high performance rdma-based mpi implementation over...
TRANSCRIPT

High Performance RDMA-Based MPI Implementation over InfiniBand
Presented byNusrat Sharmin Islam

Problem Description
● Presents a new design of MPI over InfiniBand● Brings benefit of RDMA to large as well as small
messages● Achieves better scalability by combining
send/receive operations with RDMA

Motivation
● MPI uses send/receive operations for small messages and control messages
● Using send/receive operations has disadvantages:
– The operations are slower than RDMA operations– Managing and posting descriptors at the receiver side
incur additional overhead

InfiniBand Channel and Memory Semantics
● Channel Semantics (Send/Receive):
● Sender initiates send operation by posting send descriptor
● Receiver posts a receive descriptor which describes where the message has to be put at the receiving end
● Memory Semantics (RDMA):
● Sender initiates RDMA operations by posting RDMA descriptors. The descriptor has both the local data source address and remote data destination address

MPI Protocols
Small data transferLess copy overhead
Send/receive
Large data transferLarge copy overhead
RDMA

Send/Receive Approach (Eager protocol and Control Messages)
● For a process, send/receive queues of all the connections are associated with a single CQ
● Eager Protocol: pool of pre-pinned fixed sized buffers
● Scalable for detecting incoming messages. CQ polling time does not increase with no. of connections.
CQ polling time

RDMA -Based Approach● Constraints:
– Destination address must be known– Receiver must detect arrival of incoming message
Destination Address must be known: persistent buffer associationReceiver must detect arrival of incoming message:
Detect incoming message from a single connection• Pool of buffers are organized in a ring in the receiver side• The sender uses buffers in a fixed, circular order
Detect incoming messages for all connections• Multiple connections are checked by polling them one by one• Not scalable

Hybrid approach● Combines both RDMA write
and send/receive operations for better scalability
● RDMA Polling set at the receiver
● each sender has two channels: a send/receive channel and an RDMA channel
● Sender uses RDMA channel if the connection is in RDMA polling set of the receiver
RDMA Polling Set
Restrict the size of RDMA Polling set

Structure of RDMA Channel
Sender side:• Head points to where the next
message should be copied• Tail points to those buffers that are
processed at the receiver side
Receiver side:• Head points to where the next
message should go• Tail pointer keeps track of the free
buffers

Polling for a single Connection● Issues
– Use a flag bit at the end of data– Minimize RDMA writes– Data length is variable
● Sender side– Sets data size– Sets the head and tail flags– Uses RDMA write
● Receiver side– Check if head is set– Read data size and calculate the position of tail– Poll the tail flag

Other Design Issues
● Reducing Sender Side Overhead:
● All fields in descriptor can be reused except the data field● Instead of generating CQ entries, unsignalled operations of
InfiniBand can be used
● Flow Control for RDMA Channel:
● Each time a receiver buffer is freed, the credit count increases. Receiver piggybacks the credit count
● Ensuring Message Order:
● If out-of-order packets arrive, receiver switches to the other channel and delays processing
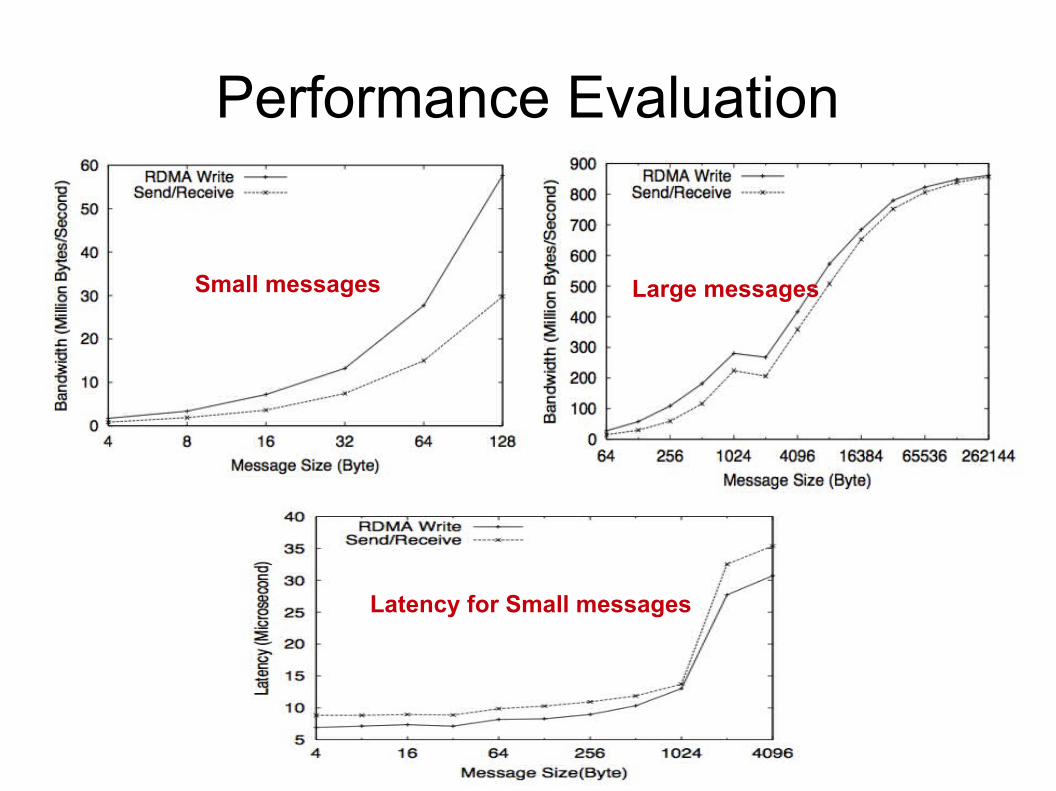
Performance Evaluation
Small messages Large messages
Latency for Small messages

Performance Evaluation
MPI AllReduce MPI Broadcast
4 Nodes 8 Nodes

Conclusion
● The RDMA based design reduces latency of small messages; the performance for large messages are improved by reducing time to transfer control messages
● Similar technique can be used for other communication subsystems such as those in cluster-based servers and file systems

RDMA Read Based Rendezvous Protocol for MPI over InfiniBand: Design Alternatives and
Benefits

Problem Description
Presents several mechanisms to exploit RDMA Read and Selective Interrupt based asynchronous progress for Rendezvous protocol● Achieves better computation/communication
overlap on InfiniBand clusters● Achieves 50% better communication progress rate

Motivation
● Rendezvous Protocol can be designed using RDMA Write or RDMA Read
● RDMA Write based protocol has several drawbacks:– requires two-way handshake– Requires the polling based progress engine to make MPI
library calls● Less computation to communication overlap, poor
application performance

RDMA Write Based Rendezvous Protocol

RDMA Read/RDMA Write: Which is beneficial?
● Sender chooses the protocol; there can be three cases
– Sender arrives first: Embeds buffer info inside RNDZ_START. Receiver need not send RNDZ_REPLY. Simply performs RDMA Read
– Receiver arrives first– Sender and Receiver arrive at the same time
● RDMA Read is beneficial– Reduces no. of control messages– Receiver can progress independently of sender– Better overlap of communication and computaion

RDMA Read based Rendezvous Protocol
Design Issues:• Limited outstanding RDMA Reads• Issuing FIN messages
Communication-ComputaionOverlap only at sender side

RDMA Read with Interrupt Based Rendezvous Protocol
Selective Interrupt: only on arrival of RNDZ_START and completion of RDMA Read Data
• Sender sets a bit in the descriptor• Receiver must request for interrupts from the CQ
Control message
handled by asynchronous event handler
Overlap in Receiver

Experimental Evaluation

Conclusion
● RDMA Read based Rendezvous protocol achieves better communication to computation overlap
● This design has strong impact on scalability of parallel applications

Design Alternatives and Performance Trade-offs for Implementing MPI-2 over InfiniBand

Problem Description
● This paper analyzes the performance and complexity trade-offs for implementing MPI-2 over InfiniBand at the RDMA channel, CH3 and ADI3 layers of MPICH2
● Focuses on point to point and one-sided communication

Motivation
● Implementation of MPI-2 on InfiniBand can be done at one of the three layers of current MPICH2 stack:
– RDMA channel– CH3– ADI3
● The objective of such a design is to get a better balance between performance and complexity

Layered Architecture of MPICH2
● RDMA has the communication functions
● CH3 is responsible for making communication progress
● Can access more performance oriented features than RDMA
● ADI3 is a full featured abstract device interface used in MPICH2
● Highest portable layer in MPICH2

RDMA Channel Level Design
● Registration cache used for reducing registration overhead
● CH3 sends communication requests to RDMA one by one
● Small messages: copy message to pre- registered buffer and report completion to CH3
● Large messages: holds the buffer until the whole rendezvous finishes

CH3 Level Design
● Implements progress engine
● Due to limited underlying resources, the requests sent from ADI may be put into a queue
● Requests are retrieved when the resource becomes available
● All requests from the sender side can be accessed, multiple Rendezvous progress at the same time; high b/w
● Datatype Communication is also optimized at this layer

ADI3 Level Design
● Header Caching:
● Reduces latency of small messages
● Caches some fields of MPI header for each connection at the receiver side
● One-Sided Communication:
● Performance can be enhanced by using RDMA features
● Scheduling of one-sided operations to achieve better latency and throughput
ADI 3 knows the content of MPI header
CH3 cannot distinguish between one vs two sided communication

Performance Evaluation
Bandwidth Point to Point latency
MPI_Put
One sided throughput test

Conclusion
● Optimizations at different levels show improvements in terms of latency and bandwidth
● Effects of these optimizations also exhibit benefits at the application levels