large-scale data science on hadoop (intel big data day)
TRANSCRIPT

1© Cloudera, Inc. All rights reserved.
Large-Scale Data Scienceon HadoopUri Laserson | Data Scientist | @laserson

2© Cloudera, Inc. All rights reserved.
About the speaker
• Data Scientist at Cloudera
• PhD in BME at MIT/Harvard
• Committer on ADAM, impyla
• Co-author on Advanced Analytics with Spark

3© Cloudera, Inc. All rights reserved.
What is a data scientist?
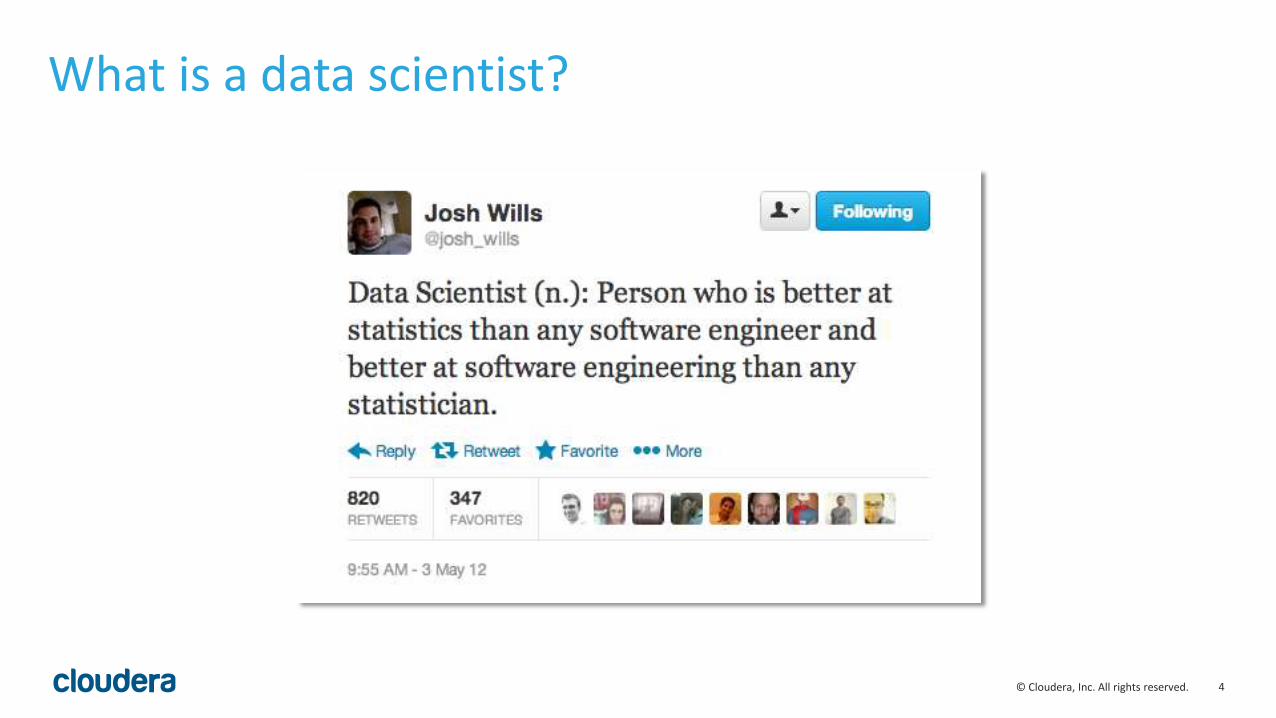
4© Cloudera, Inc. All rights reserved.
What is a data scientist?

5© Cloudera, Inc. All rights reserved.
What is a data scientist?

6© Cloudera, Inc. All rights reserved.
What is a data science?

7© Cloudera, Inc. All rights reserved.
What is a data science?
Phase 1. Collect Data Phase 2. Data Science? Phase 3. Profit!

8© Cloudera, Inc. All rights reserved.
Some things you might do as a data scientist
• Data quality issues
• Data formats/versions
• Data source integration
• Exploration/visualization
• Building/deploy models

9© Cloudera, Inc. All rights reserved.
Plumbing
Exploratory Operational

10© Cloudera, Inc. All rights reserved.
1. Data science is data plumbing

11© Cloudera, Inc. All rights reserved.
Example:
• Sells deep analysis of huge satellite images
• Easy: C++ to analyze images
• Hard: continuously reliablyingesting, transforming
• Expensive: storing, computing
• Hadoop as the data science plumber

12© Cloudera, Inc. All rights reserved.
2. Data science is investigative analytics

13© Cloudera, Inc. All rights reserved.
Example: large UK retailer
• Customer Churn
• SAS, Hive
• Path Analysis
• Giraph, MapReduce
• Customer Segmentation
• SAS, Spotfire, Impala
• Hadoop as one hub for investigative tools
• Avoid buying, training for N new tools

14© Cloudera, Inc. All rights reserved.
3. Data science is operational analytics

15© Cloudera, Inc. All rights reserved.
Example:
• Real-time Search, ML over Patient Data
• MapReduce for indexing, learning
• HBase for storage and fast access
• Storm for incremental update
• RDBMS for recent derived data
• API façade for input and querying learning
Engineering
Machine Learning

16© Cloudera, Inc. All rights reserved.
Plumbing
Exploratory Operational

17© Cloudera, Inc. All rights reserved.
Factors to consider when choosing your tools
• Single-node performance
• Scalability
• Language and tooling familiarity
• Integration with Hadoop
• Libraries / functions / richness of ecosystem
• Integration with data prep / ETL workflows
Pattern
JPMML

18© Cloudera, Inc. All rights reserved.
Plumbing in a nutshell
Plumbing Apache Kafka
Apache Pig
Apache Crunch

19© Cloudera, Inc. All rights reserved.
Serialization/RPC frameworks
• Specify schemas/services in user-friendly IDLs
• Code-generation to multiple languages (wire-compatible/portable)
• Compact, binary formats
• Natural support for schema evolution
• Multiple implementations:
• Apache Thrift, Apache Avro, Google’s Protocol Buffers
service Twitter {
void ping();
bool postTweet(1:Tweet tweet);
TweetSearchResult searchTweets(1:string query);
}
struct Tweet {
1: required i32 userId;
2: required string userName;
3: required string text;
4: optional Location loc;
16: optional string language = "english"
}

20© Cloudera, Inc. All rights reserved.
Log and service oriented architecture
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying

21© Cloudera, Inc. All rights reserved.
Log and service oriented architecture
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying

22© Cloudera, Inc. All rights reserved.
Factory (operational) vs. Laboratory (exploratory)
Programming languages
Systems languages
Latency, throughput
Huge data
Online problems
Automated
Developers, Engineers
Statistical environments, BI tools
High-level languages
Accuracy
Medium-sized data
Offline work
Ad-hoc
Statisticians, Analysts
vs.

23© Cloudera, Inc. All rights reserved.
Exploratory analytics
• Offline
• Statistical Environment
• Discovery-phase
• Model Building and Tuning
• Accuracy Important
• Medium-scale
• Visualizations
Exploratory

24© Cloudera, Inc. All rights reserved.
Exploratory: BI/visualization
• Nothing Hadoop-specific
• Take your pick of any 3rd party tool
• Typically connects to Hadoop via SQL interface with Impala

25© Cloudera, Inc. All rights reserved.
Exploratory: SAS
• Connects to Hadoop data stores
• Can push down some computation to cluster, but requires data movement
• Mature and widely used; large algolibrary
• Ongoing collaborative engineering effort with Cloudera

26© Cloudera, Inc. All rights reserved.
Exploratory: Python
• Python and JVM don’t play nice
• Hadoop Streaming / mrjob / scikit-learn
• Impyla: Python UDFs on Impala
• PySpark: Spark API in Python

27© Cloudera, Inc. All rights reserved.
Operational analytics
• Online
• Real-Time
• Cluster Environment
• Model Serving, Update
• QPS, Latency Important
• Large ScaleOperational
Pattern
JPMML

28© Cloudera, Inc. All rights reserved.
Operational: MLlib (Spark)
• Model building on Spark
• Fast (distributed in-memory)
• Basic algorithms only
• LR, SVM, decision tree
• PCA, SVD
• K-means
• ALS
• Easy integration with Spark-as-ETL

29© Cloudera, Inc. All rights reserved.
GROUPBY integration with Hadoop
Read Hadoop data Requires data movement

30© Cloudera, Inc. All rights reserved.
GROUPBY integration with Hadoop
YARN-managed Outside

31© Cloudera, Inc. All rights reserved.
GROUPBY open source
Open source Closed source

32© Cloudera, Inc. All rights reserved.
GROUPBY active community
Active community Not

33© Cloudera, Inc. All rights reserved.
Languages
Java Python R Scala

34© Cloudera, Inc. All rights reserved.
• Next-generation general processing engine for Hadoop
• APIs in Python, Java, Scala (and early R)
• DAG execution / in-memory
• Interactive REPL
• Batch or streaming
• MLlib, GraphX
• Active community
• Scala-like API

35© Cloudera, Inc. All rights reserved.
Large scale or real-time?
Large-ScaleOfflineBatch
Real-TimeOnlineStreaming
vs

36© Cloudera, Inc. All rights reserved.
Large scale or real-time?
Large-ScaleOfflineBatch
Real-TimeOnlineStreaming
vs
Why Don’t We Have Both?
λ!

37© Cloudera, Inc. All rights reserved.
Lambda architecture
• Tackle in 3 Layers
• Batch Layer: offline, big model build
• Speed Layer: near-real-time, approximate update
• Serving Layer: real-time model query / scoring

38© Cloudera, Inc. All rights reserved.
PMML
• Predictive Modeling Markup Language
• XML-based format for predictive models
• Standardized by Data Mining Group(www.dmg.org)
• Wide tool support
<PMML xmlns="http://www.dmg.org/PMML-4_1"
version="4.1">
<Header copyright="www.dmg.org"/>
<DataDictionary numberOfFields="5">
<DataField name="temperature"
optype="continuous"
dataType="double"/>
…
</DataDictionary>
<TreeModel modelName="golfing"
functionName="classification">
<MiningSchema>
<MiningField name="temperature"/>
…
</MiningSchema>
<Node score="will play">
<Node score="will play">
<SimplePredicate field="outlook"
operator="equal"
value="sunny"/>
…
</Node>
</Node>
</TreeModel>
</PMML>

39© Cloudera, Inc. All rights reserved.
Lambda implementation: Oryx 2.x
• Generic lambda-architecture platform
• With ML specializations
• hyperparam selection
• Built on Spark Streaming, Kafka
• With Intel
• 2.x: pre-alpha
github.com/OryxProject/oryx

40© Cloudera, Inc. All rights reserved.
Lambda implementation: Oryx 2.x
github.com/OryxProject/oryx

41© Cloudera, Inc. All rights reserved.
HTTP REST API
• Convention for RPC-like request / response
• HTTP verbs, transport
• GET : query
• POST : add input
• Easy from browser, CLI, Java, Python, Scala, etc.
GET /recommend/jwills
HTTP/1.1 200 OK
Content-Type: text/plain
"Ray LaMontagne",0.951
"Fleet Foxes",0.7905
"The National",0.688
"Shearwater",0.3017
