improved models and algorithms for universal dna tag systems continued … a.k.a. what did we do?
TRANSCRIPT

Improved Models and Algorithms for Universal DNA Tag Systems
continued …
a.k.a. what did we do?
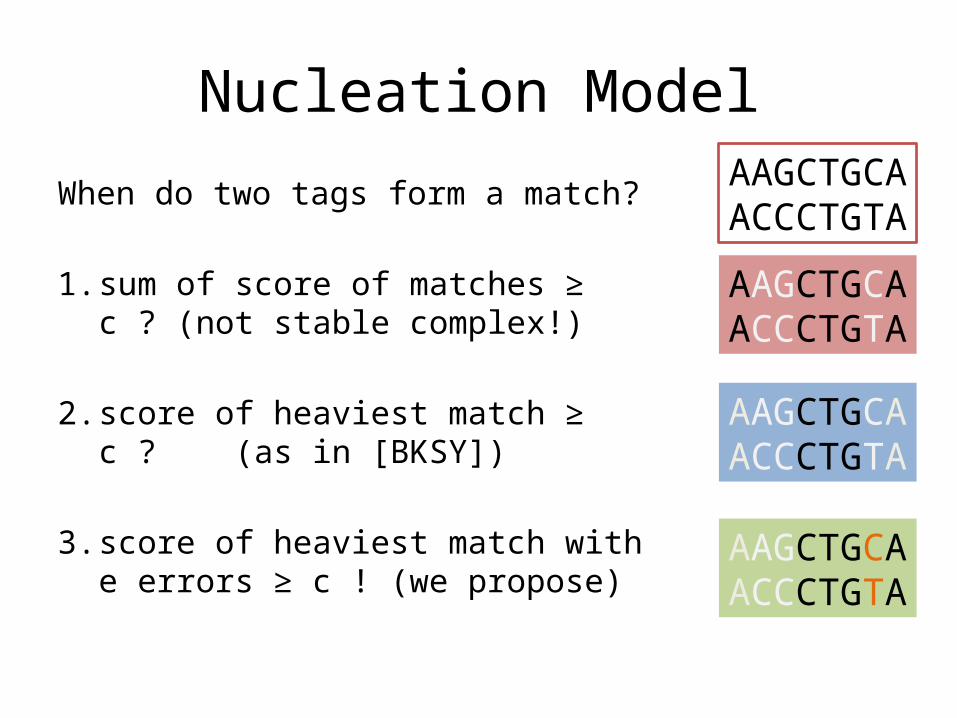
Nucleation Model
When do two tags form a match?
1. sum of score of matches ≥ c ? (not stable complex!)
2. score of heaviest match ≥ c ? (as in [BKSY])
3. score of heaviest match with e errors ≥ c ! (we propose)
AAGCTGCAACCCTGTA
AAGCTGCAACCCTGTA
AAGCTGCAACCCTGTA
AAGCTGCAACCCTGTA

Score of a single match (recap)
May be computed via either of• 2-4 Rule– easy approximation: A-T = 2, G-C = 4– sum gives melting temperature
• Nearest Neighbor Rule– sum energies due to contiguous A-T & C-G pairs– A-T different from T-A different from A-G etc ..

• It’s an improvement.[BKSY] would predict
• We predict
• mfold predicts
Is this a realistic model ?
CGTAGCACGAAAACTCGTATCA
CGTAGCACGAAAACTCGTATCA
ACAGCAATGGAGATCGGTACTA
ACAGCAATGGAGATCGGTACTA
>
<
Tm = 3.2°C Tm = 13.8°C
(6,0) match (9,1) match

Definitions
Two strings s1 and s2 have a (c,e)-match if they have substrings t1 and t2 such that:
1. w(t1) = w(t2) ≥ c
2. t1 and t2 differ in ≤ e places
A tag system is an (h,c,e)-code if3. every tag has weight atleast h4. no two tags have a (c,e)-match

Design of (h,c,e)-code with large size
Outline of Upper Bound on size• How? Via upper bound on number of c-tokens (the
substrings t that have weight ≈ c)• Choosing one c-token in a tag knocks out a sphere of
nearby c-tokens from further use in any other tag.• Similar to sphere packing bound in coding theory.
Algorithms for generating optimal codes• Modify alphabetic tree-search algorithm of [MPT]

c-tokens (recap)
• strings with weight ≥ c• no proper suffix of weight ≥ c• have weight either c or c+1• length ranges from c (all C/G) to 2c (all A/T)
• can’t use tailweight method of [BKSY]
nucleation complexes=
Two c-tokens differing in at most e symbols

A sphere around CGCA
C G C A
• is a 6-token of weight 7, length 4• how many 4-length codewords at distance 1?
TGCA·GGCA AGCA
CACACCCA·CTCA
CGGACGTACGAA
CGCCCGCTCGCG

How many such spheres pack the whole space ?
Now look at spheres around codewords of optimum code
vol(s) total number of c-tokenss a redsphere
≤must be disjoint !size of code × vol(sphere) total number of c-tokens≤

Size of a sphere
• Suppose string s has a A/T and b C/G symbols• weight = a + 2b, length = a + b• Introduce e errors into s to get t
• weight of t same as weight of s, so e1 = e2• for errors of type 1, pick in ways and options
to change to
REPLACE WEIGHT NUMBER
A→G, A→C, T→G, T→C +1 e1
G→A, C→A, G→T, C→T -1 e2
A→T, T→A, C→G, G→C 0 e3

• One tag of weight h uses (h-c+1) tokens • So size of code ≤
Size of sphere
=
Substitute a = 2l – c and b = c - l
l varies from c/2 to c, c-tokens of weight c or c+1
= number of strings of length l =

Can tighten the bound further• our sphere knocked out only c-tokens of the
same length• we should also remove similar c-tokens of
other lengths .. reduce bound by factor e ?
In comparison to [BKSY] bound• h = 30, c = 12, e = 0: 13840 ≥ #tags ≥ 12000• h = 30, c = 12, e = 2: #tags ≤ 1268• if nucleation does occur with errors then we
can’t assume so many tags

Plot of upper bound vs. c,e (h = 50)
108
64
20
1
100
10000
1000000
100000000
10000000000
1000000000000
12 14 16 18 20 22 24 26 28
uppe
r bou
nd o
nnu
mbe
r of c
odew
ords
e – number of errorsc –
weight of n
ucleation co
mplex

Open Problems & Remarks• design, analyze efficient algorithms for model
• can we use random deBruijn sequences to generate codewords ? analyze using mixing techniques on Markov chain of [KMUW] ?
• exciting new question for coding theory: alphabets with weighted Hamming distances!