huffman assignment intro · huffman assignment intro james wei professor peck april 2, 2014 slides...
TRANSCRIPT

Huffman Assignment Intro
James Wei Professor Peck April 2, 2014
Slides by James Wei

Outline • Intro to Huffman • The Huffman algorithm • Classes of Huffman • Understanding the design • Implementation • Analysis • Grading • Wrap-up

Intro to Huffman • Huffman is a compression algorithm • Works by examining characters in a file—
those appearing more frequently are replaced with shortcuts and those appearing less frequently with “longcuts”
• We can then rewrite a file with different bit encodings for each character, such that the overall length is shorter
• Of course, must also store the bit mappings

Intro to Huffman • You will be writing code to do the following: • Read a file and count the number of appearances
of every character • Create a Huffman tree/encodings from the counts • Write a header that contains the Huffman tree
data to the compressed file • Write a compressed file • Read the header to recreate the Huffman tree • Uncompress a file

Intro to Huffman • A few definitions before we proceed: • Bit – a 0 or 1; you will be reading individual bits
using the provided utility classes • Character – a chunk of 8bits which we will store in
an int; do not use the byte data type in this assignment; sometimes referred to as a word
• Huffman encoding – the sequence of bits that a character is mapped to and will be replaced with in the compressed file
• PSEUDO_EOF – a character that indicates the end of file (EOF), must be written to the compressed file and read when uncompressing
• Magic number – a special character indicating that a file is a Huffman compressed file

Intro to Huffman • A brief note on bits: • You will be working with individual bits here • We will consider a chunk of 8 bits to be a
character, which could be a letter, number, whitespace, or symbol
• The 8 bits can represent any number from 0-255; these numbers correspond with an ASCII encoding (see: http://www.asciitable.com/)
• We will represent a character using its 8 bits stored in an int, which gives us a value of 0-255 that corresponds with an ASCII code

Intro to Huffman • A brief note on bits: • For example, if we take the letter ‘A’ • ‘A’ has an ASCII code of 65 • In binary, 65 == 0100 0001 • When we read n bits, we consider those bits to be
binary for some number, which is stored in an int • So if the character in my file is ‘A’, and we read
in 8 bits, we will get an int equally 65 (more on this later)
• When we write, we will write *one* bit at a time

The Huffman Algorithm • The algorithm rewrites bit encodings so that
frequently used characters can be written in fewer bits
• For example, if I have a file that reads: “gggg”
• Then my bit representation of this is: 01100111 01100111 01100111 01100111
• I create a shortcut: “g” => 1
• And my new file is much shorter! “gggg” => 1111

The Huffman Algorithm • How do we create encodings that do not
conflict with each other? • Create a Huffman tree! • Overview of the process: • Count the number of appearances for every
character in the file • Arrange the characters as leaf nodes in a tree,
with the least frequent furthest from the root • Create the encoding for each character by tracing
a path to its node from the root

The Huffman Algorithm • Count the number of appearances for every
character in the file. • Pretty straightforward… • For this example we’ll use these counts:
Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5

The Huffman Algorithm • Arrange the characters as leaf nodes in a tree,
with the least frequent furthest from the root • Start by picking lowest two counts—join them
together as sibling nodes • Next, create a parent node for the two, and
weight the parent as the combined weights of its children
• Add the parent node to the pool of nodes to choose from, then repeat until there is only one node left—that’s the root

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
The Huffman Algorithm
G (5) C (9)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
G/C 14
The Huffman Algorithm
G (5) C (9)
(14)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
G/C 14
The Huffman Algorithm
G (5) C (9)
(14) F (11) B (14)
(25)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
G/C 14
F/B 25
The Huffman Algorithm
G (5) C (9)
(14) F (11) B (14)
(25)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
G/C 14
F/B 25
14/D 31
The Huffman Algorithm
G (5) C (9)
(14)
F (11) B (14)
(25) D (17)
(31)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
F/B 25
14/D 31
25/A 54
The Huffman Algorithm
G (5) C (9)
(14)
F (11) B (14)
(25) D (17)
(31)
A (29)
(54)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
14/D 31
25/A 54
31/E 76
The Huffman Algorithm
G (5) C (9)
(14)
F (11) B (14)
(25) D (17)
(31)
A (29)
(54) E (45)
(76)

Character Count
A 29
B 14
C 9
D 17
E 45
F 11
G 5
25/A 54
31/E 76
54/76 130
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

The Huffman Algorithm • Create the encoding for each character by
tracing a path to its node from the root • Starting from the root, trace the path to each leaf • Every time you go left, append a 0, right, a 1 • The result at each leaf is its Huffman encoding

Character Encoding
A
B
C
D
E
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

Character Encoding
A 01
B
C
D
E
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)
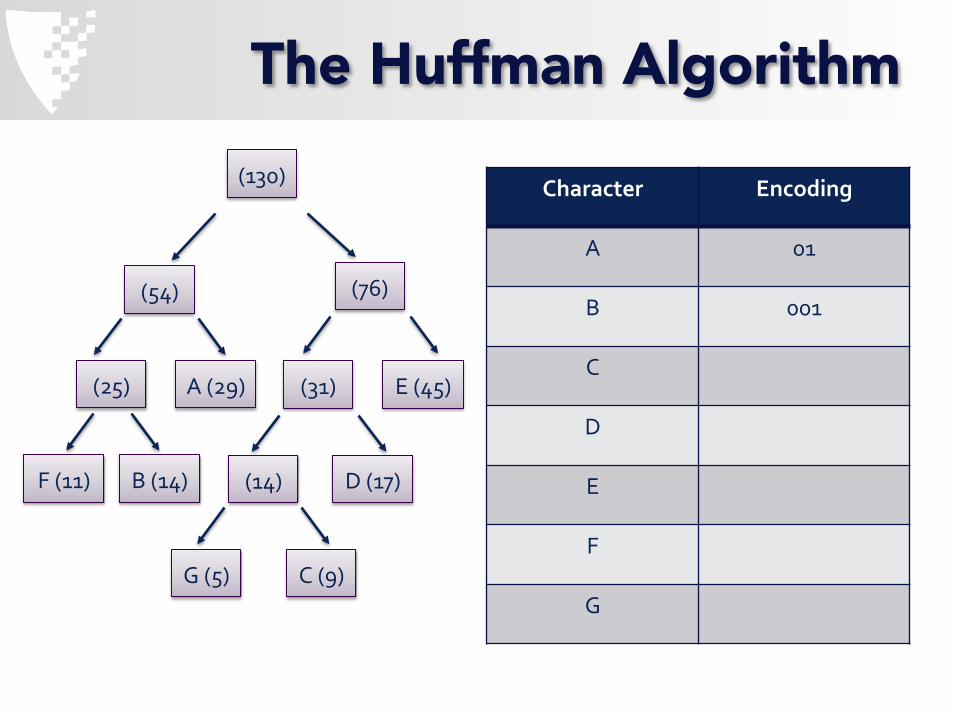
Character Encoding
A 01
B 001
C
D
E
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

Character Encoding
A 01
B 001
C 1001
D
E
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

Character Encoding
A 01
B 001
C 1001
D 101
E
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)
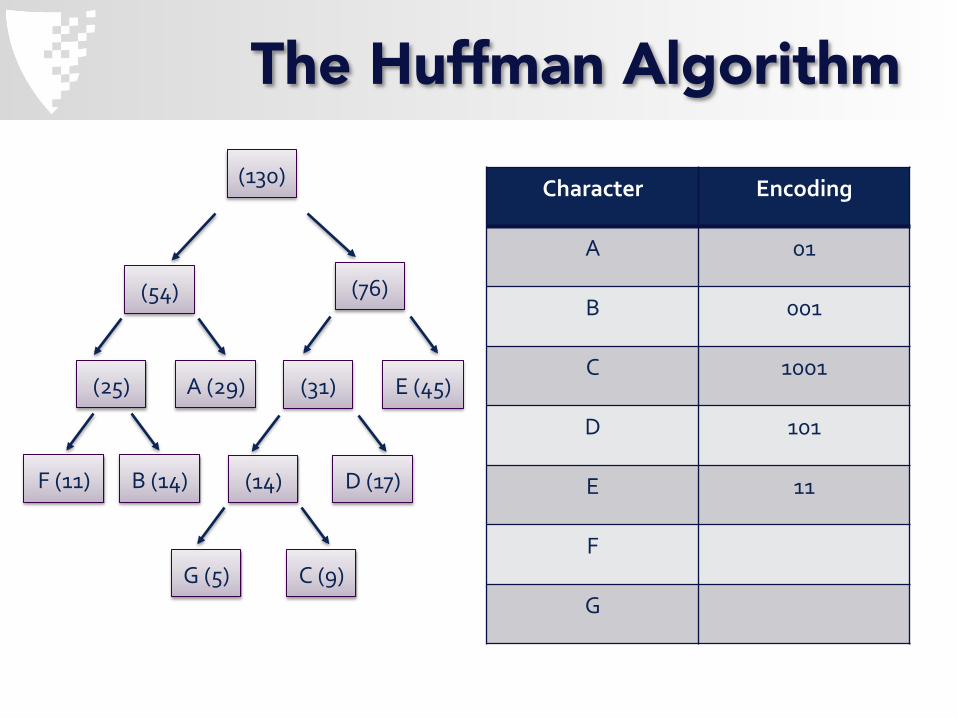
Character Encoding
A 01
B 001
C 1001
D 101
E 11
F
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)
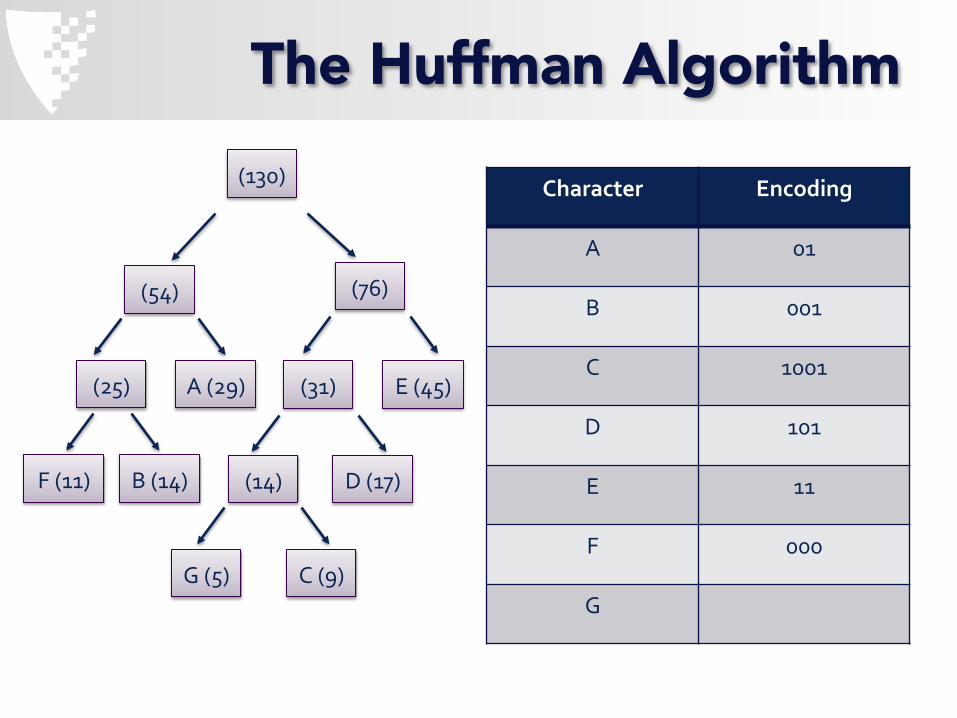
Character Encoding
A 01
B 001
C 1001
D 101
E 11
F 000
G
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

Character Encoding
A 01
B 001
C 1001
D 101
E 11
F 000
G 1000
The Huffman Algorithm
G (5) C (9)
(14) D (17)
(31) E (45)
(76)
(130)
F (11) B (14)
(25) A (29)
(54)

Classes of Huffman • The relevant classes of this assignment: • Huff: main class to run the Huffman program • SimpleHuffProcessor: what you will complete • HuffMark: benchmarking program to be used for
your analysis • IHuffConstants: contains constants that you will use
in SimpleHuffProcessor • Diff: utility tool that compares two files and returns
whether they are byte-equivalent • TreeNode: a node in the Huffman tree—implements
Comparable and compares by weight • Bit(In/Out)putStream: two classes that read and write
bit-by-bit, extends InputStream/OutputStream

Understanding the design • The only class you need to modify is
SimpleHuffProcessor, which implements IHuffProcessor
• Within this class are three methods: • preprocessCompress: to be called before a
compression—reads a file and creates Huffman encodings
• compress: uses Huffman encodings to write a compressed file
• uncompress: reads a compressed file, uses the header to build Huffman encodings, and decodes the file

Implementing preprocess • The first method we need to implement:
int preprocessCompress(InputStream) throws IOException
• This method must: • Find the weights of all characters in the file • Build a Huffman tree from the weights • Traverse the Huffman tree to determine
encodings for every character • Find and return the total number of bits saved

Implementing compress • The first method we need to implement:
int compress(InputStream, OutputStream, boolean) throws IOException
• This method must: • Check that compression actually saves bits (unless
force compression is true) • Write a magic number to the beginning of the file • Write the weight of each character to the file • Read the original file and write each character’s
Huffman encoding to the new file • Write a PSEUDO_EOF to the end of the file • Return the number of bits written to file

Implementing uncompress • The first method we need to implement:
int uncompress(InputStream, OutputStream) throws IOException
• This method must: • Check for the existence of the magic number • Read the weights from the header and rebuild the
Huffman tree • Read one bit at a time, traversing down the tree until
we hit a leaf, and write the character represented by the leaf to the file
• Return the number of bits written to file

Preprocess in detail • How do we determine character weights? • Need to use the InputStream we are given • Create a new BitInputStream using the IS as an
argument to its constructor • Create a data structure to store the weights (array,
map, your choice) • Read IHuffConstants.BITS_PER_WORD bits
using our BitInputStream readBits method; this method returns an int storing the value of the bits
• Update the weight of the returned character

Preprocess in detail • Some pseudocode to get you started: preprocessCompress(...) {
BitInputStream bis = new BIS();
int[] weights = new int[];
int current = bis.readBits(...);
while (successfully read bits) {
// update weights for current
// read next character
}
}

Preprocess in detail • How do we build the Huffman tree with code? • After counting the weights of each character,
create a TreeNode for each one • What data structure should we store our
TreeNodes in so that we can easily obtain the two with the smallest weights each iteration?
• When are we done building the tree?

Preprocess in detail • Some pseudocode to get you started:
preprocessCompress(...) { PriorityQueue<TreeNode> pq = new PQ<>(); for (every character) { pq.add(new TreeNode(character, weight)); } while (pq not empty) { if (pq only has one node) break; TreeNode left = pq.pop(); TreeNode right = pq.pop(); // create new TreeNode as parent, add to pq } // get remaining node and set as root }

Compress in detail Check for
positive bits saved
Write magic number
Write weights of each char
Attempt to read one character from file
If read successfully
Lookup encoding
Write encoding
Write PSEUDO_EOF
Return # bits written
YES
NO

Compress in detail • If you are interested in extra credit… • The header you write is simply a list of all character
weights • For extra credit, additionally write code that creates
the header from a preorder traversal of the tree, instead of weights, so that uncompress can build the tree faster.
• For full credit you need *BOTH* header implementations (but don’t write both to the compressed file!)
• You will also need to write about the differences in header implementations in your analysis to get full points for the extra credit

Uncompress in detail
Check magic number
Read weights from header
Build tree; set current to
root
Read single bit from the input stream
Move to left child
If node is leaf Move to right child
If value is PSEUDO_EOF
Return # bits written
YES
NO
Zero
One
Write value to file; set current
to root
YES
NO

BitInputStream/BitOutputStream
• Don’t need to know the inner workings of these classes—just how to use them
• BitInputStream: mainly you will use int readBits(int)
• The single argument is how many bits to read
• BitOutputStream: mainly you will use int writeBits(int, int)
• The first argument is how many bits to write • The second argument is what value to write

Analysis • It’s the last assignment—of course there’s an
analysis part! • Run HuffMark on both the calgary directory
and the waterloo directory; you may want to modify HuffMark to display more data (focus on the compress method, for the most part)
• You may also want to modify HuffMark to not skip over files with the .hf extension—you will want to compress already compressed files for your analysis!

Analysis • Once you’re comfortable with using HuffMark,
answer the following in your write-up: • Which compresses more, binary or text files? • How much additional compression do you get by
compressing an already compressed file? When does this become ineffective?
• Can you design a file that should compress a lot? When is it no longer worthwhile to keep compressing that file?
• If you did the extra credit, compare the performance and effectiveness of your two implementations

Grading • Your grade is based on: • 25% - compressing/decompressing text files • 25% - compressing/decompressing binary files • 20% - robustness, basic error handling
• Examples include not compressing if bits saved is negative (unless force compression is active), terminating if no magic number/pseudo-EOF found
• In cases where you end decompression early, do not worry if the file has already been created and is not deleted—you will not be penalized for that
• 10% - coding style and documentation • 20% - full and complete analysis

Wrap-up • Recommended plan of attack: • Read over the assignment write-up; look at the
snarf code and understand the basic flow of the program, as well as what you will be adding
• Implement preprocessCompress • Test by creating a short dummy text file and
running preprocess on it—you can check your tree for correctness by writing a brief recursive algorithm to print out its preorder traversal

Wrap-up • Recommended plan of attack: • Implement compress • Test by compressing some files and checking to
see that they have shrunk in size; try creating a file that is very short, so that the compressed file will be larger than the original—does your program detect this and abort compression? • If you open a .hf file in a text editor, you should see a
lot of gibberish • Not too much testing you can really do here without
uncompress, unfortunately

Wrap-up • Recommended plan of attack: • Implement uncompress • Test by uncompressing some .hf files from your
compress method; check the following: • Does your .unhf file match the original? Use Diff to
check that they are exactly the same. • If you try to uncompress a file that was NOT
compressed with your code, does uncompress correctly detect the missing magic number and abort?
• Comment out your code adding a pseudo-EOF to the end of the .hf file; does uncompress detect this and abort?

Good luck!
Start early!