metu informatics institute min720 pattern classification with bio-medical applications
DESCRIPTION
METU Informatics Institute Min720 Pattern Classification with Bio-Medical Applications. Part 7 : Linear and G eneralized D iscriminant F unctions. LINEAR DISCRIMINANT FUNCTIONS. Assume that t he discriminant functions are linear function s of X. - PowerPoint PPT PresentationTRANSCRIPT

METU Informatics Institute Min720
Pattern Classification with Bio-Medical Applications•
Part 7:
Linear and Generalized Discriminant Functions

LINEAR DISCRIMINANT FUNCTIONS
Assume that the discriminant functions are linear functions of X.
We may also write g in a compact form as:
where
a-augmented augmented pattern vector and weight factor.
onn wxwxwxwXg ....)( 2211
0wXW T TnwwW .......1 TnxxX ..........1
YWXWXg Taa
Ta )(
Tna wwwwW 021 ......
1.....1 na xxXY

Linear discriminant function classifier:
• It’s assumed that the discriminant functions (g’s)are linear.
• The labeled learning samples only are used to find best linear solution.
• Finding the g is the same as finding Wa.
• How do we define ‘best’? All learning samples are classified correctly?
• Does a solution exist?
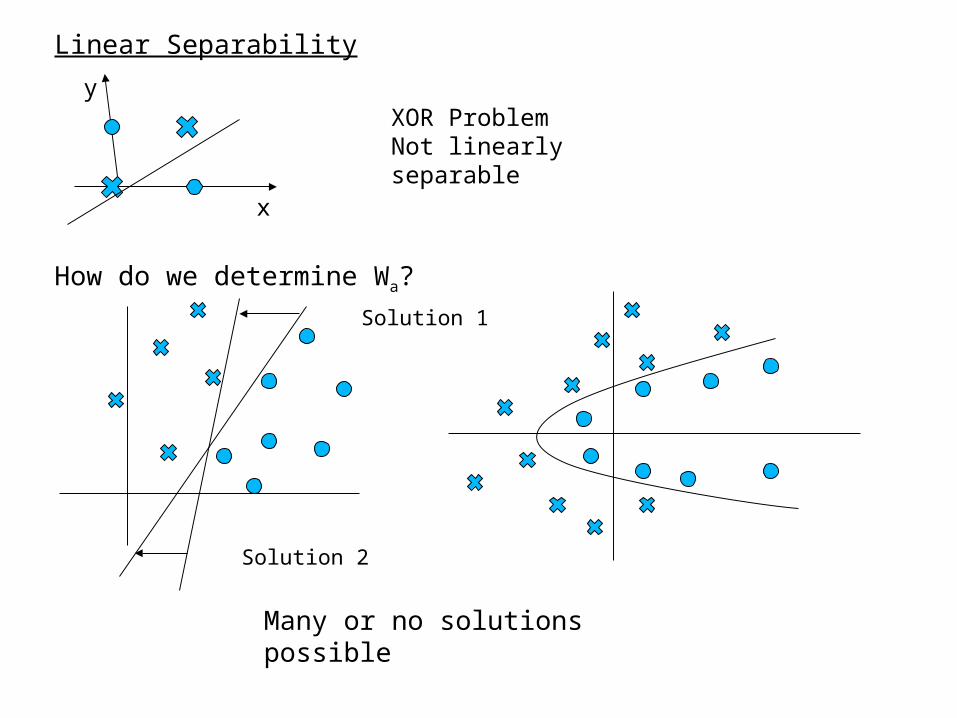
Linear Separability
How do we determine Wa?
XOR ProblemNot linearly separable
y
x
Solution 1
Solution 2
Many or no solutions possible

2 class case:
Where X is a point on the boundary (g1=g2)
a single disriminant function is enough!
R2
R1
x2
x1
g(x)<0
g(x)>0
g1-g2=0
0YW Ta
The decision boundaries are lines, planes or hyperplanes. Our aim is to find best g.
YWXWXW Taa
Taa
Ta 221
g1 g2
0)( 21 YWWXg Taa
Wa
)()()( 21 YgYgXg

on the boundary.or is the equation of the line for 2 feature problem..g(x)>0 in R1 and g(x)<0 in R2
Take two points on the hyperplane, X1 and X2
W is normal to the hyperplane.
0YW Ta
0 oT wXW
021 YWYW TT
0)( 21 ooT wwXXW
X
d
g>0
Xp
r
X2
X1
R2
R1
g<0
g=0
w
xgr
)( Show!
Hint: g(Xp)=0
g(x) is proportional to the distance of X to the hyperplane.
w
wd o distance from origin to
the hyperplane.

• What is the criteria to find W?
1. For all samples from c1, g>0, WX>0
2. For all samples from c2, g<0 WX<0
• That means, find an W that satisfies above if there is one.
• Iterative and non iterative solutions exist.

If a solution exists-the problem is called “linearly separable” and Wa is found iteratively. Otherwise “not linearly separable” piecewise or higher degree solutions are seeked.
Multicategory Problem Many to one Pairwise One function/category
undefined regions
Results with undefined regions
ioii wXWg
Many to one

pairwise
one function/category
g1=g2
g1=g3
g3=g2
g1=g2=g3
W1
W2
W3

Approaches for finding W: Consider 2-Class Problem• For all samples in category 1, we should have
• And for all samples in category 2, we should have
• Take negative of all samples in category 2, then we need
for all samples.
Gradient Descent Procedures and Perceptron Criterion• Find a solution to
• If it exists for a learning set (X:labeled samples) Iterative Solutions Non-iterative Solutions
0aTa XW
0aTa XW
0aTa XW
0aTa XW

Iterative: start with an initial estimate and update it until a solution is found.
Gradient Descent Procedures:Iteratively minimize a criterion function J(w).Solutions are called “gradient descent” procedures.• Start with an arbitrary solution.• Find - gradient• Move towards the negative of the gradient
Wao
))1((wJ
))(()()()1( kwJkkwkw Learning rate
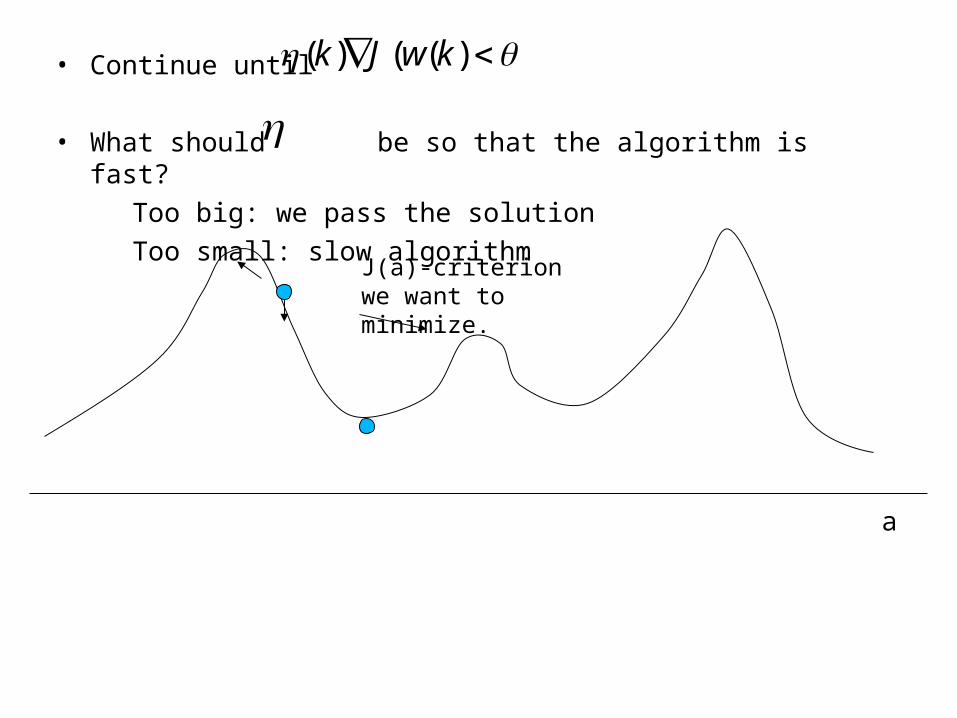
• Continue until
• What should be so that the algorithm is fast?Too big: we pass the solutionToo small: slow algorithm
a
)(()( kwJk
J(a)-criterion we want to minimize.

Perceptron Criterion Function
•Where Y is the set of misclassified samples. {Jp is proportional to the sum of distances of misclassified samples to the decision boundary.}
Hence
Batch Perceptron AlgorithmInitialize w, , k 0, θDo k k+1 w w+Until | |< θreturn w.
Yy
Tp ywwJ )()(
Yy
p yJ )(
Yy
kk ykww )(1
Sum of misclassified samples
Yk)( yk)(

Initial estimate
A solution
Second estimate

Assume linear separability.
PERCEPTRON LEARNINGAn iterative algorithm that starts with an initial weight vector and moves it back and forth until a solution is found, with a single sample correction.
w(2) w(1)
w(0)
R2
R1

Single Step Fixed-Increment Rule for 2-category CaseSTEP 1. Choose an initial arbitrary Wa(0).
STEP 2. Update Wa(k) {kth iteration} with a sample as follows (i’th sample from class 1)
If the sample , then
STEP 3. repeat step 2 for all samples until the desired inequalities are satisfied for all samples. - A positive scale factor that governs the stepsize. if fixed increment. We can show that the update of W tends to push it in the correct direction (towards a better solution).
11 CX i
0)()(
0)()()1(
11
1
ia
Ta
iaa
ia
Taa
aXkWXkW
XkWkWkW
22 CX i
0)()(
0)()()1(
22
2
ia
Ta
iaka
ia
Taa
aXkWXkW
XkWkWkW
k k

Multiply both sides with
•Rosenblatt found in 50’s.•The perceptron learning rule shown by Rosenblatt is to converge in a finite number of iterations.
EXAMPLE (FIXED INCREMENT RULE)Consider a 2-d problem where
Tia
Ta
Ta XkWkW 1)()1(
iaX1
ia
Ta
ia
Tia
ia
Ta
ia
Ta XkWXXXkWXkW 11111 )()()1(
+ve +ve
1131211
0
9,
1
5,
3
8CXXX
2232221
6
3,
3
0,
1
3CXXX

one solution
Augment X’s to Y’s
-10
-10
-5
10
10-5 5
5
x1
x2
6
5
2
112 xx
1
1
321aX
1
1
512aX
1
0
913aX
1
1
321aX
1
3
022aX
1
0
323aX
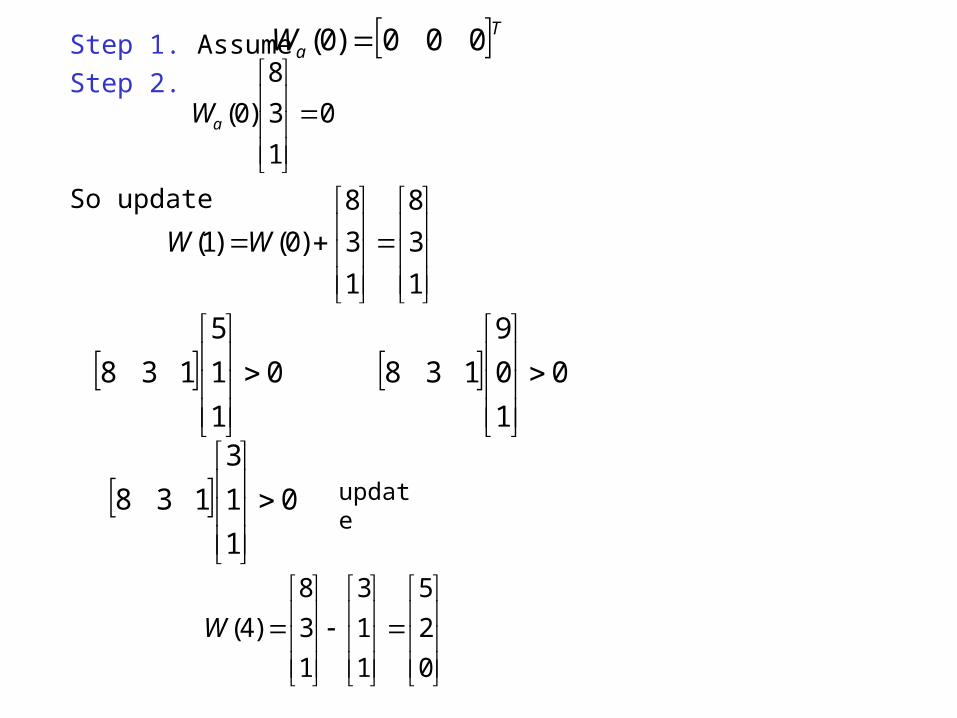
Step 1. AssumeStep 2.
So update
1
3
8
1
3
8
)0()1( WW
0
1
1
5
138
0
1
0
9
138
0
1
1
3
138
update
0
2
5
1
1
3
1
3
8
)4(W
TaW 000)0(
0
1
3
8
)0(
aW
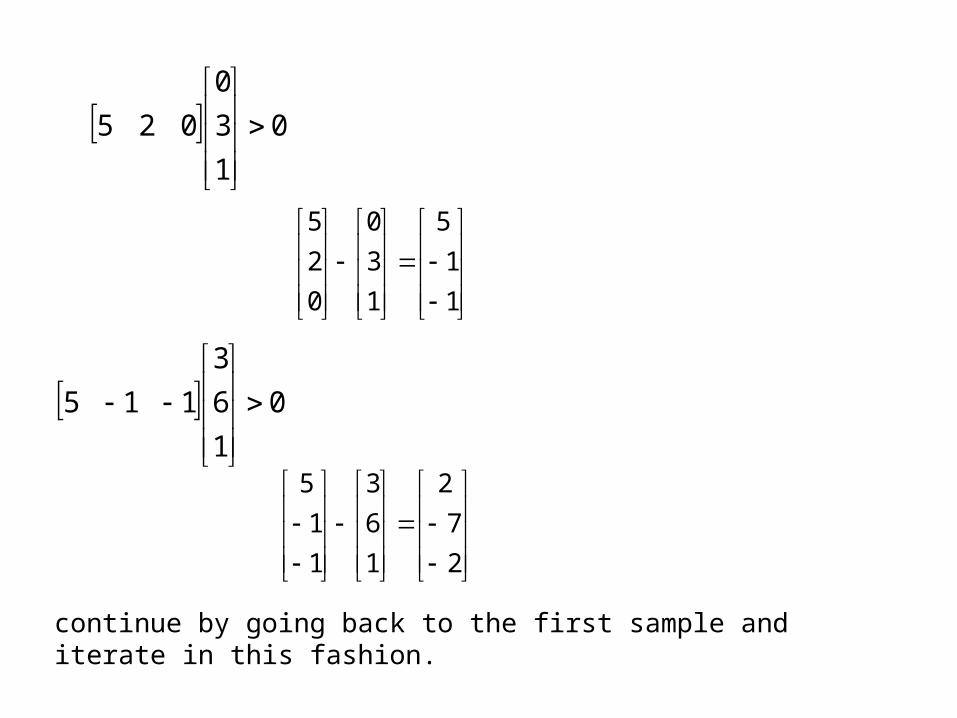
continue by going back to the first sample and iterate in this fashion.
0
1
3
0
025
1
1
5
1
3
0
0
2
5
0
1
6
3
115
2
7
2
1
6
3
1
1
5

SOLUTION:
Equation of the boundary: on the boundary.
Extension to Multicategory Case
Class 1 samples {Class 2 samples {
.
.Class c samples {
We want to find or correspondingso that
Twww
aW
021
563
0563)( 21 xxXg
111211 ......,........., nXXX222221 ......,........., nXXX
ccncc XXX ......,........., 21
nnnn c ........21 total number of samples
cgg ,,.........1 cWWW .........,, 21ikT
jikT
ii XWXWg
For all and ji ink 1

The iterative single-sample algorithm
STEP 1. Start with random arbitrary initial vectors
STEP 2. Update Wi(k) and Wj(k) using sample Xis as below:
Do for all j.STEP 3. Go to 2 unless all inequalities are satisfied and repeat for all samples.
)0(..,),........0(),0( 21 cWWW
otherwiseXkkW
XkWXkWkWkW
isi
isTj
isTii
i)()(
)()()1(
otherwiseXkkW
XkWXkWkWkW is
j
isTj
isTij
j )()(
)()()1(

GENERALIZED DISCRIMINANT FUNCTIONS
When we have nonlinear problems as below:
Then we seek for a higher degree boundary.Ex: quadratic boundary
will generate hyperquadratic boundaries.g(X) still a linear function w’s.
0)( wxwxxwXg iijiij
aTaa YWYg )(

Then, use fixed increment rule as before using and as above.EXAMPLE: Consider 2-d problem, a general form for an ellipse.
so update your samples as Ya and iterate as before .
1
.
.
......1
2
21
21
011211
n
nn
x
x
x
xx
x
wwwww
aW
aY
aW aY
02222
2111)( wxwxwXg
1
)( 22
21
02211 x
x
wwwXg

Variations and Generalizations of fixed increment rule Rule with a margin Non-seperable case: higher degree perceptrons : Neural Networks Non-iterative procedures: Minimum-squared Error Support Vector Machines
Perceptron with a marginPerceptron finds “any” solution if there’s one.
Solution region with margin b
b

•A solution can be very close to some samples since we just check if
•But we believe that a plane that is away from the nearest samples will generalize better (will give better solutions with test samples) so we put a margin b we say
•Restricts our solution region.
•Perceptron algorithm can be modified to replace 0 with b.•Gives best solutions if the learning rate is made variable and
•Modified perceptron with variable increment and a margin:-if thenShown to converge to a solution W.
0)( kT
k XWXg
bXW kT ))(( wrXg
Distance from the separating plane
kk
1~)(
bXW kT kXkWW )(

NON-SEPARABLE CASE-What to do?Different approaches
1- Instead of trying to find a solution that correctly classifies all the samples, find a solution that involves the distance of “all” samples to the seperating plane.
2-It was shown that we can increase the feature space dimension with a nonlinear transformation, the results are linearly separable. Then find an optimum solution.(Support Vector Machines)3. Perceptron can be modified to be multidimensional –Neural Nets
-
Instead ofFind a solution towhere (margin)
0iTYW
iiT bYW
0ib

Minimum-Squared Error ProcedureGood for both separable and non-separable problems for the ith sample where Yi is the augmented feature vector.
Consider the sample matrix
Then AW=B
cannot be solved since many equations, but not enough unknowns. (many solutions exist;more rows than columns)So find a W so that is minimized.
iiT bYW
Tn
T
T
Y
Y
Y
A.2
1
(For n samples A is dxn))
nb
b
b
B.2
1
BAW

Well-known least square solution (from the gradient and set it zero)
B is usually chosen as
B= [1 1…........ 1]T (was shown to approach Bayes discriminant when )
BAAAW TT 1
BA
Pseudo-inverse if ATA is non-singular (has an inverse)
n