friends of solr - nutch & hdfs
DESCRIPTION
Solr integration with Apache Nutch and HDFSTRANSCRIPT

Friends of Solr - “Nutch and HDFS”
Saumitra Srivastav [email protected]
Bangalore Apache Solr Group September-2014 Meetup

Friends

Friend #1 Nutch

What is Nutch?
- Distributed framework for large scale web crawling - but does not have to be large scale at all
- Based on Apache Hadoop
- Direct integration with Solr
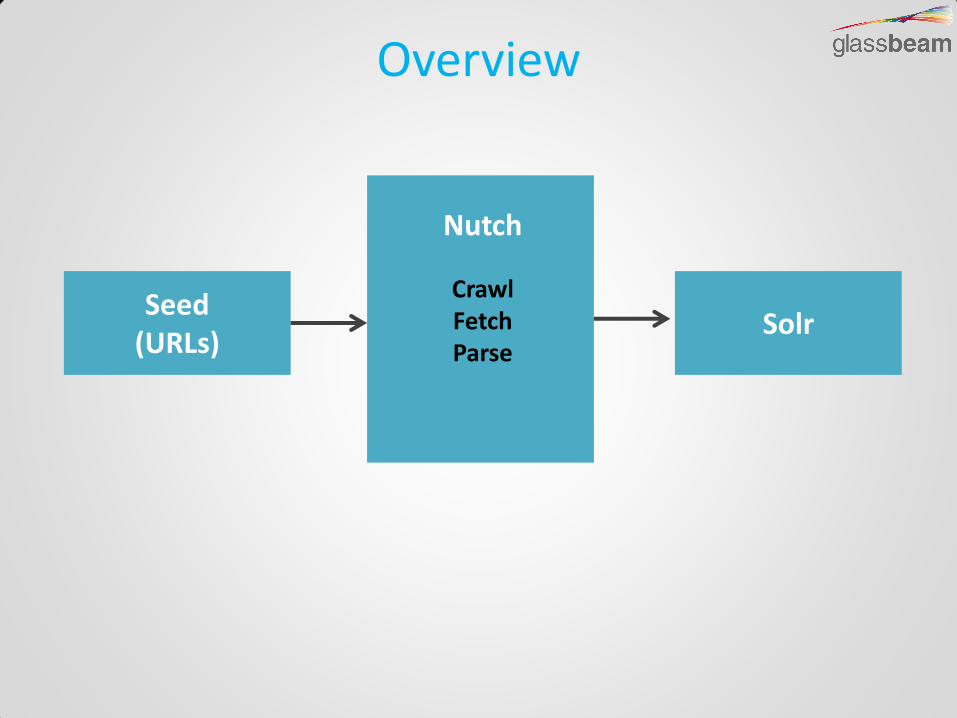
Overview
Seed (URLs)
Solr
Nutch
Crawl Fetch Parse
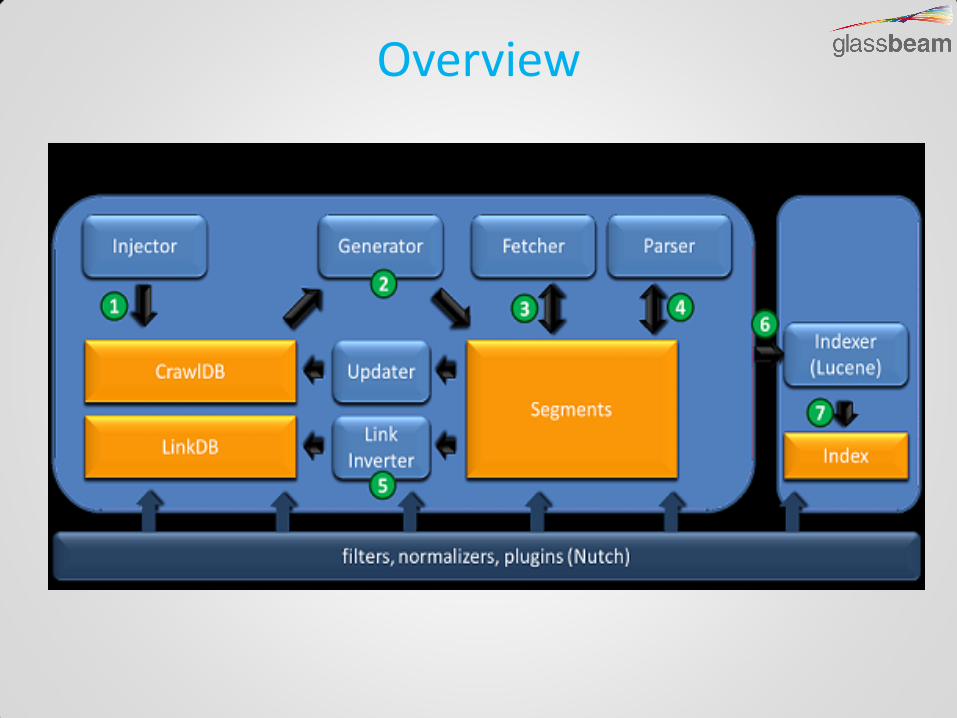
Overview

Components
- CrawlDB - Info about URLs
- LinkDB - Info about links to each URL
- Segments - set of URLs that are fetched as a unit

Segments 1. crawl_generate
- set of URLs to be fetched
2. crawl_fetch - status of fetching each URL
3. content - raw content retrieved from each URL
4. parse_text - parsed text of each URL
5. parse_data - outlinks and metadata parsed from each URL
6. crawl_parse - outlink URLs, used to update the crawldb

Scale
- Scalable storage - HDFS
- Scalable crawling - Map-Reduce
- Scalable search - SolrCloud
- Scalable backend - Gora

Features
- Fetcher - Multi-threaded fetcher - Queues URLs per hostname / domain / IP - Limit the number of URLs for round of fetching - Default values are polite but can be made
more aggressive

Features
- Crawl Strategy - Breadth-first but can be depth-first - Configurable via custom ScoringFilters

Features
- Scoring - OPIC (On-line Page Importance Calculation) by
default - LinkRank
- Protocols - Http, file, ftp, https - Respects robots.txt directives

Features
- Scheduling - Fixed or adaptive
- URL filters - Regex, FSA, TLD, prefix, suffix
- URL normalisers - Default, regex

Features
- Parsing with Apache Tika - Hundreds of formats supported - But some legacy parsers as well
- Plugins - Feeds, Language Identification etc.
- Pluggable indexing - Solr, ES etc.

Common crawled fields
- url - content - title - anchor - site - boost - digest - segment - host - type - arbitrary metadata

Setup
- Download binary and unzip - http://nutch.apache.org/downloads.html
- Conf Directory

Solr Schema

Solr-Nutch Mapping

Indexing crawled data to Solr
- Add agent.name in nutch-default.xml
- Copy fields from schema.xml to a core/collection in Solr
- create seed directory - bin/crawl <seedDir> <crawlDir> <solrURL>
<numberOfRounds>

Friend #2 HDFS

Why integrate with Hadoop?
- Hadoop is NOT AT ALL needed to scale your Solr installation
- Hadoop is NOT AT ALL needed for Solr distributed capabilities

Why integrate with Hadoop?
- Integrate Solr with HDFS when your whole pipeline is hadoop based
- Avoid moving data and indexes in and out
- Avoid multiple sinks
- Avoid redundant provisioning for Solr - Individual nodes disk, etc

Solr + Hadoop
- Read and write directly to HDFS
- build indexes for Solr with Hadoop's map-reduce

Lucene Directory Abstraction
Class Directory { listAll(); createOutput(file, context); openInput(file, context); deleteFile(file); makeLock(file); clearLock(file); ... ... }

HdfsDirectory

Index in HDFS
- writing and reading index and transaction log files to the HDFS
- does not use Hadoop Map-Reduce to process Solr data
- Filesystem cache needed for Solr performance
- HDFS not fit for random access

Block Cache
- enables Solr to cache HDFS index files on read and write
- LRU semantics - Hot blocks are cached
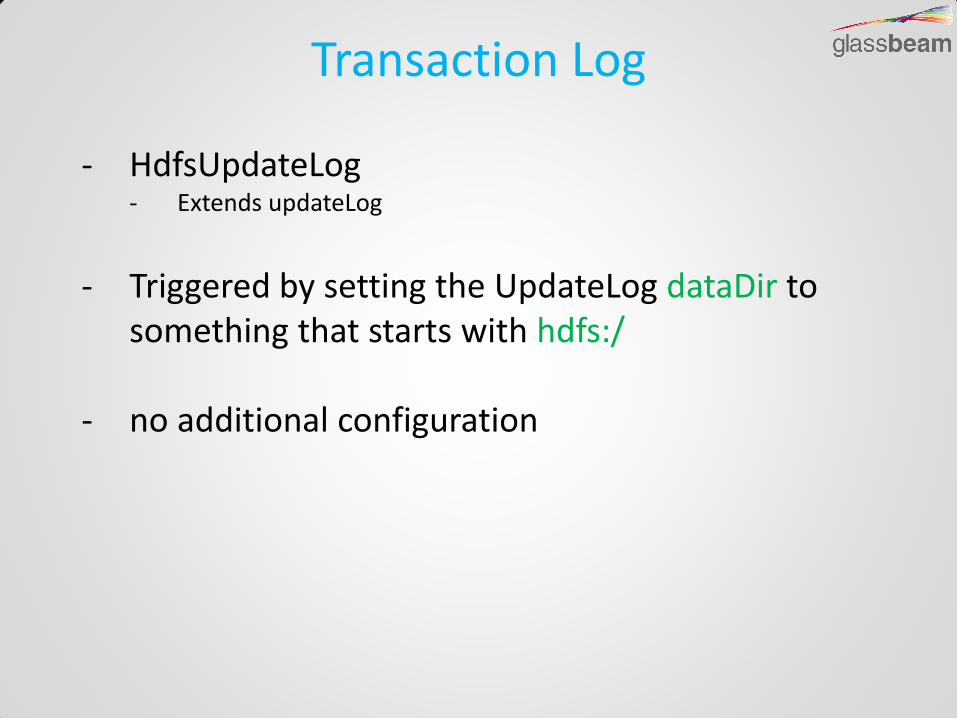
Transaction Log
- HdfsUpdateLog - Extends updateLog
- Triggered by setting the UpdateLog dataDir to
something that starts with hdfs:/
- no additional configuration

Running Solr on HDFS
Cloud mode java -Dsolr.directoryFactory=HdfsDirectoryFactory -Dsolr.lock.type=hdfs -Dsolr.hdfs.home=hdfs://localhost:5432/solr/ -DzkHost=localhost:2181 -jar start.jar

Map-Reduce index building
- Scalable index creation via map-reduce
- https://github.com/markrmiller/solr-map-reduce-example

Map-Reduce index building
- initial implementations sent documents from reducer to SolrCloud over http - Not scable
- Reducers create indexes in HDFS

Map-Reduce index building
- Reducers create indexes in HDFS
- merge the indexes down to the correct number of ‘shards’
- zookeeper aware
- Go-Live
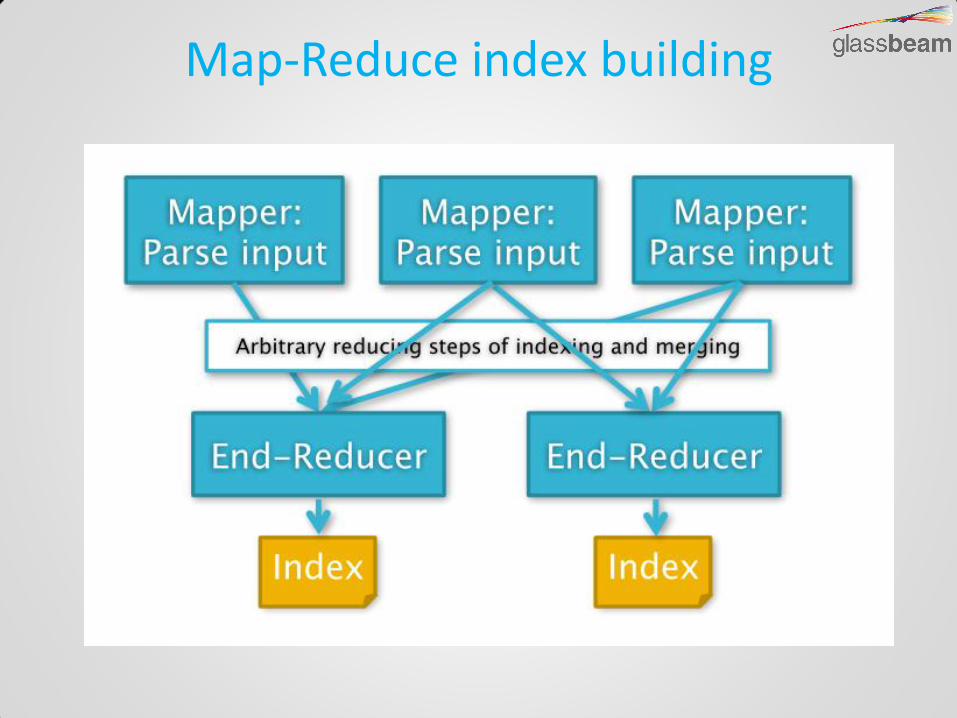
Map-Reduce index building

MorphLines
- A morphline is a configuration file that allows you to define ETL transformation pipelines
- replaces Java programming with simple configuration steps
- Extract content from input files, transform content, load content
- Uses Tika to extract content from a large variety of input documents

MorphLines SOLR_LOCATOR : { collection : collection1 zkHost : "127.0.0.1:9983" batchSize : 100 } morphlines : [ { id : morphline1 importCommands : ["org.kitesdk.**", "org.apache.solr.**"] commands : [ { readAvroContainer { ... } } { extractAvroPaths {...} } { convertTimestamp {...} } { sanitizeUnknownSolrFields {...} } { loadSolr {...} } .... ] } ]

Map-Reduce index building
bin/hadoop --config /tmp/hadoop/sample1 jar ~/softwares/solr/solr-4.10.0/dist/solr-map-reduce-*.jar -D 'mapred.child.java.opts=-Xmx500m' -libjars "$HADOOP_LIBJAR" --morphline-file /tmp/readAvroContainer.conf --zk-host localhost:2181 --output-dir hdfs://localhost/outdir --collection twitter --log4j log4j.properties --go-live --verbose "hdfs://localhost/indir"

Thanks
- Attributions • Julien Nioche’s slides on “Large scale crawling with Apache Nutch” • Mark Miller’s slides on “First Class Integration of Solr with
Hadoop”
- Connect
• [email protected] • [email protected] • https://www.linkedin.com/in/saumitras • @_saumitra_
- Join:
• http://www.meetup.com/Bangalore-Apache-Solr-Lucene-Group/