minimal string difference encodings
TRANSCRIPT

JOURNAL OF ALGORITHMS 3, 147- 156 ( 1982)
Minimal String Difference Encodings
ROBERTN.GOLDBERG
Department of Computer Science, Rutgers University, New Brunswick, New Jersey 08903
Received July 8, 1981; revised September 17, 1981
Given two strings s and t, a difference encoding is a third string that contains sufficient information to derive t from s. An algorithm is presented which derives a difference encoding that can be represented in the fewest number of bits relative to the string edit operators insert, delete, replace, and skip. This algorithm has practical significance for distributed text processing applications.
1. INTRODUCTION
Several algorithms for computing the maximal common subsequence of two strings have been presented recently in [3-71. These papers have dealt with the edit distance between two strings, or the smallest number of single-character insertions, deletions, and replacements required to change one string into the other. The insert, delete, and replace operations, supple- mented by information about the characters to which they apply, may be thought of as an encoding of the difference between the two strings. Published algorithms have minimized the cost of performing the operations required to change one string into another, but have not minimized the cost of representing the difference.
In this paper, the concern is finding the minimal string difference encoding, or the difference description that can be represented using the fewest bits. Given one of the strings and the difference encoding, it must be possible to reconstruct the second string uniquely. We present an algorithm to compute the most efficient difference encoding given the operators insert, delete, replace, and skip. The approach differs from the usual file comparison schemes such as those described in [2] which are not based on algorithms that produce minimal difference descriptions. Minimal difference encodings have practical significance for distributed text processing applications, in particular when changes made to a local copy of a file must be communi- cated to remote computer systems so that their copies can be updated.
147 Ol%-6774/82/020147-10$02.00/O Copyright 8 1982 by Academic Press. Inc. All rights of reproduction in any form resewed.

148 ROBERT N. GOLDBERG
Reference [l] describes an application of this algorithm to distributed text editing in which the communication takes place over slow-speed phone line connections.
2. PROBLEM DEFINITION
Given two strings s and t, and the notion of the current position within a string, a difference encoding is defined as an ordered sequence of the following operations which, when applied to s, yields t. The ordered sequence will be referred to as an Op$eq (pronounced op’ seek).
Delete
Insert (c)
Replace (c)
Deletes the current character in s, leaving the current posi- tion at the following character. Inserts the character c before the current character in s, leaving the current character unchanged. Replaces the current character in s with c, advancing the current character to the next one in s.
Skip Advances the current character to the next one in s.
The notion of the current position, coupled with the Skip operator, specifies the location at which each operator in OpSeq is to be applied within the modified version of s being constructed. Some of the other operators change the current position as a side effect in addition to their primary purpose. At the beginning of the operator sequence the current position is at the first character of s.
The cost of an operator reflects the number of bits used to represent it. The cost of the entire sequence is the sum of the individual costs of the operators it contains, possibly with a “discount” for using the same operator more than once in succession. The operators Insert and Replace specify new characters so their representation includes enough bits to describe that character in addition to the bits required to select the operation. Since it is possible to save some bits by representing multiple occurrences of the same operator using a repeat COUIZ~, we allow the cost of an operator to be a tuple, Cost(op) = (Costl(op),Cost2(op)), where Costl(op) is the cost of applying the operator the first time and Cost2(op) is the incremental cost of applying it successive times. The first cost must be positive and the second nonnega- tive. For reasonability we assume that the second cost is less than or equal to the first, and in the case of Insert and Replace that it is at least the cost of representing a character. The problem is to find an OpSeq such that Cost(OpSeq) is minimized.
As a concrete example, let OpSeq be represented by a string of 8 bit bytes. A sequence of operations is represented by a byte to select the

MINIMAL. STRING DIFFERENCE ENCODINGS 149
operator, followed by a second byte which is a repeat count n telling how many successive times the operator is to be applied. For Insert and Replace, the repeat count is followed by n bytes containing the new characters.’ For this example, the cost of each operator (in bytes) is
Cost (Delete) = (2,0),
Cost (Insert) = (3,1),
Cost (Replace) = (3,1),
Cost (Skip) = (2,O).
The cost of performing n Inserts, for example, is 3 + (n - 1) * 1.
3. DEFINITIONSANDNOTATION
An Op!Gq is an ordered sequence of operators that changes string s to string t. At the beginning of the sequence, the current position is at the first character of s. Last (OpSeq) is the last operator in OpSeq. SeqSefli, j, op] is the set of all OpSeq’s that end with the operator op and that change sIXi to t , : j, where x 1: i denotes the first i characters of the string x. !SeqSet[i, j, * ] is the union of SeqSet[i, j, op] for all operators op. Costl(op) is the cost of representing the operator op once (in bits or bytes), and Cost2(op) is the incremental cost of representing a second or successive op. Cost(OpSeq) is the total cost of representing OpSeq, taking into account successive occur- rences of the same operator. MinCos@eqSet[i,j, op]) is the cost of the minimum cost OpSeq in SeqSet[i, j, op]. The operator “ 1 I” denotes con- catenation. OpSeq 1 1 op represents the sequence formed by concatenating op to the end of OpSeq. !%@et[i, j, * ] 1 ( o re p p resents the set of sequences formed by concatenating op to the end of each OpSeq in SeqSet[i, j, * 1.
4.’ ALGORITHM
We will find a minimal cost Op!Seq using dynamic programming to consider the cost of every interesting sequence of operators that changes the substring s,:~ to t,:j, for i = 0 to IsI and j = 0 to ItI. Next, a second algorithm will be employed to “walk backward” through the array of interesting solution costs produced by the first algorithm to construct a minimal cost sequence that changes s to t.
‘The optimal OpSeq is relative to a particular choice of operators and their representation. This particular choice of representation is convenient but is by no means the most economical possible. For example, the selection of the operator could be done using only two bits.

150 ROBERT N. GOLDBERG
4.1. Procedure BuildL
Procedure BuildL in Fig. 1 accepts as input the two strings s and t and computes an array L[ i, j, op], the cost of the minimum cost sequence that ends with the operator op and changes the s,:~ to t 1: j. Thus, L[i, j, op] = MinCost(SeqSet[i, j, op]). The algorithm initializes L by filling in known values which depend only on the cost of each operator. Next, it fills in the
procmdure Bu i I dL (5, t) :
begin
commmnt Step 1: Initialize known values of L;
for op := Delete, Insert, Replace, Skip do L[O,O.op] := 0:
for i :- 1 upto length fs) do begin L[i.O,Deletc] :- Costl(Delete) + (i-l)*Cost2(0elete);
L[i .O, Insert] := L[i ,O.Rcplacel :- LCi ,O,Skip] :- infinity;
end ; for j :- I upto Iongth (t) dd begin
L[O,j,lnsert] := Costl(Insert) + (j-l)*CostZ(Insert);
LCO.j,Delete] :- L[O.j.Replacc] L[O,j,Skip] :- infinity:
l nd ;
LCl,l,Deletel :- L[O,l,lnsert] + Costl(Delete);
L[l,l,lnsert] :- L[l.O,Delete] + Cost1 (Insert) ;
LEl,l,Replace] := Cost1 (Replace) ;
L[l,l,Skip] := if s[l]-t[l] thmn Cost1 (Skip) else infinity:
commmnt Step 2: Fill in L[i,j] based on predecessors:
for i := I upto Imngth(s) do
for j :- 1 upto Imngthtt) do
if i+j > 2 then begin L[i . j ,Delete] := min( Smallest(i-1.j) + Cost1 (Delete).
L[i-l.j.Delete] + Cost2(Delete));
L[i,j.lnsert] := min( Smallest(i,j-1) + Costl(lnsert),
L[i.j-l,Insert] + Cost2(lnsert)):
L[i,j.Replace] :- min( Smallest(i-l.j-1) + Costl(Replace),
L[i-l,j-l.Replace] + CostZ(Replace));
L[i ,j,Skip] := if s[i]-t[j]
then min( Smallest(i-l,j-1) + Costl(Skip),
L[i-l,j-l,Skip] + CostZ(Skip))
mlsm infinity; l nd ;
end:
intmgmr procmdure Sma I I es t ( i , j 1 ;
Win cormsent Return the minimum of L[i,j,*];
Smallest :- min( L[i.j,Delete].
L[i.j,lnsertl,
L[i.j,Replace].
L[i.j,Skip] 1:
mnd ;
FIG. I. Algorithm for computing the entries of L[i, j, op].

MINIMAL STRING DIFFERENCE ENCODINGS 151
remaining entries L[i, j,op] which depend only on L[i - 1, j - 1, *], L[i, j - 1, *], and L[i - 1, j, *I. It uses procedure Smallest to compute the minimum of L[i, j, * 1, or
min(L[i, j,Delete], L[i, j,Insert], L[i, j,Replace], L[i, j,Skip]).
L is a global array and may be thought of as a matrix in which the i, jth square contains four values, corresponding to the cost of the most efficient OpSeq’s that end with each of the four possible operators, and that change s,:i to tpj.
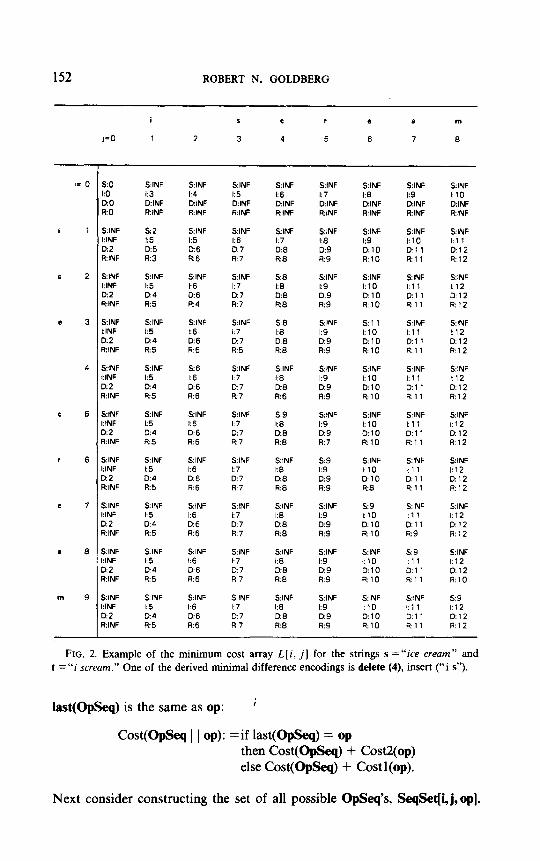
Figure 2 shows an example of the array L for the strings “ice cream” and “i scream.” The four values in L[l, l] indicate the cost of changing s, to t ,, or the string “i ” to itself, by various methods. The cheapest method is to use the skip operator, at a cost of 2 bytes. One could also delete the “i ” in s and then insert the one in t (or vice versa) at a cost of 5, or replace the “i ” in s with the one in t at a cost of 3.
To carry out the algorithm it is necessary to remember all four numbers because the cost of applying the next operator depends on the operator that was used to get to the current entry of L. For example, the cost of getting to L[4,2, Insert] from L[4, l] is 6 as a result of L[4,1, Insert], even though L[4,1, Delete] is smaller. The minimum cost of an OpSeq that changes s to t is the smallest of the four values in the last square computed, or Smallest (Is\, It\).
4.2. Proof of Correctness of Procedure BuildL
The first step of the algorithm initializes L[ * ,O, * 1, L[O, * , * 1, and L[ 1, 1, * 1. L(O,O, l ] is the minimum cost of changing the null string to itself, which is zero. yi, 0, Delete] is the minimum cost of changing s,:; to the null string with the last operator a Delete, which can be done only by i deletions in succession. UO, j, Insert] is the minimum cost of changing the null string to t,:j with the last operator an Insert, which can be done only by performing j insertions in succession. All other entries L[O, * , * ] and L[ * , 0, * ] correspond to impossible OpSeq’s so their minimum cost is set to infinity, which effectively eliminates them from consideration. For each of L[ 1, 1, * ] there is only one possible OpSeq, and its cost is known. Note that L[i, j, Skip] is infinite if si # tj.
Step 2 of the algorithm iteratively determines the value of L[i, j, op], for i = 1,2,. . . , Is], j = 1,2,. . . , Itl, i + j > 2, by examining the previously computed values L[i, j - 1, *], L[i - 1, j, *], and L[i - 1, j - 1, *]. To see that L[i, i, op] depends only on these three predecessors as computed by the algorithm, first consider computing Cost(OpSeq I I op) for any non- empty OpSeq. The incremental cost of adding op depends only on whether
152 ROBERT N. GOLDBERG
I I e I c a Ill
I=0 1 2 3 4 5 6 7 8
,= 0 so I:0 D:O R:O
1 SINF I:lNF D:2 R:INF
2 SINF I:INF D:2 R:INF
3 S:INF I:INF D:2 R:INF
4 SINF I:INF 0~2 R:INF
5 5:INF I:INF D:2 R:INF
6 S:INF I:INF D:2 R:INF
7 S:INF I:INF 0:2 R:INF
8 S:INF MNF 0:2 R:INF
9 S:INF I:INF D:2 R:INF
S:INF 1:3 BINF R:INF
SE2 1:5 D:5 R:3
S:INF 1:5 D:4 R:5
5:INF I:5 D:4 R:5
SINF 1:5 D:4 R:5
S:INF I:5 D:4 R:5
SINF 1:5 0:4 R:5
SINF 1:5 D:4 R:5
S:INF 1:5 D:4 R:5
5:INF 1:5 D:4 A:5
SINF I:4 D:INF R:INF
SINF 1:5 D:6 R:6
SINF 1:6 D:6 R:4
SINF 1:6 D:6 R:6
S:6 I.6 D:6 R:6
SANF 1:6 D:6 R:6
SINF 1:6 D:6 W6
5:INF I:6 D:6 R:6
SANF I:6 D6 R:6
SANF 1:6 D:6 R:6
5:i~F 1:5 D:INF R:INF
S:INF I:6 D:7 R7
SINF I:7 D:7 R:?
S:INF 1.7 D:7 R:5
S:INF 1:7 0:7 I?:7
S:INF I:7 0:7 R:7
SINF 1:7 D:7 R:7
S:INF 1:7 D:7 R:7
SINF 1:7 D:7 R7
S:INF I:7 0:7 R:7
S:INF 1:6 D:INF R:INF
S:INF 1:7 D:8 R:8
s:8 1:8 D:8 R:8
S:8 I:8 D:8 R:8
S:INF I:8 D:8 R:6
s:9 1:8 D:8 R:8
S:INF 1:8 D:8 R:8
S:INF I:8 D:8 R:8
S:INF I:8 D:8 R:8
SINF 1:8 D:8 R:8
WNF 1:7 D:INF R:INF
S:INF I:8 D:9 I+9
S:INF 1:9 D:9 R:9
S:INF I:9 D:9 R:9
SINF 1:9 D:9 R:9
S:INF 1:9 09 R:7
s:9 I:9 D:9 I?9
S:INF I:9 0:9 I39
S:INF 1:9 D:9 R:9
SINF Ii9 D:9 R:9
S:INF I:8 D:INF RINF
S:INF 19 D:lO R:lO
S:INF I:10 D:lO R:lO
Sll 1:lO D:lO R:lO
SINF 1:lO D:lO R:lO
S:INF 1:lO D:lO R: 10
S:INF 110 D:lO R:8
59 I:10 0:lO R.10
SINF I:10 D:lO R: 10
SINF I:10 D:lO It10
SANF 1:9 D:INF R:INF
SINF I:10 011 R:ll
S:INF I:1 1 011 Rll
S:INF 1:ll D:ll R:ll
S:INF I:1 1 D:l 1 R.1 1
S:INF 1:ll D:l 1 R:ll
SINF 1:ll D:l 1 I?11
WNF I:1 1 D:ll RI9
s:9 I.1 1 D:l 1 R:ll
S:INF I:1 1 D:l 1 I+11
SANF I:10 D:INF R:INF
SINF I:11 D:12 R:12
SINF I: 1 2 0:12 R:12
SINF 112 D:12 Rl2
SINF 1:12 D:12 RI12
S:INF I:12 D:12 w12
5:INF 1:12 0:12 R:12
5:INF I:12 DE12 A:12
S:INF I:12 D:12 R:lO
s:9 I.1 2 D:lZ R:12
FIG. 2. Example of the minimum cost array L[i, j] for the strings s =“ice cream” and t = “i sueurn.” One of the derived minimal difference encodings is delete (4), insert (“i s”).
last(OpSeq) is the same as op: ’
Cost(OpSeq ( ( op): =if last(OpSeq) = op then Cost(OpSeq) + Cost2(op) else Cost(Op!Seq) + Cost l(op).
Next consider constructing the set of all possible OpSeq’s, Seq!Set[i,j,op].

MINIMAL STRING DIFFERENCE ENCODINGS 153
From the definitions of the four operators and the fact that SeqSet[i, j, op] must end with operator op, we obtain the following set constructions:
SeqSet[i, j, Delete] = SeqSet[i - 1, j, * ] ) ] Delete
SeqSet[i, j, Insert] = SeqSet[i, j - 1, *] ] ] Insert (f,) .
SeqSet[i, j, Replace] = SeqSet[i - 1, j - 1, * ] 1 ] Replace (fj)
SeqSet[ i, j, Slop] = if si = tj then SeqSet[i - 1, j - 1, *] ] ] Skip else EmptySet
Using the definition of L[ i, j, op] and the formula for the incremental cost of concatenating an operation to the end of a sequence, these constructions lead to the following relationships in the array L:
L[ i, j, Delete] = MinCost(SeqSet[i, j, Delete]) = MinCost(SeqSet[i - 1, j, * ] I ] Delete) = min(l[i - 1, j, *] + Cost l(Delete),
L[i - 1, j, Delete] + Cost2(Delete))
L[i, j, Insert] = MinCost(SeqSet[i, j, Insert]) = MinCost[SeqSet(i, j - 1, * ] ] ] Insert) = min(l[i, j - 1, *] + Cost l(Insert),
L[i, j - 1, Insert] + Cost2(Insert))
L[i, j, Replace] = MinCost(SeqSet[i, j, Replace]) = MinCost(SeqSet[i - 1, j - 1, * ] ] ] Replace) = min(l[i - 1, j - 1, *] +Costl(Replace),
L[i - 1, j - 1, Replace] + Cost2(Replace))
Ui, j, SW1 = MinCost(SeqSet[i, j, Skip]) = MinCost(SeqSet[i - 1, j - 1, * ] ] ] Skip) = min(l[i - 1, j - 1, *] +Cost(Skip)),
1 if si = tj
L[i - 1, j - l,Skip] + Cost2(Skip)) = infinity } if si # tj
These relationships are used by Procedures BuildL and Smallest to compute L[i, j, * ] given its predecessors. 0
4.3. Procedure DeriveOpSeq
Procedure DeriveOpSeq in Fig. 3 returns a minimal-cost OpSeq given the array L produced by procedure BuildL. It first determines the last operator by examining L[]s], ItI, *] to find the op for which L[]s], ]t],op] is smallest. If there is more than one such op, it chooses one of the possibilities arbitrarily. The choice of op uniquely determines the predecessor entry L[ I?Z, n, * ] to examine. The next-to-last operator in the sequence is then the value of k for which L[]s], ]t],op] = L[ m, n, k] plus the incremental cost of of performing op after k. Again, if there is more than one such k, one is

154 ROBERT N. GOLDBERG
procedure DeriveOpSeq;
begin OpSeq :- NIL;
i := length(s); j := length(t) ;
comment Find the least cost final operator;
opcost := infinity;
for k := Delete, Insert, Replace, Skip do if L[i ,j .k] < opcost than bogin
opcost := L[i,j,k];
op := k; end:
comment Trace back the sequence ending in it:
while i>O or j>O do begin opseq := op I( opseq; case op of begin
[Delete] i:-i-l;
[insert] j:-j-l;
[Replace] begin i:=i-I; j:-j-l; and:
[Ski PI begin i:-i-l; j:-j-l; end;
and;
comment F i nd its predecessor;
for k := Delete, Insert, Replace, Skip do
if CumeCost(i,j,k,op) = opcost than begin op :- k;
end ;
opcost := L[i.j,op];
exitloop; end :
end ; return (OpSeq) ;
integer procedure CumeCost (n,m, prevOp,op) :
begin comment Return cumulative cost for applying op after L[n.m,prevOpl; Cumetost := if prevOp # op or n+m = 0
then L[n,m.prevOpI + Cost1 top)
else L[n,m,prevOpI + Cost2 cop) :
FIG. 3. Procedure to derive a minimal cost OpSeq given array L.
chosen arbitrarily. The choice of k uniquely determines the predecessor entry of L to examine next. This process continues until L[O, 0, * ] has been reached, at which point the algorithm has produced an OpSeq which changes s to t and whose cost is Smallest(l s I,[ t I).
5. COMPLEXITY ANALYSIS
The algorithm requires 1 s 1 l ( t I -naps words of storage for the array L, where nops is the number of unique operators considered by the algorithm

MINIMAL STRING DIFFERENCE ENCODINGS 155
(nops = 4 in the algorithm as presented). Nops is actually a constant with respect to the problem the algorithm solves. The memory used for storing the derived OpSeq is O(] s ] + ) t 1) in the worst case.
Step 1 of Procedure BuildL has linear time complexity O(]s] + ItI). Each iteration of step 2 examines O(nops’) locations in the array and the inner loop is executed Is] l I t I times, so the time complexity of step 2 is O(Jsl l I t I l naps*). Procednre DeriveOpSeq executes its while loop O(]s( + Itl) times and examines nops locations in the array so its time complexity is O[(]s) + I t l ) l nops].
The overall complexity of procedures BuildL and DeriveOpSeq is O(]s] l I t I l naps) in space and O(]s] l ( t ( l naps’) in time.
6. COMMENTS
Trailing Skip operators need not be included in the cost of the minimal difference description since they do not affect the resultant string. To take advantage of this optimization, procedure DeriveOpSeq can be modified to decrease L[ls 1, It 1, Skip] by the cost of the final series of n Skip operators, Costl(Skip) + (n - 1) l Cost2(Skip), before selecting the lowest-cost final operator. If skip is in fact selected as the final operator, it should begin producing OpSeq at the appropriate operator in L[ls 1 - n, f t 1 - n, * 1, rather than at L[]s], It], Skip].
The same basic algorithm can be adapted to handle additional operators with related characteristics. For example, one can add operators analogous to the four that have been introduced above but which operate on a single character at a time, to save the cost of encoding the repeat count for single-character operations. This addition will allow the algorithm to derive lower-cost difference descriptions for strings that differ by single characters. Higher-level operators, similar to those found in text editors, can also be handled by storing sufficient information in L to allow the algorithm to determine the cost of applying each operator by examining a few predeces- sor entries. In this fashion the same basic algorithm may be adapted to handle many simple context-independent operators, at some cost in time and space as the number of operators nops grows.
The algorithm presented cannot reasonably be used to compute dif- ferences between entire files directly, due to its quadratic time and space requirements. For example, assuming that the two files were of length 100,000 characters, and that each step of the algorithm takes lop6 set, the computation would require on the order of 10,000 set and 10” bytes of memory for storage of the array L. The average time and space complexity of the maximal common subsequence problem has been reduced from the I s I l I t I of the o riginal algorithm in [7] to more linear behavior in [3-51. Similar techniques may yield average case improvements to the current

156 ROBERT N. GOLDBERG
algorithm as well. Despite its quadratic time and space dependence, how- ever, the algorithm can be applied on a line-by-line basis as a user edits a file, encoding the changes “on the fly.” Alternatively, it can be used to process the output of a line-by-line file comparison utility into a more concise form.
The operators considered in this paper move forward through string s to produce string t. While one could define more general operators that move backward as well as forward, these operators would not reduce the cost of the minimum cost difference encoding. The proof of this assertion is tedious and has been omitted. Basically, any operation applied through a sequence of operators in which the direction of motion changes can be applied just as cheaply in a sequence that moves in one direction only.
ACKNOWLEDGMENTS
The author would like to thank the following persons for reading drafts of this paper and providing useful suggestions for improvement: Judith E. Dayhoff, Department of Mathematics, Robert L. Smith, Barbara G. Ryder, and Marvin C. Paull, Department of Computer Science, all at Rutgers University. Computing and text processing facilities for this research were provided by the Department of Computer Science, Rutgers University.
REFERENCES
1. R. GOLDBERG, “Software Design Issues in the Architecture and Implementation of Distrib- uted Text Editors,” Ph.D. thesis, Rutgers University, January, 1982.
2. P. HECKEL, A technique for isolating differences between files, Comm. ACM 21, No. 4
(1978). 3. D. S. HIRSCHBERG, A linear space algorithm for computing maximal common subsequences,
Comm. ACM 18, No. 6 (1975), 341-343.
4. D. S. HIRSCHBERG, Algorithms for the longest common subsequence problem, J. Assoc. Comput. Mach. 24, No. 4 (1977), 664-675.
5. J. HUNT AND T. %aMANSKI, A fast algorithm for computing longest common subsequences, Comm. ACM 20, No. 5 (1977), 350-353.
6. R. LOWIUNCE AND R. WAGNER, An extension of the string-to-string correction problem, J. Assoc. Comput. Mach. 22, No. 2 (1975), 177-183.
7. R. WAGNER AND M. FISCHER, The string-tostring correction problem, J. Assoc. Compur. Mach. 21, No. 1 (1974) 168-173.