lawrence hunter, ph.d. director, computational bioscience program university of colorado school of...
TRANSCRIPT

Lawrence Hunter, Ph.D.Director, Computational Bioscience ProgramUniversity of Colorado School of Medicine
[email protected]://compbio.uchsc.edu/Hunter
Molecular Biology Databases

Tour of the major molecular biology
databases• A database is an indexed collection of
information• There is a tremendous amount of
information about biomolecules in publicly available databases.
• Today, we will just look at some of the main databases and what kind of information they contain.

Data about Databases
• Nucleic Acids research publishes an annual database issue. 2009 issue lists 1170 editorially selected databases (link on course web site)
• Small excerpt from the A's:– AARSDB: Aminoacyl-tRNA synthetase
sequences– ABCdb: ABC transporters– AceDB: C. elegans, S. pombe, and human
sequences and genomic information– ACTIVITY: Functional DNA/RNA site activity– ALFRED: Allele frequencies and DNA
polymorphisms

Located Sequence Features
• Indexing relevant data isn’t always easy– Naming schemes are always in flux, vary across
communities, and are often controversial. – Descriptions of phenotypes are very difficult to
standardize (even many clinical ones)• Genome sequences provide a clear
reference– A “located sequence feature” (place on a
chromosome) is unambiguous and biologically meaningful
– Closely related to the molecular concept of a gene.

What can be discovered about a gene by a database search?
• Best to have specific informational goals:– Evolutionary information: homologous genes,
taxonomic distributions, allele frequencies, synteny, etc.
– Genomic information: chromosomal location, introns, UTRs, regulatory regions, shared domains, etc.
– Structural information: associated protein structures, fold types, structural domains
– Expression information: expression specific to particular tissues, developmental stages, phenotypes, diseases, etc.
– Functional information: enzymatic/molecular function, pathway/cellular role, localization, role in diseases

Using a database• How to get information out of a database:
– Summaries: how many entries, average or extreme values; rates of change, most recent entries, etc.
– Browsing: getting a sense of the kind and quality of information available, e.g. checking familiar records
– Search: looking for specific, predefined information
• “Key” to searching a database:– Must identify the element(s) of the database
that are of interest somehow:• Gene name, symbol, location or other identifying
information.• Sequences of genes, mRNAs, proteins, etc.• A crossreference from another database or database
generated id.

Searching for informationabout genes and their
products• Gene and gene product databases are
often organized by sequence– Genomic sequence encodes all traits of an
organism. – Gene products are uniquely described by their
sequences.– Similar sequences among biomolecules
indicates both similar function and an evolutionary relationship
• Macromolecular sequences provide biologically meaningful keys for searching databases

Searching sequence databases
• Starting from a sequence alone, find information about it
• Many kinds & sources of input sequences– Genomic, expressed, protein (amino acid vs.
nucleic acid) – Complete or fragmentary sequences
• Goal is to retrieve a set of similar sequences.– Exact matches are rare, and not always
interesting– Both small differences (mutations) and large
(not required for function) within “similar” sequences can be biologically important.

What might we want to know about a sequence?
• Is this sequence similar to any known genes? How close is the best match? Significance?
• What do we know about that gene?– Genomic (chromosomal location, allelic
information, regulatory regions, etc.)– Structural (known structure? structural
domains? etc.)– Functional (molecular, cellular & disease)
• Evolutionary information: – Is this gene found in other organisms? – What is its taxonomic tree?

NCBI and Entrez
• One of the most useful and comprehensive database collections is the NCBI, part of the National Library of Medicine.– Home to GenBank, PubMed & many other
familiar DBs.• NCBI provides interesting summaries,
browsers, and search tools• Entrez is their database search interface
http://www.ncbi.nlm.nih.gov/Entrez• Can search on gene names, chromosomal
location, diseases, articles, keywords...


BLAST: Searching with a sequence
• Goals is to find other sequences that are more similar to the query than would be expected by chance (and therefore are likely homologous).
• Can start with nucleotide or amino acid sequence, and search for either (or both)
• Many options– E.g. ignore low information (repetitive)
sequence, set significance critical value– Defaults are not always appropriate: READ THE
NCBI EDUCATION PAGES!

Main BLAST page

A demonstration sequence
atgcacttgagcagggaagaaatccacaaggactcaccagtctcctggtctgcagagaagacagaatcaacatgagcacagcaggaaaagtaatcaaatgcaaagcagctgtgctatgggagttaaagaaacccttttccattgaggaggtggaggttgcacctcctaaggcccatgaagttcgtattaagatggtggctgtaggaatctgtggcacagatgaccacgtggttagtggtaccatggtgaccccacttcctgtgattttaggccatgaggcagccggcatcgtggagagtgttggagaaggggtgactacagtcaaaccaggtgataaagtcatcccactcgctattcctcagtgtggaaaatgcagaatttgtaaaaacccggagagcaactactgcttgaaaaacgatgtaagcaatcctcaggggaccctgcaggatggcaccagcaggttcacctgcaggaggaagcccatccaccacttccttggcatcagcaccttctcacagtacacagtggtggatgaaaatgcagtagccaaaattgatgcagcctcgcctctagagaaagtctgtctcattggctgtggattttcaactggttatgggtctgcagtcaatgttgccaaggtcaccccaggctctacctgtgctgtgtttggcctgggaggggtcggcctatctgctattatgggctgtaaagcagctggggcagccagaatcattgcggtggacatcaacaaggacaaatttgcaaaggccaaagagttgggtgccactgaatgcatcaaccctcaagactacaagaaacccatccaggaggtgctaaaggaaatgactgatggaggtgtggatttttcatttgaagtcatcggtcggcttgacaccatgatggcttccctgttatgttgtcatgaggcatgtggcacaagtgtcatcgtaggggtacctcctgattcccaaaacctctcaatgaaccctatgctgctactgactggacgtacctggaagggagctattcttggtggctttaaaagtaaagaatgtgtcccaaaacttgtggctgattttatggctaagaagttttcattggatgcattaataacccatgttttaccttttgaaaaaataaatgaaggatttgacctgcttcactctgggaaaagtatccgtaccattctgatgttttgagacaatacagatgttttcccttgtggcagtcttcagcctcctctaccctacatgatctggagcaacagctgggaaatatcattaattctgctcatcacagattttatcaataaattacatttgggggctttccaaagaaatggaaattgatgtaaaattatttttcaagcaaatgtttaaaatccaaatgagaactaaataaagtgttgaacatcagctggggaattgaagccaataaaccttccttcttaaccatt

• Major choices:– Translatio
n– Database– Filters– Restrictio
ns– Matrix

Formatted blast output

Close hit: Macaque ADH alpha

Distant hit:L-threonine 3-
dehydrogenase from a thermophilic bacterium
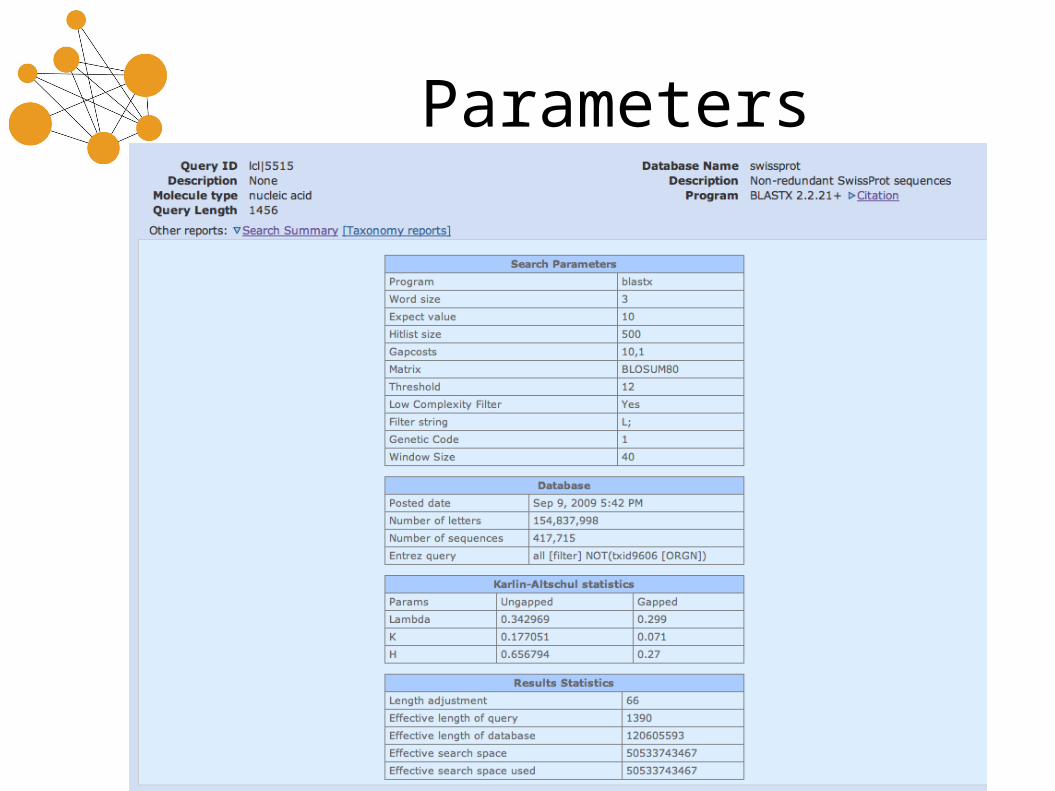
Parameters

Click on:
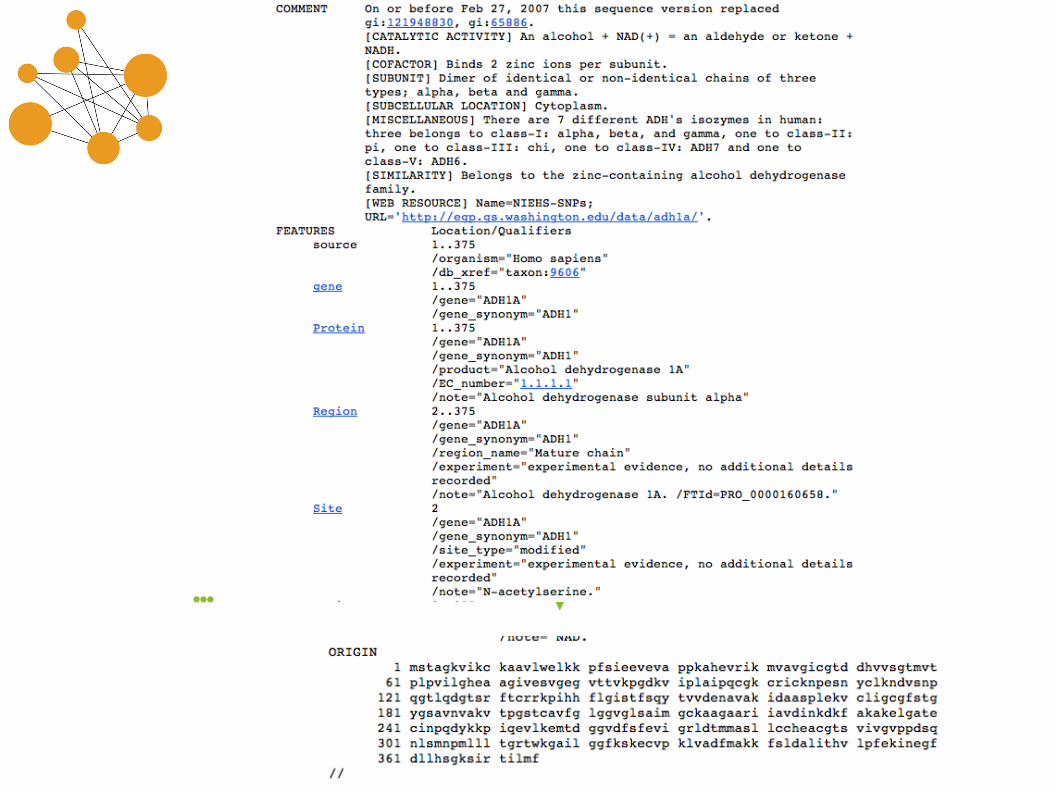
…

Taxonomy report(link from “Results of BLAST” page)

What did we just do?
• Identify loci (genes) associated with the sequence. Input was human Alcohol Dehydrogenase 1A
• For each particular “hit”, we can look at that sequence and its alignment in more detail.
• See similar sequences, and the organisms in which they are found.
• But there’s much more that can be found on these genes, even just inside NCBI…

Blink: Precomputed blast

Conserved domains

NCBI version of KEGG & EcoCyc


More from Entrez Gene

And more…


PubMed


Gene Expression

Detailed expression information

Genome map view

OMIM



NCBI is not all there is...• Links to non-NCBI databases (see also “Link
Out”)– Reactome for pathways (also KEGG)– HGNC for nomenclature– HPRD protein information– Regulatory / binding site DBs (e.g. CREB; some not
linked)– IHOP (information hyperlinked over proteins)
• Other important gene/protein resources not linked:– UniProt (most carefully annotated)– PDB (main macromolecular structure repository)– UCSC (best genome viewer & many useful ‘tracks’)– DIP / MINT (protein-protein interactions)– More: InterPro, MetaCyc, Enzyme, etc. etc.



Gene Names (not easy!)

Protein reference db



…
…


Take home messages
• There are a lot of molecular biology databases, containing a lot of valuable information
• Not even the best databases have everything (or the best of everything)
• These databases are moderately well cross-linked, and there are “linker” databases
• Sequence is a good identifier, maybe even better than gene name!

Homework• Pick a favorite gene (or, if you don’t know any,
how about looking up one of my favorites, PPAR-Delta) and gather information about it from at least five distinct resources.
• Readings:– Nucleic Acids Research online Molecular
Biology Database Collection in 2009 Nucl. Acids Res. 2009 37: D1-D4doi:10.1093/nar/gkn942 • also, browse some of the entries themselves.
– NCBI tutorial, Entrez: Making use of its power.