imc summit 2016 innovation - derek nelson - pipelinedb: the streaming-sql database
TRANSCRIPT

PipelineDBThe Streaming SQL Database
Derek Nelson

What is PipelineDB?
● Relational database

What is PipelineDB?
● Relational database
● Runs SQL queries continuously on streams, incrementally storing results in tables

What is PipelineDB?
● Relational database
● Runs SQL queries continuously on streams, incrementally storing results in tables
● Seamlessly integrates streaming computation and relational storage

PipelineDB primitives
● Continuous view: stores incrementally updating continuous query results

PipelineDB primitives
● Continuous view: stores incrementally updating continuous query results
● Continuous transform: applies a transformation to an event and writes the result to another stream

PipelineDB primitives
● Continuous view: stores incrementally updating continuous query results
● Continuous transform: applies a transformation to an event and writes the result to another stream
● Continuous trigger: fires whenever some condition is true within a continuous view

Why did we build PipelineDB?
● Data-processing demands are outpacing hardware innovation (disks)

Why did we build PipelineDB?
● Data-processing demands are outpacing hardware innovation (disks)
● Storing critical data in main memory is an obvious workaround for the disk bottleneck

Why did we build PipelineDB?
● Data-processing demands are outpacing hardware innovation (disks)
● Storing critical data in main memory is an obvious workaround for the disk bottleneck
● For a vast set of use cases, we can actually do better

Critical observations:
● If fast query results are required, then the query itself is often already known
○ Especially if consumers are other applications

Critical observations:
● If fast query results are required, then the query itself is often already known
○ Especially if consumers are other applications
● If the query is known in advance, we can efficiently compute the result continuously as new data arrives

Critical observations:
● If fast query results are required, then the query itself is often already known
○ Especially if consumers are other applications
● If the query is known in advance, we can efficiently compute the result continuously as new data arrives
● No need to store granular data after results are incrementally updated

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databasesStore Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
SELECT COUNT(*) FROM table
= ?
Store Query

Traditional databases
✓
SELECT COUNT(*) FROM table
= 16
Store Query

The Continuous Query
Query
Store
THEN

The Continuous Query
SELECT COUNT(*) FROM stream
= ?

The Continuous Query
SELECT COUNT(*) FROM stream
= 1 ✓
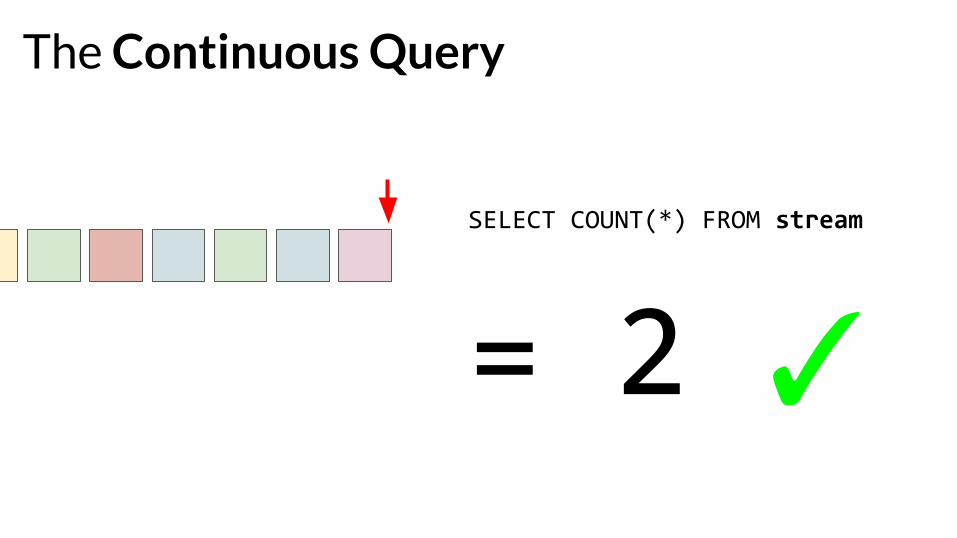
The Continuous Query
SELECT COUNT(*) FROM stream
= 2 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 3 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 4 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 5 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 6 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 7 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 8 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 9 ✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 10✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 11✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 12✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 13✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 14✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 15✓

The Continuous Query
SELECT COUNT(*) FROM stream
= 16✓

Example Topology
Kafka

Example Topology
SELECT * FROM kafka_topicJOIN table t USING (x)THEN INSERT INTO stream
TransformKafka

Example Topology
SELECT * FROM kafka_topicJOIN table t USING (x)THEN INSERT INTO stream
Transform
Continuous View
SELECT x, AVG(value)FROM stream GROUP BY x
Kafka

Example Topology
SELECT * FROM kafka_topicJOIN table t USING (x)THEN INSERT INTO stream
Transform
Continuous View
SELECT x, AVG(value)FROM stream GROUP BY x
WHEN OLD.avg < 10 AND NEW.avg > 10THEN EXECUTE PROCEDURE post_alarm(‘pipelinedb.com/alert’)
Continuous Trigger
Kafka

Example Topology
SELECT * FROM kafka_topicJOIN table t USING (x)THEN INSERT INTO stream
Transform
Continuous View
SELECT x, AVG(value)FROM stream GROUP BY x
SQL clients SELECT from continuous views for realtime results
WHEN OLD.avg < 10 AND NEW.avg > 10THEN EXECUTE PROCEDURE post_alarm(‘pipelinedb.com/alert’)
Continuous Trigger
Kafka
x AVG
a 1.442
b 7.55

Benefits of continuous SQL
● Streaming analytics with pure SQL
○ No application code
○ Very low engineering overhead
○ Add new continuous queries with no downtime

Benefits of continuous SQL
● Sustainable infrastructure cost
○ Consumed memory / disk independent of ingested data volume

total data ingested
database size
CREATE CONTINUOUS VIEW v AS SELECT COUNT(*) FROM stream
Benefits of continuous SQL
● Sustainable infrastructure cost
○ Consumed memory / disk independent of ingested data volume

Benefits of continuous SQL
● Realtime push becomes possible (no polling)
○ Incremental updates mean we can trigger any functionality the moment something interesting happens

Benefits of continuous SQL
● Realtime push becomes possible (no polling)
○ Incremental updates mean we can trigger any functionality the moment something interesting happens
CREATE TRIGGER trig ON cont_viewWHEN some_condition(new.value)THEN http_post(‘pipelinedb.com/alarm’)

Benefits of continuous SQL
● Works with all existing standard SQL clients

Benefits of continuous SQL
● Works with all existing standard SQL clients

Thank you!
PipelineDB