importing data into neo4j quickly and easily - stackoverflow
TRANSCRIPT

Importing data quickly and easily
Michael Hunger @mesiriiMark Needham @markhneedham

The data set

The data set
‣ Stack Exchange API‣ Stack Exchange Data Dump

Stack Exchange API
{ "items": [{
"question_id": 24620768,
"link": "http://stackoverflow.com/questions/24620768/neo4j-cypher-query-get-last-n-elements",
"title": "Neo4j cypher query: get last N elements",
"answer_count": 1,
"score": 1,
.....
"creation_date": 1404771217,
"body_markdown": "I have a graph....How can I do that?",
"tags": ["neo4j", "cypher"],
"owner": {
"reputation": 815,
"user_id": 1212067,
....
"link": "http://stackoverflow.com/users/1212067/"
},
"answers": [{
"owner": {
"reputation": 488,
"user_id": 737080,
"display_name": "Chris Leishman",
....
},
"answer_id": 24620959,
"share_link": "http://stackoverflow.com/a/24620959",
....
"body_markdown": "The simplest would be to use an ... some discussion on this here:...",
"title": "Neo4j cypher query: get last N elements"
}]
}
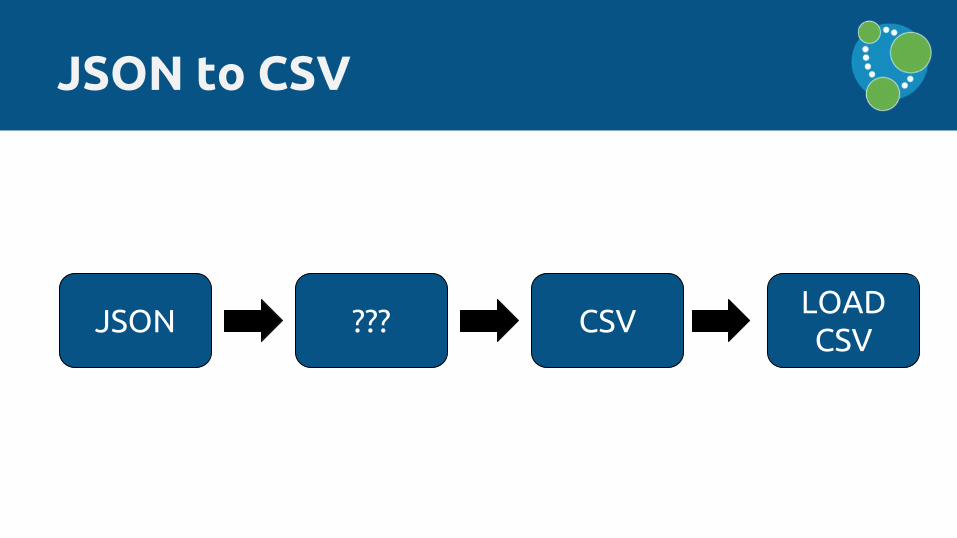
JSON to CSV
JSON ??? CSVLOAD CSV
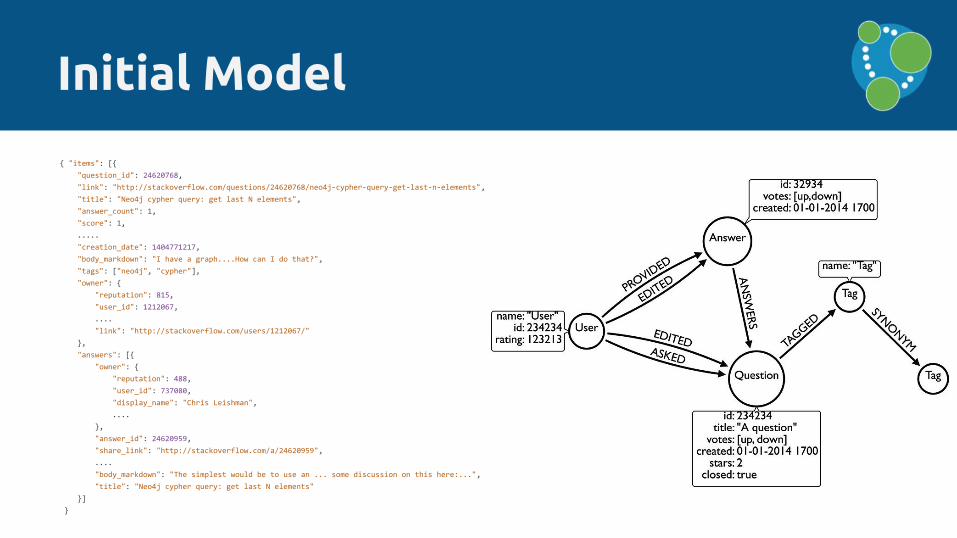
Initial Model
{ "items": [{
"question_id": 24620768,
"link": "http://stackoverflow.com/questions/24620768/neo4j-cypher-query-get-last-n-elements",
"title": "Neo4j cypher query: get last N elements",
"answer_count": 1,
"score": 1,
.....
"creation_date": 1404771217,
"body_markdown": "I have a graph....How can I do that?",
"tags": ["neo4j", "cypher"],
"owner": {
"reputation": 815,
"user_id": 1212067,
....
"link": "http://stackoverflow.com/users/1212067/"
},
"answers": [{
"owner": {
"reputation": 488,
"user_id": 737080,
"display_name": "Chris Leishman",
....
},
"answer_id": 24620959,
"share_link": "http://stackoverflow.com/a/24620959",
....
"body_markdown": "The simplest would be to use an ... some discussion on this here:...",
"title": "Neo4j cypher query: get last N elements"
}]
}
jq: Converting JSON to CSV

jq: Converting questions to CSV
jq -r '.[] | .items[] | [.question_id, .title, .up_vote_count, .down_vote_count, .creation_date, .last_activity_date, .owner.user_id, .owner.display_name, (.tags | join(";"))] | @csv ' so.json

jq: Converting questions to CSV
$ head -n5 questions.csvquestion_id,title,up_vote_count,down_vote_count,creation_date,last_activity_date,owner_user_id,owner_display_name,tags33023306,"How to delete multiple nodes by specific ID using Cypher",0,0,1444328760,1444332194,260511,"rayman","jdbc;neo4j;cypher;spring-data-neo4j"33020796,"How do a general search across string properties in my nodes?",1,0,1444320356,1444324015,1429542,"osazuwa","ruby-on-rails;neo4j;neo4j.rb"33018818,"Neo4j match nodes related to all nodes in collection",0,0,1444314877,1444332779,1212463,"lmazgon","neo4j;cypher"33018084,"Problems upgrading to Spring Data Neo4j 4.0.0",0,0,1444312993,1444312993,1528942,"Grégoire Colbert","neo4j;spring-data-neo4j"

jq: Converting answers to CSV
jq -r '.[] | .items[] | { question_id: .question_id, answer: .answers[]? } | [.question_id, .answer.answer_id, .answer.title, .answer.owner.user_id, .answer.owner.display_name, (.answer.tags | join(";")), .answer.up_vote_count, .answer.down_vote_count] | @csv'

jq: Converting answers to CSV
$ head -n5 answers.csvquestion_id,answer_id,answer_title,owner_id,owner_display_name,tags,up_vote_count,down_vote_count33023306,33024189,"How to delete multiple nodes by specific ID using Cypher",3248864,"FylmTM","",0,033020796,33021958,"How do a general search across string properties in my nodes?",2920686,"FrobberOfBits","",0,033018818,33020068,"Neo4j match nodes related to all nodes in collection",158701,"Stefan Armbruster","",0,033018818,33024273,"Neo4j match nodes related to all nodes in collection",974731,"cybersam","",0,0

Time to import into Neo4j...

Introducing Cypher
‣ The Graph Query Language‣ Declarative language (think SQL) for graphs‣ ASCII art based

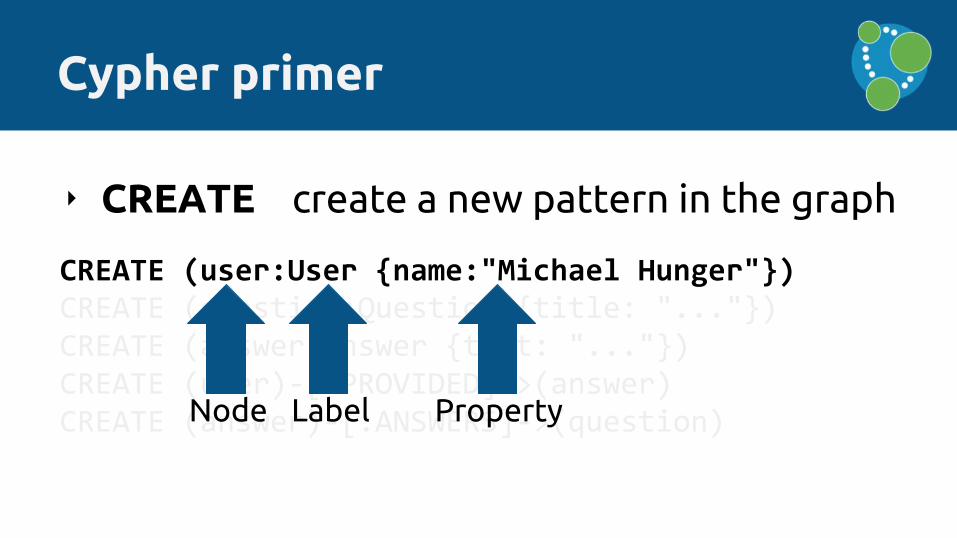
‣ CREATE create a new pattern in the graph
Cypher primer
CREATE (user:User {name:"Michael Hunger"})CREATE (question:Question {title: "..."})CREATE (answer:Answer {text: "..."})CREATE (user)-[:PROVIDED]->(answer)CREATE (answer)-[:ANSWERS]->(question)
‣ CREATE create a new pattern in the graph
Cypher primer
CREATE (user:User {name:"Michael Hunger"})CREATE (question:Question {title: "..."})CREATE (answer:Answer {text: "..."})CREATE (user)-[:PROVIDED]->(answer)CREATE (answer)-[:ANSWERS]->(question)
CREATE (user:User {name:"Michael Hunger"})
Label PropertyNode
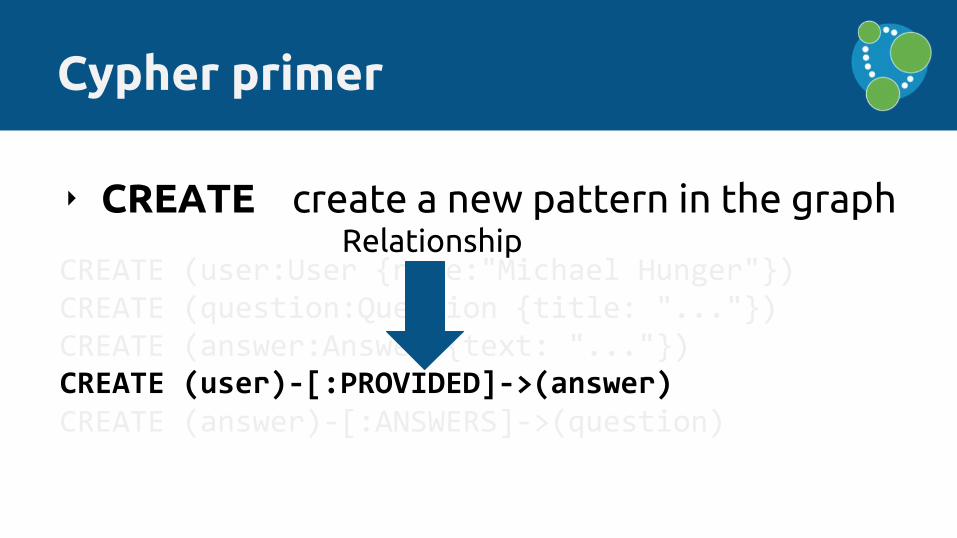
‣ CREATE create a new pattern in the graph
Cypher primer
CREATE (user:User {name:"Michael Hunger"})CREATE (question:Question {title: "..."})CREATE (answer:Answer {text: "..."})CREATE (user)-[:PROVIDED]->(answer)CREATE (answer)-[:ANSWERS]->(question)
CREATE (user)-[:PROVIDED]->(answer)
Relationship

‣ MATCH find a pattern in the graph
Cypher primer
MATCH (answer:Answer)<-[:PROVIDED]-(user:User), (answer)-[:ANSWERS]->(question)WHERE user.display_name = "Michael Hunger"RETURN question, answer

‣ MERGE find pattern if it exists, create it if it doesn’t
MERGE (user:User {name:"Mark Needham"})MERGE (question:Question {title: "..."})MERGE (answer:Answer {text: "..."})MERGE (user)-[:PROVIDED]->(answer)MERGE (answer)-[:ANSWERS]->(question)
Cypher primer

Import using LOAD CSV
‣ LOAD CSV iterates CSV files applying the provided query line by line
LOAD CSV [WITH HEADERS] FROM [URI/File path] AS rowCREATE ...MERGE ...MATCH ...

LOAD CSV: The naive versionLOAD CSV WITH HEADERS FROM "questions.csv" AS row
MERGE (question:Question { id:row.question_id, title: row.title, up_vote_count: row.up_vote_count, creation_date: row.creation_date})
MERGE (owner:User {id:row.owner_user_id, display_name: row.owner_display_name})
MERGE (owner)-[:ASKED]->(question)
FOREACH (tagName IN split(row.tags, ";") | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag));

Tip: Start with a sampleLOAD CSV WITH HEADERS FROM "questions.csv" AS row WITH row LIMIT 100
MERGE (question:Question { id:row.question_id, title: row.title, up_vote_count: row.up_vote_count, creation_date: row.creation_date})
MERGE (owner:User {id:row.owner_user_id, display_name: row.owner_display_name})
MERGE (owner)-[:ASKED]->(question)
FOREACH (tagName IN split(row.tags, ";") | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag));

Tip: MERGE on a keyLOAD CSV WITH HEADERS FROM "questions.csv" AS row WITH row LIMIT 100
MERGE (question:Question {id:row.question_id})ON CREATE SET question.title = row.title, question.up_vote_count = row.up_vote_count, question.creation_date = row.creation_date
MERGE (owner:User {id:row.owner_user_id})ON CREATE SET owner.display_name = row.owner_display_name
MERGE (owner)-[:ASKED]->(question)
FOREACH (tagName IN split(row.tags, ";") | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag));

Tip: Index those keys
CREATE INDEX ON :Label(property)

Tip: Index those keys
CREATE INDEX ON :Label(property)
CREATE INDEX ON :Question(id);
CREATE INDEX ON :User(id);

LOAD CSV WITH HEADERS FROM "questions.csv" AS row WITH row LIMIT 100
MERGE (question:Question {id:row.question_id})ON CREATE SET question.title = row.title, question.up_vote_count = row.up_vote_count, question.creation_date = row.creation_date
Tip: One MERGE per statement

LOAD CSV WITH HEADERS FROM "questions.csv" AS row WITH row LIMIT 100
MERGE (owner:User {id:row.owner_user_id})ON CREATE SET owner.display_name = row.owner_display_name
Tip: One MERGE per statement

LOAD CSV WITH HEADERS FROM "questions.csv" AS row WITH row LIMIT 100
MATCH (question:Question {id:row.question_id})MATCH (owner:User {id:row.owner_user_id})
MERGE (owner)-[:ASKED]->(question)
Tip: One MERGE per statement

Tip: Use DISTINCT
LOAD CSV WITH HEADERS FROM "questions.csv" AS row
WITH row LIMIT 100
UNWIND split(row.tags, ";") AS tag
WITH distinct tag
MERGE (:Tag {name: tag})

Tip: Use periodic commit
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "questions.csv" AS row
MERGE (question:Question {id:row.question_id})ON CREATE SET question.title = row.title, question.up_vote_count = row.up_vote_count, question.creation_date = row.creation_date

Periodic commit
‣ Neo4j keeps all transaction state in memory which is problematic for large CSV files
‣ USING PERIODIC COMMIT flushes the transaction after a certain number of rows
‣ Default is 1000 rows but it’s configurable‣ Currently only works with LOAD CSV
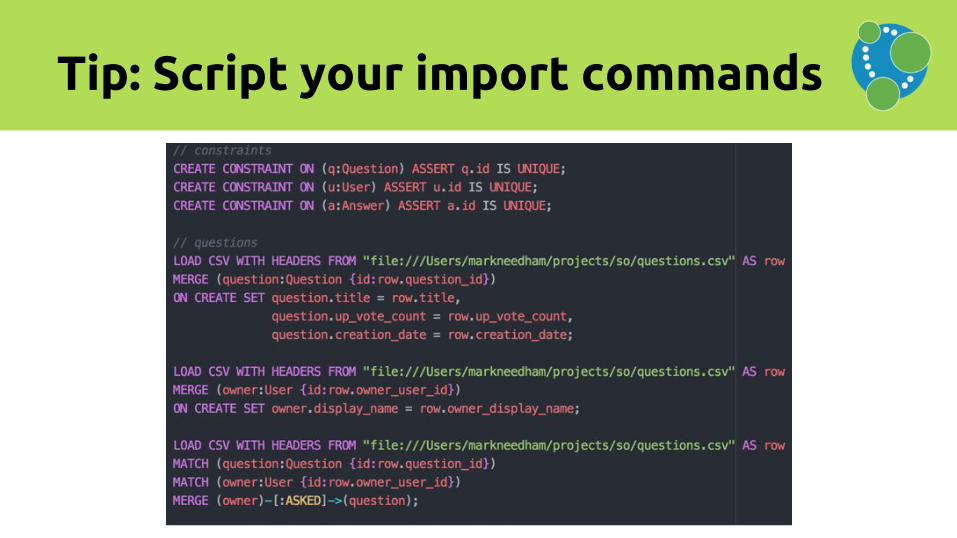
Tip: Script your import commands

Tip: Use neo4j-shell to load script
$ ./neo4j-enterprise-2.3.0/bin/neo4j-shell --file import.cql

LOAD CSV: Summary
‣ ETL power tool‣ Built into Neo4J since version 2.1‣ Can load data from any URL‣ Good for medium size data
(up to 10M rows)

Bulk loading an initial data set
‣ Introducing the Neo4j Import Tool‣ Find it in the bin folder of your Neo4j
download‣ Used to large sized initial data sets‣ Skips the transactional layer of Neo4j and
writes store files directly

Importing into Neo4j
:ID(Crime) :LABEL description
export NEO=neo4j-enterprise-2.3.0
$NEO/bin/neo4j-import \ --into stackoverflow.db \ --id-type string \ --nodes:Post extracted/Posts_header.csv,extracted/Posts.csv.gz \ --nodes:User extracted/Users_header.csv,extracted/Users.csv.gz \ --nodes:Tag extracted/Tags_header.csv,extracted/Tags.csv.gz \ --relationships:PARENT_OF extracted/PostsRels_header.csv,extracted/PostsRels.csv.gz \ --relationships:ANSWERS extracted/PostsAnswers_header.csv,extracted/PostsAnswers.csv.gz\ --relationships:HAS_TAG extracted/TagsPosts_header.csv,extracted/TagsPosts.csv.gz \ --relationships:POSTED extracted/UsersPosts_header.csv,extracted/UsersPosts.csv.gz

Expects files in a certain format
:ID(Crime) :LABEL descriptionpostId:ID(Post) title body
Nodes
userId:ID(User) displayname views
Rels
:START_ID(User) :END_ID(Post)

<?xml version="1.0" encoding="utf-16"?><posts>... <row Id="4" PostTypeId="1" AcceptedAnswerId="7" CreationDate="2008-07-31T21:42:52.667" Score="358" ViewCount="24247" Body="..." OwnerUserId="8" LastEditorUserId="451518" LastEditorDisplayName="Rich B" LastEditDate="2014-07-28T10:02:50.557" LastActivityDate="2015-08-01T12:55:11.380" Title="When setting a form's opacity should I use a decimal or double?" Tags="<c#><winforms><type-conversion><opacity>" AnswerCount="13" CommentCount="1" FavoriteCount="28" CommunityOwnedDate="2012-10-31T16:42:47.213" />...</posts>
What do we have?

<posts>... <row Id="4" PostTypeId="1" AcceptedAnswerId="7" CreationDate="2008-07-31T21:42:52.667" Score="358" ViewCount="24247" Body="..." OwnerUserId="8" LastEditorUserId="451518" LastEditorDisplayName="Rich B" LastEditDate="2014-07-28T10:02:50.557" LastActivityDate="2015-08-01T12:55:11.380" Title="When setting a form's opacity should I use a decimal or double?"
XML to CSV
Java program

The generated files$ cat extracted/Posts_header.csv"postId:ID(Post)","title","postType:INT","createdAt","score:INT","views:INT","answers:INT","comments:INT","favorites:INT","updatedAt"
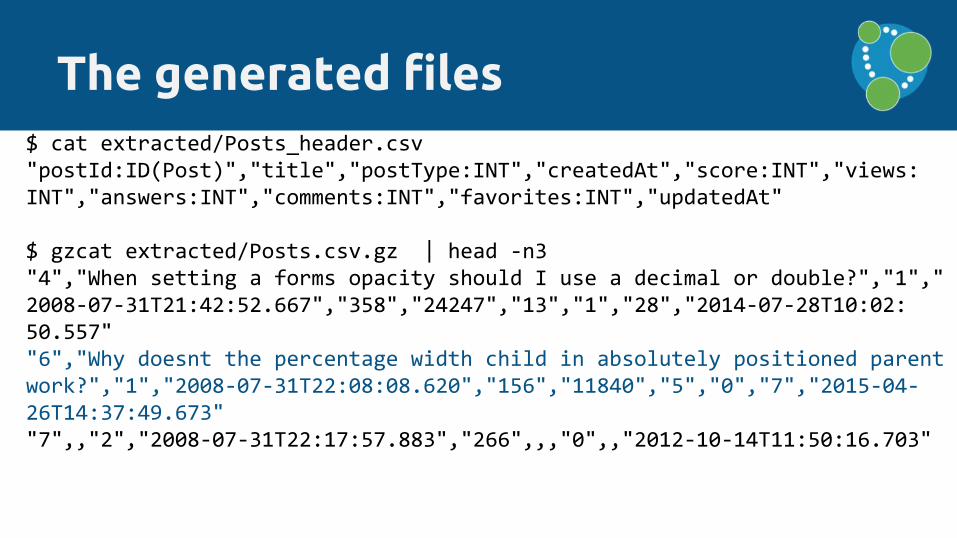
The generated files$ cat extracted/Posts_header.csv"postId:ID(Post)","title","postType:INT","createdAt","score:INT","views:INT","answers:INT","comments:INT","favorites:INT","updatedAt"
$ gzcat extracted/Posts.csv.gz | head -n3"4","When setting a forms opacity should I use a decimal or double?","1","2008-07-31T21:42:52.667","358","24247","13","1","28","2014-07-28T10:02:50.557""6","Why doesnt the percentage width child in absolutely positioned parent work?","1","2008-07-31T22:08:08.620","156","11840","5","0","7","2015-04-26T14:37:49.673""7",,"2","2008-07-31T22:17:57.883","266",,,"0",,"2012-10-14T11:50:16.703"

The generated files
$ cat extracted/Posts_header.csv
"postId:ID(Post)","title","postType:INT", "createdAt","score:INT","views:INT","answers:INT", "comments:INT","favorites:INT","updatedAt"
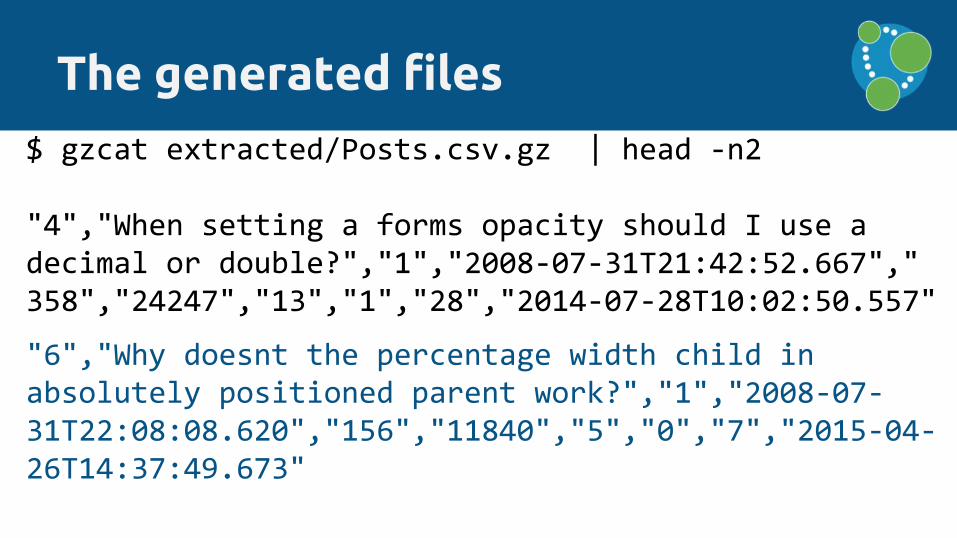
The generated files$ gzcat extracted/Posts.csv.gz | head -n2
"4","When setting a forms opacity should I use a decimal or double?","1","2008-07-31T21:42:52.667","358","24247","13","1","28","2014-07-28T10:02:50.557"
"6","Why doesnt the percentage width child in absolutely positioned parent work?","1","2008-07-31T22:08:08.620","156","11840","5","0","7","2015-04-26T14:37:49.673"

The generated files
$ cat extracted/PostsRels_header.csv":START_ID(Post)",":END_ID(Post)"

Importing into Neo4j
:ID(Crime) :LABEL description
export NEO=neo4j-enterprise-2.3.0
$NEO/bin/neo4j-import \ --into stackoverflow.db \ --id-type string \ --nodes:Post extracted/Posts_header.csv,extracted/Posts.csv.gz \ --nodes:User extracted/Users_header.csv,extracted/Users.csv.gz \ --nodes:Tag extracted/Tags_header.csv,extracted/Tags.csv.gz \ --relationships:PARENT_OF extracted/PostsRels_header.csv,extracted/PostsRels.csv.gz \ --relationships:ANSWERS extracted/PostsAnswers_header.csv,extracted/PostsAnswers.csv.gz\ --relationships:HAS_TAG extracted/TagsPosts_header.csv,extracted/TagsPosts.csv.gz \ --relationships:POSTED extracted/UsersPosts_header.csv,extracted/UsersPosts.csv.gz \
IMPORT DONE in 3m 10s 661ms. Imported: 31138574 nodes 77930024 relationships 218106346 properties

Tip: Make sure your data is clean
:ID(Crime) :LABEL description‣ Use a consistent line break style‣ Ensure headers are consistent with data‣ Quote Special characters‣ Escape stray quotes‣ Remove non-text characters

Even more tips
:ID(Crime) :LABEL description‣ Get the fastest disk you can‣ Use separate disk for input and output‣ Compress your CSV files‣ The more cores the better ‣ Separate headers from data

The End
‣ https://github.com/mdamien/stackoverflow-neo4j‣ http://neo4j.com/blog/import-10m-stack-overflow-questions/‣ http://neo4j.com/blog/cypher-load-json-from-url/
Michael Hunger @mesiriiMark Needham @markhneedham