hadoop overview - portland sql user group - oregon...
TRANSCRIPT

© Hortonworks Inc. 2013 - Confidential
Hadoop Overview - Portland SQL User Group Ajay Singh – Director, Partner Solutions 2/12/2014
Page 1

© Hortonworks Inc. 2013 - Confidential
Why Hadoop
Page 2

© Hortonworks Inc. 2013 - Confidential
Connected & Instrumented - Generating Exhaust & Insight
Page 3

© Hortonworks Inc. 2013 - Confidential
Data Platforms Pressured
Data Growth
Source: IDCç
New Sources (sen-ment, clickstream, geo, sensor, …)
2.8 ZB in 2012
85% from Usage Data
15x Machine Data by 2020
40 ZB by 2020

© Hortonworks Inc. 2013 - Confidential
Dealing with Data Tsunami
• Create Silos
• Age data to tape
• Sample
• Purge
• Re-architect – Over investment in existing architecture is not a viable strategy
Page 5

© Hortonworks Inc. 2013 - Confidential
Wide Range of New Technologies
NoSQL Storage Arrays
Hadoop MPP
Cloud Search Engine
BigTable
NewSQL
COST EFFECTIVE, FLEXIBLE, STORAGE & PROCESSING at SCALE

© Hortonworks Inc. 2013 - Confidential
Modern Data Architecture Enabled
Page 7
APPLICAT
IONS
DATA
SYSTEM
REPOSITORIES
SOURC
ES
Exis-ng Sources (CRM, ERP, POS)
RDBMS EDW MPP
Emerging Sources (Sensor, Sen-ment, Geo, Logs,
Clickstream)
OPERATIONAL TOOLS
MANAGE & MONITOR
DEV & DATA TOOLS
BUILD & TEST
Business Analy-cs
Custom Applica-ons
Packaged Applica-ons

© Hortonworks Inc. 2013 - Confidential
Realizing Value From Hadoop
Page 8

© Hortonworks Inc. 2013
20 Business Applications of Hadoop Vertical Use Case Data Type
Financial Services
New Account Risk Screens Text, Server Logs
Fraud Prevention Server Logs
Trading Risk Server Logs
Maximize Deposit Spread Text, Server Logs
Insurance Underwriting Geographic, Sensor, Text
Accelerate Loan Processing Text
Telecom
Call Detail Records (CDRs) Machine, Geographic
Infrastructure Investment Machine, Server Logs
Next Product to Buy (NPTB) Clickstream
Real-time Bandwidth Allocation Server Logs, Text, Sentiment
New Product Development Machine, Geographic
Retail
360° View of the Customer Clickstream, Text
Analyze Brand Sentiment Sentiment
Localized, Personalized Promotions Geographic
Website Optimization Clickstream
Optimal Store Layout Sensor
Manufacturing
Supply Chain and Logistics Sensor
Assembly Line Quality Assurance Sensor
Proactive Maintenance Machine
Crowdsourced Quality Assurance Sentiment

© Hortonworks Inc. 2013 - Confidential
Who is Hortonworks
Page 10

© Hortonworks Inc. 2013 - Confidential
We Do Hadoop
Page 11

© Hortonworks Inc. 2013 - Confidential
Hortonworks & Hadoop: A Long History
Page 12
2013
Focus on INNOVATION 2005: Yahoo! creates Hadoop
Focus on OPERATIONS 2008: Yahoo team extends focus to
operations to support multiple projects & growing clusters
Yahoo! begins to Operate at scale
Enterprise Hadoop
Apache Project Established
Hortonworks Data Platform
2004 2008 2010 2012 2006
STABILITY 2011: Hortonworks created to focus
on “Enterprise Hadoop“. Starts with 24 key Hadoop engineers from Yahoo

© Hortonworks Inc. 2013 - Confidential
Driving Our Innovation Through Apache
147,933 lines
614,041 lines
End Users 449,768 lines
Total Net Lines Contributed to Apache Hadoop
Yahoo: 10 Cloudera: 7
IBM: 3
10 Others
21
Facebook: 5
LinkedIn: 3
Total Number of Committers to Apache Hadoop
63 total
Hortonworks mission is to enable your modern data architecture by delivering one Enterprise Hadoop that deeply integrates
with your data center technologies
Page 13
Apache Project Committers PMC
Members
Hadoop 21 13
Tez 10 4
Hive 11 3
HBase 8 3
Pig 6 5
Sqoop 1 0
Ambari 20 12
Knox 6 2
Falcon 2 2
Oozie 2 2
Zookeeper 2 1
Flume 1 0
Accumulo 2 2
TOTAL 93 48
Total Committers Across Apache Projects

© Hortonworks Inc. 2013 - Confidential
UDA Diagram
Relying on Hortonworks…
Rackspace Portfolio for Hadoop
• Hybrid Cloud: Best-fit architecture for your application and business needs
• Open Technologies • Fanatical Support
Page 14
HDInsight & HDP for Windows
• Only Hadoop Distribution for Windows Azure & Windows Server
• Native integration with SQL Server, Excel, and System Center
• Extends Hadoop to .NET community
Instant Access + Infinite Scale
• SAP can assure their customers they are deploying an SAP HANA + Hadoop architecture fully supported by SAP
• Enables analytics apps (BOBJ) to interact with Hadoop

© Hortonworks Inc. 2013 - Confidential
Hortonworks Data Platform
Page 15

© Hortonworks Inc. 2013 - Confidential
HDP: Enterprise Hadoop Platform
Page 16
Hortonworks Data Platform (HDP)
• The ONLY 100% open source and complete platform
• Integrates full range of enterprise-ready services
• Provides tools for operators, developers, and data workers
• Certified and tested at scale
• Engineered for deep ecosystem interoperability OS/VM Cloud Appliance
PLATFORM SERVICES
HADOOP CORE
Enterprise Readiness High Availability, Disaster Recovery, Rolling Upgrades, Security and Snapshots
HORTONWORKS DATA PLATFORM (HDP)
OPERATIONAL SERVICES
DATA SERVICES
HDFS
SQOOP
FLUME
NFS
LOAD & EXTRACT
WebHDFS
KNOX*
OOZIE
AMBARI
FALCON*
YARN
MAP TEZ REDUCE
HIVE & HCATALOG PIG HBASE
© Hortonworks Inc. 2013 - Confidential Page 17
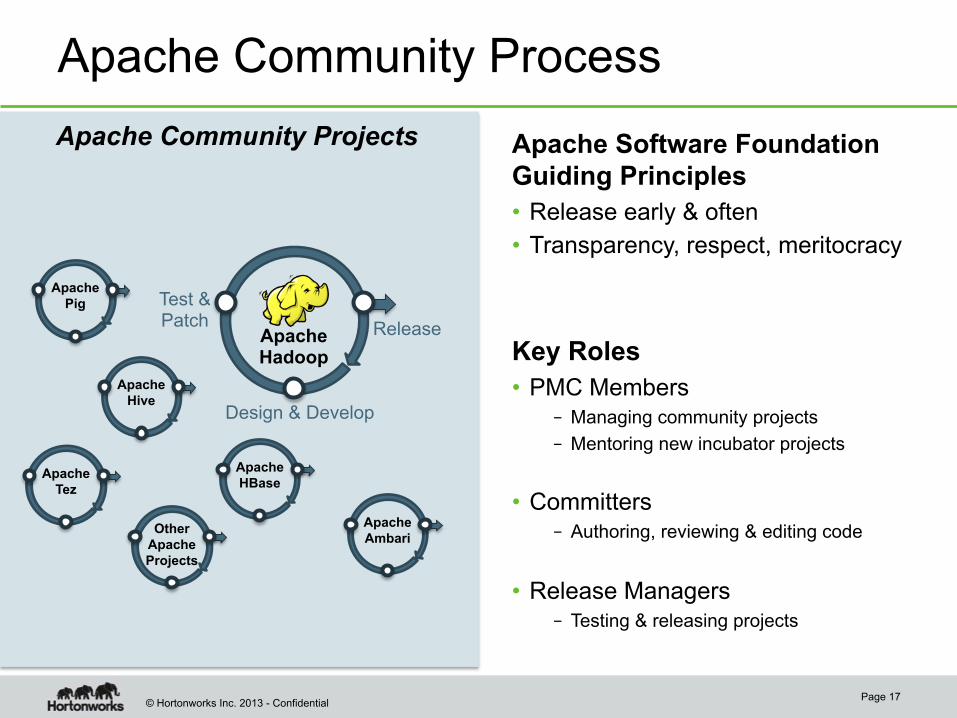
Apache Software Foundation Guiding Principles • Release early & often • Transparency, respect, meritocracy
Key Roles • PMC Members
– Managing community projects – Mentoring new incubator projects
• Committers – Authoring, reviewing & editing code
• Release Managers – Testing & releasing projects
Apache Community Process
Apache HBase
Apache Pig
Apache Tez
Other Apache Projects
Apache Hive
Apache Ambari
Apache Hadoop
Test & Patch
Design & Develop
Release
Apache Community Projects

© Hortonworks Inc. 2013 - Confidential
Virtuous Upstream->Downstream Cycle
Page 18
Upstream Community Projects Downstream Enterprise Product
Hortonworks Data Platform
Design & Develop
Distribute
Integrate & Test
Package & Certify
Apache HBase
Apache Pig
Apache Tez
Other Apache Projects
Apache Hive
Apache Ambari
Apache Hadoop
Test & Patch
Design & Develop
Release
Virtuous cycle when development & fixed issues done upstream & stable project releases flow downstream No Lock-in: Integrated, tested & certified distribution lowers risk by ensuring close alignment with Apache projects
Stable Project Releases
Fixed Issues
“We have noticed more activity over the last year from Hortonworks’ engineers on building out Apache Hadoop’s more innovative features. These include YARN, Ambari and HCatalog.” - Jeff Kelly: Wikibon

© Hortonworks Inc. 2013 - Confidential
Had
oop
Pig
HC
atal
og
Hiv
e
HB
ase
Sqo
op
Ooz
ie
Zoo
keep
er
Mah
out
Am
bari
Deliver HDP for Mainstream Enterprise
2.2.0
1.1.2
1.0.3
0.5.0
0.4.0
0.11.0
0.10.0
0.9.0
0.94.6
0.94.2
0.92.1
1.4.3
1.4.2
1.4.1
3.3.2
3.2.0
3.1.3
3.4.5
3.3.4
1.2.4
1.2.0
HMC1.1
HMC1
HDP 2.0 OCT 2013
HDP 1.2 FEB
2013
HDP 1.1 SEPT 2012
HDP 1.0 JUNE 2012
0.7.0
Hortonworks Data Platform
0.11
0.10.1
0.9.2
HDP 1.3 May
2013
0.12.0 0.12.0
0.96.0
0.8.0
1.4.1
1.4.4 4.0.0
Page 19
HDP certifies most recent & stable community innovation

© Hortonworks Inc. 2013 - Confidential
Apache Hadoop Core
Hadoop is a distributed storage & processing technology for large scale applications • HDFS:
Self-healing, distributed file system for multi-structured data; breaks files into blocks & stores redundantly across cluster
• MapReduce: Framework for running large data processing jobs in parallel across many nodes & combining results
• YARN: New application management framework that enables Hadoop to go beyond MapReduce apps
Page 20
HADOOP CORE HDFS YARN (in 2.0)
MAP REDUCE

© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 21
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache Flume: Store Log Files & Events • Distributed service for efficiently collecting, aggregating, and moving streams of
log data into HDFS
• Streaming capability with failover and recovery mechanisms
• Primary use case: move web log files directly into Hadoop
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME

© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 22
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache Sqoop: Get Data from/to SQL Databases • Move structured data in and out of Hadoop
• Tools and connectors that enable data from traditional SQL databases and data warehouses (ex. Oracle & Teradata) to be stored to & retrieved from Hadoop
• SQ-OOP: SQL to Hadoop
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME
© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 23
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache Pig: Scripting Language for Hadoop • Enables data workers to write complex data transformations using a simple
scripting language
• Pig latin (the language) defines a set of transformations on a data set such as aggregate, join and sort among others; can be extended using UDF (User Defined Functions), which can be written in Java and called directly Pig
• Pig appeals to developers familiar with scripting languages and SQL
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME

© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 24
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache Hive: SQL Interface for Hadoop • The de-facto SQL-like interface for Hadoop that enables data summarization,
ad-hoc query, and analysis of large datasets
• Connects to Excel, Microstrategy, PowerPivot, Tableau and other leading BI tools via Hortonworks Hive ODBC Driver
• HiveQL (HQL) is a language that appeals to data analysts familiar with SQL
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME

© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 25
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache HBase: NoSQL DB for Interactive Apps • Non-relational, columnar database that provides a way for developers to create,
read, update, and delete data in Hadoop in a way that performs well for interactive applications
• Commonly used for serving “intelligent applications” that predict user behavior,
detect shifting usage patterns, or recommend ways for users to engage
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME

© Hortonworks Inc. 2013 - Confidential
Enterprise Data Services
Page 26
HADOOP CORE
DATA SERVICES
Hadoop supports data services that store, process & access data in many ways
Apache HCatalog: Metadata & Table Management • Metadata service that enables users to access Hadoop data as a set of tables
without needing to be concerned with where or how their data is stored
• Enables consistent data sharing and interoperability across data processing tools such as Pig, MapReduce and Hive
• Enables deep interoperability and data access with systems such as SQL Server, etc.
WEBHDFS
HCATALOG
HIVE PIG HBASE
SQOOP
FLUME

© Hortonworks Inc. 2013 - Confidential
Enterprise Operational Services
Page 27
HADOOP CORE
OPERATIONAL SERVICES
Distributed Storage & Processing
Hadoop needs operational services for productive operations & management
Apache Ambari: Management & Monitoring • Make Hadoop clusters easy to operate • Simplified cluster provisioning with a step-by-step install wizard • Pre-configured operational metrics for insight into health of Hadoop services • Visualization of job and task execution for visibility into performance issues • Complete RESTful API for integrating with existing operational tools • Intuitive user interface that makes controlling a cluster easy and productive
DATA SERVICES
Store, Process and Access Data
OOZIE
AMBARI
HUE

© Hortonworks Inc. 2013 - Confidential
Enterprise Operational Services
Page 28
HADOOP CORE Distributed Storage & Processing
Hadoop needs operational services for productive operations & management
Apache Oozie: Workflow & Scheduling • Workflow system that coordinates jobs written in multiple languages such as
MapReduce, Pig and Hive
• Allows specification of order and dependencies between jobs so processing can happen in an orderly manner
DATA SERVICES
Store, Process and Access Data
OPERATIONAL SERVICES
OOZIE
AMBARI
HUE

© Hortonworks Inc. 2013 - Confidential
Enterprise Operational Services
Page 29
HADOOP CORE Distributed Storage & Processing
Hadoop needs operational services for productive operations & management
Hue: Web Based Development Environment • A web based application to interact with Core Hadoop and Data Services
• Extends access from command line to web based environment
• Supports Hive query submission, Pig script execution, HCatalog metastore review, HDFS file browsing, Map Reduce job design, Oozie workflow definition
DATA SERVICES
Store, Process and Access Data
OPERATIONAL SERVICES
OOZIE
AMBARI
HUE

© Hortonworks Inc. 2013 - Confidential
Hive – A Deeper Look
Page 30

© Hortonworks Inc. 2013 - Confidential
Hive – SQL Analytics For Any Data Size
Page 31
Sensor Mobile
Weblog Opera7onal
/ MPP
Store and Query all Enterprise Data in Hive
Use Exis-ng SQL Tools and Exis-ng SQL Processes

© Hortonworks Inc. 2013 - Confidential
Hive Use Cases
Page 32
Scalable Analy7cs
• SQL analytics over terabytes to 100s of petabytes of data.
• Gain deeper insight by using more data.
Scalable ETL
• SQL-based ETL that supports larger data volumes and new types of data.
• Bring more data, or new types of data, into your existing warehouse.
Agile Data
• Native support for unstructured and semi-structured data.
• Unlock value from semi-structured data using tools you already have.

© Hortonworks Inc. 2013 - Confidential
Hive Scales To Any Workload
Page 33
" The original developers of Hive. " More data than existing RDBMS could handle. " 100+ PB of data under management. " 15+ TB of data loaded daily. " 60,000+ Hive queries per day. " More than 1,000 users per day.

© Hortonworks Inc. 2013 - Confidential
Hive: The De-Facto SQL Interface for Hadoop
Page 34

© Hortonworks Inc. 2013 - Confidential
ODBC/JDBC Access for Popular BI Tools
Page 35
• Seamless integration with BI tools such as Excel, PowerPivot, MicroStrategy, and Tableau
• ODBC 3.52 standard compliant driver
• Supports Linux & Windows
Free for use with Hortonworks Data Platform.
Applications & Spreadsheets
Visualization & Intelligence
ODBC / JDBC
Hortonworks Data Platform

© Hortonworks Inc. 2013 - Confidential
HiveQL Features
• HiveQL is similar to other SQLs – Uses familiar relational database concepts
(tables, rows, columns and schema) – Based on the SQL-92 specification
• Treats Big Data as tables
• Converts SQL queries into MapReduce/Tez jobs – User does not need to know MapReduce
• Also supports plugging custom MapReduce scripts into queries
Page 36

© Hortonworks Inc. 2013 - Confidential
Hive Tables
• A Hive table consists of: – Data: typically a file or group of files in HDFS – Schema: in the form of metadata stored in a relational database
• Schema and data are separate – A schema can be defined for existing data – Data can be added or removed independently – Hive can be "pointed" at existing data
• You have to define a schema if you have existing data in HDFS that you want to use in Hive
Page 37

© Hortonworks Inc. 2013 - Confidential
Defining a Table
Page 38
CREATE TABLE mytable (name string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ’,’ STORED AS TEXTFILE;
Each row is comma delimited text
HiveQL statements are terminated with a semicolon

© Hortonworks Inc. 2013 - Confidential
Managing Tables
Page 39
Operation Command Syntax See current tables SHOW TABLES
Check the schema DESCRIBE mytable;
Change the table name ALTER TABLE mytable RENAME to mt;
Add a column
ALTER TABLE mytable ADD COLUMNS (mycol STRING);
Drop a partition
ALTER TABLE mytable DROP PARTITION (age=17)

© Hortonworks Inc. 2013 - Confidential
Loading Data
• Hive warehouse default location is: – /apps/hive/warehouse
• The schema is checked when the data is queried – If a row does not match the schema, it will be read as null
Page 40
LOAD DATA LOCAL INPATH 'input/mydata/data.txt’ INTO TABLE myTable;
Indicate data path
INSERT INTO TABLE birthdays SELECT firstName, lastName, birthday FROM customers WHERE birthday IS NOT NULL;

© Hortonworks Inc. 2013 - Confidential
Loading Data Examples
Page 41
• LOAD DATA LOCAL INPATH '/tmp/customers.csv' OVERWRITE INTO TABLE customers;
• LOAD DATA INPATH '/user/train/customers.csv' OVERWRITE INTO TABLE customers;
• INSERT INTO TABLE birthdays SELECT firstName, lastName, birthday FROM customers WHERE birthday IS NOT NULL;

© Hortonworks Inc. 2013 - Confidential
Performing Queries
• SELECT • WHERE clause • UNION ALL and DISTINCT • GROUP BY and HAVING • JOIN • ORDER BY • LIMIT clause
– Rows returned are chosen at random • Can use REGEX Column Specification
Page 42
SELECT '(ds|hr)?+.+' FROM sales;

© Hortonworks Inc. 2013 - Confidential
Query Examples
Page 43
• SELECT * FROM customers; • SELECT COUNT(1) FROM customers; • SELECT firstName, lastName, address, zip
FROM customers WHERE orderID > 0 GROUP BY zip;
• SELECT customers.*, orders.* FROM customers JOIN orders ON (customers.customerID = orders.customerID) order by orders.qty;
• SELECT customers.*, orders.* FROM customers LEFT OUTER JOIN orders ON (customers.customerID = orders.customerID);

© Hortonworks Inc. 2013 - Confidential
Hive’s Journey to SQL Compliance
Page 44
Evolu-on of SQL Compliance in Hive
SQL Datatypes SQL Seman7cs INT/TINYINT/SMALLINT/BIGINT SELECT, INSERT
FLOAT/DOUBLE GROUP BY, ORDER BY, HAVING
BOOLEAN JOIN on explicit join key
ARRAY, MAP, STRUCT, UNION Inner, outer, cross and semi joins
STRING Sub-‐queries in the FROM clause
BINARY ROLLUP and CUBE
TIMESTAMP UNION
DECIMAL Standard aggrega7ons (sum, avg, etc.)
DATE Custom Java UDFs
VARCHAR Windowing func7ons (OVER, RANK, etc.)
CHAR Advanced UDFs (ngram, XPath, URL)
Interval Types Sub-‐queries for IN/NOT IN, HAVING
JOINs in WHERE Clause
INTERSECT / EXCEPT
Legend Available
Roadmap
Hive 11
Hive 12 -‐ GA
Hive 13

© Hortonworks Inc. 2013 - Confidential
SPEED: Increasing Hive Performance
Performance Improvements included in Hive 12 – Vectorization – Base & advanced query optimization – Startup time improvement – Join optimizations
Page 45
Human Acceptable Query Times across ALL use cases • Simple and advanced queries across petabytes in seconds • Integrates seamlessly with existing tools • Currently a 60x improvement in just six months
© Hortonworks Inc. 2013 - Confidential
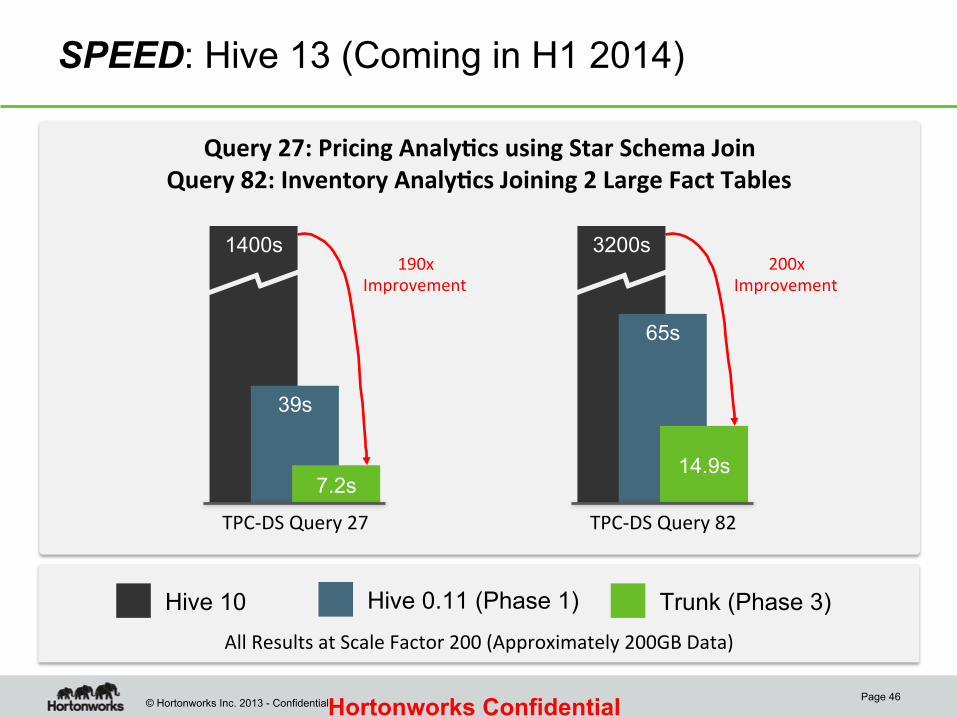
SPEED: Hive 13 (Coming in H1 2014)
Page 46
Hive 10 Trunk (Phase 3) Hive 0.11 (Phase 1)
190x Improvement
1400s
39s
7.2s
TPC-‐DS Query 27
3200s
65s
14.9s
TPC-‐DS Query 82
200x Improvement
Query 27: Pricing Analy-cs using Star Schema Join Query 82: Inventory Analy-cs Joining 2 Large Fact Tables
All Results at Scale Factor 200 (Approximately 200GB Data)
Hortonworks Confidential

© Hortonworks Inc. 2013 - Confidential
Key Resources
Page 47

© Hortonworks Inc. 2013 - Confidential
Solution: Hortonworks HDP Sandbox
Page 48
“The combination of tutorials and hands-on workshops in one application is truly unique.”
“The ability to actually use Hadoop so quickly without being required to build your own environment is a massive time savings.”

© Hortonworks Inc. 2013 - Confidential
Use Cases & Demos
• Audience – Sales, Solution Architects, Business
Analysts & Developers
• Using Hadoop to Deliver Business Applications – White paper & sample demos
• Available – http://hortonworks.com/use-cases
Page 49

© Hortonworks Inc. 2013 - Confidential
Cluster Sizing Guide • Audience
– Solution Architects & Developers
• How to design a hadoop cluster – Key Considerations
– Cluster Storage Capacity – Server Specification – Cluster Size – Network Fabric
• Cluster Design Guide – Developed by team with deepest
operational experience – Balances cost & performance for best
enterprise value
• Available – http://hortonworks.com/wp-content/
uploads/downloads/2013/06/Hortonworks.ClusterConfigGuide.1.0.pdf
Page 50
Community Driven Apache Hadoop
!
!!
Apache Hadoop Cluster Configuration Guide April 2013
!!!!!!!!!!!!!!
!© 2013 Hortonworks Inc. http://www.hortonworks.com

© Hortonworks Inc. 2013 - Confidential
Hortonworks Blog
• Audience – Sales, Solution Architects,
Business Analysts & Developers
• Covering Technical & Business innovations in Apache Hadoop
• Available – http://hortonworks.com/blog/
Page 51

© Hortonworks Inc. 2013 - Confidential
Q&A
Page 52