in4080 natural language processing - uio.no · accuracy: (tp+tn)/n ... lm_4 slide 1- 65 9 language...
TRANSCRIPT

INF4080 – 2018 FALLNATURAL LANGUAGE PROCESSING
Jan Tore Lønning
1

Lecture 6, 12 Sep
Language models, and more
2

Today
Recap: Classification
Language models
Smoothing Language models
Back to Naïve Bayes: the two models
Multinomial NB as Language model
Smoothing in Naïve Bayes
Implementations of Naïve Bayes
3

Classification4

Set-up for experiments5

6

Evaluation measures
Accuracy: (tp+tn)/N
Precision:tp/(tp+fp)
Recall: tp/(tp+fn)
F-score combines P and R
𝐹1 =2𝑃𝑅
𝑃+𝑅=
11𝑅+
1𝑃
2
F1 called ‘’harmonic mean’’
General form
𝐹 =1
𝛼1
𝑃+(1−𝛼)
1
𝑅
for some 0 < 𝛼 < 1
7
Is in C
Yes NO
Class
ifier
Yes tp fp
No fn tn

Today
Recap: Classification
Language models
Smoothing Language models
Back to Naïve Bayes: the two models
Multinomial NB as Language model
Smoothing in Naïve Bayes
Implementations of Naïve Bayes
8

Slides from Jurafsky & Martin 3. ed.
LM_4
Slide 1- 65
Language models9

Today
Recap: Classification
Language models
Smoothing Language models
Back to Naïve Bayes: the two models
Multinomial NB as Language model
Smoothing in Naïve Bayes
Implementations of Naïve Bayes
10

Naive Bayes11

The two models12
Bernoulli
(the standard form of NB)
NLTK book, Sec. 6.1, 6.2, 6.5
Jurafsky and Martin, 2.ed, sec. 20.2, WSD
Multinomial model
For text classification
Related to n-gram models
Jurafsky and Martin, 3.ed, sec. 4, Sentiment analysis
Both
Manning, Raghavan, Schütze, Introduction to Information Retrieval, Sec. 13.0-13.3

Multinomial NB: Decision
fi refers to position i in the text, vi is the word occurring in this position
Simplifying assumption: a word is equally likely in all positions
Hence we count how many times each word occurs in the text
13
n
i
miimSs
nnmSs
svfPsPvfvfvfsP
mm 1
2211|)(maxarg,...,,|maxarg
n
i
mimSs
n
i
miimSs
svPsPsvfPsP
mm 11
|)(maxarg|)(maxarg

Multinomial NB: Training14
where C(sm, o) is the number of occurrences of objects o in class sm
where C(wi, sm) is the number of occurrences of word wi in all texts in class sm
is the total number of words in all texts in class sm
Bernoulli counts the number of objects/texts where wi occurs
Multinomial counts the number of occurrences of wi.
)(
),(ˆ
oC
osCsP
m
m
j
mj
mi
miswC
swCswP
),(
),(|ˆ
j
mjswC ),(

Naïve Bayes: Relationship to Language Modeling
Jurafsky & Martin
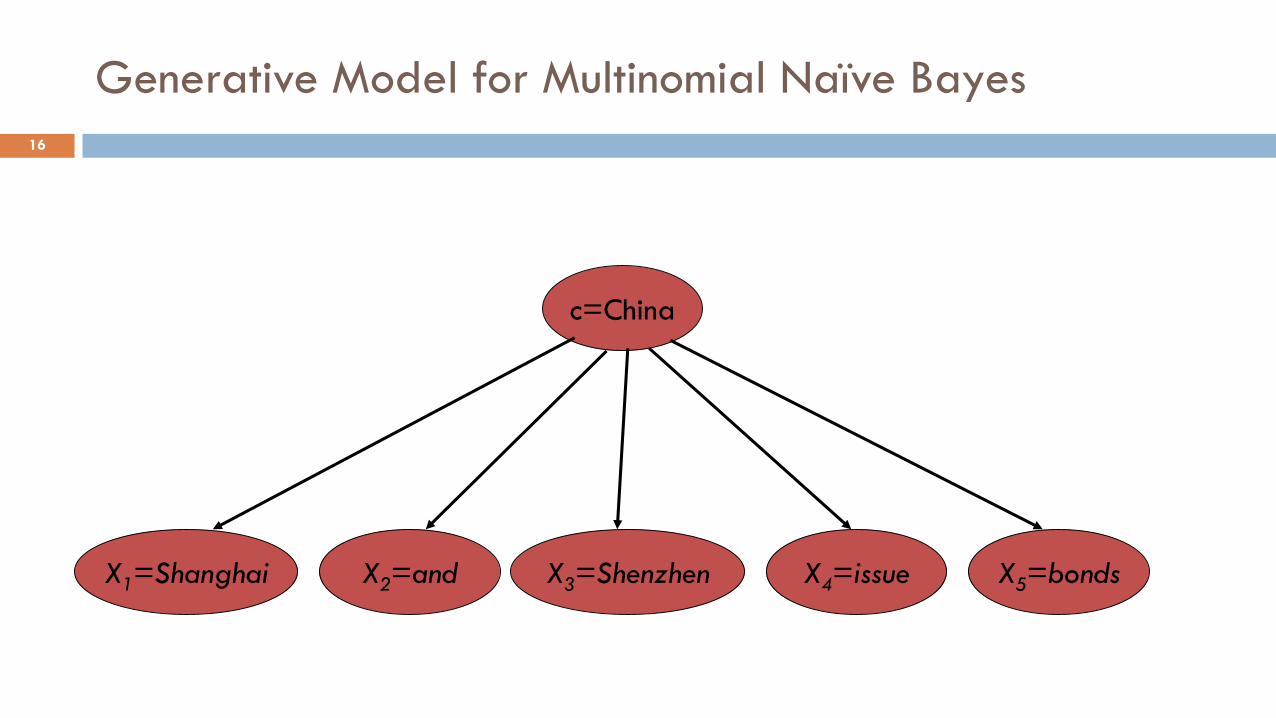
Generative Model for Multinomial Naïve Bayes
16
c=China
X1=Shanghai X2=and X3=Shenzhen X4=issue X5=bonds

Naïve Bayes and Language Modeling
Naïve bayes classifiers can use any sort of feature
URL, email address, dictionaries, network features
But if, as in the previous slides
We use only word features
we use all of the words in the text (not a subset)
Then
Naïve bayes has an important similarity to language modeling.
17

Each class = a unigram language model
Assigning each word: P(word | c)
Assigning each sentence: P(s|c)=σ(𝑤𝑜𝑟𝑑 𝑖𝑛 𝑠)𝑃 𝑤𝑜𝑟𝑑|𝑐
0.1 I
0.1 love
0.01 this
0.05 fun
0.1 film
…
I love this fun film
0.1 0.1 .05 0.01 0.1
Class pos
P(s | pos) = 0.0000005
Sec.13.2.1

Naïve Bayes as a Language Model
Which class assigns the higher probability to s?
0.1 I
0.1 love
0.01 this
0.05 fun
0.1 film
Model pos Model neg
filmlove this funI
0.10.1 0.01 0.050.10.10.001 0.01 0.0050.2
P(s|pos) > P(s|neg)
0.2 I
0.001 love
0.01 this
0.005 fun
0.1 film
Sec.13.2.1

Naïve Bayes: Relationship to Language Modeling
Jurafsky & Martin (end)

Multinomial text classification21
Build a unigram language model for each class
Score the document according to the different classes
Choose the class with the best score
Conversely:
The multinomial NB text classifier may be extended with bigram, or more
generally n-gram, features

Comparison
A number of terms t1, t2, .. tn
Corresponding features f1, f2, … fn
Possible values: {True, False}
fi = True in document d if and only if tioccurs in d
Training, for each class
Count the number of documents where tioccurs and
the number of documents where it doesn't occur
For a document d there is a feature fi for each word position w_i in the document
The possible values are all words that occurs in training
The value v_i is the word that actually occurs in position w_i
Training, for each class
Count the number of occurrences of each word
22
Bernoulli Multinomial

Implementation23

Doing it ourselves24
Possible to implement Naive Bayes classifiers ourselves
(That's not the case for all classifiers)
Efficiency (and memory space) may be challenging
Many available implementations. More efficient.
E.g. scikit-learn

Available learners
Bernoulli NB
Decision trees
(Python inefficient)
Bernoulli NB
Multinomial NB
and many, many more
Much more efficient
25
NLTK Scikit-learn
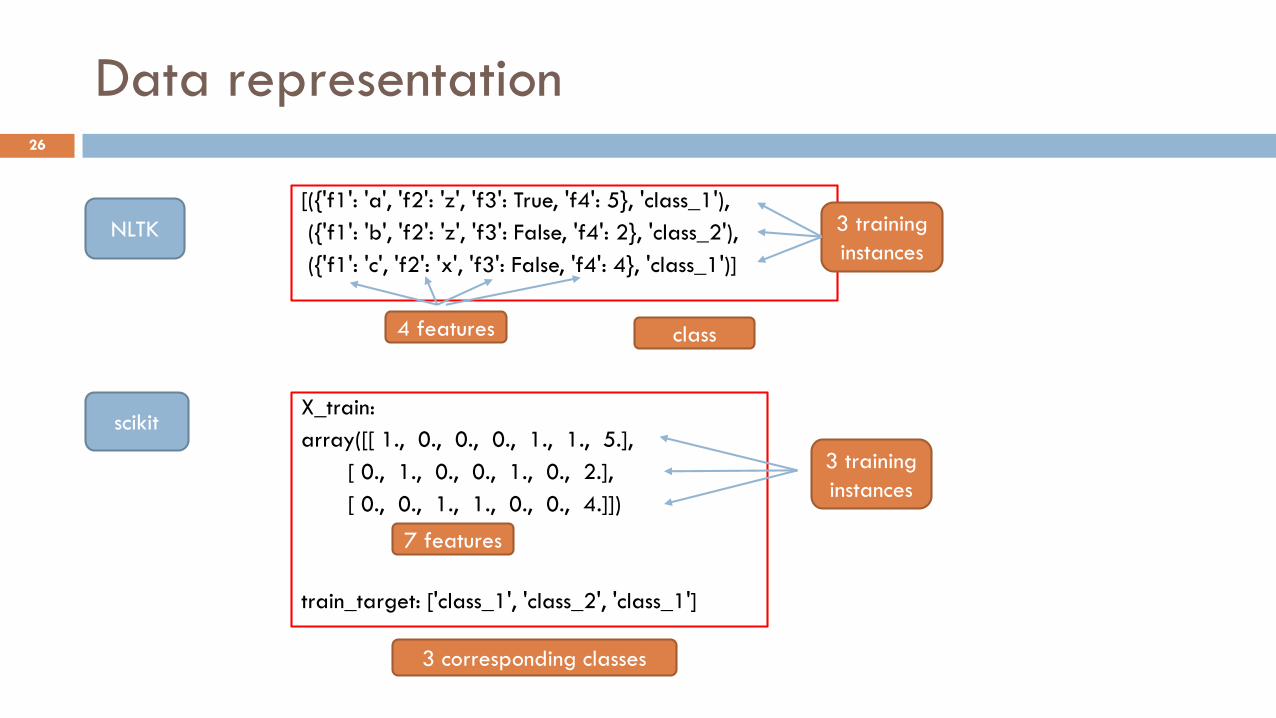
Data representation
[({'f1': 'a', 'f2': 'z', 'f3': True, 'f4': 5}, 'class_1'),
({'f1': 'b', 'f2': 'z', 'f3': False, 'f4': 2}, 'class_2'),
({'f1': 'c', 'f2': 'x', 'f3': False, 'f4': 4}, 'class_1')]
X_train:
array([[ 1., 0., 0., 0., 1., 1., 5.],
[ 0., 1., 0., 0., 1., 0., 2.],
[ 0., 0., 1., 1., 0., 0., 4.]])
train_target: ['class_1', 'class_2', 'class_1']
26
4 features
scikit
NLTK
7 features
class
3 corresponding classes
3 training
instances
3 training
instances

One-hot encoding
X_train:
array([[ 1., 0., 0., 0., 1., 1., 5.],
[ 0., 1., 0., 0., 1., 0., 2.],
[ 0., 0., 1., 1., 0., 0., 4.]])
train_target: ['class_1', 'class_2', 'class_1']
27
scikit
7 features
classes
feature 1 feature 2
a b c x y
(1,0,0) (0,1,0) (0,0,1) (1,0) (0,1)
3 training
instances

Converting a dictionary
We can construct the data to scikit directly
Scikit has methods for converting Python-dictionaries/NLTK-format to arrays
» train_data = [inst[0] for inst in train]
» train_target = [inst[1] for inst in train]
» v = DictVectorizer()
» X_train=v.fit_transform(train_data)
» X_test=v.transform(test_data)
28
1. Constructs (=fit)
repr. format
2. Transform
Transform
Use same v as
for train

Multinomial NB in scikit
We can construct the data to scikit directly
Scikit has methods for converting text to bag of words arrays
» train_data=["en rose er en rose", "anta en rose er en fiol"]
» v = CountVectorizer()
» X_train=v.fit_transform(train_data)
» print(X_train.toarray())[[0 2 1 0 2][1 2 1 1 1]]
29

30
Laplace-smoothing
MLE-estimate:
Laplace-estimat:
Lidstone-smoothing: add k, e.g. 0.5: 𝑃 𝑤𝑖 =𝑐𝑖+𝑘
𝑁+𝑘𝑉
Nltk.NaiveBayesClassifier uses Lidstone (0.5) as default

Example, Bernoulli, 10,000 terms
𝑃 𝑝𝑖𝑡𝑡 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠) =
15
959
𝑃 𝑝𝑖𝑡𝑡 = 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔) =
6
941
𝑃 𝑝𝑖𝑡𝑡 = 𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠) =
944
959
𝑃 𝑝𝑖𝑡𝑡 = 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔) =
935
941
𝑃 𝑝𝑖𝑡𝑡 = 𝑇𝑟𝑢𝑒 𝑝𝑜𝑠) =
15 + 1
959 + 2=
16
961
𝑃 𝑝𝑖𝑡𝑡 = 𝑇𝑟𝑢𝑒 𝑛𝑒𝑔) =
6+1
941+2
𝑃 𝑝𝑖𝑡𝑡 = 𝐹𝑎𝑙𝑠𝑒 𝑝𝑜𝑠) =
944+1
959+2
𝑃 𝑝𝑖𝑡𝑡 = 𝐹𝑎𝑙𝑠𝑒 𝑛𝑒𝑔) =
935+1
941+2
Unsmoothed Smoothed
31

Example, Multinomial, 10,000 terms
𝑃 𝑤 = 𝑝𝑖𝑡𝑡 𝑝𝑜𝑠) =
31
798 742
𝑃 𝑤 = 𝑝𝑖𝑡𝑡 𝑛𝑒𝑔) =
25
705 726
𝑃 𝑤 = 𝑝𝑖𝑡𝑡 𝑝𝑜𝑠) =
31+1
798 742+10 000=
32
799 742
𝑃 𝑤 = 𝑝𝑖𝑡𝑡 𝑛𝑒𝑔) =
25+1
705 726+10 000=
26
706 726
Unsmoothed Smoothed
32