impact of auto-tuning of kernel loop transformation by using ppopen-at
TRANSCRIPT

Impact of Auto-tuning of Kernel Loop Transformation
by using ppOpen-ATTakahiro Katagiri
Supercomputing Research Division,
Information Technology Center,
The University of Tokyo
1
.
Collaborators:Satoshi Ohshima, Masaharu Matsumoto (Information Technology Center, The University of Tokyo)SPNS2013, December 5th -6th, 2013 Conference Room, 3F, Bldg.1, Earthquake Research Institute (ERI), The University of TokyoDecember 6th, 2013, ppOpen-HPC and Automatic Tuning (Chair: Hideyuki Jitsumoto), 1330-1400

OutlineBackground
ppOpen-AT System
Target Application and Its Kernel Loop Transformation
Performance Evaluation
Conclusion
2

OutlineBackground
ppOpen-AT System
Target Application and Its Kernel Loop Transformation
Performance Evaluation
Conclusion
3

Performance Portability (PP)
4
Keeping high performance in multiple computer environments.
◦ Not only multiple CPUs, but also multiple compilers.
◦ Run-time information, such as loop length and number of threads, is important.
Auto-tuning (AT) is one of candidate technologies to establish PP in multiple computer environments.
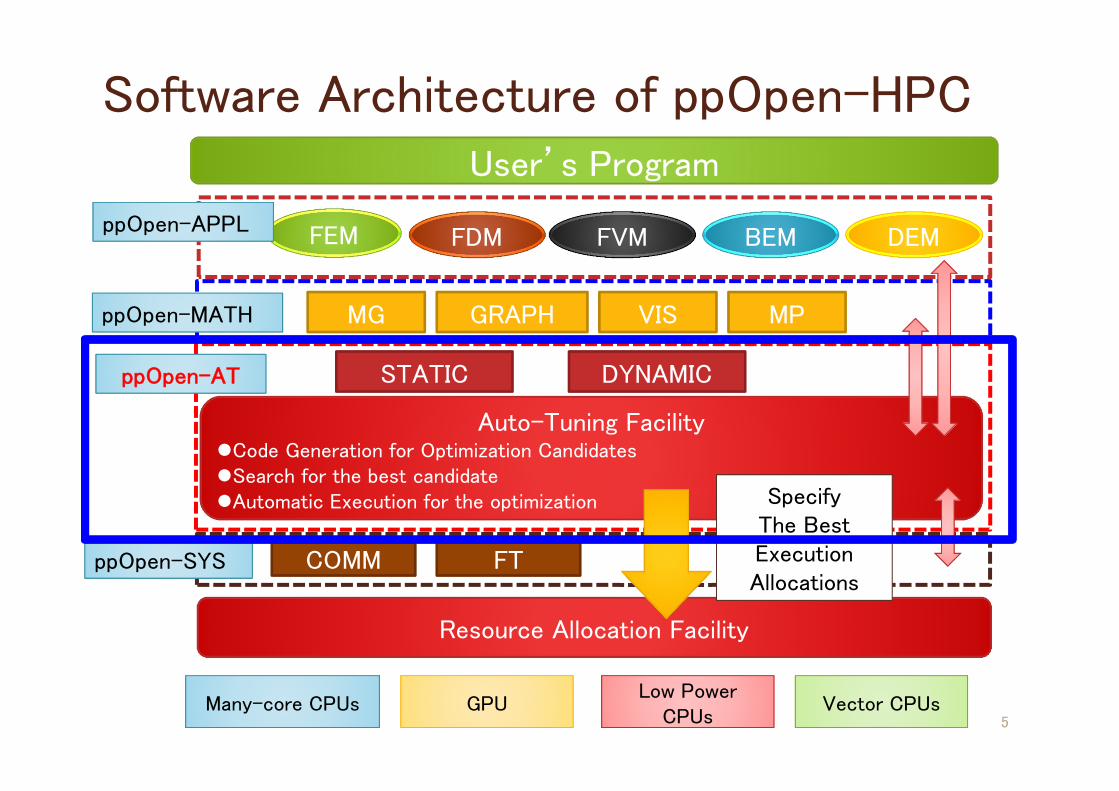
5
FVM DEMFDMFEM
Many-core CPUs GPULow Power
CPUsVector CPUs
MG
COMM
Auto-Tuning FacilityCode Generation for Optimization CandidatesSearch for the best candidateAutomatic Execution for the optimization
Resource Allocation Facility
ppOpen-APPL
ppOpen-MATH
BEM
ppOpen-AT
User’s Program
GRAPH VIS MP
STATIC DYNAMIC
ppOpen-SYS FT
Specify The Best Execution Allocations
Software Architecture of ppOpen-HPC

OutlineBackground
ppOpen-AT System
Target Application and Its Kernel Loop Transformation
Performance Evaluation
Conclusion
6

Design Policy of ppOpen-AT I. Domain Specific Language (DSL) for
Dedicated Processes for ppOpen-HPCSimple functions of languages
to restrict computation patterns in ppOpen-HPC.
II. Directive-base AT LanguageCodes of ppOpen-HPC are frequently
modified, since it is under development software.
To add AT functions, we provide AT by a directive-base manner.
7

Design Policy of ppOpen-AT (Cont’d)III. Utilizing Developer’s Knowledge
Some loop transformations require increase of memory and/or computational complexities.
To establish the loop transformation, user admits via the directive.
IV. Minimum Software-Stack RequirementTo establish AT in supercomputers in
operation, our AT system does not use dynamic code generator. No daemon and no dynamic job submission
are required. No script language is also required for
the AT system.8

ppOpen‐AT SystemppOpen‐APPL /*
ppOpen‐ATDirectives
User KnowledgeLibrary
Developer
① Before Release‐time
Candidate1
Candidate2
Candidate3
CandidatenppOpen‐AT
Auto‐Tuner
ppOpen‐APPL / *
AutomaticCodeGeneration②
:Target Computers
Execution Time④
Library User
③
Library Call
Selection
⑤
⑥
Auto‐tunedKernelExecution
Run‐time
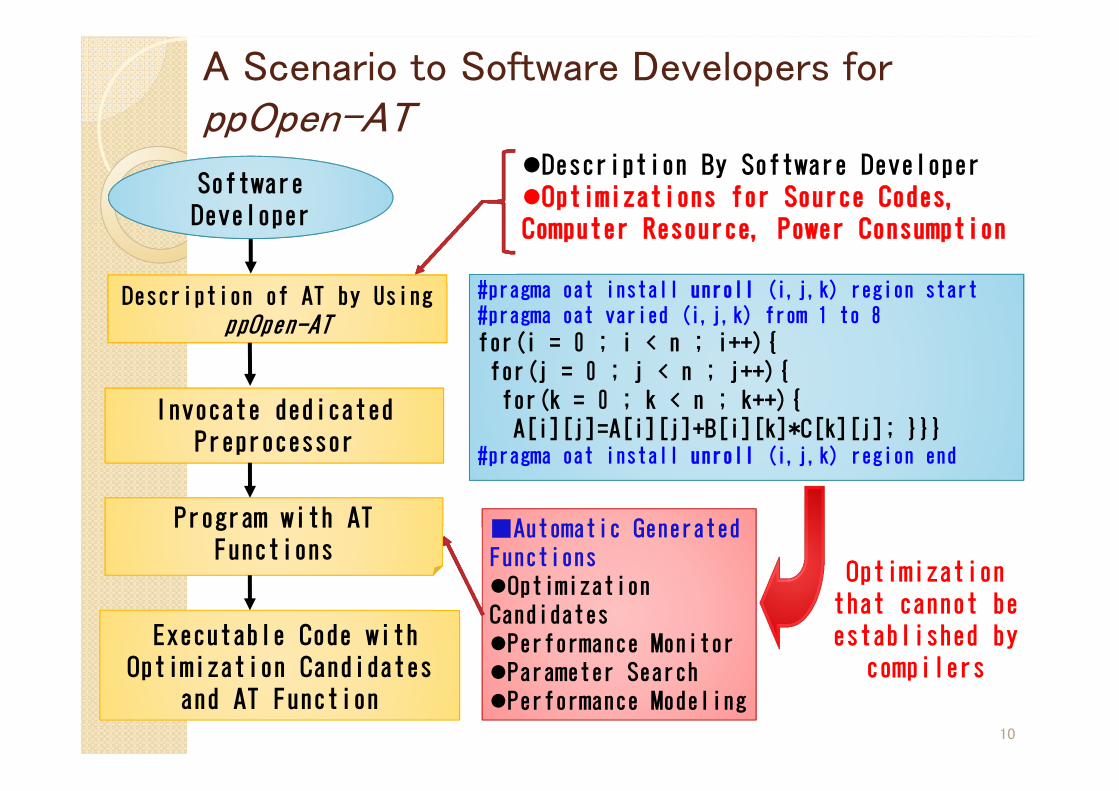
A Scenario to Software Developers for ppOpen-AT
10
Executable Code with Optimization Candidates
and AT Function
Invocate dedicated Preprocessor
Software Developer
Description of AT by UsingppOpen-AT
Program with AT Functions
Optimizationthat cannot be established by
compilers
#pragma oat install unroll (i,j,k) region start#pragma oat varied (i,j,k) from 1 to 8
for(i = 0 ; i < n ; i++){for(j = 0 ; j < n ; j++){for(k = 0 ; k < n ; k++){A[i][j]=A[i][j]+B[i][k]*C[k][j]; }}}
#pragma oat install unroll (i,j,k) region end
■Automatic Generated FunctionsOptimization CandidatesPerformance MonitorParameter Search Performance Modeling
Description By Software DeveloperOptimizations for Source Codes, Computer Resource, Power Consumption

Power Optimization for Science and Technology Computations
Algorithm selection function on ppOpen‐AT. Automatic selection for implementation to minimize energy between CPU and GPU executions
according to problem sizes. Addition to AT function of ppOpen‐AT, technology for power measurement and AT numerical
infrastructures is used. This is a joint work with Suda Lab., U.Tokyo. [IEEE MCSoC‐13]
Main Board PSU
C
U
CPU
GPU card
PCI-Express
GPU power
12V 3.3V 12V
PSU:•12V power linePCI-Express bus:
•12V power line•3.3V power line
pCurrent probes
pvolatge probes
#pragma OAT call OAT_BPset("nstep")#pragma OAT install select region start#pragma OAT name SelectPhase#pragma OAT debug (pp)
#pragma OAT select sub region startat_target(mgn, nx, ny, n, dx, dy, delta, nstep, nout, 0,
calc_coef_a_w_pmobi, init, model);#pragma OAT select sub region end#pragma OAT select sub region start
at_target(mgn, nx, ny, n, dx, dy, delta, nstep, nout, 1,calc_coef_a_w_pmobi, init, model);
#pragma OAT select sub region end#pragma OAT install select region end
ppOpen‐AT Description (C Language)
Automatic Generation
P_initial(); P_start();P_stop();P_recv(&rec);P_close();
GPUExecution
GPUExecution
CPUExecution
CPUExecution
Target Codes
AT Numerical Infrastructures
API for power measuring
Power Auto‐tuner
Target Computer
Target Program+
AT Auto‐tuner
Optimizing Optimizing Energy by measuring powers

Outline• Background• ppOpen‐AT System• Target Application and Its Kernel Loop Transformation
• Performance Evaluation• Conclusion
12

Target ApplicationSeism_3D:
Simulation for seismic wave analysis.
Developed by Professor Furumura at the University of Tokyo.
◦ The code is re-constructed as ppOpen-APPL/FDM.
Finite Differential Method (FDM)
3D simulation
◦ 3D arrays are allocated.
Data type: Single Precision (real*4)
13

The Heaviest Loop(10%~20% to Total Time)
14
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K)+ (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K)+ (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QGRMAXY = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K)) RMAXZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I,J+1,K+1))SXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT) * QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT) * QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT) * QG
END DOEND DOEND DO
Flow Dependency

Loop fusion –One dimensional (a loop collapse)
15
DO KK = 1, NZ * NY * NXK = (KK-1)/(NY*NX) + 1J = mod((KK-1)/NX,NY) + 1I = mod(KK-1,NX) + 1RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRMAXY = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I,J+1,K+1))RLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QGSXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
END DO
M it L l th i h
GPU.
Merit: Loop length is huge.This is good for OpenMP thread parallelism and GPU.

Loop fusion – Two dimensional
16
DO KK = 1, NZ * NY K = (KK-1)/NY + 1J = mod(KK-1,NY) + 1DO I = 1, NX
RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRMAXY = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I,J+1,K+1))RLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QGSXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
ENDDOEND DO
Example:Merit: Loop length is huge.This is good for OpenMP thread parallelism and GPU.
This I-loop enables us an opportunity of pre-fetching

Loop Split with Re-Computation
17
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QG
ENDDODO I = 1, NX
STMP1 = 1.0/RIG(I,J,K)STMP2 = 1.0/RIG(I+1,J,K)STMP4 = 1.0/RIG(I,J,K+1)STMP3 = STMP1 + STMP2RMAXY = 4.0/(STMP3 + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I,J+1,K+1))QG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
END DOEND DO END DO
Re-computation is needed.⇒Compilers do not apply it
without directive.

Perfect Split: Two 3-nested Loops
18
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QG
ENDDO; ENDDO; ENDDO
DO K = 1, NZDO J = 1, NYDO I = 1, NX
STMP1 = 1.0/RIG(I,J,K)STMP2 = 1.0/RIG(I+1,J,K)STMP4 = 1.0/RIG(I,J,K+1)STMP3 = STMP1 + STMP2RMAXY = 4.0/(STMP3 + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I,J+1,K+1))QG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
END DO; END DO; END DO;
Perfect Splitting

New ppOpen-AT Directives- Loop Split & Fusion with data-flow dependence
19
!oat$ install LoopFusionSplit region start!$omp parallel do private(k,j,i,STMP1,STMP2,STMP3,STMP4,RL,RM,RM2,RMAXY,RMAXZ,RMAYZ,RLTHETA,QG)
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K); RM = RIG (I,J,K); RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RL
!oat$ SplitPointCopyDef region start QG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)
!oat$ SplitPointCopyDef region endSXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QG
!oat$ SplitPoint (K, J, I)STMP1 = 1.0/RIG(I,J,K); STMP2 = 1.0/RIG(I+1,J,K); STMP4 = 1.0/RIG(I,J,K+1)STMP3 = STMP1 + STMP2RMAXY = 4.0/(STMP3 + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I,J+1,K+1))
!oat$ SplitPointCopyInsertSXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
END DO; END DO; END DO!$omp end parallel do!oat$ install LoopFusionSplit region end
Re-calculation is defined in here.
Using the re-calculation is defined in here.
Loop Split Point

Automatic Generated Codes for the kernel 1ppohFDM_update_stress #1 [Baseline]: Original 3-nested Loop
#2 [Split]: Loop Splitting with K-loop (Separated, two 3-nested loops)
#3 [Split]: Loop Splitting with J-loop
#4 [Split]: Loop Splitting with I-loop
#5 [Split&Fusion]: Loop Fusion to #1 for K and J-loops (2-nested loop)
#6 [Split&Fusion]: Loop Fusion to #2 for K and J-Loops(2-nested loop)
#7 [Fusion]: Loop Fusion to #1(loop collapse)
#8 [Split&Fusion]: Loop Fusion to #2(loop collapse, two one-nest loop)

Outline• Background• ppOpen‐AT System• Target Application and Its Kernel Loop Transformation
• Performance Evaluation• Conclusion
21

An Example of Seism_3D Simulation West part earthquake in Tottori prefecture in Japan
at year 2000. ([1], pp.14) The region of 820km x 410km x 128 km is discretized with 0.4km.
NX x NY x NZ = 2050 x 1025 x 320 ≒ 6.4 : 3.2 : 1.
[1] T. Furumura, “Large-scale Parallel FDM Simulation for Seismic Waves and Strong Shaking”, Supercomputing News, Information Technology Center, The University of Tokyo, Vol.11, Special Edition 1, 2009. In Japanese.
Figure : Seismic wave translations in west part earthquake in Tottori prefecture in Japan. (a) Measured waves; (b) Simulation results; (Reference : [1] in pp.13)

Problem Sizes (Tottori Prefecture Earthquake) 8 Nodes(8MPI Processes, Minimum running condition of
ppOpen‐APPL/FDM with respect to 32GB/node)Value of NZ Problem Sizes
(NX x NY x NZ)Process Grid(Pure MPI, the FX10)
Problem Size per Core
Weak Scaling, Problem Sizes when we use whole nodes of the FX10(65,536 Cores、Pure MPI Process Grid: 64 x 64 x 16)
10 64 x 32 x 10 8 x 8 x 2 8 x 4 x 5 512 x 256 x 80
20 128 x 64 x 20 8 x 8 x 2 16 x 8 x 10 1024 x 512 x 160
40 256 x 128 x 40 8 x 8 x 2 32 x 16 x 20 2048 x 1024 x 320
80 512 x 256 x 80 8 x 8 x 2 64 x 32 x 40 4096 x 2048 x 640
160 1024 x 512 x 160 8 x 8 x 2 128 x 64 x 80 8192 x 4096 x 1280
320 (Maximum Size for 32GB /node)
2048 x 1024 x 320 8 x 8 x 2 256 x 128 x 160 16384 x 8192 x 2560
Same as size as Tottori’s Earthquake Simulation

With AT(Speedups to the case without AT)
Pure MPITypes of hybrid MPI‐OpenMP Execution
2.5
AT Effect for Hybrid OpenMP‐MPI
Original without AT
Pure MPI
Speedup to pure MPI Execution
Types of hybrid MPI‐OpenMP Execution
The FX10, Kernel: update_stress
1
No merit for Hybrid MPI‐OpenMPI Executions. 1
Effect on pure MPI Execution
Gain by using MPI‐OpenMPI Executions.
By adapting loop transformation from the AT, we obtained: Maximum 1.5x speedup to pure MPI (without Thread execution) Maximum 2.5x speedup to pure MPI in hybrid MPI‐OpenMP execution.
PXTY :X Processes, Y Threads / Process

OTHER KERNEL AND CODE OPTIMIZATION

Kernel update_vel (ppOpen‐APPL/FDM)• m_velocity.f90(ppohFDM_update_vel)!OAT$ install LoopFusion region start!OAT$ name ppohFDMupdate_vel!OAT$ debug (pp)!$omp parallel do private(k,j,i,ROX,ROY,ROZ)do k = NZ00, NZ01do j = NY00, NY01do i = NX00, NX01
!OAT$ RotationOrder sub region startROX = 2.0_PN/( DEN(I,J,K) + DEN(I+1,J,K) )ROY = 2.0_PN/( DEN(I,J,K) + DEN(I,J+1,K) )ROZ = 2.0_PN/( DEN(I,J,K) + DEN(I,J,K+1) )
!OAT$ RotationOrder sub region end!OAT$ RotationOrder sub region start
VX(I,J,K) = VX(I,J,K) + ( DXSXX(I,J,K)+DYSXY(I,J,K)+DZSXZ(I,J,K) )*ROX*DTVY(I,J,K) = VY(I,J,K) + ( DXSXY(I,J,K)+DYSYY(I,J,K)+DZSYZ(I,J,K) )*ROY*DTVZ(I,J,K) = VZ(I,J,K) + ( DXSXZ(I,J,K)+DYSYZ(I,J,K)+DZSZZ(I,J,K) )*ROZ*DT
!OAT$ RotationOrder sub region endend do; end do; end do
!$omp end parallel do!OAT$ install LoopFusion region end

Reorder of sentences!OAT$ RotationOrder sub region start
Sentence iSentence ii
!OAT$ RotationOrder sub region endSentences 1
!OAT$ RotationOrder sub region startSentence ISentence II
!OAT$ RotationOrder sub region end
Sentence 1Sentence iSentence ISentence iiSentence II
Automatic Code Generation

Related Work (AT Languages)
#1: Method for supporting multi-computer environments. #2: Obtaining loop length in run-time.#3: Loop split with increase of computations, and loop fusion to the split loop.#4: Re-ordering of inner-loop sentences. #5: Algorithm selection.#6: Code generation with execution feedback. #7: Software requirement.
AT Language / Items
#1
#2
#3
#4
#5
#6
#7
ppOpen‐AT OATDirectives
✔ ✔ ✔ ✔ None
Vendor Compilers Out of Target Limited ‐Transformation
Recipes Recipe
Descriptions✔ ✔ ChiLL
POET XformDescription
✔ ✔ POET translator, ROSE
X language XlangPragmas
✔ ✔ X Translation,‘C and tcc
SPL SPL Expressions ✔ ✔ ✔ A Script Language
ADAPT
ADAPT Language
✔ ✔ PolarisCompiler
Infrastructure, Remote Procedure
Call (RPC)
Atune‐IL atunePragmas
✔ A Monitoring Daemon

Outline• Background• ppOpen‐AT System• Target Application and Its Kernel Loop Transformation
• Performance Evaluation• Conclusion
31

ConclusionKernel loop transformation is
a key technology to establish high performance for current multi-core and many-core processors.
Utilizing run-time information for problem sizes (loop length) and the number of threads is important.
Minimum software stack for auto-tuning facility is required for supercomputers in operation.
32

ppOpen-AT is free software!
ppOpen-AT version 0.2 is now available!
The licensing is MIT.
Or, please access the following page:
http://ppopenhpc.cc.u-tokyo.ac.jp/
33