intro to apache kudu (short) - big data application meetup
TRANSCRIPT

1© Cloudera, Inc. All rights reserved.
Intro to Apache Kudu (incubating) Hadoop Storage for Fast Analytics on Fast DataMike Percy, Kudu committer & PPMC [email protected] | @mike_percy

2© Cloudera, Inc. All rights reserved.
Agenda
• Why Kudu? Motivations and design goals• Use cases• Technical design and selected internals • Performance• How to get started

3© Cloudera, Inc. All rights reserved.
Previous storage landscape of the Hadoop ecosystem
HDFS (GFS) excels at:• Batch ingest only (eg hourly)• Efficiently scanning large amounts
of data (analytics)HBase (BigTable) excels at:
• Efficiently finding and writing individual rows
• Making data mutable
Gaps exist when these properties are needed simultaneously
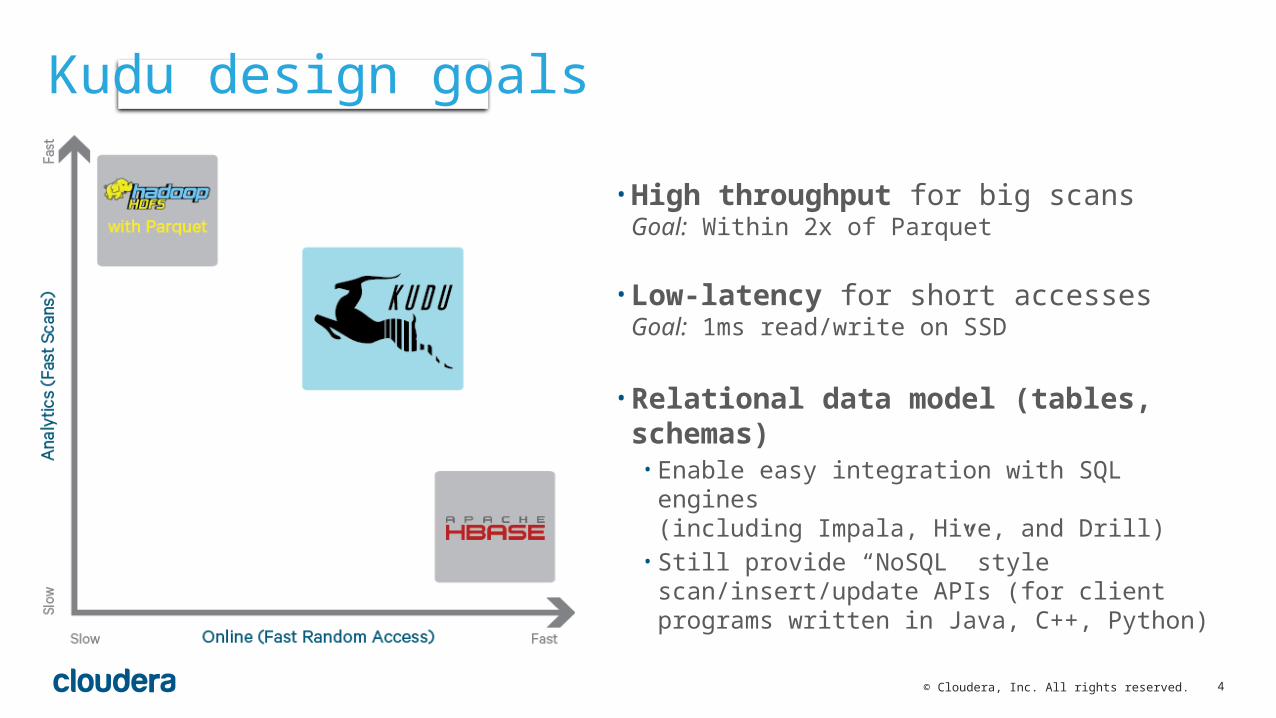
4© Cloudera, Inc. All rights reserved.
• High throughput for big scansGoal: Within 2x of Parquet
• Low-latency for short accesses Goal: 1ms read/write on SSD
• Relational data model (tables, schemas)• Enable easy integration with SQL engines
(including Impala, Hive, and Drill)• Still provide “NoSQL” style scan/insert/update APIs
(for client programs written in Java, C++, Python)
Kudu design goals

5© Cloudera, Inc. All rights reserved.
Where Kudu fits in the Hadoop big data stackStorage for fast (low latency) analytics on fast (high throughput) data
• Simplifies the architecture for building analytic applications on changing data
• Optimized for fast analytic performance
• Natively integrated with the Hadoop ecosystem of components
FILESYSTEMHDFS
NoSQLHBASE
INGEST – SQOOP, FLUME, KAFKA
DATA INTEGRATION & STORAGE
SECURITY – SENTRY
RESOURCE MANAGEMENT – YARN
UNIFIED DATA SERVICES
BATCH STREAM SQL SEARCH MODEL ONLINE
DATA ENGINEERING DATA DISCOVERY & ANALYTICS DATA APPS
SPARK, HIVE, PIG
SPARK IMPALA SOLR SPARK HBASE
RELATIONALKUDU

6© Cloudera, Inc. All rights reserved.
Kudu: Scalable and fast tabular storage
• Tabular• Store tables like a “normal” database• Individual record-level access to 100+ billion row tables
• Scalable• Tested up to 275 nodes (~3PB cluster)• Designed to scale to 1000s of nodes, tens of PBs
• Fast• Millions of read/write operations per second across cluster• Multiple GB/second read throughput per node

7© Cloudera, Inc. All rights reserved.
Kudu: Strong schema, NoSQL + SQL (via integrations)
• Each table has a SQL-like schema• Finite number of columns (unlike HBase/Cassandra)• Types: BOOL, INT8, INT16, INT32, INT64, FLOAT, DOUBLE, STRING, BINARY,
TIMESTAMP• Some subset of columns makes up a possibly-composite primary key• Fast ALTER TABLE
• Java, Python, and C++ “NoSQL” style APIs• Insert(), Update(), Delete(), Scan()
• Integrations with MapReduce, Apache Spark, and Apache Impala (incubating)• Apache Drill work-in-progress

8© Cloudera, Inc. All rights reserved.
Kudu use cases
Kudu is best for use cases requiring a simultaneous combination ofsequential and random reads and writes
• Time series• Examples: Streaming market data, fraud detection / prevention, risk monitoring• Workload: Insert, updates, scans, lookups
• Machine data analytics• Example: Network threat detection• Workload: Inserts, scans, lookups
• Online reporting• Example: Operational data store (ODS)• Workload: Inserts, updates, scans, lookups

9© Cloudera, Inc. All rights reserved.
Xiaomi use case
• World’s 4th largest smart-phone maker (most popular in China)• Gather important RPC tracing events from mobile app and backend service. • Service monitoring & troubleshooting tool.
High write throughput• >5 Billion records/day and growing
Query latest data and quick response• Identify and resolve issues quickly
Can search for individual records• Easy for troubleshooting
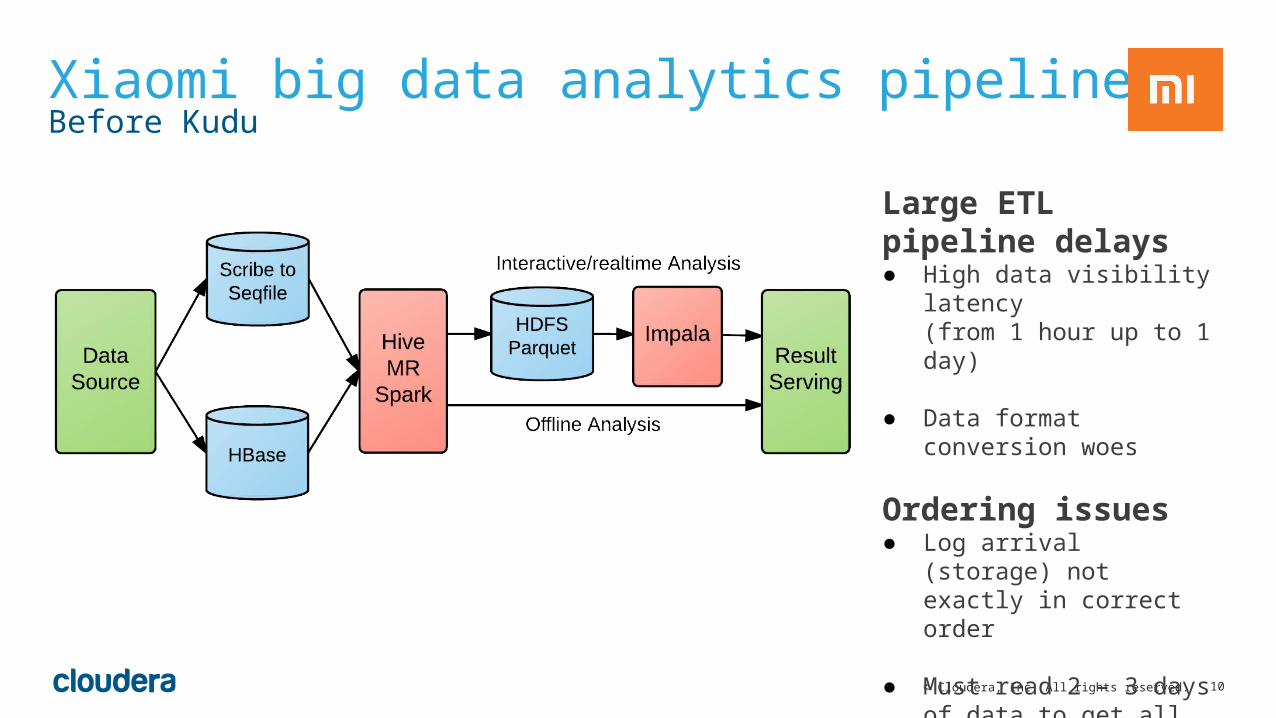
10© Cloudera, Inc. All rights reserved.
Xiaomi big data analytics pipelineBefore Kudu
Large ETL pipeline delays● High data visibility latency
(from 1 hour up to 1 day)
● Data format conversion woes
Ordering issues● Log arrival (storage) not
exactly in correct order
● Must read 2 – 3 days of data to get all of the data points for a single day

11© Cloudera, Inc. All rights reserved.
Xiaomi big data analytics pipelineSimplified with Kudu
Low latency ETL pipeline● ~10s data latency
● For apps that need to avoid direct backpressure or need ETL for record enrichment
Direct zero-latency path● For apps that can tolerate
backpressure and can use the NoSQL APIs
● Apps that don’t need ETL enrichment for storage / retrieval
OLAP scanSide table lookupResult store

12© Cloudera, Inc. All rights reserved.
Xiaomi benchmark
• 6 real queries from application trace analysis application• Q1: SELECT COUNT(*)• Q2: SELECT hour, COUNT(*) WHERE module = ‘foo’ GROUP BY HOUR• Q3: SELECT hour, COUNT(DISTINCT uid) WHERE module = ‘foo’ AND app=‘bar’
GROUP BY HOUR• Q4: analytics on RPC success rate over all data for one app• Q5: same as Q4, but filter by time range• Q6: SELECT * WHERE app = … AND uid = … ORDER BY ts LIMIT 30 OFFSET 30

13© Cloudera, Inc. All rights reserved.
Xiaomi benchmark results
Q1 Q2 Q3 Q4 Q5 Q6
1.4 2.0 2.3 3.1 1.3 0.9 1.3
2.8 4.0
5.7 7.5
16.7 kuduparquet
Query latency (seconds):
• HDFS parquet file replication = 3• Kudu table replication = 3• Each query run 5 times then averaged

14© Cloudera, Inc. All rights reserved.
How it works (whirlwind tour)

15© Cloudera, Inc. All rights reserved.
Kudu tables are partitioned into “tablets” (regions)Partitioning based on primary key (PK)• Native support for
range partitioning and/or hash partitioning (salting)
• Hash example: PRIMARY KEY (tweet_id) DISTRIBUTE BY HASH(tweet_id) INTO 100 BUCKETS

16© Cloudera, Inc. All rights reserved.
Each tablet is fault tolerant via Raft consensus
• A single Tablet Server can host many tablets
• Metadata is stored on just another tablet, but only Master Server processes host that tablet
• Raft consensus:• Strong consistency• Leader election on failure• Replication factor 3 or 5
is typical

17© Cloudera, Inc. All rights reserved.
Kudu: Cluster metadata management
• Replicated master• Acts as a tablet directory• Acts as a catalog (which tables exist, etc)• Acts as a load balancer (tracks TS liveness, re-replicates under-replicated
tablets)• Caches all metadata in RAM for high performance
• Under heavy load, 99.99% response times still in microseconds (650us)• Client configured with master addresses
• Client asks master for tablet locations as needed and caches them locally

18© Cloudera, Inc. All rights reserved.
Example usage: Spark & Impala

19© Cloudera, Inc. All rights reserved.
Spark DataSource integration (work-in-progress)
sqlContext.load("org.kududb.spark", Map("kudu.table" -> “foo”, "kudu.master" -> “master.example.com”)) .registerTempTable(“mytable”)df = sqlContext.sql( “select col_a, col_b from mytable “ + “where col_c = 123”)

20© Cloudera, Inc. All rights reserved.
Impala integration
• CREATE TABLE … DISTRIBUTE BY HASH(col1) INTO 16 BUCKETS AS SELECT … FROM …
• INSERT/UPDATE/DELETE
• Optimizations like predicate pushdown, scan parallelism, plans for more on the way

21© Cloudera, Inc. All rights reserved.
Benchmarks

22© Cloudera, Inc. All rights reserved.
TPC-H (analytics benchmark)
• 75 server cluster• 12 (spinning) disks each, enough RAM to fit dataset• TPC-H Scale Factor 100 (100GB)
• Example query:• SELECT n_name, sum(l_extendedprice * (1 - l_discount)) as revenue FROM customer, orders, lineitem, supplier, nation, region WHERE c_custkey = o_custkey AND l_orderkey = o_orderkey AND l_suppkey = s_suppkey AND c_nationkey = s_nationkey AND s_nationkey = n_nationkey AND n_regionkey = r_regionkey AND r_name = 'ASIA' AND o_orderdate >= date '1994-01-01' AND o_orderdate < '1995-01-01’ GROUP BY n_name ORDER BY revenue desc;

23© Cloudera, Inc. All rights reserved.
• Kudu outperforms Parquet by 31% (geometric mean) for RAM-resident data

24© Cloudera, Inc. All rights reserved.
Versus other NoSQL storage• Apache Phoenix: OLTP SQL engine built on HBase• 10 node cluster (9 worker, 1 master)• TPC-H LINEITEM table only (6B rows)
Load TPCH Q1 COUNT(*)COUNT(*)WHERE…
single-rowlookup
0.01
0.1
1
10
100
1000
100002152
21976
131
0.04
1918
13.2
1.7
0.7 0.15
155
9.3
1.4 1.5 1.37
PhoenixKuduParquet
Tim
e in
sec (
log
scal
e)

25© Cloudera, Inc. All rights reserved.
Getting started with Kudu

26© Cloudera, Inc. All rights reserved.
Kudu: Project status
• First open source beta released by Cloudera in September ‘15• Latest version 0.6.0 released end of November
• Usable for many applications• Have not experienced data loss, reasonably stable (almost no crashes reported)• Still requires some expert assistance, and you’ll probably find some bugs
• Version 0.7 planned for February• Now a part of the Apache Software Foundation (ASF) Incubator

27© Cloudera, Inc. All rights reserved.
Getting started as a user
• Home page: http://getkudu.io• User mailing list: [email protected]• Chat room: http://getkudu-slack.herokuapp.com/ • Technical whitepaper: http://getkudu.io/kudu.pdf• Quickstart VM
• Easiest way to get started: Impala and Kudu in an easy-to-install VM• Yum / APT repos• CSD and Parcels
• For automated installation on a Cloudera Manager-managed cluster

28© Cloudera, Inc. All rights reserved.
Getting started as a developer
• Source code: http://github.com/cloudera/kudu• All commits go upstream, nothing is held back
• Public gerrit: http://gerrit.cloudera.org• All code reviews happening here
• Public JIRA: http://issues.cloudera.org• Includes bugs going back to 2013. Come see our dirty laundry!
• Developer mailing list: [email protected]
• Apache 2.0 licensed open source and an ASF incubator project.• Contributions are welcome and encouraged!

29© Cloudera, Inc. All rights reserved.
Questions?http://getkudu.io
@ApacheKudu