lucenerdd for (geospatial) search and entity linkage
TRANSCRIPT

LuceneRDD Entity Linkage & (Spatial) Search
Anastasios Zouzias ScalaIO @ Lyon 2016

* Data Scientist @ Swisscom, CH: Mobility Insights Team* Researcher @ IBM Research, Zurich: Machine
Learning & Search Engineer * PhD in Univ. of Toronto: ML & Randomized Algorithms * Scala Developer (day job): 2-3 years * Apache Solr / Elasticsearch developer: 3+ years
About myself

How many of you have used Spark?

Apache Spark
RDD (Resilient Distributed Dataset)Distributes data over multiple nodes
Executor #1
…
Spark Master Executor #2
Executor #n
[Paris] [Bern]
[Athens]
[Ottawa] [Warsaw] [Rome]
[Zagreb] [Lisbon] [Dublin]
…
RDD“Spark Driver”

How many of you have used
Lucene/Solr/Elastic?

Apache Lucene
* Lucene is a powerful Java search library that lets you easily do search or Information Retrieval (IR)
* Used by LinkedIn, Twitter, and many more… * Scalable and High-performance indexing * Powerful, Accurate and Efficient Search algorithms

LuceneRDDWhat is it?
Open-source projecthttps://github.com/zouzias/spark-lucenerdd
Spark:Partitioning / distribution
of queries / data
Lucene:Indexing / querying
data (single partition)
LuceneRDD:Query / dispatch /
aggregation of data

MotivationWhy LuceneRDD exists?
* Natively support of full-text / spatial search in Spark(without external Elastic/Solr cluster)
* Scalable Entity Linkage (approx. join) with Spark & Lucene * Personal: Better understanding of Spark’s Internals (RDDs) * Personal: Better understanding of Scala (implicits)
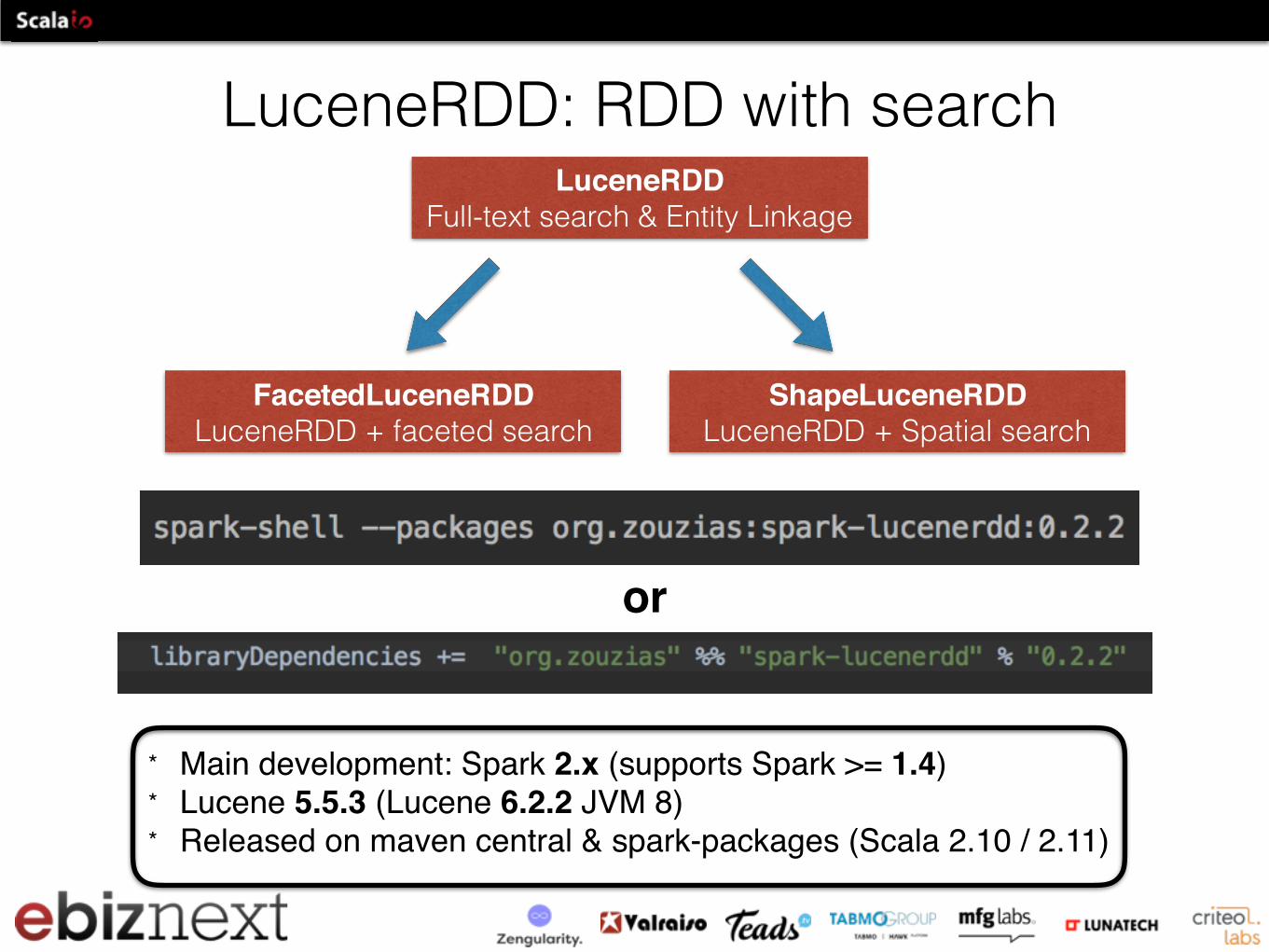
LuceneRDD: RDD with searchLuceneRDD
Full-text search & Entity Linkage
FacetedLuceneRDDLuceneRDD + faceted search
ShapeLuceneRDDLuceneRDD + Spatial search
* Main development: Spark 2.x (supports Spark >= 1.4)* Lucene 5.5.3 (Lucene 6.2.2 JVM 8)* Released on maven central & spark-packages (Scala 2.10 / 2.11)
or

LuceneRDD
Main ideaIndex RDD partition data with
distributed Lucene index (inverted index per partition)
Index
Index
Index
…
LuceneRDD
Executor #1
…
Spark Master
Executor #2
Executor #n
[Paris] [Bern]
[Athens]
[Ottawa] [Warsaw] [Rome]
[Zagreb] [Lisbon] [Dublin]
…
RDD
Index storage disk or memory

Index
Index
Index
…
LuceneRDDDataFrame to LuceneRDD*
Executor #1
…
Spark Master
Executor #2
Executor #n
[Paris] [Bern]
[Athens]
[Ottawa] [Warsaw] [Rome]
[Zagreb] [Lisbon] [Dublin]
…
RDD/DataFrame
Language analyzers, i.e., French, English etc.. are
configurable
Language analyzers, i.e., French, English etc.. are
configurable

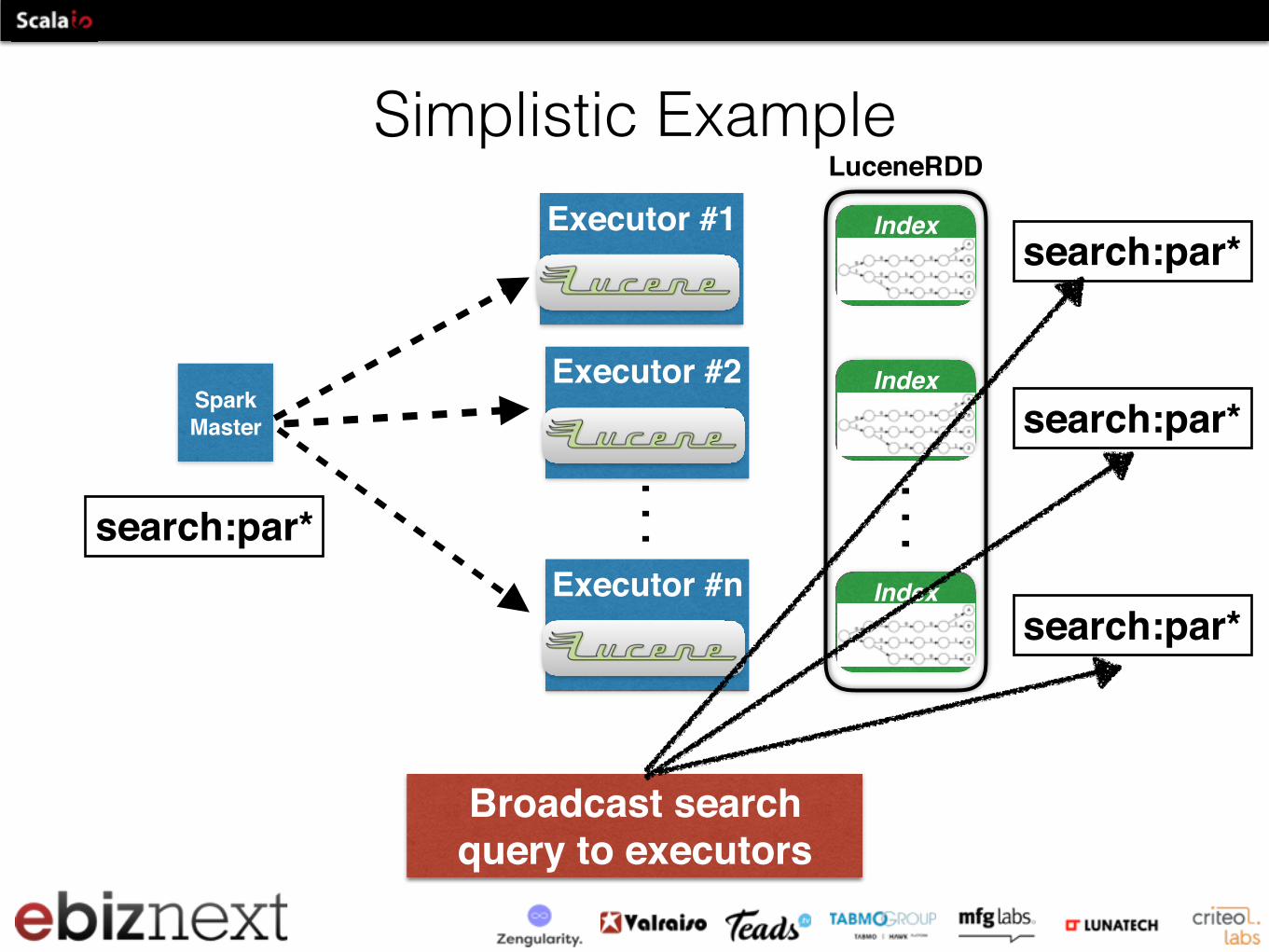
Simplistic ExampleExecutor #1
…
Spark Master
Executor #2
Executor #nsearch:par*
Index
Index
Index
…
LuceneRDD
[Paris] [Bern]
[Athens]
[Ottawa] [Warsaw] [Rome]
[Zagreb] [Lisbon] [Dublin]
…
RDD
Executor #1
…
Spark Master
Executor #2
Executor #n
Broadcast search query to executors
Index
Index
Index
…
LuceneRDD
search:par*
search:par*
search:par*
search:par*
Simplistic Example

Executor #1
…
Spark Master
Executor #2
Executor #n
Lucene prefix Search on each partition
Index
Index
Index
…
LuceneRDD
search:par*
List(Paris)
List()
List()
…
LuceneRDDResponse
topK results / partition
Simplistic Example
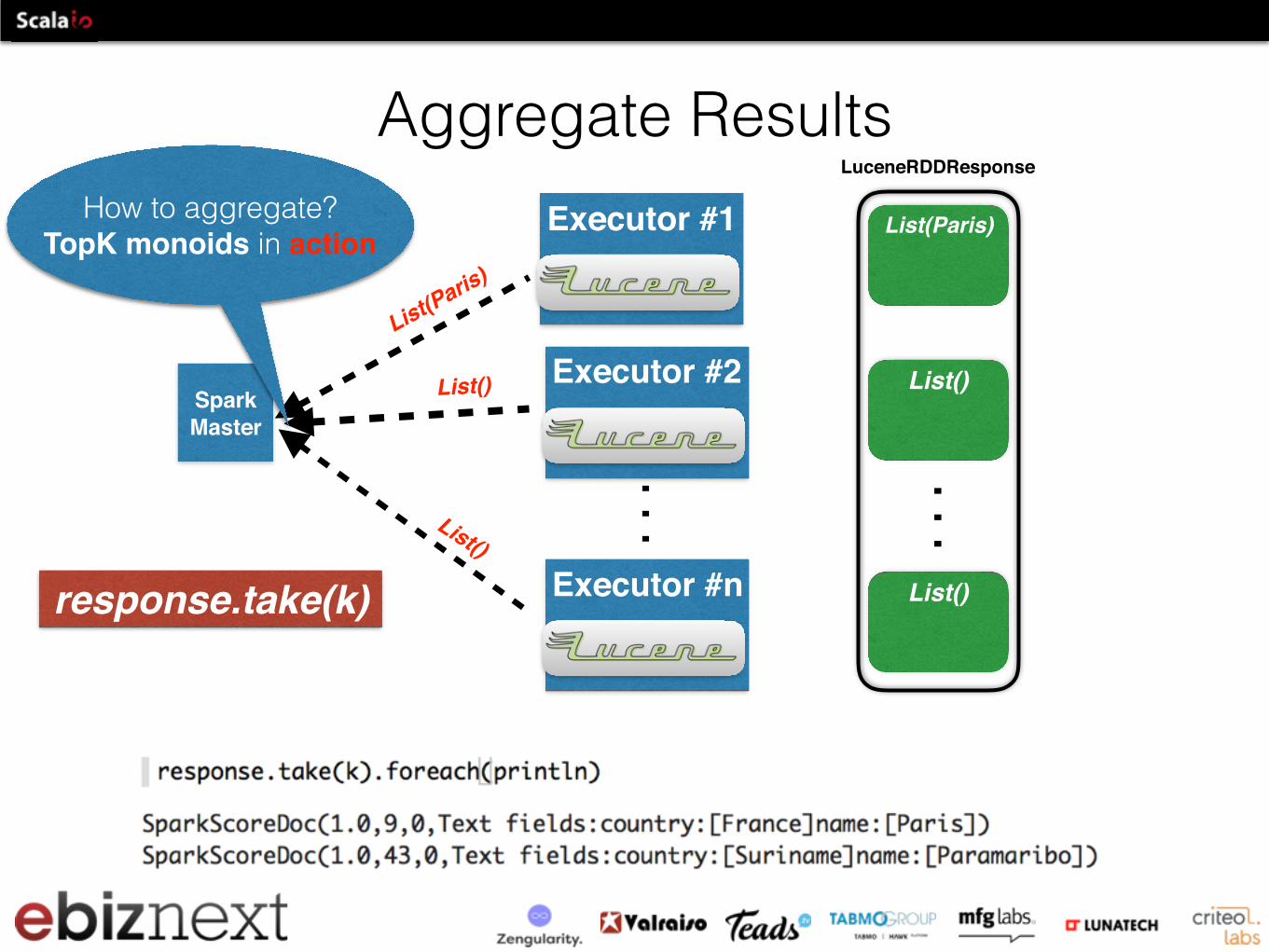
Aggregate ResultsExecutor #1
…
Spark Master
Executor #2
Executor #n
List(Paris)
List()
List()
…
LuceneRDDResponse
response.take(k)
List(Paris)
List()
List()
How to aggregate? TopK monoids in action

LuceneRDDResponse
TopKMonoid((0.8, Paris), (0.7, Result2), (0.6, Result3))
TopKMonoid((0.71, XXX), (0.35, YYY), (0.25, ZZZ))
TopKMonoid((0.12, XXX), (0.09, YYY), (0.05, ZZZ))
Executor #1
…Spark Master
Executor #2
Executor #n
List(Paris)
List()
List()+
=
+
TopK Sorted Scored Results
Twitter’s Algebird TopKMonoid
Aggregate Results

Executor #1
…
Spark Master
Executor #2
Executor #n
List(Paris)
List()
List()
…
LuceneRDDResponse
LuceneRDDResponse.take(k)
List(Paris)
List()
List()

LuceneRDD Operations
ShapeLuceneRDDLuceneRDD + Spatial search
FacetedLuceneRDDLuceneRDD + faceted search
Flexible multi-fields query: term/Fuzzy/Prefix/etc sub-queries
+ boolean queries

Entity Linkage a.k.a. approximate join

Join left & right dataset according to a “similarity”
(NO ids available)
Left Dataset Right DatasetEntity Linkage (approx. join)
?
Simplicity: one-to-one linkage

Left Dataset Right DatasetEntity Linkage (approx. join)
?
Naive approachCompute pairwise scores does not scale: O(n2)
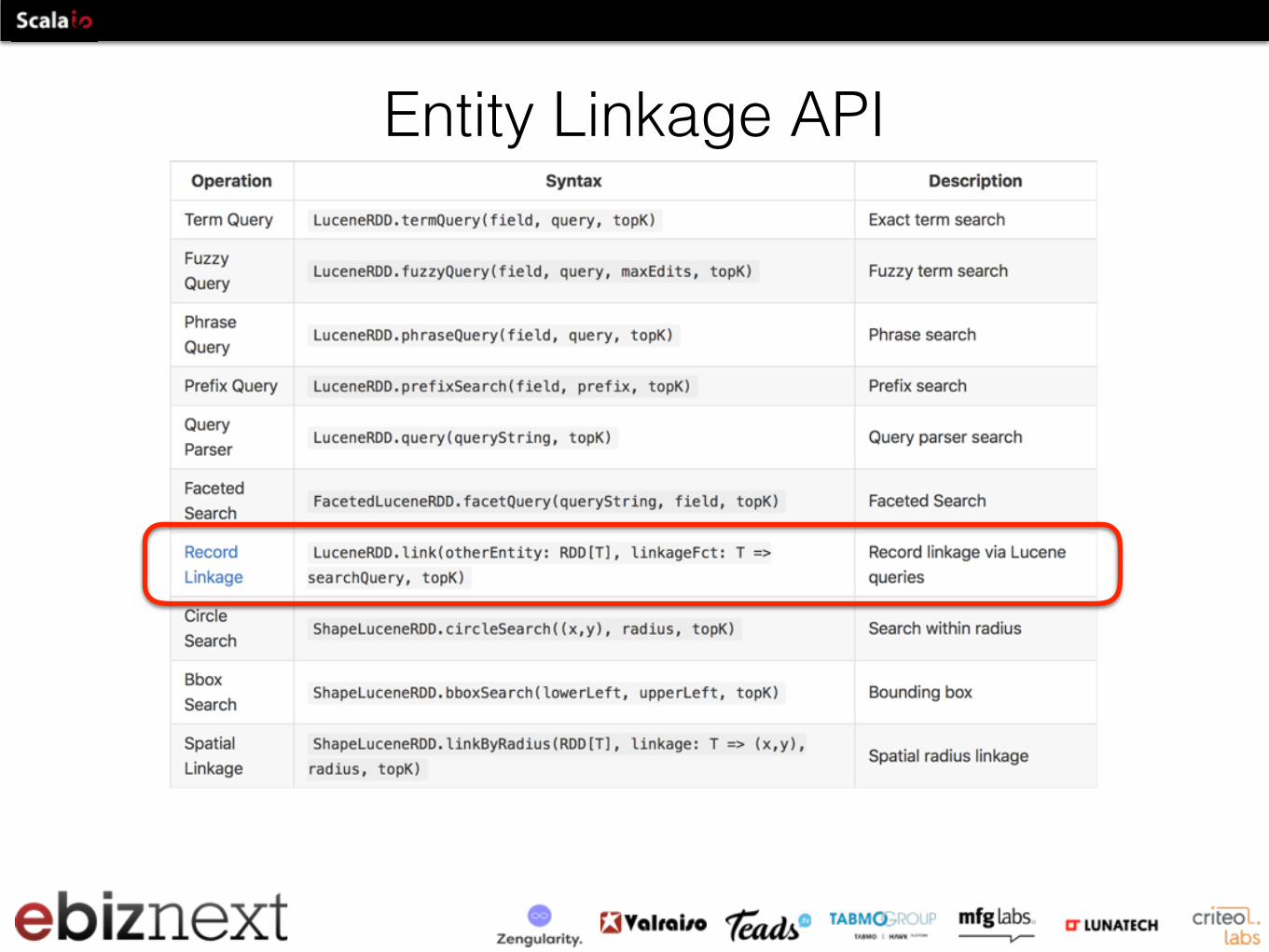
Entity Linkage API

LuceneRDD Approximate Join1) Index right dataset using LuceneRDD 2) Define “search similarity function” between each left entity &
right dataset 3) For every left entity, search & zip using topK results
Index
Index
Index
…
LuceneRDD

LuceneRDD Entity Linkage1) Index right dataset using LuceneRDD 2) Define “search similarity function” between left & right dataset 3) For every left entity, search & zip by search similarly
Index
Index
Index
…
LuceneRDD
List(“name:james")
List(“name:joel")
List(“name:ram")
…
RDD[String]
Spark Master
(3b)
Col
lect
& b
road
cast
(RD
D[S
trin
g])
(3a)
Map
to s
earc
h qu
erie
s

LuceneRDD: linkage codeQuery each partition and zip query with topK results
Reduce topK monoids per query
Map each left entity to search query & broadcast to
each partition

Does LuceneRDD approx. join scale?
https://github.com/zouzias/spark-lucenerdd-aws
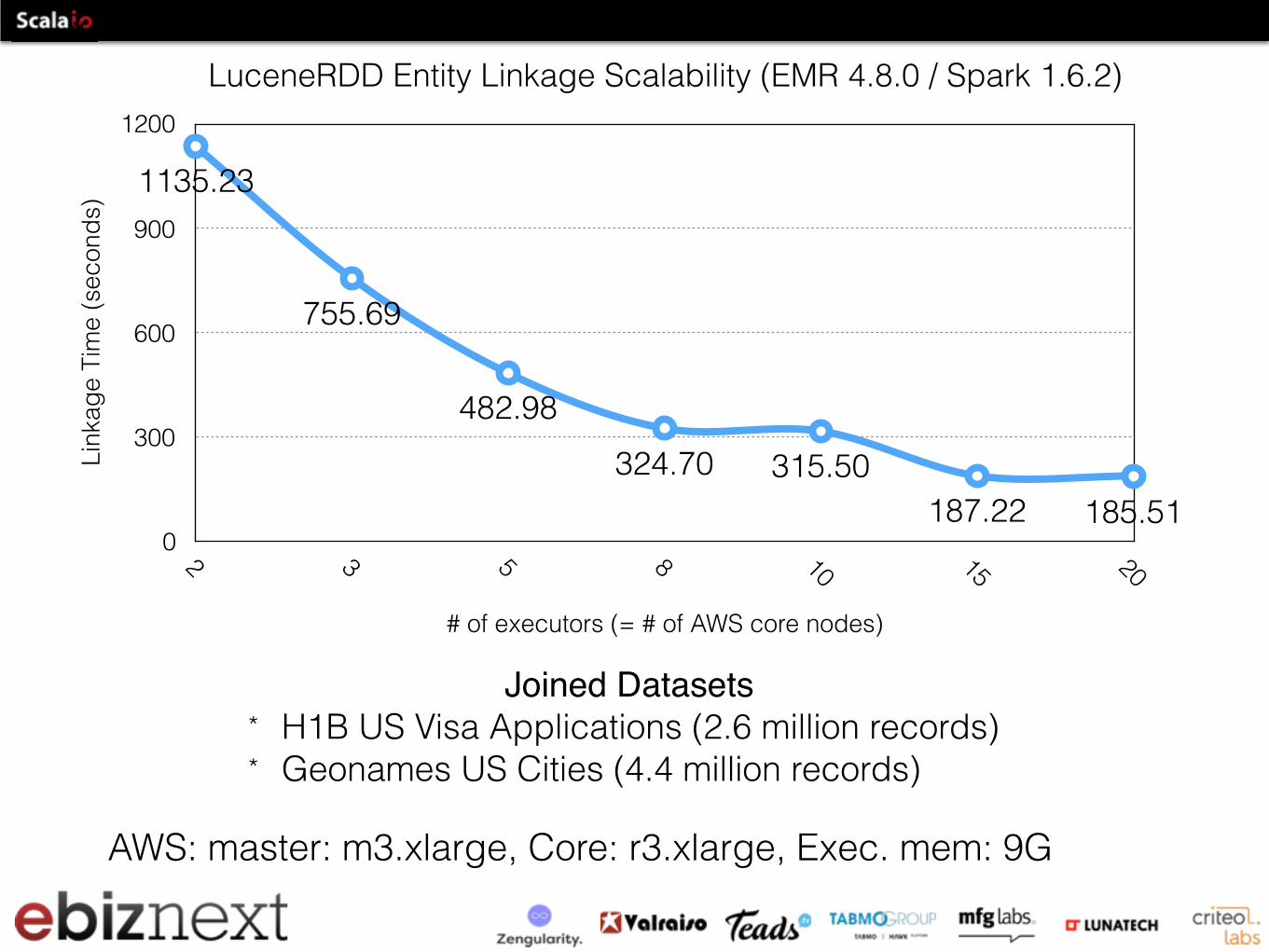
LuceneRDD Entity Linkage Scalability (EMR 4.8.0 / Spark 1.6.2)Li
nkag
e Ti
me
(sec
onds
)
0
300
600
900
1200
# of executors (= # of AWS core nodes)
2 3 5 8 10 15 20
1135.23
755.69
482.98324.70 315.50
187.22 185.51
AWS: master: m3.xlarge, Core: r3.xlarge, Exec. mem: 9G
Joined Datasets* H1B US Visa Applications (2.6 million records) * Geonames US Cities (4.4 million records)

Demo LuceneRDD Linkage API
(ACM vs DBLP research articles)
https://github.com/zouzias/spark-lucenerdd-examples
Köpcke, H.; Thor, A.; Rahm, E. Evaluation of entity resolution approaches on real-world match problems Proc. 36th Intl. Conference on Very Large Databases (VLDB), 2010
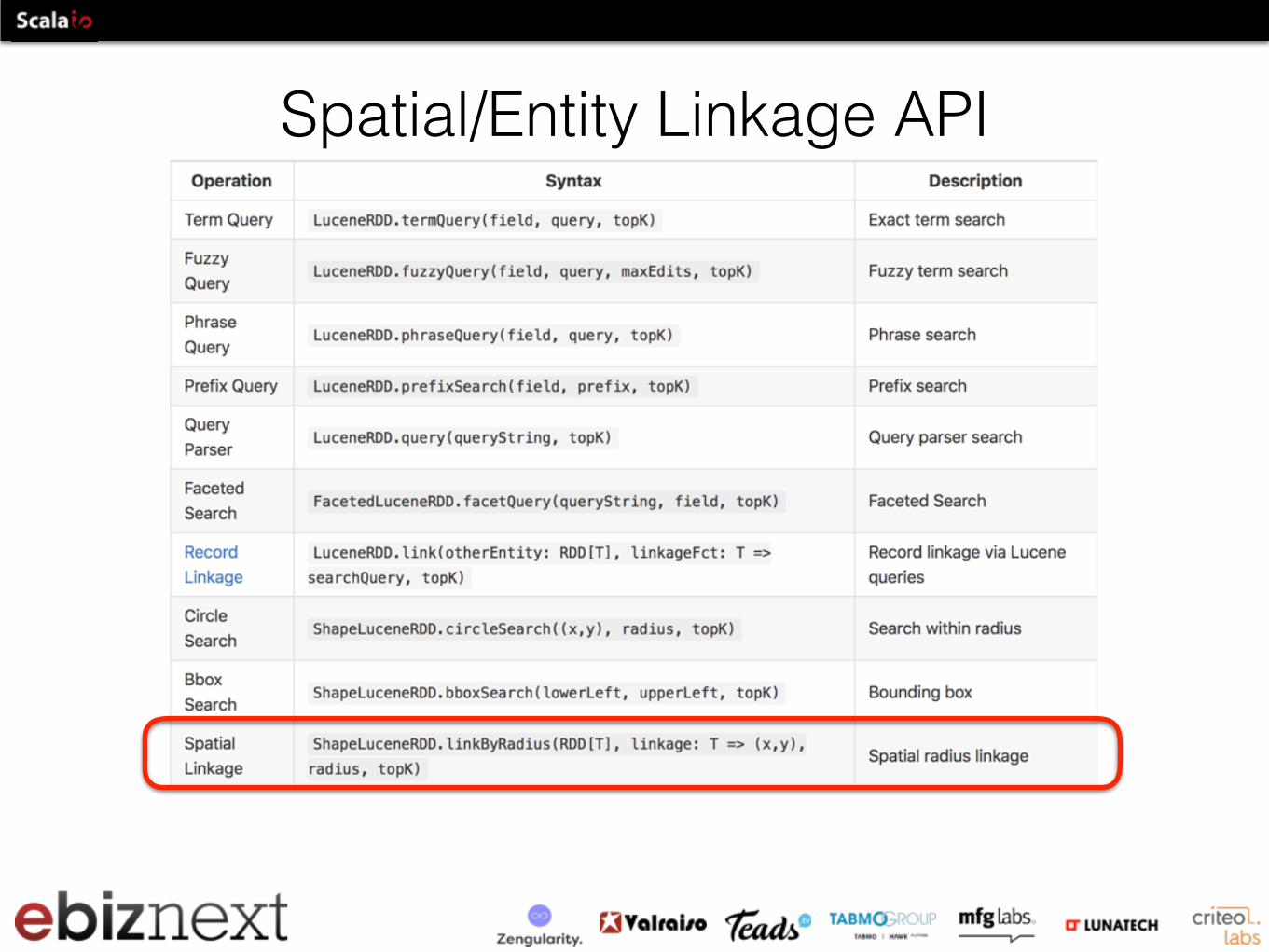
Spatial/Entity Linkage API

Demo ShapeLuceneRDD Linkage
(Country polygons vs Capital points)
https://github.com/zouzias/spark-lucenerdd-examples

Future Work
* Contributors / use cases are welcome! * More performance tests with approx. join * Spatial-linkage performance tests using
open Street Map data * Bypass the collect-broadcast Spark pattern?

Merci pour votre attention! Questions?

Elastic/SolrCloud ConnectorExecutor
#1
…
Executor #2
Executor #n
Driver
Cluster
Node 1
/
Node 2
/
Node m
/
…
Limitations - m is fixed & (usually) small compared to n- additional network communication: execs & elastic/solr