grids from computing to data management jean-marc pierson lionel brunie insa lyon, dec 04
Post on 19-Dec-2015
216 views
TRANSCRIPT

GridsFrom Computing to Data Management
Jean-Marc Pierson
Lionel Brunie
INSA Lyon, dec 04

2
Outline
a very short introduction to Grids a brief introduction to parallelism a not so short introduction to Grids data management in Grids
3
Grid concepts : an analogy
Electric power distribution :the electric network and high voltage
4
Grids concepts
Computer power distribution :Internet network and high performance (parallelism and distribution)

5
Parallelism : an introduction Grids dates back only 1996 Parallelism is older ! (first classification in 1972)
Motivations : need more computing power (weather forecast, atomic
simulation, genomics…) need more storage capacity (petabytes and more) in a word : improve performance ! 3 ways ...
Work harder --> Use faster hardware
Work smarter --> Optimize algorithms
Get help --> Use more computers !

6
Parallelism : the old classification Flynn (1972) Parallel architectures classified by the
number of instructions (single/multiple) performed and the number of data (single/multiple) treated at same time
SISD : Single Instruction, Single Data SIMD : Single Instruction, Multiple Data MISD : Multiple Instructions, Single Data MIMD : Multiple Instructions, Multiple Data

7
SIMD architectures
in decline since 97 (disappeared from market place)
concept : same instruction performed on several CPU (as much as 16384) on different data
data are treated in parallel subclass : vectorprocessors
act on arrays of similar data using specialized CPU; used in computer intensive physics

8
MIMD architectures
different instructions are performed in parallel on different data
divide and conquer : many subtasks in parallel to shorten global execution time
large heterogeneity of systems

9
Another taxonomy
based on how memories and processors interconnect
SMP : Symmetric Multiprocessors MPP : Massively Parallel Processors Constellations Clusters Distributed systems

10
Symmetric Multi-Processors (1/2)Small number of identical processors (2-64)Share-everything architecture
single memory (shared memory architecture) single I/O single OS equal access to resources
CPU CPU CPU
HDMemory
network

11
Pro : easy to program : only one address space to exchange
data (but programmer must take care of synchronization in memory access : critical section)
Cons : poor scalability : when the number of processors
increase, the cost to transfer data becomes too high; more CPUs = more access memory by the network = more need in memory bandwidth !
Direct transfer from proc. to proc. (->MPP)Different interconnection schema (full impossible
!, growing in O(n2) when nb of procs increases by O(n)) : bus, crossbar, multistage crossbar, ...
Symmetric Multi-Processors (2/2)
12
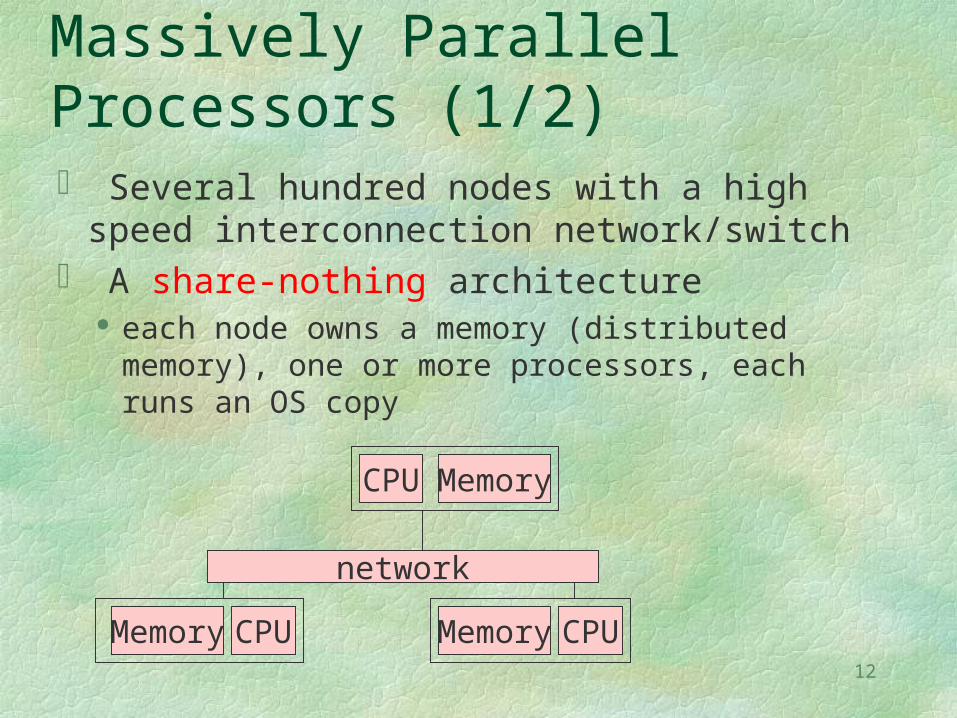
Massively Parallel Processors (1/2) Several hundred nodes with a high speed
interconnection network/switch A share-nothing architecture
each node owns a memory (distributed memory), one or more processors, each runs an OS copy
CPU
CPU
CPUMemory
network
Memory
Memory

13
Pros : good scalability
Cons : communication between nodes longer than in shared
memory; improve interconnection schema : hypercube, (2D or 3D) torus, fat-tree, multistage crossbars
harder to program : • data and/or tasks have to be explicitly distributed to nodes• remote procedure calls (RPC, JavaRMI)• message passing between nodes (PVM, MPI), synchronous
or asynchronous communications DSM : Distributed Shared Memory : a virtual memory upgrade : processors and/or communication ?
Massively Parallel Processors (2/2)

14
Constellations
a small number of processors (up to 16) clustered in SMP nodes (fast connection)
SMPs are connected through a less costly network with “poorer” performance
With DSM, memory may be addressed globally : each CPU has a global memory view, memory and cache coherence is guaranteed (ccNuma)
CPUCPU
Memory
network
CPU
CPU CPUCPU
Memory
network
CPU
CPU CPUCPU
Memory
network
CPU
CPU
Interconnection network Periph.

15
Clusters a collection of workstations (PC for instance)
interconnected through high speed network, acting as a MPP/DSM with network RAM and software RAID (redundant storage, // IO)
clusters = specialized version of NOW : Network Of Workstation
Pros : low cost standard components take advantage of unused computing power

16
Distributed systems
interconnection of independent computers each node runs its own OS each node might be any of SMPs, MPPs,
constellations, clusters, individual computer …
the heart of the Grid ! «A distributed system is a collection of independent
computers that appear to the users of the system as a single computer » Distributed Operating System. A. Tanenbaum, Prentice Hall, 1994

17
Where are we today (nov 22, 2004) ?
a source for efficient and up-to-date information : www.top500.org
the 500 best architectures ! we head towards 100 Tflops 1 Flops = 1 floating point operation per second 1 TeraFlop = 1000 GigaFlops = 100 000
MegaFlops = 1 000 000 000 000 flops = one thousand billion operations per second

18
Today's bests comparison on a similar matrix maths test (Linpack) :Ax=b
Rank Tflops Constructor Nb of procs
1 70.72 (USA) IBM BlueGene/L / DOE 32768
2 51.87 (USA) SGI Columbia / Nasa 10160
3 35.86 (Japon) NEC EarthSim 5120
4 20.53 (Espagne) IBM MareNostrum 3564
5 19.94 (USA) California Digital Corporation 4096
41 3.98 (France) HP Alpha Server / CEA 2560
19
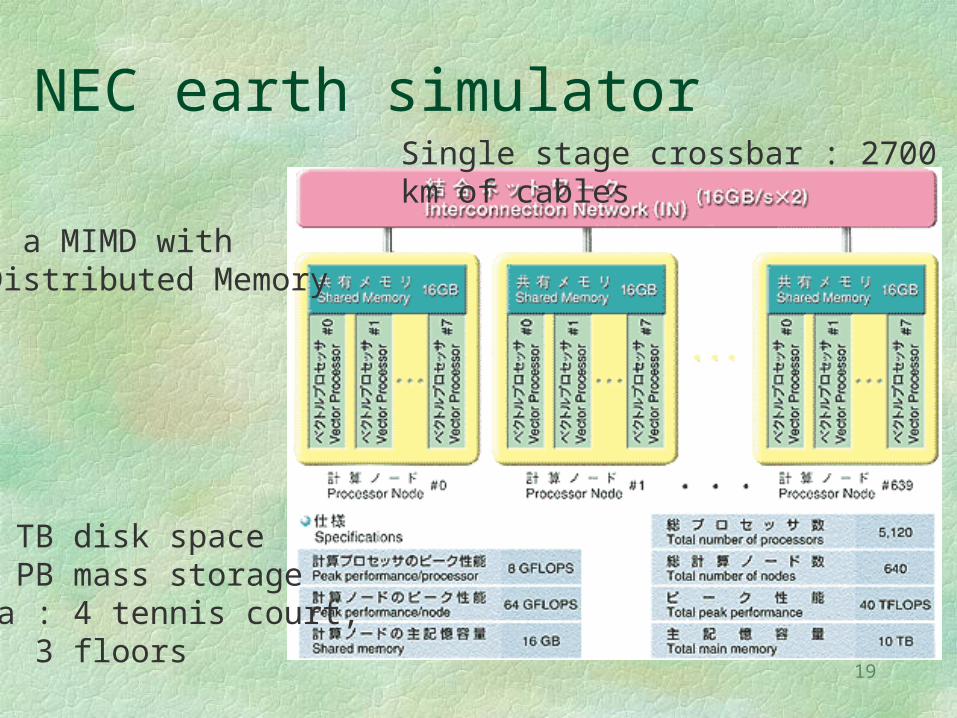
NEC earth simulatorSingle stage crossbar : 2700 km of cables
700 TB disk space1.6 PB mass storagearea : 4 tennis court,
3 floors
- a MIMD withDistributed Memory
20
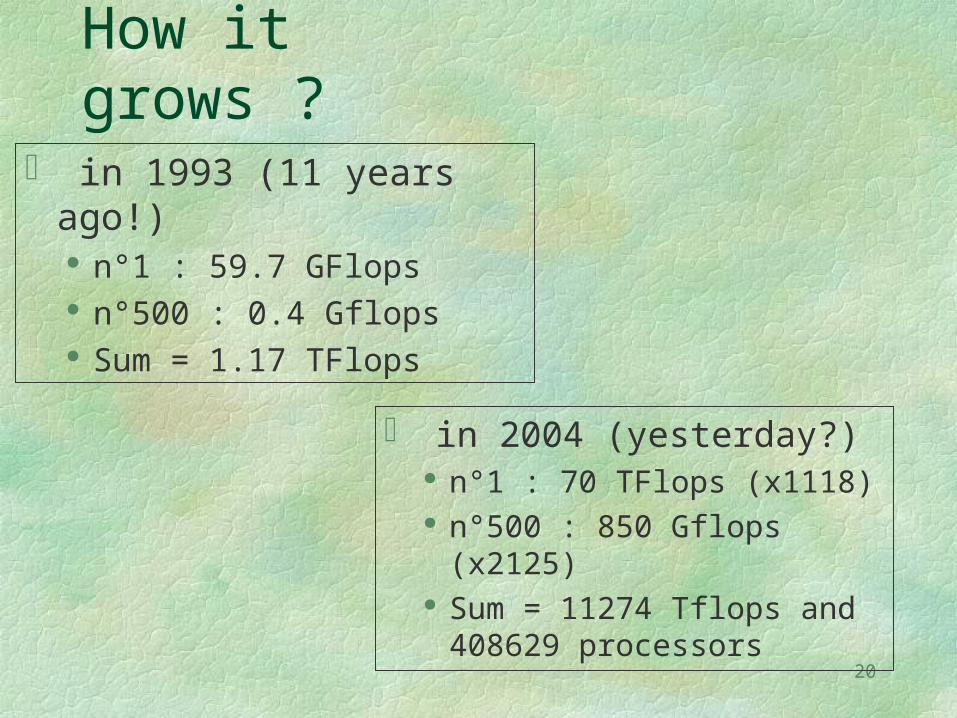
How it grows ? in 1993 (11 years ago!)
n°1 : 59.7 GFlops n°500 : 0.4 Gflops Sum = 1.17 TFlops
in 2004 (yesterday?) n°1 : 70 TFlops (x1118) n°500 : 850 Gflops (x2125) Sum = 11274 Tflops and
408629 processors
21
22

23
Problems of the parallelismTwo models of parallelism :
driven by data flow : how to distribute data ? driven by control flow : how to distribute tasks ?
Scheduling : which task to execute, on which data, when ? how to insure highest compute time (overlap
communication/computation?) ? Communication
using shared memory ? using explicit node to node communication ? what about the network ?
Concurrent access to memory (in shared memory systems) to input/output (parallel Input/Output)

24
The performance ? Ideally grows linearly Speed-up :
if TS is the best time to treat a problem in sequential, its time should be TP=TS/P with P processors !
Speedup = TS/TP
limited (Amdhal law): any program has a sequential and a parallel part : TS=F+T//, thus the speedup is limited : S = (F+T//)/(F+T///P)<1/F
Scale-up : if TPS is the time to treat a problem of size S with P
processors, then TPS should also be the time to treat a problem of size n*S with n*P processors

25
Network performance analysis scalability : can the network be extended ?
limited wire length, physical problems
fault tolerance : if one node is down ? for instance in an hypercube
multiple access to media ? inter-blocking ? The metrics :
latency : time to connect bandwidth : measured in MB/s

26
Tools/environment for parallelism (1/2)
Communication between nodes :By global memory ! (if possible, plain or virtual)Otherwise : low-level communication : sockets
s = socket(AF_INET, SOCK_STREAM, 0 ); mid-level communication library (PVM, MPI)
info = pvm_initsend( PvmDataDefault ); info = pvm_pkint( array, 10, 1 ); info = pvm_send( tid, 3 ); remote service/object call (RPC, RMI, CORBA)service runs on distant node, only its name and
parameters (in, out) have to be known

27
Tools/environment for parallelism (2/2)Programming tools
threads : small processes data parallel language (for DM archi.):
• HPF (High Performance Fortran)
say how data (arrays) are placed, the system will infer the best placement of computation (to minimize total computation time (e.g. further communications)
task parallel language (for SM archi.):• OpenMP : compiler directives and library routines; based
on threads. The parallel program is close to sequential; it is a step by step transform
– Parallel loop directives (PARALLEL DO)
– Task parallel constructs (PARALLEL SECTIONS)
– PRIVATE and SHARED data declarations

28
Parallel databases : motivationsNecessity
Information systems increased in size ! Transactional load increased in volume !
• Memory and IO bottleneck were worse and worse Query in increased in complexity (multi sources,
multi format txt-img-vid)Price
the ratio "price over performance" is continuously decreasing (see clusters)
New applications data mining (genomics, health data) decision support (data warehouse) management of complex hybrid data

29
Target application example (1/2) Video servers
Huge volume of raw data bandwidth : 150 Mb/s; 1h - 70 GB bandwidth TVHD : 863 Mb/s; 1h = 362 GB 1h MPEG2 : 2 GB NEED of Parallel I/O
Highly structured, complex and voluminous metadata (descriptors) NEED large memory !

30
Target application example (2/2) Medical image databases
images produced by PACS (Picture Archiving Communication Systems)
1 year of production : 8 TB of dataHeterogeneous data (multiple imaging
devices) Heterogeneous queriesComplex manipulations (multimodal image
fusion, features extractions)NEED CPUs, memory, IO demands !

31
Other motivation : the theoric problems !
query optimization execution strategy load balancing

32
Intrinsic limitationsStartup timeContentions :
concurrent accesses to shared resources sources of contention :
• architecture
• data partitioning
• communication management
• execution plan
Load imbalance response time = slowest process NEED to balance data, IO, computations, comm.

33
Shared memory archi. and databases
Pros : data transparently accessible easier load balancing fast access to data
Cons : scalability availability memory and IO contentions

34
Shared disks archi. and databases
Pros : no memory contentions easy code migration from uni-processor server
Cons : cache consistence management IO bottleneck

35
Share-nothing archi. and databases
Pros : cost scalability availability
Cons : data partitioning communication management load balancing complexity of optimization process

36
Communication : high performance networks (1/2)
High bandwidth : Gb/s Low latency : µs Thanks to :
point to point switch based topology custom VLSI (Myrinet) network protocols (ATM) kernel bypassing (VIA) net technology (optical fiber)

37
Communication : high performance networks (2/2)
Opportunity for parallel databases WAN : connecting people to archives (VoD, CDN) LAN : local network as a parallel machine
NOW are used :• as virtual super-servers
ex: one Oracle server + some read-only databases on idle workstations (hot sub-base)
• as virtual parallel machines
a different database on several machines (in hospital, one for citology, one for MRI, one for radiology, …)
SAN : on PoPC (Piles of PC), clusters• low cost parallel DBMS

38
Bibliography / WebographyG.C Fox, R.D William and P.C Messina "Parallel Computing Works !"Morgan Kaufmann publisher, 1994, ISBN 1-55860-253-4
M. Cosnard and D Trystram
"Parallel Algorithms and Architectures"
Thomson Learning publisher, 1994, ISBN 1-85032-125-6
M. Gengler, S. Ubéda and F. Desprez,
"Initiation au parallélisme : concepts, architectures et algorithmes"
Masson, 1995, ISBN 2-225-85014-3
Parallelism: www.ens-lyon.fr/~desprez/SCHEDULE/tutorials.html www.buyya.com/cluster
Grids : www.lri.fr/~fci/Hammamet/Cosnard-Hammamet-9-4-02.ppt TOP 500 : www.top500.org PVM:www.csm.ornl.gov/pvm
OpenMP : www.openmp.org HPF : www.crpc.rice.edu/HPFF