetween CPU and GPU to reduce memory transfers between host and GPU, and alsothe parameters of the floor planning problem itself such as deep and bread searchsetting. The experiments with two hardware platforms and several floor plans showedthat the speedup of the GPU version was between 6 and 160 depending on manyproperties and parameters.
Schröck and Vogt [82] published another parallel SA. The algorithm was in theirwork used for preconditioning of gauge fields in order to increase the probabilityof reaching the global maximum of a gauge fixing functional. The application wasaccelerated by the GPU for computation of the Coulomb, Landau and maximallyAbelian gauge fixing in 3+1 dimensional SU(3) lattice gauge field theories.
Li and Liu [58] presented in 2012 a SA algorithm for prediction of protein structures.The problem of optimal protein structure was first defined in terms compatible with
123

Int J Parallel Prog
the SA algorithm. The function to be minimized was defined using bond stretching,bond angle deformation energy, dihedral angles, and nonbonding interactions. Then,a parallel architecture with the usage of GPU was designed. Each thread on the GPUsimulated a Markov process of the SA computation of the protein structure. Thesethreads were grouped into blocks and grids in a way typical for GPU parallelism. Thedata describing protein structures were moved into local memory of each thread. Eachthread processed the data in local or global memory. The speedup achieved by thisalgorithm was around 3.2-times in comparison with a single threaded CPU version.
A brief comparison of the performance of SA on the CPUs and GPUs was pub-lished by Bajrami et al. [6]. Unfortunately, the comparison presented in the studywas not really comprehensive enough to include all possibilities of modern day GPUimplementations and even the test problem was not well-defined.
A more detailed study of the implementation of parallel SA is due to Ferreiro etal. [31]. The authors first designed a single-threaded general purpose SA algorithm andthen developed its GPU version. Finally a more efficient parallel synchronous versionof the algorithm which was able to exchange solutions on every temperature level wasdeveloped. The CPU and GPU variants of the SA algorithm were tested on severalwell-known real-parameter optimization test functions. The speedup of both GPU-powered algorithms was 70 and 260 respectively. The speed up was mainly affectedby the number of variables which was set between 8 and 512. Then the analysis ofthe proposed algorithm was tested with respect to the number of executed threads perblock and number of blocks. The comparison suggested that the GPU versions of theSA could be very efficient for both, simple and complex test functions.
5 Conclusions
The inception of the GPUs as extremely powerful and widely available general-purposeparallel computing devices has clearly initiated a major thrust in the research effortsfocused on the design and implementation of parallel and data parallel variants ofnature-inspired meta-heuristics. The GPGPU computing established a new platformfor evolutionary meta-heuristics and the data structures and operations involved insuch algorithms are being improved and modified in order to be executed in a dataparallel way most efficiently. There is a plenty of studies focusing on the design ofdata parallel GA, GP, DE, PSO, and SA for the GPUs or utilizing a GPU-poweredmeta-heuristics to solve complex problems.
The correctness and performance of proposed data parallel algorithms is usuallydemonstrated on selected target problem or on a benchmarking function (set of bench-marking functions). The benchmarking functions are most often more or less modifiedreal parameter optimization test functions known e.g. from [90]. However also neweroptimization test suites such as the large scale global optimization functions from [92]are sometimes used. In general, recent studies vary in the type of implemented algo-rithm, in the granularity and parallelization degree, in the choice of platform andprogramming language, in application domain, and in testing and evaluation method-ology.
123

Int J Parallel Prog
General-purpose computing on graphics processing units (GPGPU) computing is arapidly evolving ecosystem. With increasing capability of GPGPU hardware, drivers,runtime components, SDKs, and software libraries provided by GPU manufacturersor third parties, the challenges of application developers do change quickly. Whereassimple tasks such as random number generation required attention of the researchersin the recent past, the latest SDKs provide efficient readily available solutions andthe authors can focus on the design and development of highly optimized hardware-aware data parallel versions of their algorithms. The variety of different studies andapproaches is hard to compare due to different variants of DE that were implemented,different test problems, different test hardware and often different methodologies.
Nevertheless, several observations can be made on the basis of surveyed papers:there are ongoing efforts to implement fine-grained data parallel nature-inspired meta-heuristics on GPUs and utilize full power of the devices. Different parallel modelsknown from the past are being implemented and new models tailored to the SIMDarchitecture of the GPUs are being introduced. The logical structure of the algorithms(populations, chromosomes, swarms, vectors) is mapped onto GPU features such asthread blocks and threads. The GPU-accelerated meta-heuristics are aiming on solvingoptimization tasks in real-time (online). The majority of recent works used nVidiahardware and the CUDA platform with CUDA-C to implement the algorithms on theGPU. Other technologies found in surveyed studies were OpenCL and Matlab withJacket library. Figure 2 illustrates the 50 most frequent words from the studies onGA and DE summarized in this work (common words and algorithm names wereremoved). Figure 3 provides the same kind of visualisation for articles on PSO andSA respectively.
The power of GPUs is not to be missed when it comes to nature-inspired meta-heuristics’ implementation in the present day. The excellent performance of currentGPUs allows an application of the algorithms in areas where it was not feasible until
(a) (b)
Fig. 2 50 most frequent words in surveyed articles on GA and DE. a Genetic algorithms. b Differentialevolution
123

Int J Parallel Prog
(a) (b)
Fig. 3 50 most frequent words in surveyed articles on PSO and SA. a Particle swarm optimization. bSimulated annealing
now and the data parallel versions of the algorithms developed in order to exploit themassively parallel architecture of the GPUs can provide a good starting point for theimplementation of these methods on emerging data parallel platforms (such as Intel’sXeon Phi) and by the means of new more advanced programming languages (such asCilk++).
Another promising line of research is parallelization of nature-inspired meta-heuristics for grids, clouds, and hybrid systems. The majority of grids and cloudcomputing platforms of today feature hybrid nodes, i.e. compute nodes with one ormore floating-point accelerators, and the algorithms and applications targeting sucha platforms can take advantage of that. However, large-scale heterogeneous distrib-uted environments represent both an opportunity and a challenge when it comes to itsefficient use for nature-inspired methods. For example, Pop [70] dealt recently withoptimization of resource control in large-scale distributed environments and Bessiset al. [10,11] addressed the problem of meta-scheduling in heterogeneous distributedenvironments.
Acknowledgments This work was supported by the European Regional Development Fund in theIT4Innovations Centre of Excellence project (CZ.1.05/1.1.00/02.0070) and by the Bio-Inspired Methods:research, development and knowledge transfer project, Reg. No. CZ.1.07/2.3. 00/20.0073 funded by Oper-ational Programme Education for Competitiveness, co-financed by ESF and state budget of the CzechRepublic.
References
1. Alba, E., Luque, G., Nesmachnow, S.: Parallel metaheuristics: recent advances and new trends. Int.Trans. Oper. Res. 20(1), 1–48 (2013). doi:10.1111/j.1475-3995.2012.00862.x
2. Alba, E., Troya, J.M.: A survey of parallel distributed genetic algorithms. Complexity 4(4), 31–52(1999)
123

Int J Parallel Prog
3. Arabas, J., Maitre, O., Collet, P.: PARADE: a massively parallel differential evolution template forEASEA. In: Proceedings of the 2012 International Conference on Swarm and Evolutionary Compu-tation, SIDE’12, pp. 12–20. Springer, Berlin (2012). doi:10.1007/978-3-642-29353-5_2
4. Arenas, M.G., Romero, G., Mora, A.M., Castillo, P.A., Merelo, J.J.: GPU parallel computation inbioinspired algorithms: a review. In: Advances in Intelligent Modelling and Simulation, Studies inComputational Intelligence, vol. 422, pp. 113–134. Springer (2012)
5. Bacardit, J., Llora, X.: Large-scale data mining using genetics-based machine learning. Wiley Inter-discip. Rev. Data Min. Knowl. Discov. 3(1), 37–61 (2013)
6. Bajrami, E., Asic, M., Cogo, E., Trnka, D., Nosovic, N.: Performance comparison of simulated anneal-ing algorithm execution on GPU and CPU. In: MIPRO, 2012 Proceedings of the 35th InternationalConvention, pp. 1785–1788 (2012)
7. Banzhaf, W., Nordin, P., Keller, R.E., Francone, F.D.: Genetic Programming—An Introduction on theAutomatic Evolution of Computer Programs and Its Applications. Morgan Kaufmann, San Francisco,CA (1998)
8. Banerjee, P., Jones, M., Sargent, J.: Parallel simulated annealing algorithms for cell placement onhypercube multiprocessors. Parallel Distrib. Syst. IEEE Trans. 1(1), 91–106 (1990). doi:10.1109/71.80128
9. Bertsimas, D., Tsitsiklis, J.: Simulated annealing. Stat. Sci. 8(1), 10–15 (1993)10. Bessis, N., Sotiriadis, S., Cristea, V., Pop, F.: Modelling requirements for enabling meta-scheduling
in inter-clouds and inter-enterprises. In: Intelligent Networking and Collaborative Systems (INCoS),2011 Third International Conference on, pp. 149–156 (2011). doi:10.1109/INCoS.2011.120
11. Bessis, N., Sotiriadis, S., Xhafa, F., Pop, F., Cristea, V.: Meta-scheduling issues in interoperable hpcs,grids and clouds. Int. J. Web Grid Serv. 8(2), 153–172 (2012). doi:10.1504/IJWGS.2012.048403
12. Buchty, R., Heuveline, V., Karl, W., Weiss, J.P.: A survey on hardware-aware and heterogeneouscomputing on multicore processors and accelerators. Concurr. Comput. Pract. Exp. 24(7), 663–675(2012). doi:10.1002/cpe.1904
13. Cagnoni, S., Bacchini, A., Mussi, L.: OpenCL implementation of particle swarm optimization: acomparison between multi-core CPU and GPU performances. In: Chio, C., Agapitos, A., Cagnoni,S., Cotta, C., Vega, F., Caro, G., Drechsler, R., Ekárt, A., Esparcia-Alcázar, A., Farooq, M., Langdon,W., Merelo-Guervós, J., Preuss, M., Richter, H., Silva, S., Simões, A., Squillero, G., Tarantino, E.,Tettamanzi, A., Togelius, J., Urquhart, N., Uyar, A., Yannakakis, G. (eds.) Applications of Evolu-tionary Computation, Lecture Notes in Computer Science, vol. 7248, pp. 406–415. Springer, Berlin(2012). doi:10.1007/978-3-642-29178-4_41.
14. Cano, A., Zafra, A., Ventura, S.: Speeding up the evaluation phase of GP classification algorithms onGPUs. Soft Comput. 16(2), 187–202 (2012)
15. Cantú-Paz, E.: Efficient and Accurate Parallel Genetic Algorithms. Kluwer, Dordrecht (2000)16. Cavuoti, S., Garofalo, M., Brescia, M., Pescap, A., Longo, G., Ventre, G.: Genetic algorithm model-
ing with GPU parallel computing technology. In: Neural Nets and Surroundings, Smart Innovation,Systems and Technologies, vol. 19, pp. 29–39. Springer (2013)
17. Cerný, V.: Thermodynamical approach to the traveling salesman problem: an efficient simulationalgorithm. J. Optim. Theory Appl. 45, 41–51 (1985). doi:10.1007/BF00940812
18. Chen, H., Flann, N., Watson, D.: Parallel genetic simulated annealing: a massively parallel SIMDalgorithm. Parallel Distrib. Syst. IEEE Trans. 9(2), 126–136 (1998). doi:10.1109/71.663870
19. Chen, R.B., Hsieh, D.N., Hung, Y., Wang, W.: Optimizing latin hypercube designs by particle swarm.Stat. Comput., 1–14 (2012). doi:10.1007/s11222-012-9363-3
20. Cheang, S.M., Leung, K.S., Lee, K.H.: Genetic parallel programming: design and implementation.Evolut. Comput. 14(2), 129–156 (2006)
21. Chitty, D. M., Malvern, Q.: A data parallel approach to genetic programming using programmablegraphics hardware. In: GECCO G07: Proceedings of the 9th Annual Conference on Genetic andEvolutionary Computation, pp. 1566–1573, ACM Press (2007)
22. Chitty, D.: Fast parallel genetic programming: Multi-core CPU versus many-core GPU. Soft Comput.16(10), 1795–1814 (2012)
23. Choong, A., Beidas, R., Zhu, J.: Parallelizing simulated annealing-based placement using gpgpu. In:Field Programmable Logic and Applications (FPL), 2010 International Conference on, pp. 31–34(2010). doi:10.1109/FPL.2010.17
24. Clerc, M.: Particle Swarm Optimization. ISTE. Wiley (2010). http://books.google.cz/books?id=Slee72idZ8EC
123

Int J Parallel Prog
25. Czarn, A., MacNish, C., Vijayan, K., Turlach, B.A.: Statistical exploratory analysis of genetic algo-rithms: the influence of gray codes upon the difficulty of a problem. In: Webb, G.I., Yu, X. (ed.)Australian Conference on Artificial Intelligence, Lecture Notes in Computer Science, vol. 3339, pp.1246–1252. Springer (2004)
26. Datta, D., Mehta, S., Shalivahan, Srivastava, R.: Recent Advances in Information Technology (RAIT),2012 1st International Conference on CUDA based Particle Swarm Optimization for geophysicalinversion, pp. 416–420 (2012). doi:10.1109/RAIT.2012.6194456
27. de Veronese, L., Krohling, R.: Differential evolution algorithm on the GPU with C-CUDA. In: Evo-lutionary Computation (CEC), 2010 IEEE Congress on, pp. 1–7 (2010). doi:10.1109/CEC.2010.5586219
28. Desell, T.J., Anderson, D.P., Magdon-Ismail, M., Newberg, H.J., Szymanski, B.K., Varela, C.A.:An analysis of massively distributed evolutionary algorithms. In: IEEE Congress on EvolutionaryComputation, pp. 1–8. IEEE (2010)
29. Engelbrecht, A.: Computational Intelligence: An Introduction, 2nd edn. Wiley, New York, NY (2007)30. Fabris, F., Krohling, R.A.: A co-evolutionary differential evolution algorithm for solving min-max
optimization problems implemented on GPU using C-CUDA. Expert Syst. Appl. 39(12), 10,324–10,333 (2012). doi:10.1016/j.eswa.2011.10.015, http://www.sciencedirect.com/science/article/pii/S0957417411015004
31. Ferreiro, A., García, J., López-Salas, J., Vázquez, C.: An efficient implementation of parallel simulatedannealing algorithm in GPUs. J. Glob. Optim., 1–28 (2012). doi:10.1007/s10898-012-9979-z
32. Franco, M.A., Krasnogor, N., Bacardit, J.: Speeding up the evaluation of evolutionary learning sys-tems using GPGPUs. In: Proceedings of the 12th Annual Conference on Genetic and EvolutionaryComputation, GECCO10, pp. 1039–1046. ACM, New York, NY (2010)
33. Frishman, Y., Tal, A.: Multi-level graph layout on the GPU. IEEE Trans. Vis. Comput. Graphics13(6), 1310–1319 (2007). doi:10.1109/TVCG.2007.70580
34. Gallego, R., Alves, A., Monticelli, A., Romero, R.: Parallel simulated annealing applied to long termtransmission network expansion planning. Power Syst. IEEE Trans. 12(1), 181–188 (1997). doi:10.1109/59.574938
35. General-purpose computation on graphics hardware. http://www.gpgpu.org. Accessed Jul 201336. Hager, G., Zeiser, T., Wellein, G.: Data access optimizations for highly threaded multi-core cpus with
multiple memory controllers. In: Parallel and Distributed Processing. IPDPS 2008. IEEE InternationalSymposium on, pp. 1–7 (2008). doi:10.1109/IPDPS.2008.4536341
37. Han, Y., Roy, S., Chakraborty, K.: Optimizing simulated annealing on gpu: a case study with icfloorplanning. In: Quality Electronic Design (ISQED), 2011 12th International Symposium on, pp.1–7 (2011). doi:10.1109/ISQED.2011.5770735
38. Harding, S., Banzhaf, W.: Fast genetic programming on GPUs. Genet. Program. 4445(3), 90–101(2007)
39. Harding, S.: Genetic Programming on Graphics Processing Units Bibliography. http://www.gpgpgpu.com. Accessed Jul 2013
40. Hofmann, J., Limmer, S., Fey, D.: Performance investigations of genetic algorithms on graphics cards.Swarm Evolut. Comput. 12, 33–47 (2013)
41. Hung, Y., Wang, W.: Accelerating parallel particle swarm optimization via GPU. Optim. MethodsSoftw. 27(1), 33–51 (2012)
42. Hwu, W.W.: Illinois ECE 498AL: programming massively parallel processors. In: Lecture 13: Reduc-tions and Their Implementation. http://nanohub.org/resources/7376 (2009)
43. Jaroš, J.: Jiri Jaros’s software website, http://www.fit.vutbr.cz/jarosjir/prods.php.en Accessed Jul 201344. Jaroš, J., Pospíchal, P.: A fair comparison of modern CPUs and GPUs running the genetic algorithm
under the knapsack benchmark. In: Di Chio, C. et al. (eds.) Applications of Evolutionary Computa-tion. Lecture Notes in Computer Science, pp. 426–435. Springer, Heidelberg (2012). doi:10.1007/978-3-642-29178-4_43
45. Jaroš, J.: Multi-GPU island-based genetic algorithm for solving the knapsack problem. In: IEEECongress on Evolutionary Computation, pp. 1–8 (2012)
46. Jayaraman, R., Darema, F.: Error tolerance in parallel simulated annealing techniques. In: ComputerDesign: VLSI in Computers and Processors. ICCD ’88., Proceedings of the 1988 IEEE InternationalConference on, pp. 545–548 (1988). doi:10.1109/ICCD.1988.25759
47. Juillé, H., Pollack, J.B.: Massively parallel genetic programming. In: Advances in Genetic Program-ming vol. 2, chapter 17, pp. 339–358. MIT Press (1996)
123

Int J Parallel Prog
48. Kennedy, J., Eberhart, R.: Particle swarm optimization. In: Neural Networks, Proceedings., IEEEInternational Conference on, vol. 4, pp. 1942–1948 (1995). doi:10.1109/ICNN.1995.488968
49. Kilic, O., El-Araby, E., Nguyen, Q., Dang, V.: Bio-inspired optimization for electromagnetic struc-ture design using full-wave techniques on GPUs. In: International Journal of Numerical Modelling:Electronic Networks, Devices and Fields, pp. n/a–n/a (2013). doi:10.1002/jnm.1878
50. Kirkpatrick, S., Gelatt, C.D., Vecchi, M.P.: Optimization by aimulated annealing. Science 220(4598),671–680 (1983). doi:10.1126/science.220.4598.671
51. Krömer, P., Platoš, J., Snášel, V.: Differential evolution for the linear ordering problem implemented onCUDA. In: Smith, A.E. (ed.) Proceedings of the 2011 IEEE Congress on Evolutionary Computation,pp. 790–796. IEEE Computational Intelligence Society, IEEE Press, New Orleans, USA (2011)
52. Krömer, P., Platoš, J., Snášel, V.: A brief survey of differential evolution on graphic processing Units.In: IEEE Symposium on Differential Evolution (SDE), pp. 157–164 (2013)
53. Krömer, P., Snášel, V., Platoš, J., Abraham, A.: Many-threaded implementation of Differential Evo-lution for the CUDA platform. In: Krasnogor, N., Lanzi, P.L. (ed.) GECCO, pp. 1595–1602. ACM(2011)
54. Langdon, W.B., Harrison, A.P.: GP on SPMD parallel graphics hardware for mega bioinformaticsdata mining. Soft Comput. 12(12), 1169–1183 (2008)
55. Langdon, W.B.: Large scale bioinformatics data mining with parallel genetic programming on graph-ics processing units. In: Cantu-Paz, E., de Vega, F. (ed.). Parallel and Distributed ComputationalIntelligence. Studies in Computational Intelligence, pp. 113–141. Springer, Berlin (2010)
56. Langdon, W.B.: Graphics processing units and genetic programming: an overview. Soft Comput. 15,1657–1669 (2011). doi:10.1007/s00500-011-0695-2
57. Leskinen, J., Périaux, J.: Distributed evolutionary optimization using Nash games and GPUs–applications to CFD design problems. Comput. Fluids (0) (2012). doi:10.1016/j.compfluid.2012.03.017, http://www.sciencedirect.com/science/article/pii/S0045793012001132
58. Li, H., Liu, C.: Prediction of protein structures using GPU based simulated annealing. In: MachineLearning and Applications (ICMLA), 2012 11th International Conference on, vol. 1, pp. 630–633(2012). doi:10.1109/ICMLA.2012.117
59. Luong, T., Melab, N., Talbi, E.-G.: GPU-based island model for evolutionary algorithms. In:GECCO’10: Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computa-tion, pp. 1089–1096. ACM, New York (2010)
60. Mahfoud, S.W., Goldberg, D.E.: Parallel recombinative simulated annealing: a genetic algorithm.Parallel Comput. 21(1), 1–28 (1995). doi:10.1016/0167-8191(94)00071-H
61. Maitre, O., Baumes, L.A., Lachiche, N., Corma, A., Collet, P.: Coarse grain parallelization of evo-lutionary algorithms on GPGPU cards with EASEA. In: Proceedings of the 11th Annual Confer-ence on Genetic and Evolutionary Computation, GECCO’09, pp. 1403–1410. ACM, New York, NY(2009)
62. Mitchell, M.: An Introduction to Genetic Algorithms. MIT Press, Cambridge, MA (1996)63. Munawar, A., Wahib, M., Munetomo, M., Akama, K.: Hybrid of genetic algorithm and local search
to solve MAX-SAT problem using nVidia CUDA framework. Genet. Programm. Evolvable Mach.10, 391–415 (2009)
64. Nashed, Y.S., Ugolotti, R., Mesejo, P., Cagnoni, S.: libCudaOptimize: an open source library of GPU-based metaheuristics. In: Proceedings of the Fourteenth International Conference on Genetic andEvolutionary Computation Conference Companion, GECCO Companion ’12, pp. 117–124. ACM,New York, NY (2012). doi:10.1145/2330784.2330803.
65. Nashed, Y.S.G., Mesejo, P., Ugolotti, R., Dubois-Lacoste, J., Cagnoni, S.: A comparative study ofthree GPU-based metaheuristics. In: Proceedings of the 12th International Conference on ParallelProblem Solving from Nature—Volume Part II, PPSN’12, pp. 398–407. Springer, Berlin (2012).doi:10.1007/978-3-642-32964-7_40
66. Nobile, M., Besozzi, D., Cazzaniga, P., Mauri, G., Pescini, D.: A gpu-based multi-swarm pso methodfor parameter estimation in stochastic biological systems exploiting discrete-time target series. In:Giacobini, M., Vanneschi, L., Bush, W. (eds.) Evolutionary Computation, Machine Learning andData Mining in Bioinformatics, Lecture Notes in Computer Science, vol. 7246, pp. 74–85. Springer,Berlin (2012). doi:10.1007/978-3-642-29066-4_7.
67. Nobile, M.S., Besozzi, D., Cazzaniga, P., Mauri, G., Pescini, D.: Estimating reaction constants in sto-chastic biological systems with a multi-swarm PSO running o GPUs. In: Proceedings of the Fourteenth
123

Int J Parallel Prog
International Conference on Genetic and Evolutionary Computation Conference Companion, GECCOCompanion ’12, pp. 1421–1422. ACM, New York, NY (2012). doi:10.1145/2330784.2330964
68. NVIDIA: NVIDIA CUDA Programming Guide Accessed Jul 201369. Platoš, J., Snášel, V., Ježowicz, T., Krömer, P., Abraham, A.: A PSO-based document classification
algorithm accelerated by the CUDA platform. In: Systems, Man, and Cybernetics (SMC), 2012 IEEEInternational Conference on, pp. 1936–1941 (2012). doi:10.1109/ICSMC.2012.6378021
70. Pop, F.: Optimization of resource control for transitions in complex systems. Math. Probl. Eng. 12(2012). doi:10.1155/2012/625861
71. Pospíchal, P., Jaroš, J. Schwarz, J.: Parallel genetic algorithm on the CUDA architecture. In: Di Chio,C. et al. (eds.) Applications of Evolutionary Computation. Lecture Notes in Computer Science, pp.442–451. Springer, Heidelberg (2010). doi:10.1007/978-3-642-12239-2_46
72. Price, K.V., Storn, R.M., Lampinen, J.A.: Differential Evolution a Practical Approach to Global Opti-mization. Natural Computing Series. Springer, Berlin (2005) http://www.springer.com/west/home/computer/foundations?SGWID=4-156-22-32104365-0&teaserId=68063&CENTER_ID=69103
73. Pryor, G., Lucey, B., Maddipatla, S., McClanahan, C., Melonakos, J., Venugopalakrishnan, V., Patel,K., Yalamanchili, P., Malcolm, J.: High-level GPU computing with Jacket for Matlab and C/C++.In: Modeling and Simulation for Defense Systems and Applications VI, vol. 8060, pp. 806,005–806,005–6 (2011). doi:10.1117/12.884899
74. Qin, A.K., Raimondo, F., Forbes, F., Ong, Y.S.: An improved CUDA-based implementation of dif-ferential evolution on GPU. In: Proceedings of the Fourteenth International Conference on Geneticand Evolutionary Computation Conference, GECCO ’12, pp. 991–998. ACM, New York, NY (2012).doi:10.1145/2330163.2330301
75. Rabinovich, M., Kainga, P., Johnson, D., Shafer, B., Lee, J., Eberhart, R.: Particle Swarm Optimizationon a GPU. In: Electro/Information Technology (EIT), 2012 IEEE International Conference on, pp.1–6 (2012). doi:10.1109/EIT.2012.6220761
76. Ramirez-Chavez, L.E., Coello Coello, C.A., Rodriguez-Tello, E.: A GPU-based implementation ofdifferential evolution for solving the gene regulatory network model inference problem. In: Proceed-ings of the Fourth International Workshop on Parallel Architectures and Bioinspired Algorithms,WPABA 2011, pp. 21–30. Galveston Island, TX, USA (2011)
77. Reguera-Salgado, J., Martin-Herrero, J.: High performance GCP-based Particle Swarm Optimizationof orthorectification of airborne pushbroom imagery. In: Geoscience and Remote Sensing Symposium(IGARSS), 2012 IEEE, International, pp. 4086–4089 (2012). doi:10.1109/IGARSS.2012.6350729
78. Roberge, V., Tarbouchi, M.: Efficient parallel particle swarm optimizers on GPU for real-time har-monic minimization in multilevel inverters. In: IECON 2012—38th Annual Conference on IEEEIndustrial Electronics Society, pp. 2275–2282 (2012). doi:10.1109/IECON.2012.6388882
79. Roberge, V., Tarbouchi, M.: Parallel particle swarm optimization on graphical processing unit forpose estimation. WSEAS Trans. Comput. 11, 170–179 (2012)
80. Robilliard, D., Marion-Poty, V., Fonlupt, C.: Genetic programming on graphics processing units.Genet. Program Evolvable Mach., 10, 447–471, Kluwer Academic Publishers (2009)
81. Rutenbar, R.: Simulated annealing algorithms: an overview. Circuits Devices Mag. IEEE 5(1), 19–26(1989). doi:10.1109/101.17235
82. Schröck, M., Vogt, H.: Gauge fixing using overrelaxation and simulated annealing on GPUs. PoSLATTICE2012, 187 (2012)
83. Sharma, B., Thulasiram, R., Thulasiraman, P.: Portfolio management using particle swarm optimiza-tion on GPU. In: Parallel and Distributed Processing with Applications (ISPA), 2012 IEEE 10thInternational Symposium on, pp. 103–110 (2012). doi:10.1109/ISPA.2012.22
84. Sharma, B., Thulasiram, R., Thulasiraman, P.: Normalized particle swarm optimization for complexchooser option pricing on graphics processing unit. J. Supercomput., 1–23 (2013). doi:10.1007/s11227-013-0893-z
85. Simonsen, M., Pedersen, C.N., Christensen, M.H., Thomsen, R.: GPU-accelerated high-accuracymolecular docking using guided differential evolution: real world applications. In: Proceedings ofthe 13th Annual Conference on Genetic and Evolutionary Computation, GECCO’11, pp. 1803–1810.ACM, New York, NY (2011). doi:10.1145/2001576.2001818
86. Souza, D.L., Teixeira, O.N., Monteiro, D.C., Oliveira, R.C.L.A.: A new cooperative evolutionarymulti-swarm optimizer algorithm based on CUDA architecture applied to engineering optimization.In: Hatzilygeroudis, I., Palade, V. (ed.) Combinations of Intelligent Methods and Applications, Smart
123

Int J Parallel Prog
Innovation, Systems and Technologies, vol. 23, pp. 95–115. Springer, Berlin (2013). doi:10.1007/978-3-642-36651-2_6
87. Stivala, A., Stuckey, P., Wirth, A.: Fast and accurate protein substructure searching with simulatedannealing and GPUs. BMC Bioinform. 11(1), 1–17 (2010). doi:10.1186/1471-2105-11-446
88. Storn, R.: Differential evolution design of an IIR-filter. In: Proceeding of the IEEE Conference onEvolutionary Computation ICEC, pp. 268–273. IEEE Press (1996)
89. Storn, R., Price, K.: Differential Evolution—A Simple and Efficient Adaptive Scheme for GlobalOptimization over Continuous Spaces. Technical Report (1995). http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.1.9696
90. Suganthan, P.N., Hansen, N., Liang, J.J., Deb, K., Chen, Y.P., Auger, A., Tiwari, S.: Problem Defi-nitions and Evaluation Criteria for the CEC 2005 Special Session on Real Parameter Optimization.Technical Report. Nanyang Technological University (2005)
91. Tagawa, K.: Concurrent differential evolution based on generational model for multi-core CPUs.In: Bui, L.T., Ong, Y.S., Hoai, N.X., Ishibuchi, H., Suganthan, P.N. (eds.) SEAL, Lecture Notes inComputer Science, vol. 7673, pp. 12–21. Springer (2012)
92. Tang, K., Yao, X., Suganthan, P.N., MacNish, C., Chen, Y.P., Chen, C.M., Yang, Z.: BenchmarkFunctions for the CEC 2008 Special Session and Competition on Large Scale Global Pptimization.Technical Report, Nature Inspired Computation and Applications Laboratory, USTC (2007). http://nical.ustc.edu.cn/cec08ss.php
93. Tanese, R.: Distributed genetic algorithms. In: Proceedings of the 3rd International Conference onGenetic Algorithms, pp. 434–439. Morgan Kaufmann Publishers, Burlington, MA (1989)
94. Tasoulis, D., Pavlidis, N., Plagianakos, V., Vrahatis, M.: Parallel differential evolution. In: Evolution-ary Computation, 2004. CEC2004. Congress on, vol. 2, pp. 2023–2029. IEEE (2004)
95. Tufts, P.: Parallel case evaluation for Genetic Programming. In: 1993 Lectures in Complex Systems,volume VI of Santa Fe Institute Studies in the Science of Complexity, pp. 591–596. Addison-Wesley,Reading, MA (1995)
96. Ugolotti, R., Nashed, Y., Cagnoni, S.: Real-Time GPU Based Road Sign Detection and Classification.In: Coello, C., Cutello, V., Deb, K., Forrest, S., Nicosia, G., Pavone, M. (eds.) Parallel problem solvingfrom nature—PPSN XII. In: Lecture Notes in Computer Science, vol. 7491, pp. 153–162. Springer,Berlin (2012). doi:10.1007/978-3-642-32937-1_16
97. Ugolotti, R., Nashed, Y.S., Mesejo, P., Špela Ivekovic, Mussi, L., Cagnoni, S.: Particle swarmoptimization and differential evolution for model-based object detection. Appl. Soft Com-put. (0), (2012). doi:10.1016/j.asoc.2012.11.027, http://www.sciencedirect.com/science/article/pii/S156849461200511X
98. Valdez, F., Melin, P., Castillo, O.: Bio-inspired optimization methods on graphic processing unitfor minimization of complex mathematical functions. In: Castillo, O., Melin, P., Kacprzyk, J. (eds.)Recent Advances on Hybrid Intelligent Systems, Studies in Computational Intelligence, vol. 451, pp.313–322. Springer, Berlin (2013). doi:10.1007/978-3-642-33021-6_25.
99. Wachowiak, M.P., Foster, A.E.L.: GPU-based asynchronous global optimization with particle swarm.J. Phys. Conf. Ser. 385(1), 012,012 (2012). http://stacks.iop.org/1742-6596/385/i=1/a=012012
100. Wang, H., Rahnamayan, S., Wu, Z.: Parallel differential evolution with self-adapting control para-meters and generalized opposition-based learning for solving high-dimensional optimization prob-lems. J. Parallel Distrib. Comput. 73(1), 62–73 (2013). doi:10.1016/j.jpdc.2012.02.019. http://www.sciencedirect.com/science/article/pii/S0743731512000639. Metaheuristics on GPUs
101. Wang, L., Yang, B., Chen, Y., Zhao, X.: Predict the hydration of portland cement using differentialevolution. In: Evolutionary Computation (CEC), 2012 IEEE Congress on, pp. 1–5 (2012). doi:10.1109/CEC.2012.6252984
102. Wilt, N.: The CUDA Handbook: A Comprehensive Guide to GPU Programming. Addison-Wesley,Reading, MA (2013)
103. Wong, M., Wong, T.: Implementation of parallel genetic algorithms on graphics processing units. In:Intelligent and Evolutionary Systems, pp. 197–216. Springer, Berlin (2009)
104. Wong, T.T., Wong, M.L.: Parallel evolutionary algorithms on consumer-level graphics processingunit. In: Parallel Evolutionary Computations, pp. 133–155 (2006)
105. Wu, A.S., Lindsay, R.K., Riolo, R.: Empirical observations on the roles of crossover and mutation.In: Bäck, T. (ed.) Proceedings of the Seventh International Conference on Genetic Algorithms, pp.362–369. Morgan Kaufmann, San Francisco, CA (1997). citeseer.ist.psu.edu/wu97empirical.html.
123

Int J Parallel Prog
106. Xiao, C., Qiming, W.: Modified parallel differential evolution algorithm with local spectral feature tosolve data registration problems. In: Computer Science and Network Technology (ICCSNT), 2011International Conference on, vol. 3, pp. 1386–1389 (2011). doi:10.1109/ICCSNT.2011.6182223
107. Zhang, Z., Seah, H.S.: CUDA acceleration of 3D dynamic scene reconstruction and 3D motionestimation for motion capture. In: Parallel and Distributed Systems (ICPADS), 2012 IEEE 18thInternational Conference on, pp. 284–291 (2012). doi:10.1109/ICPADS.2012.47
108. Zhang, S., He, Z.: Implementation of parallel genetic algorithm based on CUDA. In: Cai, Z., Li, Z.,Kang, Z., Liu, Y. (eds.) ISICA 2009. LNCS, vol. 5821, pp. 24–30. Springer, Heidelberg (2009)
109. Zhao, J., Wang, W., Pedrycz, W., Tian, X.: Online parameter optimization-based prediction for con-verter gas system by parallel strategies. Control Syst. Technol. IEEE Trans. 20(3), 835–845 (2012).doi:10.1109/TCST.2011.2134098
110. Zhu, W.: Massively parallel differential evolution—pattern search optimization with graphics hard-ware acceleration: an investigation on bound constrained optimization problems. J. Glob. Optim.,1–21 (2010). doi:10.1007/s10898-010-9590-0
111. Zhu, W., Li, Y.: GPU-accelerated differential evolutionary markov chain Monte Carlo method formulti-objective optimization over continuous space. In: Proceeding of the 2nd Workshop on Bio-Inspired Algorithms for Distributed Systems, BADS ’10, pp. 1–8. ACM, New York, NY (2010).doi:10.1145/1809018.1809021
123