help your enterprise implement big data with control-m for hadoop
TRANSCRIPT

© Copyright 1/15/2015 BMC Software, Inc1
Joe GoldbergSolutions Marketing
October 2014
Help your Enterprise Implement Big Data with Control-M for Hadoop

© Copyright 1/15/2015 BMC Software, Inc3
Who is using Hadoop and why?
© Copyright 1/15/2015 BMC Software, Inc4
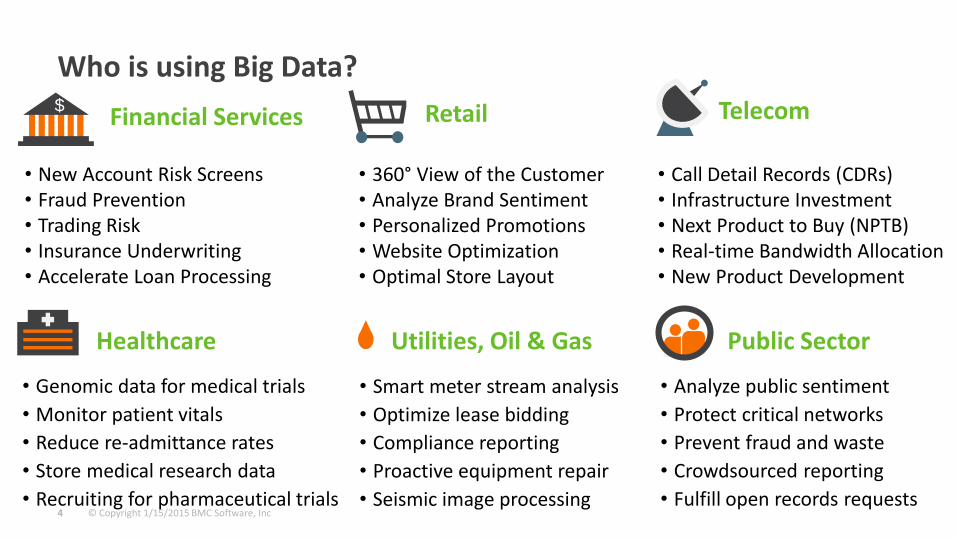
Who is using Big Data?$
• New Account Risk Screens• Fraud Prevention• Trading Risk• Insurance Underwriting• Accelerate Loan Processing
Financial Services
• 360° View of the Customer• Analyze Brand Sentiment• Personalized Promotions• Website Optimization• Optimal Store Layout
Retail
• Call Detail Records (CDRs)• Infrastructure Investment• Next Product to Buy (NPTB)• Real-time Bandwidth Allocation• New Product Development
Telecom
Healthcare
• Genomic data for medical trials
• Monitor patient vitals
• Reduce re-admittance rates
• Store medical research data
• Recruiting for pharmaceutical trials
Utilities, Oil & Gas
• Smart meter stream analysis
• Optimize lease bidding
• Compliance reporting
• Proactive equipment repair
• Seismic image processing
Public Sector
• Analyze public sentiment
• Protect critical networks
• Prevent fraud and waste
• Crowdsourced reporting
• Fulfill open records requests

© Copyright 1/15/2015 BMC Software, Inc5
Hadoop
Lots of
Data
Traditional

© Copyright 1/15/2015 BMC Software, Inc6
The Players

© Copyright 1/15/2015 BMC Software, Inc7
Building a (Hadoop) Business Service

© Copyright 1/15/2015 BMC Software, Inc8
• Identify Data Sources and Targets
• Write code
• Test
• Deploy
• Production
The Steps

© Copyright 1/15/2015 BMC Software, Inc9
© Copyright 1/15/2015 BMC Software, Inc10
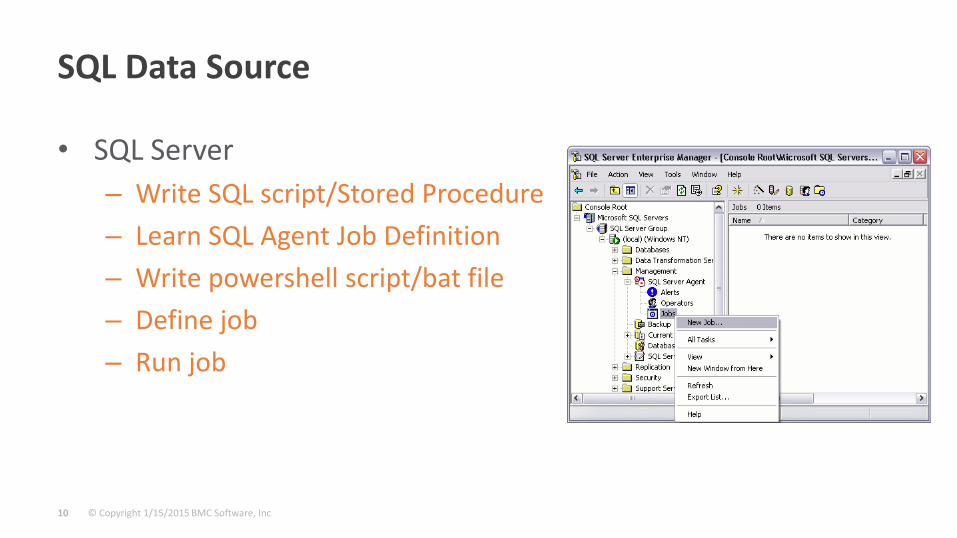
SQL Data Source
• SQL Server
– Write SQL script/Stored Procedure
– Learn SQL Agent Job Definition
– Write powershell script/bat file
– Define job
– Run job

© Copyright 1/15/2015 BMC Software, Inc11
ETL Data Source
• Informatica
– Build Informatica workflows
– Learn PowerCenter Scheduler
– Write Scripts
– Build PowerCenter job
– Run job
© Copyright 1/15/2015 BMC Software, Inc12
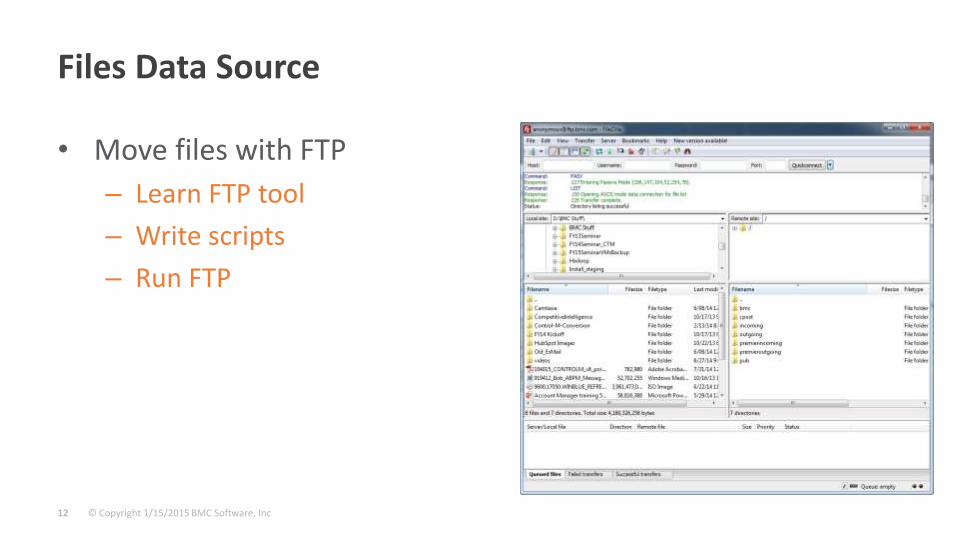
Files Data Source
• Move files with FTP
– Learn FTP tool
– Write scripts
– Run FTP
© Copyright 1/15/2015 BMC Software, Inc13
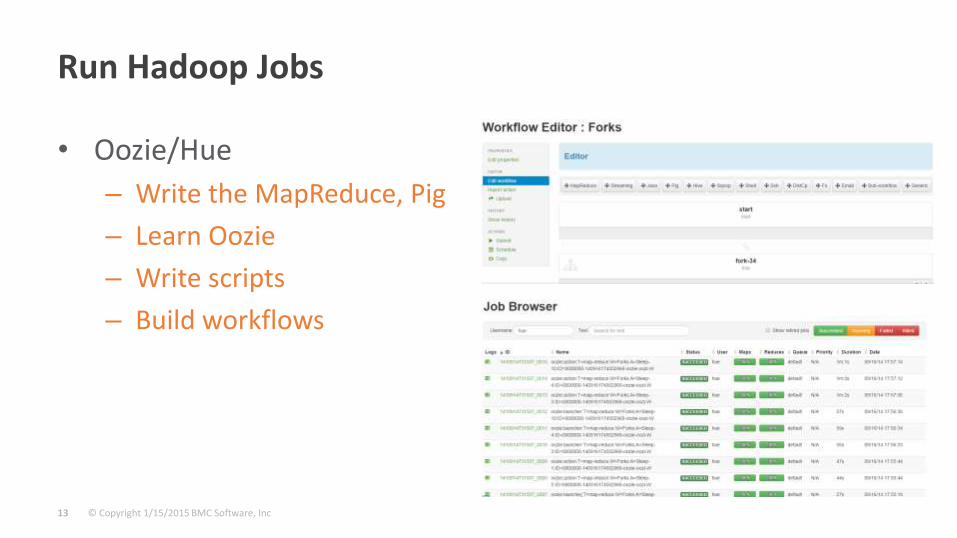
Run Hadoop Jobs
• Oozie/Hue
– Write the MapReduce, Pig
– Learn Oozie
– Write scripts
– Build workflows
© Copyright 1/15/2015 BMC Software, Inc14
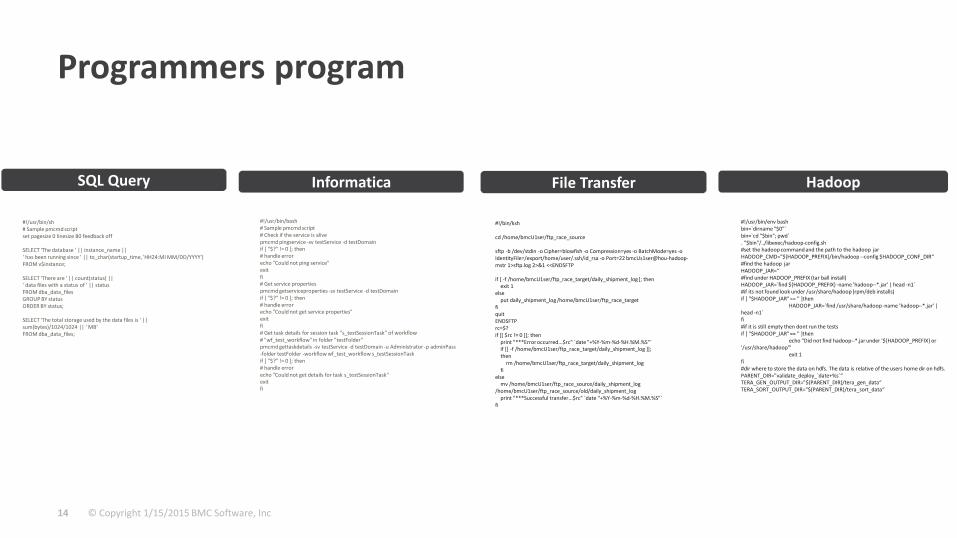
SQL Query
#!/usr/bin/sh# Sample pmcmd scriptset pagesize 0 linesize 80 feedback off
SELECT 'The database ' || instance_name ||' has been running since ' || to_char(startup_time, 'HH24:MI MM/DD/YYYY')FROM v$instance;
SELECT 'There are ' || count(status) ||' data files with a status of ' || statusFROM dba_data_filesGROUP BY statusORDER BY status;
SELECT 'The total storage used by the data files is ' ||sum(bytes)/1024/1024 || ' MB'FROM dba_data_files;
#!/usr/bin/env bashbin=`dirname "$0"`bin=`cd "$bin"; pwd`. "$bin"/../libexec/hadoop-config.sh#set the hadoop command and the path to the hadoop jarHADOOP_CMD="${HADOOP_PREFIX}/bin/hadoop --config $HADOOP_CONF_DIR“#find the hadoop jarHADOOP_JAR='‘#find under HADOOP_PREFIX (tar ball install)HADOOP_JAR=`find ${HADOOP_PREFIX} -name 'hadoop--*.jar' | head -n1`#if its not found look under /usr/share/hadoop (rpm/deb installs)if [ "$HADOOP_JAR" == '' ]then
HADOOP_JAR=`find /usr/share/hadoop -name 'hadoop--*.jar' | head -n1`fi#if it is still empty then dont run the testsif [ "$HADOOP_JAR" == '' ]then
echo "Did not find hadoop--*.jar under '${HADOOP_PREFIX} or '/usr/share/hadoop'"
exit 1fi#dir where to store the data on hdfs. The data is relative of the users home dir on hdfs.PARENT_DIR="validate_deploy_`date+%s`“TERA_GEN_OUTPUT_DIR="${PARENT_DIR}/tera_gen_data“TERA_SORT_OUTPUT_DIR="${PARENT_DIR}/tera_sort_data“
Hadoop
#!/bin/ksh
cd /home/bmcU1ser/ftp_race_source
sftp -b /dev/stdin -o Cipher=blowfish -o Compression=yes -o BatchMode=yes -o IdentityFile=/export/home/user/.ssh/id_rsa -o Port=22 bmcUs1ser@hou-hadoop-mstr 1>sftp.log 2>&1 <<ENDSFTP
if [ -f /home/bmcU1ser/ftp_race_target/daily_shipment_log ]; thenexit 1
elseput daily_shipment_log /home/bmcU1ser/ftp_race_target
fiquitENDSFTPrc=$?if [[ $rc != 0 ]]; then
print "***Error occurred...$rc" `date "+%Y-%m-%d-%H.%M.%S"`if [[ -f /home/bmcU1ser/ftp_race_target/daily_shipment_log ]]; then
rm /home/bmcU1ser/ftp_race_target/daily_shipment_logfi
elsemv /home/bmcU1ser/ftp_race_source/daily_shipment_log
/home/bmcU1ser/ftp_race_source/old/daily_shipment_logprint "***Successful transfer...$rc" ̀ date "+%Y-%m-%d-%H.%M.%S"`
fi
File TransferInformatica
#!/usr/bin/bash# Sample pmcmd script# Check if the service is alivepmcmd pingservice -sv testService -d testDomainif [ "$?" != 0 ]; then# handle errorecho "Could not ping service"exitfi# Get service propertiespmcmd getserviceproperties -sv testService -d testDomainif [ "$?" != 0 ]; then# handle errorecho "Could not get service properties"exitfi# Get task details for session task "s_testSessionTask" of workflow# "wf_test_workflow" in folder "testFolder"pmcmd gettaskdetails -sv testService -d testDomain -u Administrator -p adminPass-folder testFolder -workflow wf_test_workflow s_testSessionTaskif [ "$?" != 0 ]; then# handle errorecho "Could not get details for task s_testSessionTask"exitfi
Programmers program

© Copyright 1/15/2015 BMC Software, Inc15
What happens when this runs?
• What is related to what?• Are we on time or late?• What if something fails?
– Which program was running?– Where is the output?– How do I fix it?– Can I just rerun it? If so,
from the beginning?– Does any cleanup have to be done?– How do I track this problem and the steps
taken to resolve the problem?
#!/usr/bin/env bashbin=`dirname "$0"`bin=`cd "$bin"; pwd`. "$bin"/../libexec/hadoop-config.sh#set the hadoop command and the path to the hadoop jarHADOOP_CMD="${HADOOP_PREFIX}/bin/hadoop --config $HADOOP_CONF_DIR“#find the hadoop jarHADOOP_JAR='‘#find under HADOOP_PREFIX (tar ball install)HADOOP_JAR=`find ${HADOOP_PREFIX} -name 'hadoop--*.jar' | head -n1`#if its not found look under /usr/share/hadoop (rpm/deb installs)if [ "$HADOOP_JAR" == '' ]then
HADOOP_JAR=`find /usr/share/hadoop -name 'hadoop--*.jar' | head -n1`fi#if it is still empty then dont run the testsif [ "$HADOOP_JAR" == '' ]then
echo "Did not find hadoop--*.jar under '${HADOOP_PREFIX} or '/usr/share/hadoop'"
exit 1fi#dir where to store the data on hdfs. The data is relative of the users home dir on hdfs.PARENT_DIR="validate_deploy_`date+%s`“TERA_GEN_OUTPUT_DIR="${PARENT_DIR}/tera_gen_data“TERA_SORT_OUTPUT_DIR="${PARENT_DIR}/tera_sort_data“
Hadoop
© Copyright 1/15/2015 BMC Software, Inc16
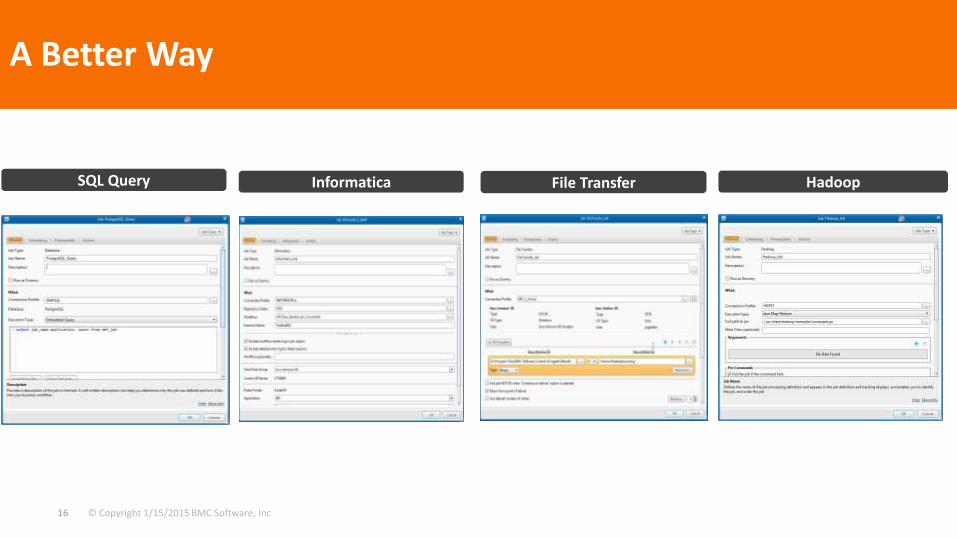
SQL Query HadoopFile TransferInformatica
A Better Way

© Copyright 1/15/2015 BMC Software, Inc17
Defining Control-M for Hadoop jobs
Set Script parameters
Hadoop Program parameters
HDFS commands• get• put• rm• move• rename
Supports all ApacheDistributions (0.x-2.x):• Cloudera• Hortonworks• MapR• Pivotal• BigInsights
© Copyright 1/15/2015 BMC Software, Inc18
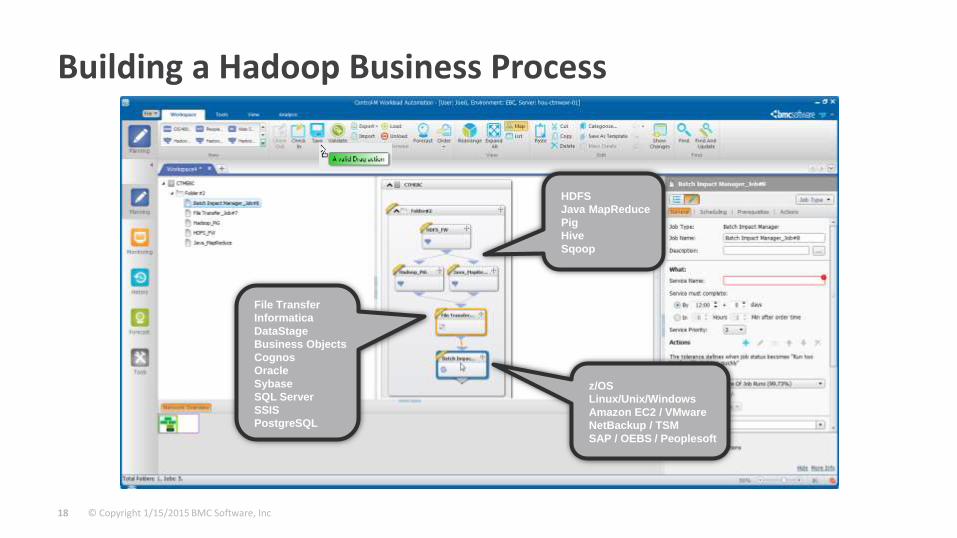
Building a Hadoop Business Process
HDFS
Java MapReduce
Pig
Hive
Sqoop
File Transfer
Informatica
DataStage
Business Objects
Cognos
Oracle
Sybase
SQL Server
SSIS
PostgreSQL
z/OS
Linux/Unix/Windows
Amazon EC2 / VMware
NetBackup / TSM
SAP / OEBS / Peoplesoft

© Copyright 1/15/2015 BMC Software, Inc19
Connection Profile
© Copyright 1/15/2015 BMC Software, Inc20
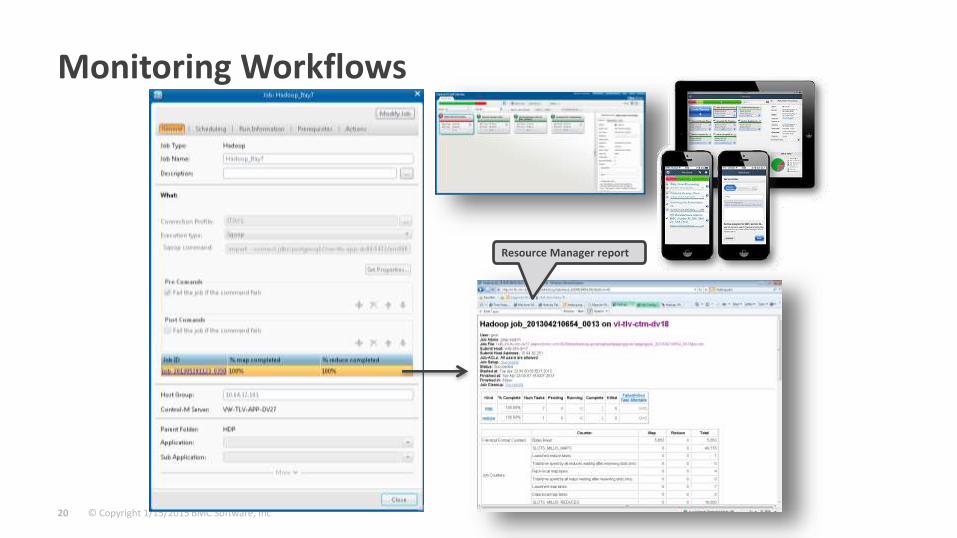
Monitoring Workflows
Resource Manager report
© Copyright 1/15/2015 BMC Software, Inc21
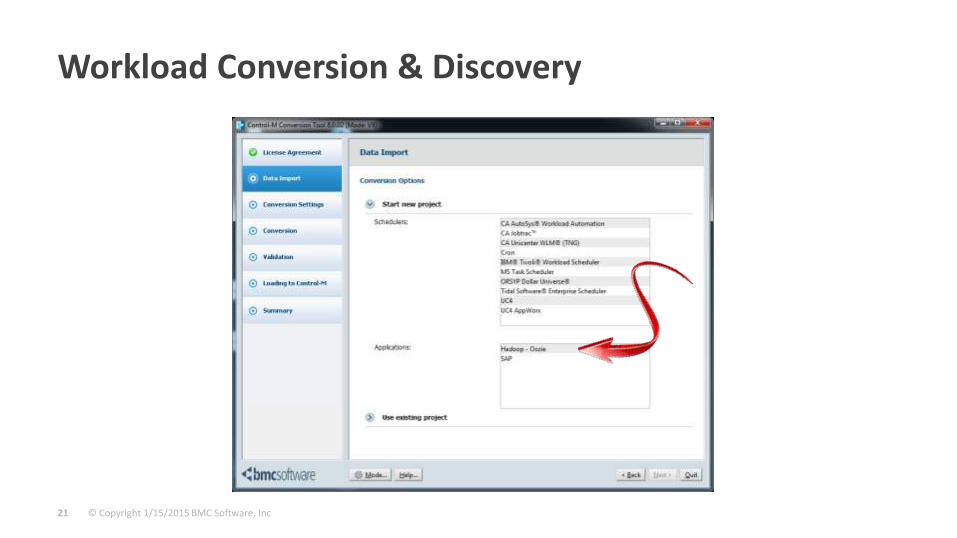
Workload Conversion & Discovery
© Copyright 1/15/2015 BMC Software, Inc22
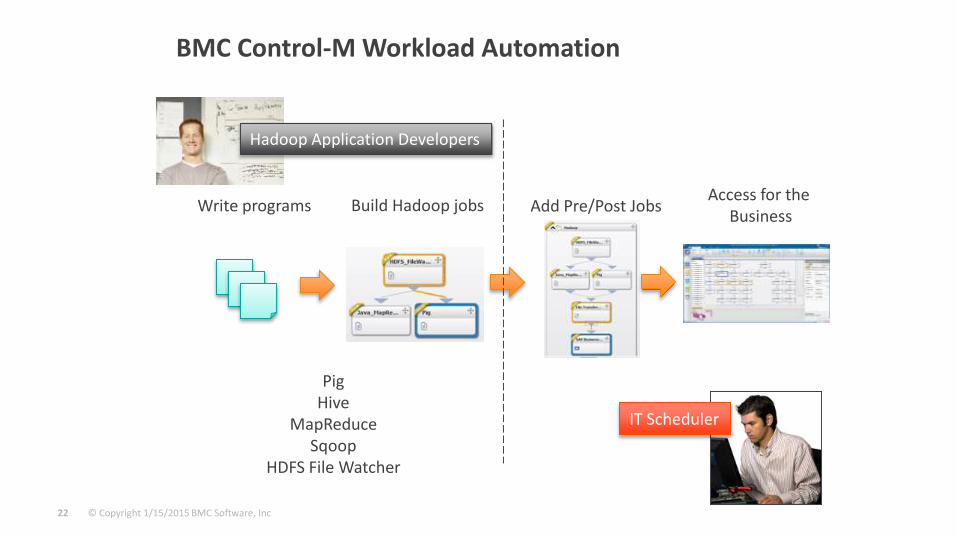
BMC Control-M Workload Automation
Hadoop Application Developers
Write programs Build Hadoop jobs Add Pre/Post JobsAccess for the
Business
IT Scheduler
PigHive
MapReduceSqoop
HDFS File Watcher

© Copyright 1/15/2015 BMC Software, Inc23
And the fun is just beginning…

© Copyright 1/15/2015 BMC Software, Inc24
Partner
Why BMC Control-M for Hadoop?

© Copyright 1/15/2015 BMC Software, Inc25
Key Takeaways
Eliminate scripting with built-in capabilities
Reduce the complexity of building and testing applications
Production Applications run more reliably, are easier to monitor and ensure compliance
Big Data and Hadoop are coming to your Data Center
Easily build composite applications leveraging the full power of your technology fabric
Build Applications Faster Increase Service Quality Gain Business Agility

© Copyright 1/15/2015 BMC Software, Inc26
For Additional Information: www.bmc.com/hadoop

© Copyright 1/15/2015 BMC Software, Inc27
Thank You.Be sure to visit Control-M Labs