benchmarking hadoop - which hadoop sql engine leads the herd
TRANSCRIPT

Which Hadoop SQL Engine Leads the Herd?
Stewart Tate STSM, Chief Designer, IBM Big Data Cluster
Lead Architect BigInsights Performance
IBM Silicon Valley Laboratory ∙ San Jose ∙ California

2 © 2013 IBM Corporation
Acknowledgements and Disclaimers Availability. References in this presentation to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates.
The workshops, sessions and materials have been prepared by IBM or the session speakers and reflect their own views. They are provided for informational purposes only, and are neither intended to, nor shall have the effect of being, legal or other guidance or advice to any participant. While efforts were made to verify the completeness and accuracy of the information contained in this presentation, it is provided AS-IS without warranty of any kind, express or implied. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, this presentation or any other materials. Nothing contained in this presentation is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software.
All customer examples described are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual environmental costs and performance characteristics may vary by customer. Nothing contained in these materials is intended to, nor shall have the effect of, stating or implying that any activities undertaken by you will result in any specific sales, revenue growth or other results.
© Copyright IBM Corporation 2014. All rights reserved.
— U.S. Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
IBM, the IBM logo, ibm.com, BigInsights, and Big SQL are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or TM), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at •“Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml
•TPC Benchmark, TPC-DS, and QphDS are trademarks of Transaction Processing Performance Council
•Cloudera, the Cloudera logo, Cloudera Impala are trademarks of Cloudera.
•Other company, product, or service names may be trademarks or service marks of others.
2

3 © 2013 IBM Corporation
Our journey begins…
• Evaluating three SQL engines in major Hadoop Distributions
IBM BigInsights 3.0.0.1 Big SQL v3
Cloudera (CDH5) Impala 1.4
Hortonworks (HDP 2.1) Hive 0.13
• Workload
Simulated Enterprise Retail Operation using 99 Queries
Hadoop-DS based on TPC-DS benchmark

4 © 2013 IBM Corporation
Three Identical Hadoop Clusters…
Management Node
One x3650 M4 BD Two E5-2680 v2 2.8GHz 10-core
128GB RAM, 1866MHz
2TB 3.5” HDD
Dual-port 10GbE
RHEL 6.4
EXT4/HDFS/Parquet/ORC
Data Nodes
Sixteen x3650 M4 BD Two E5-2680 2.8GHz 10-core
128GB RAM, 1866MHz
Ten 2TB 3.5” HDD
Four 120GB 3.5” SSD
Dual-port 10GbE
RHEL 6.4
EXT4/HDFS/Parquet/ORC
Using
Lenovo Servers designed for Hadoop
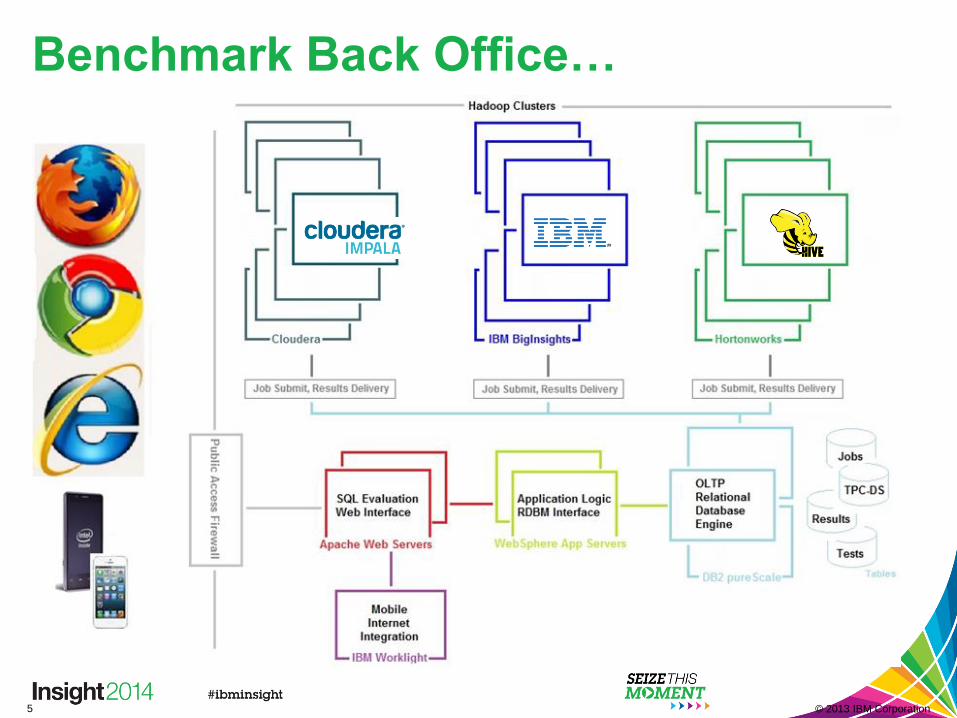
5 © 2013 IBM Corporation
Benchmark Back Office…

6 © 2013 IBM Corporation
Live access to Audited & Real-time results
http://app.insightibm.com

7 © 2013 IBM Corporation
Which SQL Engine Leads the Herd?
View results from each Hadoop Distro via our mobile app
http://app.insightibm.com

8 © 2013 IBM Corporation
Big SQL – Runs 100% of the queries
Key points
Impala & Hive require many
queries to be re-written, some
significantly
Owing to various restrictions,
some queries could not be re-
written or failed at run-time
Re-writing queries in a
benchmark scenario where
results are known is one thing
– doing this against real
databases in production is
another

9 © 2013 IBM Corporation
Hadoop-DS benchmark – Single user performance @ 10TB
Big SQL is 3.6x faster than Impala and 5.4x faster than Hive 0.13
for single query stream using 46 common queries

10 © 2013 IBM Corporation
Hadoop-DS benchmark – multi-user performance @ 10TB
With 4 streams, Big SQL is 2.1x faster than Impala and 8.5x faster than Hive 0.13
for 4 query streams using 46 common queries
**See Speaker notes for disclaimer

11 © 2013 IBM Corporation
Hadoop-DS benchmark – Big SQL with 99 queries @ 30TB
Big SQL completed 4 concurrent query streams @30TB in 1.8x time of a single query stream
Big SQL
completed
396 queries in
only 1.8x time
of 99 queries

12 © 2013 IBM Corporation
Thank you!

13 © 2013 IBM Corporation
About TPC-DS Queries • The queries are diverse, and many are complex
• Reflecting real business needs – a random sample:
Find customers returning items more frequently than normal (q1)
States with customers most ammenable to premium priced offers (q6)
List key metrics for unadvertised in-store promotions by demographic (q7)
Identify similar customers purchasing through multiple sales outlets (q10)
Find customers shifting purchasing habits to the web (q11)
Key measures for catalog sales fulfilled from an alternate warehouse (q16)
Find frequently sold items and the circumstances under which repeat sales take place (q23)
Understand the products and retail locations where items are likely to be return and subsequently re-purchased via the catalog (q29)
Display customers making significant local purchases comparing to buying potential based on dependents and vehicles owned (q34)

14 © 2013 IBM Corporation
Hadoop-DS benchmark
• Aim: To provide the fairest and most meaningful comparison of SQL over Hadoop solutions so far
• Hadoop-DS benchmark is based on the TPC-DS* benchmark. Key deviations:
No data maintenance or data persistence phases
• Not possible across all vendors
Uses a common query set across all solutions
• The sub-set of queries that all vendors can successfully execute at that scale factor
• Queries are not cherry picked
• It is the most complete TPCDS like benchmark executed to date
• Worked with TPC certified auditor to review the benchmark
• Is analogues to porting a relational workload to SQL on Hadoop
Bringing Order out of Chaos

15 © 2013 IBM Corporation
Big SQL 3.0 – Key Performance Features
• Advanced re-write and cost based optimizer backed by decades of IBM R&D
• Optimized HDFS readers for different storage formats
Native readers
• Self tuning memory manager
Optimize memory allocation between Big SQL consumers depending on the workload
• Informational Constraints
• Advanced Statistics
• Resource sharing and WLM