designing high-performance mpi collectives in mvapich2 for ... · high performance open-source mpi...
TRANSCRIPT

15th ANNUAL WORKSHOP 2019
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Hari Subramoni
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~subramon
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
99
58
2131
95
63
23 27
65
0
25
50
75
100
MPI-FFT VASP AMG COSMO Graph500 MiniFE MILC DL-POLY HOOMD-blue
Perc
enta
ge o
f C
om
mu
nic
atio
n T
ime
Spen
t in
Co
llect
ive
Op
erat
ion
s (%
)
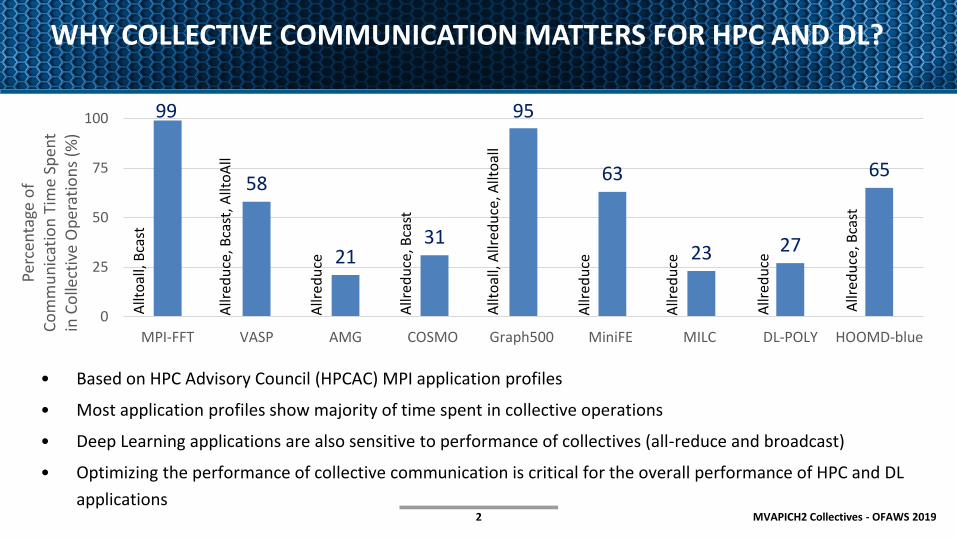
WHY COLLECTIVE COMMUNICATION MATTERS FOR HPC AND DL?
http://www.hpcadvisorycouncil.com
Allt
oal
l, B
cast
Allt
oal
l, A
llred
uce
, Allt
oal
l
Allr
edu
ce, B
cast
, Allt
oA
ll
Allr
edu
ce
Allr
edu
ce, B
cast
Allr
edu
ce
Allr
edu
ce
Allr
edu
ce
Allr
edu
ce, B
cast
• Based on HPC Advisory Council (HPCAC) MPI application profiles
• Most application profiles show majority of time spent in collective operations
• Deep Learning applications are also sensitive to performance of collectives (all-reduce and broadcast)
• Optimizing the performance of collective communication is critical for the overall performance of HPC and DL
applications2 MVAPICH2 Collectives - OFAWS 2019

Why different algorithms of even a dense collective such as Alltoall do not achieve theoretical peak bandwidth offered by the system?
ARE COLLECTIVE DESIGNS IN MPI READY FOR MANYCORE ERA?
1
10
100
1000
10000
100000
1000000
1 2 4 8
16
32
64
12
8
25
6
51
2
1
K
2
K
4
K
8
K
16
K
32
K
64
K
12
8K
25
6K
5
12
K
1
M
2
M
4
M
BrucksRecursive-DoublingScatter-DestinationPairwise-ExchangeTheoretical-Peak
Effe
ctiv
e b
and
wid
th (
MB
/s)
Alltoall Algorithms on single KNL 7250 in Cache-mode using MVAPICH2-2.3rc1
~3.5X
3 MVAPICH2 Collectives - OFAWS 2019

▪ High Performance open-source MPI Library for InfiniBand, Omni-Path, Ethernet/iWARP, and RDMA over Converged Ethernet (RoCE)
• MVAPICH (MPI-1), MVAPICH2 (MPI-2.2 and MPI-3.1), Started in 2001, First version available in 2002
• MVAPICH2-X (MPI + PGAS), Available since 2011
• Support for GPGPUs (MVAPICH2-GDR) and MIC (MVAPICH2-MIC), Available since 2014
• Support for Virtualization (MVAPICH2-Virt), Available since 2015
• Support for Energy-Awareness (MVAPICH2-EA), Available since 2015
• Support for InfiniBand Network Analysis and Monitoring (OSU INAM) since 2015
• Used by more than 2,975 organizations in 88 countries
• More than 529,000 (> 0.5 million) downloads from the OSU site directly
• Empowering many TOP500 clusters (Nov ‘18 ranking)
• 3rd ranked 10,649,640-core cluster (Sunway TaihuLight) at NSC, Wuxi, China
• 14th, 556,104 cores (Oakforest-PACS) in Japan
• 17th, 367,024 cores (Stampede2) at TACC
• 27th, 241,108-core (Pleiades) at NASA and many others
• http://mvapich.cse.ohio-state.edu
OVERVIEW OF THE MVAPICH2 PROJECT
Partner in the upcoming TACC Frontera System
4 MVAPICH2 Collectives - OFAWS 2019

▪Multiple directions being worked out by the MVAPICH2 project
1. Contention-aware, kernel-assisted designs for large-message intra-node collectives (CMA collectives)
2. Integrated collective designs with SHARP
3. Designs for scalable reduction operations for GPUs
4. Shared-address space (XPMEM)-based scalable collectives
▪ Solutions have been integrated into the MVAPICH2 libraries and publicly available
AGENDA
5 MVAPICH2 Collectives - OFAWS 2019

1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessage Size
Different Processes
PPN-2PPN-4PPN-8PPN-16PPN-32PPN-64
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessage Size
Same Process, Same Buffer
IMPACT OF COLLECTIVE COMMUNICATION PATTERN ON CMA COLLECTIVES
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4MMessage Size
Same Process, Diff Buffers
Late
ncy
(u
s)
All-to-All – Good Scalability One-to-All - Poor Scalability One-to-All – Poor Scalability
> 100x worse
> 100x worse
No increase with PPN
P0
P1P3
P2
P0
P1 P3
P2
P0
P1 P3
P2
Contention is at Process level
6 MVAPICH2 Collectives - OFAWS 2019

1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M 4M
Message Size
KNL (2 Nodes, 128 procs)
MVAPICH2Intel MPIOpenMPITuned CMA
1
10
100
1000
10000
100000
1000000
1K 4K 16K 64K 256K 1M
Message Size
KNL (4 Nodes, 256 Procs)
MVAPICH2
Intel MPI
OpenMPI
Tuned CMA
MULTI-NODE SCALABILITY USING TWO-LEVEL ALGORITHMS
1
10
100
1000
10000
100000
1000000
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
Message Size
KNL (8 Nodes, 512 Procs)
MVAPICH2
Intel MPI
OpenMPI
Tuned CMA
Late
ncy
(u
s)
• Significantly faster intra-node communication• New two-level collective designs can be composed• 4x-17x improvement in 8 node Scatter and Gather compared to default MVAPICH2
~ 2.5x Better
~ 3.2xBetter
~ 4xBetter
~ 17xBetter
7
S. Chakraborty, H. Subramoni, and D. K. Panda, Contention Aware Kernel-Assisted MPI
Collectives for Multi/Many-core Systems, IEEE Cluster ’17, BEST Paper Finalist Available since MVAPICH2-X 2.3bMVAPICH2 Collectives - OFAWS 2019

0
0.2
0.4
0.6
56 224 448
DD
OT
Tim
ing
(Sec
on
ds)
Number of Processes
MVAPICH2
NUMA-Aware (proposed)
MVAPICH2+SHArP
0
20
40
60
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(u
s)
Message Size (Byte)
MVAPICH2
NUMA-aware (Proposed)
MVAPICH2+SHArP
PERFORMANCE OF NUMA-AWARE SHARP DESIGN ON XEON + IB CLUSTER
• As the message size decreases, the benefits of using Socket-based design increases
• NUMA-aware design can reduce the latency by up to 23% for DDOT phase of HPCG
OSU Micro Benchmark (16 Nodes, 28 PPN) HPCG (16 nodes, 28 PPN)
23%
40%
Low
er is b
etter
8
M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda, Scalable Reduction
Collectives with Data Partitioning-based Multi-Leader Design, SuperComputing '17. Available since MVAPICH2-X 2.3b
MVAPICH2 Collectives - OFAWS 2019

0
2
4
6
8
10
4 8 16 32 64 128
Late
ncy
(u
s)
Message Size (Bytes)
1 PPN*, 8 Nodes
MVAPICH2
MVAPICH2-SHArP
0.1
1
10
100
4 8 16 32 64 128
Ove
rlap
(%
)
Message Size (Bytes)
1 PPN, 8 Nodes
MVAPICH2
MVAPICH2-SHArP
SHARP BASED NON-BLOCKING ALLREDUCE IN MVAPICH2
MPI_Iallreduce Benchmark
2.3x
*PPN: Processes Per Node
• Complete offload of Allreduce collective operation to “Switch”
o Higher overlap of communication and computation
Available since MVAPICH2 2.3a
Low
er is b
etter
Hig
he
r is
bet
ter
9 MVAPICH2 Collectives - OFAWS 2019

MVAPICH2-GDR VS. NCCL2 – ALLREDUCE ON DGX-2(PRELIMINARY RESULTS)
• Optimized designs in upcoming MVAPICH2-GDR offer better/comparable performance for most cases
• MPI_Allreduce (MVAPICH2-GDR) vs. ncclAllreduce (NCCL2) on 1 DGX-2 node (16 Volta GPUs)
1
10
100
1000
10000
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR-2.3.1 NCCL-2.3
~1.7X better
Platform: Nvidia DGX-2 system (16 Nvidia Volta GPUs connected with NVSwitch), CUDA 9.2
0
10
20
30
40
50
60
8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR-2.3.1 NCCL-2.3
~2.5X better
10 MVAPICH2 Collectives - OFAWS 2019

▪MVAPICH2-GDR offers excellent performance via advanced designs for MPI_Allreduce.
▪Up to 11% better performance on the RI2 cluster (16 GPUs)
▪Near-ideal – 98% scaling efficiency
EXPLOITING CUDA-AWARE MPI FOR TENSORFLOW (HOROVOD)
0
100
200
300
400
500
600
700
800
900
1000
1 2 4 8 16
Imag
es/s
eco
nd
(H
igh
er is
bet
ter)
No. of GPUs
Horovod-MPI Horovod-NCCL2 Horovod-MPI-Opt (Proposed) Ideal
MVAPICH2-GDR 2.3 (MPI-Opt) is up to 11% faster than MVAPICH2
2.3 (Basic CUDA support)
A. A. Awan et al., “Scalable Distributed DNN Training using TensorFlow and CUDA-Aware MPI: Characterization, Designs, and Performance Evaluation”, Under Review, https://arxiv.org/abs/1810.11112
11 MVAPICH2 Collectives - OFAWS 2019

MVAPICH2-GDR VS. NCCL2 – RESNET-50 TRAINING
• ResNet-50 Training using TensorFlow
benchmark on 1 DGX-2 node (8 Volta GPUs)
0
500
1000
1500
2000
2500
3000
1 2 4 8
Imag
e p
er s
eco
nd
Number of GPUs
NCCL-2.3 MVAPICH2-GDR-Next
7.5% higher
Platform: Nvidia DGX-2 system (16 Nvidia Volta GPUs connected with NVSwitch), CUDA 9.2
75
80
85
90
95
100
1 2 4 8
Scal
ing
Effi
cien
cy (
%)
Number of GPUs
NCCL-2.3 MVAPICH2-GDR-Next
Scaling Efficiency =Actual throughput
Ideal throughput at scale× 100%
12 MVAPICH2 Collectives - OFAWS 2019

▪Offload Reduction computation and communication to peer MPI ranks
• Every Peer has direct “load/store” access to other peer’s buffers
•Multiple pseudo roots independently carry-out reductions for intra-and inter-node
•Directly put reduced data into root’s receive buffer
▪ True “Zero-copy” design for Allreduce and Reduce
•No copies require during the entire duration of Reduction operation
• Scalable to multiple nodes
▪ Zero contention overheads as memory copies happen in “user-space”
SHARED ADDRESS SPACE (XPMEM-BASED) COLLECTIVES
J. Hashmi, S. Chakraborty, M. Bayatpour, H. Subramoni, and D. Panda, Designing Efficient Shared Address Space Reduction Collectives
for Multi-/Many-cores, International Parallel & Distributed Processing Symposium (IPDPS '18), May 2018.
13
Available since MVAPICH2-X 2.3rc1
MVAPICH2 Collectives - OFAWS 2019

APPLICATION-LEVEL BENEFITS OF XPMEM-BASED COLLECTIVES
MiniAMR (Broadwell, ppn=16)
• Up to 20% benefits over IMPI for CNTK DNN training using AllReduce
• Up to 27% benefits over IMPI and up to 15% improvement over MVAPICH2 for MiniAMR application kernel
0
100
200
300
400
500
600
700
800
28 56 112 224
Exec
uti
on
Tim
e (s
)
No. of Processes
Intel MPI
MVAPICH2
MVAPICH2-XPMEM
CNTK AlexNet Training (Broadwell, B.S=default, iteration=50, ppn=28)
0
10
20
30
40
50
60
70
16 32 64 128 256
Exec
uti
on
Tim
e (s
)
No. of Processes
Intel MPI
MVAPICH2
MVAPICH2-XPMEM20%
9%
27%
15%
14 MVAPICH2 Collectives - OFAWS 2019
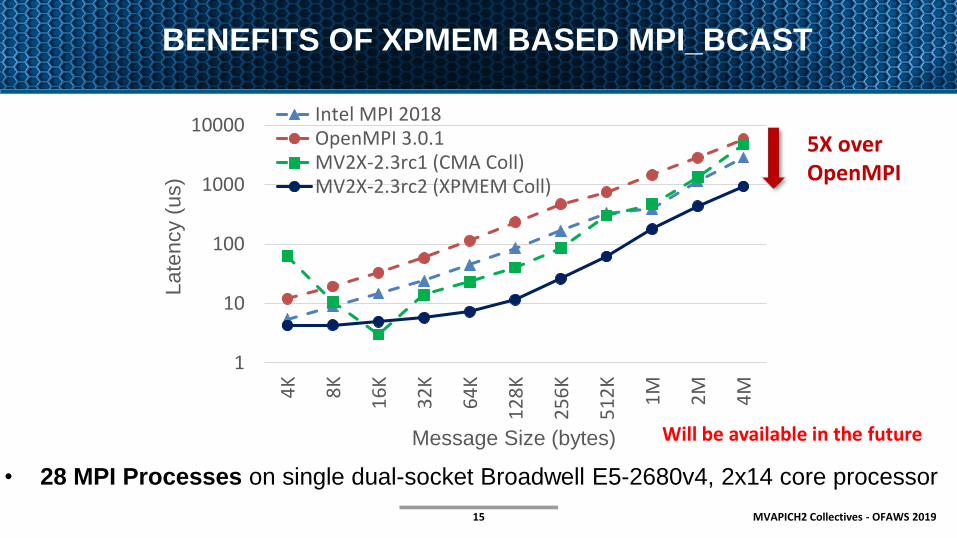
BENEFITS OF XPMEM BASED MPI_BCAST
• 28 MPI Processes on single dual-socket Broadwell E5-2680v4, 2x14 core processor
1
10
100
1000
10000
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
2M
4M
Intel MPI 2018OpenMPI 3.0.1MV2X-2.3rc1 (CMA Coll)MV2X-2.3rc2 (XPMEM Coll)
Late
ncy (
us)
5X over OpenMPI
Message Size (bytes)
MVAPICH2 Collectives - OFAWS 201915
Will be available in the future

BENEFITS OF XPMEM BASED MPI_SCATTER
• High cache-locality and contention-free access compared to CMA
1
10
100
1000
10000
100000
51
2
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
2M
4M
Intel MPI 2018OpenMPI 3.0.1MV2X-2.3rc1 (CMA Coll)MV2X-2.3rc2 (XPMEM Coll)
Late
ncy (
us)
~28X better thanstate-of-the-art
Message Size (bytes)
MVAPICH2 Collectives - OFAWS 201916
Will be available in the future

BENEFITS OF XPMEM BASED MPI_GATHER
• High cache-locality for medium messages and contention-free access
1
100
10000
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
2M
4M
Intel MPI 2018OpenMPI 3.0.1MV2X-2.3rc1 (CMA Coll)MV2X-2.3rc2 (XPMEM Coll)
Late
ncy (
us)
10X over Intel MPI
Message Size (bytes)
MVAPICH2 Collectives - OFAWS 201917
Will be available in the future

BENEFITS OF XPMEM BASED MPI_ALLTOALL
• 28 MPI Processes on single dual-socket Broadwell E5-2680v4, 2x14 core processor
1
10
100
1000
10000
100000
12
8
25
6
51
2
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
2M
4M
Intel MPI 2018
OpenMPI 3.0.1
MV2X-2.3rc1 (CMA Coll)
MV2X-2.3rc2 (XPMEM)
Late
ncy (
us)
Up to 6X over IMPI and OMPI
Message Size (bytes)
Data can’t fit in shared L3 for 28ppn Alltoall, leads to same performance as existing designs
MVAPICH2 Collectives - OFAWS 201918
Will be available in the future

▪Many-core nodes will be the foundation blocks for emerging Exascale systems
▪Communication mechanisms and runtimes need to be re-designed to take
advantage of the high concurrency offered by manycores
▪Presented a set of novel designs for collective communication primitives in
MPI that address several challenges for modern clusters
▪Demonstrated the performance benefits of our proposed designs under a
variety of multi-/many-cores and high-speed networks and a range of HPC and
DL applications
▪ These designs are already available in MVAPICH2 libraries
CONCLUDING REMARKS
19 MVAPICH2 Collectives - OFAWS 2019

THANK YOU!
Network-Based Computing Laboratoryhttp://nowlab.cse.ohio-state.edu/
[email protected], [email protected]
The High-Performance MPI/PGAS Projecthttp://mvapich.cse.ohio-state.edu/
The High-Performance Deep Learning Projecthttp://hidl.cse.ohio-state.edu/
20 MVAPICH2 Collectives - OFAWS 2019