fast time series classification using numerosity reduction dme paper presentation jonathan millin...
TRANSCRIPT

Fast Time Series Classification Using Numerosity Reduction
DME Paper PresentationJonathan Millin & Jonathan Sedar
Fri 12th Feb 2010

Fast Time Series Classification Using Numerosity Reduction
• Appearing in Proceedings of 23rd International Conference on Machine Learning 2006.
• Authors:– Xiaopeng Xi, Eamonn Keogh, Christian Shelton, Li Wei,
• Computer Science & Engineering Dept, UC Riverside, CA
– Chorirat ‘Ann’ Ratanamahatana.• Dept of Computer Engineering, Chulalongkorn Uni, Bangkok
• Cited by 34 papers (Google Scholar)

Overview
• High classification accuracy on time-series data is achieved using Dynamic Time Warping and a novel application of numerosity reduction to efficiently reduce computational complexity.
Fast Time Series Classification Using Numerosity Reduction

Agenda
• Introduction• Methods– Dynamic Time Warping– Numerosity Reduction– Adaptive Warping Window (AWARD)– Fast AWARD
• Results• Discussion
Fast Time Series Classification Using Numerosity Reduction

Time-Series Data Classification
• Classifying through pattern matching
Time Series ClassificationIntroduction

What is Dynamic Time Warping?
• Compare similar time series allowing for temporal skew:
Dynamic Time WarpingMethods

How does DTW Work?Dynamic Time Warping
• Align series• Construct
distance matrix
• Find optimal warping path
• Introduce warping window to reduce complexity
Methods

DTW PerformanceDynamic Time Warping
Reported comparisons
Fig. 3
Figs. 4,5,7
Test sets (shown later)
Methods

DTW Vs LiteratureECG• Xi et al. (2006) use 1NN-DTW and
Euclidian Distance: ‘perfect accuracy’
• Kim & Smyth et al. (2004) use HMM: 98% accuracy
Lighting (FORTE-2)• Xi et al. (2006) use 1NN-DTW:
error rate 9.09%• Eads & Glocer et al. (2005) use
grammar guided feature extraction: error rate 13.22%
Dynamic Time Warping
ControlChart• Xi et al. (2006) use 1NN-DTW: error
rate 0.33%• Rodriguez & Alonso et al (2000)
use 1st order logic rules with boosting: error rate 3.6%
• Nanopolus & Alcock et al. (2001) use multi-layer perceptron NN: error rate 1.9%
• Wu & Chang (2004) use ‘super kernel fusion’: error rate 0.79%
• Chen & Kamel (2005) use ‘Static Minimization-Maximization approach’: best error rate 7.2%
Methods

Dynamic Time WarpingDynamic Time Warping
• DTW is ‘at least as accurate’ as Euclidean distance
Methods

DTW gives great results, but
• Naive implementation is computationally expensive
• LB_Keogh reduces amortised cost to O(n)• At the limits of DTW algorithm optimisation• Look elsewhere for classification speed gains...
...Numerosity reduction
Dynamic Time WarpingMethods

Numerosity Reduction Techniques
• Naive Rank Reduction
• Adaptive Warping Window (AWARD)
• Fast Numerosity Reduction (FastAWARD)
Numerosity Reduction TechniquesMethods

Naive Rank ReductionNumerosity Reduction: Naive Rank Reduction
x1
x2
d1
d2
d3
x3
x4
d3 > d4 > d2 > d1
x5
d4
• Principle: remove instances in an order which minimises misclassifications.
1. Ranking (iterative O(n))– Remove duplicates – Apply 1NN classification– Rank each x according to class of 1st NN– Break ties by proximity of nearest class
2. Thresholding– User defined, (keep n highest, best n%)
Methods

• Classification accuracy declines when the size of the dataset decreases
Naive Rank ReductionNumerosity Reduction: Naive Rank Reduction
• Larger r gives better accuracy on smaller datasets
• Motivates adaptive window
Methods

Adaptive Warping Window (AWARD)
• What– Dynamically adjusting the window size during numerosity reduction
• Why– Larger windows give better accuracy on smaller datasets
• How– Initialise r to best warping size (exhaustive search r=1:100)– Begin Naïve Rank Reduction (shown earlier)– Tests accuracy of the reduced set with r and r+1– If accuracy(r+1) > accuracy(r) then r++
• Problems– Provides a better accuracy during numerosity reduction, but the
additional checks increase complexity from O(n) to O(n3)
Numerosity Reduction: AWARDMethods

FastAWARD
• What– Essentially AWARD, but uses the calculations from
previous iterations to reduce complexity• Why– Reduce complexity to reduce execution time
• How– performs incremental updates after each step to
reduce complexity of future steps
Numerosity Reduction: FastAWARDMethods

How - Storing information
• Done by storing (for each i=r:100):– Nearest neighbour matrix (A)– Distance matrix (B)– Accuracy array (ACC)
Methods Numerosity Reduction: FastAWARD
Q
C
r
r
ACC

How – Incremental Updates
• After each item is discarded:– Update A (Neighbors)– Update B (Distances)– Update ACC (Accuracy)– Check if ACC[r+1]>ACC[r]
Methods Numerosity Reduction: FastAWARD
x1
x2
d1
d2
d3
bob
x3
d3 > d4 > d1 > d2
x4
d4
x1
x2
d1
dnew
d4x3
dnew > d1 > d3
x4

Interim Recap
• Dynamic Time Warping accounts for skew• Using AWARD numerosity reduction• FastAWARD vs AWARD
...Does it work?
RecapMethods

Experiments (Accuracy)Experimental WorkResults

ExperimentsExperimental WorkResults

Experiments (Accuracy)
• etc
Experimental WorkResults

Experiments (Efficiency)
• Massive improvements in efficiency of numerosity reduction process
Experimental WorkResults

Experiments (Anytime Classification)
• Etc
Experimental WorkResults

Summary
• 1NN-DTW is an excellent time series classifier• DTW is computationally expensive because of the
number of pattern matches• DTW algorithm is at limits of optimisation• Improve speeds by reducing number of required
matches• (Fast)AWARD adjusts the warping window with
numerosity – increases accuracy• FastAWARD is several orders of magnitude faster than
AWARD
SummaryDiscussion

Our Critique
• Two Patterns dataset seems cherry-picked• DTW model may necessitate bespoke pre-processing• RandomFix vs RankFix – very similar results• AWARD efficiency comparisons ignore initialisation
effort and speed wasn’t compared to other methods (RT1, 2, 3)
• Comparisons of r incomplete• Anytime classification experiments seem rigged in
favour of AWARD
Discussion Our Critique

Two Patterns dataset seems cherry-picked
Reported comparisons
Fig. 3
Figs. 4,5,7
Test sets (shown later)
Discussion Our Critique

DTW model may necessitate bespoke pre-processing
Discussion Our Critique

RandomFix vs RankFix - similar results
Discussion Our Critique

AWARD efficiency comparisons ignore initialisation effort and speed wasn’t
compared to other methods (RT1, 2, 3)
Discussion Our Critique
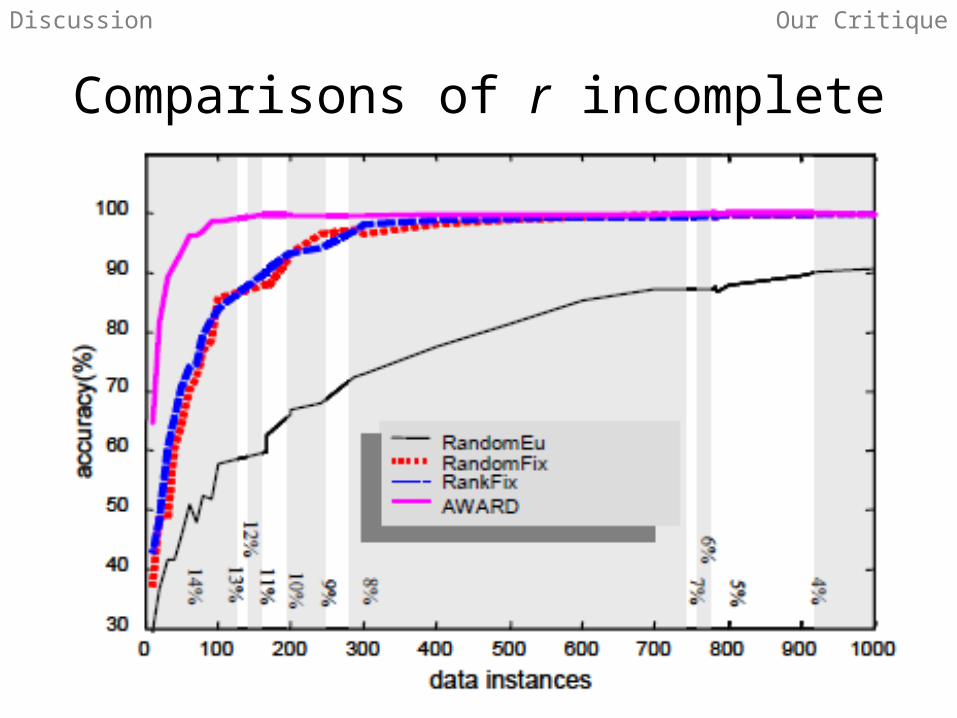
Comparisons of r incompleteDiscussion Our Critique

Anytime classification is rigged?Discussion Our Critique

Q&A
Thank You.