jamie kinney, aws scientific computing [email protected]
TRANSCRIPT

© 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
Scientific Computing on Amazon Web ServicesJamie Kinney, AWS Scientific Computing

AWS Scientific Computing (SciCo)

Scientific Computing Initiatives
Y0L0!

Why does Amazon care about Scientific Computing?• In order to meaningfully change our world for the better by accelerating
the pace of scientific discovery
• It is a great application of AWS with a broad customer base
• The scientific community helps us innovate on behalf of all customers– Streaming data processing & analytics– Exabyte scale data management solutions and exaflop scale compute– Collaborative research tools and techniques– New AWS regions– Significant advances in low-power compute, storage and data centers– Efficiencies which will lower our costs and therefore pricing for all customers

Why Did We Create SciCo?
In order to make it easy to find, discover and use AWS for scientific computing at any scale. Specifically, SciCo helps AWS:
• More effectively support global “Big Science” Collaborations• Develop a solution-centric focus for engaging with the global scientific and
engineering communities• Accelerate the development of a scientific computing ecosystem on AWS• Educate and Evangelize our role in Scientific Computing

How is AWS Used for Scientific Computing?
• High Performance Computing (HPC) for Engineering and Simulation
• High Throughput Computing (HTC) for Data-Intensive Analytics• Collaborative Research Environments• Hybrid Supercomputing centers• Citizen Science• Science-as-a-Service

Why do researchers love using AWS?
Time to ScienceAccess research
infrastructure in minutes
Low CostPay-as-you-go pricing
ElasticEasily add or remove capacity
Globally AccessibleEasily Collaborate with
researchers around the world
SecureA collection of tools to
protect data and privacy
ScalableAccess to effectively
limitless capacity

Research Grants
AWS provides free usage credits to help researchers:• Teach advanced courses• Explore new projects• Create resources for the
scientific community
aws.amazon.com/grants

Amazon Public Data Sets

AWS hosts “gold standard” reference data at our expense in order to catalyze rapid innovation and increased AWS adoption
A few examples:
• 1,000 Genomes ~250 TB
• Cancer Genomics Data Sets ~2-6 PB
• Astronomy Data and APIs 1PB+
• Common Crawl
• OpenStreetMap
• Census Data
Public Data Sets

Peering with all global research networks
Image courtesy John Hover - Brookhaven National Lab
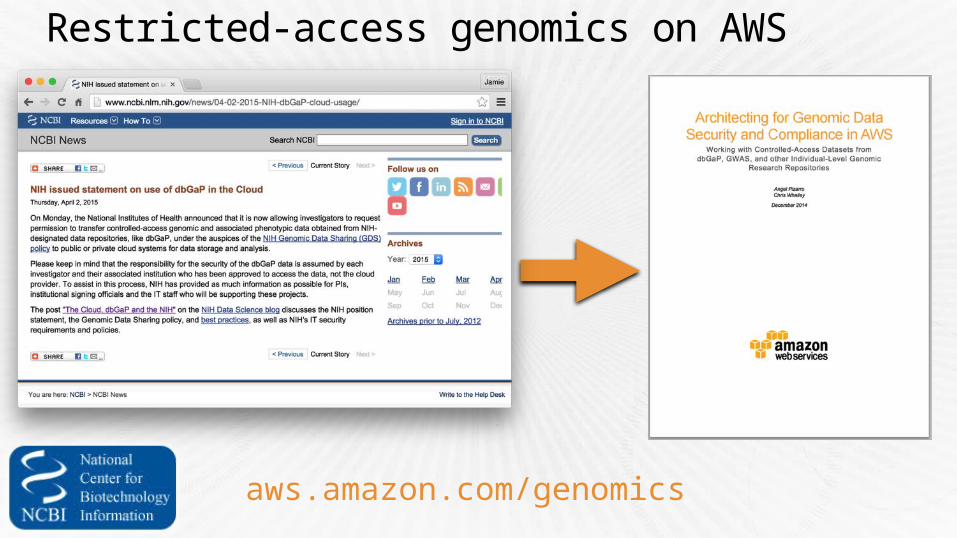
Restricted-access genomics on AWS
aws.amazon.com/genomics

Curiosity Remote Control Overview

HPC on AWS

Characterizing HPC
Tightly Coupled
Loosely Coupled
Embarrassingly
parallel
Elastic
Batch workloads
Interconnected jobs
Network sensitivity
Job specific
algorithms

Characterizing HPC
Tightly Coupled
Loosely Coupled
Supporting
Services
Embarrassingly
parallel
Elastic
Batch workloads
Data management
Task distribution
Workflow
management
Interconnected jobs
Network sensitivity
Job specific
algorithms
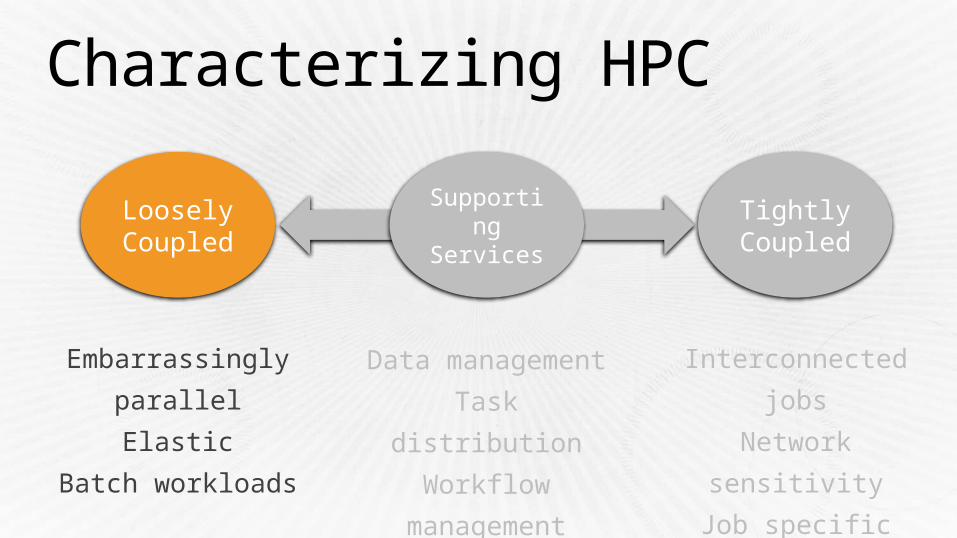
Characterizing HPC
Tightly Coupled
Loosely Coupled
Supporting
Services
Embarrassingly
parallel
Elastic
Batch workloads
Data management
Task distribution
Workflow
management
Interconnected jobs
Network sensitivity
Job specific
algorithms
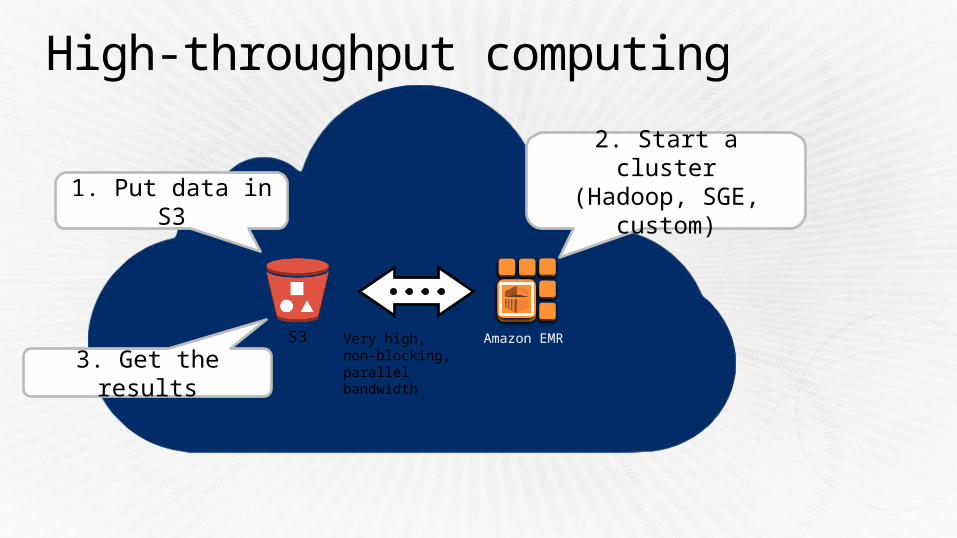
High-throughput computing
S3 Amazon EMRVery high,non-blocking, parallel bandwidth
2. Start a cluster(Hadoop, SGE,
custom)1. Put data in S3
3. Get the results

Easily scale to more computational nodes

Computational compound analysisSolar panel material Estimated serial computation time 264 years
156,314 core cluster across 8 regions1.21 petaFLOPS (Rpeak)
Simulated 205,000 materials18 hours for $33,000 16¢ per molecule
http://news.cnet.com/8301-1001_3-57611919-92/supercomputing-simulation-employs-156000-amazon-processor-cores/

Use Spot instances to save $$$
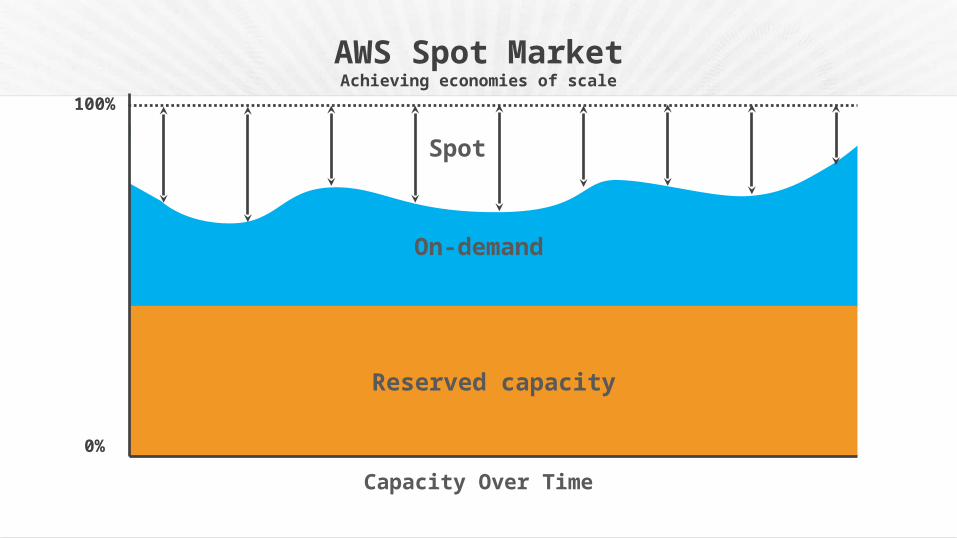
On
On-demand
Reserved capacity
100%
Capacity Over Time
AWS Spot MarketAchieving economies of scale
Spot
0%

How do Spot instances work?
2 minute warning

Spot price market examples
• r3.2xlarge– 8 vCPU– 61GB RAM– 1 x 160GB D– $0.70 per hour
* Prices on April 17, 2015

Spot price market examples
• r3.4xlarge– 16 vCPU– 122GB RAM– 1 x 320GB SSD– $1.40 per hour
* Prices on April 17, 2015

Spot price market examples
• c3.8xlarge– 32 vCPU– 60GB RAM– 2 x 320 SSD– $1.68 per hour
* Prices on April 17, 2015

Spot friendly workloads• All Spot applications should be…
– Time-flexible: You can’t expect Spot to always be available, so they can wait until it is, or use OD/RI instances
– Fault-tolerant: the application can gracefully handle Spot interruptions– (Because Spot may not be available and Spot Instances may be interrupted)
• Great Spot applications are…– Distributed: the application has jobs that can be spread out across many
Spot Instances, instance types, AZs, even regions– Scalable: the application can pile on more Spot Instances in parallel to get
its job(s) done faster– (Access up to 10,000s of Spot Instances worldwide)

Spot friendly architectures
• Fault tolerant– Worker resources are ephemeral
• De-centralized workflows– Worker resources can run in multiple Availability Zones
• Stateless applications– Worker resources grab work items and data from resilient data
stores– Amazon SQS, Amazon SWF, Amazon S3

Using Spot effectively – normalize application requirements
• CPU Generation (Intel AVX2.0 in Haswell)• Memory/core• Networking

Using Spot effectively – bidding strategies
• You only pay what current Market price• But, bid what you are willing to pay
Bid only what you are willing to pay.
(by default, bid limited to 4 * On Demand Price)

Frontend Applicationson On-Demand/Reserved Instances
+
Backend Applications*on Spot Instances
* e.g., image segmentation, genomic alignment
Use On-Demand & Spot

Amazon EC2 Auto Scaling Spotaws autoscale create-launch-configuration --launch-configuration-name spotlc-5cents --image-id ami-e565ba8c --instance-type d2.2xlarge --spot-price “0.25”
aws autoscale create-auto-scaling-group --auto-scaling-group-name spotasg --launch-configuration spotlc-5cents --availability-zones “us-east-1a,us-east-1b” --max-size 16 --min-size 1 --desiredcapacity 3
http://aws.amazon.com/cli/

Leverage Spot instances in workflows1 days worth of effort
resulted in 50% savings in cost
Harvard Medical SchoolThe Laboratory of Personal Medicine
Run EC2 clusters to analyze entire genomes
“The AWS solution is stable, robust, flexible, and low cost. It has everything to recommend it.”
Dr. Peter Tonellato, LPM, Center for Biomedical Informatics, Harvard Medical School
http://aws.amazon.com/solutions/case-studies/harvard/
https://cosmos.hms.harvard.edu/

Parallel clusters can work on the same data
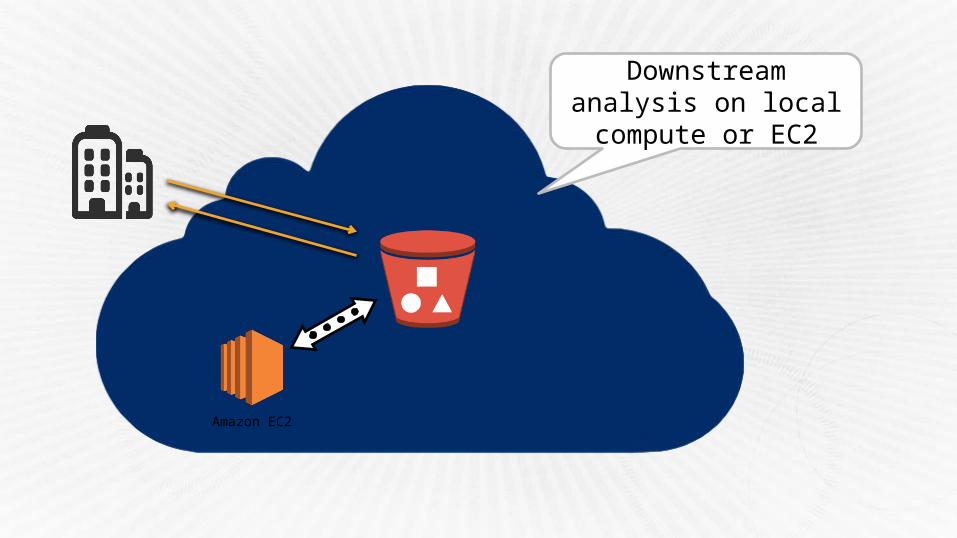
Amazon EC2
Downstream analysis on local compute or
EC2

Launch in VPC for secure computing

Science Ecosystem
StorageDatabaseCompute

Partner Ecosystem

Characterizing HPC
Tightly Coupled
Loosely Coupled
Supporting
Services
Embarrassingly
parallel
Elastic
Batch workloads
Data management
Task distribution
Workflow
management
Interconnected jobs
Network sensitivity
Job specific
algorithms

Cluster instances deployed in a ‘Placement
Group’ enjoy low latency, full bisection 10
Gbps bandwidth
10Gbps
Network placement groups

Enhanced Networking: SR-IOVA standardized way for a single I/O device to present itself as multiple separate device
http://glennklockwood.blogspot.com/2013/12/high-performance-virtualization-sr-iov.html

OpenFOAM® Computational Fluid Dynamics software simulating the environmental conditions at Cyclopic Energy’s wind power sites
Case Study
Cyclopic EnergyCluster Compute
Two months worth of simulations in a two-day period
“AWS makes it possible for us to deliver state-of-the-art technologies to clients within timeframes that allow us to be dynamic, without having to make large investments in physical hardware.”

Intel Xeon E5-2670 (Sandy Bridge)
15GB or 60GB RAM
1 NVIDIA Grid k520 GPU 1,536 Cores4GB Mem
GPU instance sizeGPU Optimized
Name GPU vCPUMemory
(GiB)Networ
kSSD
g2.2xlarge
1 8 15 High 1 x 60
g2.8xlarge
4 32 60 10 Gb 2 x 120

Massive parallel clusters running in
GPUs
NVIDIA Tesla cards in specialized
instance types
CUDA & OpenCL

Case Study
National Taiwan University50 x cg1.4xlarge instance types
100 nvidia Tesla M2050
“Our purpose is to break the record of solving the shortest vector problem (SVP) in Euclidean lattices…the vectors we found are considered the hardest SVP anyone has solved so far.”
Prof. Chen-Mou Cheng, the Principal Investigator of Fast Crypto Lab
$2,300 for using 100 Tesla M2050 for ten hours

Characterizing HPC
Tightly Coupled
Loosely Coupled
Supporting
Services
Embarrassingly
parallel
Elastic
Batch workloads
Data management
Task distribution
Workflow
management
Interconnected jobs
Network sensitivity
Job specific
algorithms

Middleware Services
Data managementFully managed SQL, NoSQL and object storage
1
Relational Database
Service
Fully managed database
(MySQL, Oracle, MSSQL)
DynamoDB
NoSQL, Schemaless,
Provisioned throughput
database
S3
Object datastore up to
5TB per object
99.999999999%
durability

Collection CollaborationComputation
Moving computation nearer the
data“Big Data” changes dynamic of computation and data
sharing
Direct Connect
Import/Export
S3
DynamoDB
EC2
GPUs
Elastic Map Reduce
CloudFormation
Simple Workflow
S3

Middleware Services
Feeding workloadsUsing highly available Simple Queue
Service to feed EC2 nodes
2
Amazon SQS
Processing
task/processing
trigger
Processing results

Middleware Services
Coordinating workloads & task clustersHandle long running processes across many nodes and task
steps with Simple Workflow
3
Task A
Task B
(Auto-
scaling)Task C
2
3
1

Other Stuff

• A centralized repository of public datasets
• Seamless integration with cloud based applications
• No charge to the community• Tell us what else you’d like for
inclusion …
AWS Public Data Sets1000 Genomes Project
Genome in A Bottle
Landsat 8
NASA NEX: Earth science data sets
The Cannabis Sativa Genome
US Census Data: US demographic data from 1980, 1990, and 2000 US Censuses
Freebase Data Dump: A data dump of all the current facts and assertions in the Freebase system, an open database covering millions of topics
Google Books n-grams

SDKs
Java Python PHP .NET Ruby nodeJS
iOS Android AWS Toolkit for Visual
Studio
AWS Toolkit for Eclipse
Tools for Windows
PowerShell
CLI

AWS Services are a few clicks away…
https://console.aws.amazon.com

AWS Research Grantshttp://aws.amazon.com/grants

A Simple Form