improving data interoperability for python and r
TRANSCRIPT

1© Cloudera, Inc. All rights reserved.
Improving data interoperability in Python and RWes McKinney @wesmckinn
NYC R Conference April 8, 2016

2© Cloudera, Inc. All rights reserved.
http://numfocus.org

3© Cloudera, Inc. All rights reserved.
Me
• Data Science Tools at Cloudera, formerly DataPad CEO/founder
• Serial creator of structured data tools / user interfaces
• Wrote bestseller Python for Data Analysis 2012
• Open source projects
• Python {pandas, Ibis, statsmodels}
• Apache {Arrow, Parquet, Kudu (incubating)}
• Mostly work in Python and Cython/C/C++

4© Cloudera, Inc. All rights reserved.
In process:Python for Data Analysis: 2nd Edition
Coming late 2016 / early 2017

5© Cloudera, Inc. All rights reserved.
Apache Arrow
http://arrow.apache.orgSome slides from Strata-HW talk w/ Jacques Nadeau

6© Cloudera, Inc. All rights reserved.
Arrow in a Slide• New Top-level Apache Software Foundation project
• Focused on Columnar In-Memory Analytics1. 10-100x speedup on many workloads2. Common data layer enables companies to choose best of
breed systems 3. Designed to work with any programming language4. Support for both relational and complex data as-is
• Developers from 13+ major open source projects involved• A significant % of the world’s data will be processed through Arrow!
Calcite
Cassandra
Deeplearning4j
Drill
Hadoop
HBase
Ibis
Impala
Kudu
Pandas
Parquet
Phoenix
Spark
Storm
R

7© Cloudera, Inc. All rights reserved.
High Performance Sharing & InterchangeToday With Arrow
• Each system has its own internal memory format
• 70-80% CPU wasted on serialization and deserialization
• Similar functionality implemented in multiple projects
• All systems utilize the same memory format
• No overhead for cross-system communication
• Projects can share functionality (eg, Parquet-to-Arrow reader)

8© Cloudera, Inc. All rights reserved.
Arrow in action: Feather File Format for Python and R
•Problem: fast, language-agnostic binary data frame file format
•By Wes McKinney (Python) and Hadley Wickham (R)
•Read speeds close to disk IO performance

9© Cloudera, Inc. All rights reserved.
Real World Example: Feather File Format for Python and R
library(feather) path <- "my_data.feather"write_feather(df, path) df <- read_feather(path)
import feather path = 'my_data.feather' feather.write_dataframe(df, path)df = feather.read_dataframe(path)
R Python
10© Cloudera, Inc. All rights reserved.
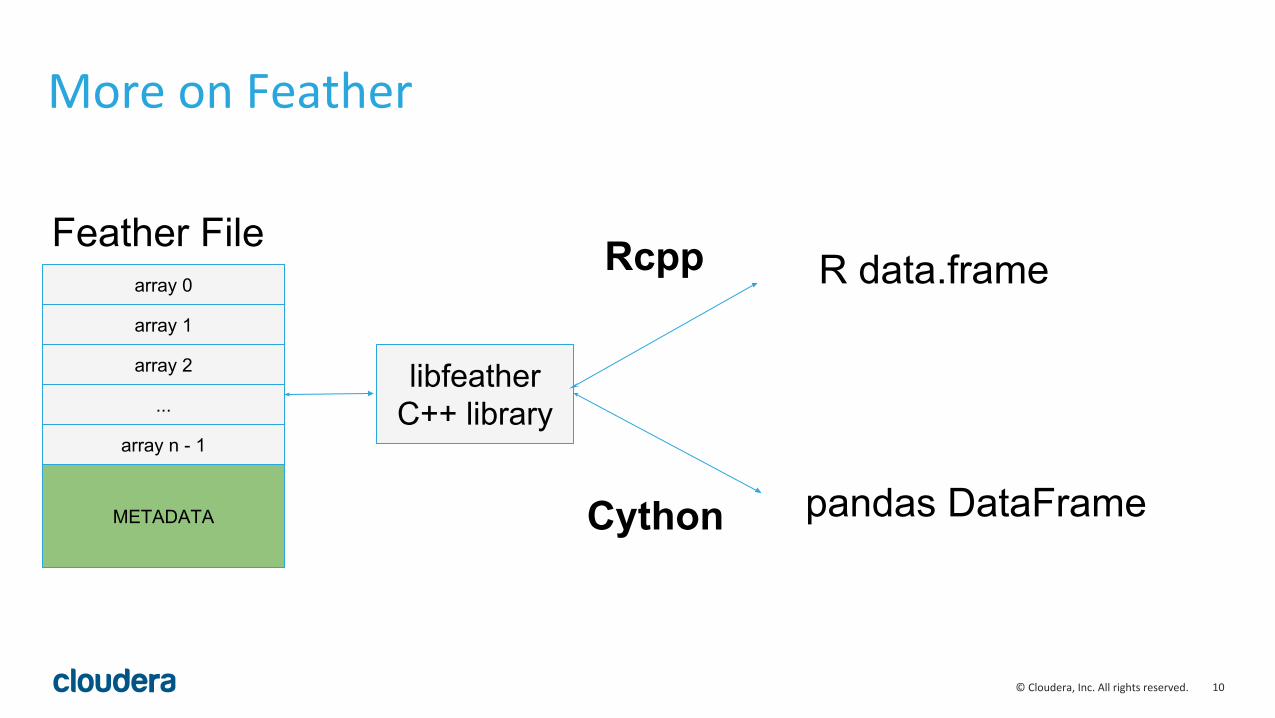
More on Feather
array 0
array 1
array 2
...
array n - 1
METADATA
Feather File
libfeatherC++ library
Rcpp
Cython
R data.frame
pandas DataFrame

11© Cloudera, Inc. All rights reserved.
Feather: the good and not-so-good
• Good• Language-agnostic memory representation• Extremely fast• New storage features can be added without much difficulty
• Not-so-good• Data must be convert to/from storage representation (Arrow) and in-
memory “proprietary” data structures (R / Python data frames)

12© Cloudera, Inc. All rights reserved.
Shared needs for Python, R, Julia, ...
• If PLs can establish a common data frame C/C++-level memory representation, we can share algorithms and libraries much more easily• Example: dplyr’s in-memory backend
• Other requirements• Permissive licensing (Python / Julia require MIT/Apache-like)• Common build/test/packaging for shared C/C++ library components

13© Cloudera, Inc. All rights reserved.
Get Involved in Arrow• Join the community
• Slack: https://apachearrowslackin.herokuapp.com/
• http://arrow.apache.org
• @ApacheArrow

14© Cloudera, Inc. All rights reserved.
Thank youWes McKinney @wesmckinn
Views are my own