history of speech synthesis – some · pdf filehistory of speech synthesis – some...
TRANSCRIPT

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 1
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 2
History of Speech Synthesis – Some Highlights
1. The VODER, the FIRST EVER electronic speech synthesis, demonstrated at the New York World's Fair, 1939, by Bell Laboratories.
2. The only MONOTONE SYNTHESIZER ever made! Designed to make research on speech acoustics very easy. The `Pattern Playback' contributed greatly to our understanding of speech acoustics. Haskins Laboratories, New York City, 1951
3. First song in synthetic speech, "Bicycle Built for Two" with synthetic piano. This song was reprised by Hal in `2001: A Space Odyssey'. Bell Laboratories, by Louis Gerstman and Max Mathews, 1961.
5. SPEAK-N-SPELL toy. The first mass produced high-tech speech product. The system announces words to be spelled using a simple keyboard. Popular for 3-8 year olds in the early 1980s.
6. MODERN SPEECH SYNTHESIS BY RULE. Dennis Klatt devoted many years to development of MITalk, a research system that converted ordinary printed text into intelligible speech synthesized entirely ``by rule''. The commercial version of this system, DECtalk, comes standard with several voices :
A. `Perfect Paul' --talking at about 300 words/minute
B. `Beautiful Betty'
7- Comparison of synthesis and a natural recording, automatic analysis-resynthesis using multipulse linear prediction, Bishnu Atal, 1982
http://www.cs.indiana.edu/rhythmsp/ASA/Contents.html

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 3
Homer Dudley’s VODER
• Manually controlled through complex keyboard
• Various keys and pedals used to change the :
•Pitch •Excitation source•Spectrum shape
• 1939 World’s Fair in San Francisco
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 4
Gunnar Fant’s OVE Synthesizer
Samples: How are you? I love you!
What did you say before that? ...
• Developed at the Royal Institute of Technology, Stockholm
• A Formant Synthesizer for vowels
– F1 and F2 could be controlled

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 5
Cooper’s Pattern Playback
One of the influential speech synthesizers…
“These days ... It's easy to tell ...
Four hours ...”
Franklin Cooper (1908-1999).
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 6
It works like an inverse sound spectrograph

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 7
Modern TTS systems
• 1960’s first full TTS: Umeda et al (1968)• 1970’s
– Joe Olive 1977 concatenation of linear-prediction diphones– Speak and Spell
• 1980’s– 1979 MIT MITalk (Allen, Hunnicut, Klatt)
• 1990’s-present– Diphone synthesis– Unit selection synthesis
DALLAS (June 11, 1978) - A new speech synthesis monolithic integrated circuit has been developed by Texas Instruments. It marks the first time the human vocal tract has been electronically duplicated on a single chip of silicon. Measuring 44,000 square mils, the chip is fabricated using TI's low-cost metal gate P-channel MOS process, the same used for TI calculator MOS ICs.
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 8
Principles of Speech Synthesis
• Entails the conversion of an input text into speech waveforms using– Some form of stored (coded) speech data.
– Appropriate algorithms for pronunciation, syntax rules, concatenation, ...
• Characteristics of synthesizers : – Size of speech units (phonemes, diphones, syllables, words, …).
– Methods used to code and store units (concatenation schemes).
– Synthesis methods : speech units to speech signals (articulatory, formant, waveform, ..)
– Any additional enhancements : prosody, naturalness, etc..
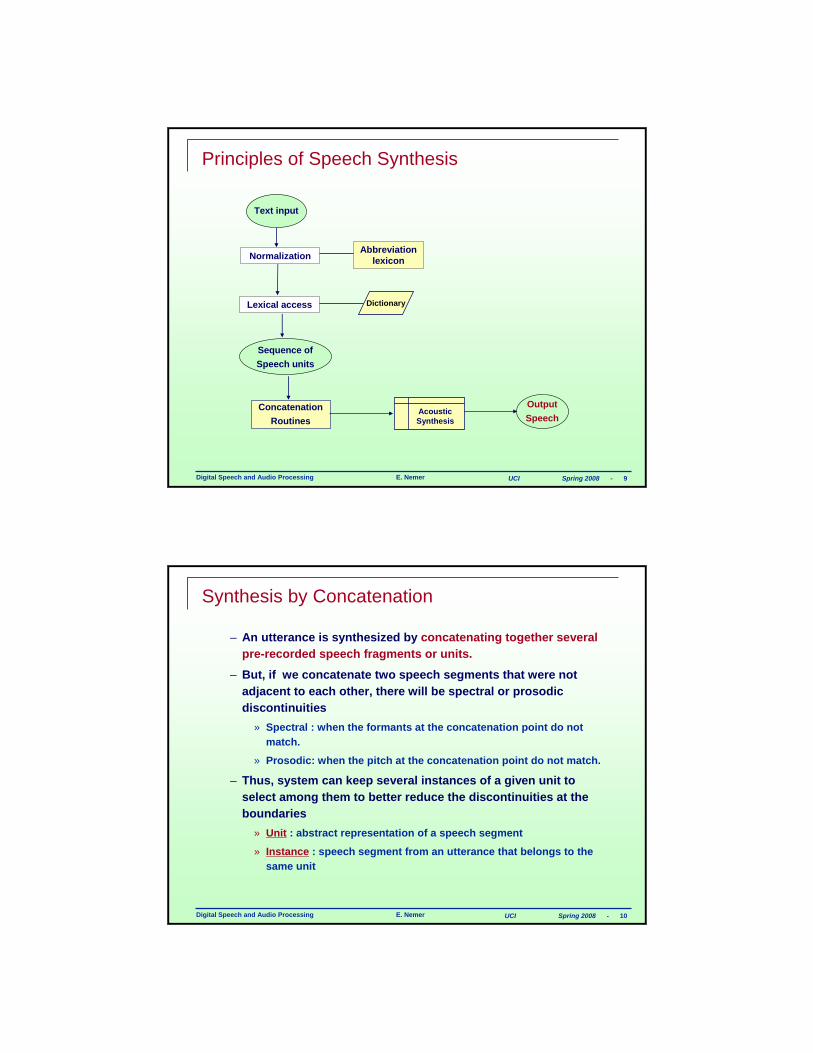
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 9
Principles of Speech Synthesis
Text input
Abbreviation lexiconNormalization
Lexical access
Sequence of Speech units
Concatenation Routines
AcousticSynthesis
Dictionary
OutputSpeech
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 10
Synthesis by Concatenation
– An utterance is synthesized by concatenating together several pre-recorded speech fragments or units.
– But, if we concatenate two speech segments that were not adjacent to each other, there will be spectral or prosodic discontinuities
» Spectral : when the formants at the concatenation point do not match.
» Prosodic: when the pitch at the concatenation point do not match.
– Thus, system can keep several instances of a given unit to select among them to better reduce the discontinuities at the boundaries
» Unit : abstract representation of a speech segment
» Instance : speech segment from an utterance that belongs to the same unit

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 11
Concatenative synthesis
• Requires database of previously recorded human speech covering allthe possible segments to be synthesised
• Segment might be phoneme, syllable, demi-syllables, diphones, word, phrase, or any combination
• For a given text, these segments are joined based on some joining rules
• Depending what type of segments are used, audible glitches because of transition between segments
• Efficient lookup and searching is necessary to locate the segments
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 12
Units to concatenate
• Choice of units– Should lead to low concatenation distortion.– Should lead to low prosodic distortion.– Should be generalizable, if unrestricted text-to-speech is needed.– Should be trainable.– Memory vs. complexity.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 13
Diphone concatenation
• What: model all phone-phone transition in a language:
– one occurrence of each– assume two-phone context is sufficient
• Why: It is important for natural sounding speech is to get the transitions right (allophonic variation, coarticulation effects)
• How: found at the boundary between phoneme segments
– “diphones” are fragments of speech signal cutting across phoneme boundaries.
– A diphone begins at the second half of a phone (stationary area) and ends at the first half of the next phone (stationary area). Thus, a diphone always contains a sound transition.
m y n u m b er
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 14
Diphone concatenation – Memory
• How many: If a language has P phones, then nb of diphones ~P2 :– 800 for Spanish– 1200 for French– 2500 for German– 1444 for English
• Compare diphones to other units for English language synthesis– If phonemes are used, then about 250 phone variants are needed.– If syllables are used, and all words included , we need 20,000 syllables, though
estimates show 4440 are sufficient, and 1370 cover 93% of the cases. – If demi-syllables are used, about 3000 are used, though a large vocabulary can
be created from 2000. A demi-syllable consists of half the vowel in a syllable and the consonant part (up to 4 consonants).
– If words are used, and all words are included, then > 300,000 are needed. It’s estimated that only 50,000 are really required and most people use only 5000.
– If morphemes are used, then about 12,000 would be needed. (morphemes are the basic elements of words, without the prefix and suffix. e.g. : ‘antidisestablishmentarianism’ = root morpheme ‘establish’ + 4 suffix and 2 prefix morphemes).
• Min set : even a small vocabulary would still require > 1000 diphones

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 15
Diphone synthesis
• Training:– Choose units (kinds of diphones)
– Record 1 speaker saying 1 example of each diphone
– Mark the boundaries of each diphones,
» cut each diphone out and create a diphone database
• Synthesizing an utterance:– grab relevant sequence of diphones from database
– Concatenate the diphones, doing slight signal processing at boundaries
» if both diphones are voiced, need to join them pitch-synchronously
– use signal processing to change the prosody (F0, energy, duration) of selected sequence of diphones
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 16
Diphone synthesis
• Pros– Well-understood, mature technology
– Manageable in number
– Can be automatically extracted from recordings of human speech
– Capture most inter-allophonic variants
– Mid-phone is more stable so easier to join
• Cons : – Diphone synthesis only captures local effects
» But there are many more global effects (syllable structure, stress pattern, word-level effects)
– Signal processing still necessary for modifying durations– Source data is still not natural– Units are just not large enough; can’t handle word-specific effects, etc
» we sometimes need triphones, or some other larger units.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 17
Signal Processing for Concatenative Synthesis
• Diphones recorded in one context must be generated in other contexts
• Features are extracted from recorded units
• Signal processing manipulates features to smooth boundaries where units are concatenated
• Signal processing modifies signal via ‘interpolation’– intonation
– duration
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 18
Unit selection synthesis
• Same idea as concatenative synthesis, but database contains bigger variety (or instances) of units.
• Multiple examples of phonemes (under different prosodic conditions) are recorded :
– Thus synthesis involves selecting the “appropriate” instances, both phonetically and prosodically.
• The selection algorithms can use different criteria:– target, concatenation cost– phonological structure matching
• In general, selecting appropriate unit is complex:– Too many competing candidates. – Un-foreseen context in unrestricted text synthesis.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 19
Synthesis in limited domains
• Unit selection can yield mixed results• Generally a problem due to open-endedness
– Unseen contexts will be synthesized poorly
• Restricting the domain provides set of known contexts– Every context to be produced can be in the recordings
• Results in better-sounding synthesis– …for the things it can say
• Examples– Weather reports– Bus information (place names)– …
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 20
Concatenation Examples
Synthesis by concatenating….– Random word/phrase concatenation
– Phone concatenation
– Diphone concatenation
– Sub-word unit selection

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 21
Unrestricted Text-to-Speech
• It is often desirable to have a general synthesizer that accepts general text and produces natural sounding speech.
• However, text-to-phoneme conversion is not straightforward– Dr Smith lives on Marine Dr in Chicago IL. He got his PhD from MIT. He
earns $70,000 p.a.
– Have Toy read that book? No I’m still reading it. I live in Reading.
• Synthesis is more than stringing phonemes; it involves merging appropriate allophones (phone variants), with coarticulation effects, as well as prosodic features (pitch, loudness, length).
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 22
Unrestricted Text-to-Speech
• A number of processing steps are required : – Text normalization
» Abbreviations, …– Letter to phone rules
» How to pronounce each phone (or unit).– Lexical exceptions and ambiguity
» Which words violate basic rules of grammar and pronunciation.– Adding prosody, based on context, and speaker
» Amplitude, F0, duration, …– Adding special ‘effects’ for naturalness– Determine how to acoustically synthesize the string of units produced.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 23
Phoneme-to-speech module
Architecture of TTS systems
Text-to-phoneme module
Text input
Letters-to-phoneme
conversion
Prosodic modelling
Acoustic synthesis
Abbreviation lexicon
Exceptions lexicon
Orthographic rules
Phoneme string
Normalization
Grammar rulesPhoneme string +
prosodic annotation
Prosodic model
Synthetic speech output
Various methods
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 24
Text Normalization
• Any text that has a special pronunciation should be stored in a lexicon– Abbreviations (Mr, Dr, Rd, St, Middx)
– Acronyms (UN but UNESCO)
– Special symbols (&, %)
– Particular conventions (£5, $5 million, 12°C)
– Numbers are especially difficult
» 1995 2001 1,995 236 3017 233 4488

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 25
Text Normalization
• Thus, we need to analyze raw text into pronounceable words
• Sample problems:– He stole $100 million from the bank
– It's 13 St. Andrews St.
– The home page is http://www.uci.edu
– yes, see you the following tues, that's 11/12/07
• Steps– Identify tokens in text– Chunk tokens into reasonably sized sections– Map tokens to words– Identify proper types for words
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 26
Letter to Phoneme (or sound)
• How to pronounce a word? Look in dictionary! But:– How about unknown words ?
– Easier for some languages (Spanish, Italian, Welsh, Czech, Korean)
– Much harder for others (English, French)
– Partially alphabetic or complex combinations of letters and signs (Arabic, Hebrew)
– Not alphabetic at all (Chinese, Japanese)
• We need “Letter-to-Sound” Rules

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 27
Letter to Phoneme (or sound)
• We also need homographic disambiguation
• Homograph disambiguation requires syntactic analysis– He makes a record of everything they record.
– I read a lot. What have you read recently?
• Analysis also essential to determine appropriate prosodic features:– What is the context : a question , an exclamation
– What word is being emphasized.
– Possible emotion of the speaker
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 28
Prosody modelling
• Pitch, length, loudness (also F0, duration, Intensity)
• Intonation (pitch, F0)– essential to avoid monotonous robot-like voice
– linked to basic syntax (eg statement vs question), but also to thematization (stress)
– Pitch range is a sensitive issue
• Rhythm (length or duration)– Has to do with pace (natural tendency to slow down at end of utterance)
– Also need to pause at appropriate place
– Linked (with pitch and loudness) to stress

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 29
• Prosody – Extends beyond phonemes to syllables, words, phrases, sentences.– Perception of rhythm, intonation, stress helps the listener understand the
speech message by cueing logical breaks in the flow of an utterance. – In addition to segmenting utterances, prosody signals that:
» A given utterance may be a question (e.g. ‘Joe has studied ?’) » A clause is main or subordinate.» The utterance is finished.
– Serves as a continuity guide in noisy environments– Cues to the state of the speaker : attitudes , emotions are signals thru
intonation. F0, amplitude patterns vary with emotions, in that their values goes up and so does their variability.
– Extremely important to speech perception : communication can still occur even with severely distorted segmentals by exploiting perceived aspects of F0, duration, and amplitude.
Importance of Prosody
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 30
Prosody modelling
PROSODY
Speaker Characteristics
•Gender•Age
Feelings• Anger• Happening• Sadness Context
• neutral• questioning• commanding
F0DurationStress

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 31
Intonation marking
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 32
Global Prosodic Features
From a presentation by Arik Nemtsov
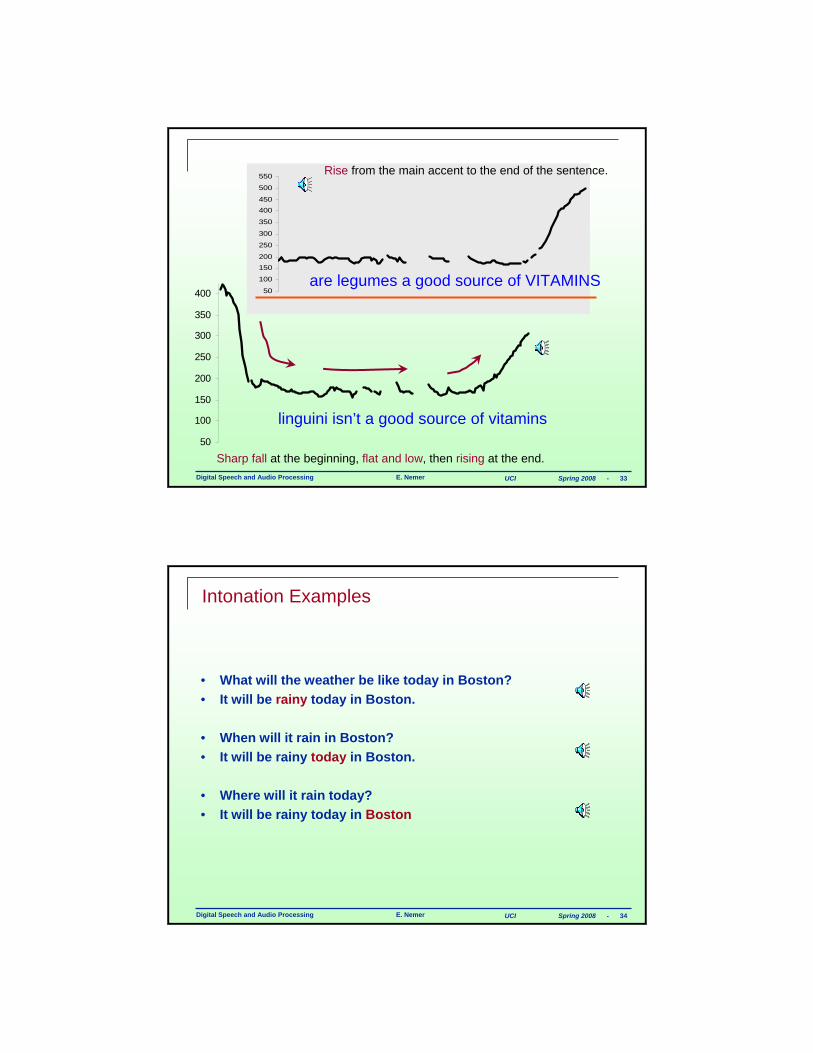
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 33
50
100
150
200
250
300
350
400
linguini isn’t a good source of vitamins
Sharp fall at the beginning, flat and low, then rising at the end.
are legumes a good source of VITAMINS
Rise from the main accent to the end of the sentence.
50
100
150200
250
300
350
400450
500
550
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 34
Intonation Examples
• What will the weather be like today in Boston?• It will be rainy today in Boston.
• When will it rain in Boston?• It will be rainy today in Boston.
• Where will it rain today?• It will be rainy today in Boston
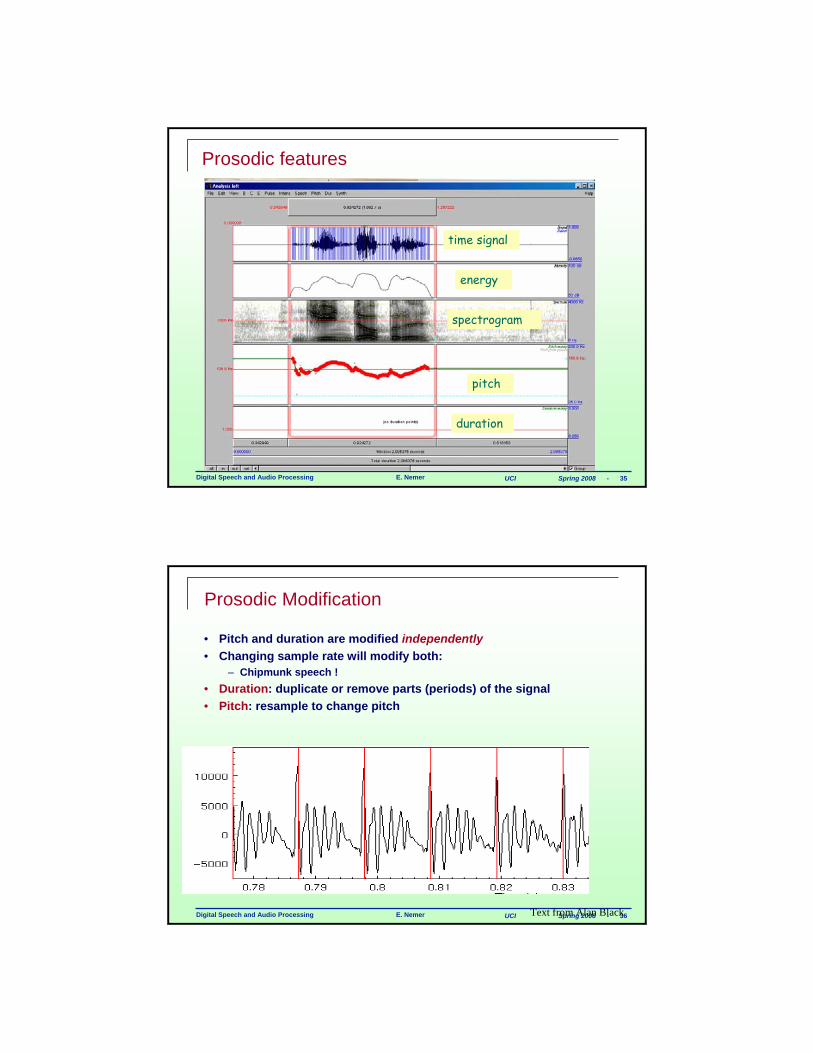
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 35
Prosodic features
time signal
energy
spectrogram
pitch
duration
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 36
Prosodic Modification
• Pitch and duration are modified independently• Changing sample rate will modify both:
– Chipmunk speech !• Duration: duplicate or remove parts (periods) of the signal• Pitch: resample to change pitch
Text from Alan Black
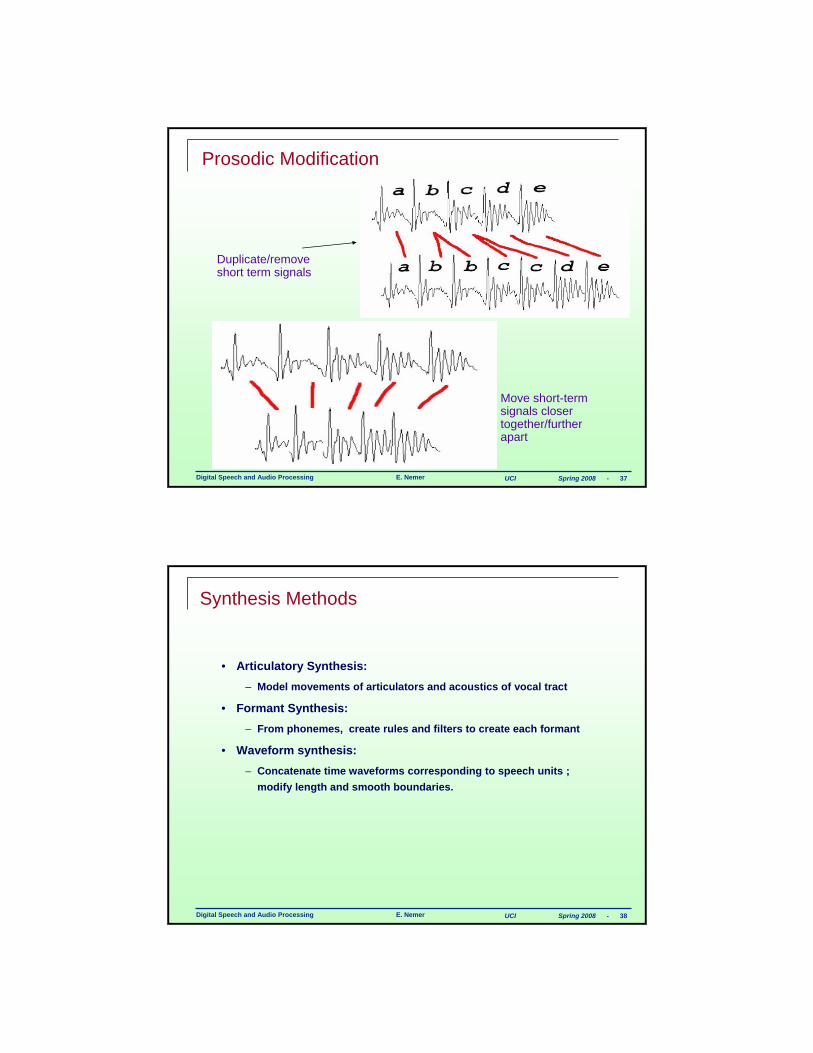
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 37
Prosodic Modification
Duplicate/remove short term signals
Move short-term signals closer together/further apart
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 38
Synthesis Methods
• Articulatory Synthesis:– Model movements of articulators and acoustics of vocal tract
• Formant Synthesis:– From phonemes, create rules and filters to create each formant
• Waveform synthesis:– Concatenate time waveforms corresponding to speech units ;
modify length and smooth boundaries.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 39
Synthesis Methods
DSP needs
Memory requirements
Naturalness
Cost
Could require sizable but not huge database
Only few global data structures required
Relatively large memory to store waveform.
Computational model needs precision and significant DSP power
Resonator/Antiresonator modeling of poles and zeros
Proper boundary smoothing, and waveform modification is crucial.
Most NaturalNatural approximate modeling
Synthetic
ComplexModerateModerate.
ArticulativeFormantWaveform
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 40
Articulatory synthesis
• Simulation of physical processes of human articulation :– Transforms an input phoneme sequence into a set of muscle commands, based on
some physical model of the human anatomy.
– This yields an elaborate model for vocal tract shapes (fct of space, time) or a number of finite area functions.
– From the area functions, the system is ‘implemented’ as a lattice network, or a transmission line equivalent, to generate the time functions of pressure and velocity.
– Alternatively, formant frequencies and bandwidths can be derived from the area functions and used in a formant synthesizer.
• Very complex to implement, even though it is the most intuitively appealing.
PhonemesMuscle
CommandsArea
FunctionsFormant
synthesizer
Solve forPressure, Velocity fct
resonators
Deriveacoustics
or

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 41
Articulatory synthesis
Historically, scientists like Wolfgang von Kempelen (1734-1804) and others used bellows, reeds and tubes to construct mechanical speaking machines.
• Small whistles controlled consonants• Rubber mouth and nose; nose had to be
covered with two fingers for non-nasals• Unvoiced sounds: mouth covered, auxiliary
bellows driven by string provides puff of air
Modern versions simulate electronically the effect of articulator positions, vocal tract shape, etc.
Wolfgang von Kempelen (1734-1804), Lawyer, physicist, engineer, student of language in the Austro-Hungarian empire. Conceived of and built a mechanical speech synthesizer. Published it in 1791 (Mechanismus der menschlichen Sprache, Vienna).
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 42
Articulatory synthesisPhoneme sequence are converted into a set of muscle commands.Muscles commands are transformed into vocal tract area functionsor a number of finite area cross sections.From the area functions, we can solve for the time function of pressure and velocity in a number of ways. The system can be ‘implemented’ as a lattice network, or a transmission line equivalent.
Phonemes
Articulationrules
A2 A3 A4A1
Or use finite number of Area functions With boundary conditions.
Or implement as a lattice network
Solve expression for velocity and pressure
O’Shaughnessy p 347

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 43
Articulatory synthesis
Typical systems assume that 7-14 parameters can adequately describe
articulatory behaviour , such as :
• velum opening • Lip closure• Tongue body• Tongue tip • Jaw height • Pharyns width • Etc….
O’Shaughnessy p 348
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 44
Articulatory synthesis
Target values for the selected parameters are stored for each phoneme; The time sequence (trajectory) of the parameter values is obtained by interpolating between the targets, using physical characteristics (time constants of the different articulators), and coarticulation constraint models.
O’Shaughnessy p 348

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 45
Articulatory synthesis
• Articularly synthesis advantages
– allows the accurate modelling of transients due to abrupt area changes
– automatic generation of turbulence excitation for narrow constrictions.
– captures the aerodynamic conditions that affects pressure and velocity.
– Captures certain types of co-articulation (backward type).
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 46
Formant synthesis
• Reproduces the relevant spectral characteristics of the acoustic signal:– Amplitude, frequency and bandwidth of formants– Other resonances and noise, eg for nasals, laterals, fricatives etc.
• Values of acoustic parameters are derived by rule from phonetic transcription.
• Result is intelligible, but sounds synthetic
F1
F2F3
F4

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 47
Formant Synthesis
• The vocal tract is represented by a cascade of 2nd order resonators, each representing either a formant or the spectral shape of the excitation source.
• Antiresonators are used to capture the spectral zeros mostly in nasals• Spectral amplitude of the resonators can be controlled. • Some advanced synthesizers allow 4 lower formants and 3 corresponding
bandwidths to be varied as function of time.
O’Shaughnessy p 349
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 48
Formant speech synthesis
• Waveform generation from Formant values– Formant resonance can be implemented with a second-order IIR filter
– With and where are formant’s center frequency, formant bandwidth, sampling frequency
– Typically use the parallel model to synthesize fricatives and stops and the cascade model for all voiced sounds
221)2cos(211)(
−−−− +−=
zezfezH i
i bi
bi ππ π
sii FFf /= sii FBb /= sii FandBF ,

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 49
Klatt’s Model
• A specific implementation of Formant Synthesis
• A combination of Cascade/Parallel formant synthesizer– Source filter model
• Voicing source – impulsive model
• Turbulent noise – random number generator
• Vocal tract transfer function – resonator combination
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 50
Klatt’s Model
R1 – R6 : second-order IIR filter : 1 resonant frequency.RNP : nasal resonance (pole) , RNZ : FIR filter with the nasal zeroA1- AN : gain for each filter RGP : low pass filter RGZ and RGS : bandpass filter
nasal resonance (pole)
FIR filter with the nasal zero
bandpass filters

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 51
Formant Synthesis
• Simulating fricatives– Pseudo-random generators are
summed to produce a Gaussian noise shape excitation
– A parallel set of resonators is often used to generate the high frequency speech energy .
– High pass filter models lips, enhances intelligibility.
• Simulating nasals– Requires one more resonator
than vowels because the acoustic path including the nasal tract is longer than the vocal tract.
– Antiresonator is used to model the spectral zero, only at the lower frequency (higher frequency zero is not perceptuatlly important).
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 52
Formant Synthesis
• Formant Generation by rule– Rules on how to generate formant trajectories from a phonetic
string is based on the locus theory– The locus theory specifies that formant frequencies within a
phoneme tend to reach a stationary value called the target– Target for formant frequencies and bandwidths are defined– This target is reached if either the phoneme is sufficiently long
or the previous phoneme’s target is close to the the current phoneme’s target
– Rule-based systems store targets for each phoneme as well as maximum allowable slope and transition times

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 53
LPC Synthesis
• A simpler form of Formant synthesis:– All spectral properties are captured in the LPC coefficients.
– Can be implemented with a single lattice filter
• Interpolation is more elaborate due to stability and lack of degree of freedom:
– Use of alternative forms (LSF, PARCOR, …)
• Approximate : All-pole assumptions – Less accurate for nasals
– Cannot shape spectral zeros explicitly.
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 54
Waveform Synthesis
• An alternative to spectral-based synthesis. Involves concatenating waveforms corresponding to speech units, modifying them according to context, and smoothing the boundaries.
• Pitch-synchronous Overlap and add (OLA)
– Used to concatenate waveform sections, and alter durations.
– Can only simulate the voice of the training speaker.
– Similar in quality to LPC synthesis
– Requires a manual pitch period marking.
– Requires a large memory for the stored waveforms.

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 55
Waveform Concatenation
Overlap-and-add (OLA)
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 56
Waveform : Duration Modification
• Hanning windows of length 2N used to multiply the analysis signal• Resulting windowed signals are added• Analysis windows, spaced 2N• Synthesis windows, spaced N• Time compression is uniform with factor of 2• Pitch periodicity somewhat lost around 4th window

Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 57
TD-PSOLA ™
• Windowed• Pitch-synchronous• Overlap-• -and-add
• Time-Domain Pitch Synchronous Overlap and Add• Patented by France Telecom (CNET)• Very efficient
– No FFT (or inverse FFT) required• Can modify Hz up to two times or by half
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 58
Altering Pitch
X
Hanningwindow
=
Original diphone Extractedpitch period
Hannedpitch period
‘C_A’
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 59
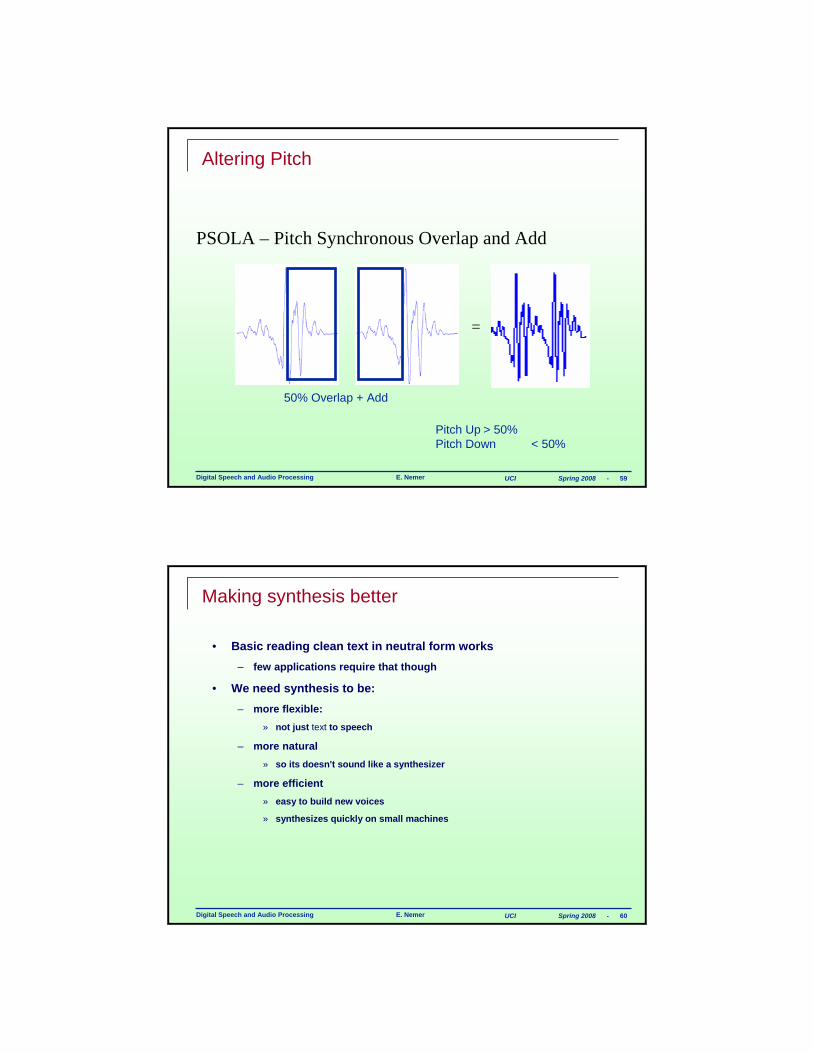
PSOLA – Pitch Synchronous Overlap and Add
=
50% Overlap + Add
Pitch Up > 50%Pitch Down < 50%
Altering Pitch
Digital Speech and Audio Processing E. Nemer UCI Spring 2008 - 60
Making synthesis better
• Basic reading clean text in neutral form works– few applications require that though
• We need synthesis to be:– more flexible:
» not just text to speech
– more natural» so its doesn't sound like a synthesizer
– more efficient» easy to build new voices
» synthesizes quickly on small machines