histogram*of*oriented*gradients*for*detection*of*multiple...
TRANSCRIPT

Histogram of Oriented Gradients for Detection of Multiple Scene Properties Maesen Churchill Adela Fedor
I. Introduction Content-‐based image retrieval is an interesting problem within the field of computer vision. There are many situations in which a user might want to query a large set of images to find only images with some set of properties. For example, in order to show photos from a recent vacation to a friend, one might want to be able to search through a large collection of personal photos to find scenes of people, on the beach. It would be ideal if multiple properties of a scene could be detected from a single set of features. Ideally, a program would only have to make a one-‐time calculation of a feature vector upon image upload, and learn several properties of the image by applying this defined set of features to multiple classifiers. Furthermore, introducing a new category to this scheme could be done without recomputing all feature vectors for this set of images; one could simply impose a new, trained classifier to this set. Thus, it would be convenient if there were some canonical descriptor for different types of images. For our project, we will test the feasibility of using Histogram of Oriented Gradient feature sets as such canonical descriptors. We will evaluate the performance of these descriptors at detecting multiple properties of images by attempting to classify images into one of four categories: scenes with humans, scenes with bikes, scenes with both humans and bikes, and scenes with neither humans nor bikes.
II. Previous Work Histogram of Oriented Gradient (HOG) descriptors are proven to be effective at object detection, and in particular with human detection [1]. These features have been used to solve a variety of problems, including pedestrians recognition and tracking [7], hand gesture recognition for sign language translation and gesture-‐based technology interfaces [4], face recognition [3], and body part recognition for tracking [1]. HOG descriptors have also been used in tasks that are not human-‐centric, such as classification of vehicle orientation, a problem relevant for autonomous vehicles [5]. However, these classification tasks use a sliding window approach to obtain descriptions of areas localized to just the subject of detection. To detect multiple scene properties, descriptors would have to use the entire image
as a detection window. Moreover, for each of these tasks, the parameters of the HOG features are tuned to optimize for the specific classification task. If using a single feature vector to learn several properties of an image is possible, we will have to use a fixed set of parameters.
III. HOG Descriptors for Image Classification
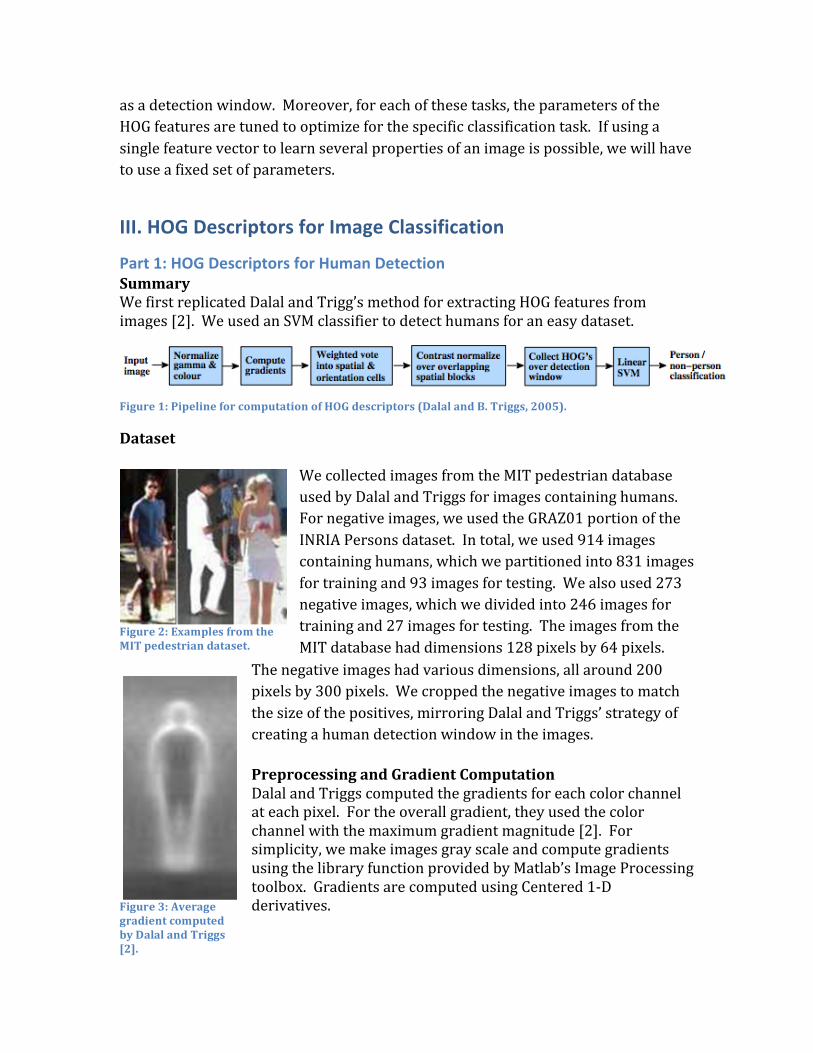
Part 1: HOG Descriptors for Human Detection Summary We first replicated Dalal and Trigg’s method for extracting HOG features from images [2]. We used an SVM classifier to detect humans for an easy dataset.
Figure 1: Pipeline for computation of HOG descriptors (Dalal and B. Triggs, 2005).
Dataset
We collected images from the MIT pedestrian database used by Dalal and Triggs for images containing humans. For negative images, we used the GRAZ01 portion of the INRIA Persons dataset. In total, we used 914 images containing humans, which we partitioned into 831 images for training and 93 images for testing. We also used 273 negative images, which we divided into 246 images for training and 27 images for testing. The images from the MIT database had dimensions 128 pixels by 64 pixels.
The negative images had various dimensions, all around 200 pixels by 300 pixels. We cropped the negative images to match the size of the positives, mirroring Dalal and Triggs’ strategy of creating a human detection window in the images. Preprocessing and Gradient Computation Dalal and Triggs computed the gradients for each color channel at each pixel. For the overall gradient, they used the color channel with the maximum gradient magnitude [2]. For simplicity, we make images gray scale and compute gradients using the library function provided by Matlab’s Image Processing toolbox. Gradients are computed using Centered 1-‐D derivatives.
(a) (b) (c) (d) (e) (f) (g)Figure 6. Our HOG detectors cue mainly on silhouette contours (especially the head, shoulders and feet). The most active blocks arecentred on the image background just outside the contour. (a) The average gradient image over the training examples. (b) Each “pixel”shows the maximum positive SVM weight in the block centred on the pixel. (c) Likewise for the negative SVM weights. (d) A test image.(e) It’s computed R-HOG descriptor. (f,g) The R-HOG descriptor weighted by respectively the positive and the negative SVM weights.
would help to improve the detection results in more generalsituations.Acknowledgments. This work was supported by the Euro-pean Union research projects ACEMEDIA and PASCAL. Wethanks Cordelia Schmid for many useful comments. SVM-Light [10] provided reliable training of large-scale SVM’s.
References[1] S. Belongie, J. Malik, and J. Puzicha. Matching shapes. The8th ICCV, Vancouver, Canada, pages 454–461, 2001.
[2] V. de Poortere, J. Cant, B. Van den Bosch, J. dePrins, F. Fransens, and L. Van Gool. Efficient pedes-trian detection: a test case for svm based categorization.Workshop on Cognitive Vision, 2002. Available online:http://www.vision.ethz.ch/cogvis02/.
[3] P. Felzenszwalb and D. Huttenlocher. Efficient matching ofpictorial structures. CVPR, Hilton Head Island, South Car-olina, USA, pages 66–75, 2000.
[4] W. T. Freeman and M. Roth. Orientation histograms forhand gesture recognition. Intl. Workshop on Automatic Face-and Gesture- Recognition, IEEE Computer Society, Zurich,Switzerland, pages 296–301, June 1995.
[5] W. T. Freeman, K. Tanaka, J. Ohta, and K. Kyuma. Com-puter vision for computer games. 2nd International Confer-ence on Automatic Face and Gesture Recognition, Killington,VT, USA, pages 100–105, October 1996.
[6] D. M. Gavrila. The visual analysis of human movement: Asurvey. CVIU, 73(1):82–98, 1999.
[7] D. M. Gavrila, J. Giebel, and S. Munder. Vision-based pedes-trian detection: the protector+ system. Proc. of the IEEE In-telligent Vehicles Symposium, Parma, Italy, 2004.
[8] D. M. Gavrila and V. Philomin. Real-time object detection forsmart vehicles. CVPR, Fort Collins, Colorado, USA, pages87–93, 1999.
[9] S. Ioffe and D. A. Forsyth. Probabilistic methods for findingpeople. IJCV, 43(1):45–68, 2001.
[10] T. Joachims. Making large-scale svm learning practical. InB. Schlkopf, C. Burges, and A. Smola, editors, Advances inKernel Methods - Support Vector Learning. The MIT Press,Cambridge, MA, USA, 1999.
[11] Y. Ke and R. Sukthankar. Pca-sift: A more distinctive rep-resentation for local image descriptors. CVPR, Washington,DC, USA, pages 66–75, 2004.
[12] D. G. Lowe. Distinctive image features from scale-invariantkeypoints. IJCV, 60(2):91–110, 2004.
[13] R. K. McConnell. Method of and apparatus for pattern recog-nition, January 1986. U.S. Patent No. 4,567,610.
[14] K. Mikolajczyk and C. Schmid. A performance evaluation oflocal descriptors. PAMI, 2004. Accepted.
[15] K. Mikolajczyk and C. Schmid. Scale and affine invariantinterest point detectors. IJCV, 60(1):63–86, 2004.
[16] K. Mikolajczyk, C. Schmid, and A. Zisserman. Human detec-tion based on a probabilistic assembly of robust part detectors.The 8th ECCV, Prague, Czech Republic, volume I, pages 69–81, 2004.
[17] A. Mohan, C. Papageorgiou, and T. Poggio. Example-basedobject detection in images by components. PAMI, 23(4):349–361, April 2001.
[18] C. Papageorgiou and T. Poggio. A trainable system for objectdetection. IJCV, 38(1):15–33, 2000.
[19] R. Ronfard, C. Schmid, and B. Triggs. Learning to parse pic-tures of people. The 7th ECCV, Copenhagen, Denmark, vol-ume IV, pages 700–714, 2002.
[20] Henry Schneiderman and Takeo Kanade. Object detectionusing the statistics of parts. IJCV, 56(3):151–177, 2004.
[21] Eric L. Schwartz. Spatial mapping in the primate sensory pro-jection: analytic structure and relevance to perception. Bio-logical Cybernetics, 25(4):181–194, 1977.
[22] P. Viola, M. J. Jones, and D. Snow. Detecting pedestriansusing patterns of motion and appearance. The 9th ICCV, Nice,France, volume 1, pages 734–741, 2003.
Figure 3: Average gradient computed by Dalal and Triggs [2].
Figure 2: Examples from the MIT pedestrian dataset.

Weighted voting in cells We partitioned each image into 6 by 6 pixel cells. For each cell, we computed a histogram of gradient orientation. We used a signed orientation (between 0 and 360 degrees) and had 9 spatial bins for each histogram. Votes were weighted by gradient magnitude. Normalization over overlapping spatial blocks In order to provide some invariance to illumination, histograms were concatenated together and then normalized across larger spatial blocks. We used blocks of 3 cells by 3 cells. Histograms were normalized according to L2 norm:
𝑣 → 𝑣/ 𝑣 ! + 𝜖! For the overall descriptor, we concatenated the normalized histograms for dense, overlapping blocks across the entire image. Support Vector Machine For classification, we trained a soft (C = 0.01) SVM with a Gaussian kernel on our training examples.
Part 1: Results We were able to classify our test set with 92% accuracy. Full results are shown below: Predicted Human Predicted Non-‐human
Human 87 4 Non Human 5 22
Part 2: HOG Descriptors for detection of multiple image properties Summary We then assessed the accuracy of HOG descriptors at predicting: 1) whether the image has a human or not, and 2) whether the image has a bike or not, by applying two SVM classification schemes. Descriptors were computed across the entirety of images, not just a spatial window. Dataset We used a portion of the INRIA person dataset to create image sets for four object categories: those containing humans, those containing bikes, those containing humans and bikes, and those containing neither. In total, we had 323 images of humans (partitioned into 291 for training and 32 for testing), 373 images of bikes (partitioned into 336 for training and 37 for testing), 273 images of humans and bikes (partitioned into 246 for training and 27 for testing), and 210 images of neither (partitioned into 186 for training and 24 for testing).

Our dataset was diverse and challenging. It included images taken from a variety of viewpoints, with different illuminations and levels of occlusion. Though it is common practice to eliminate images that are particularly difficult [8], due to extreme occlusion, for example, we did not perform any data sanitation.
Figure 4: Samples from our dataset. Examples (from left to right) of bikes, humans, humans and bikes, and neither humans nor bikes.
Because our descriptors must serve as feature vectors for classifiers that predict the presence of multiple object categories, we did not clip our images or use a sliding detecting window at various scales. This marks a departure from Dalal and Triggs, who used a superset of our dataset, clipped to object-‐sized windows:
Figure 5: Images used by Dalal and Triggs, for comparison. Figure 2. Some sample images from our new human detection database. The subjects are always upright, but with some partial occlusionsand a wide range of variations in pose, appearance, clothing, illumination and background.
probabilities to be distinguished more easily. We will oftenuse miss rate at 10!4FPPW as a reference point for results.This is arbitrary but no more so than, e.g. Area Under ROC.In a multiscale detector it corresponds to a raw error rate ofabout 0.8 false positives per 640!480 image tested. (The fulldetector has an even lower false positive rate owing to non-maximum suppression). Our DET curves are usually quiteshallow so even very small improvements in miss rate areequivalent to large gains in FPPW at constant miss rate. Forexample, for our default detector at 1e-4 FPPW, every 1%absolute (9% relative) reduction in miss rate is equivalent toreducing the FPPW at constant miss rate by a factor of 1.57.
5 Overview of ResultsBefore presenting our detailed implementation and per-
formance analysis, we compare the overall performance ofour final HOG detectors with that of some other existingmethods. Detectors based on rectangular (R-HOG) or cir-cular log-polar (C-HOG) blocks and linear or kernel SVMare compared with our implementations of the Haar wavelet,PCA-SIFT, and shape context approaches. Briefly, these ap-proaches are as follows:Generalized Haar Wavelets. This is an extended set of ori-ented Haar-like wavelets similar to (but better than) that usedin [17]. The features are rectified responses from 9!9 and12!12 oriented 1st and 2nd derivative box filters at 45" inter-vals and the corresponding 2nd derivative xy filter.PCA-SIFT. These descriptors are based on projecting gradi-ent images onto a basis learned from training images usingPCA [11]. Ke & Sukthankar found that they outperformedSIFT for key point based matching, but this is controversial[14]. Our implementation uses 16!16 blocks with the samederivative scale, overlap, etc., settings as our HOG descrip-tors. The PCA basis is calculated using positive training im-ages.Shape Contexts. The original Shape Contexts [1] used bi-nary edge-presence voting into log-polar spaced bins, irre-spective of edge orientation. We simulate this using our C-HOG descriptor (see below) with just 1 orientation bin. 16angular and 3 radial intervals with inner radius 2 pixels andouter radius 8 pixels gave the best results. Both gradient-
strength and edge-presence based voting were tested, withthe edge threshold chosen automatically to maximize detec-tion performance (the values selected were somewhat vari-able, in the region of 20–50 graylevels).Results. Fig. 3 shows the performance of the various detec-tors on the MIT and INRIA data sets. The HOG-based de-tectors greatly outperform the wavelet, PCA-SIFT and ShapeContext ones, giving near-perfect separation on the MIT testset and at least an order of magnitude reduction in FPPWon the INRIA one. Our Haar-like wavelets outperform MITwavelets because we also use 2nd order derivatives and con-trast normalize the output vector. Fig. 3(a) also shows MIT’sbest parts based and monolithic detectors (the points are in-terpolated from [17]), however beware that an exact compar-ison is not possible as we do not know how the database in[17] was divided into training and test parts and the nega-tive images used are not available. The performances of thefinal rectangular (R-HOG) and circular (C-HOG) detectorsare very similar, with C-HOG having the slight edge. Aug-menting R-HOG with primitive bar detectors (oriented 2nd
derivatives – ‘R2-HOG’) doubles the feature dimension butfurther improves the performance (by 2% at 10!4 FPPW).Replacing the linear SVM with a Gaussian kernel one im-proves performance by about 3% at 10!4 FPPW, at the costof much higher run times1. Using binary edge voting (EC-HOG) instead of gradient magnitude weighted voting (C-HOG) decreases performance by 5% at 10!4 FPPW, whileomitting orientation information decreases it by much more,even if additional spatial or radial bins are added (by 33% at10!4 FPPW, for both edges (E-ShapeC) and gradients (G-ShapeC)). PCA-SIFT also performs poorly. One reason isthat, in comparison to [11], many more (80 of 512) principalvectors have to be retained to capture the same proportion ofthe variance. This may be because the spatial registration isweaker when there is no keypoint detector.
6 Implementation and Performance StudyWe now give details of our HOG implementations and
systematically study the effects of the various choices on de-1We use the hard examples generated by linear R-HOG to train the ker-
nel R-HOG detector, as kernel R-HOG generates so few false positives thatits hard example set is too sparse to improve the generalization significantly.

HOG Computation For efficiency and accuracy, we used a Matlab library function for HOG computation during this part of our investigation. The HOG implementation that we used normalized non-‐overlapping blocks. To prevent over-‐fitting our classifiers, we used much larger blocks. We tried computing HOG descriptors for our 200 pixel by 300 pixel images with 3 and 6 blocks per image side. Support Vector Machines We used two soft (C=0.01) Support Vector Machines for classification (each with a Gaussian kernel). For the human classifier, images of humans made up the set of positive samples. For the bike classifier, images of bikes made up the set of positive samples. Thus, for both classifiers, images with bikes and humans are included as positive samples. After classification by both SVMs, predictions for test images are assigned according to: Bike classifier predicted
positive Bike classifier predicted
negative Human classifier predicted positive
“Human and bike” “Human”
Human classifier predicted negative
“Bike” “Neither human nor bike”
IV. Results Through this method, we achieved the highest success rates with 6 by 6 blocks. The success rate was 77% for human classification and 71% for bike classification. Overall, 58% of images were correctly classified into one of the four categories.
Predicted: Human
Predicted: Bike
Predicted: Human & Bike
Predicted: Neither
Actual: Human 22 6 0 4 Actual: Bike 5 32 0 0 Actual:
Human & Bike 10 5 12 0
Actual: Neither 8 15 1 0

These results demonstrate that our method does a fairly good job categorizing images containing either just humans or just bikes. Many of the incorrect classifications had obvious challenges that a HOG descriptor cannot account for, such as occlusion, scaling, illumination and orientation. Scaling Orientation
Illumination Occlusion
However, our classification has very poor specificity. In particular, images with neither bikes nor humans were consistently labeled inaccurately. A large set of humans make up the set of negative samples for the bike classifier. Likewise, bikes are abundant in the set of negative images for the human classifier. As a result, our model is likely over-‐fitting negative samples for bikes to be images of humans, and vice versa. To correct for this, we removed a large number of bike images from the negative samples of our human training set. We also removed a large number of humans from our bike training set. We then reran the classifier on descriptors with 6 blocks per side. Using the new training sets, we achieved a success rate of about 76% for classifying humans correctly; however, the rate for classifying bikes correctly fell to about 58%.
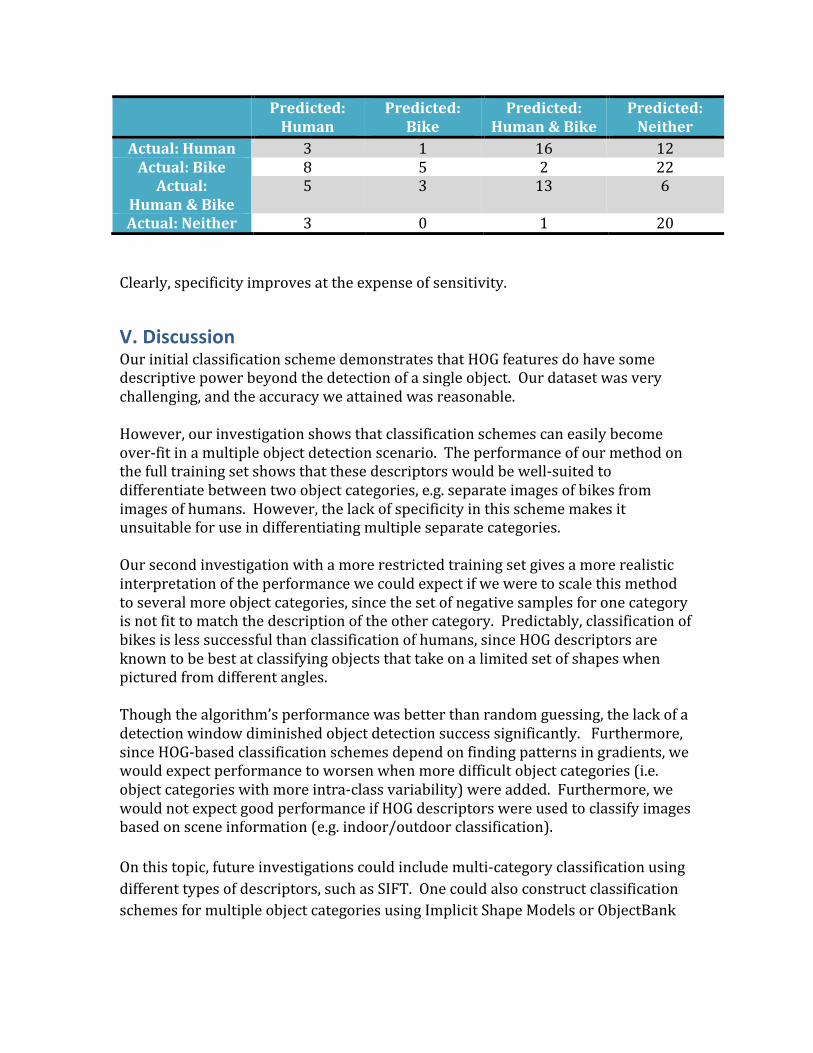
Predicted: Human
Predicted: Bike
Predicted: Human & Bike
Predicted: Neither
Actual: Human 3 1 16 12 Actual: Bike 8 5 2 22 Actual:
Human & Bike 5 3 13 6
Actual: Neither 3 0 1 20 Clearly, specificity improves at the expense of sensitivity.
V. Discussion Our initial classification scheme demonstrates that HOG features do have some descriptive power beyond the detection of a single object. Our dataset was very challenging, and the accuracy we attained was reasonable. However, our investigation shows that classification schemes can easily become over-‐fit in a multiple object detection scenario. The performance of our method on the full training set shows that these descriptors would be well-‐suited to differentiate between two object categories, e.g. separate images of bikes from images of humans. However, the lack of specificity in this scheme makes it unsuitable for use in differentiating multiple separate categories. Our second investigation with a more restricted training set gives a more realistic interpretation of the performance we could expect if we were to scale this method to several more object categories, since the set of negative samples for one category is not fit to match the description of the other category. Predictably, classification of bikes is less successful than classification of humans, since HOG descriptors are known to be best at classifying objects that take on a limited set of shapes when pictured from different angles. Though the algorithm’s performance was better than random guessing, the lack of a detection window diminished object detection success significantly. Furthermore, since HOG-‐based classification schemes depend on finding patterns in gradients, we would expect performance to worsen when more difficult object categories (i.e. object categories with more intra-‐class variability) were added. Furthermore, we would not expect good performance if HOG descriptors were used to classify images based on scene information (e.g. indoor/outdoor classification). On this topic, future investigations could include multi-‐category classification using different types of descriptors, such as SIFT. One could also construct classification schemes for multiple object categories using Implicit Shape Models or ObjectBank

heat maps. The performance of HOG descriptors could be used as a baseline for performance.

References [1] Corvee, E., 2010. Body Parts Detection for People Tracking Using Trees of Histogram of Oriented Gradient Descriptors. In: IEEE pp. 469 – 475. [2] Dalal, N., Triggs, B., 2005. Histograms of oriented gradients for human detection. In: Proc. CVPR 2005, vol. 1, pp. 886-‐893. <http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1%467360>. [3] Déniz, O., Bueno, G., Salido, J., De la Torre, F., 2011. Face recognition using Histograms of Oriented Gradients. In: Pattern Recognition Letters vol. 32 issue 12, http://www.sciencedirect.com/science/journal/01678655/32/12, pp. 1598–1603. [4] Freeman, W. T., Roth, M., 1994. Orientation Histograms for Hand Gesture Recognition. In: IEEE. [5] Huber, D., Morris, D.D., Hoffman, R., 2010. Visual classification of coarse vehicle orientation using Histogram of Oriented Gradients features. In: IEEE, pg. 921 – 928. [6] Ludwig, O., 2011. HOG descriptor for Matlab. http:// http://www.mathworks.com/matlabcentral/fileexchange/28689-‐hog-‐descriptor-‐for-‐matlab/content/HOG.m. Universidade de Coimbra. [7] Suard, F., Rakotomamonjy, A., Bensrhair, A., Broggi, A., 2006. Pedestrian Detection using Infrared images and Histograms of Oriented Gradients. In: IEEE, pp. 206 – 212. [8] Szummer , M., R. W. Picard, 1997. Indoor-‐Outdoor Image Classification. In: IEEE, pp. 43-‐51.