introduction to bioinformatics and biocomputing i dr tan tin wee director bioinformatics centre
TRANSCRIPT

Introduction to Bioinformatics and Biocomputing I
Dr Tan Tin Wee
Director
Bioinformatics Centre
http://www.bic.nus.edu.sg/
http://www.apbionet.org/

Twin pillars of Economy Two Major Late 20th Century
Technologies
A new emerging area

Historical Background• Life Science - young compared to physics and
chemistry
• 1953 Structure of DNA
• 1960s Understanding of “code of life”
• 1970s Genetic manipulation technology
• 1980s Widespread innovation -biotechnology/genetic revolution
• 1990s Human Genome Project
• 2000s Structural Genomics ?

GenBank DNA Sequence Databank Growth Chart
0
200000000
400000000
600000000
800000000
1000000000
1200000000
1400000000
1600000000
Year
Bas
es
Inte
rnet
N
od
esInternet Growth
Bas
es

Two Serious Problems
• Overwhelming rate of unorganised proliferation of insufficiently structured scientific data in some disciplines - example in life sciences: Genome Project etc.
• Low and Uncertain Performance of Network Data Communications and bandwidth limitation – example of APBionet-APAN collaboration

Bottleneck
• From Sequence
• To Structure
• To Function
• Predicting Function: From Genes to Genomes and Back
» J.Mol Biol (1998) 283, 707-725
Goal of the Human Genome Program
(and the Genomes Projects!) • Sequence the 3 billion base pairs of
humanDNA and identify the 100,000 genes contained in the human genome
• Do it for other genomes

Genomes Project!• Human• Vertebrates - mouse, dog, sheep, cattle, fish etc
etc• Invertebrates - C elegans, drosophila• Plants - arabidopsis etc • Microbes
– E coli, H. Influenzae, H. pylori, Mycoplasma genitalium, B subtilis, Borrelia, Chlamydia, Aquifex, Methanocccus Methanobacterium….
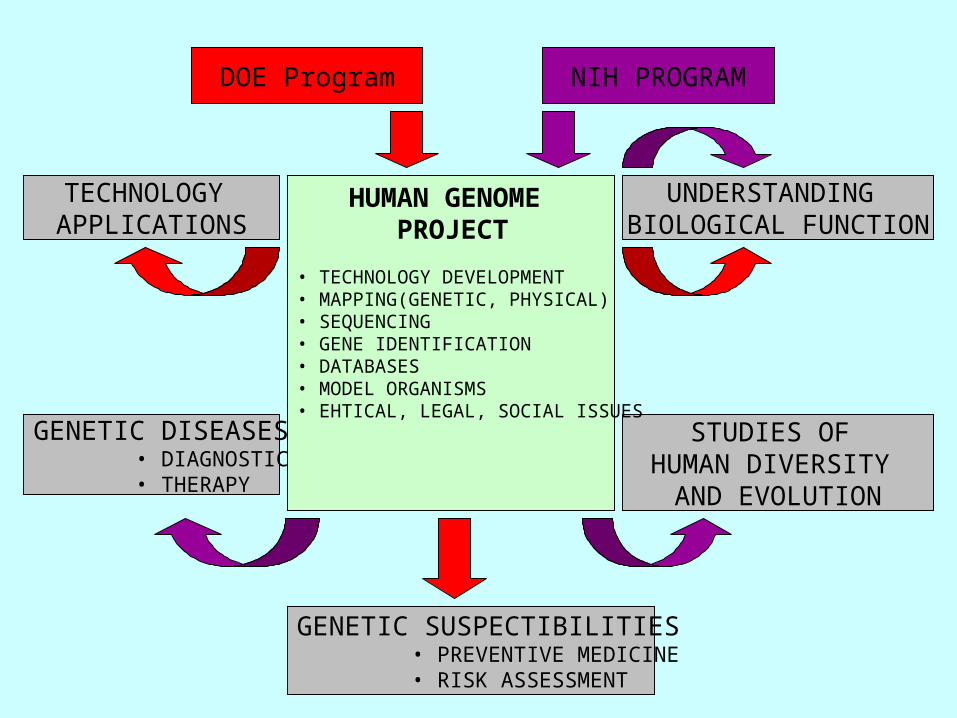
DOE Program NIH PROGRAM
TECHNOLOGY APPLICATIONS
STUDIES OF HUMAN DIVERSITY
AND EVOLUTION
GENETIC DISEASES • DIAGNOSTICS • THERAPY
GENETIC SUSPECTIBILITIES • PREVENTIVE MEDICINE • RISK ASSESSMENT
UNDERSTANDING BIOLOGICAL FUNCTION
• TECHNOLOGY DEVELOPMENT• MAPPING(GENETIC, PHYSICAL)• SEQUENCING• GENE IDENTIFICATION• DATABASES• MODEL ORGANISMS• EHTICAL, LEGAL, SOCIAL ISSUES
HUMAN GENOME PROJECT

Large Throughput Sequencing Now Happening
will deluge us with more data/information

New DOE/NIH Five-Year Plan(continued)
Sequencing - Related Goals• Model Organisms
- C. Elegans - 1998
- Drosophila - 2002
- Mouse - 2008• Full length cDNAs - 2003• Continued technology development• Sustained sequencing capacity
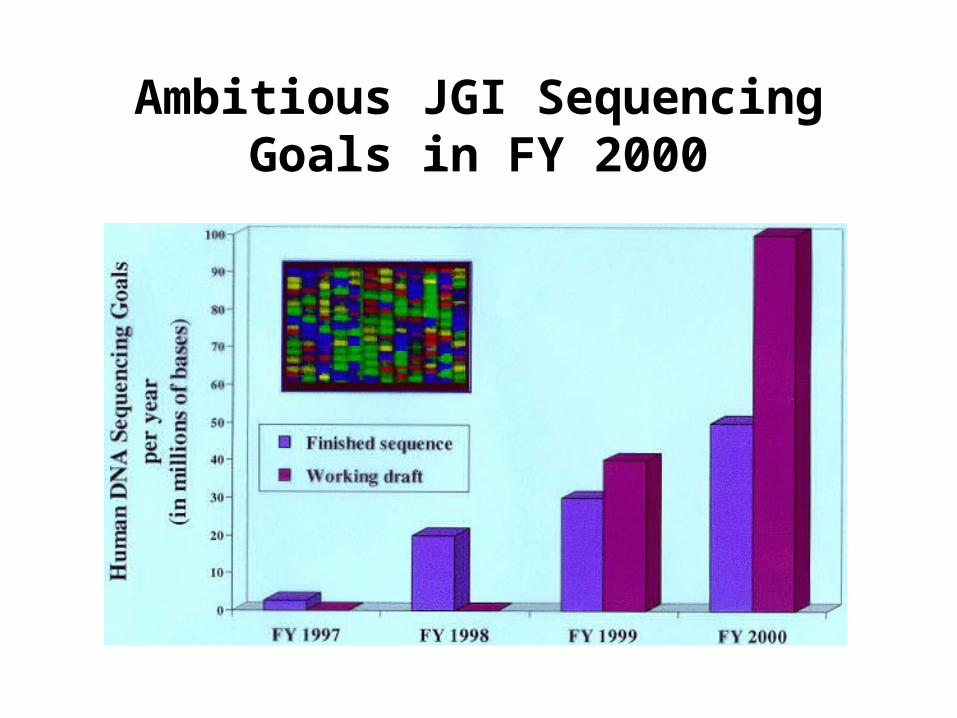
Ambitious JGI Sequencing Goals in FY 2000

Microbial Genome Research• Capitalises on advances in human
genome program• Map/sequence microbes with
- environmental/energy relevance
- phylogenetic significance
- commercial value• Predict gene function, regulation,
and interactions

Microbial Genome ProgramSequencing Will Advance Biotechnology for
a Sustainable Future
• biosensors and biomonitoring
• bioremediation and biorestoration
• manufacturing and bioprocessing
• biofuels - biohydrogen, ethanol, biodiesel
• photosynthesis and biomass production
• disease and drought resistance
• 180 paradigm shift in how biology is done

Microbial Genome ProgramSequencing Completed --
• Mycoplasma genitalium -- free living , smallest genome
• Methanococcus jannaschii -- methane producer
• Archaeoglobus fulgidus -- oil well souring
• Thermotoga maritima -- energy from plant biomass
• Deinococcus radiodurans -- radiation resistant, bioremediation
• Methanobacterium thermoautotrophicm -- methane producer
• Pyrobaculum aerophilum -- thermophile (100NC)
• Aquifex aeolicus VF5 -- deep branching lineage

Microbial Genome ProgramSequencing in progress --
• Pyrococcus furiosus -- model hypothermophile
• Clostridium acetobutylicum -- biotech & waste remediation
• Shewanaella putrefaciens -- bioremediation
• Pseudomonas putida -- bioremediation
• Thiobacillus ferroxidans -- CO2 fixation
• Desulfovibrio vulgaris -- bioremediation
• Caulobacter crescentus -- bioremediation
• Chlorobium tepidum -- carbon management
• Dehalococcoides ethenogenes -- bioremediation
• Carboxydothermus hydrogenoformans -- H2 production

Challenges and Opportunities
Private and public sector
sequencing efforts are
about to drive the
genome project into……
Information Overload!!!

What is Bioinformatics?Bioinformatics is :
• the use of computers (and persistent data structures) in pursuit of biological research.
• an emerging new discipline, with its own goals, research program, and practitioners.
• the sine qua non for 21st-century biology.
• The most significantly underfunded component of 21st-century biology
• all of the above.

Visualising Genome Information

What is Genome Annotation?The Process of Adding Biology Information and
Predictions to a Sequenced Genome Framework

Increasing Volume of Data :A Biological Data Deluge
• Between now and 2003, over 50,000 new human genes and proteins.
• 100,000 new genes and proteins from genome sequencing of microbes and model organisms.
• Variants will be found or manufactured at high throughput(mutants, normal population variants, man-made constructs, homologues determined in many species from gene-specific environmental screens).
• If 40,000 per year, > 3,000 per month, >100 per day
• In just 1997, about 12,000 genes and proteins were discovered

Paradigm Shift in BiologyThe new paradigm, now emerging, is that all
the ‘genes’ will be known (in the sense of
being resident in databases available
electronically), and that the starting point of a
biological investigation will be theoretical. An
individual scientist will being with a
theoretical conjecture, only then turning to
experiment to follow or test that hypothesis.
Walter Gilbert. 1991. Towards a paradigm shift in biology. Nature, 349:99.

Call for Change
Among the many new tools that are or will be
needed (for 21st century biology), some of
those having the highest priority are :
• bioinformatics
• computational biology
• functional imaging tools using biosensors and biomakers
• transformation and transient expression technologies
• nanotechnologies
Impact of Emerging Technologies on the Biological Sciences: Report of a
Workshop. NSF-supported workshop, held 26-27 June 1995, Washington, DC.

Human Resources Issues
Elbert Branscomb : “You must recognize that some day you may need as many computer scientists as biologists in your labs.”
Craig Venter : “At TIGR, we already have twice as many computer scientists on our staff.”
Exchange at DOE workshop on high-throughput sequencing.

Fundamental Dogma
Although a few databases already exist
to distribute molecular information,
the post-genomic era will need many more to collect, manage, and publish
the coming flood of new findings

Base Pairs in Genbank

Projected Base Pairs

Current Situation
• Computational Infrastructure for processing genome sequences geared for 2 million bases pairs per day
• New sequencing technology (whole genome shotgun) has changed the landscape
• Raw data must be processed not just finished clones
• Data generation Jan 1 1999 - 30 million per day, mid-1999 - 1 billion bases per week.
• Most comprehensive analyses will be beyond capabilities of all but a few sites

Private Sector Genome Research

Current Situation
• Computational Infrastructure for processing genome sequences geared for 2 million bases pairs per day
• New sequencing technology (whole genome shotgun) has changed the landscape
• Raw data must be processed not just finished clones
• Data generation Jan 1 1999 - 30 million per day, mid-1999 - 1 billion bases per week.
• Most comprehensive analyses will be beyond capabilities of all but a few sites
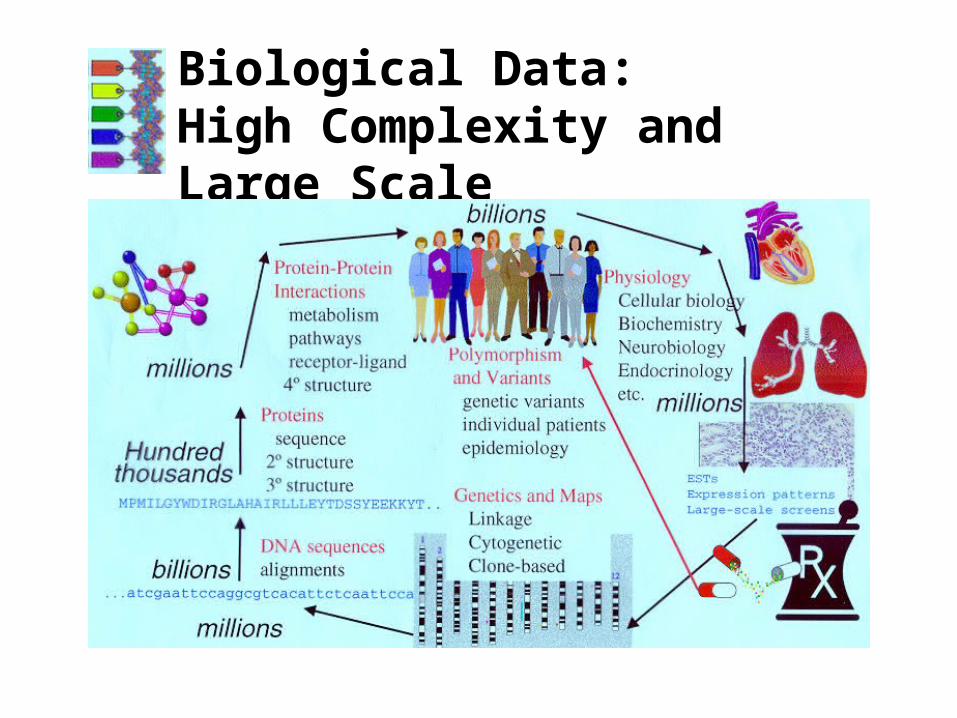
Biological Data:High Complexity and Large Scale

Computational Biology in the High-Throughput Era
The Genome and Beyond
• Scientific Challenges
• Algorithmic Challenges
• Computational Challenges

IT-Biology Synergism
• Physics needs calculus, the method for manipulating information about statistically large numbers of vanishingly small, independent, equivalent things.
• Biology needs information technology, the method for manipulating information about large numbers of dependent, historically contigent, individual things

Moore’s Law : The Statement
Every eighteen months, the number of
transistors that can be placed on the chip
doubles.
- Gordon Moore, co-founder of Intel
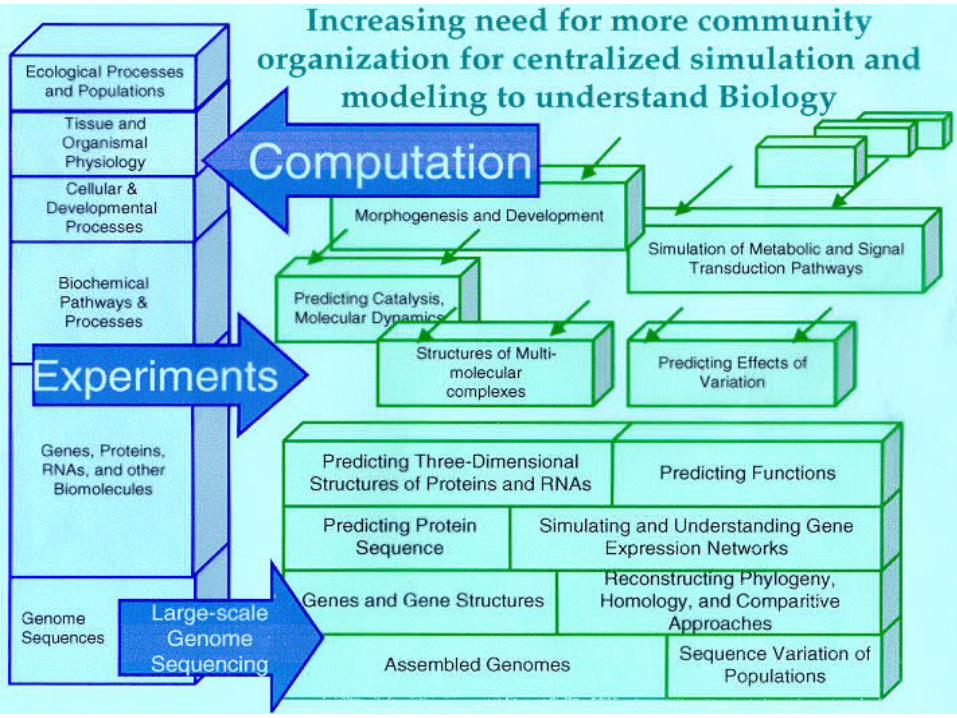

Exemplar Problems in Biosciences that
canonly be addressed with significantly enhanced Computational Power1. Full genome-genome comparisons
2. Rapid assessment of polymorphic genetic variations
3. Complete construction of orthologous or paralogous groups of genes
4. Structure determination of large macromolecular assemblies/complexes
5. Dynamically simulation of realistic oligomeric systems
6. Rapid structural/topological clustering of proteins
7. Prediction of unknown molecular structures; Protein folding
8. Computer simulation of membrane structure and dynamic function
9. Simulation of genetic networks and the sensitivity of these pathways to component stiochiometry and kinetics
10.Integration of observations across scales of vastly different dimensions and organization to yield realistic environmental models for basic biology and societal needs

General Scope of Introductory Bioinformatics
• Database Searching
• Sequence Alignment
• Gene finding
• Functional Genomics
• Protein Classification
• Phylogenetic inference

Analogy
• 1980s Gene Cloning, rDNA technology - Revolutionised biological and medical research changing it into engineering - genetic engineering
• 1990s Biocomputing and Bioinformatics - Revolutionised biomedical research and turned it into an informational science
• 2000s The next generation ???

Acknowledgements
• Dr John Wooley, Dept of Energy, USA, for his ppt report on DOE's projected research expenditure and the overview of bioinformatics (copyright)
• Colleagues at BIC