kshitij judah eecs, osu dissertation proposal presentation
TRANSCRIPT

Developing Learning Systems that Interact and Learn from Human Teachers
Kshitij JudahEECS, OSU
Dissertation Proposal Presentation

Outline PART I: User-Initiated Learning
PART II: RL via Practice and Critique Advice
PART III: Proposed future directions for the PhD program Extending RL via practice and critique advice Active Learning for sequential decision making

PART IUser-Initiated Learning

• All of CALO’s learning components can perform Learning In The Wild (LITW)
• But the learning tasks are all pre-defined by CALO’s engineers:– What to learn– What information is relevant for learning– How to acquire training examples– How to apply the learned knowledge
• UIL Goal: Make it possible for the user to define new learning tasks after the system is deployed
User-Initiated Learning (UIL)

TIMELINE
Scientist
Sets sensitivity to confidential
Sends email to team
Sends email to a colleague
“Lunch today?”
Does not set sensitivity to confidential
Collaborates on aClassified project
Sends email to team
Forgets to set sensitivity to confidential
Research Team
Motivating Scenario:Forgetting to Set Sensitivity

“Please do not forget to set sensitivity when sending email”
Scientist
Research TeamTeaches CALO to learn to
predict whether user has forgot to set sensitivity
Sends email to team
CALO reminds user to set sensitivity
Motivating Scenario:Forgetting to Set Sensitivity
TIMELINE

SAT Based Reasoning System
SPARKProcedure
InstrumentedOutlook Event
s
user
Integrated Task Learning
user
Modify Procedure
Procedure Demonstration and Learning Task Creation
User Interface for Feature Guidance
User SelectedFeatures
user
Feature Guidance
Email + Related Objects
CALO Ontology
TrainedClassifier
Feature Guidance
Machine Learner
KnowledgeBase
Training Examples
Learning
Legal Features
SAT Based Reasoning System
Class Labels
User-CALO Interaction: TeachingCALO to Predict Sensitivity
Compose new email

SAT Based Reasoning System
SPARKProcedure
InstrumentedOutlook Event
s
user
Integrated Task Learning
user
Compose new email
Modify Procedure
Procedure Demonstration and Learning Task Creation
User Interface for Feature Guidance
User SelectedFeatures
user
Feature Guidance
Email + Related Objects
CALO Ontology
TrainedClassifier
Feature Guidance
Machine Learner
KnowledgeBase
Training Examples
Learning
Legal Features
SAT Based Reasoning System
Class Labels
User-CALO Interaction: TeachingCALO to Predict Sensitivity

SAT Based Reasoning System
SPARKProcedure
InstrumentedOutlook Event
s
user
Integrated Task Learning
user
Compose new email
Modify Procedure
Procedure Demonstration and Learning Task Creation
User Interface for Feature Guidance
User SelectedFeatures
user
Feature Guidance
Email + Related Objects
CALO Ontology
TrainedClassifier
Feature Guidance
Machine Learner
KnowledgeBase
Training Examples
Learning
Legal Features
SAT Based Reasoning System
Class Labels
User-CALO Interaction: TeachingCALO to Predict Sensitivity

SAT Based Reasoning System
SPARKProcedure
InstrumentedOutlook Event
s
user
Integrated Task Learning
user
Compose new email
Modify Procedure
Procedure Demonstration and Learning Task Creation
User Interface for Feature Guidance
User SelectedFeatures
user
Feature Guidance
Email + Related Objects
CALO Ontology
TrainedClassifier
Feature Guidance
Machine Learner
KnowledgeBase
Training Examples
Learning
Legal Features
SAT Based Reasoning System
Class Labels
User-CALO Interaction: TeachingCALO to Predict Sensitivity

Assisting the User: Reminding

• Logistic Regression is used as the core learning algorithm
• Features– Relational features extracted from ontology
• Incorporate User Advice on Features– Apply large prior variance on user selected features– Select prior variance on rest of the features through cross-
validation
• Automated Model Selection– Parameters: Prior variance on weights, classification threshold– Technique: Maximization of leave-one-out cross-validation
estimate of kappa ()
The Learning Component

• Problems:– Attachment Prediction– Importance Prediction
• Learning Configurations Compared:– No User Advice + Fixed Model Parameters– User Advice + Fixed Model Parameters– No User Advice + Automatic parameter Tuning– User Advice + Automatic parameter Tuning
• User Advice: 18 keywords in the body text for each problem
Empirical Evaluation

• Set of 340 emails obtained from a real desktop user
• 256 training set + 84 test set
• For each training set size, compute mean kappa () using test set to generate learning curves
• is a statistical measure of inter-rater agreement for discrete classes
• is a common evaluation metric in cases when the classes have a skewed distribution
Empirical Evaluation: Data Set

Attachment Prediction
Empirical Evaluation: Learning Curves

Importance Prediction
Empirical Evaluation: Learning Curves

• We intended to test the robustness of the system to bad advice
• Bad advice was generated as follows:– Use SVM based feature selection in WEKA to
produce a ranking of user provided keywords
– Replace top three words in the ranking with randomly selected words from the vocabulary
Empirical Evaluation: Robustness to Bad Advice

Attachment Prediction
Empirical Evaluation: Robustness to Bad Advice

Importance Prediction
Empirical Evaluation: Robustness to Bad Advice

• User interfaces should support rich instrumentation, automation, and intervention
• User interfaces should come with models of their behavior
• User advice is helpful but not critical
• Self-tuning learning algorithms are critical for success
Lessons Learned

PART IIReinforcement Learning via Practice
and Critique Advice

PROBLEM: Usually RL takes a long time to learn a good policy.
Reinforcement Learning (RL)
Teacher
behavior
advice
RESEARCH QUESTION: Can we make RL perform better with some outside help, such as critique/advice from teacher and how?
GOALS: Non-technical
users as teachers
Natural interaction methods
state
action
rewardEnvironment

RL via Practice + Critique Advice
?Policy Parameters
Trajectory Data
Practice Session
Advice Interface
In a state si action ai is bad, whereas action aj is good. Teacher
Critique Session
Critique Data

Solution Approach
Trajectory Data
Practice Session
Advice Interface
In a state si action ai is bad, whereas action aj is good. Teacher
Critique Session
Policy Parameters
Critique Data
Estimate Expected Utility using Importance Sampling.(Peshkin & Shelton, ICML 2002)

Critique Data Loss L(θ,C)
Imagine: Our teacher is an Ideal Teacher (Provides All Good Actions)
Set of all Good
actions
Any action not in O(si) is suboptimal according to Ideal
Teacher
All actions
are equallygood
Advice Interface
Ideal Teacher
Advice Interface
Some good
actions
Some bad actions
Some actions
unlabeled

‘Any Label Learning’ (ALL)
Imagine: Our teacher is an Ideal Teacher (Provides All Good Actions)
Set of all Good
actions
Any action not in O(si) is suboptimal according to Ideal
Teacher
All actions
are equallygood
Advice Interface
Ideal Teacher
Learning Goal: Find a probabilistic policy, or classifier, that has a high probability of returning an action in O(s) when applied to s.
ALL Likelihood (LALL(,C)) :
Probability of selecting an action in O(Si) given state si

Critique Data Loss L(θ,C) Coming back to reality: Not All Teachers are Ideal !
and provide partial evidence about O(si)
Advice Interface
What about the naïve approach of treating as the true set O(si) ? Difficulties: When there are actions outside of that are equally good
compared to those in , the learning problem becomes even harder.
We want a principled way of handling the situation where either or can be empty.

Expected Any-Label Learning
The Gradient of Expected Loss has a compact closed form.
…
and provide partial evidence about O(si)
User Model Assume independence among different states.
From corresponding for all states , we can get:
Expected ALL Loss:

Map 1 Map 2
Experimental Setup
Our Domain: Micro-management in tactical battles in the Real Time Strategy (RTS) game of Wargus.
5 friendly footmen against a group of 5 enemy footmen (Wargus AI).
Two battle maps, which differed only in the initial placement of the units.
Both maps had winning strategies for the friendly team and are of roughly the same difficulty.
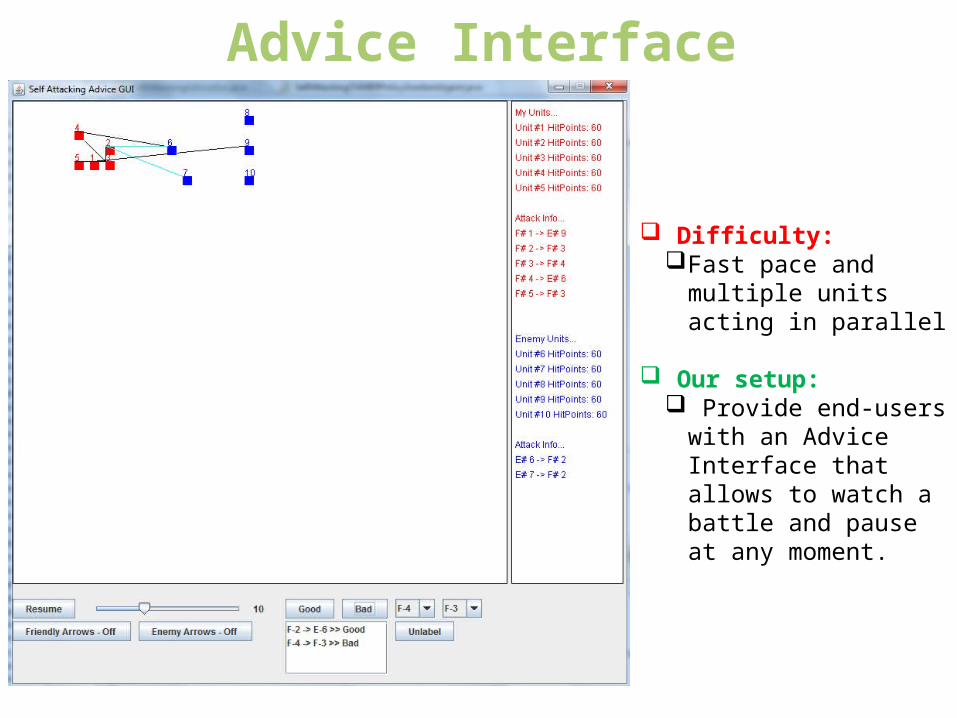
Advice Interface
Difficulty:Fast pace and
multiple units acting in parallel
Our setup: Provide end-users
with an Advice Interface that allows to watch a battle and pause at any moment.

Goal is to evaluate two systems1. Supervised System = no practice session2. Combined System = includes practice and
critique
The user study involved 10 end-users 6 with CS background 4 no CS background
Each user trained both the supervised and combined systems
30 minutes total for supervised 60 minutes for combined due to additional time
for practice
Since repeated runs are not practical results are qualitative
To provide statistical results we first present simulated experiments
User Study

Simulated Experiments
After user study, selected the worst and best performing users on each map when training the combined system
Total Critique data: User#1: 36, User#2: 91, User#3: 115, User#4: 33.
For each user: divide critique data into 4 equal sized segments creating four data-sets per user containing 25%, 50%, 75%, and 100% of their respective critique data.
We provided the combined system with each of these data sets and allowed it to practice for 100 episodes. All results are averaged over 5 runs.

Simulated Experiments Results:Benefit of Critiques (User #1)
RL is unable to learn a winning policy (i.e. achieve a positive value).

Simulated Experiments Results:Benefit of Critiques (User #1)
With more critiques performance increases a little bit.

As the amount of critique data increases, the performance improves for a fixed number of practice episodes.
RL did not go past 12 health difference on any map even after 500 trajectories.
Simulated Experiments Results:Benefit of Critiques (User #1)

Simulated Experiments Results:Benefit of Practice (User #1)
Even with no practice, the critique data was sufficient to outperform RL.
RL did not go past 12 health difference.

Simulated Experiments Results:Benefit of Practice (User #1)
With more practice performance increases too.
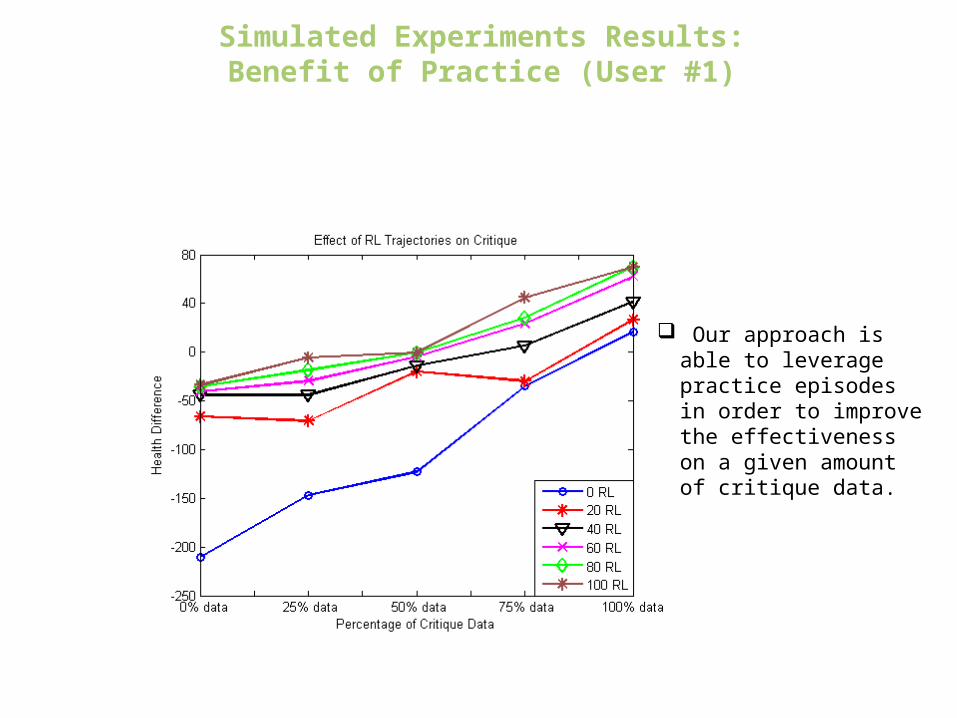
Simulated Experiments Results:Benefit of Practice (User #1)
Our approach is able to leverage practice episodes in order to improve the effectiveness on a given amount of critique data.

Goal is to evaluate two systems1. Supervised System = no practice session2. Combined System = includes practice and
critique
The user study involved 10 end-users 6 with CS background 4 no CS background
Each user trained both the supervised and combined systems
30 minutes total for supervised 60 minutes for combined due to additional time
for practice
Results for Actual User Study

Results of User Study
-50 0 50 80 1000123456789
10
Health Difference Achieved by Users
SupervisedCombined
Health Difference
Num
ber o
f Use
rs
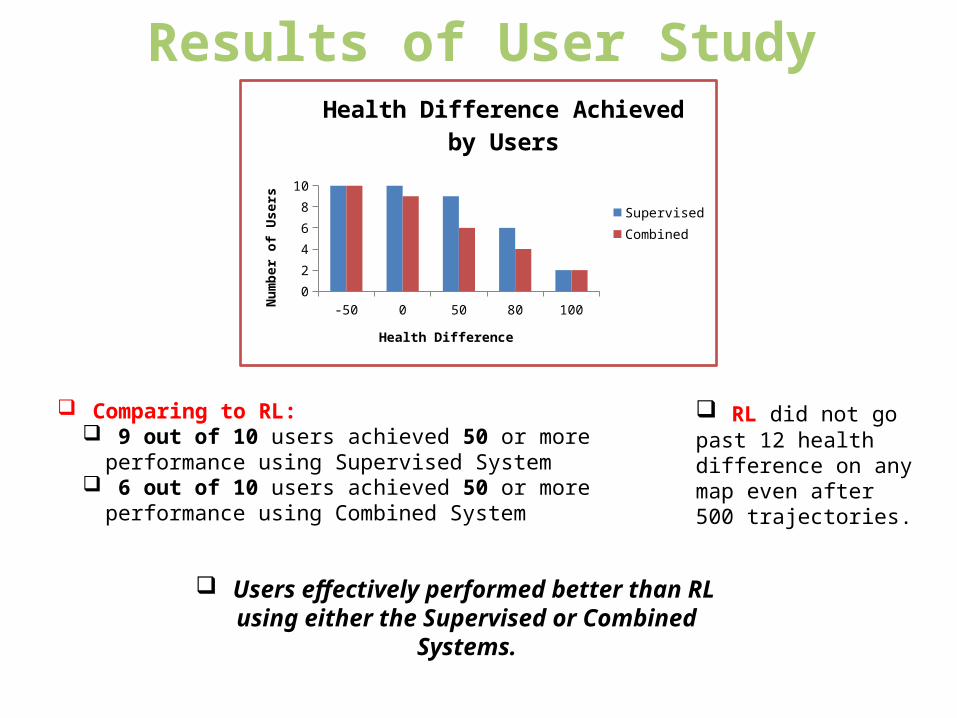
Results of User Study
Comparing to RL: 9 out of 10 users achieved 50 or more
performance using Supervised System 6 out of 10 users achieved 50 or more
performance using Combined System
Users effectively performed better than RL using either the Supervised
or Combined Systems.
RL did not go past 12 health difference on any map even after 500 trajectories.
-50 0 50 80 1000123456789
10
Health Difference Achieved by Users
SupervisedCombined
Health Difference
Num
ber o
f Use
rs

Results of User Study
Frustrating Problems for Users Large delay experience. (not an issue in many
realistic settings)
Policy returned after practice was sometimes poor, seemed to be ignoring advice. (perhaps practice sessions were too short)
Comparing Combined and Supervised: The end-users had slightly greater success
with the supervised system v/s the combined system.
More users were able to achieve performance levels of 50 and 80 using the supervised system.
-50 0 50 80 1000123456789
10
Health Difference Achieved by Users
SupervisedCombined
Health Difference
Num
ber o
f Use
rs

PART IIIFuture Directions

Future Direction 1: Extending RL via Practice and Critique Advice
Understanding the effects of user models: Study sensitivity of our algorithm to various settings of
model parameters. Robustness of our algorithm against inaccurate
parameter settings. Study benefits of using more elaborate user models.
Understanding the effects of mixing advice from multiple teachers: Pros: addresses incompleteness and lack of quality of
advice from a single teacher. Cons: introduces variations and more complex patterns
that are hard to generalize. Study benefits and harms of mixing advice.
Understanding the effects of advice types: Study the effects of feedback only versus mixed advice.

Future Direction 2: Active Learning for Sequential Decision Making
Current advice collection mechanism is very basic: An entire episode is played before the teacher. Teacher scans the episode to locate places where
critique is needed. Only one episode is played.
Problems with current advice collection mechanism: Teacher is fully responsible for locating places where
critique is needed. Scanning an entire episode is very cognitively
demanding. Good possibility of missing places where advice is
critical. Showing only one episode is a limitation, especially in
stochastic domains.
GOAL: Learner should itself discover places where it needs advice and query teacher at those places.
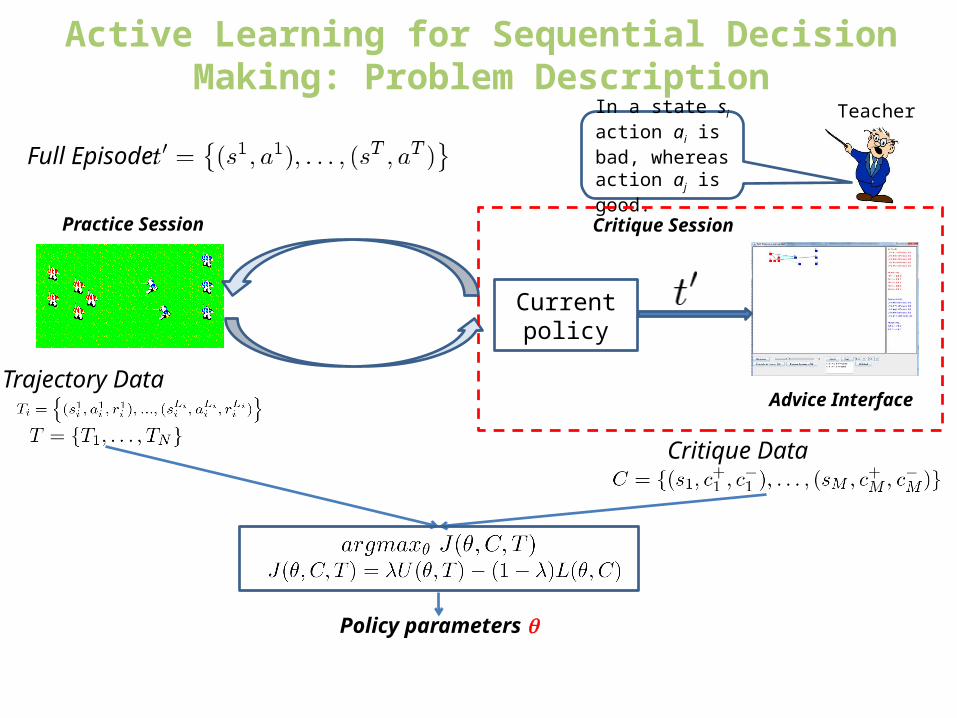
Trajectory Data
Practice Session
Advice Interface
In a state si action ai is bad, whereas action aj is good.
Teacher
Critique Session
Policy parameters
Critique Data
Active Learning for Sequential Decision Making: Problem Description
Currentpolicy
Full Episode:

Trajectory Data
Practice Session
Advice Interface
In a state si action ai is bad, whereas action aj is good.
Teacher
Critique Session
Policy parameters
Critique Data
Active Learning for Sequential Decision Making: Problem Description
Active LearningModule
Best sequence:
Currentpolicy
CostModel ($
$)
Problem: How to select that best optimizes benefit-to-cost tradeoff?

What about existing techniques?
Few techniques exist for the problem of ‘active learning’ in sequential decision making with an external teacher
All techniques make some assumptions that work only for certain applications
Some techniques request full demonstration from start state
Some techniques assume teacher is always available and request a single or multi-step demonstration when needed
Some techniques removes assumption of teacher being present at all times but they pause till the request for demonstration is satisfied

What about existing techniques?
We feel such assumptions are unnecessary in general
Providing demonstration is quite labor intensive and sometimes not even practical
We instead seek feedback and guidance on potential execution traces of our policy
Pausing and waiting for the teacher is also inefficient
We never want to pause but keep generating execution traces from our policy for teacher to critique later when he/she is available

What about Supervised Active Learning techniques?
Active learning is well developed for supervised setting
All instances come from single distribution of interest
Best instance is selected based on some criterion and queried for its label
In our setting, the distribution of interest is the distribution of states along the teacher's policy (or a good policy)
Asking queries about states that are far off of the teacher's policy is likely to not produce any useful feedback (losing states in Chess or Wargus)
Learner faces additional challenge to identify states that occur along the teacher's policy and query in those states

Proposed Approach for Supervised Setting
Define new performance metric: Expected Common Prefix Length (ECPL):
is # of time steps and agree up to first disagreement, starting from

State with first disagreement
Common Prefix Length
Unimportant States
Proposed Approach for Supervised Setting

Proposed Approach for Supervised Setting
Ideally we should select sequences that directly maximize ECPL
Heuristic: Identify sequence that contains states with high probability of first disagreement (similar to uncertainty sampling)
Common Prefix Length
Unimportant States
States where first disagreement is likely
High ConfidenceExecution(most likely we are on right path)
Low ConfidenceExecution(most likely we are going to make a wrong turn)
(most likely we should not be here)

Proposed Approach for Supervised Setting
Fixed length sequences
Variable length sequences: compute optimal length that trades off benefit from critique versus cost of critique. We plan to use return on investment heuristic proposed by Haertel et. Al. (Return on Investment for Active Learning, NIPS Workshop on Cost Sensitive Learning, 2009)
Common Prefix Length
Unimportant States
States where first disagreement is likely
High ConfidenceExecution(most likely we are on right path)
Low ConfidenceExecution(most likely we are going to make a wrong turn)
(most likely we should not be here)

Proposed Approach for Practice Setting
Practice followed by active learning: let the agent practice, when critique session starts use heuristics from supervised setting to select best sequence for the current policy
Modify heuristic from supervised setting: Can we better discover sequences with first disagreement using information from practice
Based on self assessment during practice

Evaluation Plans
We will use RTS game Wargus as our domain
Extend our current tactical battle micromanagement scenarios with more and different types of combat units
Teach control policies for attack and maneuver behavior of individual units
Teach policies to control low-level actions in resource gathering tasks
User Studies: Conduct further user studies

Research Timeline
Period Research Topic
Aug 2010 Get proposal approved.
Sept-Oct 2010 Active learning in supervised setting, teacher models (for journal).
Nov-Dec 2010 Active learning in practice setting, advice patterns (for journal).
Jan 2011 Submit a paper to IJCAI/AAAI.
Feb-Mar 2011 Start writing journal paper, mixing advice (for journal).
Apr-May 2011 Finish writing journal paper, start writing dissertation.
June-Aug 2011 Finish writing dissertation, submit journal paper.
Sept 2011 defense.

Conclusion
Presented our completed work on: User-Initiated Learning RL via Practice and Critique Advice
Proposed future directions for the PhD program: Extending RL via practice and critique advice Active Learning for sequential decision making
Presented potential approaches and evaluation plans in order to carry out proposed work
Presented a timeline for completing the proposed work

Questions ?