ppopen-at : yet another directive-base at language
TRANSCRIPT

ppOpen-AT : Yet Another Directive-base AT
Language
Takahiro Katagiri, Supercomputing Research Division,
Information Technology Center,
The University of Tokyo
1
29. September bis 4. Oktober 2013, Dagstuhl Seminar 13401Automatic Application Tuning for HPC ArchitecturesSession: infrastructures, 10:30-11:00, October 1st (TUE) , 2013.
Collaborators:Satoshi Ohshima, Masaharu Matsumoto (Information Technology Center, The University of Tokyo)

QUESTIONS FOR
AT ON SUPERCOMPUTER
IN OPERATION
6

Performance Portability (PP)
7
Keeping high performance in multiple computer environments.
◦ Not only multiple CPUs, but also multiple compilers.
◦ Run-time information, such as loop length and number of threads, is important.
Auto-tuning (AT) is one of candidates technologies to establish PP in multiple computer environments.

Questions Are open AT infrastructures, including numerical
libraries with AT, available for supercomputers in operation?
We should consider with:
◦ Is run-time code generator of AT available for login-nodes with low-overheads, and available for dedicated batch-job systems? Need to take care about different venders, such as Fujitsu, NEC,
Hitachi, Cray, etc..
◦ Are required software-stacks available for the systems? Scripting languages, such as python, perl, etc.
In some Japanese supercomputers, very limited script languages are supported.
Dedicated compiler, such as CAPS, etc.8

Questions (Cont’d)
We should consider with:
◦ Do AT systems require special daemons or OS kernel modifications?
Additional daemons are not permitted to prevent high-loads of login-nodes in supercomputer.
OS kernel modification is not permitted to keep support contract by venders.
It is more desirable that all executions for AT perform in user level.
9

RELATED PROJECT
10

ppOpen-HPC (1/3)• Open Source Infrastructure for development and
execution of large-scale scientific applications on post-peta-scale supercomputers with automatic tuning (AT) • “pp” : post-peta-scale
• Five-year project (FY.2011-2015) (since April 2011) • P.I.: Kengo Nakajima (ITC, The University of Tokyo)• Part of “Development of System Software Technologies for
Post-Peta Scale High Performance Computing” funded by JST/CREST (Japan Science and Technology Agency, Core Research for Evolutional Science and Technology)
• 4.5 M$ for 5 yr.• Team with 6 institutes, >30 people (5 PDs) from
various fields: Co-Desigin• ITC/U.Tokyo, AORI/U.Tokyo, ERI/U.Tokyo, FS/U.Tokyo• Kyoto U., JAMSTEC
11

ppOpen-HPC (2/3)• Source code developed on a PC with a single
processor is linked with these libraries, and generated parallel code is optimized for post-peta scale system.
• Users don’t have to worry about optimization tuning, parallelization etc.• CUDA, OpenGL etc. are hidden.• Part of MPI codes are also hidden.• OpenMP, OpenACC could be hidden
– ppOpen-HPC consists of various types of optimized libraries, which covers various types of procedures for scientific computations. • FEM, FDM, FVM, BEM, DEM
12OPL@SC12

ppOpen-HPC covers …13

PPOPEN-ATBASICS
19
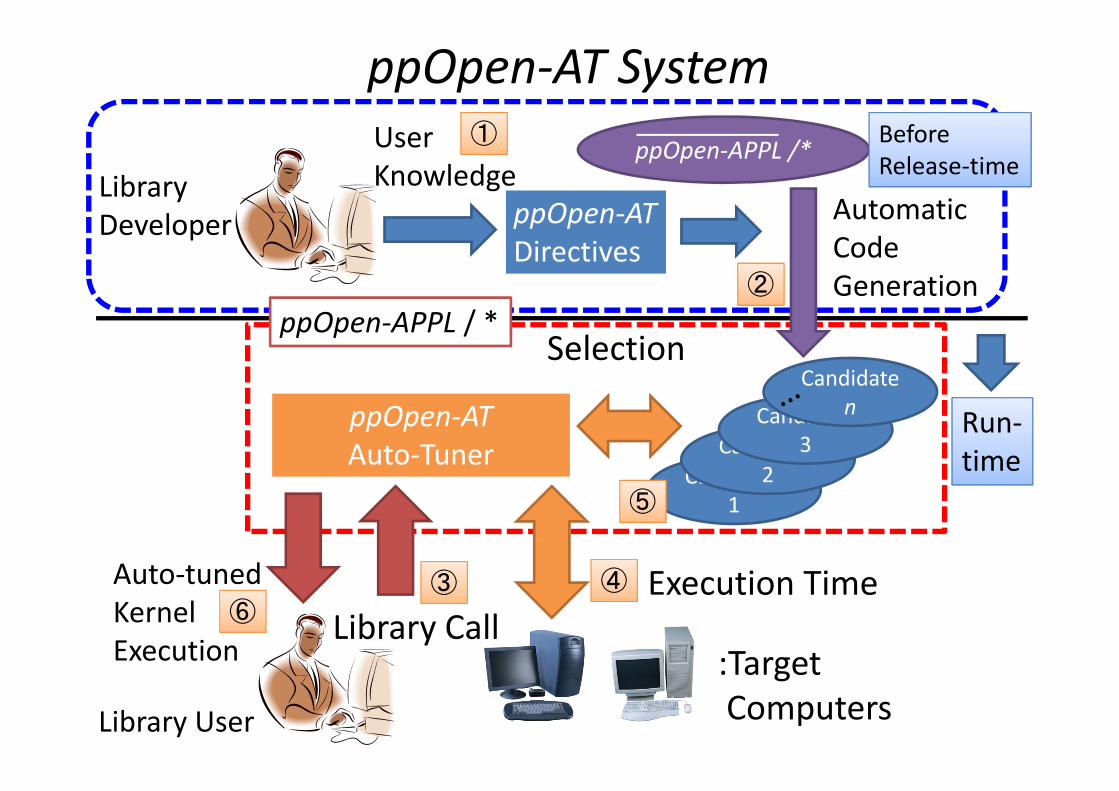
ppOpen‐AT SystemppOpen‐APPL /*
ppOpen‐ATDirectives
User KnowledgeLibrary
Developer
① Before Release‐time
Candidate1
Candidate2
Candidate3
CandidatenppOpen‐AT
Auto‐Tuner
ppOpen‐APPL / *
AutomaticCodeGeneration②
:Target Computers
Execution Time④
Library User
③
Library Call
Selection
⑤
⑥
Auto‐tunedKernelExecution
Run‐time

EARLY EXPERIENCE IN
EXPLICIT METHOD
(FINITE DIFFERENCE
METHOD)
24

Target ApplicationSeism_3D:
Simulation for seismic wave analysis.
Developed by Professor Furumura at the University of Tokyo.
◦ The code is re-constructed as ppOpen-APPL/FDM.
Finite Differential Method (FDM)
3D simulation
◦ 3D arrays are allocated.
Data type: Single Precision (real*4)
25

An Example of Seism_3D Simulation West part earthquake in Tottori prefecture in Japan
at year 2000. ([1], pp.14) The region of 820km x 410km x 128 km is discretized with 0.4km.
NX x NY x NZ = 2050 x 1025 x 320 ≒ 6.4 : 3.2 : 1.
[1] T. Furumura, “Large-scale Parallel FDM Simulation for Seismic Waves and Strong Shaking”, Supercomputing News, Information Technology Center, The University of Tokyo, Vol.11, Special Edition 1, 2009. In Japanese.
Figure : Seismic wave translations in west part earthquake in Tottori prefecture in Japan. (a) Measured waves; (b) Simulation results; (Reference : [1] in pp.13)

The Heaviest Loop(10%~20% to Total Time)
27
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K)RM = RIG (I,J,K)RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RLQG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)SXX (I,J,K) = ( SXX (I,J,K)+ (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K)+ (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QGRMAXY = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K)) RMAXZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I+1,J,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(1.0/RIG(I,J,K) + 1.0/RIG(I,J+1,K) + 1.0/RIG(I,J,K+1) + 1.0/RIG(I,J+1,K+1))SXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT) * QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT) * QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT) * QG
END DOEND DOEND DO
Flow Dependencies

New ppOpen-AT Directives- Loop Split & Fusion with data-flow dependence
33
!oat$ install LoopFusionSplit region start!$omp parallel do private(k,j,i,STMP1,STMP2,STMP3,STMP4,RL,RM,RM2,RMAXY,RMAXZ,RMAYZ,RLTHETA,QG)
DO K = 1, NZDO J = 1, NYDO I = 1, NX
RL = LAM (I,J,K); RM = RIG (I,J,K); RM2 = RM + RMRLTHETA = (DXVX(I,J,K)+DYVY(I,J,K)+DZVZ(I,J,K))*RL
!oat$ SplitPointCopyDef region start QG = ABSX(I)*ABSY(J)*ABSZ(K)*Q(I,J,K)
!oat$ SplitPointCopyDef region endSXX (I,J,K) = ( SXX (I,J,K) + (RLTHETA + RM2*DXVX(I,J,K))*DT )*QGSYY (I,J,K) = ( SYY (I,J,K) + (RLTHETA + RM2*DYVY(I,J,K))*DT )*QGSZZ (I,J,K) = ( SZZ (I,J,K) + (RLTHETA + RM2*DZVZ(I,J,K))*DT )*QG
!oat$ SplitPoint (K, J, I)STMP1 = 1.0/RIG(I,J,K); STMP2 = 1.0/RIG(I+1,J,K); STMP4 = 1.0/RIG(I,J,K+1)STMP3 = STMP1 + STMP2RMAXY = 4.0/(STMP3 + 1.0/RIG(I,J+1,K) + 1.0/RIG(I+1,J+1,K))RMAXZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I+1,J,K+1))RMAYZ = 4.0/(STMP3 + STMP4 + 1.0/RIG(I,J+1,K+1))
!oat$ SplitPointCopyInsertSXY (I,J,K) = ( SXY (I,J,K) + (RMAXY*(DXVY(I,J,K)+DYVX(I,J,K)))*DT )*QGSXZ (I,J,K) = ( SXZ (I,J,K) + (RMAXZ*(DXVZ(I,J,K)+DZVX(I,J,K)))*DT )*QGSYZ (I,J,K) = ( SYZ (I,J,K) + (RMAYZ*(DYVZ(I,J,K)+DZVY(I,J,K)))*DT )*QG
END DO; END DO; END DO!$omp end parallel do!oat$ install LoopFusionSplit region end
Re-calculation is defined in here.
Using the re-calculation is defined in here.
Loop Split Point

Candidates of Auto-generated Codes
#1 [Baseline]: Original 3-nested Loop
#2 [Split]: Loop Splitting with I-loop
#3 [Split]: Loop Splitting with J-loop
#4 [Split]: Loop Splitting with K-loop(Separated, two 3-nested loops)
#5 [Split&Fusion]: Loop Fusion with #2(2-nested loop)
#6 [Fusion]: Loop Fusion with #1(loop collapse)
#7 [Fusion]: Loop Fusion with #1(2-nested loop) 34

Overview
1. Background and ppOpen-HPC Project
2. ppOpen-AT Basics
3. Adaptation to an FDM Application
4. Performance Evaluation
5. Conclusion
35

PERFORMANCE EVALUATION
WITH
PPOPEN-APPL/FDM
IN ALPHA VERSION
36
Takahiro Katagiri, Satoshi Ito, Satoshi Ohshima, "Early Experiences for Adaptation of Auto-tuning by ppOpen-AT to an Explicit Method”Special Session: Auto-Tuning for Multicore and GPU (ATMG) (In Conjunction with the IEEE MCSoC-13), National Institute of Informatics, Tokyo, Japan, September 26-28, 2013

Test Environments 1. FX10 (The Fujitsu PRIMEHPC FX10)
◦ SPARC64 IXfx(1.848 GHz), 16 Cores, Maximum 16 Threads.
◦ Fujitsu Fortran Compiler, Version 1.2.1.
◦ Option:-Kfast, -openmp.
2. T2K (The AMD Quad-core Opteron (Barcelona))
◦ AMD Opteron 8356 (2.3 GHz),16 Cores (4 Sockets),Maximum 16 Threads
◦ Intel Fortran Compiler, Version 11.0.
◦ Option:-fast openmp -mcmodel=medium.
3. Sandy Bridge (Intel Sandy Bridge)
◦ Xeon E5 (Sandy Bridge E5-2687W),(8 Physical Cores, 16 Threads) (3.1 GHz),(Turbo boost off),32 Cores (2 Sockets),Maximum 32 Threads.
◦ Intel Fortran Compiler, Version 12.1.
◦ Option:-fast –openmp -mcmodel=medium.
4. SR16K (HITACHI SR16000/M1)
◦ IBM Power7 (3.83 GHz),32 Cores (4 Sockets),Maximum 64 Threads (SMT)
◦ HITACHI Optimization Fortran,Version. 03-01-/B.
◦ Option: -opt=ss –omp. 37

AT Effect: Very Small and Small
0
2
4
6
8
10
1 4 8 16
#1 #2 #3 #4 #5 #6 #7
39
(A) FX10 (VERY SMALL, #REPEAT = 100,000)
#Threads
Time In Seconds
0
2
4
6
8
10
1 4 8 16
#1 #2 #3 #4 #5 #6 #7
(B)T2K (VERY SMALL, #REPEAT = 100,000)
0
0.1
0.2
0.3
0.4
0.5
1 8 16 32
#1 #2 #3 #4 #5 #6 #7
#Threads
Time In Seconds
(C)SANDY BRIDGE (SMALL, #REPEAT = 1,000)
0
0.1
0.2
0.3
0.4
0.5
1 8 32 64
#1 #2 #3 #4 #5 #6 #7
(D)SR16K (SMALL, #REPEAT = 1,000)
#2, #5 are the best.#4, #5, #7 are the best.
#2, #3, #4, #5 are the best.#2, #4, #5 are the best.
#5 and #7 were the best when the number of threads was increase.
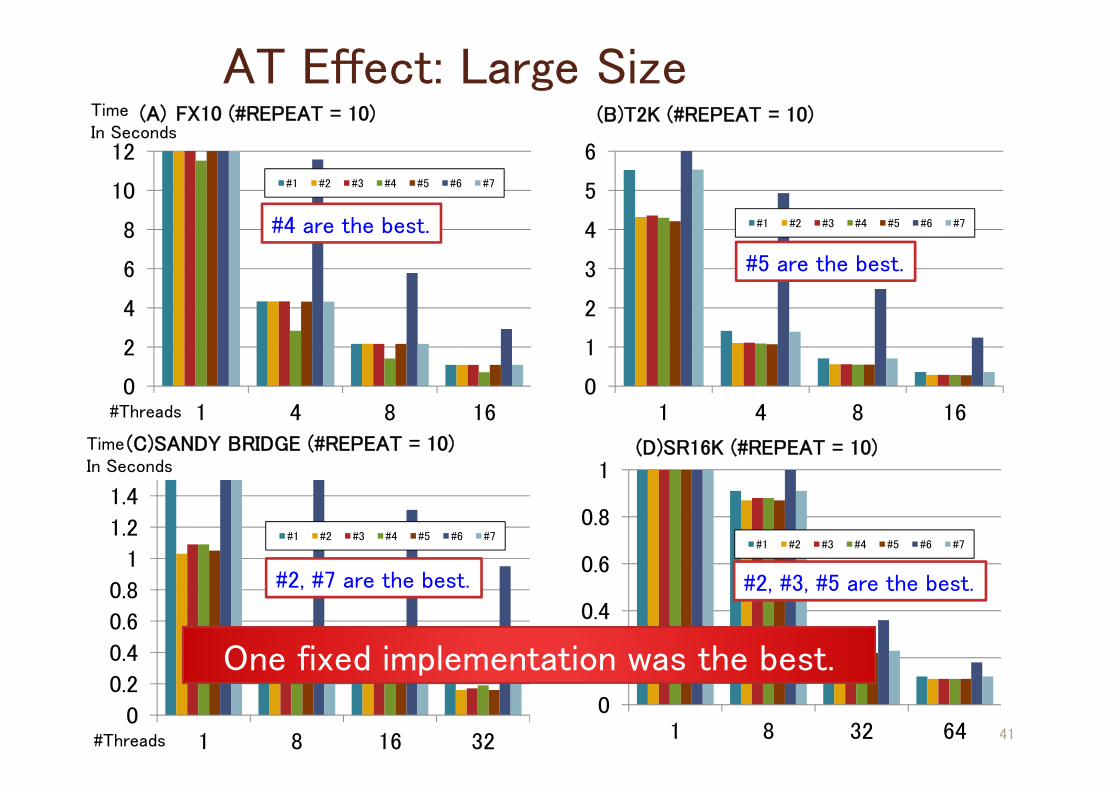
AT Effect: Large Size
0
2
4
6
8
10
12
1 4 8 16
#1 #2 #3 #4 #5 #6 #7
41
(A) FX10 (#REPEAT = 10)
#Threads
Time In Seconds
0
1
2
3
4
5
6
1 4 8 16
#1 #2 #3 #4 #5 #6 #7
(B)T2K (#REPEAT = 10)
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 8 16 32
#1 #2 #3 #4 #5 #6 #7
#Threads
Time In Seconds
(C)SANDY BRIDGE (#REPEAT = 10)
0
0.2
0.4
0.6
0.8
1
1 8 32 64
#1 #2 #3 #4 #5 #6 #7
(D)SR16K (#REPEAT = 10)
#2, #3, #5 are the best.#2, #7 are the best.
#5 are the best.
#4 are the best.
One fixed implementation was the best.

With AT(Speedups to the case without AT)
Pure MPITypes of hybrid MPI‐OpenMP Execution
2.5
AT Effect for Hybrid OpenMP‐MPI
Original without AT
Pure MPI
Speedup to pure MPI Execution
Types of hybrid MPI‐OpenMP Execution
The FX10, Kernel: update_stress
1
No merit for Hybrid MPI‐OpenMPI Executions. 1
Effect on pure MPI Execution
Gain by using MPI‐OpenMPI Executions.
By adapting loop transformation from the AT, we obtained: Maximum 1.5x speedup to pure MPI (without Thread execution) Maximum 2.5x speedup to pure MPI in hybrid MPI‐OpenMP execution.
PXTY :X Processes, Y Threads / Process

ANSWER ANDPLANS FOR THE FUTURE
50

Current Answers to AT systems
Minimum software-stack requirement is important to use AT facility in supercomputers in operation.
Since we have no standardization for AT functions, efforts for AT with full user-level execution are required.
51

Future Direction The standardization of AT functions for
supercomputers is important future direction, such as:◦ Performance monitors.◦ Code generators, esp. dynamic code generators.◦ Job schedulers, such as batch-job systems.◦ Compiler optimizations including directives and compiler
options.◦ Defining AT targets, such as execution speed, memory
amounts, or power consumption, etc.. ◦ etc.
Making standardization strategy for AT functionswith venders is important.◦ Message Passing Interface (MPI) standardization in MPI
Forum is one of success examples for the standardization. ◦ Why not make standardization and forum for AT? 52