hadoop engineering bo_f_final
TRANSCRIPT

© Hortonworks Inc. 2011
Hadoop Engineering Best Practices
Raja Aluri, Release EngDeepesh Khandelwal, Quality EngRamya Sunil, Quality Eng
Page 1

© Hortonworks Inc. 2011
Agenda
• Source Mechanics
• Why do System Testing?
• Test Matrix
• Automated Testing Flow
• Test Planning
• Planning your own System Testing
• Q & A
Page 2Architecting the Future of Big Data

© Hortonworks Inc. 2011
Apache Hortonworks Partner Source Mechanics
• Hortonworks Open Source Philosophy
• How we do Apache first development
• How we incorporate fixes or features that did not make into apache yet
• How we integrate our partner contributions to the source code
• Bookkeeping of the delta between apache and Hortonworks
Page 3Architecting the Future of Big Data

© Hortonworks Inc. 2011
Apache-Hortonworks-Partner Source flow
Page 4Architecting the Future of Big Data
Partner
Apac
he R
ef
HD
P Re
f
Part
ner
HWX
Apac
he R
ef
HD
P
Apache Git
Had
oop
bran
ch-2
Had
oop
bran
ch-2
.4
Issue Type Course of Action
Normal Issue Patch in Apache first
Urgent Issue Patch in HWX Repo first
Read-Write Repository
Read-Only Repository
ContinuousMerges
ContinuousMerges
HDP Build CI
HDP Package
Repo
HDP Maven Repository
Publish Releases
QE Workflow for Testing
© Hortonworks Inc. 2011
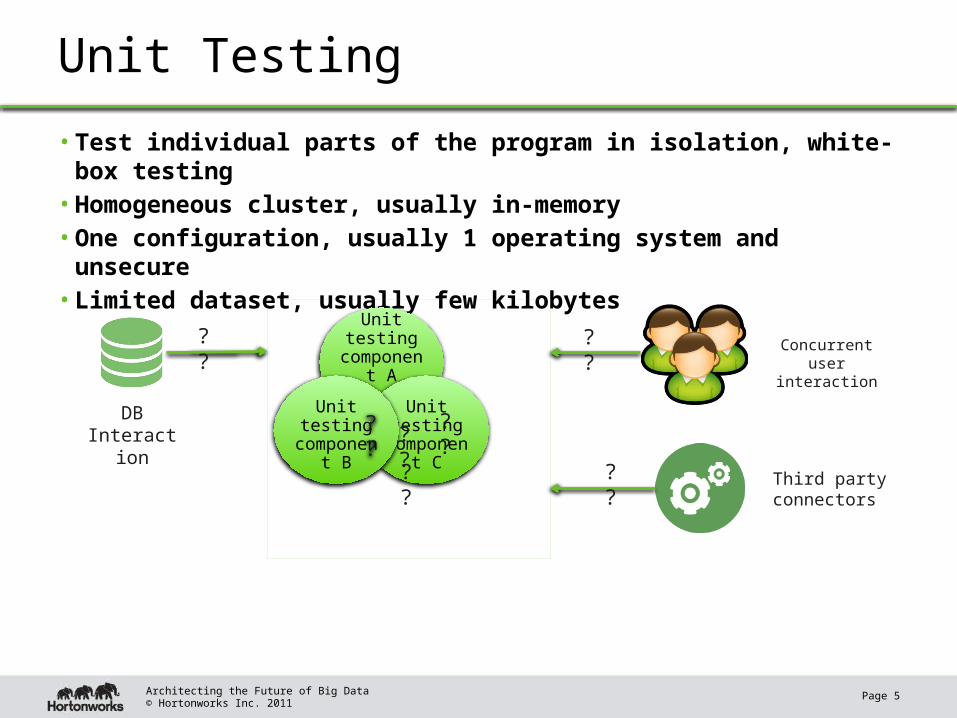
Unit Testing
• Test individual parts of the program in isolation, white-box testing• Homogeneous cluster, usually in-memory• One configuration, usually 1 operating system and unsecure• Limited dataset, usually few kilobytes
Page 5Architecting the Future of Big Data
Unit testing component
A
Unit testing
component C
Unit testing
component B
?? ????
??
DB Interaction
Concurrent user
interaction
Third party connectors
??
??
??

© Hortonworks Inc. 2011
System Testing
• Mimics production environment– Multiple nodes in the cluster– Multiple concurrent users– Different workloads
• Multiple configurations to test• Large dataset, more complex and richer• Encompasses different types of testing
– Functional– Performance, Stress and Reliability– High Availability– Backwards Compatibility– Integration testing– Third party connectors– Upgrade testing
Page 6Architecting the Future of Big Data

© Hortonworks Inc. 2011
System Testing cont...
• Heterogeneous testing– Cross version testing– Cross operating system testing– Hardware configs like Disk and CPU– Security settings, level of encryption
Page 7Architecting the Future of Big Data

© Hortonworks Inc. 2011
Test Matrix
• Total of ~15000+ configurations to test!
Page 8Architecting the Future of Big Data
OS•CentOS•SuSE•Debian•Ubuntu•Windows
JDK•Oracle JDK•OpenJDK•Different version - 1.6.x, 1.7.x, 1.8.x
Security•Disabled•Enabled – MIT-only, AD-only, MIT-AD
•Ranger - enabled/disabled
Encryption•Wire encryption – enabled/disabled
•Transparent Data Encryption – enabled/disabled
DB•Mysql•Oracle•Postgres•MSSQL
File system•HDFS•WASB•Other vendor specific FSs
Others•Tez – enabled/disabled•Slider apps v/s standalone
© Hortonworks Inc. 2011
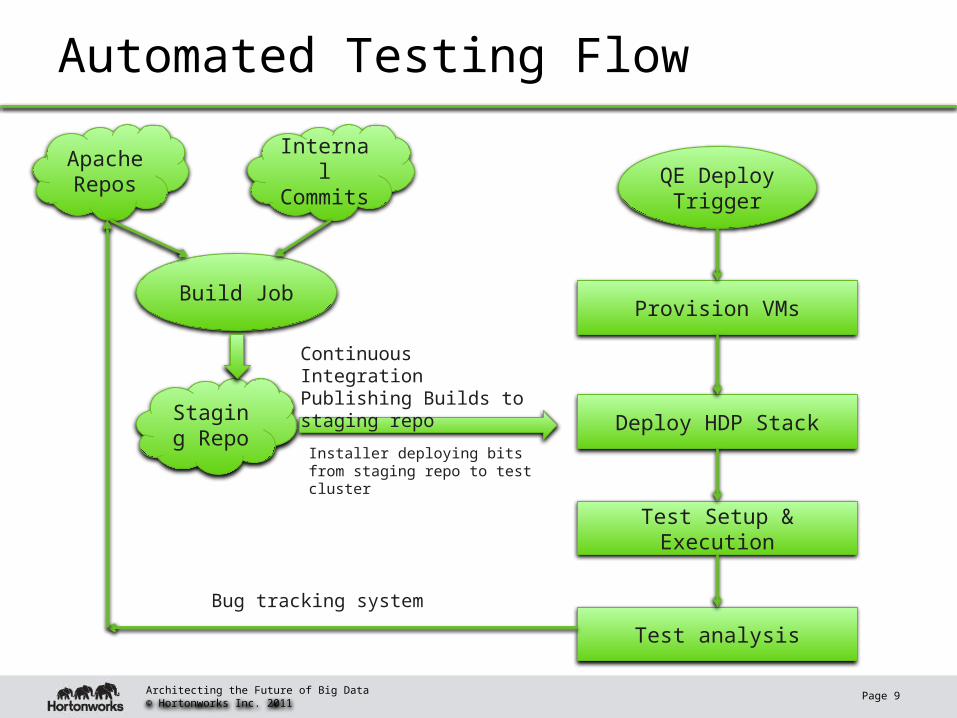
Automated Testing Flow
Page 9Architecting the Future of Big Data
Build Job
Apache Repos
Internal Commits
Staging Repo
QE Deploy Trigger
Provision VMs
Deploy HDP Stack
Test Setup & Execution
Test analysis
Continuous Integration Publishing Builds to staging repo
Installer deploying bits from staging repo to test cluster
Bug tracking system

© Hortonworks Inc. 2011
Test Planning
20+ components in the HDP stack and growing!
Page 10Architecting the Future of Big Data
Test plan
Internal developers
Apache jiras and
community forums
Product Management
Support tickets

© Hortonworks Inc. 2011
Planning your own QATS
Architecting the Future of Big DataPage 11

© Hortonworks Inc. 2011
Typical user scenarios
• Fresh install• Upgrade stack, going from an earlier release to a newer one• Migration, changing distributions• Applying changes to an existing cluster
– Upgrading hardware in regards to CPU, memory, disks– Changing dependent software pieces like OS, JDK– Changing security settings like turning ON Kerberos, Encryption– Changing component configs in *-site.xml, enabling HA
Page 12Architecting the Future of Big Data
© Hortonworks Inc. 2011
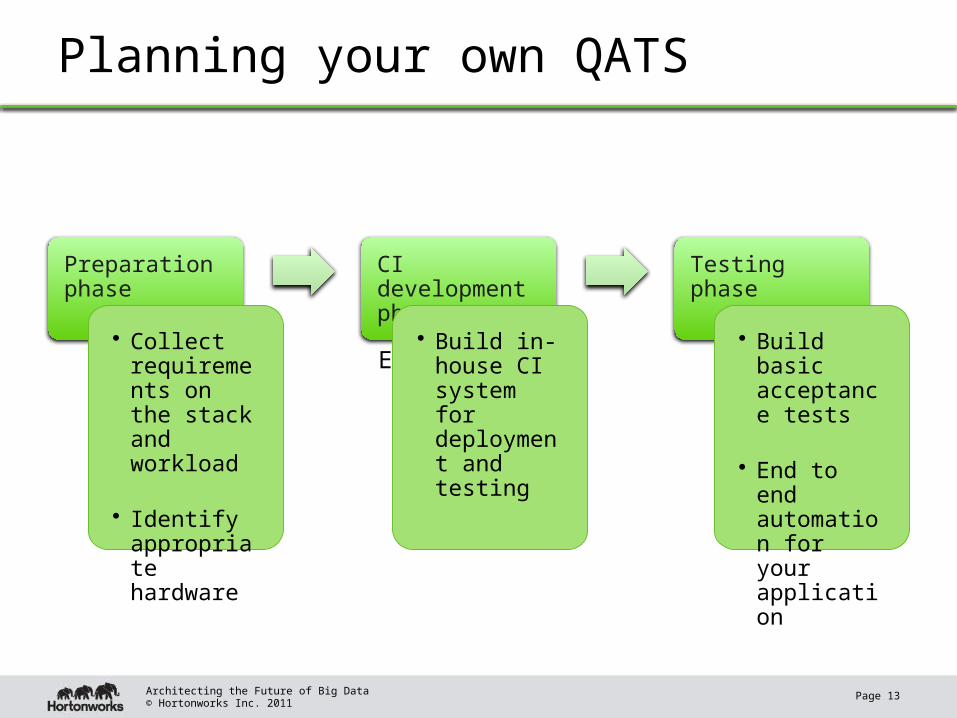
Planning your own QATS
Page 13Architecting the Future of Big Data
E2E automation
Preparation phase
• Collect requirements on the stack and workload
• Identify appropriate hardware
CI development phase
• Build in-house CI system for deployment and testing
Testing phase
• Build basic acceptance tests
• End to end automation for your application

© Hortonworks Inc. 2011
Preparation Phase
• Collect the stack requirements– Identify all the stack components that will be installed including the third-party
applications, connectors– Identify the installer– Identify configs
• Hardware selection– Should be scaled appropriately to mimic production environment– Prefer multi-node than single-node with component services distributed
• Collect workload information– Use actual workload whenever possible– If not, simulate the workload, some tools available
– Use rumen to obtain jobtrace from existing clusters
– Use gridmix to generate workload
– Data set size and complexity– Number of concurrent users
Page 14Architecting the Future of Big Data
© Hortonworks Inc. 2011
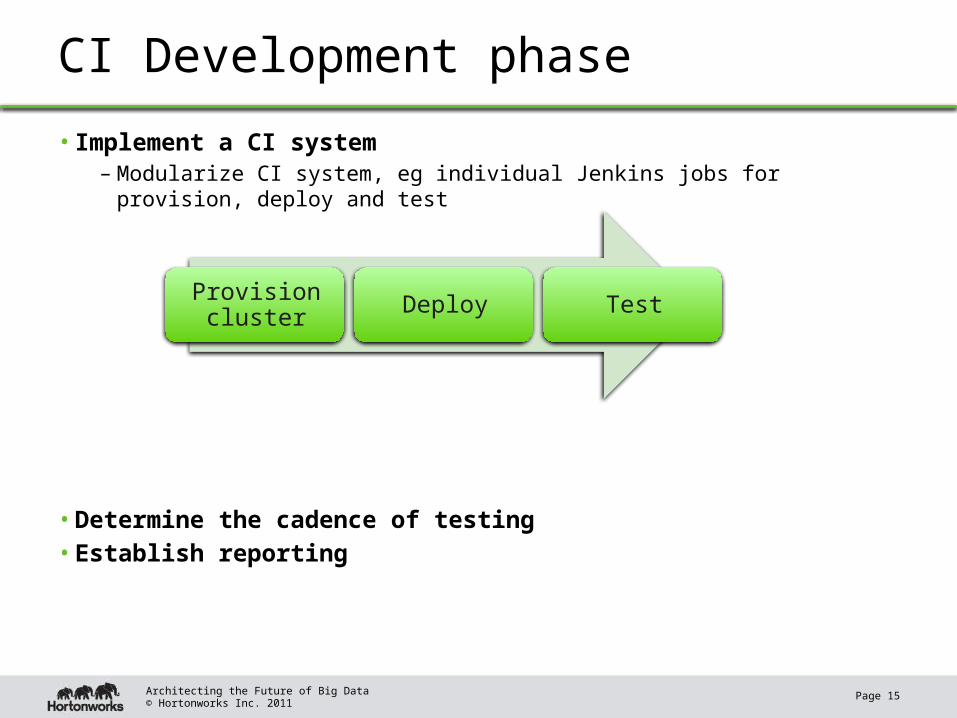
CI Development phase
• Implement a CI system– Modularize CI system, eg individual Jenkins jobs for provision, deploy and test
• Determine the cadence of testing• Establish reporting
Page 15Architecting the Future of Big Data
Provision cluster Deploy Test

© Hortonworks Inc. 2011
Testing Phase
• Basic Acceptance Tests – Basic service check for individual deployed components– Basic acceptance tests to validate integrations
• Establish baseline – to track performance of pipeline components in future
• Compatibility tests (including apps, third party connectors, dashboards etc)
• E2E automation to simulate production workloads
Page 16Architecting the Future of Big Data

© Hortonworks Inc. 2011
Q & A
Page 17Architecting the Future of Big Data

© Hortonworks Inc. 2011
Thank You!
Architecting the Future of Big DataPage 18