li tak sing comps311f. xml markup languages many people might not realize that there were markup...
TRANSCRIPT

Li Tak Sing
COMPS311F

XMLMarkup languages
Many people might not realize that there were markup languages even before computers were invented. What we refer to as a markup language consists of symbols used to annotate texts in documents. For example, in the early days of printing, authors prepared manuscripts of their books on papers. Proofreaders and editors marked on the manuscripts with a markup language that the people working in print shops understood. The symbols in this type of markup language would not actually appear in the resulting books, but they gave instructions on how to present the texts.

XMLHTML is a modern markup language that
deals with how data should be displayed on a Web browser. HTML does this by enclosing texts in begin and end tags. This is a sample HTML document. <h3>Sample HTML</h3> <p>I am the <b>first</b> paragraph. I have two sentences.</p> <p>I am the <i>second</i> paragraph. I am longer than the first paragraph. I have three sentences.</p>

HTMLIn the sample, we have the begin tags for
level 3 heading <h3>, paragraph <p>, bold font <b> and italics font <i>. There are corresponding end tags with an extra slash / like </h3>, </p>, </b> and </i>. Note that the tags may be nested. For example, the pair of bold tags can be placed inside paragraph tags. The sample HTML document displays on Mozilla Firefox as follows.

XML basicsSo what exactly is XML? XML stands for
Extensible Markup Language. It has been defined by the World Wide Web Consortium (W3C) with design goals including, but not limited to, the following:
• Compatible with the Internet • Useful for a wide range of applications • Easy to create and process • Readable by humans.

XML basicsAn XML document is very useful. It can hold
the data for a purchase order, an invoice, an employment application, a price list, a collection of music CDs or many other kinds of data. Below is a sample XML document, but keep in mind that XML documents found in the real world may be larger than the samples you see in this unit.

XML basics<?xml version="1.0" encoding="ISO-8859-1"?> <employee-list> <employee> <name>John</name> <hours>40</hours> <rate>30</rate> </employee> <employee> <name>Mary Lou</name> <hours>30</hours> <rate>35</rate> </employee> </employee-list>

Processing instructionsThe first line is a processing instruction enclosed
with <? and ?>. It captures the XML version number and the character set used. If you are using an XML tool to assist your creation of XML documents, the tool will generate their values for you according to the tool’s current configuration.
Other processing instructions are allowed. In general, processing instructions provide information to applications to help them process XML documents. For example, stylesheet information may be provided to help applications correctly interpret the XML documents.

ElementsAn element is enclosed in a pair of begin and
end tags. For instance, in the previous XML document, we have a begin tag <employee-list> and an end tag </employee-list>. The end tag looks just like the begin tag except for the extra slash. The employee-list element is the root element of this XML document. It has a child element employee which in turn has child elements name, hours and rate. The data can be used to calculate the weekly payroll. We see that elements in XML documents can nest and repeat.

ElementsThis document has elements named employee-list,
employee, name, hours and rate. Element names are case sensitive in XML. Therefore </Rate> is not the proper end tag for the begin tag <rate> due to the unmatched case in the first character of the tag name.
The first character of an element name can be any letter from the alphabet or an underscore. The remaining characters can be alphanumeric, hyphens, underscores and even periods. Spaces are allowed in the content of an element as in the following element. <name>Mary Lou</name>
Spaces are not permitted inside an element name. Therefore the following is not allowed. <number of hours>30</number of hours>
After replacing spaces with hyphens or underscores, the following is allowed. <number_of_hours>30</number_of_hours>

Empty elementsYou can use an empty element to
represent that the item is unknown or not applicable. An empty element for a commission element can be represented in one of three ways. <commission></commission> <commission/> <commission />

WhitespacesThe characters for spaces, line feeds, tabs
and carriage returns are collectively called whitespaces. In XML adjacent whitespaces inside a pair of begin and end tags are significant. The following three elements are different unless programmers make the decision to treat them the same. <name>Oliver Au</name> <name>Oliver Au</name> <name>Oliver
Au</name>

WhitespacesOn the other hand, whitespaces outside of a
pair of begin and end tags are insignificant. <hours>30</hours>
<rate>35</rate>The above and the following are the same in
XML. <hours>30</hours> <rate>35</rate>
In HTML however, two or more consecutive whitespaces are always treated the same as one whitespace.

Entity referencesCan you spot a problem with the following
element? <condition> 3 < 5 </condition>

Entity referencesThe content of the element is a Boolean
expression that makes use of the less than operator < which is also the first character of a tag. XML processing applications are built to be precise. Using the same symbol < as the less than operator and the beginning character of a tag is a source of confusion. To avoid problems, we replace the character with its entity reference in the Boolean expression.
<condition> 3 U+003C 5 </condition>

Entity referencesCharacher unicode in XML DTD name
& U+0026 &
< U+003C <
> U+003E >
" U+0022 "
' U+0027 '

XML attributesAn element can have any number of
attributes. The following is an element that captures the year of publication of an attribute.
<PUBLISHED year="2002">Wiley</PUBLISHED>
This is another difference between HTML and XML. The double quotes around an attribute value, as in "2002", are optional in HTML but are compulsory in XML.

XML parsersThe meaning of a sentence is not determined only
by the words used. We often have to determine the sentence structure before we can correctly understand the sentence. In computer science and linguistics, parsing is the process of recognizing the structure of a program, an HTML document, an XML document or an English sentence.
A program that performs this task is called a parser. All the popular Web browsers have a built-in XML parser. Even the programs that you write to process XML documents for a course assignment are also XML parsers. Fortunately, you don’t have to build the parsing capability from scratch as it comes with Java’s class library.

XML namespacesXML elements have names. When an
application processes two or more kinds of XML documents, there may be element name conflicts. Suppose we have an XML document holding the information of some fruit. <table> <row> <column>Apples</column> <column>Oranges</column> </row> </table>

We have another XML document holding the information of a piece of furniture. <table> <name>Oak Dining Table</name> <width>100</width> <length>220</length> </table>

XML namespacesIf we were to merge the two XML documents as
one, XMP parsers trying to process the merged document will be confused. The element name table is used for different purposes under distinct structures. We can use qualified names to prevent confusion. In the following merged XML document, h and furn are local names. We qualify the local names with an optional prefix xmlns which stands for XML name space. Other prefixes are also allowed. The qualified name say xmlns:h is defined as a uniform resource identifier (URI) which is a character string identifying an Internet resource. An XML parser would not actually access the URI which just uniquely identifies a qualified name.

XML namespaces<h:table
xmlns:h="http://www.mycompany.com/fruits"> <h:row> <h:column>Apples</h:column> <h:column>Oranges</h:column> </h:row> </h:table> <furn:table xmlns:furn="http://www.mycompany.com/furniture"> <furn:name>Oak Dining Table</furn:name> <furn:width>100</furn:width> <furn:length>220</furn:length> </furn:table>

XML namespacesPrefixes and namespaces can be defined
for elements at any level. Once defined, the prefixes can be used in the child elements. You can also define two prefixes in one element as shown in the root element below.

<?xml version="1.0" encoding="utf-8"?> <root xmlns:h=”http://www.mycompany.com/fruits” xmlns:furn="http://www.mycompany.com/furniture"> <h:table> <h:row> <h:column>Apples</h:column> <h:column>Oranges</h:column> </h:row> </h:table> <furn:table>
<furn:name>Oak Dining Table</furn:name> <furn:width>100</furn:width> <furn:length>220</furn:length> </furn:table> </root>

Default namespace Having to repeat the prefix on each tag is a
tedious chore. An alternative is to define a default namespace as follows without the local names of h or furn. Prefixes are not required for the distinction.

Default namespace <?xml version="1.0" encoding="utf-8"?>
<root> <table xmlns="http://www.mycompany.com/fruits"> <row> <column>Apples</column> <column>Oranges</column> </row> </table> <table xmlns="http://www.mycompany.com/furniture"> <name>Oak Dining Table</name> <width>100</width> <length>220</length> </table> </root>

An XML document of library booksThis XML document uses a popular and
space efficient character set utf-8 which employs 1 byte to represent commonly used characters and more bytes for others like Chinese characters. It has the advantage of being backward compatible with the original ASCII character set. The document demonstrates the use of attributes and comments.

An XML document of library books <LIBRARY>
<BOOK> <TITLE>Complete idiot's guide to XML</TITLE> <AUTHOR> <FIRST-NAME>David</FIRST-NAME> <LAST-NAME>Gulbransen</LAST-NAME> </AUTHOR> <PUBLISHED place="Indianapolis" year="2000">Que</PUBLISHED> </BOOK> <!-- Note that the following book has two authors --> <BOOK> <TITLE>Java developer's guide to e-commerce with XML and JSP</TITLE> <AUTHOR> <FIRST-NAME>William B.</FIRST-NAME> <LAST-NAME>Brogden</LAST-NAME> </AUTHOR> <AUTHOR> <FIRST-NAME>Chris</FIRST-NAME>

An XML document of library books <LAST-NAME>Minnick</LAST-NAME> </AUTHOR>
<PUBLISHED place="" year="2001">Sybex</PUBLISHED> </BOOK> <BOOK> <TITLE>XPath essentials</TITLE> <AUTHOR> <FIRST-NAME>Andrew</FIRST-NAME> <LAST-NAME>Watt</LAST-NAME> </AUTHOR> <PUBLISHED place="New York" year="2002">Wiley</PUBLISHED> </BOOK> </LIBRARY>

XML versus HTML Due to their similar appearance and shared
lineage, people often like to compare XML with HTML. It is true that both are captured in plain texts that can be edited with an ordinary editor and that their elements are enclosed in begin and end tags. But they also have important differences. The following table summarizes the differences between the two.

A comparison between HTML and XMLXML HTML
Emphasizes data contents Emphasizes data display
Allows customized tags Only allow pre-defined tags
Tages are case-sensitive Tages are not case-sensitive
Multiple adjacent whitespaces in an element content are different from a single whitespace
Multiple adjacent whitespaces in an element content are the same as a single whitespace
Double quotes around attribute values are compulsory
Double quotes around attribute values are optional
Processed by tailor-made programs as well as generic XML parsers
Processed mainly by standard Web browsers

MetalanguagesA metalanguage is a language used to describe
another language. Though XML is precise, it is also generic enough to allow many different documents to be syntactically correct. These documents are said to be well formed. For different applications, XML documents hold different kinds of data in different document structures. If one computer program produces XML documents for another program to process, the two programs must agree on the same document structure. A metalanguage
builds on top of XML syntax to further describe the structure of the documents for the two programs to share. Starting in the next section, we will study two representative metalanguages Document Type Definition
(DTD) and XML Schema Definition (XSD).

Document Type Definition (DTD) Many metalanguages have been used to
specify XML document structures. DTD was the first such language proposed and it is still taught and used today. However, the popularity of DTD has been overtaken by a more powerful alternative called XML Schema. Our coverage on DTD will therefore be relatively brief.

Referring to a DTD file Following is anemployee-list with a <!
DOCTYPE> declaration added. The first word after the DOCTYPE keyword must be the name of the root element which in our case is employee-list. In this declaration, we specify "employee-list.dtd" as the file to hold the allowed syntax for the employee-list element. We use the SYSTEM keyword to indicate that the DTD file is defined by ourselves. An alternative PUBLIC keyword may be used but it is not applicable to us in this course.
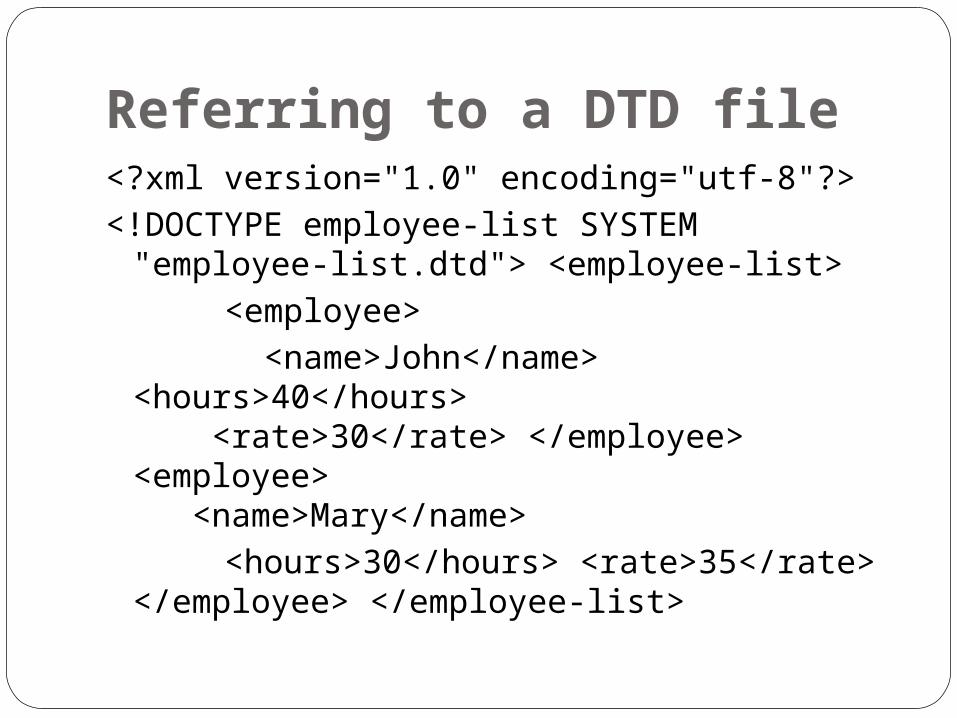
Referring to a DTD file <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE employee-list SYSTEM
"employee-list.dtd"> <employee-list> <employee> <name>John</name>
<hours>40</hours> <rate>30</rate> </employee> <employee> <name>Mary</name>
<hours>30</hours> <rate>35</rate> </employee> </employee-list>

Referring to a DTD file Without any path information, the DTD file is
assumed to be in the same directory as the XML file. We could use one of the following declarations which specify a DTD file with a relative path, an absolute path and a URL respectively. The double-dot .. in the relative path stands for the parent directory.
<!DOCTYPE employee-list SYSTEM "../employee-list.dtd"> <!DOCTYPE employee-list SYSTEM "c:/MT311 Development/employee-list.dtd"> <!DOCTYPE employee-list SYSTEM "http://www.mysite.com/files/employee-list.dtd">

Defining elements in DTD The following is the content of the
employee.dtd file with five declarations. An <!ELEMENT> declaration has two pieces of information. The first one is the name of the element being defined. The second one is an expression that defines the element. <?xml version="1.0" encoding="utf-8"?> <!ELEMENT employee-list (employee*)> <!ELEMENT employee (name, hours, rate)> <!ELEMENT name (#PCDATA)> <!ELEMENT hours (#PCDATA)> <!ELEMENT rate (#PCDATA)>

Defining elements in DTD The first <!ELEMENT> declaration in
employee.dtd defines an employee-list as zero or more employee elements using a trailing asterisk. (employee*) The second <!ELEMENT> declaration defines employee as a sequence of name, hours and rate with commas. (name, hours, rate) The remaining <!ELEMENT> declarations define individual elements name, hours and rate as parsed character data denoted by #PCDATA.

Repetitions in DTD The following are the characters you can
place after an element in an expression to denote repetitions.
Symbol Meaning
* Zero or more times
+ One or more times
? Zero or one time

Choices in DTDAn element can be defined as one of
several things. For example, a vehicle element may be defined as a motorcycle, car, van or truck. We use vertical strokes to separate choices. <!ELEMENT vehicle (motorcycle | car | van | truck)>

Attributes in DTDThe following is the PUBLISHED element you
saw earlier with two attributes.
<PUBLISHED place="Indianapolis" year="2000">Que</PUBLISHED> We can use an <!ATTLIST> declaration to define the list of attributes allowed in an element. If we want to allow two attributes place and year in the PUBLISHED element, we use the following declaration. <!ATTLIST PUBLISHED place CDATA #REQUIRED year CDATA "2000">

Both attributes hold CDATA which stands for character data. The place attribute is required in the PUBLISHED element thus we use #REQUIRED. The year attribute has a default value of "2000" if not specified. Here are some additional options for attributes that could be used.
Option Meaning
#REQUIRED Attribute values must specified in the XML element
#IMPLIED Attribute values are optional in the XML element
"default value" Attributes will have the default value if ommitted.
#FIXED "fixed value" Attributes have the fixed values

Drawbacks of DTD DTD itself does not follow XML syntax, which
means that people using DTD have to learn a separate set of rules in addition to the XML rules. In addition, DTD has a rather limited set of data types. We cannot allow data more details than #PCDATA. For example, even integer data can only be defined as #PCDATA. The ways to construct complex elements are limited to simple sequence, repetitions and choices. For example, we will have an awkward definition to specify the course workload of a full-time student as three to six courses.

Drawbacks of DTD Finally, DTD does not support reuse. If two
elements have a similar structure, their structures must be repeated at the top-level as follows. <!ELEMENT Student (Name, Id, Address, Phone, Courses+)> <!ELEMENT Tutor (Name, Id, Address, Phone, Courses+)>