evolving sql server for modern hardware paul larson, eric n. hanson, mike zwilling microsoft plus to...
TRANSCRIPT

Paul Larson, ICDE 2015 1
Evolving SQL Server for Modern Hardware
Paul Larson, Eric N. Hanson, Mike ZwillingMicrosoft
plus to the many members of the Apollo and Hekaton teams

Paul Larson, ICDE 2015 2
SQL Server 2014
Evolving the architecture of SQL Server
• Hardware changed drastically since 1980s• Large cheap memory, plenty of cores, SSDs
• Deep architectural changes needed• To fully exploit the changing hardware• To adapt to different workloads
• Apollo: column-store optimized for DW• Hekaton: in-memory, row-store optimized
for OLTP• Queries and transactions can cross all three
engines
Common Front End: API, Catalog, Language, Management, Security, …
Common Back End: Storage, Backup, High-Availability, Resource Management, …
Apollo column-store
engine
Optimized for data
warehousing
Classical row-store
engine
General Purpose
Hekaton row-store
engine
Optimized for OLTP

Paul Larson, ICDE 2015 3
Agenda
• Apollo column store engine• Hekaton in-memory OLTP engine• Looking ahead

Paul Larson, ICDE 2015 4
Why add columnar storage?
1. Column stores beat the pants off row stores on analytical queries2. Increased importance of analytical workloads
• Analytical queries scan lots of rows but access only a few columns• Row stores excel at OLTP-type workloads
• Short requests accessing a few rows• Lots of overheads for scanning lots of rows
• Indexes and materialized views help • But they are expensive to store and maintain
• Column stores excel at analytical queries• Fast scans, reduced storage, reduced IO, less memory wasted• But updates tend to be slow, small lookups are expensive

Paul Larson, ICDE 2015 5
What’s in Apollo?
• Column store indexes• An index that stores data column-wise (instead of row-wise)• Can be used as a primary index (base storage) or as a secondary index• Compressed to save space• Optimized for scans
• Batch mode (vectorized) operators • Process batches of rows (~1000) instead of one row at time• Scan operator with filtering and aggregation on compressed data• Operators for select, hash join, hash aggregation, union all

Paul Larson, ICDE 2015 6
Index creation and storage
• Also have a global dictionary per column (not shown)
CA B
Encode, compress
Encode, compress
Encode, compress
Row
gro
up 3
Row
gro
up 1
Row
gro
up 2
SegmentDictionary
Dire
cto
ry
Blobs

Paul Larson, ICDE 2015 7
Column store compression
1. Encoding – convert to integers• Value-based encoding (linear transformation• Dictionary encoding
2. Row reordering• Find optimal permutation of rows (best compression)• Proprietary algorithm
3. Compression • Run length encoding (value + number of consecutive repeats)• Bit packing (use min number of bits)
4. Optional on-disk archival compression (Lempel-Ziv)

Paul Larson, ICDE 2015 8
Observed compression ratios
Database Name
Raw data size (GB)
Compression ratio
Archival compression? GZIP
No Yes
EDW 95.4 5.84 9.33 4.85
Sim 41.3 2.2 3.65 3.08
Telco 47.1 3.0 5.27 5.1
SQM 1.3 5.41 10.37 8.07
MS Sales 14.7 6.92 16.11 11.93
Hospitality 1.0 23.8 70.4 43.3
Paul Larson, ICDE 2015 9
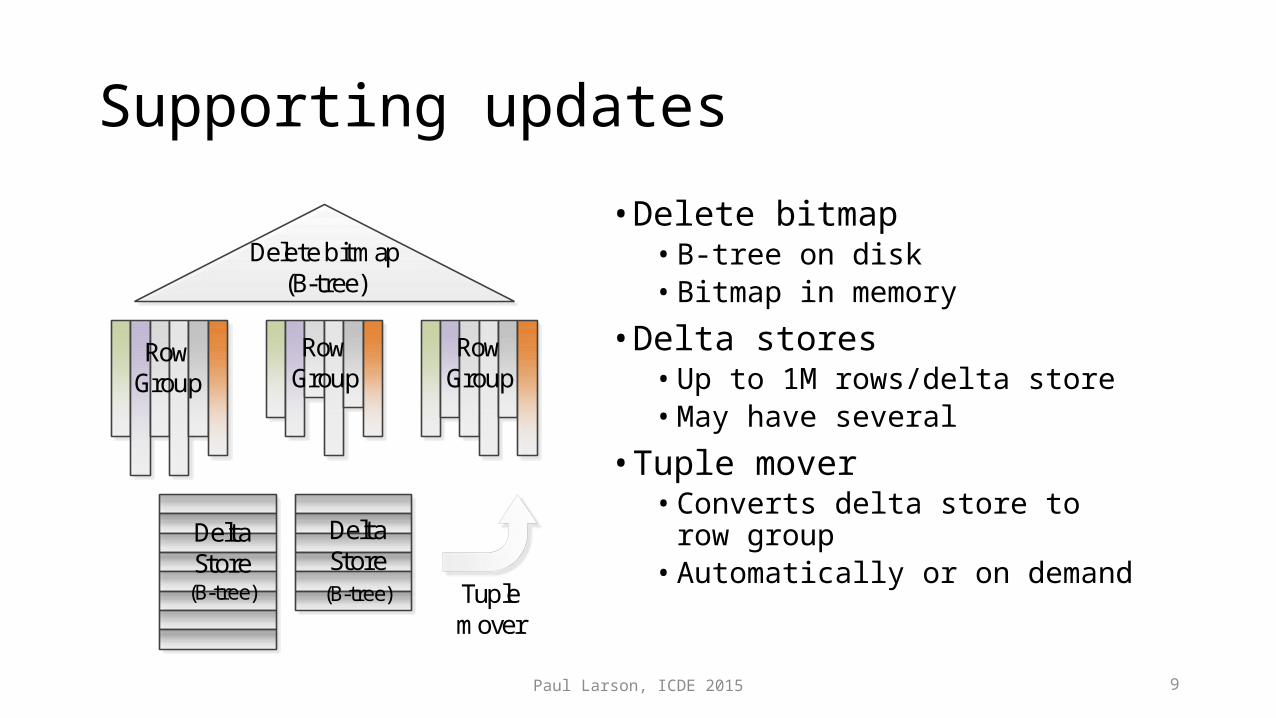
Supporting updates
• Delete bitmap• B-tree on disk• Bitmap in memory
• Delta stores• Up to 1M rows/delta store• May have several
• Tuple mover• Converts delta store to row group• Automatically or on demand
Row Group
Row Group
Row Group
Delete bitmap (B-tree)
Tuple mover
Delta Store
(B-tree)
Delta Store
(B-tree)

Paul Larson, ICDE 2015 10
Record performance on TPC-H
Date published
CS indexes used?
Sockets/cores/threads
QphH Price/QphH
4/15/13 No 8/80/160 158,108 $6.49
4/16/14 Yes 4/60/12025% fewer cores
404,0052.5X faster
$2.3464% cheaper
4/06/15 Yes 8/120/24050% more cores
652,2394.1X faster
$2.4363% cheaper
TPC-H, 10,000GB scale

Paul Larson, ICDE 2015 11
Customer Experiences
• Bwin.Party• Time to prepare 50 reports reduced by 92%• Best reduction: 17 min to 3 sec, 340X faster
• Clalit Health• 48 out of 50 problem queries ran faster• Average speedup 400X• Average wait time reduced from 20 min to 3 sec
• DevCon Security• Reports went from 10-12 sec to 1 sec, >10X• Ad hoc queries went from 5-7 min to 1-2 sec, > 100X

Paul Larson, ICDE 2015 12
Agenda
• Apollo column store engine• Hekaton in-memory OLTP engine• Looking ahead

Paul Larson, ICDE 2015 13
Hekaton: what and why
• Hekaton is a high performance, memory-optimized OLTP engine architected for modern HW trends and integrated into SQL Server
• Market need for ever higher throughput and lower latency OLTP at lower cost
• HW trends demanded architectural changes • Large main memories, lots of cores, SSDs• Data doesn’t live on disk anymore!

SQL Server Integration
• Same manageability, administration & development experience
• Integrated queries & transactions
• Integrated HA and backup/restore
Main-Memory Optimized
• Direct pointers to rows
• Indexes exist only in memory
• No buffer pool• No write-ahead
logging• Stream-based
storage
Non-Blocking Execution
• Lock-free data structures
• Multi-version optimistic concurrency control with full ACID support
• No locks, latches or spinlocks
• No I/O during transaction
T-SQL Compiled to Native Machine
Code• T-SQL compiled to
machine code leveraging VC compiler
• Procedure and its queries, becomes a C function
• Aggressive optimizations @ compile-time
Hekaton Architectural Pillars A
rch
itectu
ral P
illa
rsR
esu
lts
Hybrid engine but integrated experience
Speed of an in-memory cache
with capabilities of a database
Transactions execute to completion
without blocking
Queries & business logic run
at native-code speed
Pri
nci
ple
s Performance-critical data fits in
memoryConflicts are Rare
Push decisions to compilation time
Built-In
Paul Larson, ICDE 2015 14

Paul Larson, ICDE 2015 15
Record and index structure
90,150 Susan Beijing
50, ∞ Jane Prague
100, 200 John Paris
70, 90 Susan Brussels
200, ∞ John Beijing
Timestamps NameChain ptrs City Range index on City
Hash index on Name
JS
• Rows are multi-versioned• Each row version has a valid time range indicated by two timestamps• A version is visible if transaction read time falls within version’s valid time• A table can have multiple indexes
Row format
BW-
tree

Paul Larson, ICDE 2015 16
Transaction validation (for update transactions)
• Read stability• Check that each version read is still visible as of the end of the transaction
• Phantom avoidance• Repeat each scan checking whether new versions have become visible since the
transaction began
• Extent of validation depends on isolation level• Snapshot isolation: no validation required • Repeatable read: read stability• Serializable: read stability, phantom avoidance
Details in “High-Performance concurrency control mechanisms for main-memory databases”, VLDB 2011

Paul Larson, ICDE 2015 17
Non-blocking execution
• Goal: enable highly concurrent execution• no thread switching, waiting, or spinning during execution of a transaction
• Lead to three design choices• Use only latch-free data structure • Multi-version optimistic concurrency control• Allow certain speculative reads (with commit dependencies)
• Result:• Read-only transactions run without blocking or waiting• Update transactions block only on final log write
• Exception: speculative reads may force a transaction to wait before returning a result (rare)

Paul Larson, ICDE 2015 18
Durability and availability
• Logging changes before transaction commit• All new versions, keys of old versions in a single IO• Aborted transactions write nothing to the log
• Checkpoint - maintained by rolling log forward• Organized for fast, parallel recovery• Require only sequential IO
• Recovery – rebuild in-memory database from checkpoint and log• Scan checkpoint files (in parallel), insert records, and update indexes• Apply tail of the log
• High availability (HA) – based on replicas and automatic failover• Integrated with AlwaysOn (SQL Server’s HA solution)• Up to 8 synch and asynch replicas

Paul Larson, ICDE 2015 19
Hekaton Engine Performance (micro-benchmark)
Transaction size in #lookups/#updates
Speedup over classical engineLookups Updates
1 10.8X 20.2X10 18.4X 23.4X
100 18.1X 31.4X1,000 18.9X 27.9X
10,000 20.4X 30.5X

20
0 6 12 18 240.0
500,000.01,000,000.01,500,000.02,000,000.02,500,000.03,000,000.03,500,000.0
1V MV/O
Threads
Thro
ughp
ut (t
x/se
c)Scalability under extreme contention (1000 row table)
80% R=1020% R=10, W=2
5×
Single version, locking
Multiversion, optimistic
Paul Larson, ICDE 2015

Paul Larson, ICDE 2015
Performance does make a difference!• Bwin.party – large online gaming site
• ASP.NET session state repository • Went from 15,000 requests/sec to 250,000 requests/sec, 17X• Achieved 450,000 requests/sec in testing, 30X• Replaced 18 servers by one server
• Edgenet – provides real-time price/availability data for retailers• 8X-11X faster data ingestion enabled huge service improvements• Moved from once-a-day batch ingestion to continuous data ingestion• Consolidated multiple servers into a single database server• Removed application caching layer
• Samsung Electro-Mechanics – statistical process control system• Improved OLTP performance by 24X and DW performance by 22X• Now able to ingest and analyze all sensor data from manufacturing lines• Improved quality control, better products
21

Paul Larson, ICDE 2015 23
Agenda
• Apollo column store engine• Hekaton in-memory OLTP engine• Looking ahead

Paul Larson, ICDE 2015 24
In the not-so-distant future
• Support for real-time analytics• Column store indexes on Hekaton tables• Making secondary CS indexes updatable
• Column store enhancements• B-tree indexes on primary CS• Even faster scans

Paul Larson, ICDE 2015 25
Thank you for your attention