an evening with... apache hadoop meetup
TRANSCRIPT

An Evening with… Apache HadoopArkho Innova Meetup Series

• Un espacio para compartir experiencias y conocimiento
• Un espacio para hacer relaciones entre equipos con intereses afines
• Un espacio para pasarla bien
Gracias por su asistencia!!!

Agenda1.Qué es ? Introducción Apache Hadoop.
2.MapReduce.
3.Integración Apache Hadoop y otras plataformas.
4.Escenarios claves.
5.Hadoop as a service (HaaS).
6.Hadoop en la industria de la salud.

1. ¿Qué es Hadoop?

Introducción Apache Hadoop
• Framework Open Source que permite el procesamiento distribuido de grandes volúmenes de datos a través de un cluster de servidores.
• Data mining utilizando clustering.
• Diseñado para escalar desde uno a varios servidores.
• Fault tolerance, High Available Service
• Procesamiento paralelo masivo de datos no estructurados.
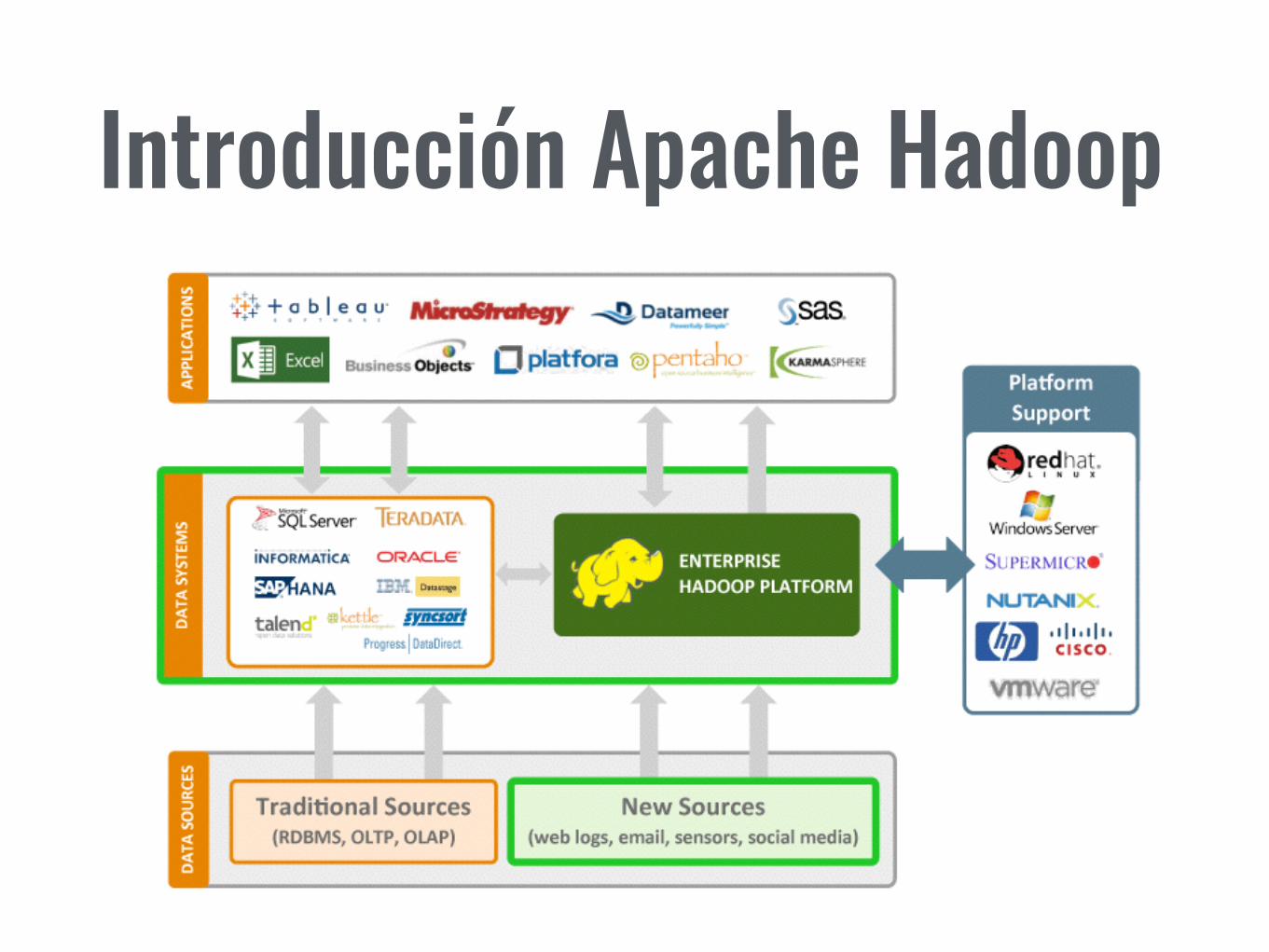
Introducción Apache Hadoop
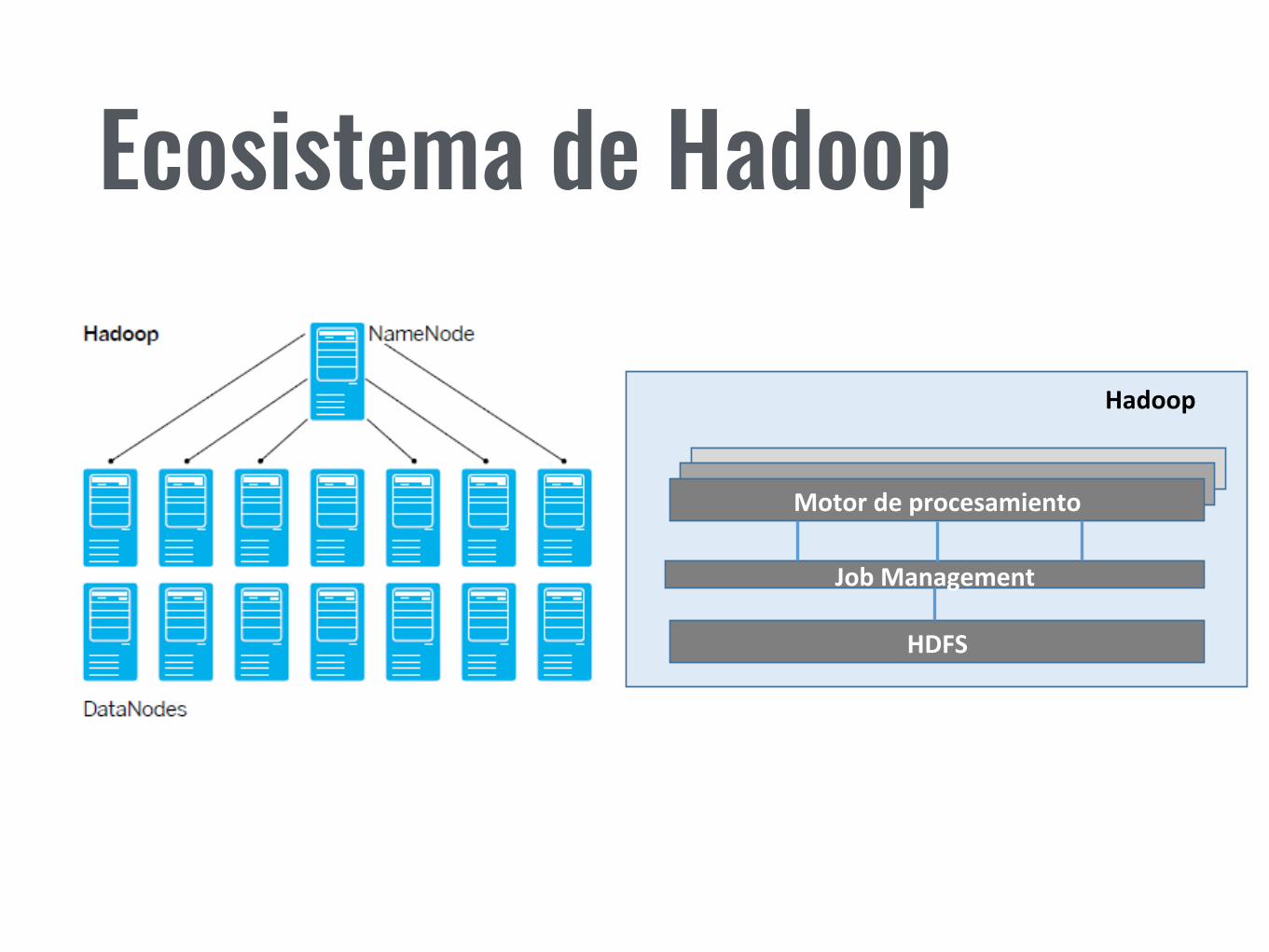
Ecosistema de Hadoop
HDFS
Hadoop
JobManagement
Motordeprocesamiento

Ecosistema de Hadoop
HDFS
Hadoop
MapReduce
Hive HBase Mahout
Pig Sqoop …

Componentes principales• Job Tracker
• Administra la ejecución de los trabajos en cada uno de los nodos
• Mantiene información de nodos: cercanía, carga datos
• Sabe donde esta la información
• Reprograma las tareas fallidas
• Task Tracker
• Es el encargado de ejecutar la tarea
• Fair Scheduler:
• Encargado de organización del trabajo
• Distribución de los trabajos en pool y colas

HDFS• Principalmente es un sistema de archivos distribuido
• Fue diseñado para se usado con Hardware Básico
• Tiene la capacidad de almacenar un archivo gigante en varias maquinas
• Existe redundancia para tolerar fallos
• Hadoop tiene una interfaz de comandos para usar con HDFS
• Tal como unix también tiene la capacidad de usar permisos de archivos

• Namenode • Es el master de todos los nodos • Maneja la metadata. ( nombres de archivos y rutas por ejemplo) • Regula el acceso a los archivos • Controlas las operaciones de I/O
• Datanode • Mantienen la información concretamente • Es donde se ejecutan las operaciones de lectura-escritura
• Bloque • Es la unidad de almacenamiento de HDFS. • Tamaño por defecto 64MB, normalmente es 128MB. Más de 512MB no recomendable.
HDFS
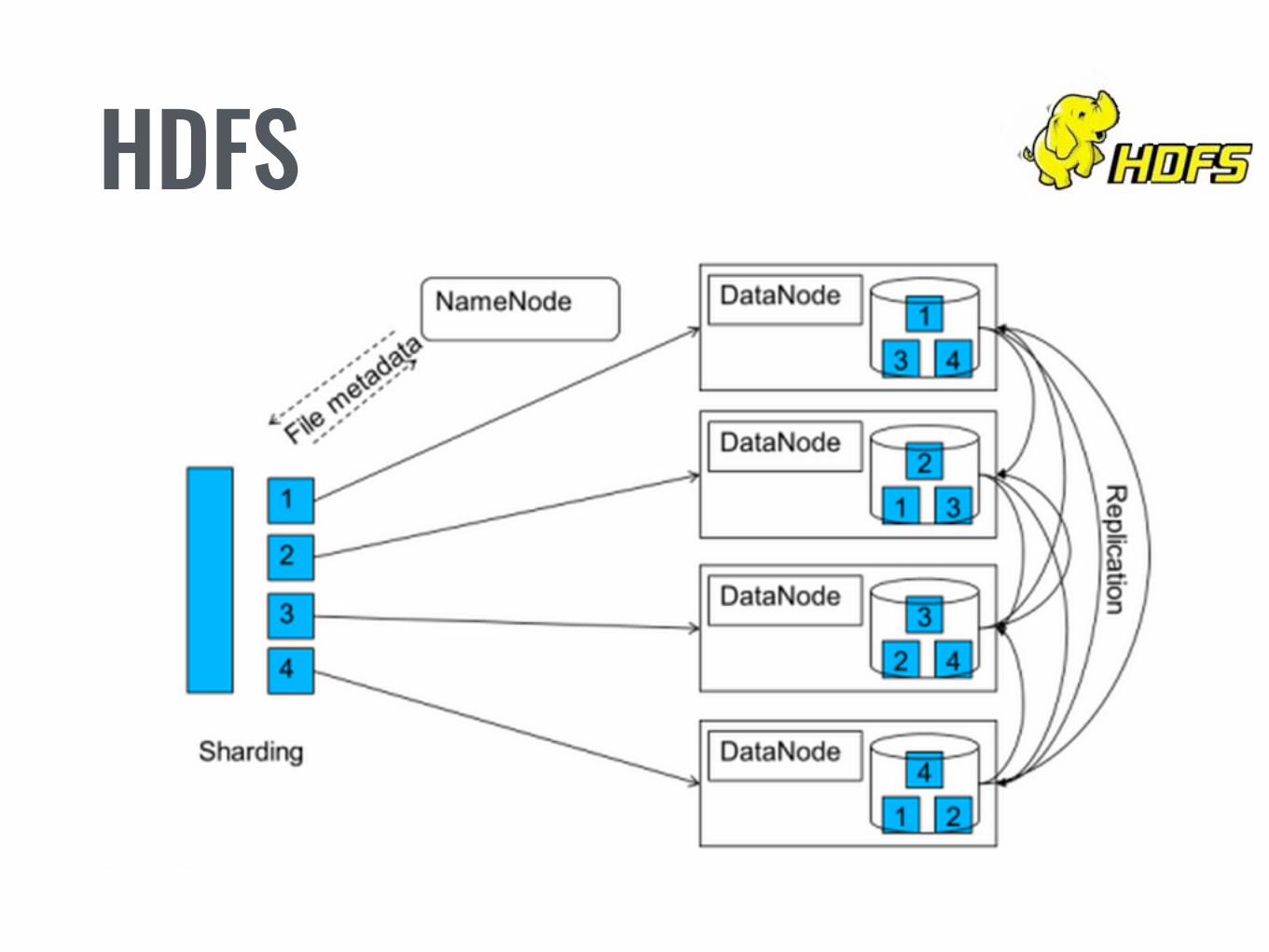
HDFS

2. MapReduce• Modelo de programación para procesamiento de gran volumen de datos.
• Divide el procesamiento en dos faces: map() & reduce()
• Estructurados en tuplas del tipo (clave, valor)
• La función map() se ejecuta en todas las máquinas del cluster.
• El resultado de la función map() es utilizado como input de la función reduce()
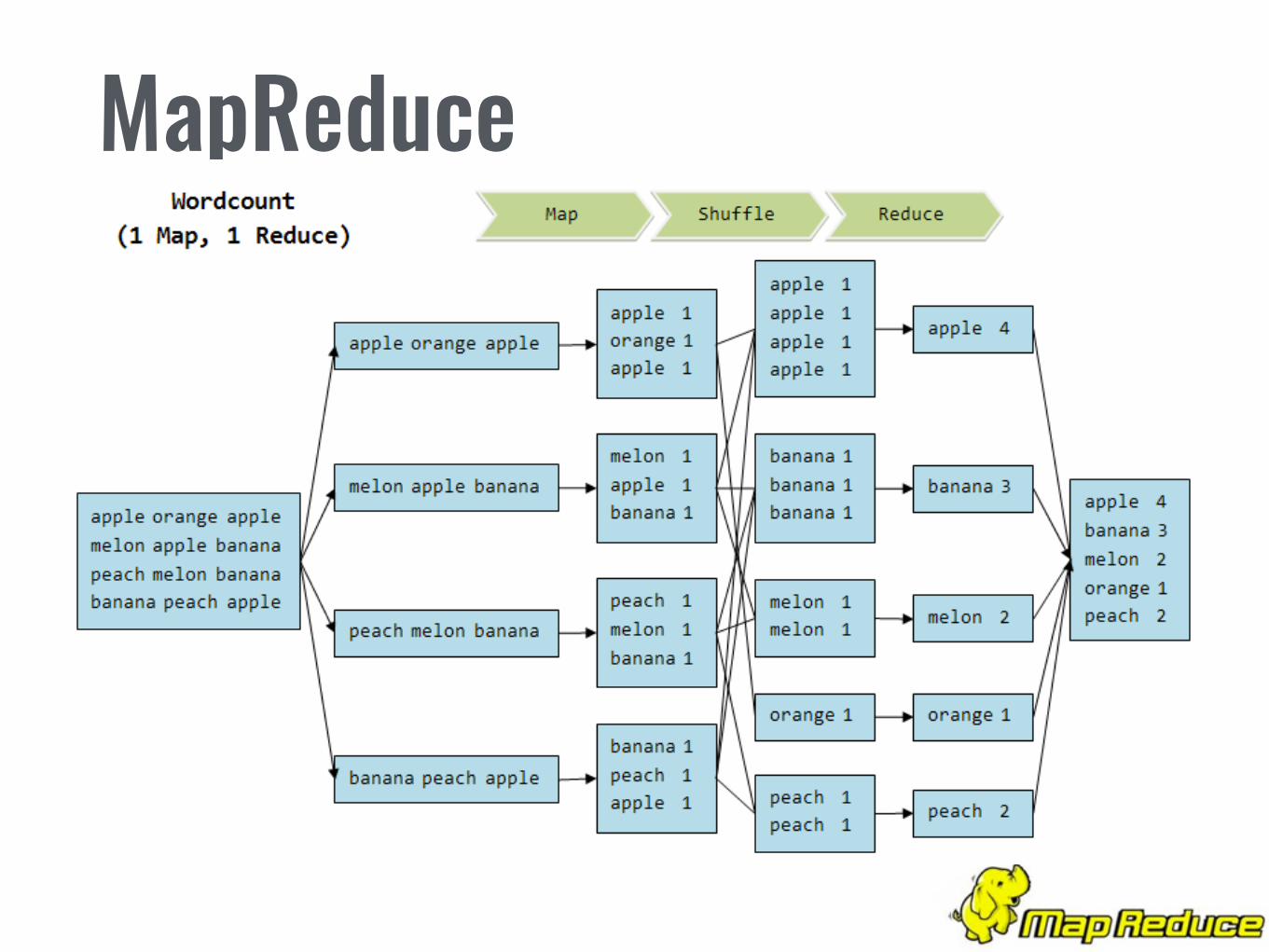
MapReduce

3. Integración Apache Hadoop y otras plataformas• Conciliación de datos estructurados y no-estructurados (web logs,
datos de maquina, datos no estructurados, censores, audio, video, imágenes, etc).
• Procesamiento batch donde el tiempo de procesamiento es menos crítico para el negocio.
• Proveer storage de bajo costo y procesamiento de grandes volúmenes de datos.

Integración Apache Hadoop y otras plataformas
• Procesamiento complejo a gran velocidad.
• Permite evaluar consultas que no son fácilmente expresadas mediante SQL.
• BI y minería de datos y en donde procesos de negocio pueden cambiar rápidamente o generar muchos datos en poco tiempo.

Integración Apache Hadoop y otras plataformas
• Oracle Analytics
• SAS
• SAP HANA – Apache Hadoop
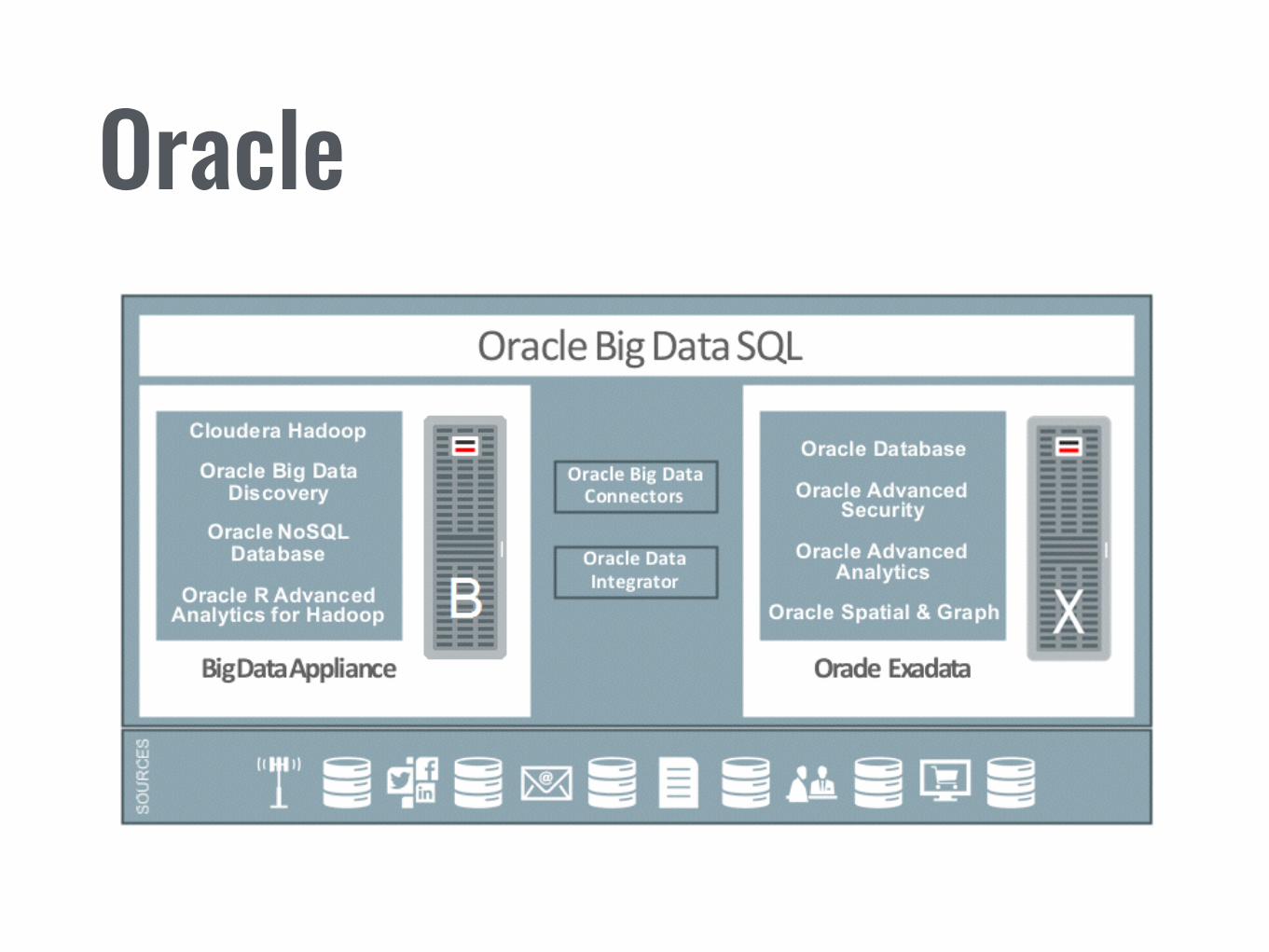
Oracle
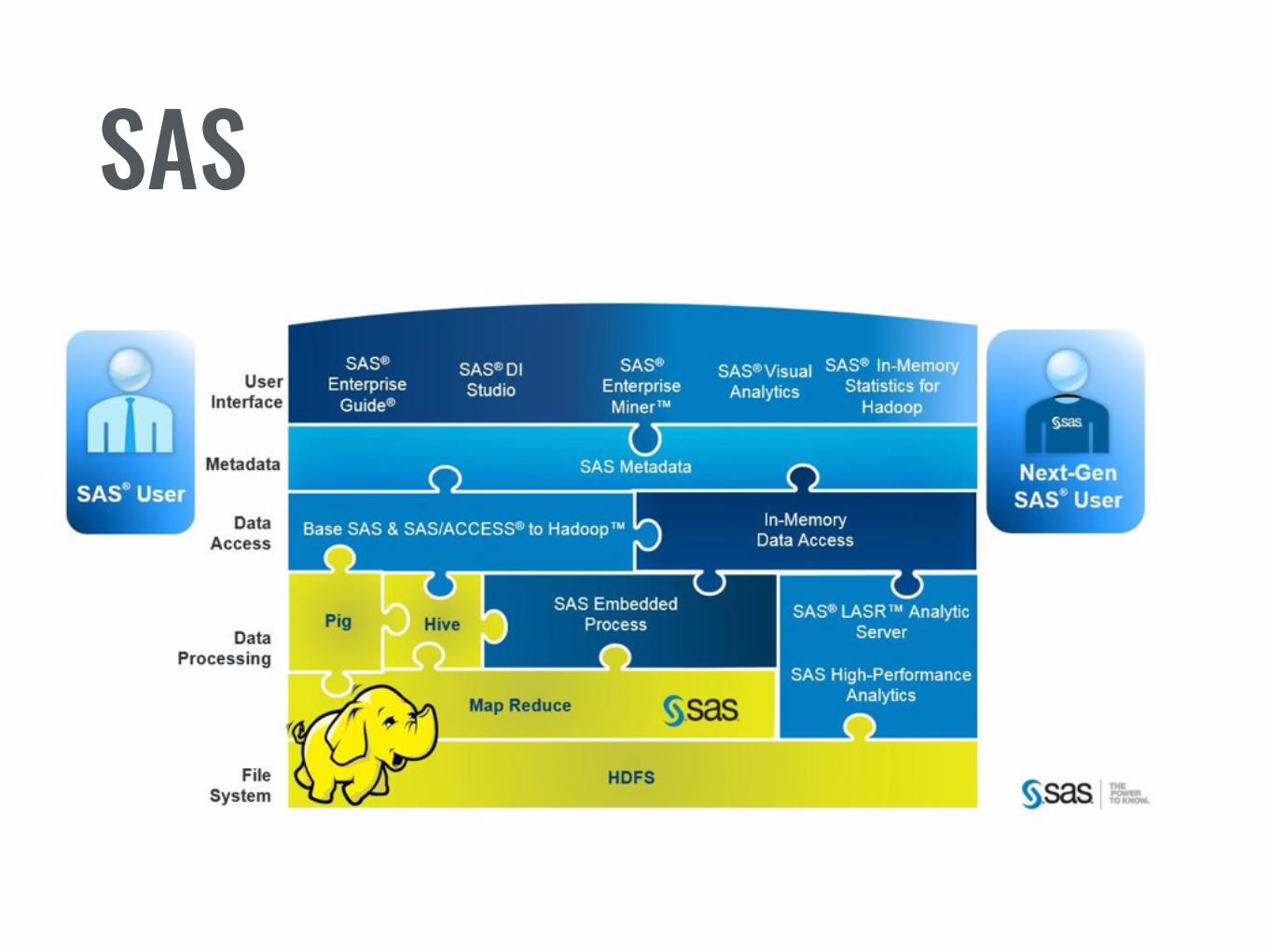
SAS
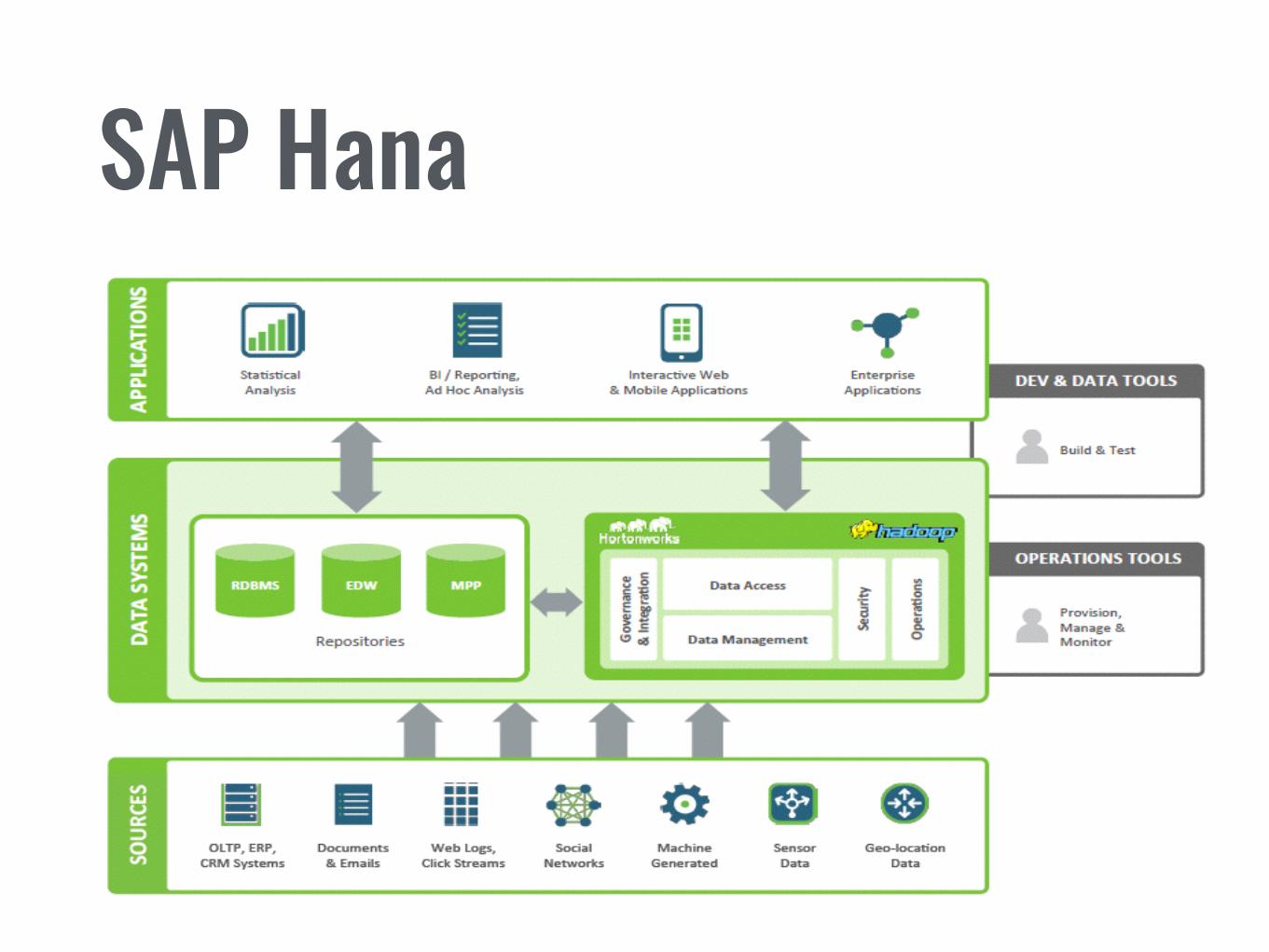
SAP Hana
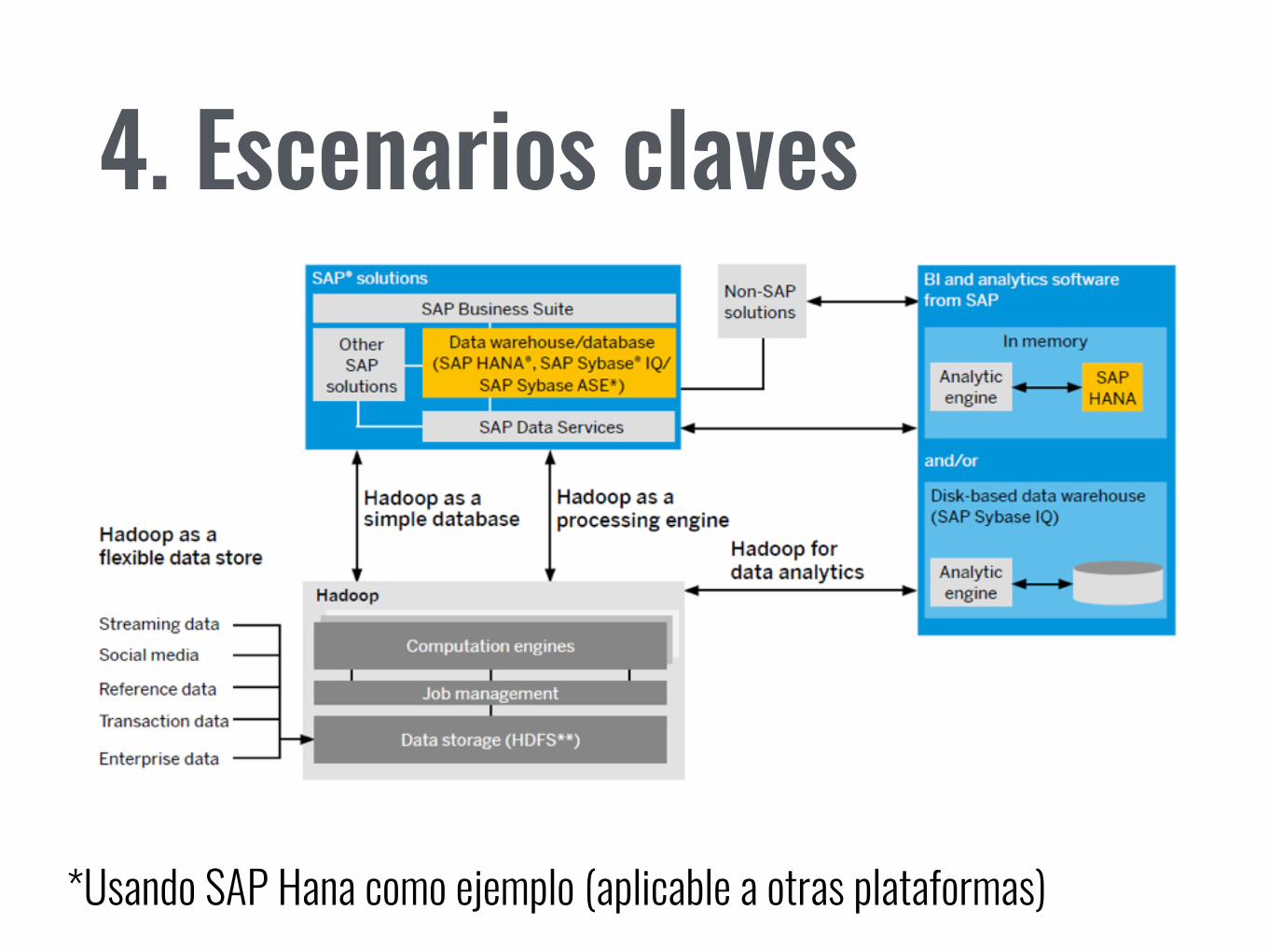
4. Escenarios claves
*Usando SAP Hana como ejemplo (aplicable a otras plataformas)
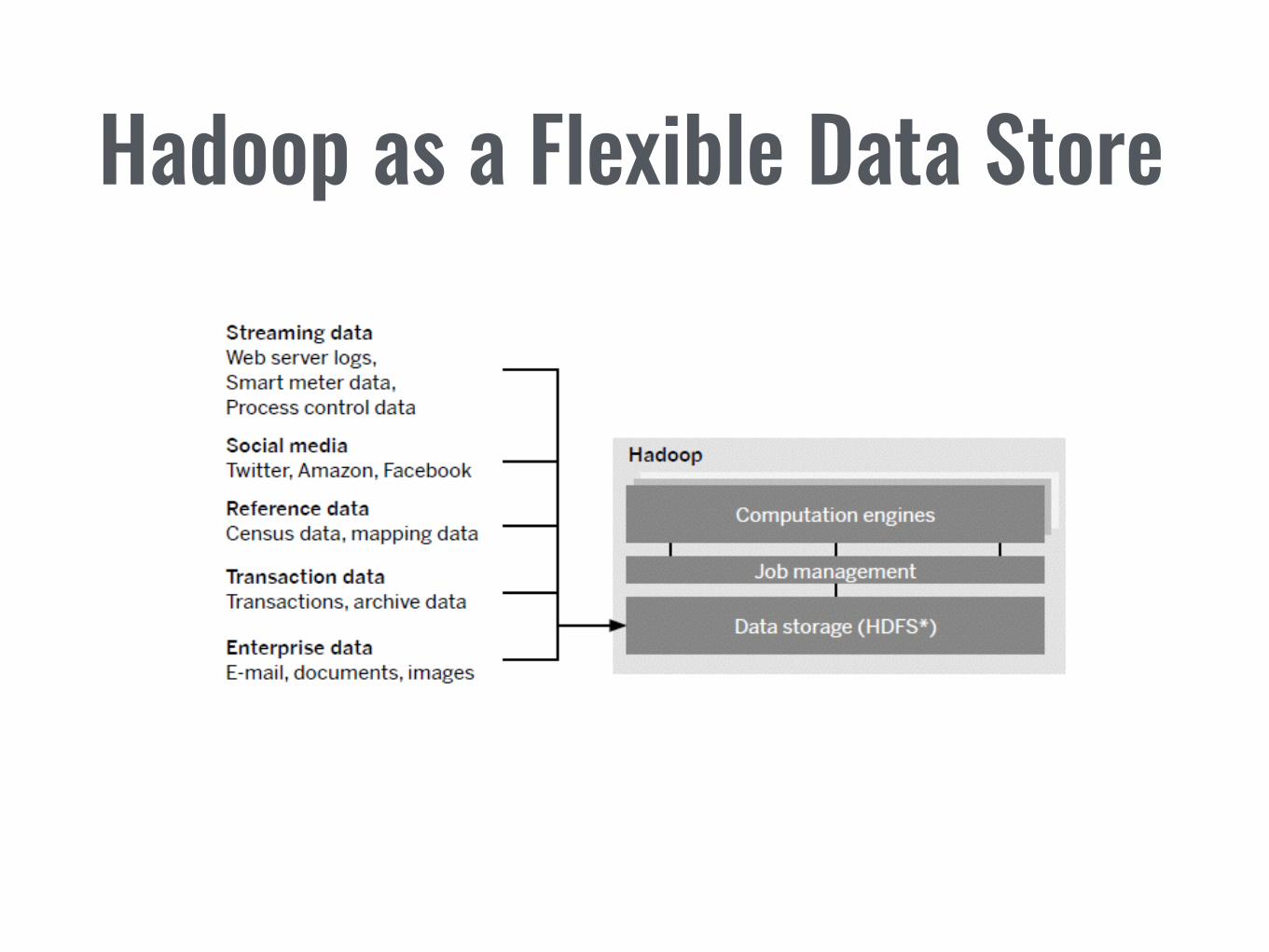
Hadoop as a Flexible Data Store
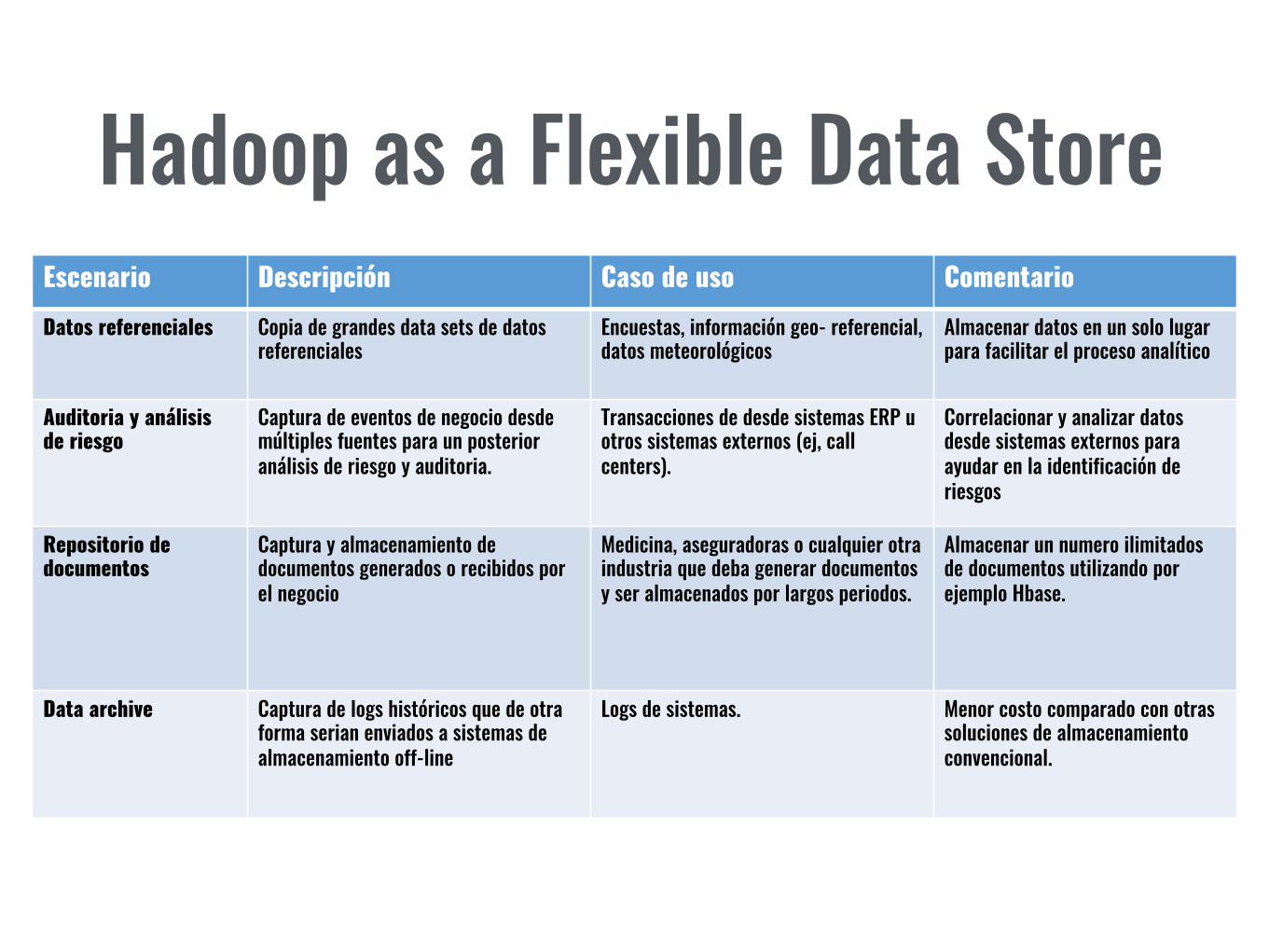
Hadoop as a Flexible Data StoreEscenario Descripción Caso de uso Comentario
Datos referenciales Copia de grandes data sets de datos referenciales
Encuestas, información geo- referencial, datos meteorológicos
Almacenar datos en un solo lugar para facilitar el proceso analítico
Auditoria y análisis de riesgo
Captura de eventos de negocio desde múltiples fuentes para un posterior análisis de riesgo y auditoria.
Transacciones de desde sistemas ERP u otros sistemas externos (ej, call centers).
Correlacionar y analizar datos desde sistemas externos para ayudar en la identificación de riesgos
Repositorio de documentos
Captura y almacenamiento de documentos generados o recibidos por el negocio
Medicina, aseguradoras o cualquier otra industria que deba generar documentos y ser almacenados por largos periodos.
Almacenar un numero ilimitados de documentos utilizando por ejemplo Hbase.
Data archive Captura de logs históricos que de otra forma serian enviados a sistemas de almacenamiento off-line
Logs de sistemas. Menor costo comparado con otras soluciones de almacenamiento convencional.

Hadoop as a simple database

Hadoop as a simple databaseEscenario Descripción Caso de uso Comentario
ETL desde otros sistemas hacia Hadoop
Ingresar data hacia Hadoop desde sistemas externos tal como SAP HANA o algún data warehouse.
Combinar datos en fuentes analíticas con datos desde Hadoop.
SAP Data Service provee ETL para transferencia de datos desde Hadoop.
Disponer de una base de datos para el almacenamiento de volúmenes de documentos de gran tamaño
Rápido almacenamiento y recuperación de “blobs” utilizando HBase
Almacenamiento de archivos PDF, imágenes o video.
Esta funcionalidad es utilizada por Facebook para para almacenar y recuperar datos.
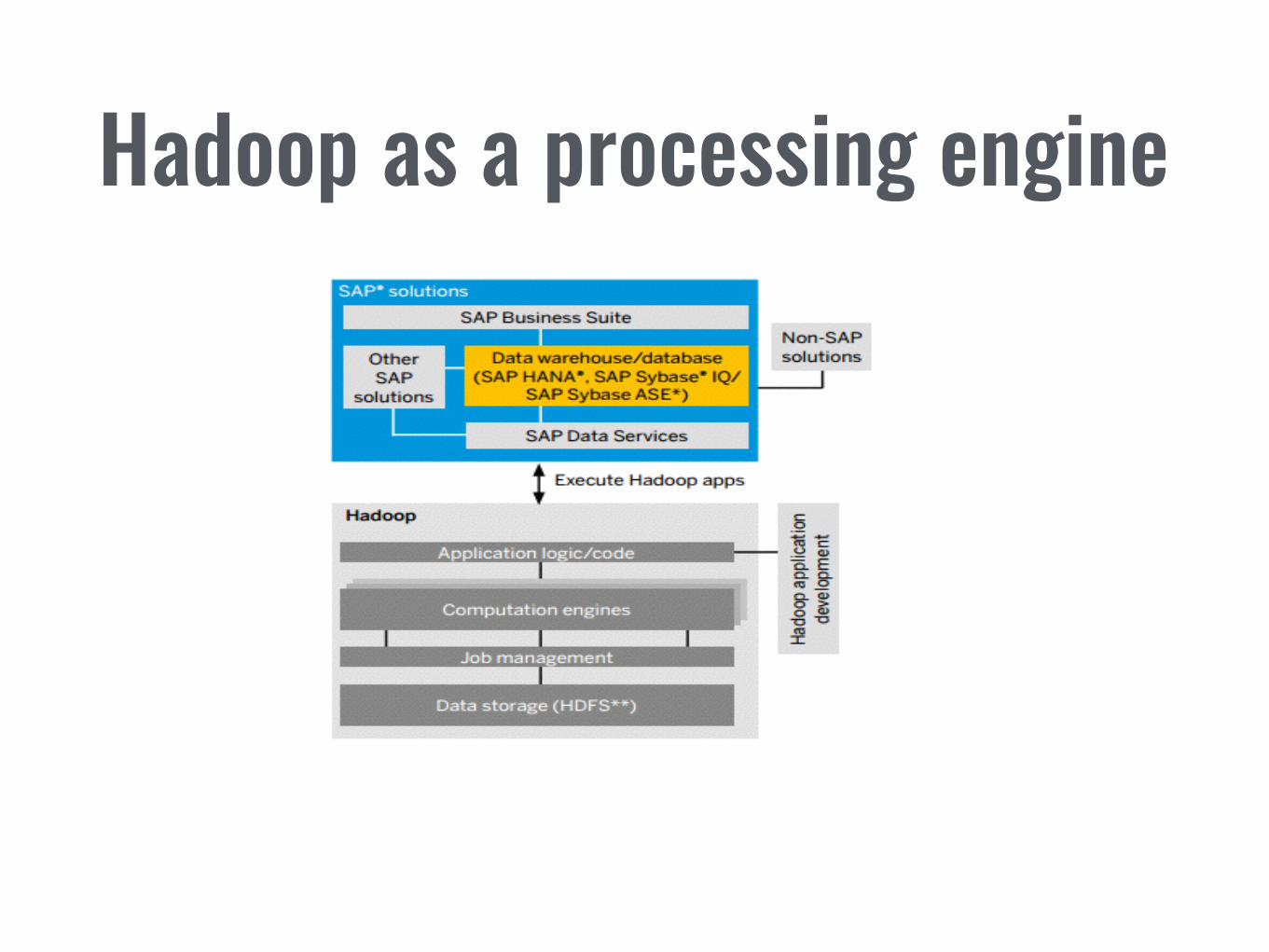
Hadoop as a processing engine
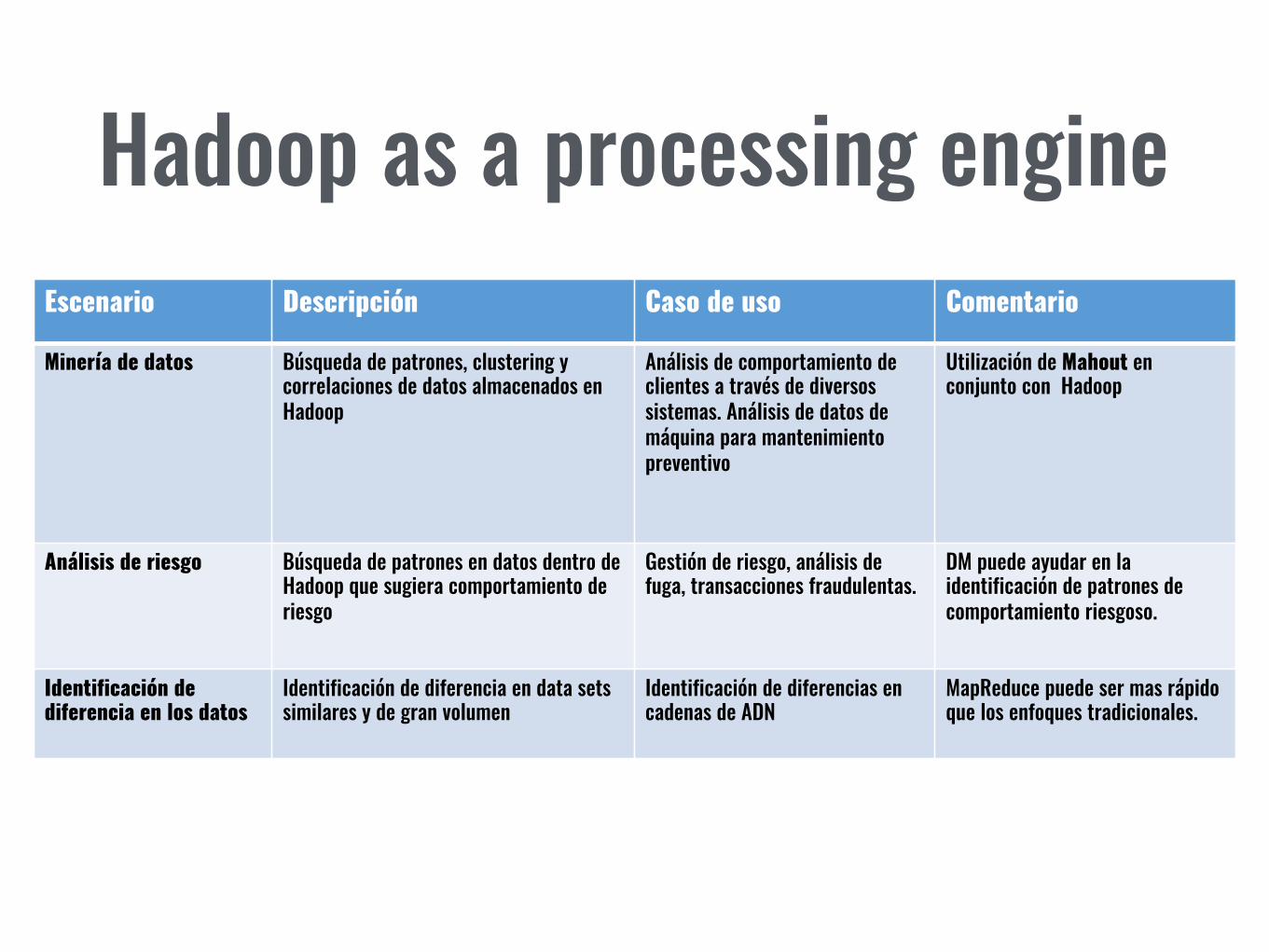
Hadoop as a processing engineEscenario Descripción Caso de uso Comentario
Minería de datos Búsqueda de patrones, clustering y correlaciones de datos almacenados en Hadoop
Análisis de comportamiento de clientes a través de diversos sistemas. Análisis de datos de máquina para mantenimiento preventivo
Utilización de Mahout en conjunto con Hadoop
Análisis de riesgo Búsqueda de patrones en datos dentro de Hadoop que sugiera comportamiento de riesgo
Gestión de riesgo, análisis de fuga, transacciones fraudulentas.
DM puede ayudar en la identificación de patrones de comportamiento riesgoso.
Identificación de diferencia en los datos
Identificación de diferencia en data sets similares y de gran volumen
Identificación de diferencias en cadenas de ADN
MapReduce puede ser mas rápido que los enfoques tradicionales.

Hadoop for data analytics
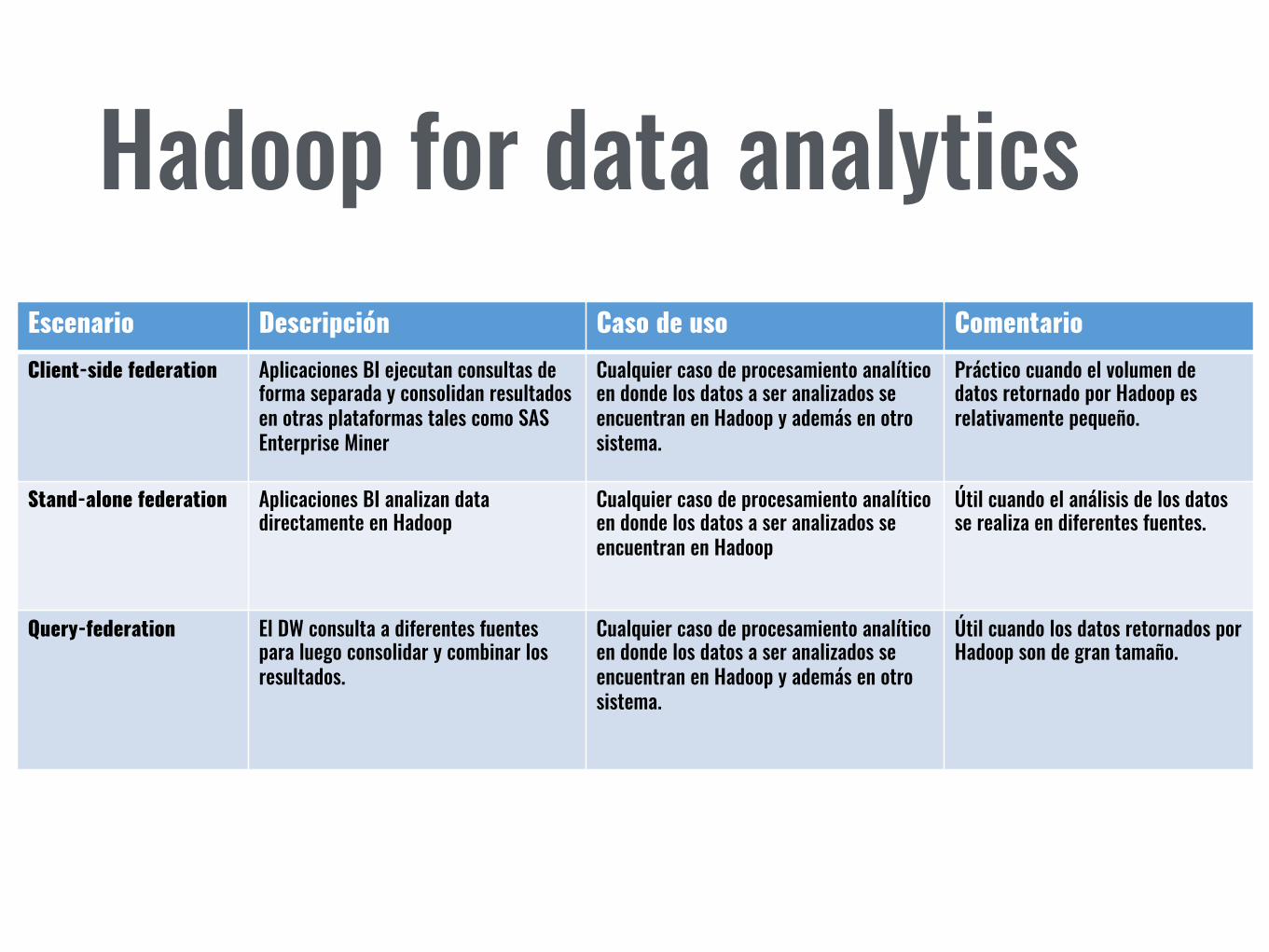
Hadoop for data analyticsEscenario Descripción Caso de uso Comentario
Client-side federation Aplicaciones BI ejecutan consultas de forma separada y consolidan resultados en otras plataformas tales como SAS Enterprise Miner
Cualquier caso de procesamiento analítico en donde los datos a ser analizados se encuentran en Hadoop y además en otro sistema.
Práctico cuando el volumen de datos retornado por Hadoop es relativamente pequeño.
Stand-alone federation Aplicaciones BI analizan data directamente en Hadoop
Cualquier caso de procesamiento analítico en donde los datos a ser analizados se encuentran en Hadoop
Útil cuando el análisis de los datos se realiza en diferentes fuentes.
Query-federation El DW consulta a diferentes fuentes para luego consolidar y combinar los resultados.
Cualquier caso de procesamiento analítico en donde los datos a ser analizados se encuentran en Hadoop y además en otro sistema.
Útil cuando los datos retornados por Hadoop son de gran tamaño.
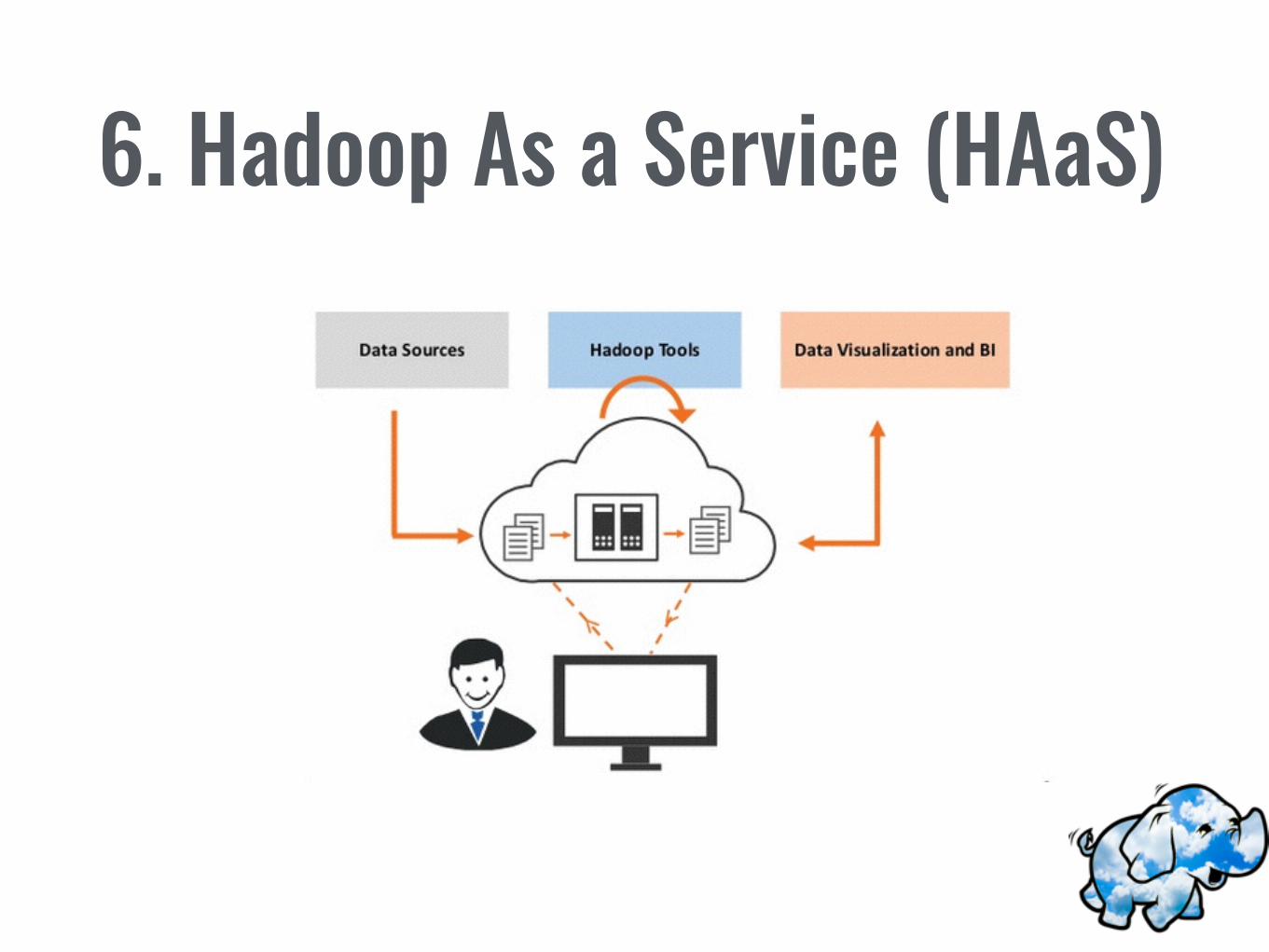
6. Hadoop As a Service (HAaS)

Hadoop As a Service (HAaS)
• Solución de cloud computing que hace el procesamiento de datos de gran escala accesible, fácil y económico.
• Oportunidad para clientes que no cuentan con el “know how” y/o infraestructura necesaria.
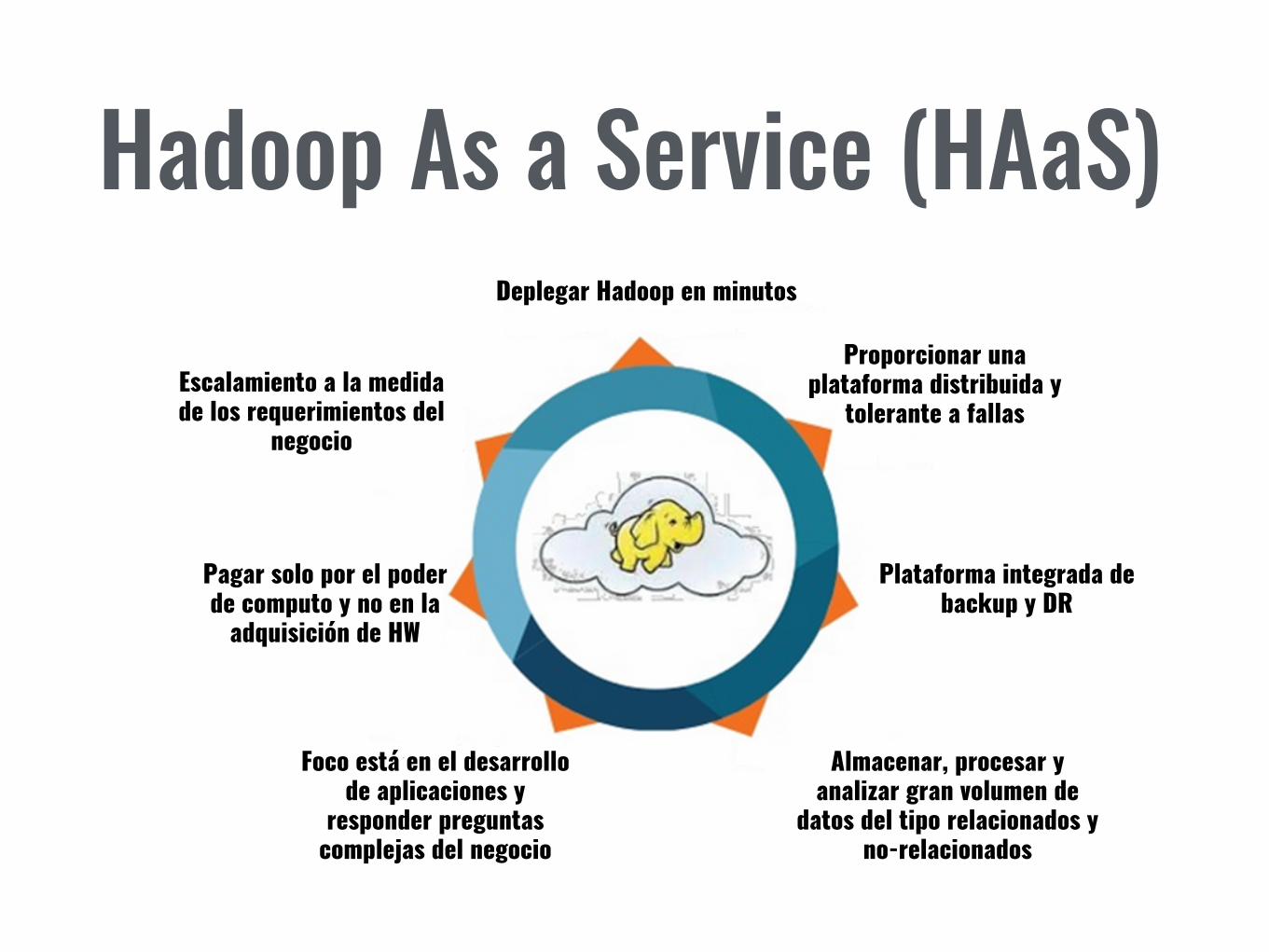
Hadoop As a Service (HAaS)Deplegar Hadoop en minutos
Proporcionar una plataforma distribuida y
tolerante a fallas
Plataforma integrada de backup y DR
Almacenar, procesar y analizar gran volumen de
datos del tipo relacionados y no-relacionados
Foco está en el desarrollo de aplicaciones y
responder preguntas complejas del negocio
Pagar solo por el poder de computo y no en la
adquisición de HW
Escalamiento a la medida de los requerimientos del
negocio
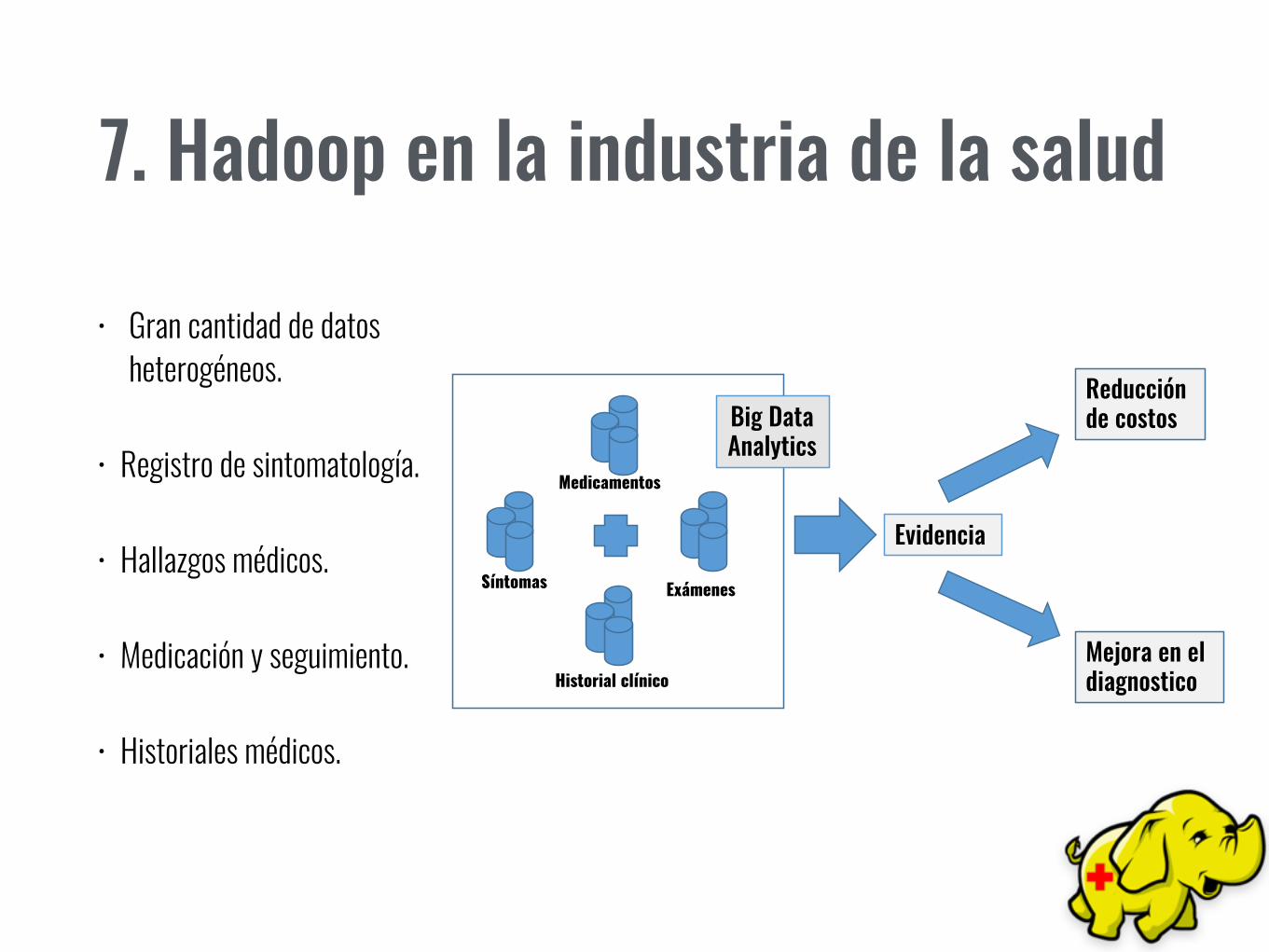
7. Hadoop en la industria de la salud
• Gran cantidad de datos heterogéneos.
• Registro de sintomatología.
• Hallazgos médicos.
• Medicación y seguimiento.
• Historiales médicos.
Síntomas
Medicamentos
Historial clínico
Exámenes
Big Data Analytics
Evidencia
Reducción de costos
Mejora en el diagnostico

Hadoop en la industria de la salud• Procesamiento de imágenes (HIPI – Hadoop Image Processing Interface)
• Almacenamiento de bajo costo y alto poder de computo.
• Posibilidad de realizar procesamiento analítico sobre el cluster.
• La industria requiere de análisis en tiempo real.
• Necesidad de aplicar el proceso KDD (Knowledge Discovery in Databases) para identificar patrones validos y útiles tanto para los pacientes como para los médicos.
• Almacenamiento en la nube potencia soluciones de HAaS.

• Monitoreo constante de los efectos de tratamiento médico.
• Diagnóstico asistido.
• Detección de fraudes .
• Monitoreo de pacientes.
• Análisis de imágenes.
• Repositorio de referencia a búsquedas de enfermedades y síntomas de pacientes.
• Análisis de laboratorio.
Hadoop en la industria de la salud

An Evening with… Apache HadoopArkho Innova Meetup Series - Ejemplo práctico