wp-sgi-hadoop-big data...
TRANSCRIPT

SGI® Hadoop™ Big Data Engine on Intel® Xeon® Processor E5 Family ‐ Reference Implementations with Data Integration capabilities
With the ever increasing amount of data being captured, transformed and analyzed in the Big Data space, the need for speed and scale of the total solution is becoming critical. Organizations increasingly need to ingest and analyze high velocity data in real‐time, and then export that data into a historical datastore like Hadoop for further analysis. Users need performance features in data integration methodologies to export data quickly to Hadoop for analytics and that too in a continuous manner. This paper describes two Hadoop Reference Implementations on SGI® Rackable™ clusters based on Intel Xeon Processor E5 Family, that are factory‐installed, pre‐optimized, and delivered ready‐to‐run with an ecosystem of analytical solutions, in order to provide application developers (end customers or ISVs) a best‐in‐class, differentiated Business Intelligence (“BI”) solution over Hadoop. Additional features include measured capabilities for data ingestion by high velocity databases/applications followed by integration to Hadoop for analytics. References to performance data measured on SGI Hadoop C2005‐TY6 cluster based on Intel Xeon Processor 5600 series are often made in this paper.
____________________________________________________
1. Introduction
The major pain points for Big Data processing are its volume, velocity and variety and the ordeal for finding value in it. While Hadoop is a widely used technology for processing Big Data, challenges like sizing, configuring and optimizing Hadoop to meet end‐user requirements is a big conceptual hurdle. Next, comes choosing the right Applications for Hadoop. Applications need to be written to scale, with streaming access to data, also requiring write‐once‐read‐many access model for files. The other challenge lies in applying the knowledge of analytics in the structured space to the unstructured domain. Lastly, users need to ingest and analyze high velocity data in real‐time, and then collect that data into a historical datastore like Hadoop for further analysis. Thus, an integrated solution for speed and scale is required to address the different levels of throughput, processing rate and availability of information for a seamless information flow across an enterprise.
This paper talks about SGI Hadoop Reference Implementations (RIs) that solves the above challenges as follows: Solve complexity of Hadoop deployment
– With a factory‐installed, optimized Hadoop integrated with the hardware and an ecosystem of analytical options, SGI Hadoop RIs allow customers to run complex analytical Applications atop Hadoop, out of the box.
– SGI Hadoop RIs provide little deployment effort, low maintenance cost and maximum Rack density.
– Built on top of standard Apache Hadoop distributions, SGI Hadoop RIs provide a modular approach to verticals.
Solve Hadoop optimization challenges with a
predictable performance:
– SGI Hadoop RIs are built for affordable price/performance and provide linear Terasort performance, optimal performance/watt, allowing

2
organizations to focus on application development instead of performance tuning.
Solve challenges of volume, velocity, variety of data:
– SGI Hadoop RIs have a raw capacity to support 100s of terabytes to petabytes of high velocity data in three densely‐packed Rack configurations;
– Special features of the RIs include characterization of performance of data integration to HDFS.
Solves challenges to find value in information: – SGI Hadoop RIs contain pre‐packaged
analytical ISV software and demos, followed by activation as per customer’s desire.
– SGI Hadoop RIs support options for import/export, search, mine, predict, creating Business Models, and visualizing data for Business Intelligence.
.

2. SGI Hadoop Reference Implementations
In this section, two reference implementations on SGI Rackable half‐depth and full‐depth servers have been discussed.
2.1. Half-Depth Specifications SGI Hadoop Reference Implementation on half‐depth servers is available in single rack and multi‐rack configurations. Hardware comprises of SGI® Rackable® half‐
depth servers – C2005‐RP1 servers as NameNode,
Secondary NameNode, JobTracker with the following specs:
2x Intel® Xeon® Processors E5‐2630 (2.3 GHz, six‐core);
8x 8GB 1.35v 1333MHz DIMMs (64GB Memory);
4x 3.5’’ 1TB 7200rpm SATA 6Gb/s drives in RAID configuration;
1x Dual port 10GbE NIC;
Redundant Power Supply.
– C2005‐RP1 servers as DataNodes/ TaskTrackers with the following specs:
2x Intel® Xeon® Processors E5‐2630 (2.3 GHz, six‐core);
8x 8GB 1.35v 1333MHz DIMMs (64GB Memory);
10x 2.5’’ 1TB 7200rpm SATA 6Gb/s drives.
– C2005‐RP1 server as Application Node
with the following specs: 2x Intel® Xeon® Processors E5‐
2680 (2.7 GHz, eight‐core); 16x 8GB 1.35v 1333MHz
DIMMs (128GB Memory); 4x 3.5’’ 1TB 7200rpm SAS
6Gb/s drives in RAID5 configuration;
1x Dual port 10GbE NIC; Redundant Power Supply.
Network: o 2x LG‐Ericsson ES‐4550G 48‐port GigE
switches, per rack o 1x LG‐Ericsson ES‐5048XG 10GigE spine
switch.
2.2. Full-Depth Specifications SGI Hadoop Reference Implementation on full‐depth servers is available in single rack and multi‐rack configurations. Hardware comprises of SGI® Rackable® full‐
depth servers – C1110‐RP6 with Intel Xeon E5‐2600
Processor Series as Hadoop NameNode, Secondary NameNode, JobTracker
Full‐depth 1U form factor for density;
Intel Xeon Processors E5‐2630 (2.3GHz six‐core);
8x 8GB 1.35v 1333MHz DIMMs (64GB Memory);
4x 3.5’’ 1TB 7200rpm SATA 6Gb/s drives RAID5 configuration;
Redundant Power Supply.
– C1110‐RP6 with Intel Xeon E5‐2600 Processor Series as Hadoop DataNodes:
Full‐depth 1U form factor for density;
DataNodes & TaskTracker: SGI Rackable C2005‐RP1 servers with
Intel Xeon Processor E5‐2600 Series
NameNode, Secondary NameNode, JobTracker: SGI Rackable C2005‐RP1 servers with Intel Xeon Processor E5‐2600 Series
Application Node: SGI Rackable C2005‐RP1 server with Intel Xeon
Processor E5‐2600 Series

4
Intel Xeon Processors E5‐2630 (2.3GHz six‐core);
8x 8GB 1.35v 1333MHz DIMMs (64GB Memory);
10x 2.5’’ 1TB 7200rpm SATA 6Gb/s drives.
– C1110‐RP6 with Intel Xeon E5‐2600
Processor Series as Application Node Full‐depth 1U form factor for
density; Intel Xeon Processors E5‐2680
(2.7GHz eight‐core);
16x 8GB 1.35v 1333MHz DIMMs (128GB Memory);
4x 3.5’’ 1TB 7200rpm SAS 6Gb/s drives RAID 5 configuration;
1x Dual port 10GbE NIC; Redundant Power Supply.
Network: o 2x LG‐Ericsson ES‐4550G 48‐port GigE
switches, per rack o 1x LG‐Ericsson ES‐5048XG 10GigE spine
switch.
½ Rack: 160 TB raw capacity
Multi‐Rack: Petabytes useable capacity
10GigE
1 Rack: 320 TB raw capacity
Import, Export, Search, Mine, Predict & Visualize data for Business Intelligence
Figure 1: Options to sell Single Rack and Multi‐Rack configurations
Software stack comprises of: – Operating System: RHELTM 6 .2 (2.6.32‐
220.el6.x86_64) – Cloudera® distribution including
Apache Hadoop 3 update 2 (hadoop‐0.20.2‐cdh3u2
– SGI MC 1.5.0 – An ecosystem of Business Intelligence
Applications software from ISVs like,
Datameer®, Kitenga®, Pentaho® and Quantum4D® (Figures 2 and 3).
– Data ingestion and Integration capabilities from high velocity databases like VoltDB into HDFS.
DataNodes & TaskTracker: SGI Rackable C1110‐RP6 servers with
Intel Xeon Processor E5‐2600 Series
NameNode, Secondary NameNode, JobTracker: SGI Rackable C1110‐RP6 servers with Intel Xeon Processor E5‐2600 Series
Application Node: SGI Rackable C1110‐RP6 server with Intel Xeon
Processor E5‐2600 Series
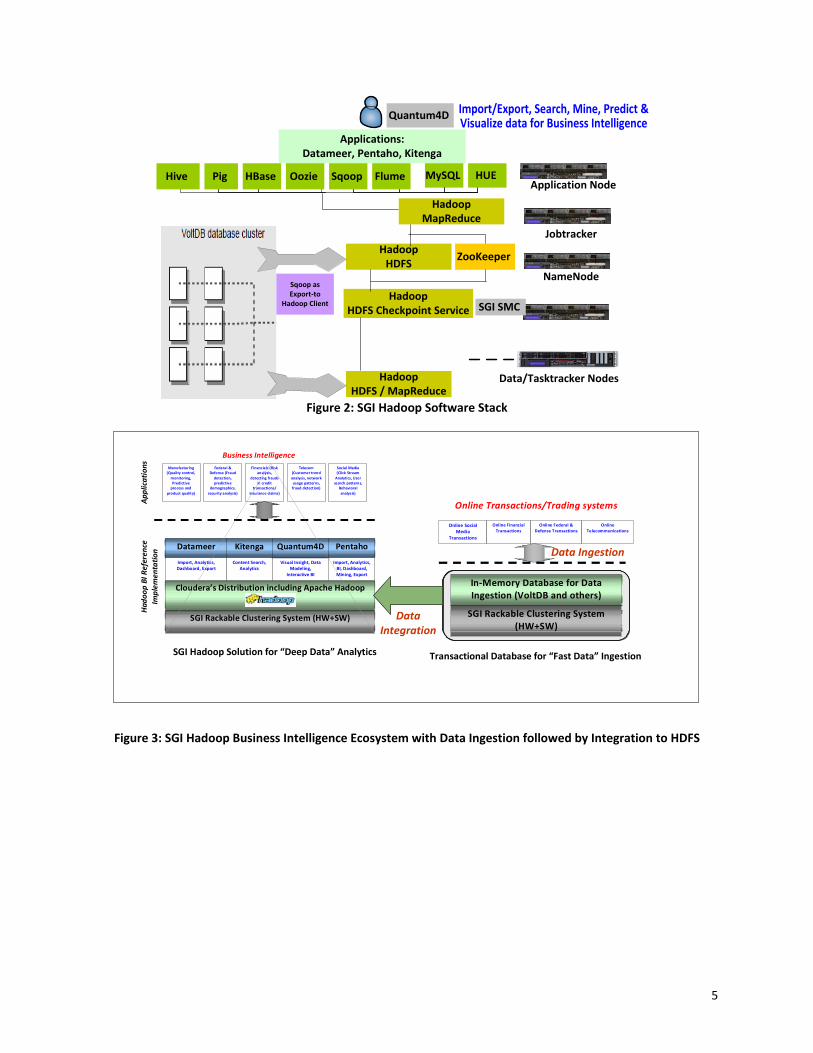
5
Application Node
NameNode
Jobtracker
Data/Tasktracker Nodes
ZooKeeper
SGI SMC
Hadoop HDFS / MapReduce
Hadoop MapReduce
Hadoop HDFS
Hadoop HDFS Checkpoint Service
Import/Export, Search, Mine, Predict & Visualize data for Business Intelligence
Applications: Datameer, Pentaho, Kitenga
HBase Oozie Sqoop Flume HUE
Quantum4D
Hive Pig MySQL
Sqoop as Export‐to
Hadoop Client
Figure 2: SGI Hadoop Software Stack
In‐Memory Database for Data Ingestion (VoltDB and others)
SGI Rackable Clustering System (HW+SW)
Online Transactions/Trading systems
Online Social Media
Transactions
Online Financial Transactions
Online Federal & Defense Transactions
Online Telecommunications
Transactional Database for “Fast Data” IngestionSGI Hadoop Solution for “Deep Data” Analytics
Data Integration
Data Ingestion
Cloudera’s Distribution including Apache Hadoop
Datameer
Import, Analytics, Dashboard, Export
Pentaho
Import, Analytics, BI, Dashboard, Mining, Export
Business Intelligence
Kitenga
Content Search, Analytics
Visual Insight, Data Modeling,
Interactive BI
Quantum4D
Had
oop BI Referen
ce
Implem
entatio
n
SGI Rackable Clustering System (HW+SW)
Social Media (Click Stream Analytics, User search patterns,
Behavioral analysis)
Financials (Risk analysis,
detecting frauds in credit
transactions/ insurance claims)
Federal & Defense (Fraud
detection, predictive
demographics, security analysis)
Telecom (Customer trend analysis, network usage patterns, fraud detection)
App
lications
Manufacturing (Quality control, monitoring, Predictive process and
product quality)
Figure 3: SGI Hadoop Business Intelligence Ecosystem with Data Ingestion followed by Integration to HDFS

6
3. Standard Benchmark Performance
This section describes the various Hadoop standard benchmarks executed on SGI Hadoop Reference Implementation based on Intel Xeon Processor E5‐2600 series. Note: References to measured performance data on a 32‐node C2005‐TY6 Hadoop cluster based on Intel Xeon Processor 5600 series have been made, where relevant and/ where C2005‐RP1 results are not immediately available on a large 32‐node configuration.
The following benchmarks have been executed: 1. TestDFSIO1, which is a standard benchmark used
to perform I/O stress test for HDFS; 2. TeraSort2, which helps derive the sort time for
1TB or any other amount of data in the Hadoop cluster. It is a benchmark that combines testing the HDFS and MapReduce layers of an Hadoop cluster;
3. WordCount3, which reads text files and counts how often words occur. The input and ouput are text files, each line of which contains a word and the count of how often it occurred, separated by a tab;
4. Sort4 uses the map/reduce framework to sort
the input directory into the output directory. The inputs and outputs must be Sequence files where the keys and values are BytesWritable.
1 http://www.michael‐noll.com/blog/2011/04/09/benchmarking‐and‐stress‐testing‐an‐hadoop‐cluster‐with‐terasort‐testdfsio‐nnbench‐mrbench/#testdfsio 2 http://sortbenchmark.org/ 3 http://wiki.apache.org/hadoop/WordCount 4 http://wiki.apache.org/hadoop/Sort

3.1. Benchmark Results
3.1.1. Terasort Benchmark Results as of the date this paper was written (March, 2012) show that a SGI Rackable C2005‐RP1 Hadoop cluster based on Intel Xeon E5‐2667 processors is ~17% faster on a single node and almost similar on eight nodes or higher, when compared to a SGI Rackable C2005‐TY6 Hadoop cluster, based on Intel Xeon E5645 processors. The behavior with E5‐2667 processors downclocked to 2.3 GHz is also similar, showing almost no difference in performance with 4 nodes and higher (Figure 4). The inherent distributed nature of Hadoop becomes predominant over CPU type as the size of the cluster increases. Also, Terasort on the SGI Rackable C2005‐RP1 Hadoop cluster scales almost linearly and the scalability is similar while using Intel Xeon Processor E5‐2600 and
5600 series (Figure 5). The clusters are running Cloudera’s distribution including Apache Hadoop (CDH3u2). SGI Rackable C2005‐RP1 cluster is ~3x and ~2x faster than an Oracle Sun X2270 cluster6 on a single node and 8 nodes, respectively (Figure 6). It is important to note that, a single SGI Rackable C2005‐TY6 node with 10 HDDs is ~2x faster than that with 4 HDDs (Figure 7). So a balance of cores to drives is important.
Terasort Elapsed time: SGI Rackable Hadoop Cluster - 100 GB job size
1801
2103
1909
0
500
1000
1500
2000
2500
1 2 4 8 10Number of Nodes
Tim
e in
Sec
onds
Intel Xeon Processor E5-2667 @ 2.9 GHz
Intel Xeon Processor E5645 @ 2.4 GHz
Intel Xeon Processor E5-2667 @ 2.3 GHz(downclocked)
Lower the better
Figure 4: Terasort Elapsed Time: SGI Rackable Hadoop cluster with Intel Xeon Processor E5‐2600 vs. 5600 series

8
Terasort Scaling: SGI Rackable Hadoop Cluster -100 GB job size
0
2
4
6
8
10
12
14
1 2 4 8 10Number of Nodes
Scal
ing
Intel Xeon Processor E5-2667 @2.9 GHzIntel Xeon Processor E5645 @2.4 GHzIntel Xeon E5-2667 Processor @2.3 GHz (downclocked)
Figure 5: Terasort Scaling: SGI Rackable C2005‐RP1 Hadoop cluster on Intel® Xeon® Processor E5‐2600 series
Terasort Elapsed Time on SGI vs. Sun Hadoop Cluster: 100 GB input data size
167206443911
1801 4669272141
6010
0500
100015002000250030003500400045005000550060006500
1 2 4 8 10Number of Nodes
Elap
sed
Tim
e (S
ecs)
Time (secs) SGITime (secs) Sun cluster
Lower the better
Figure 6: Terasort Elapsed Times: SGI Rackable C2005‐RP1 Hadoop cluster vs. Oracle Sun X2272 M2 cluster5
5 http://sun.systemnews.com/articles/152/1/server/23549

Terasort Elapsed Time: 100GB job size1x SGI Rackable C2005-TY6: 4 HDDs vs. 10 HDDs
6034
3046
0
1000
2000
3000
4000
5000
6000
7000
4 HDDs 10 HDDs
Elap
sed
Tim
e (s
ecs)
Lower the better
2x faster
Lower the better
Lower the better
Figure 7: Terasort Elapsed time: A single SGI Rackable C2005‐TY6 node with 4 HDDs vs. 10 HDDs

3.1.2. WordCount Benchmark WordCount @ 1 TB job size, scales linearly across a 10‐node SGI Rackable C2005‐TY6 and C2005‐RP1 Hadoop cluster, with an enhanced scalability between 4 to 8 nodes. The WordCount performance on C2005‐TY6 cluster is similar to that on a C2005‐RP1 cluster with a 5‐8% improvement on the latter. WordCount has a 28x capability to count occurrence of a word from text files, while using 5x nodes in a SGI Rackable C2005‐RP1 cluster (Figure 8). The 4 to 8‐node enhanced scalability is a contributing factor.
Word Count Scaling: SGI Hadoop Cluster: 1 TB Job Size
10585
20,994
744
9,990
1,3721480
21989
0
4000
8000
12000
16000
20000
24000
2 4 8 10
Number of Nodes
Elap
sed
Tim
e (s
ecs)
Intel Xeon E5-2667 Processor@ 2.3 GHz (downclocked)Intel Xeon Processor E5645@ 2.4 GHz
28.2x scaling on 5x nodes
Lower the better
Figure 8: WordCount Scaling on SGI Rackable C2005‐RP1 Hadoop cluster

3.1.3. TestDFSIO Benchmark This section describes the TestDFSIO benchmark performance on a 32‐node SGI Rackable C2005‐TY6 Hadoop cluster, based on Intel Xeon 5600 processors. The behavior will be almost similar on a C2005‐RP1 cluster. • In TestDFSIO read tests on a SGI Rackable
C2005‐TY6 Hadoop cluster, uniform scaling occurs as all the read requests benefit from parallelism with more nodes in the cluster.
• On a single data node cluster all reads will have
to happen on the single node whereas on a 2 data node cluster more reads could occur in parallel (Figure 9).
• In TestDFSIO write tests on a SGI Rackable
C2005‐TY6 Hadoop cluster, the number of maps created is equal to the number of files specified as a parameter. For a run with 1000 files, each 1 GB in size, a 1000 map jobs each of which will create a file of 1GB in size is created by the MapReduce engine.
On a single datanode cluster, all the
1000 files will be created locally on the local disks as the 1000 map jobs (tasks) all run on the same node.
With 2 data nodes, each map job or
task will have to create 500 MB locally and 500 MB remotely. That means there is a network overhead where map task will have to write half the file
size over to the network and that data will have to be written on the disks of the remote data node and the map tasks will have to wait until the remote writes completes successfully. Basically each map task will run for a longer time on a 2 node cluster to do the same amount of work when compared to a single node run.
With more nodes added, the
parallelism of map tasks gains over the amount of work per node. So the elapsed time reduces substantially (Figure 9).
• Best Read Performance with multiple files: The sweet spot for best read performance was observed to be ~250 seconds. The best read performance was observed with 100 files of 10 GB each and with 10,000 files of 100 MB each (Figure 10).
• Best Write Performance with multiple files: The sweet spot for best write performance was observed to be ~525 seconds. The best write performance was observed with 100 files of 10 GB each and with 10,000 files of 100 MB each (Figure 10).

TestDFSIO: I/O scaling w/ 1TB Data Size:SGI Rackable C2005-TY6 Hadoop cluster
0
1000
2000
3000
4000
5000
6000
2 4 8 16 32Number of Nodes
Elap
sed
Tim
e (s
ecs) Writes
Reads
Lower the better
Figure 9: TestDFSIO Scaling on a 32‐node SGI Rackable C2005‐TY6 Hadoop cluster
TestDFSIO: I/O Scaling w/ Number of Files on 32-node SGI Rackable C2005-TY6 Hadoop Cluster - 1 TB Job Size
0
500
1000
1500
2000
10 100 1000 10000 100000Number of Files
Res
pons
e Ti
me
(Sec
s)
WritesReads
Lower the better
Figure 10: TestDFSIO Scaling with Number of Files
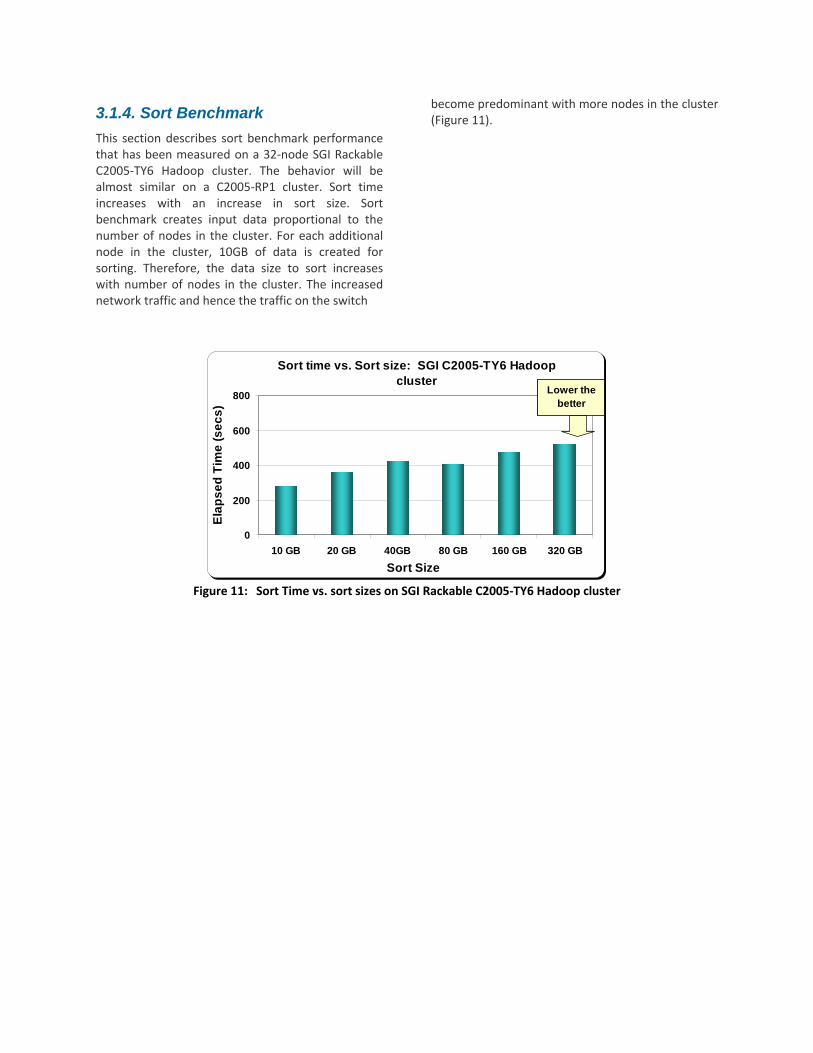
3.1.4. Sort Benchmark This section describes sort benchmark performance that has been measured on a 32‐node SGI Rackable C2005‐TY6 Hadoop cluster. The behavior will be almost similar on a C2005‐RP1 cluster. Sort time increases with an increase in sort size. Sort benchmark creates input data proportional to the number of nodes in the cluster. For each additional node in the cluster, 10GB of data is created for sorting. Therefore, the data size to sort increases with number of nodes in the cluster. The increased network traffic and hence the traffic on the switch
become predominant with more nodes in the cluster (Figure 11).
Sort time vs. Sort size: SGI C2005-TY6 Hadoop cluster
0
200
400
600
800
10 GB 20 GB 40GB 80 GB 160 GB 320 GBSort Size
Elap
sed
Tim
e (s
ecs)
Lower the better
Figure 11: Sort Time vs. sort sizes on SGI Rackable C2005‐TY6 Hadoop cluster

4. Case Study
4.1. SSD vs. HDD This section describes a case study to characterize performance of Hadoop with SSDs vs. HDDs. Terasort performance with SSDs has been projected from a single node (with 10x 480 GB OCZ SSDs) to ten nodes to derive price/performance metrics. Projections show that a 10‐node C2005‐RP1 Hadoop cluster with SSDs is 38% faster than a similar configuration with HDDs (Figure 12).
TeraSort Elapsed time on SGI Rackable C2005-RP1 Cluster: SSDs vs. HDDs
1851340
500
1000
1500
2000
2500
1 2 4 8 10Number of Nodes
Tim
e in
Sec
onds
Elapsed Time with HDDs
Projected Elapsed Time with SSDs
Lower the better
Figure 12: Terasort Elapsed time on a 10‐node SGI Rackable C2005‐RP1 Hadoop cluster with HDDs vs. SSDs
5. Price/Performance
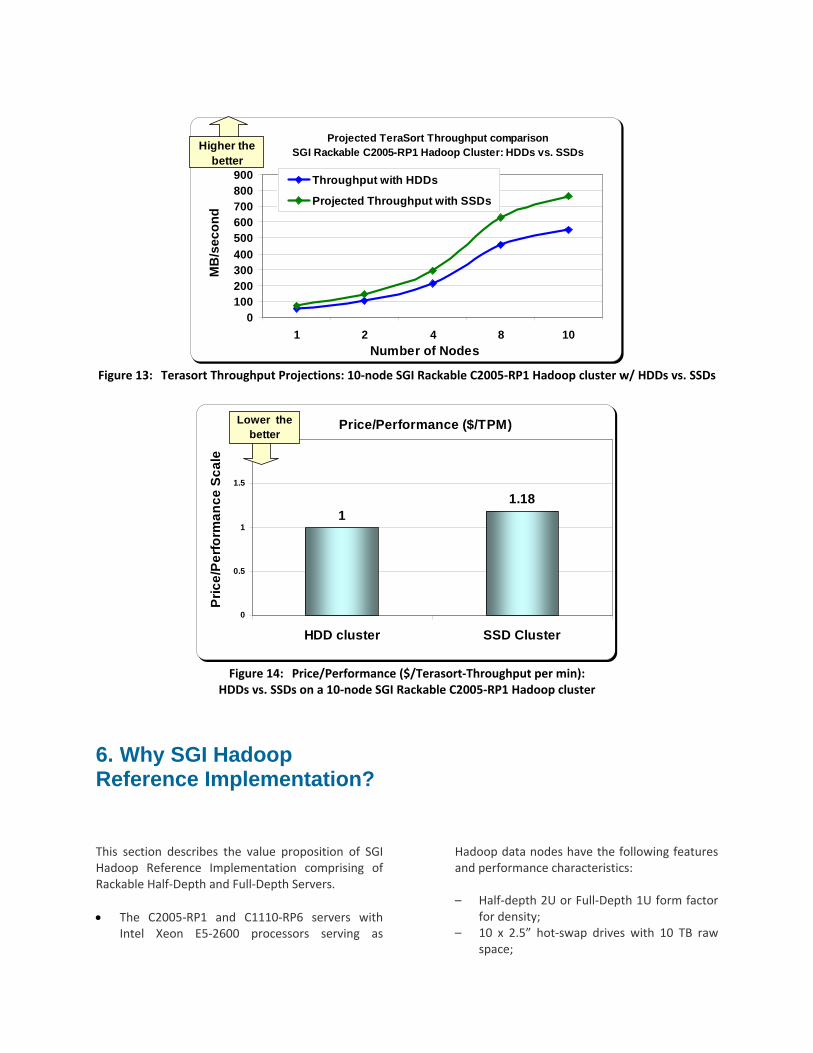
This section describes the price/performance metrics of a 10‐node Hadoop cluster using C2005‐RP1 nodes. Terasort throughput projections on a 10‐node cluster comprising of SSDs vs. HDDs (Figure 13) have been calculated based on the measured data on a single node. Also, the variation of price/performance with SSDs vs. HDDs is calculated using the measured data and derived projections (Figure 14).
With SSDs on all of the 10 nodes, the projected price/performance ($/TPM) is ~18% higher than that of the HDD configuration. TPM is the Terasort‐Throughput per minute. Thus, a cluster with all HDDs may be often cheaper in Price/Performance than a cluster with all SSDs. So it is important to justify the need for SSDs depending on the workload being executed.
Projected TeraSort Throughput comparisonSGI Rackable C2005-RP1 Hadoop Cluster: HDDs vs. SSDs
0100200300400500600700800900
1 2 4 8 10Number of Nodes
MB
/sec
ond
Throughput with HDDs
Projected Throughput with SSDs
Higher the better
Figure 13: Terasort Throughput Projections: 10‐node SGI Rackable C2005‐RP1 Hadoop cluster w/ HDDs vs. SSDs
Price/Performance ($/TPM)
1.181
0
0.5
1
1.5
2
HDD cluster SSD Cluster
Pric
e/Pe
rform
ance
Sca
le
Lower the better
Figure 14: Price/Performance ($/Terasort‐Throughput per min):
HDDs vs. SSDs on a 10‐node SGI Rackable C2005‐RP1 Hadoop cluster
6. Why SGI Hadoop Reference Implementation?
This section describes the value proposition of SGI Hadoop Reference Implementation comprising of Rackable Half‐Depth and Full‐Depth Servers. • The C2005‐RP1 and C1110‐RP6 servers with
Intel Xeon E5‐2600 processors serving as
Hadoop data nodes have the following features and performance characteristics:
– Half‐depth 2U or Full‐Depth 1U form factor
for density; – 10 x 2.5” hot‐swap drives with 10 TB raw
space;

16
– An optimally balanced configuration of cores, drives and memory;
– HDD or Flash‐enabled; – Power optimized; – Linear scalability and predictable
performance with Terasort on a Hadoop cluster ;
– Affordable Price/Performance; – Options to sell Single Rack and Multi‐Rack
configurations. • SGI brings to market two differentiated Hadoop
Reference Implementations on SGI Rackable clusters with a factory‐installed, optimized Hadoop along with measured data ingestion and integration capabilities into HDFS.
• The Reference Implementations overall help
customers to leverage little deployment effort, low maintenance cost, Maximum Rack density, affordable price/performance, Terasort scalability and hence predictable performance, optimized performance/watt ‐ allowing organizations to focus on application development instead of performance tuning.
• With the analytical capabilities atop Hadoop,
the Reference Implementations support fast processing and deep analytics against 100s of
terabytes to petabytes of data helping customers to Import/Export, Search, Mine, Predict, create Business Models, and Visualize data for Business Intelligence (Refer to Section 8).
Table 1 shows the market‐leading solution that SGI brings with its Hadoop RI.

Integrated NoSQL/Hadoop Solutions
Features/Advantages Comparisons SGI Hadoop BI Reference
Implementation
EMC Green Plum
HP Vertica Oracle Big Data
Appliance
Dell Hadoop Solution
Netapp Hadoop Solution
IBM Netezza
+ Hadoop
Appliance‐based proprietary and closed architecture Out of the box factory installed and configured Hadoop stack
Drag‐and‐drop analytics and indexing pipelines
Open source core enabled customization and rapid innovation
Hadoop enabled for scalability Hive enabled BI
Spreadsheet‐based analytics
Native visualization of search results
3D visualization of Big Data results
Natural Language Processing for enhanced metadata
Multiple Language/Character sets
Document and content security
Ingestion of multiple document formats
Table 1: SGI Hadoop Reference Implementation Feature comparison
Sources: • Green plum Hadoop: http://www.greenplum.com/products/greenplum‐hd • HP Vertica + Hadoop: http://www.vertica.com/the‐analytics‐platform/native‐bi‐etl‐and‐hadoop‐mapreduce‐integration/ • Oracle Big Data Appliance: http://www.oracle.com/us/corporate/features/feature‐obda‐498724.html • Dell Hadoop Cluster: http://i.dell.com/sites/content/business/solutions/whitepapers/en/Documents/hadoop‐enterprise.pdf • NetApp Hadoop Solution: http://www.netapp.com/us/solutions/infrastructure/hadoop.html; http://media.netapp.com/documents/ds‐3237.pdf • IBM Netezza + BigInsights Hadoop: http://thinking.netezza.com/video/using‐hadoop‐ibm‐netezza‐appliance; http://thinking.netezza.com/blog/hadoop‐netezza‐synergy‐data‐analytics‐part‐2

7. SGI Hadoop RI with Data Integration
This section describes capabilities of data integration into HDFS.
Organizations increasingly need to ingest and analyze high velocity data in real‐time, and then collect that data into a historical datastore like Hadoop for further analysis. Users need:
Fexibility to select which data will be exported from a a data source to Hadoop;
Ability to enrich data, using standard SQL and relational semantics, prior to exporting it to Hadoop;
Ability to quickly configure a data integrator with the existing Sqoop/Hadoop settings, to minimize the time and effort needed to bring your infrastructure online.
A robust, loosely‐coupled product integration is required that allows the different components to operate at different levels of throughput, availability and processing state.
7.1. Sqoop as Export-to-Hadoop client
This section describes a case study where a SGI Hadoop cluster is using Sqoop export‐to‐Hadoop client(s) to characterize the functionality and performance of data ingestion from external high‐velocity transactional databases or Applications, followed by integration to HDFS.
While VoltDB helps to handle data in high velocity state, Hadoop is an excellent solution for analyzing massive volumes of historical data. Thus, an integration framework using Sqoop as an export
client to Hadoop offers the flexibility to handle a continuum of “fast” and “deep” data applications.
The Sqoop Export‐to‐Hadoop client provides the following capabilities and benefits:
Flexibility of choosing rows and columns of the selected database tables or SQL query result sets to be imported to HDFS;
Parallelism of operations by leveraging MapReduce to import and export the data, followed by fault tolerance.
Support for binary and non‐binary data types and support for immediate manipulation by Hive.
Data Compressibility and large object support (BLOB, CLOB) for imports.
Figure 15 shows the Sqoop Export‐to‐Hadoop client in action with the following steps:
Sqoop is a tool designed to easily import information from SQL databases into a Hadoop cluster.
The Sqoop Export‐to‐Hadoop client connects to the Application cluster.
Imports individual tables or entire databases to files in HDFS.
Generates Java classes to allow one to interact with the imported data.
Provides the ability to import from SQL databases straight into a Hive data warehouse, if needed.

Sqoop as Export-to-
Hadoop Client
Figure 15: Export‐to‐Hadoop client in action

7.2. Performance of Data Ingestion and Integration
This section describes the benchmark that has been run to derive performance metrics for data ingestion by a transactional VoltDB database followed by integration into HDFS using the Sqoop Export‐to‐Hadoop client.
An OLTP cluster has been used to ingest and execute a high velocity streaming application in‐memory with social networking data. The data is then integrated to Hadoop/HDFS in near‐real time for deep analytics. Recording the time to ingest a certain amount of data and then integrating it to HDFS has been the goal.
The benchmark configuration (Figure 16) comprised of:
Application Nodes: 24x SGI Rackable C2005‐TY7 servers each with
Intel Xeon Processors X5675 (3.06GHz six‐core);
12x 8GB 1.35v 1333MHz DIMMs (96GB Memory);
4x 2.5’’ 1TB 7200rpm SATA 6Gb/s drives;
1x Dual port 1GbE NIC;
VoltDB Enterprise Edition database software.
Admin Node: 1x SGI Rackable C2005‐TY6 server with
Intel Xeon Processors E5645 (2.4GHz six‐core);
6x 8GB 1.35v 1333MHz DIMMs (48GB Memory);
4x 3.5’’ 1TB 7200rpm SATA 6Gb/s drives in RAID configuration;
1x Dual port 10GbE NIC;
Redundant Power Supply.
Export Nodes to Hadoop: 2x SGI Rackable C2005‐TY7 servers with the following specs:
Intel Xeon Processors X5675 (3.06GHz six‐core);
12x 8GB 1.35v 1333MHz DIMMs (96GB Memory);
8x 3.5’’ 1TB 7200rpm SAS 6Gb/s drives in RAID0 configuration;
2x Dual port 10GbE NICs;
Redundant Power Supply;
Sqoop as Export‐to‐Hadoop client software.
Operating System: RHEL 6.2 ‐ 2.6.32‐220.el6.x86_64
• Network:
• 1x LG‐Ericsson ES‐4550G 48‐port GigE as top‐of‐rack switch
• 1x LG‐Ericsson 5048XG switch 48‐port 10GigE switch from export nodes to Hadoop.
Test Phases and Results: The phases of data ingestion comprised of streaming transactions, SQL query execution on the data for analytics on the fly, followed by data insertion to export tables in the database.
This ingestion phase is followed by integration to HDFS using a Sqoop export client.
The duration of the Test duration was 10 Minutes (600 seconds).
• Data Ingestion phases:
• Transaction Rates
• Single client: 108K TPS on average
• 20 client cluster: 2.164M TPS on average
• SQL Statement execution rates
• Single Client: 540K SQL statements per second
• 20 Client cluster: 10.820M SQL Statements per second
• Table insertion rate
• Single client: 216K rows per second (Note: 2 insertions per transaction)

21
• 20 Client cluster: 4.328M rows per second
• Total Rows in VoltDB ingested in 600 secs
• 2.5968 Billion rows (4.328M * 600)
• Data Ingestion Phase:
• Transfer rate of Sqoop client
• Row size: 59 bytes per row.
• Total size of rows: 153.2GB (2.59B* 59)
• Average transfer rate in bytes for Sqoop client: 4.4 MB/s.
Refer to Figure 17. It is important to note that using multiple Sqoop clients is most likely to improve the data transfer rate to HDFS. Work will continue to test and enhance the performance of Sqoop to HDFS.
Admin Node (1)
C2005-TY6
VoltDB Data/Replica Nodes (24)
C2005-TY7
Export Nodes (2)
C2005-TY7
10 GigE
10 GigE
To Hadoop
10 GigE switch
10 GigE switch
10 GigE
GigE
Figure 16: Data Ingestion and Integration to HDFS: Benchmark Schematics

Data Ingestion by VoltDB and Integration to HDFS
2.2
10.84.3
2596.8
153.2
4.4
1
10
100
1000
10000
TransactionRate (TPS) (M)
SQL executionrate (M)
Table insertionrate (M)
Total Rowsingested (M)
Total data tointegrate (GB)(59 bytes/row)
Sqoop transferrate (1 client)
(MB/s)
Higher the better
Figure 17: Performance ‐ Data Ingestion followed by Integration to HDFS
8. Big Data Applications on Hadoop
This section describes the ISV applications tested on the Hadoop Reference Implementation. Kitenga Zettavox 1.5 in SGI Hadoop RI handles content extraction and analytics, including the extraction of named entities and data crawling. It indexes content, applies natural‐language processing and machine learning and generates metadata ‐ in readiness for analysts to chart, graph, model and visualize the data. This software sports a drag‐and‐drop interface to obviate the need for programming
expertise in authoring, monitoring, analyzing and searching data. ZettaSearch is included with ZettaVox, as is ZettaViz, allowing users to search visualizations once created in ZettaVox. ZettaVox also integrates with the Quantum4D® Builder product to support export of Big Data and interacting with that data in a comprehensive three‐dimensional information visualization and modeling tool. Initial support for Quantum4D is based on exporting quantitative relationship information derived from Big Data resources to Quantum4D using an intermediary MySQL® database (Figure 18). For more information about Kitenga and Quantum4D, refer to: www.kitenga.com and http://www.quantum4d.com/

23
Hadoop ServerJob Tracker
Hadoop ServerJob Tracker
HadoopTask Manager
HadoopTask ManagerHadoopTask Manager
HadoopTask Manager
HadoopTask Manager/Data Node
HadoopTask Manager/Data Node
Hadoop ServerName node
Hadoop ServerName node
IndexingIndexing Entity ExtractionEntity
Extraction CrawlingCrawlingSNASNA
HDFSHDFS HDFSHDFS
ZettaVox Services SOLR MySQL
Quantum4DQuantum4DZettaVox ClientZettaVox Client ZettaSearchClient
ZettaSearchClient
Hadoo
pNod
esApp
lication
Nod
eClient
Nod
e
Figure 18: Content Search and Analytics: Workflow on SGI Hadoop Reference Implementation
8.1. Text Analytics This section describes a Text Analytics Application that has been run using Kitenga on SGI Hadoop Reference Implementation. In this Application:
ZettaVox is used to import biology‐themed
documents into HDFS.
The documents are processed by a machine‐learning‐based biological named entity extractor to extract protein names, DNA sequence names, RNA sequence names, cell lines, and other information.
The Application shows the results in a heat
map and a pie chart, supporting the interactive interrogation of the results (Figure 19).
Researchers can apply these approaches to
new domains of research, as well as to understanding relationships in large‐scale text corpora.
Figure 19: Heat Map and Pie Chart of results from a
biology‐themed document

24
8.2. Search Indexing This section describes an Application for indexing searched documents that has been run using Kitenga on SGI Hadoop Reference Implementation. In this Application: The ZettaVox client is used to author a Hadoop‐
enabled workflow for indexing documents.
During the indexing process, the people, places, and organizations are extracted from the documents.
Indexing is routed through a SOLR‐based indexing engine.
ZettaSearch is used to show search results with extracted metadata attached to different user interface artifacts, supporting the efficient drill‐down into the indexed documents for information discovery (Figure 20).
Figure 20: Indexed Search Results after extracting people, places and organizations for a search string
“NASA”.
8.3. Social Network Analytics This section describes a Social Network Analytics Application and shows how Kitenga ZettaVox integrates with Quantum4D three‐dimensional information visualization and modeling tool. The Application has been tested on SGI Hadoop Reference Implementation. In this Application:
Quantum4D (Q4D) allows for a 3D visualization of mash ups.
The ZettaVox client is used to author a Hadoop‐
enabled workflow for Social Network Analysis (SNA).
The SNA technology extracts people, places, and organizations from text resource crawled from the web or local to the system and finds the statistical correlations between them.
ZettaVox exports the filtered data from Hadoop into a MySQL database creating a new visualization “Space” in Quantum4D (See Figure 18).
The demo uses the generated MySpace® data to connect to other resources from the Q4D Metabase, identifies important information within the relationship graph and connects that information to other resources, to “mash up” the space with existing data.
Mashup generated from Social Network Analysis shows forty or so people, places, and organizations. Q4D allows for a 3D visualization of this particular mash up (Figure 21).
Figure 21: Visualizing a Mashup of people, places and organizations via Social Network
Analysis

25
The Datameer Analytics Solution (DAS) has been tested on SGI Hadoop RI. DAS is specifically end‐user‐focused for Hadoop‐based analytics. It provides four key elements: Seamless ELT (Extract, Load, and Transform) –
provides point‐and‐click integration with structured, semi‐ & unstructured data connectors and plug‐in APIs. There are 20+ pre‐built connectors included with DAS;
Powerful Analytics via an interactive spreadsheet UI with over 200 built‐in analytic functions;
Self‐Service, drag and drop dashboards with charts, graphs, maps and rich visualizations;
Mash‐up data from any data source to create personalized views or integrate into existing enterprise portals.
For more information, refer to www.datameer.com.

26
8.4. Financial Analytics This section describes a demonstration of a Financial Analytics Application using DAS on SGI Hadoop Reference Implementation. The application imports financial data into Hadoop’s HDFS, then filters and analyzes the data using a simple spreadsheet, presenting the analysis on dashboards with user‐defined look and feel. In this Application: DAS’s Data Integration module is used to import
AMEX stock price and volume data into HDFS from a local file system via SFTP/SSH, simulating the remote collection of market data from a third party.
In the DAS Analytics module, the imported data is processed in workbooks using interactive
spreadsheet like UI which has over 200 built‐in analytical functions.
DAS’s Visualization module delivers Interactive
dashboards and a variety of charts and tables are created with results from the spreadsheet analytics using simple drag & drop semantics.
The dashboards created can be accessed with a
URL that allows for Mashups and powerful visualization for business users.
Figures 22, 23 and 24 show the workbook analytics created from the imported data as well as the dashboards created from the workbook during analytics.
Figure 22: Workbook for Financial Analytics on SGI Hadoop Reference Implementation

Figure 23: Dashboard showing Stock Volume by date and closing stock price for “PDC”
Figure 24: Dashboard showing Line chart and Bubble graph of open & close stock price for “PDC”

28
Pentaho has been tested on SGI Hadoop Reference Implementation. This enables a user to reap the benefits of Hadoop by making it easier and faster to create BI applications. The Pentaho® Data Integration (PDI) for Hadoop provides: Highly scalable ETL (Extract, Transform and
Load) for Hadoop data; Massively scalable ETL via deployment across
Map Reduce clusters; Coordination and execution of Hadoop tasks via
Pentaho management console; Pentaho Agile BI to rapidly design and develop
BI applications;
Hybrid analytics of unstructured Hadoop data and structured data from other sources.
Pentaho BI Suite for Hadoop provides: Batch (production) or ad‐hoc reporting via HIVE
with Hadoop; Ad‐hoc reporting with HIVE so users don’t need
to know SQL. Refer to Figure 25. For more information, refer to: http://www.pentaho.com/hadoop/
Hadoop ServerJob Tracker
Hadoop ServerJob Tracker
HadoopTask Manager
HadoopTask ManagerHadoopTask Manager
HadoopTask Manager
HadoopTask Manager/Data Node
HadoopTask Manager/Data Node
Hadoop ServerName node
Hadoop ServerName node
TransformTransform ImportImport Data Source ConnectorsData Source ConnectorsExportExport
HDFS/HBASEHDFS/HBASE
HDFS/HBASEHDFS/HBASE
Pentaho PDI
Pentaho BI SUITE DASHBOARDS & REPORTSPentaho BI SUITE DASHBOARDS & REPORTS
Hadoo
pNod
esApp
lication
Nod
eClient
Nod
e
Hive MySQLHBase Pig
Figure 25: Data Integration and BI Workflow on SGI Hadoop Reference Implementation
8.5. BI on Hadoop This section describes an Application workflow on SGI Hadoop RI using Pentaho Data Integration (PDI) to import data, followed by Pentaho BI Suite to perform BI using Hive Query Language. In this Application:
PDI is used to import data into HDFS;
Queries are submitted via the Hive JDBC connection;
MapReduce jobs are generated and executed by Hive. The results are streamed to a relational database where they are accessible via a Metadata layer.
The BI Suite allows for interactive BI queries using drag/drop facility, running batch jobs, ad‐hoc reporting and analytics.
Figures 26 and 27 shows the import job, Hive QL capability, running BI queries using drag/drop, and exporting the results to a dashboard.

29
Developers who are used to writing SQL queries in a RDBMS world can combine Pentaho PDI and Hive QL for executing BI queries atop Hadoop.
Figure 26: Running Interactive BI queries using drag/drop facility on SGI Hadoop RI
Figure 27: Data Integration to SGI Hadoop RI for Hive‐based BI

30
9. Summary
As depicted in this paper, SGI® Rackable™ half‐depth and full‐depth servers can combine affordable price/performance, super‐linear scalability, disk capacity, Rack density, power and cooling efficiency to serve as Hadoop nodes in a cluster. This enables adding more of these server hosts into a rack or scaling out to multiple Racks to minimize energy usage and maintain an optimal performance and capacity level in a Data Center for Hadoop deployments. The Hadoop Reference Implementations from SGI provide a pre‐optimized integrated platform for customers who have not only deployed Hadoop in their Data Centers but also thinking of investing in such deployments. A Hadoop cluster delivered ready‐to‐run alleviates the apprehension of its adoption by leveraging SGI Ecosystem ‐ Skills, Knowledge, People, Partners. To summarize: – SGI Rackable clusters can deal with challenges in
volume, velocity, variety and value of unstructured data for fast transactions and deep analytics;
– Flexibility of choice of memory, compute,
capacity, I/O, network latency, and low power of Rackable Rackmount servers helps to:
Optimize task assignment and expedite
MapReduce tasks across distributed nodes with efficient parallelism;
Maintain filesystem metadata operations for HDFS;
Store large HDFS files and handle HDFS read/write requests;
Co‐locate I/O with TaskTrackers for optimal data locality;
Achieve optimal performance‐per‐watt across all load levels.
– The SGI Hadoop Reference Implementations are
able to provide a linear Terasort scalability with an affordable price/performance ($/TPM),
where TPM is the Terasort‐Throughput per minute;
– SGI Hadoop Reference implementations are
built on top of standard Apache Hadoop distributions and provides a modular approach to various verticals;
– SGI Hadoop Reference Implementations offer
data ingestion followed by data integration capabilities to HDFS;
– With an ecosystem of various analytical options
on top of Hadoop, the SGI Hadoop Reference Implementations offer a best‐in‐class business intelligence solution over Hadoop, all out of the box.
The SGI Hadoop Reference Implementations are most suitable for Manufacturing, Social Media/Online Gaming, Financial Trading, Federal, Telecommunications and other commercial markets, where large scalability, energy efficiency for server consolidation and extreme performance of Big Data Analytics, are the primary goals.
Contact: Sanhita Sarkar Big Data Solutions & Performance, SGI, 46555 Landing Parkway Fremont, CA 94538

© 2012 Silicon Graphics International Corp. All rights reserved. SGI and Rackable registered trademarks or trademarks of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. Intel and Xeon are trademarks of Intel Corporation. All other trademarks are property of their respective holders.