hadoop101 - distributed matters · hadoop101 lars&george&...
TRANSCRIPT

1
Hadoop 101 Lars George NoSQL-‐Ma4ers, Cologne – April 26, 2013

What’s Ahead?
• Overview of Apache Hadoop (and related tools) • What it is • Why it’s relevant • How it works
• No prior experience needed • Feel free to ask quesQons

About Me
• Director EMEA Services @ Cloudera • ConsulQng on Hadoop projects (everywhere)
• Apache Commi4er • HBase and Whirr
• O’Reilly Author • HBase – The DefiniQve Guide
• Now in Japanese!
• Contact • [email protected] • @larsgeorge
日本語版も出ました!

What is Apache Hadoop?
• A scalable data storage and processing system • An open source Apache project • Hadoop clusters are built from standard hardware • Distributed and fault-‐tolerant • Widely implemented by many organizaQons

What Does Apache Hadoop Offer?
• Core Hadoop offers two key features • Storage: Hadoop Distributed File System (HDFS) • Processing: MapReduce
• Other related tools provide addiQonal capabiliQes • This includes Hive, Sqoop, Flume, and Mahout • CollecQvely known as the Hadoop ecosystem

Why Do We Need Apache Hadoop?
• Let’s explore this first • Then we’ll delve into technical details acerwards

We Generated Li4le Data Before
• Consider an evening of dinner and a movie (1992) • Look up restaurant in phone book • Consult map (on paper!) for direcQons • Drive to restaurant • Pay with cash • Check newspaper for movie showQmes • Buy Qcket at box office window
• Not much data is being generated here… • That’s OK, because storage cost > $3500/GB back then

We Generate Lots of Data Now
• Consider a similar evening in 2012 • Look up restaurant using Yelp on mobile phone • Use phone’s map socware to find the restaurant • Check into restaurant on Foursquare • Pay with credit card • Watch movie online via Nenlix Streaming • Tweet about how bad the movie was
• Lots of data being generated here… • That’s OK, because storage only costs $0.05/GB now

The Value of Volume
• One tweet is an anecdote • But a million tweets may signal important trends
• One person’s product review is an opinion • But a million reviews might uncover a design flaw
• One person’s diagnosis is an isolated case • But a million medical records could idenQfy the cause
• TradiQonal tools can’t handle “big data” • But Hadoop scales well into the petabytes

How Are OrganizaQons Using Hadoop?
• Just a few examples... • AnalyQcs • Product recommendaQons • Ad targeQng • Fraud detecQon • Natural language processing • Route opQmizaQon

Where Did Hadoop Come From?
• Spinoff of Apache Nutch • Inspired by two Google publicaQons
• The Google File System • MapReduce: Simplified Data Processing on Large Clusters

Hallmarks of Hadoop’s Design
• Machine failure is unavoidable – embrace it • Build reliability into the system • “More” is usually be4er than “faster” • Throughput is more important than latency • Network bandwidth is a precious resource • You have far more data than code

HDFS: Hadoop Distributed File System
• Inspired by the Google File System • Provides low-‐cost storage for massive amounts of data
• Not a general purpose filesystem • Highly opQmized for processing data with MapReduce • Cannot modify file content once wri4en • It’s actually a user-‐space Java process • Accessed using special commands or APIs

HDFS Blocks
• When data is loaded into HDFS, it’s split into blocks • Blocks are of a fixed size (64 MB by default) • These are huge when compared to UNIX filesystems
230 MB Input File
Block 1 (64 MB)
Block 2 (64 MB)
Block 3 (64 MB)
Block 4 (38 MB)

HDFS ReplicaQon
• Each block is then replicated to mulQple machines • Default replicaQon factor is three (but configurable)
Block 1 (64 MB)
Slave node B
Slave node C
Slave node D
Slave node A
Slave node E

HDFS Demo
• I will now demonstrate the following 1. How to create a directory in HDFS 2. How to copy a local file to HDFS 3. How to display the contents of a file in HDFS 4. How to remove a file from HDFS

Basic HDFS Architecture
• NameNode: HDFS Master daemon • Manages namespace and metadata • Only one NameNode per cluster *
• DataNode: HDFS slave daemon • Provides storage and retrieval for data blocks

HDFS Architectural VariaQons
• Secondary NameNode • Performs periodic merges on the NameNode’s data • Despite the name, this does not provide failover
• High Availability (reliability) • AcQve/standby configuraQon • Standby NameNode replaces older Secondary NameNode
• HDFS federaQon (scalability) • MulQple namespaces per cluster • Independent of high availability

MapReduce IntroducQon
• MapReduce is a programming model • It’s a way of processing data • You can implement MapReduce in any language
• MapReduce has its roots in funcQonal programming • Many languages have funcQons named map and reduce • These funcQons have largely the same purpose in Hadoop
• Popularized for large-‐scale processing by Google • MapReduce processing in Hadoop is batch-‐oriented

MapReduce Benefits
• Scalability • Hadoop divides the processing job into individual tasks • Tasks execute in parallel (independently) across cluster
• Simplicity • Each task receives one input record • Each task emits zero or more output records
• Ease of use • Hadoop provides job scheduling and other infrastructure • Don’t have to write any file or network I/O code
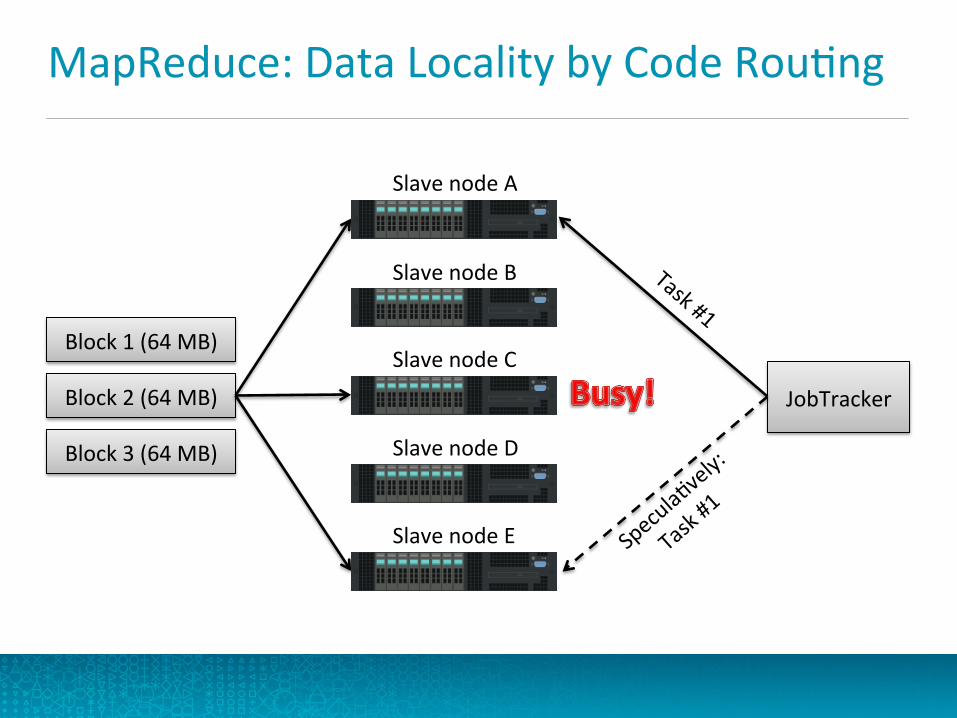
MapReduce: Data Locality by Code RouQng
Block 2 (64 MB)
Slave node B
Slave node C
Slave node D
Slave node A
Slave node E
Block 3 (64 MB)
Block 1 (64 MB)
JobTracker

MapReduce Architecture
• Like HDFS, MapReduce in Hadoop is master/slave • JobTracker is the master daemon
• One per cluster • Performs job scheduling and monitoring
• TaskTracker is the slave daemon • Many per cluster • Executes the individual tasks that make up a job • Collocated with DataNode daemon (data locality)

MapReduce Code for Hadoop
• Usually wri4en in Java • This uses Hadoop’s API directly • Data is passed as parameters to Map and Reduce methods • Output is emi4ed via Java method calls
• You can do basic MapReduce in other languages • Using the Hadoop Streaming wrapper program • Map and Reduce funcQons use STDIN / STDOUT for data • Some advanced features require Java code

MapReduce Example in Python
• The following example uses Python • Via Hadoop Streaming
• It processes log files and summarizes events by type • I’ll explain both the data flow and the code
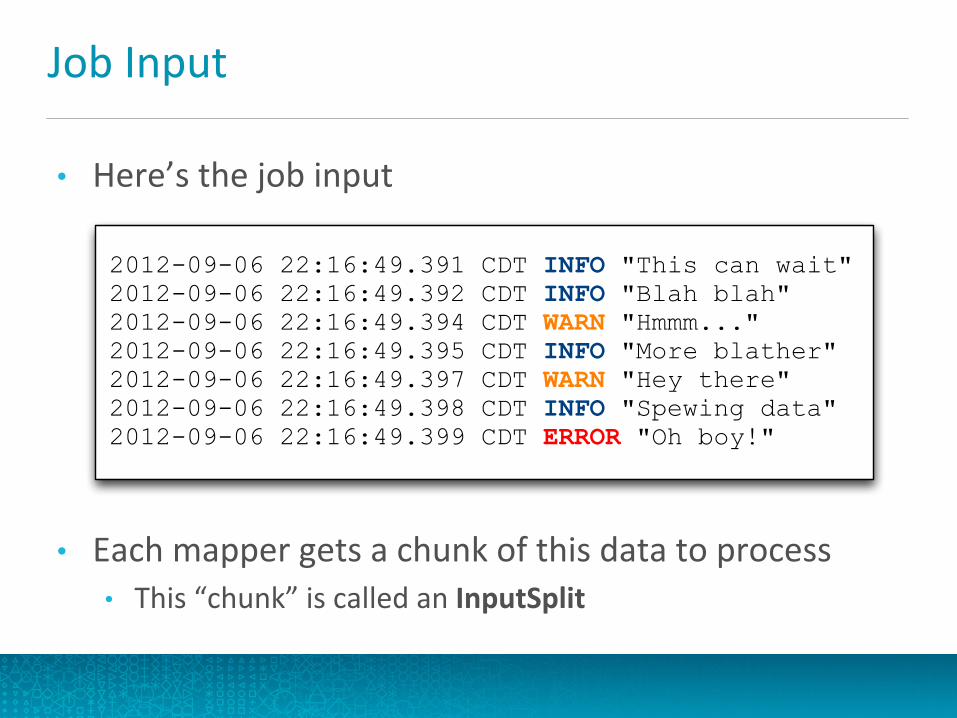
Job Input
• Here’s the job input
• Each mapper gets a chunk of this data to process • This “chunk” is called an InputSplit
2012-09-06 22:16:49.391 CDT INFO "This can wait"2012-09-06 22:16:49.392 CDT INFO "Blah blah"2012-09-06 22:16:49.394 CDT WARN "Hmmm..."2012-09-06 22:16:49.395 CDT INFO "More blather"2012-09-06 22:16:49.397 CDT WARN "Hey there"2012-09-06 22:16:49.398 CDT INFO "Spewing data"2012-09-06 22:16:49.399 CDT ERROR "Oh boy!"

#!/usr/bin/env python import sys levels = ['TRACE', 'DEBUG', 'INFO', 'WARN', 'ERROR', 'FATAL'] for line in sys.stdin: fields = line.split() for field in fields: field = field.strip().upper() if field in levels: print "%s\t1" % field
1 2 3 4 5 6 7 8 9
10 11 12 13
Python Code for Map FuncQon
• Our map funcQon will parse the event type • And then output that event (key) and a literal 1 (value)
If this field matches a log level, print it, a tab separator, and the literal value 1
Split every line (record) we receive on standard input into fields, normalized by case
Define list of known log events

Output of Map FuncQon
• The map funcQon produces key/value pairs as output
INFO 1INFO 1WARN 1INFO 1WARN 1INFO 1ERROR 1

Input to Reduce FuncQon
• The Reducer receives a key and all values for that key
• Keys are always passed to reducers in sorted order • Although not obvious here, values are unordered
ERROR 1INFO 1INFO 1INFO 1INFO 1WARN 1WARN 1

Python Code for Reduce FuncQon
• The Reducer extracts the key and value it was passed
#!/usr/bin/env python import sys previous_key = '' sum = 0 for line in sys.stdin: key, value = line.split() value = int(value) # continued on next slide
1 2 3 4 5 6 7 8 9
10 11 12 13
IniQalize loop variables
Extract the key and value passed via standard input

Python Code for Reduce FuncQon
• Then simply adds up the value for each key
# continued from previous slide if key == previous_key: sum = sum + value else: if previous_key != '': print '%s\t%i' % (previous_key, sum) previous_key = key sum = 1 print '%s\t%i' % (previous_key, sum)
14 15 16 17 18 19 20 21 22 23
If key unchanged, increment the count
Print sum for final key
If key changed, print sum for previous key
Re-‐init loop variables

Output of Reduce FuncQon
• Its output is a sum for each level
ERROR 1INFO 4WARN 2
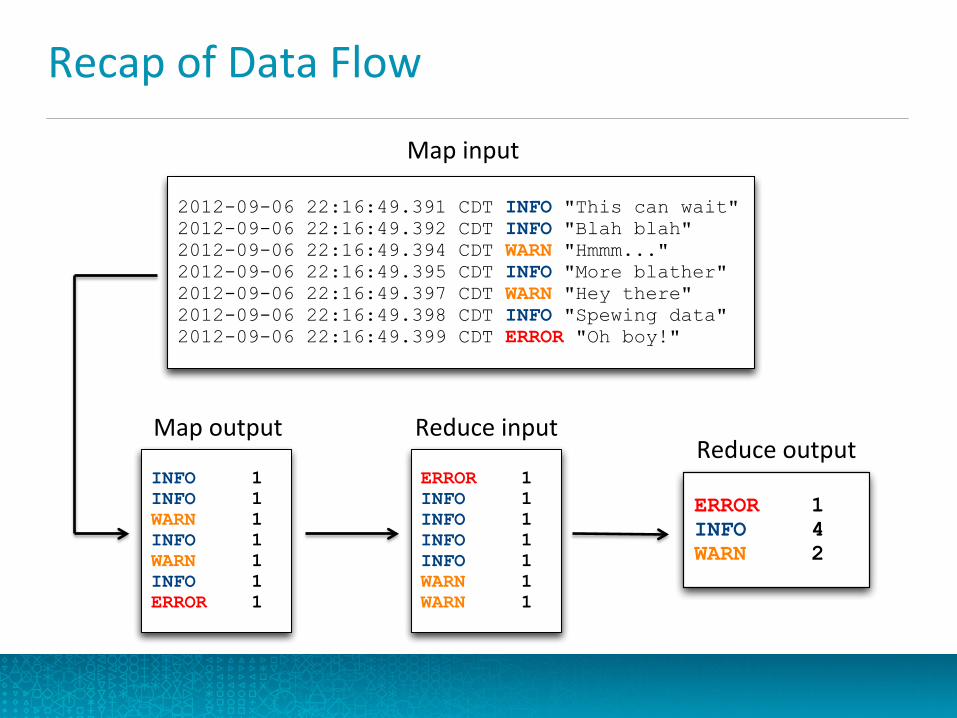
Recap of Data Flow
ERROR 1INFO 4WARN 2
2012-09-06 22:16:49.391 CDT INFO "This can wait"2012-09-06 22:16:49.392 CDT INFO "Blah blah"2012-09-06 22:16:49.394 CDT WARN "Hmmm..."2012-09-06 22:16:49.395 CDT INFO "More blather"2012-09-06 22:16:49.397 CDT WARN "Hey there"2012-09-06 22:16:49.398 CDT INFO "Spewing data"2012-09-06 22:16:49.399 CDT ERROR "Oh boy!"
INFO 1INFO 1WARN 1INFO 1WARN 1INFO 1ERROR 1
ERROR 1INFO 1INFO 1INFO 1INFO 1WARN 1WARN 1
Map input
Map output Reduce input Reduce output

How to Run a Hadoop Streaming Job
• I’ll demonstrate this now…

Hadoop Ecosystem – Example CDH
STORAGE
RESOURCE MGMT & COORDINATION
BATCH COMPUTE
BATCH PROCESSING
USER INTERFACE WORKFLOW MGMT METADATA CLOUD
REAL-‐TIME ACCESS & COMPUTE
INTEGRATION
YA YARN
ZO ZOOKEEPER
HDFS HADOOP DFS
HB HBASE
MR MAPREDUCE
MR2 MAPREDUCE2
HI HIVE
PI PIG
MA MAHOUT
HU HUE
OO OOZIE
WH WHIRR
SQ SQOOP
FL FLUME
FILE FUSE-‐DFS
REST WEBHDFS HTTPFS
SQL ODBC JDBC
AC ACCESS
MS META STORE
DF DATAFU
IM IMPALA
SE SEARCH
MANAGEMENT
CLOUDERA NAVIGATOR
CLOUDERA MANAGER
CORE (REQUIRED)
RTD RTQ
BDR
AUDIT (v1.0) LINEAGE
ACCESS (v1.0) LIFECYCLE
EXPLORE
CORE

Apache Flume
• Copies data into HDFS as it’s generated • Can handle a variety of input sources
• Data appended to log files • UNIX syslog • Output from programs • Data received on network ports • Custom sources

Apache Sqoop
• Database integraQon for HDFS • CompaQble with any database via JDBC driver • High-‐performance custom connectors available for others
• Can import database tables into HDFS • All tables from a DB, a single table, or a porQon of a table
• Can also export data from HDFS back to a database

Apache Hive and Apache Pig
• High-‐level processing for data stored in HDFS • Hive uses a SQL-‐like language called HiveQL • Pig uses a more procedural language called PigLaQn
• AlternaQve to wriQng MapReduce code • Reduces development Qme and increases producQvity
• But they have the same latency as MapReduce • Because they create MapReduce jobs that run on cluster

Apache HBase
• High-‐performance NoSQL database built on HDFS • Based on Google’s BigTable paper
• Very scalable • Low latency data access • No high-‐level query language

Cloudera’s Impala
• Offers the benefits of both Hive and HBase • Scalability • Performance • High-‐level query language (subset of SQL-‐92)
• Announced at Hadoop World + Strata in October • Open source and available under Apache License • Download the beta from Cloudera Web site

Other Notable Ecosystem Components
• Apache Whirr • Libraries for running cloud-‐based services
• Apache Mahout • Scalable machine learning libraries
• Apache Oozie • Workflow management for Hadoop jobs
• Apache ZooKeeper • SynchronizaQon services for distributed systems

Typical Stack Architectures
STORA
GE
MAP
RED
UCE
QUER
Y
HDFS HADOOP DFS
MR MAPREDUCE
IM IMPALA
MR MAPREDUCE
INGEST
SQ SQOOP
FL FLUME
REST WEBHDFS HTTPFS
SQL ODBC JDBC
HDFS HADOOP DFS
HDFS HADOOP DFS
MR MAPREDUCE
HB HBASE
HI HIVE
PI PIG
JA JAVA MR
HI HIVE
PI PIG
JA JAVA MR
HI HIVE
PI PIG
JA JAVA MR
BATCH w/ READ ONLY BATCH w/ RANDOM WRITE BATCH OR REAL TIME QUERY
OUTGEST
SQ SQOOP
FL FLUME
REST WEBHDFS HTTPFS
SQL ODBC JDBC
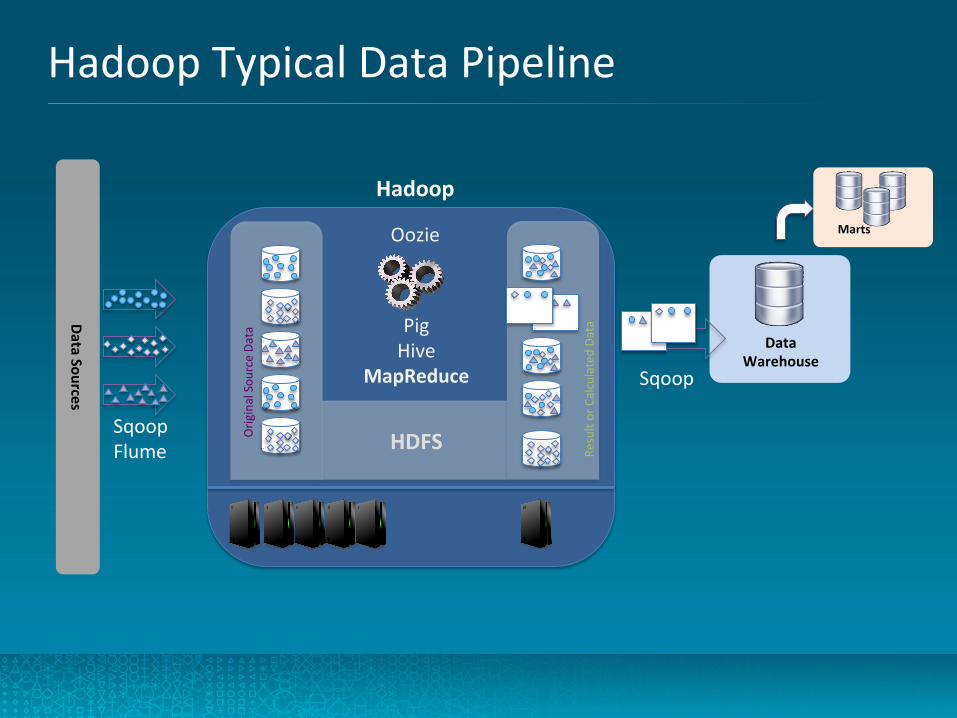
Hadoop Typical Data Pipeline
Data Sources
Pig Hive
MapReduce
HDFS Orig
inal Sou
rce Da
ta
Result or Calculated Da
ta
Data Warehouse
Marts
Sqoop
Hadoop
Oozie
Sqoop Flume

Conclusion
• Apache Hadoop: scalable data storage + processing • HDFS (storage) • MapReduce (processing)
• The Hadoop ecosystem includes addiQonal tools • Help integrate Hadoop with other systems • Make it easier to analyze data in HDFS

Next Steps…
• Cloudera’s DistribuQon including Apache Hadoop • Not just Hadoop, but also Hive, Pig, HBase, Mahout, etc. • Free and 100% open source (Apache license) • Easy to install packages • Can download a virtual machine with CDH pre-‐installed

Highly Recommended Books
Tom White ISBN: 1-‐449-‐31152-‐0
Eric Sammer ISBN: 1-‐449-‐32705-‐2

46
Thank You! Lars George, Director EMEA Services Cloudera, Inc.