introduzione al corso di bioinformatica e analisi dei genomi aa...
TRANSCRIPT

Introduzione al corso di bioinformatica e analisi dei genomi
AA 2015-2016
Docente: Silvia Fuselli

Possibili testi di riferimento • Introduction to Genomics, A.M. Lesk, Oxford
– Capitoli 1, 3, 4, 6, 7
• Bioinformatica, Pascarella e Paiardini, Zanichelli
– Capitoli 1, 2, 3, 4, 5, 6
• Bioinformatic Data Skills, Vince Buffalo, O’REILLY

Materiale didattico
http://docente.unife.it/silvia.fuselli

Programma
I. Dimensioni ed organizzazione dei genomi (settembre)
a. Procarioti
b. Eucarioti
II. Metodologie di analisi dei genomi con particolare
approfondimento dei metodi di Next generation sequencing
(NGS) (prima metà di ottobre)
a. Frederick Sanger e lo sviluppo dei metodi di sequenziamento
b. I metodi di sequenziamento di seconda generazione (NGS): High Throughput
Sequencing
c. Metodi di sequenziamento di terza generazione: sequenziamento a singola
molecola (Single Molecule Real Time Technology e Nanopore sequencing)

Programma
III. Confronto di sequenze: allineamenti a coppie e allineamenti
multipli, ricerche di sequenze in banche dati, Basic Local
Alignment Search Tool (BLAST) (seconda metà di ottobre)
IV. Banche dati biologiche (con esercizi al Computer di
consultazione dei relative siti web) (prima metà di novembre)
a. National Center for Biotechnology Information (NCBI)
b. UCSC Genome Bioinformatics Site (o ENSEMBL)

Programma
V. Bioinformatica e next generation sequencing (12 ore in
dicembre)
• Questa parte del programma prevedera’ l’utilizzo di un computer per analizzare
dati di sequenziamento prodotti con metodologie High Throughput Sequencing
(tecnologia Illumina). In particolare esploreremo i passaggi attraverso i piu’ comuni
strumenti bioinformatici che dal dato grezzo di output dei sequenziatori
permettono di ottenere i file definitivi su cui e’ possibile effettuare interpretazioni
biologiche

Seconda parte del corso (LAB: laboratorio multimediale, Dip. SVEB, terzo piano sezione di Fisiologia)
Martedì Mercoledì Martedì Mercoledì Martedì Mercoledì Martedì Mercoledì Martedì Mercoledì
17-nov 18-nov 24-nov 25-nov 01-dic 02-dic 09-dic 15-dic 16-dic
Dott. Sandionigi
Dott. Sandionigi
Dott. Sandionigi Lab Lezione D5 Lab Lab Lab Lab Lab
Dott. Sandionigi
Dott. Sandionigi
Dott. Sandionigi Lab Lezione D5 Lab Lab Lab Pier Lab
Lab Lab
SBE
Martedì Mercoledì Martedì Mercoledì Lun 30-nov
Gio 03-dic Giovedì 10-dic Lun 14-dic Gio 17-dic
17-nov 18-nov 24-nov 25-nov 11.30-13.30
8.30-11.30
9.30-11.30 11.30-13.30 8.30-11.30
Dott. Sandionigi
Dott. Sandionigi Lezione D5
Dott. Sandionigi Lab Lab Lab Lab Lab Lab
Dott. Sandionigi
Dott. Sandionigi Lezione D5
Dott. Sandionigi Lab Lab Lab Lab Lab Lab
Lab Lab
BAS

Qualche definizione (wikipedia).. Genomics Genomics is a discipline in genetics that applies recombinant DNA, DNA sequencing methods, and bioinformatics to sequence, assemble, and analyze the function and structure of genomes (the complete set of DNA within a single cell of an organism) Bioinformatics Bioinformatics is an interdisciplinary field that develops methods and software tools for understanding biological data. As an interdisciplinary field of science, bioinformatics combines computer science, statistics, mathematics and engineering to study and process biological data.
Le due protagoniste del corso: Genomica e Bioinformaitica

Biologists
collect molecular data:
DNA & Protein sequences,
gene expression, etc.
Computer scientists
(+Mathematicians, Statisticians, etc.)
Develop tools, softwares, algorithms
to store and analyze the data.
Bioinformaticians
Study biological questions by
analyzing molecular data
Bioinformatics
The field of science in which biology, computer science and
information technology merge into a single discipline

Perché?
Noi ci occuperemo di bioinformatica di dati di sequenze di DNA



Lezione 1
Le molecole di base che costituiscono la vita

Le molecole dell’ereditarietà
L’informazione ereditaria di tutti gli organismi viventi, con l’eccezione di alcuni virus, è a carico della molecola dell’acido desossiribonucleico (DNA).
Legame debole
Legame forte
purina
purina
pirimidina
pirimidina
5’ 3’
3’ 5’
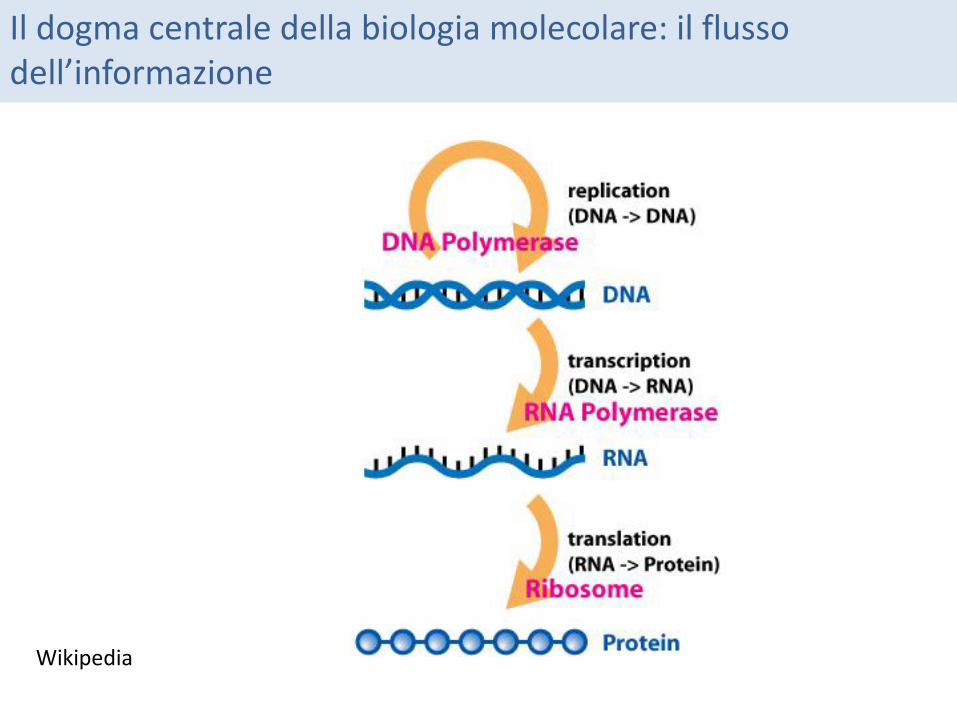
Il dogma centrale della biologia molecolare: il flusso dell’informazione
Wikipedia

La trascrizione: il DNA antisenso (strand -) 3’ -5’ viene trascritto in un RNA 5’-3’ (copia esatta del filamento “senso” cioè di quello codificante)
Il dogma centrale della biologia molecolare: il flusso dell’informazione

Codice genetico
La trascrizione
DNA strand+ DNA strand- mRNA
DNA strand +: la stessa tripletta dell’mRNA con T al posto di U
La traduzione Perchè triplette?
4 basi disponibili, 20 AA da codificare. Scopriamo quante lettere mettere in un codone (n) Combinazioni possibili: 4n
41 = 4 42 = 16 ancora troppo piccolo 43 = 64 prima potenza di 4 più grande del numero di AA

Il codice genetico universale è ridondante
Codice genetico

Il codice genetico organizzato secondo un criterio di degenerazione
six
Codice genetico
Perchè non 20 triplette codificanti e 44 stop codon? Alta probabilità che una mutazione produca uno stop codon (pericoloso!) Perchè alcuni aminoacidi sono codificati da pochi codoni e altri da molti? Ad esempio, il numero di codoni che codificano un particolare aminoacido correla con la sua frequenza nelle proteine (“importanza” dell’AA, necessità di assicurarne la sintesi)

Il codice genetico dei mitocondri dei vertebrati
Codice genetico
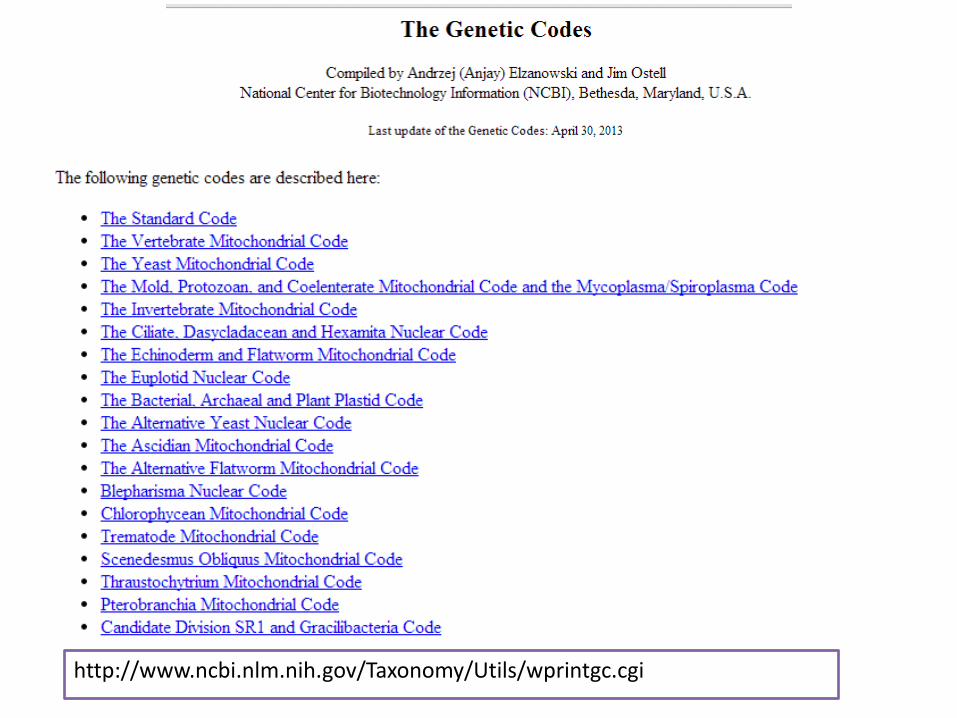
http://www.ncbi.nlm.nih.gov/Taxonomy/Utils/wprintgc.cgi

La traduzione: aminoacidi
In bioinformatica spesso si deve valutare il “peso” del cambiamento AA in una proteina o nel confronto tra due proteine per poi poter proseguire con il resto delle analisi > matrici di sostituzione


Matrici di sostituzione
Nelle sequenze proteiche ci sono 20 aminoacidi con determinate dimensioni, cariche, codone di codifica, caratteristiche chimiche. Matrici di sostituzioni AA hanno un punteggio per ognuna delle 210 possibili coppie di AA (180 = ((20*20)/2) – 20)) Queste matrici vengono calcolate dando un punteggio alla relazione tra due AA sulla base di alcune precise caratteristiche
Es. Matrice di sostituzione nucleotidica 4 nucleotidi > 6 possibili sostituzioni

Sostituzioni aminoacidiche > matrici

Sostituzioni aminoacidiche

FASTA format In bioinformatics, FASTA format is a text-based format for representing either nucleotide sequences or peptide sequences, in which nucleotides or amino acids are represented using single-letter codes.


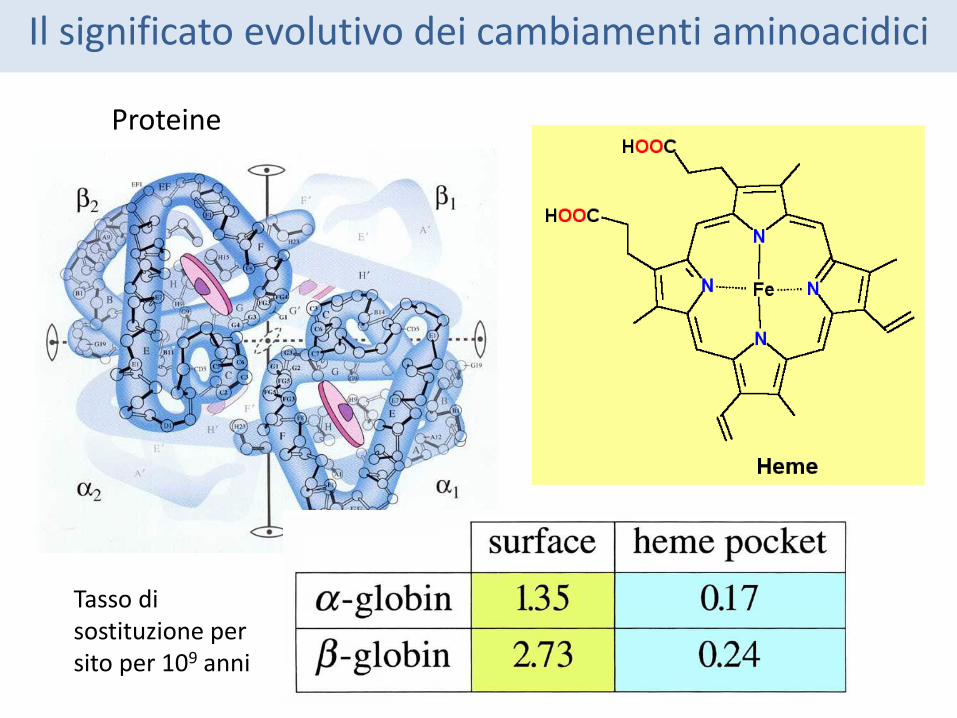
Il significato evolutivo dei cambiamenti aminoacidici
Proteine
Tasso di sostituzione per sito per 109 anni

Mutazioni
Le sequenze di DNA sono solitamente copiate in modo preciso durante la replicazione. Raramente tuttavia possono avvenire degli errori che originano nuove sequenze. Questi errori si chiamano mutazioni.
Da un punto di vista evolutivo una mutazione è una sequenza nella linea germinale che differisce dalla sua controparte nelle cellule somatiche, che viene ereditata dalla progenie la quale sarà dunque caratterizzata da una “novità” genetica. Le mutazioni sono quindi la fonte di variabilità e di novità evolutiva

Transizione (pur>pur ; pir>pir)
Trasversione (pur>pir ; pir>pur)
ricombinazione
delezione
inserzione
inversione
Sostituzioni nucleotidiche
Mutazioni nucleotidiche

Mutazioni nucleotidiche

sinonima
nonsinonima
nonsenso
Mutazioni nucleotidiche: effetto sulla traduzione

Ogni codone codificante un AA può mutare in altri 9 codoni attraverso sostituzioni di un singolo nucleotide. Esempio: CCU (Pro)
6 possibili sostituzioni nonsinonime UCU (Ser) ACU (Thr) GCU (Ala) CUU (Leu) CAU (His) CGU (Arg)
3 possibili sostituzioni sinonime CCC CCA CCG
Mutazioni nucleotidiche: effetto sulla traduzione

Ogni codone codificante un AA può mutare in altri 9 codoni attraverso sostituzioni di un singolo nucleotide.
61 codoni “senso” ↓ 61x9 =549 possibili sostituzioni nucleotidiche

Se assumiamo che
1. Tutti i codoni siano ugualmente presenti nelle regioni codificanti
2. Ogni sito abbia la stessa probabilità di mutare In un gene codificante qualunque ci aspettiamo una frequenza relativa dei diversi tipi di sostituzioni come in tabella
sostituzioni numero Frequenza
Totali (1,2,3 base) 549 100
Sinonime 134 25
Nonsinonime 415 75
Missenso (non senso) 392 (23) 71 (4)
Totali (1 base) 183 100
Sinonime 8 4
Nonsinonime 175 96
Missenso (non senso) 166 (9) 91 (5)
Totali (2 base) 183 100
Sinonime 0 0
Nonsinonime 183 100
Missenso (non senso) 176 (7) 96 (4)
Totali (3 base) 183 100
Sinonime 126 69
Nonsinonime 57 31
Missenso (non senso) 50 (7) 27 (4)
Alcune caratteristiche importanti: •Circa il 70% dei cambiamenti in 3° base sono sinonimi •Il 100% dei cambiamenti in 2° base sono nonsinonimi •Il 96% dei cambiamenti in 1° base sono nonsinonimi

Inserzioni e delezioni Nel confronto tra due sequenze è impossibile capire se ci sia stata una delezione in una delle due o una inserzione nell’altra INserzioni de DELezioni vengono in generale chiamate INDELS

F
r
a
m
e
s
h
i
f
t
Terminazione prematura per delezione
Perdita di un codone di stop per delezione
Perdita di un codone di stop per inserzione
Terminazione prematura per inserzione
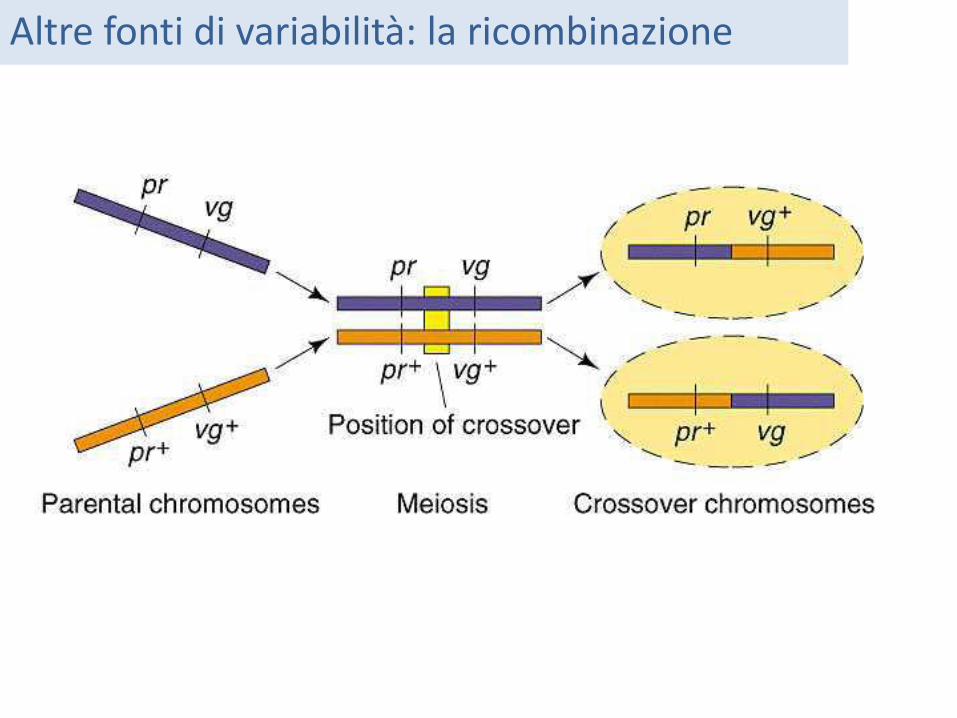
Altre fonti di variabilità: la ricombinazione
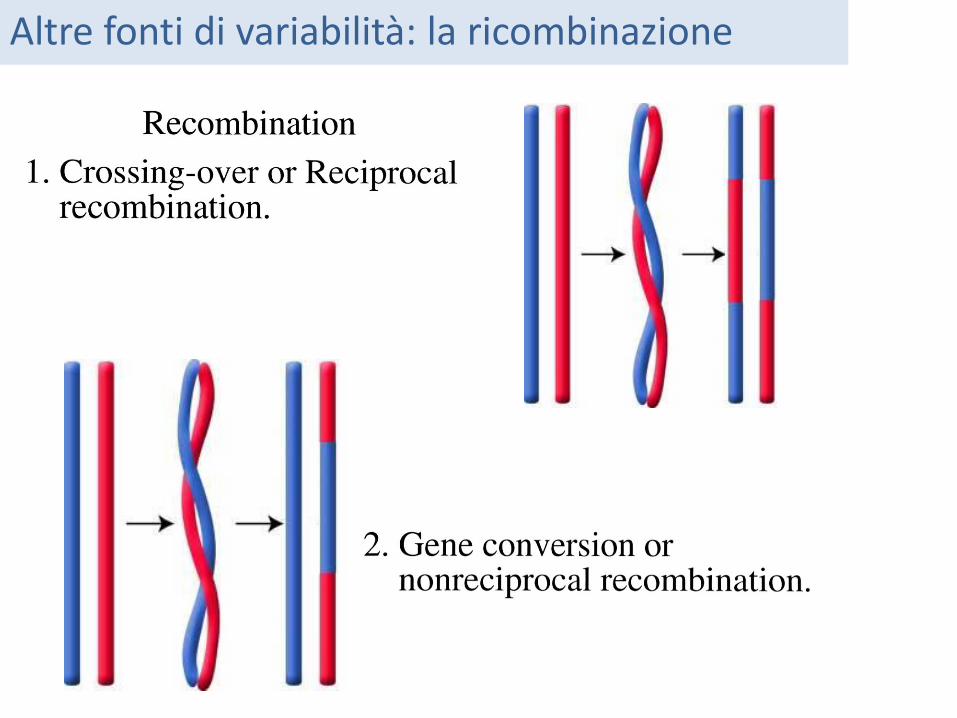
Altre fonti di variabilità: la ricombinazione

La ricombinazione reciproca è un potente mezzo di generazione della variabilità 5’—AACT—3’ and 5’—CTTG—3’ -> 6 possibili nuove sequenze: 5’—ATTG—3’ 5’—CACT—3’ 5’—AATG—3’ 5’—CTCT—3’ 5’—AACG—3’ 5’—CTTT—3’
Altre fonti di variabilità: la ricombinazione

Inserzioni e delezioni
Crossing over ineguale
Delezione “intra strand”
Altre fonti di variabilità: la ricombinazione