evaluation of embedded processors for next generation asic
TRANSCRIPT

IN DEGREE PROJECT ELECTRICAL ENGINEERING,SECOND CYCLE, 30 CREDITS
, STOCKHOLM SWEDEN 2021
Evaluation of embedded processors for next generation asicEvaluation of open source Risc-V processors and tools ability to perform packet processing operations compared to Arm Cortex M7 processors
MIKE MUSASA MUTOMBO
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE


Evaluation of embeddedprocessors for nextgeneration asic
Evaluation of open source Risc-Vprocessors and tools ability to performpacket processing operations compared toArm Cortex M7 processors
MIKE MUSASA MUTOMBO
Degree Programme in Electrical EngineeringDate: May 21, 2021Supervisor: Dimitrios Statis, Shafqat UllahExaminer: Ahmed HermaniSchool of Electrical Engineering and Computer ScienceHost company: Ericsson ABSwedish title: Utvärdering av inbyggda processorer för nästageneration asicSwedish subtitle: Utvärdering av öppen källkod Risc-V processoreroch verktyg’s förmåga att utföra databehandlingsfunktioner ijämförelse med en Arm Cortex M7 processor

Evaluation of embedded processors for next generation asic /Utvärdering av inbyggda processorer för nästa generation asic
c© 2021 Mike Musasa Mutombo

Abstract | i
AbstractNowadays, network processors are an integral part of information technology.With the deployment of 5G network ramping up around the world, numerousnew devices are going to take advantage of their processing power andprogramming flexibility. Contemporary information technology providersof today such as Ericsson, spend a great amount of financial resources onlicensing deals to use processors with proprietary instruction set architecturedesigns from companies like Arm holdings.
There is a new non-proprietary instruction set architecture technologybeing developed known as Risc-V. There are many open source processorsbased on Risc-V architecture, but it is still unclear how well an open-sourceRisc-V processor performs network packet processing tasks compared to anArm-based processor.
The main purpose of this thesis is to design a test model simulatingand evaluating how well an open-source Risc-V processor performs packetprocessing compared to an Arm Cortex M7 processor. This was doneby designing a C code simulating some key packet processing functionsprocessing 50 randomly generated 72 bytes data packets. The followingfunctions were tested: framing, parsing, pattern matching, and classification.The code was ported and executed in both an Arm Cortex M7 processor andan emulated open source Risc-V processor.
A working packet processing test code was built, evaluated on an ArmCortex M7 processor. Three different open-source Risc-V processors weretested, Arianne, SweRV core, and Rocket-chip. The execution time of bothcases was analyzed and compared. The execution time of the test code onArm was 67, 5 ns.
Based on the results, it can be argued that open source Risc-V processortools are not fully reliable yet and ready to be used for packet processingapplications.
Further evaluation should be performed on this topic, with a more in-depthlook at the SweRV core processor, at physical open-source Risc-V hardwareinstead of emulators.
KeywordsNetwork processing, Risc-V, Packet processing, Instruction set architecture,Open-source

ii | Abstract

Sammanfattning | iii
SammanfattningNätverksprocessorer är en viktig byggsten av informationsteknik idag. I taktmed att 5G nätverk byggs ut runt om i världen, många fler enheter kommeratt kunna ta del av deras kraftfulla prestanda och programerings flexibilitet.Informationsteknik företag somEricsson, spenderarmycket ekonomiska resurserpå licenser för att kunna använda proprietära instruktionsuppsättnings arkitekturteknik baserade processorer från ARM holdings. Det är väldigt kostam attfortsätta köpa licenser då dessa arkitekturer är en byggsten till designen avmånga processorer och andra komponenter.
Idag finns det en lovande ny processor instruktionsuppsättnings arkitekturteknik som inte är licensierad så kallad Risc-V. Tack vare Risc-V har mångapropietära och öppen källkod processor utvecklats idag. Det finns dock väldigtlite information kring hur bra de presterar i nätverksapplikationer är käntidag. Kan en öppen-källkod Risc-V processor utföra nätverks databehandlingfunktioner lika bra som en proprietär Arm Cortex M7 processor?
Huvudsyftet med detta arbete är att bygga en test model som undersökerhur väl en öppen-källkod Risc-V baserad processor utför databehandlingsoperationer av nätverk datapacket jämfört med en Arm Cortex M7 processor.Detta har utförts genom att ta fram en C programmeringskod som simulerar enmottagning och behandling av 72 bytes datapaket. De följande funktionernatestades, inramning, parsning, mönster matchning och klassificering. Kodenkompilerades och testades i både en Arm Cortex M7 processor och 3 olikaemulerade öppen källkod Risc-V processorer, Arianne, SweRV core ochRocket-chip.
Efter att ha testat några öppen källkod Risc-V processorer och använt testkoden i en ArmCortexM7 processor, kan det hävdas att öppen-källkod Risc-Vprocessor verktygen inte är tillräckligt pålitliga än. Denna rapport tyder på attöppen-källkod Risc-V emulatorer och verktygen behöver utvecklas mer för attanvändas i nätverks applikationer.
Det finns ett behov av ytterligare undersökning inomdetta ämne i framtiden.Exempelvis, en djupare undersökning av SweRV core processor, eller enöppen-källkod Risc-V byggd hårdvara krävs.
NyckelordNätverksprocessorer, instruktionsuppsättnings arkitektur, Risc-V, öppen-källkod,processorer

iv | Sammanfattning

Acknowledgments | v
AcknowledgmentsI would like to thank my parents, Symphorien Kazadi Musasa who is sadlyno longer here to read this work and Kyungu Nkulu Faustine for inspiring meevery day and for their sacrifices for me to be where I am today. They havetaught me resilience, perseverance, an inquisitive spirit which has led me topursue a career in engineering.
I would like to thank the rest of my family and friends, who kept onencouraging me to keep going when I had doubts during this project andhelpedme staymotivated and finish this project during the Covid-19 pandemic.
I would like to thank my childhood friend Ario Amin for all of the good cprogramming advice.
I would like to thank Pierre Rhoddin and Shafqat Ullah for giving me theopportunity to work on this project for Ericsson and expand my knowledge asan engineer while putting to the test what I’ve learned at KTH.
I would like to give an extra thank you to Shafqat Ullah, Johnny Öberg, andDimitrios Stathis for the countless advice, guidance, meetings, and availabilityto answers questions and help when i encountered road blocks.
I would like to thank Kungliga tekniska högskolan, for everything I havelearned there about electrical engineering and how to quickly adapt and learnnew information.
Last but not least, I thank God for the life I get to live and the amazingthings I get to be part of.
Stockholm, May 2021Mike Musasa Mutombo

vi | Acknowledgments

CONTENTS | vii
Contents
1 Introduction 11.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Research question . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.5 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.6 Research Methodology . . . . . . . . . . . . . . . . . . . . . 61.7 Delimitations . . . . . . . . . . . . . . . . . . . . . . . . . . 71.8 Structure of the thesis . . . . . . . . . . . . . . . . . . . . . . 8
2 State of the art 92.1 Network processing . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Network processors . . . . . . . . . . . . . . . . . . . 92.1.2 Packet processing . . . . . . . . . . . . . . . . . . . . 11
2.2 CISC vs RISC instruction set architecture . . . . . . . . . . . 122.3 Risc-V project . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.1 The Risc-V instruction set . . . . . . . . . . . . . . . 152.4 ARMv7 instruction set architecture . . . . . . . . . . . . . . . 182.5 Arm M processors family . . . . . . . . . . . . . . . . . . . 21
2.5.1 Arm Cortex M7 processor . . . . . . . . . . . . . . . 222.6 Related work area . . . . . . . . . . . . . . . . . . . . . . . . 26
2.6.1 RVNet packet processing system . . . . . . . . . . . . 262.7 Ericsson . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Method 293.1 Project model . . . . . . . . . . . . . . . . . . . . . . . . . . 303.2 Project Phases . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2.1 Literature study and state of the art . . . . . . . . . . 323.2.2 Packet processing simulation code in C . . . . . . . . 32

viii | Contents
3.2.3 The Risc-V phase . . . . . . . . . . . . . . . . . . . . 403.2.4 The Arm phase . . . . . . . . . . . . . . . . . . . . . 423.2.5 Performance evaluation . . . . . . . . . . . . . . . . . 443.2.6 Result documentation and presentation . . . . . . . . 44
4 Implementation 474.1 Packet processing code . . . . . . . . . . . . . . . . . . . . . 47
4.1.1 Framing . . . . . . . . . . . . . . . . . . . . . . . . 494.1.2 Parsing . . . . . . . . . . . . . . . . . . . . . . . . . 544.1.3 Searching and classifying . . . . . . . . . . . . . . . 544.1.4 Packet modification . . . . . . . . . . . . . . . . . . . 55
4.2 Risc-V implementation . . . . . . . . . . . . . . . . . . . . . 574.3 Arm implementation . . . . . . . . . . . . . . . . . . . . . . 61
5 Results 655.1 Packet processing code . . . . . . . . . . . . . . . . . . . . . 655.2 Risc-V implementation . . . . . . . . . . . . . . . . . . . . . 675.3 Arm test results . . . . . . . . . . . . . . . . . . . . . . . . . 70
6 Discussion 716.1 Packet processing code . . . . . . . . . . . . . . . . . . . . . 716.2 Risc-V implementation . . . . . . . . . . . . . . . . . . . . . 726.3 Arm implementation . . . . . . . . . . . . . . . . . . . . . . 736.4 Advantages and disadvantages summary . . . . . . . . . . . . 73
7 Conclusions and Future work 757.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 757.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . 767.3 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
References 77
A Additional Hello world output log 81
B Additional testar output log 83
C Additional Side by side comparison output log 86
D Packet processing code 87

LIST OF FIGURES | ix
List of Figures
2.1 Ethernet data link layer protocol encapsulated into a IEEE 802.3MAC packet . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 A general packet processing framework [1] . . . . . . . . . . 122.3 Table summary of several ISA support for desirable architectural
features. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4 Table of the state of the base and Risc-V extensions [2] . . . . 152.5 RV32I instruction formats [3] . . . . . . . . . . . . . . . . . . 162.6 A sample of some of the 16-bit Thumb instruction encoding [3] 202.7 32-bit Thumb instruction encoding with different encoding
examples [3] . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.8 An Arm cortex M7 implementation [4] . . . . . . . . . . . . . 222.9 Components of the CortexM7 processor from the ArmCortex
M7 reference manual [4] . . . . . . . . . . . . . . . . . . . . 242.10 Hardware overview of the RVNet processing framework [5] . . 27
3.1 Project model . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2 Idea 2 flow chart . . . . . . . . . . . . . . . . . . . . . . . . 343.3 Idea 3 flow chart . . . . . . . . . . . . . . . . . . . . . . . . 363.4 CRC check example from the sender side . . . . . . . . . . . 383.5 CRC check example from the receiver side . . . . . . . . . . 393.6 Arm implementation description graph . . . . . . . . . . . . 43
4.1 Bytes to bits conversion flow chart . . . . . . . . . . . . . . . 484.2 Framing algorithm step 1 flow chart . . . . . . . . . . . . . . 504.3 Framing algorithm step 2 flow chart . . . . . . . . . . . . . . 514.4 Framing algorithm step 3 flow chart . . . . . . . . . . . . . . 534.5 Example of a parsing for loop flow chart, preamble for loop . 544.6 Searching and classifying flow . . . . . . . . . . . . . . . . . 564.7 Hello world output log snippet . . . . . . . . . . . . . . . . . 604.8 SimVision waveform analysis example for 50 packets . . . . . 63

x | LIST OF FIGURES
5.1 CRC check example test result . . . . . . . . . . . . . . . . . 665.2 Framing algorithm result . . . . . . . . . . . . . . . . . . . . 665.3 Preamble parsing result . . . . . . . . . . . . . . . . . . . . . 675.4 Search and classification result . . . . . . . . . . . . . . . . . 675.5 Hello world output log, lines 19 -195 . . . . . . . . . . . . . 685.6 Testar output log, first 200 cycles . . . . . . . . . . . . . . . 685.7 Same packet processed execution side to side comparison
output log snippet . . . . . . . . . . . . . . . . . . . . . . . 695.8 Same packet processed execution side to side comparison
output log snippet . . . . . . . . . . . . . . . . . . . . . . . 69
A.1 Hello world output log, lines 196-325 . . . . . . . . . . . . . 81A.2 Hello world output log, lines 341-514 . . . . . . . . . . . . . 82
B.1 Testar output log, cycles 200 to 320 . . . . . . . . . . . . . . 83B.2 Testar output log, cycles 332 to 500 . . . . . . . . . . . . . . 84B.3 Testar output log, cycles from lines 30 000 . . . . . . . . . . . 84B.4 Testar output log, last cycles . . . . . . . . . . . . . . . . . . 85
C.1 Same packet processed execution side to side comparisonoutputlog snippet . . . . . . . . . . . . . . . . . . . . . . . . 86

LIST OF TABLES | xi
List of Tables
1.1 Sub-goals and how they can be achieved . . . . . . . . . . . . 5
2.1 Table of Arm cortex M7 different interfaces . . . . . . . . . . 25
3.1 List of requirements . . . . . . . . . . . . . . . . . . . . . . . 303.2 List of requirements for the Risc-V processor selection . . . . 41
5.1 Execution time on Arm cortex M7 for 1, 5, 10 and 50 datapackets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70

xii | LIST OF TABLES

LISTINGS | xiii
Listings
4.1 Test code in C . . . . . . . . . . . . . . . . . . . . . . . . . . 584.2 Hello world C code from the Rocket-chip repository . . . . . . 594.3 Testar test code . . . . . . . . . . . . . . . . . . . . . . . . . 61D.1 Packet processing code . . . . . . . . . . . . . . . . . . . . . 87

xiv | LISTINGS

List of acronyms and abbreviations | xv
List of acronyms and abbreviationsAHB Advance high speed buss
AHBD Advance high performance lite debug
AHBP Ad hoc broadcast protocol
AHBS Advance high speed buss slave
AMD Advanced micro devices
APB Advanced peripheral bus
ARM Acorn risc machine
ASIP Application specific instruction processor
ATB Advance trace bus
AXI Advanced extensible interface
BIU Bus interface unit
BRAM Block random access memory
CISC Complex instruction set architecture
CRC Cyclic redundancy check
CTI Cross trigger interface
DCCM Data closely coupled memory
DDR Double data rate
DSP Digital signal processor
DTCM Data tightly coupled memory
ECC Error correction code
ELF Executable and linkable format
ETM Embedded trace macrocell

xvi | List of acronyms and abbreviations
FPGA Field programmable gate array
FPU Floating point unit
GBPS Gigabit-per-second
GCC GNU compiler collection
IBM International Business Machines Corporation
ICT Information and communication technology
IEEE Institute of electrical and electronics engineers
IOT Internet of things
ISA Instruction set architecture
ISR Interrupt service routine
ITCM Instructions TCM
ITM Instrumentation trace macrocell
MAC Medium access control
MBIST Memory built in self test
MIPS Million instructions per seconds
MPU Memory protecting unit
NP Network processor
PPB Private peripheral bus
RAN Radio access network
RISC Reduced instruction set architecture
RTL Register transfer level
SP Stack pointer
TCM Tightly-coupled memory

List of acronyms and abbreviations | xvii
TCU Tightly-coupled interface unit
WIC Wake-up interrupt controller

xviii | List of acronyms and abbreviations

Introduction | 1
Chapter 1
Introduction
1.1 BackgroundNetwork processor (NP) are currently key essential components of many high-end network systems and network processing environments today [1]. Theyare chips that can process network packets at Gigabit-per-second (GBPS)speeds [1]. Their flexible programmability and ability to perform complexpacket processing operations make them a crucial tool for future internetapplications thanks to the bandwidth explosion of the latest years [6].
Nowadays, there are many network processor manufacturers, such as Intel,International Business Machines Corporation (IBM) and Acorn risc machine(ARM) holdings, who produce quality network processors and offer paidlicensing deals to use their technology. These licensing deals are expensivefor information and communication providers such as Ericsson today sincethey have to pay great fees for every device they produce [7].
Most popular processors are based on X86 instruction set architecture.There has been debates onwhether using a Reduced instruction set architecture(RISC) or Complex instruction set architecture (CISC) based Instruction setarchitecture (ISA) is more efficient performance-wise [8], [9]. Blem et al[9]found in their study that there is nothing more energy efficient in one ISA classor the other but rather that ARM,Million instructions per seconds (MIPS), andX86 processors are simply engineering design points optimized for differentlevels of performance and that the type of applications plays a role as well.
In 2010 a new instruction set architecture for processors, Risc-V started

2 | Introduction
being developed at the University of Berkley as part of a parallel computingproject [2]. The goal of developing this ISA was to enable the developmentof open-source ISA and royalty-free for different hardware, software, andacademia for processor development [10].
Risc-V technology is currently under development and is still being testedin different applications. There are many Risc-V processor implementations[11]. Some have commercial licenses and non-commercial licenses but thereare a few that have been developed in the same open-source spirit as the Risc-V ISA such as Rocket-chip, SweRV core, Ariane, and more. One previousstudy involving the Rocket-chip Risc-V processor in an optimized fast Networkpacket processing framework has been performed earlier [5]. When comparedto the Intel X86 based DDPK network framework, different results wereobtained for different packet sizes.
So far, it is not yet fully known and agreed upon today if a license-freeRisc-V processor is reliable enough and can perform as well as or better thanArm processors in packet processing applications.
1.2 ProblemSome of the packet processing functions of a network system can be executedfaster and efficiently on a separate processor, for example, parsing, classifyingframes, and pattern matching. Using an extra processor for these tasks willease the load of the main processor and enable it to focus on more complextasks. The use of extra processors implies more money being spent onlicensing deals for every device that is produced by information technologyproviders such as Ericsson with companies like ARM since most commercialISA are proprietary.
TheRisc-V ISAwas developedwith an open-source spirit to bring somethingnew to the ISA market that is not proprietary [3]. The Risc-V technology isrelatively new and being tested in many different types of areas. Several open-source Risc-V processors have been and are being developed today [11]. Risc-V has a lot of potentials, but very little is known about how well it performscompared to current technology in different areas. So far, one of those areasis network processing. The question remains as to whether a Risc-V processorcan perform packet processing as well or better than an Arm-based processor?

Introduction | 3
1.3 Research questionCan an open-source Risc-V processor handle packet processing as well orbetter than an ARM based processor?
1.4 PurposeThe main purpose of this thesis is to design a test model that simulatesand evaluates how well an open-source Risc-V processor performs packetprocessing compared to an Arm Cortex M7 processor. This will provideEricsson with knowledge that could be used to decide whether it would bebeneficial for the company’s future to invest in developing or use Risc-V basedprocessors for some of their current network processing systems today. It willalso add some contribution to what is know of Risc-V processor in networkprocessing user cases other than what is documented in Wang et al study [5].
There are both financial and scientific benefits in examining howwell Risc-V technology is performing today in comparison to what is commonly used. Ifbig information technology providers like Ericsson begin incorporating Risc-V processors in their system, this will lead to other providers getting moreinterested in Risc-V based technology too. The result of this study will offeropportunities to boost and push for the development of Risc-V technology bydesigning Risc-V based solutions for network system.
This thesis also presents a good and interesting engineering project thatwill allow the author to test and broaden his projectmanagement and engineeringskills. Moreover, if it fulfills the criteria of a master thesis, it will result in theauthor being granted a Master of Science degree in electrical engineering andcomputer science.
1.5 GoalsThe goal of this project is to evaluate the maturity and performance of license-free open-source Risc-V processors in network processing usage compared

4 | Introduction
to an Arm M7 processor. This will be achieved by designing a C softwareprogram simulating a system receiving 50 randomly generated 72 bytesinternet data packets and performing some packet processing operations onthe packet. The following packet processing functions will be implemented:
• Framing, ensuring that the data is correct using Cyclic redundancy check(CRC)
• Parsing the incoming data packet and dividing it into different fields tounderstand what type of packet it is and classify it.
• Packet modification, modifying some of the packet’s data
• Pattern matching and classification, search for specific byte patterns inthe packet
The code will be compiled and executed on both an open-source Risc-V processor and an Arm Cortex M7 processor. Performance data of theexecution time (number of cycles) will be collected using Cadence SimVision,simulating tools. If time permits, synthesis for area and power performance ofboth processors will be performed.
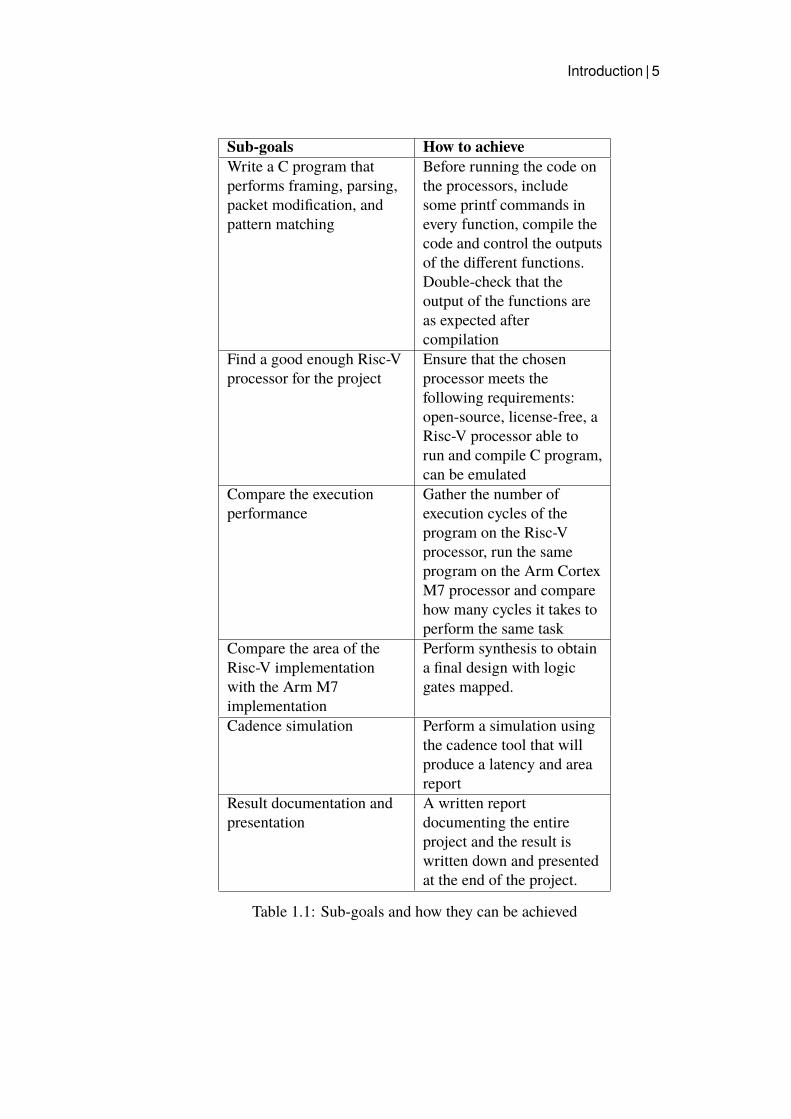
Introduction | 5
Sub-goals How to achieveWrite a C program thatperforms framing, parsing,packet modification, andpattern matching
Before running the code onthe processors, includesome printf commands inevery function, compile thecode and control the outputsof the different functions.Double-check that theoutput of the functions areas expected aftercompilation
Find a good enough Risc-Vprocessor for the project
Ensure that the chosenprocessor meets thefollowing requirements:open-source, license-free, aRisc-V processor able torun and compile C program,can be emulated
Compare the executionperformance
Gather the number ofexecution cycles of theprogram on the Risc-Vprocessor, run the sameprogram on the Arm CortexM7 processor and comparehow many cycles it takes toperform the same task
Compare the area of theRisc-V implementationwith the Arm M7implementation
Perform synthesis to obtaina final design with logicgates mapped.
Cadence simulation Perform a simulation usingthe cadence tool that willproduce a latency and areareport
Result documentation andpresentation
A written reportdocumenting the entireproject and the result iswritten down and presentedat the end of the project.
Table 1.1: Sub-goals and how they can be achieved

6 | Introduction
A final report documenting the entire project as well as the results will bedelivered at the end of the project.
1.6 Research MethodologyFor this thesis, a more quantitative approach will be required since someperformance data will be collected, analyzed, and compared to answer theresearch question. No specific behavior of the technology (Risc-V in this case)will be studied but by performing some tests on a specific case study, someacceptable results can be obtained to answer the research question. In thisthesis, an experiment will be used to measure how well a specific task is beingperformed. Based on the above-mentioned arguments, a quantitative approachis well-suited to a qualitative approach.
Based on the conclusions found inWang et al.’s paper [5], where a physicalfast and high energy efficiency network processing system on Risc-V ISA wasimplemented, a more pessimistic assumption can be made. In Wang et al.study [5], an entire network processing framework was implemented on aField programmable gate array (FPGA) with many optimizations for examplepre-allocation buffers. The results indicate good performance on that Risc-Vimplementation for data packets of sizes larger than 256 bytes. This thesis willfocus on 72 bytes data packets and as a result, the expectations are moderate.As mentioned earlier, very little research has been conducted on networkpacket processing with Risc-V based processor. The RVNet paper was theonly paper found during the literature search that used one directly [5]. Thisthesis project can bring some new insight into the topic.
A mixture of applied research and an empirical research method is chosenfor this thesis considering that a specific question will be answered. Nocausalities, relations, or behavior will be studied in depth but through aninductive strategy, experiments will be run, data will be collected and analyzedto answer the thesis question. The inductive strategy in this case will be usedinstead of a deductive one because there are not enough previous studies orresearch on this topic. This is needed to have full confidence in the hypothesisthat will be generated from the results of this experiment.
The data that will be used for the packet processing will be randomlygenerated data bytes for the experiment. This guarantees no violations of

Introduction | 7
ethical standards as no personal information from people will be used. TheC code will be designed in such a way that the input data packet can easily bemodified to perform the packet processing on different sets of data.
To limit the number of variables affecting the results, some specificallyselected packet processing functions will be implemented in the experiments,one can view the experiment as a specific case study.
The validity of the results will be guaranteed by the check-up middle stepsduring the experiments. For example, to guarantee that the separate packetprocessing functions in the C code are performing correctly, they will be testedwith a well-designed test packet and printf calls will be put in place at the endof every function. The results of the Arm processor will be analyzed usingthe SimVision tool from Cadence to check that data is being written to thememory and correct signal activities on the data buses of the processor areobserved.
The C code will be available as an appendix at the end of the report.Information on how to build the same Risc-V processor as well as every steptaken for the experiment will be documented in the same report to allow otherinvestigators to replicate the experiments. The experiment will be performedon many different data packets to get reliable results. There may be somedetailed information that is confidential for Ericsson that will not be publishedbut most of the technical steps needed will be available in the report. The datapackets are randomly produced so no confidential or personal data will be usedin this thesis. This thesis will be performed in good faith and every externalmaterial used during the project will be mentioned with a reference to make itaccessible.
1.7 DelimitationsDue to the difficulty to correctly evaluate how complex the work will be andthat the thesis has a time limit, this section clarifies what will not be done inthis thesis. This project will use developed open-source Risc-V processor asit is and not make a new processor nor change some architectural features.No special optimization nor add-ons such as extra memory or buses will beused. No Risc-V physical hardware will be built, instead, every test willbe virtual/ software-based. The Risc-V processor will be built and run on a

8 | Introduction
Linux-based system (Ubuntu 20.04 LTS). The Arm Cortex M7 will be a realone accessed remotely. Only the packet processing functions mentioned inthe goals subsection will be implemented. These are some of the key packetprocessing information and the C code algorithm will not be optimized. Moretime will be allocated to getting acquainted with the test processors, writingthe C simulation code, and porting the code to be executed on the differentprocessors.
1.8 Structure of the thesisChapter 2 presents relevant technical background information about networkprocessing, the Risc-V project, ArmCortexM7 processors. Chapter 3 presentsthe method used to solve the problem, with a project model comprising thedifferent phases of the project. Chapter 4 describes in detail the implementationof the different phases and how they were executed to solve the problem andobtain some results. Chapter 5 presents the results of the experiments. Theseresults are discussed in Chapter 6, with a special focus on what can be learnedfrom the data and project in general. Finally, chapter 7 is where everythingis wrapped up, conclusions are drawn and some recommendations for futurework based on the findings from this thesis.

State of the art | 9
Chapter 2
State of the art
In order to understand this report, some basic technical background knowledgeabout Risc-V ISA, the Risc-V project, network processors and Arm cortexM7 processors are needed. This chapter gives an overall description of thesedifferent topics based on reliable books, papers and product documentations.
2.1 Network processingThe continued growth of the internet, as well as the quest for a more connectedworld, has made telecommunication and data networks very essential to ourworld today. A lot of information is being transmitted and processed throughnetwork systems.
Network systems are special-purpose systems containing both hardwareand software that are used for network processing [1]. Network processingconsist of two different planes, a control plane and a data plane [1], [5]. Thecontrol plane is in charge of controlling and managing the forwarding process,while the data plane handles the actual packet forwarding process [5]. This isdone with the help of network processors.
2.1.1 Network processorsA network processor is an Application specific instruction processor (ASIP)for networking applications. It is a software programmable device witharchitectural features and special circuitry for packet processing [6]. Network

10 | State of the art
processors are categorized into 3 categories based on their use and capacities[1].
• Entry-level NP or access NP, with a process streaming capacity of up 1or 2 Gbps packets. These are used in applications such as telephony,digital subscriber loop access, cable modems, Radio access network(RAN), and optical networks. Some examples of such NPs are EZchip’sNPA, Wintegra’s WinPath, Agere, PMC Sierra, and Intel’s IXP2300.
• Mid-level NP with a processing streaming capacity between 2–5 Gbpspackets, these are commonly used in applications such as servicecards of communication equipment, data center equipment, deep packetinspection, and layer 7 applications. Some examples are AMCC, Intel’sIPX, C-port, Agere, Vittese, and IBM’s NP, Cisco’s QFP, Cavium, RMI,Broadcom, Silverback, and Chelsio.
• High-end level NPwith a processing streaming capacity between 10–100Gbps packets, mainly used for core and metro networks. Hundredsof millions of packets per second can be processed by these powerfulnetwork processors. Some examples are the EZchip’s NPs, Xelerated,Sandburst (which was bought by Broadcom), Bay Microsystems, or thein-house Alcatel-Lucent SP2.
Network processors have different architecture and programming modelsthan general-purpose processors [1]. Most NPs include extra hardware fortraffic management and search engines and have high-speed memory andpacket I/O interfaces. Some important key functions performed by a NP are:
• Parsing incoming data frames to understand what they are
• Retrieving important information from frames
• Packet analysis
• Classifying frames
• Modifying the frame’s contents or headers, changing addresses, oraltering the contents
• Forwarding
• Pattern matching

State of the art | 11
2.1.2 Packet processingPacket processing can be categorized according to direction [1] :
• Ingress (entering the equipment or the network processor, from thenetwork)
• Egress (exiting the equipment or the network processor, to the network).
• Combinations of Ingress and Egress
This project looks at an Ingress packet process. When a packet entersa network processor, it goes through a framing process to ensure that thepacket arrived correctly. This will be followed by the parsing and classificationprocess, identifying what type of data this packet contains and the forwardingdirection. Figure 2.1 shows what type of information is stored in the differentbits of an Ethernet data packet.
octets: 6 6 2 46 to 1500 0 to 46 4
ETHERNETdata link-layer
DestinationAddress
SourceAddress
Length/Type Data Payload Padding CRC
octets: 7 1... ... Variable
MACpacket
Preamble SFD MAC Client Data Padding CRC Extension
Figure 2.1: Ethernet data link layer protocol encapsulated into a IEEE 802.3MAC packet
Since there aremany fields, a searching process is often necessary to accesssome specific information and find some patterns. The next step is to modifythe packet (if necessary) before transmitting it. Transmitting generally requiressome extra functions such as queuing, prioritization, and traffic managementof the packet to ensure that the receiver can receive the transmitted packet atexpected traffic patterns. But these last functions can be executed outside of anetwork processor. Figure 2.2 shows a general packet processing frameworksummarizing all of the steps from [1].
The most common tasks in ingress processing are listed below [1] :
• Error checking
• Security checking and decoding

12 | State of the art
• Classification (or demultiplexing)
• Traffic management (measurement and policing)
• Searching (usually address lookup)
• Header manipulations
• Packet reassembly
• Packet prioritization and queuing
• Packet forwarding
Figure 2.2: A general packet processing framework [1]
2.2 CISC vsRISC instruction set architectureFromCharles Babbage’s analytical engine in the 1840’s, the Robinsonmachinein world war II to toady’s modern computers, the architecture of automatedcomputing devices have undergone a lot of changes [12]. Today, there aremany different computing architectures for a wide range of user needs.
The architecture of a computer can be viewed as the interface between thehardware and the lowest level software[13]. This creates an abstraction level toimprove the design process. There are two main philosophies when it comesto computer architecture, specifically CISC and RISC. Complex instructionscould be computed during many cycles in CISC computers. The hardware

State of the art | 13
performsmost of the work. Examples of CISC architecture are the intel X8688and X64 architectures, Advanced micro devices (AMD) processors Opteron,Ryzen, Athlon, Turion, IBM370/168.
In RISC computers, which were introduced around 1948 by John VonNeumann, data and instructions of different types could be stored in memory,the stored program concept was introduced[13]. The program code could bestored and manipulated in the same way as data. Complex instructions couldbe computed using simple instructions.
RISC’s basic philosophy is to move the complexity from the hardware tothe language compiler [14]. This is done by keeping the hardware as simpleas possible and fast. Complex instructions are executed using sequencesof simpler instructions. In addition, RISC processors also have smallerand simpler instruction decode units that produce fast instruction execution,reducing both size and power consumption of a processing unit. The CortexM7 by ARM holdings is an example of a RISC based processor.
2.3 Risc-V projectRisc-V is an open ISA design based on RISC principles developed originallyat the University of California, Berkeley in 2010 by Yunsup Lee, KrsteAsanović, David A. Patterson, and Andrew Waterman [2]. After manyiterations and improvement of RISC architecture projects, hence the nameRisc-V, it was officially introduced in 2013 [15]. Risc-V was developed toenable the innovation and development of processors of the future throughopen standard collaboration as well as providing students with a free andopen-source platform for academic purposes. There are many reasons why theRisc-V development was necessary that have been described by Asanovic andPatterson [10] and Waterman [3] but the most important among them were:
• The proprietary nature of most popular commercial ISA’s hinders thedevelopment of free and open-source implementations based on themsince the companies are making big profit through licensing deals [7].The negotiation process for these licenses is long and the fees are quiteexpensive too. One of the biggest risks with most of these technologiesbeing proprietary is that in case a company owning one of them shutsdown, the technology will go down along with it [10].

14 | State of the art
• The massive complexity of the popular commercial instruction setspresents a substantial challenge for implementation in hardware, asWaterman mentioned in [3]. It is possible to get similar performanceswith simpler instruction sets.
The team at the University of Berkley also looked at the possibility to usean existing instruction set instead of building a new one based on the followingcriteria :
• Create a free and open-source ISA
• Support 32 and 64 bit address spaces
• Create a small but complete ISA
• Support the IEEE 754-2008 floating point standard
• Create an ISA fully virtualizable and with position-independent code
• Support compressed instructions
• Orthogonalize (e.g. separate) the user ISA and privileged architecture.
Here is a table taken from [3], where they compared some potentialcommercial and open-source ISA while developing Risc-V.
Figure 2.3: Table summary of several ISA support for desirable architecturalfeatures.
Today, Risc-V is managed by the Risc-V foundation [2].

State of the art | 15
2.3.1 The Risc-V instruction setRisc-V was designed to have a very simple and small base implementationsuitable for academic purposes, research, and low power embedded systems.It is also extendable to a more powerful ISA for high-performance computing[3]. While developing the Risc-V ISA, the developers were careful in theirapproach after learning from the mistakes and flaws of previous RISC designswhile setting it up for improvement that may be needed in the future [15].It is a very modular instruction set with the base implementation (RV32I)being small enough and containing the necessary functions to be used in asmall embedded system. Different types of extensions can be added, theseextensions are frozen after a while to limit the number of changes that can bemade. A frozen extension is locked and no additional changes can be made toit. Some of the different extensions will be described in this section.
Below in figure 2.4 is a table taken from the Risc-V foundation website ofthe current status of different extensions as of 20191214. Some are awaitingratification but are not expected to change.
Figure 2.4: Table of the state of the base and Risc-V extensions [2]
Some more detailed descriptions of the base model and extensions can befound inWaterman [3], Ledin [15] and Patterson&Hennessy [13]. Some shortsummaries describing the base models and some of the extensions available

16 | State of the art
are listed below:
• Characteristic summary of the RISC-V base instruction set (RV32I)
– 32 integers– 32 registers– 32-bit addresses– 47 instructions– 8 system calls– 1 program counter register– Little Indian order– 6 instruction formats (R, I, S,U, SB, SJ)– 21 computational instructions (no multiplication, no division,bitwise shifts)
– 5 memory access instructions– 6 flow control instructions
Figure 2.5 shows the instruction formats of RV32 taken from [3]
Figure 2.5: RV32I instruction formats [3]
• Characteristic summary of the Risc-V 64 integer base ISA (RV64I)
It is pretty similar to the 32 base ISA with some small add-ons anddifferences.
– 64-bit address– 64 registers

State of the art | 17
– 12 new instructions
– 3 new memory access instructions
A very short summary of the different extensions
• M extension
– For integer multiplication and division
• A extension
– Provides atomic read and write for multi-threaded processing inshared memory
– Load reserved and store conditional
– Suitable for inter-processor synchronisation
• C extension
– Implements compressed instructions
– Alternate 16-bit expression of common 32-bit instructions
– Minimized code size with no execution performance penalty
• F single precision floating-point extension
– Floating-point registers are added
– Floating-point instructions complying with the IEEE 754-2008single-precision standard are added
– Single floating-point precision arithmetic
– Single floating-point precision load and store
• D double precision floating-point extension
– Expands floating-point f extension to 64 bits following the IEEE754-2008 double precision standard
– Can not work without F extension present
– Double precision arithmetic
– Double precision load and store

18 | State of the art
Other extensions include theQ extension for 128-bit quad-precision floating-point mathematics, the G extension, the L extension for decimal floatingpoints, the V extension for parallel, and many more described in detail byWaterman [3], and Ledin [15] as mentioned earlier.
Since Risc-V is not proprietary, there are open-source Risc-V simulators,compilers, debuggers, and easily available open-source Risc-V implementationsonline. It can be used in a wide range of different applications from microembedded processors to server multiprocessors. Most of the implementationcan be found on the Risc-V website [11].
2.4 ARMv7 instruction set architectureIn 2006 a new ISA, ARMv7 was introduced by ARM, which was based ontheir previous ISA Thumb-2. ARMv7 has 3 different types of profiles.
• ARMv7-A, an application profile for systems that support both ARMand Thumb instruction set, requiring virtual address support
• ARMv7-R, real-time profile for systems supporting the ARM andThumb instruction sets, and requiring physical address only support
• ARMv7-M, microcontroller profile for systems supporting only theThumb instruction set. The overall size and deterministic operation foran implementation are more important than the performance
The last profile is use for the implementation of the Arm Cortex M7processor. ARMv7 is built on the Thumb-2 ISA. It supports all of Thumb-2 instructions, with a floating-point extension, and Digital signal processor(DSP) extension. Thumb-2 added a mixture of 16 and 32 bits instructions.Thumb instructions are also denser than ARM ISA instructions, which leads toless memory being required for those instructions, and Thumb caching betterthan regular ARM ISA [16].
A summary of the characteristics of ARMv7 ISA is displayed below,more detailed information can be found in the ARMv7 Architecture referencemanual on the ARM website [17].
• 32-bit instructions
• 16 registers

State of the art | 19
• Can perform conditional branch instructions
• Compare and branch on zero instructions
• If -then instructions (conditionally executes one portion of code oranother but avoids the need for jumping)
• Data processing instructions (standard data processing instructions, shiftinstructions, multiply instructions, divide instructions, parallel additionand subtraction)
• Floating-point data processing instructions
• Load and store instructions
• Exception generating instructions
• Co-processor instructions
• Floating points load and store instructions
• Floating-point register transfer instructions (transfer data from ARMcore registers to floating point extension registers and the other wayaround)
• Floating-point data-processing instructions
Figure 2.6 shows some of the different 16-bit instruction encoding takenfrom the ARMv7-M architecture reference manual that can be accessed here[17].

20 | State of the art
Figure 2.6: A sample of some of the 16-bit Thumb instruction encoding [3]
Figure 2.8 shows some of the different 32-bit instruction encoding takenfrom the ARMv7-M architecture reference manual that can be accessed here[17], with more detailed information.

State of the art | 21
Figure 2.7: 32-bit Thumb instruction encoding with different encodingexamples [3]
2.5 Arm M processors familyArm M processors are high-performance processors for cost-sensitive andpower-constrained solutions [18]. They are suitable for a wide variety of

22 | State of the art
applications such as automotive, medical applications, internet of things [18].Power consumption is reduced thanks to the high-performance floating-pointunit. By combining the control and signal processing on the same unit, thechip system cost is reduced.
2.5.1 Arm Cortex M7 processorThe Arm Cortex M7 processor is a 32-bit processor with 6 stage pipeline fordiscrete processing and microcontrollers [4]. It is used in a wide range ofapplications such as automotive, industrial automation, medical devices, high-end audio, image and voice processing, sensor fusion and motor control [18].
Figure 2.8: An Arm cortex M7 implementation [4]
The cortexM7 is a highly efficient high-performance, embedded processorwith features such as low interrupt latency, low cost debug, in order superscalar pipeline, optional floating point unit and supports single and doubleprecision arithmetic and optional memory protecting unit [17]. Many of theinstructions can be dual-issued because of the multiple memory interfaces[17]. The supported memory interfaces are as followed:
• Tightly-coupled memory (TCM) interface
• Harvard instruction and data caches Advanced extensible interface(AXI) master interface

State of the art | 23
• Dedicated low-latency Advance high speed buss (AHB)-Lite peripheralAd hoc broadcast protocol (AHBP) interface.
Here below is a summary of the main features of the Cortex M7 processor,these are more detailed in the processor reference manual [4].
• An in-order issue, super-scalar pipeline with dynamic branch prediction
• DSP extension
• The ARMv7-M Thumb instruction set
• Banked Stack pointer (SP)
• Hardware integer divide instructions
• Handler and thread modes
• Thumb and debug states
• Automatic processor state saving and restoration for low-latency Interruptservice routine (ISR) entry and exit
• Support for ARMv7-Mbig-endian byte-invariant or little-endian accesses
• Support for ARMv7-M unaligned accesses
• Low-latency interrupt processing
• A low-cost debug solution
• Support for an optional Embedded trace macrocell (ETM)
• A memory system, which includes an optional Memory protecting unit(MPU) and Harvard data and instruction cache with ECC.
• An optional Floating point unit (FPU)
The processor has a set of optional and fixed component blocks as depicted infigure 2.9. The optional components are Wake-up interrupt controller (WIC),ITM, FPU, MPU, instruction cache and data cache controllers as well as theCross trigger interface (CTI), and ETM.

24 | State of the art
Figure 2.9: Components of the Cortex M7 processor from the Arm Cortex M7reference manual [4]
In figure 2.9, the memory system is in blue. As mentioned earlier, it isoptional. This system consists of the following taken from [4] :
• A Bus interface unit (BIU) with a configurable AMBA 4 AXI interfaceable to support a high-performance L2 memory system.
• An extendedAHB-Lite interface to support low-latency system peripherals
• ATightly-coupled interface unit (TCU)with TCM interfaces for supportof an external Error correction code (ECC) logic and an Advance highspeed buss slave (AHBS) interface for system access to TCM
• Instruction and data caches and controllers with optional ECC
• A Memory built in self test (MBIST) interface. The interface supportsMBIST operation while the processor is running
The Cortex M7 has also a lot of different interfaces. Table 2.1 summarizessome of the key interfaces as described in the Cortex M7 Arm user guide,where more details can be found [4].

State of the art | 25
Interface Short descriptionAd hoc broadcast protocol (AHBP)interface
The Advance high speed buss(AHB)-Lite peripheral interfaceprovides access suitable for lowlatency system peripherals, as wellas support for unaligned memoryaccesses, write buffer for bufferingof write data, and exclusive accesstransfers for multiprocessor systems
Advance high speed buss slave(AHBS) interface
The AHBS interface enablessystem access to Tightly-coupledmemory (TCM)
Advance high performance litedebug (AHBD) interface
The AHBD interface providesdebug access to the Cortex M7processor and the entire memorymap
External Private peripheral bus(PPB)
The Advanced peripheral bus(APB) External enables access toCoreSight-compatible debug andtrace components, in the systemconnected to the processor
Advance trace bus (ATB) interfaces The ATB interfaces output traceinformation used for debugging andit is compatible with the CoreSightarchitecture
TCM interface The processor can have up to twoTCM memory instances. One is forinstructions, Instructions TCM(ITCM). The second one is for thedata, Data DTCM. Each of themhave a double word data width
Cross trigger interface An optional cross trigger interfaceunit which includes an interfacesuitable for connection to externalCoreSight components using aCross Trigger Matrix is included inthe processor.
Memory built in self test (MBIST)interface
Tests the RAMs during productiontest. The RAM of the Cortex M7processor can also be tested usingthe MBIST interface during normalexecution. This is known as onlineMBIST
AXI master interface The AXI master interface enablesaccess to an external memorysystem
Table 2.1: Table of Arm cortex M7 different interfaces

26 | State of the art
2.6 Related work areaAs mentioned earlier in the background section (2), Risc-V is still a relativelynew technology that is being developed and tested in many different technicalareas. There has been some studies extending the Risc-V architecture in orderto add some new instructions [19], [20], [21].
There are not many studies as of the writing of this thesis, that have testedRisc-V in network processing applications except in Wang et al. study [5],where a fast network processor system was designed using a Risc-V processor.
2.6.1 RVNet packet processing systemRVNet is a fast and high energy efficiency packet processing framework basedon the open-source Risc-V processor Rocketchip [5]. RVNet uses numerousspecial advanced designed hardware as well as many optimization methods forimproved performance and lower power consumption. A summary of some ofthe optimizations is described below [5]:
• A direct path between caches and Ethernet devices is created for fasterprocessing and prioritizing network packets
• Use of Block random access memory (BRAM) instead of Double datarate (DDR)
• Preallocated buffers
• A ring structure instead of a circular queue system
• Data prefetching
• A fast driver

State of the art | 27
Figure 2.10: Hardware overview of the RVNet processing framework [5]
Even with all of these optimizations, RVNet did not perform as well asX86 processor based network processing frameworks for a packet size of 64bytes. More stable performance was observed for bigger packets, 256 bytes.
No hardware will be designed in this this thesis, no software optimizationwill be implemented, but the focus will be on building a test model forthe comparison of packet processing performance of open-source Risc-Vprocessor with an Arm Cortex M7. Nevertheless, results from RVNet, weretaken into consideration, when the hypothesis and philosophical assumptionswere made. The packet size in this thesis will be 72 bytes, which is a moderateincrease from 64 bytes.
2.7 EricssonEricsson is one of the leading providers of Information and communicationtechnology (ICT) to service providers [22] in the world today. They providenetworks, digital services, managed services, and emerging businesses; poweredby 5G and Internet of things (IOT) platforms.
When it comes to networks, the development, delivery, and managementof telecommunication networks through the provision of hardware, software,and services to enable connectivity are a big part of what the company doesto enable the digital transformation of next-generation mobile services.

28 | State of the art
The company was founded in 1876 by Lars Magnus Ericsson with thephilosophy that communication is a basic human need and has continued todevelop and deliver solutions, innovative technology to enable communicationaround the world [22]. Ericsson has a strong culture of collaborating withothers to develop open standards enabling global communications and connection.The company focuses heavily on research and development resulting in manypatents [23], while continuing to push forward to discover the next big thingwith technology in focus.
Ericsson is the project initiator and stakeholder of this thesis in collaborationwith the Royal Institute of Technology in Stockholm. This project is performedin the Asic research and development department with Shafqat Ullah as thesupervisor.

Method | 29
Chapter 3
Method
As described and argued for in the introduction, a quantitative approach isused in this project to answer the research question. This project was carriedout using a traditional project management approach. The goal of the projectwas clearly defined and was broken down into sub-goals. Thereafter, a workbreakdown was performed breaking down the project into smaller parts whileidentifying necessary steps to answer the research question.
As a result, it became clear what requirements needed to be met in thisproject to design a project model. After considering the goal and sub-goals,the next step was to translate them into requirements.

30 | Method
Requirement Description1 Implement the packet processing
functions (framing, parsing, packetmodification, pattern matching) in the Cprogramming language
2 Learn more on Risc-V architecture andopen-source Risc-V processors
3 Make a requirement list for the choice ofan open-source Risc-V processor in theproject
4 Find a way to port the packet processing Ccode to the chosen open-source Risc-Vprocessor
5 Find a way to port the packet processing Ccode to an Arm Cortex M7 processor
6 Measure the packet processing executiontime on both processors
7 Analyze and compare the execution timefrom both processors
8 If enough time is available, performsynthesis and power analysis
Table 3.1: List of requirements
3.1 Project modelFrom the work breakdown, a project model that is illustrated in figure 3.1 wasdesigned. This model was the basis from which the project was divided intodifferent phases, milestones, and tollgates during project planning.
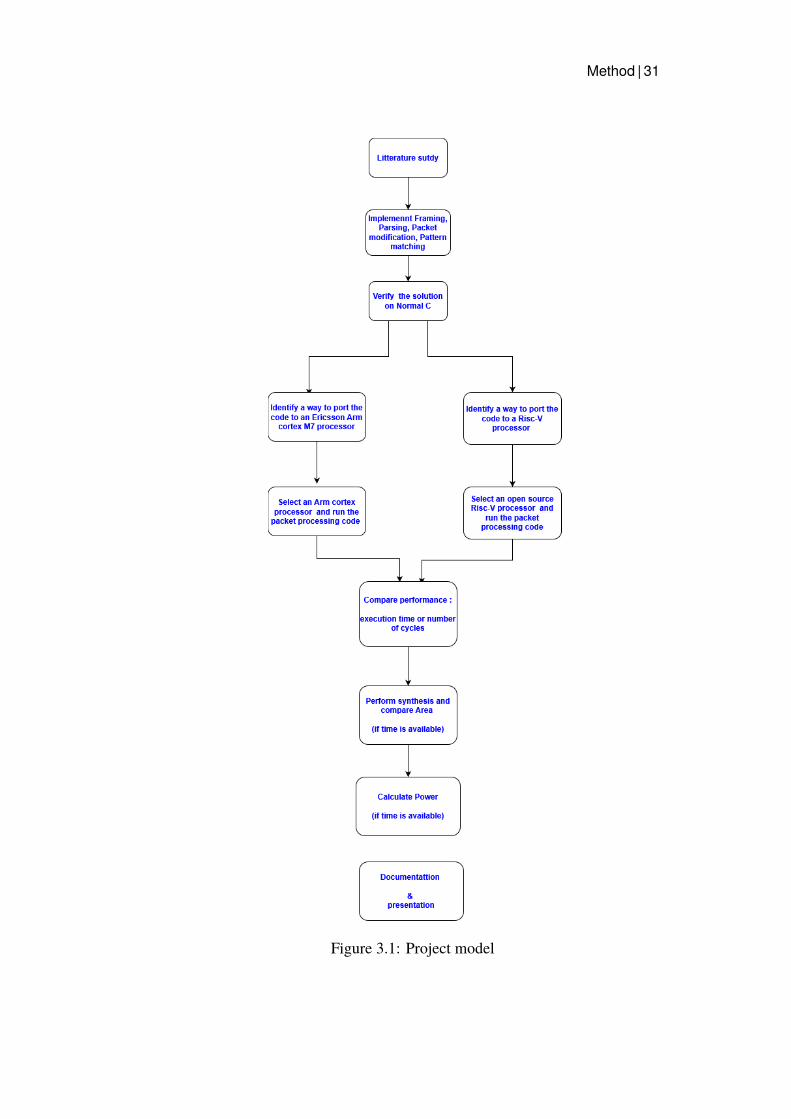
Method | 31
Figure 3.1: Project model

32 | Method
3.2 Project PhasesThe different phases of the project were:
• Literature study and state of the art
• Packet processing simulation code
• Risc-V phase
• Arm phase
• Performance evaluation
• Result documentation
• Result presentation
3.2.1 Literature study and state of the artDuring this phase, information about Risc-V technology, network processors,packet processing, and Arm Cortex M7 processors was gathered. TheInstitute of electrical and electronics engineers (IEEE) explorer database,ARM development website and documentation as well as finding books onthe mentioned topics were essential sources of information. This process wasalso essential to evaluate what is feasible for this project and discover what hasalready been done.
3.2.2 Packet processing simulation code in CAfter the literature study, a set of packet processing functions to be implementedwas chosen. The next challenge was to design a test that could simulate packetsentering a processor, the chosen packet processing functions being performedon the packet and the execution time of the packet processing being registered.In this thesis, 72 bytes Ethernet data packets will be simulated and processed.
The choice to write the code using the C programming language is basedon the fact that GNU compiler collection (GCC) C compilers for both ARMprocessors and Risc-V do exist nowadays and are properly working. Only onecode written in C programming language will therefore be necessary both forthe ARM and the Risc-V implementation. The C programming language is

Method | 33
also relatively easy to use and commonly used in embedded system design.
The first idea was to use two computers, one working as the sender of thepackets and the second one as the receiver that would process the packets.This idea would have required some more external hardware, that may addadditional latencies and other external factors affecting the results. Obtainingresults that are only depending on the processor’s performance as much aspossible and limiting the effects of external factors like extra hardware thatcould add latencies or affecting the results is a priority. This idea was thereforemodified into a second idea.
The second idea was to use two txt files with one file acting as a packetsender filled with lines of characters representing a 72 bytes packet each. Thesecond file will then be acting as a receiver, where the processed packetswill be written to after packet processing has been performed. The packetprocessing simulation software will read each line from the first file, save themin a temporary character list and treat them as a data packet. The characters inthe temporary list will be converted to their corresponding byte representationbefore the packet processing can begin. Before calling the packet processingfunctions, a specific start variable or address will be set to 1, marking thestart of the packet processing. When the packet processing is completed,another end variable or address will be set to 1, marking the end of thepacket processing. These markers will enable the measurement of the packetprocessing execution time when analyzing the signals on the SimVision tool.Finally, the processed packet will be written to a second txt file. A graphicalrepresentation of the second idea is illustrated below.
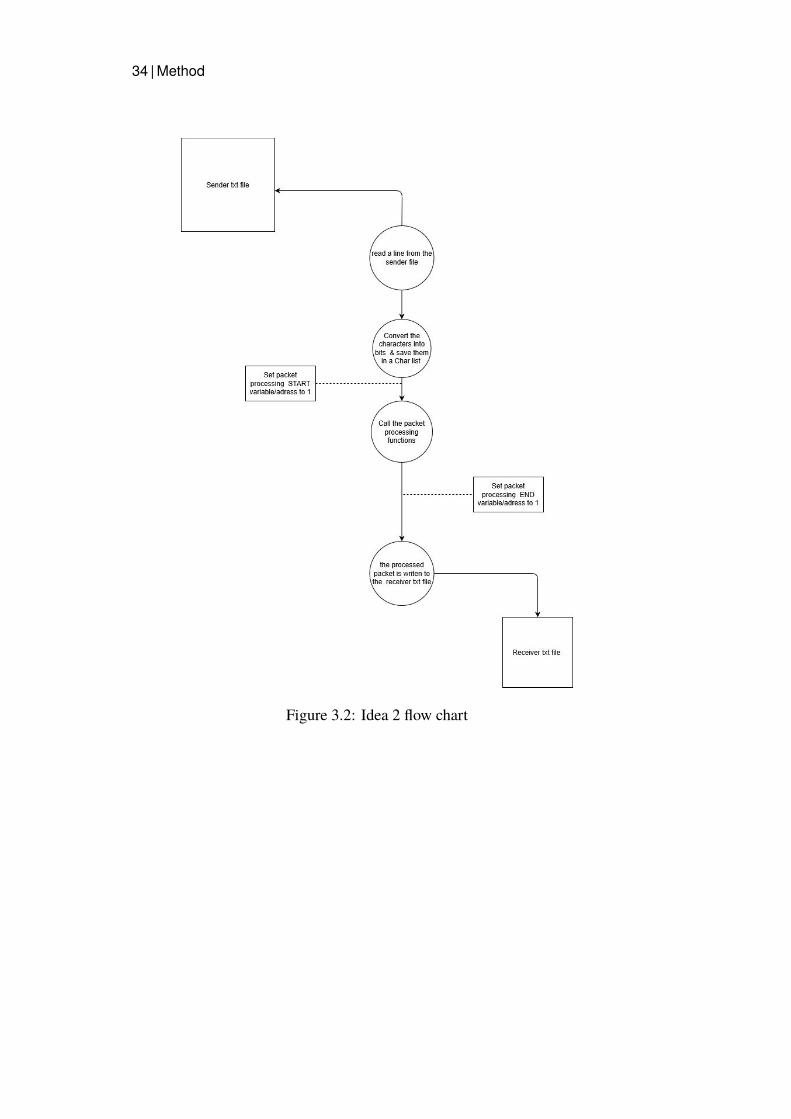
34 | Method
Figure 3.2: Idea 2 flow chart

Method | 35
The final idea was not to use the txt files for a sender or a receiver, butrather put the input packets as character lists at the beginning of the packetprocessing code. Every char list representing a packet is converted to their bitrepresentation before the packet processing begins. The same start and endvariables are used before and after the packet processing process. Figure 3.3shows a flow chart of the code. This method was chosen after discovering thatthe Risc-V processors and ARM processors in this project, could only acceptC bare-metal code and a limited set of external libraries. Some functionsrequired to access data from a txt files and print results on a terminal werenot available. By designing the code to work as a C bare-metal code, muchtime will be saved in using the processors without modifications. The txt filesonly served as storage locations and could easily be replaced by character listsin this project. The code version used for the Risc-V processor will be slightlydifferent but the same algorithms for the packet processing functions will beused. These differences are explained more in detail in the Risc-V phase andArm phase later.

36 | Method
Figure 3.3: Idea 3 flow chart

Method | 37
The input data
The data used for the packet processing will be randomly generated data bytesfor the software. This guarantees no violations of ethical standards as nopersonal information or any sensitive data from the companywill be used. Thisdata will consist of ethernet data packets to be processed. A set of 50 differentcharacter lists with 72 elements will be generated, simulating 50 different 72bytes packets. This method makes it easy to modify the content of the lists oradding more packets.
The packet processing functions to be implemented
Based on the literature study on packet processing, some key functions thatcould be implemented and tested on both processors were identified.
• Framing: ensuring that the data is correct using CRC
• Parsing: parse the incoming data packet and dividing it into differentfields to understand what type of packet it is and classify it
• Packet modification: modifying some of the packet’s data
• Pattern matching: search for a specific bit pattern in the packet
Framing can be the first task for received packets and the last task for outgoingpackets [1]. There aremany different ways to check the validity of data packets.One method is to use a CRC check algorithm which will be implemented inthis project. CRC is based on polynomial coding and modulo 2 division [1].CRC checking is a good test since this presents a lot of work for the processors.
Framing is performed both for received data packets and data packets thatare going to be sent. Because the input data in this project are randomlygenerated, the data will never be correct at the beginning of the program.Nevertheless, a framing algorithm can be called at the beginning to ensurethis task is performed.
From the sender side, a data packet to be sent is augmented with an r-1number of 0 bits. The r is the number of bits in the key. A modulo 2 divisionis then performed with the key. The remainder from the division is saved. Theremainder is appended at the end of the original data to form the encoded data

38 | Method
that will be sent. Figure 3.4 shows an example from the sender side.
Figure 3.4: CRC check example from the sender side
From the receiver side, the encoded data is received. A modulo 2 Xordivision is performed. If the final remainder is only zeros, the data received iscorrect otherwise an error occurred during transmission.

Method | 39
Figure 3.5: CRC check example from the receiver side
Using randomly generated packet input presents a different challenge sincethe CRC bit in the packets will not be generated from a key at the start. Thischallenge should not affect the execution time test to a great extent, since theCRCgeneration for Ethernet packets is generally handled by theMACcircuitryand in dedicated chips that are external to the network processors [1]. Byhaving a set 1 byte divider and designing an algorithm that divides the entirepacket with the divider, the same principles of the CRC algorithm are applied.The same steps that a CRC check would take in the processor are executed withvery little probability of the results being correctly transmitted data value.
Parsing is going to be implemented by splitting the packets in the preamblebytes (8 bytes), destination address bytes (6 bytes), source address bytes (6bytes), Ethernet type bytes (4 bytes), data payload bytes (46 bytes), and CRCframe check bytes(4 bytes). Each segment can be saved in different characterlists. This will be done using simple for loops.
Searching and classifying will be implemented by designing an algorithm

40 | Method
that goes through the Ethernet type bytes segments of the data packet andcompares them with a set of 3 different sets of bytes to classify the packets asbeing of type 1, 2, or 3. The different bytes are defined by these respectivebytes 0X0800, 0X0806, 0X86DD. This will be done using for loops and ifconditions in C.
The packetmodificationwill be implemented by an algorithm thatmodifiesthe content of the Ethernet type bytes to set it to a different type. The checkEthernet type algorithm will be called again after that.
Validity of the software
Because the software is written in bare metal code and with no access to printfunctions, a slightly modified version of the code containing printf calls withthe same algorithms will be compiled and run on a terminal. This will be doneto check if the packet processing function’s algorithms are behaving as theyshould during the software development before porting any code to either Armor Risc-V processors.
3.2.3 The Risc-V phaseThere are many different implementations of Risc-V processors today, mostof them are described on the Risc-V website [11]. Most of the processorshave commercial licenses but there are some with open source licenses. Arequirement list for selecting a processor for this project was determined.

Method | 41
Requirement Description1 Open source licensing2 Can execute C code or compiled C code3 System Verilog code for a build is
available and easily accessible4 Can be verilated
5 An emulator tool is available
6 The processor has been used or a variantof the processor has been used prior to thisstudy as a base for or in other solutions
Table 3.2: List of requirements for the Risc-V processor selection
The verilator requirement was set since building a processor using averilator enables a simple way to run the C packet processing code on anemulated Risc-V processor. Most of the open-source Risc-V processors canbe verilated using the verilators from the veripool website for verilator [24].
Based on the requirements, 3 potential candidates from theRisc-V foundationwebsite[2] were identified. After a processor is chosen, a read-through of thedocumentation of the processor is performed in to understand how to build it,emulate it and also identify the necessary tools and libraries.
Everything will be done using the Ubuntu 20.04 Lts operating system. Theprocess in general was executed as follow:
• Clone the Git-hub repository of the processor
• Build the required tools
• Set environmental variables and path to point to local files
• Verilate a model of the processor
• Build an emulator
• If there are available test benches for the processor, run them
• Compile a simple test C code to produce assembly files and Executableand linkable format (ELF) files using GCC compilers

42 | Method
• Run the C test executable file on the processor to check that correctexecution of a C written code can be performed
• Read through the output log to calculate the number of cycles to executethe program and write down the execution time.
• Compile the packet processing code and run the executable on theprocessor
• Read through the output log to calculate the number of cycles to executethe program and write down the execution time.
3.2.4 The Arm phaseArm processors are already in use at Ericsson in many different projects anddevices. In some projects, Arm Cortex M7 processors are used. Using theCitrix tool, different machines running physical processors can be accessedremotely.
The overall plan of action is to insert a slightly modified version of thepacket processing code inside another ready C code that has been executed onan Arm Cortex M7 processor. Recompile this code with the packet processingcalled in the initialization function of the bigger code. Thereafter, a test benchdesigned for the bigger codewill be executed on the processor that will producea wave file of signals. The signals of the wave file will be analyzed using theSimVision tools from Cadence. From the signal analysis the execution timeof the packet processing can be calculated.
The packet processing code will be modified slightly. All operatingsystem-related functions such as printf will be deleted. All of the differentpacket processing functions will be merged into one function. This functionwill take in a data packet (char list in this case) as an input. Every modifiedalgorithmwill be inserted one portion at a time and tested through compilation,to guarantee the compatibility of every modified portion. The entire packetprocessing code is too big to be inserted all at once. In case there are anyerrors, these will be hard to identify. This will serve as another way to checkif the modified code is working properly.
In order to measure the execution time, two integer values will be sentto two different addresses mapping to the AXI busses. These will be a start

Method | 43
and end points between packet processing function calls. The start will beset before the function call for the packet processing is performed. The endfunction will be set after the packet processing function call. Later on, whenthe waveform file is available, the execution time can be calculated by lookingat the respective AXI busses address signals of the sent integer. Figure 3.6shows an overview of how the implementation will take place.
The entire process will first be performed for one data packet, with onefunction call of the packet processing function. If this works properly andthe signals can be analyzed from the waveform file, the code will be editedto perform 10 function calls with 10 different random packets. This willlater be increased to 50 function calls with 50 different packets. These willbe performed 100 times each and an average of the execution time will becalculated and documented.
Figure 3.6: Arm implementation description graph

44 | Method
3.2.5 Performance evaluationRisc-V performance evaluation
During the study of open source Risc-V, a commonway to analyze performancetime was observed. Most of the processors recorded a trace of all executedinstructions and at what cycles the execution occurs in an output log orexecution log. These can be used to trace when the packet modificationsoftware instructions start and end. By multiplying the number of cycleswith the execution time of one cycle, a total execution time can be obtained.The same code will be run several times as well to ensure repeatability andreliability of the measurements. A minimum of 100 times is estimated to besufficient.
Arm performance evaluation
Since the packet processing software is inserted in the code of the deviceprocessor before the build, a set of timestamps for when the packet processingstarts and ends are necessary to measure the execution time. The Armexecution time will be measured using the AXI busses of the processor. Byactivating the AXI busses through a data transfer to one of the AXI peripheraladdresses before the start of the packet processing algorithm and at the end ofthe algorithm to a different address, the execution time can be measured.
When a test bench of the home code is executed, the packet processing willbe initiated and executed as well. With help of the SimVision tool, a waveformof all the signals that are executed and when they are active can be visualized.By observing the AXI time stamp signals on the diagram, the execution time ofthe packet processing will be obtained. By performing the packet processingon a varying number of packets (1, 5, 10, 50 packets) and repeating the test aminimum of 100 times, a good and reliable average of the execution time willbe obtained.
3.2.6 Result documentation and presentationDuring this phase, a well-written report documenting both the process andthe results of the project will be finalized and written using tools such asoverleaf. The report is also a very important document as it will be part of

Method | 45
the examination moments of the project participant’s Master of engineeringdegree. A final presentation of the project results will take place using zoom.An oral presentation will be given to present the project, communicate theresults and discuss it.

46 | Method

Implementation | 47
Chapter 4
Implementation
4.1 Packet processing codeThe input data of the packet processing code consisted of character lists of 72elements representing a 72 bytes packet. Each character element represents adata byte. Firstly every character from the data list was converted into their bitform with the help of two for loops. One loop iterated between each characterand the second took each bit from a converted character and saved it in a newlist. This was done by shifting a byte by (7- current bit step) steps and maskingit with 0X01. Figure 4.1 illustrates the flow chart.
Printf functions printing the results on the terminal with small iterationindex sizes were used first to check the correctness of the translated bits. Theiteration index was set to the final one after confirmation of expected behavior.

48 | Implementation
Figure 4.1: Bytes to bits conversion flow chart

Implementation | 49
4.1.1 FramingThe next stepwas to perform a framing algorithm. During the framing process,the correctness of a data packet can be verified either using a CRC checkor IP checksum [1]. Thus, an 8-bit CRC check algorithm was implementedto push the limits of the processor’s computing power. The following 8 bitskey: 10101011 was used for the modulo 2 division, which was implementedusing the Xor function. Assuming that the data packet was being received,the division would take place just as in the example described in 3.5. It isimportant to note that the preamble bits (header bits) were not included aspart of the inputs in the algorithm.
The algorithm is comprised of 3 steps. In the first step, the divider10101011was saved in an 8 elements character list. A char [8] list, representingthe 8-bit dividend is created. This list was filled with the first 8 bits afterthe packet header bytes from the converted packet. The header contained 8bytes, which explains the use of index 64 in the for loop. Another Char [8] listtemporary_list was created to save the rest of every 8-bit modulo 2 division.The first division was performed using a for loop. The execution flow is shownin figure 4.2.
In step 2, the dividend was updated for the second division. The rest wassaved in the temporary_list starting at index 1 up to index 7. These became thefirst 7 bits of the new 8-bit dividend. The last dividend bit was a new bit fromthe converted data packet. The index was 71 since the bits used in the firstdivision were between 64 and 71. Thereafter, a big for loop performed the restof the modulo 2 division. The loop size is 441 since 441 plus 71 is equal to512 bits and 72 bytes data packets without the 8-byte header also correspondto 512 bits.
For each division, it is important to check if the first dividend is 0 or 1 inorder to avoid the introduction and propagation of errors in the Xor function.If the first dividend was 0, every bit would be Xor with 0. At the end of the forloop, a new dividend was updated and the loop restarted. Figure 4.3 shows theexecution flow of the algorithm. When the loopwas done, step 3 was activated.

50 | Implementation
Figure 4.2: Framing algorithm step 1 flow chart

Implementation | 51
Figure 4.3: Framing algorithm step 2 flow chart

52 | Implementation
In the third step, the last rest value was checked to confirm that every bitwas zero. If this condition was true, the data received was correct. If evenjust one of the bits was not 0, the data had been corrupted. The last resultfrom the temporary_list contained the last rest. These values were moved tothe last dividend. Due to the use of character lists, a character resultcheck wasset to 0. Resultcheck was then used in every " if statement " where it wascompared to every rest bit. This was done for syntax purposes, to ensure thattwo-character values are compared. Figure 4.4 shows the flow of execution ofthe last framing step.
Printf functions printing the rest of every division as well as the last reston the terminal with small indexes were used to confirm the correctness ofthe algorithm execution. The iteration index was set to the final one afterconfirmation of expected behavior. For example, starting with a modulo 2division of 10 bits data packets instead of the big data packets directly.
The example described in the figure 3.5 was also tested with a smallerversion of this algorithm to ensure that it could detect correct packet transmissiontoo. When the framing process was done, it was time to parse the convertedpacket.

Implementation | 53
Figure 4.4: Framing algorithm step 3 flow chart

54 | Implementation
4.1.2 ParsingThe algorithm is very simple. From the converted data packet list of bits, usingfor loops and character lists, the different categories of the bits from the packetsuch as preamble, source address were identified and saved in specific charlists. Figure 4.5 shows how the preamble for loop executed parsing the otherfunctions using the same flow with different start indexes from the converteddata packet list.
Figure 4.5: Example of a parsing for loop flow chart, preamble for loop
4.1.3 Searching and classifyingA practical way of testing a searching function is to identify what type ofEthernet packet is sent. Using 3 different predefined data types markers0X0800, 0X0806, 0X86DD, the newly parsed Ethernet bytes bits were comparedwith all the 3 predefined types. The comparison was done with one type at thetime, starting with type 1.
The comparisonwas performed between every 4 bytes in nested if statements.If the first 4 bits of Ethernet_type were equal to the first 4 bits of one of thetypes then another if statement compared the next set of 4 bits. There were 4

Implementation | 55
sets of 4 bits to be compared. A variable Ethernet_packet_type was set to 0if none of the 3 types was identified, 1 if type 1 was identified, 2 when it wastype 2, and 3 if it was type 3.
Printf functions printing the results on the terminal were inserted duringdevelopment to print the final value of the ethernet_packet_type. Figure 4.6shows a flow of the algorithm searching for type 1 and 2. Type 3 will be foundsimilarly.
4.1.4 Packet modificationThe parsed ethernet packet bits weremodified to the type 3 bits by setting thosevalues to the same as the type 3. The searching and classifying algorithmswere used once again to confirm the modification. These algorithms are quitedemanding with the nested loops if statements to be checked for every type.This forced the processor to perform a lot of computation.

56 | Implementation
Figure 4.6: Searching and classifying flow

Implementation | 57
4.2 Risc-V implementationBased on the requirements, 3 potential candidates were identified. These werethe Rocket-chip processor, the SweRV core, and Arianne. The Simulation wasdone on a Linux operative system (Ubuntu 20.04).
Arianne was chosen as the first Risc-V processor. It is a single-issueinstruction, six stage processor with branch prediction, and an external TLB.While downloading the necessary tools and building the processor using theGithub instructions, many deficiencies and unexpected errors occurred. Mostinstructions did not behave as documented, the processor verilator was neverbuilt properly. This processor was deemed unfitting for this project since moredevelopment and better documentation are needed to fix issues that arose andimprove its reliability. At the time of the writing of this report, the Arianne github repository could not be found anymore.
The second choice was to use the SweRV core processor [25] which is aRegister transfer level (RTL) designed processor. This processor was used,when idea number 2 described in the methodology was tested, which includedusing a txt file as sender and receiver. First, a Risc-V GCC tool was clonedand installed in the operative system. Secondly, the entire Github file for theprocessor was cloned. A verilator was also installed to run simulations lateron. The setup process was not complicated, since there already exists setupscripts in the folders for configuration. But before building any configurationsof the processor, an important step is to set the path to point to the location ofthe processor. In the documentation, this was done by setting the RV_ROOTenvironment variable to the root of the SweRV directory structure. Anotherimportant thing to note is to be aware that some verilator versions are notcompatible with the configuration files, even the latest ones could be faulty.
Using the command RV_ROOT/configs/swerv.config -dccm_size=64, aprocessor with a Data closely coupled memory (DCCM) of size 64 kb couldbe built. Using the command make -f RV_ROOT/tools/Makefile, the defaultrecommended test codes were emulated and run successfully, with expectedresults on the console.log.
A simple user-written C test code, with less than 10 lines printing thestring " the example is good " using a printf call to the console was designed(see listing 4.1). This was used to test how the processor could simulate

58 | Implementation
user-written code. It was discovered while looking at the test code that theprocessor did not simulate C code directly rather took in assembly code files asarguments. Thus the GCC compiler was used to compile the simple test codeand an assembly code of this test was generated. Simulating this assemblycode on the processor did not work properly. It was observed that the processoras currently build could not execute a regular printf function and some otherfunctions from the standard C libraries.
After contacting some of the SweRV core developers, it was confirmed thatin order to use regular printf for example, a user needs to define their specialfunctions. In addition, the SweRV core can not run any standard I/O libraryfunctions and some standard C functions. A new boot code should be included,a new data hex file and program hex file need to be designed and somememoryconsiderations need to be taken into account. As the processor was currentlybuilt, there were many functions used in the packet processing software thatcould not be executed. Using a different processor was a more time-efficientalternative than allocating more time to writing new code segments, redefiningC functions, and modifying many of the current C code.
Listing 4.1: Test code in C
# inc lude < s t d i o . h># inc lude < s t r i n g . h># inc lude < s t d l i b . h>
i n t a = 3 ;i n t b= 4 ;i n t c ;
i n t main ( ) {
c = a+b ;
p r i n t f ( " t h e ␣ example ␣ i s ␣good␣ " ) ;
}

Implementation | 59
The final open-source Risc-V processor used was a Rocket-chip processorfrom the Rocketchip core generator. The Rocket core is a processor with 5stages in-order core with a page-based virtual memory, a non-blocking datacache, and a front-end with branch prediction [26]. The Rocketchip generatordescribed on the Rocketchip generator git hub website [27] was used.
Firstly, the Github file was cloned to the Ubuntu operative system. Sub-modules were updated. Necessary rocket tools were installed using therecommended instructions for ubuntu. AROCKETCHIP environment variablewas set to point to the installed Rocketchip directory using the export command.A RISCV environment variable was set up using the export command settingthe RISCV variable to point to the installed rocket tools directory. Both wereperformed in the bashrc file before sourcing it. The C emulator, which isstored inside the Rocketchip directory and was built from there, using thecommand make -jN run. N represents the number of cores, 4 cores were usedin this test. This command builds a cycle-accurate emulator, compiles theemulator, compiles all Risc-V assembly tests and benchmarks, runs both testsand benchmarks on the emulator.
The next step involved testing the given hello world code that is includedin the Github file using the default configuration, see listing 4.2. A small helloworld file was written and compiled using the Risc-V GCC compiler. With thecommand : ./emulator-freechips.rocketchip.system-freechips.rocketchip.system. DefaultConfig +verbose helloworld 2>&1 | spike-dasm > output.log,an output log file is created as the program executes.
Listing 4.2: Hello world C code from the Rocket-chip repository
# inc lude < s t d i o . h># inc lude < s t r i n g . h># inc lude < s t d l i b . h>
char t e x t [ ] = " Vafgehpgvba ␣ f r g f ␣ j n ag ␣gb␣ or ␣ s e r r ! " ;
/ / Don ’ t use t h e s t a c k , because sp i s n ’ t s e t up .

60 | Implementation
v o l a t i l e i n t wa i t = 1 ;
i n t main ( ){
whi le ( wa i t ) ;
/ / Doesn ’ t a c t u a l l y go on t h e s t a c k ,/ / because t h e r e are l o t s o f GPRs .
i n t i = 0 ;whi le ( t e x t [ i ] ) {
char l ower = t e x t [ i ] | 32 ;i f ( lower >= ’ a ’ && lower <= ’m’ )
t e x t [ i ] += 13 ;e l s e i f ( l ower > ’m’ && lower <= ’ z ’ )
t e x t [ i ] −= 13 ;i ++;
}
whi le ( ! wa i t ) ;}
In the output log, the instructions from every cycle, with their assemblycode as well can be recorded and traced, see Figure 4.7. When analyzing thehello world output log, the output lines looked similar to theGithub descriptionfound in the Rocket-chip documentation. The execution continued until thestack pointer was set to 0 and this line is repeated over and over, nothing morehappens. This might be a way to show the end of execution.
Figure 4.7: Hello world output log snippet
Before compiling and running the packet processing software code on thisemulator, a small test code " testar" was written and compiled to see how theemulator handled user-written code 4.3. This was a simple code adding two

Implementation | 61
integer values and saving the result in an integer variable. Testing smallercode first was the first step to gain a better understanding of how the rocketprocessor works. Unfortunately, when running the smaller code and lookingat the output log, the results did look a bit questionable. It seemed that the helloworld codewas executed even though the testar executable files are called usingthe instruction " ./emulator-freechips.rocketchip.system-freechips.rocketchip.system.DefaultConfig +verbose testar 2>&1 | spike-dasm > output.log " . Thiswas observed when comparing their execution log files. A test compiling andrunning the packet processing code for one packet was executed twice for thesame packet. Even in this case, the execution output log was intriguing.
Due to the unreliability, inconsistencies of the test code output logs, and alack of time, a decision was made to move on to the Arm implementation.
Listing 4.3: Testar test code
# inc lude < s t d i o . h># inc lude < s t r i n g . h># inc lude < s t d l i b . h>
i n t a = 0 ;i n t c= 5 ;i n t D= 2 ;i n t main ( ) {a = 5+2 ;
c= a+ c ;D= a+c ;
}
4.3 Arm implementationThe Arm implementation was carried out using one model of Ericsson’s ArmCortex M7 processors. The Citrix tool enabled remote access to Ericssonservers and machines. The plan was to include the packet processing codeas one function inside the C code of another bigger home code used in anArm Cortex M7 processor model, with an already built test bench. The packetprocessing code was slightly modified and converted into one function instead

62 | Implementation
of many different functions. This function will be called at the end of theinitialization sequences of the bigger home code.
All algorithms were tested before insertion into the bigger home code.All operating system function calls were deleted. As the packet processingsoftware code is big, all newly modified functions were copied inside theother C code one at a time first to detect syntax errors and misses. The firstcompilation tests were also performed only for one packet. The full codewas then compiled to produced executable files. After that, each functionwas compiled without errors, the entire new modified code was insertedand compiled successfully. A testbench from Ericsson for the bigger homecode was run, producing a waveform file of all signals. These signals in thewaveform files were analyzed using the SimVision tool from Cadence.
To measure the execution time, simple integer data were written to cor-responding AXI buss addresses before the packet processing is called andafter the call. For example MMIO32_WRITE (0x40000000,1) writes 1 to theperipheral address 0x40000000. This was used as a time stamping methodto have start and end markers between packet processing function calls. It isimportant to have a difference of 4 bytes between the addresses for timestampsto limit unaligned memory access penalties.
When everything worked perfectly for one packet, the function was calledfor 5 packets with 5 function calls of the packet processing. Later, the entireprocess was performed for 10 packets. In order to measure the executiontime for 50 packets, timestamps were inserted in between every 10th packetprocessing function calls. While looking at waveform signals, the clock,the axim_awadrress, and axim_wdata, and axim_awready are the necessarysignals to be analyzed to identify the execution time. Figure 4.8 shows anexample of analysis.

Implementation | 63
Figure 4.8: SimVision waveform analysis example for 50 packets
Lastly, the process was performed for 50 different packets 100 times.The execution times were documented and analyzed using Excel to note theexecution time of the packet processing code on the Arm processor.

64 | Implementation

Results | 65
Chapter 5
Results
In this chapter, the results of the thesis are presented. Early in the project, anumber of goals (see1.5) and sub-goals (see 1.1) were set. Somewere achievedand are presented here. The test data packet used when producing these resultscomprised these characters 111110011010001010101111111111111111111111111111111111111111111111111001. These characters were convertedinto their equivalent data bits before running any packet processing on them.The other 49 data packets are included in the appendix containing the full code.
5.1 Packet processing codeA well-functioning packet processing code was produced. The code can beseen in appendix D as it is too big to be included in this chapter. Whencompiling the code and testing the base version of the code executed with onedata packet, printf statements were added to print the test result on a Linuxterminal. Figures 5.1 to 5.4 shows the terminal results.
First, a smaller version of the framing algorithm was tested using the CRCreceiver example from figure 3.5. In figure 5.1, the last rest is 0000 and theisdatacorrupted variable is 0.

66 | Results
Figure 5.1: CRC check example test result
The expected framing result of the randomly generated packet looks likeit is corrupted since these were not encoded using the same key as a divider.Figure 5.2 shows the framing results confirming the corruption.
Figure 5.2: Framing algorithm result
By comparing the equivalent bits of every byte of an Ethernet data packet,the parsing function managed to parse the packet correctly. Figure 5.3 showsan example of the preamble bits of the packet.

Results | 67
Figure 5.3: Preamble parsing result
The search and classification managed to identify and correctly classifywhat type of Ethernet packet before and after modification.
Figure 5.4: Search and classification result
5.2 Risc-V implementationIn the Risc-V implementation section 4.2, the 3 different Risc-V processorsused in the project are mentioned. The Rocket-chip processor was the lastone to be used. When running the recommended helloworld test code fromthe Github documentation (see listing 4.2), the output log was analyzed andcompared to the output log of a simple user-written code called testar (seelisting 4.3).
Figure 5.5 shows a sample of the first lines from the output log for helloworld. More samples can be found in the appendix A.
Figure 5.6 shows a sample of the first lines from the output log of the testarcode. More samples can be found in the appendix B.
By comparing the hello world and testar output logs the same instructionsare, for the most part, executed on both output log files, which is unexpectedas the C codes are different.
Furthermore, one 72 bytes packet was processed and the same compiledcode was executed twice on the emulator. This produced different result outputlogs, when their contents are compared, see figure 5.7 and 5.8.

68 | Results
Figure 5.5: Hello world output log, lines 19 -195
Figure 5.6: Testar output log, first 200 cycles

Results | 69
Figure 5.7: Same packet processed execution side to side comparison outputlog snippet
Figure 5.8: Same packet processed execution side to side comparison outputlog snippet

70 | Results
5.3 Arm test resultsIn table 5.1, the result of the average execution time for 1 packet, 10 packets,20 packets, and 50 packets that were executed 100 times are presented. Allpackets have the same size of 72 bytes.
Nr of data packets average execution time1 data packet 3,75 ns5 data packets 3,75 ns10 data packet 13,75 ns50 data packet 67,5 ns
Table 5.1: Execution time on Arm cortex M7 for 1, 5, 10 and 50 data packets

Discussion | 71
Chapter 6
Discussion
6.1 Packet processing codeThe packet processing code has been built with the flexibility to simulatebigger packet sizes that could be used for future work if needed. It handlesand tests some of the most used key functions of packet processing correctlyas the results show.
In the C programming language, the smallest variable that a user canhandle and use in lists are characters. Every character represents an 8-bitvalue, this created some challenges in how to access every bit. In the code,each character of a packet is translated into their bit equivalent and then eachbit is once again saved as a character. This may make the packet bigger insize when every bit is represented by a character, but this should not haveany major impact on how the algorithms of the different functions perform.This aspect is valuable from a workload perspective because it pushes theprocessors to perform more work but negatively affects execution time due toa bigger workload and memory storage challenges. Nevertheless, the samecode and algorithms using characters and character lists are used in bothprocessors. This should push both processors to use the same workloadand give a reasonable evaluation of the different execution times to enablecomparison.
The codewas not designedwith optimization inmind, but rather functionality.It is likely probable that some of the codes can be optimised and more packetprocessing functions can be added.

72 | Discussion
6.2 Risc-V implementationWorkingwith open-source developed product can be very challenging, especiallywhen there aremany contributors to the development of the products. This wasexperienced while working with open-source developed Risc-V processors.Most contributors put a lot of effort into the practical issues related tobuilding the product and solving such issues, but they overlook updating thedocumentation and user instructions for outside users of their products.
Three different Risc-V processors were evaluated in this project. Many ofthe challenges of the Risc-V implementation were due to the documentationlacking some key information or some extra tools that need to be developed.The current documentation and building instructions do not always behave asexpected when building and using the processors. External users may need toperform some additional, research and work in order to use them. Dependingon the type of tools being used and the type of implementation, more orless additional extra work will need to be performed. The extra work cancomprise rewriting some standard c library functions that are not supported bythe compiler. Design a new boot code function in assembler to runC programs,reviewing how the linker file works (if there is a working linker file), reviewmemory, and data accesses are examples of extra work that may be needed.
The processor files are numerous and large. Thus exploring them togain a better understanding of how they work properly is a tedious and time-consuming task compared to using a processor developed by a company. TheRisc-V technology is very promising but open source Risc-V processors arenot fully reliable and ready to be used yet and may therefore demand morework.
The processors evaluated in this project managed to execute the test codesincluded in their development files. The problem lies in running externaluser programs as shown in the main results of the Rocket-chip processor witha simple test processor. Based on the output log of the testar code, it isnoticeable that the processor could not execute a user program but insteadexecuted some other code. This is most likely due to some errors in theemulator build/ configuration. Another example reinforcing the unreliabilityof the included rocket emulator is illustrated in figures 5.8 and C.1, where thesame packet processing is executed but it produced different output logs. Boththe instructions and addresses written and read on the output logs are different

Discussion | 73
when the same compiled code is executed.
It is possible to build a system using a Rocket-chip processor, as shown inimplementation but one may need to review the current emulator and modifyit. Another alternative is to develop a new Risc-V emulator for the Rocket-chipprocessor in order to test it.
6.3 Arm implementationThe method used for the Arm implementation worked relatively easily. Thisis mostly because there is already a set of well-functioning and reliable Armtools at Ericsson. These tools have already been used in previous projects thatconfirmed their reliability.
However, the execution time results are interesting. The execution timeis the same regardless of whether if it’s one packet or many packets. Alinear relationship between the number of packets and execution time canbe expected but this is not the case. It is even more apparent when lookingat the execution time of every ten packets of the 50. Every 10 blocks differin execution time, this is most likely due to unaligned memory load penalty.The packet processing code uses a character list to represent 72-byte packetsand new character lists are used to save and manipulate data. The inability tocontrol how the memory stores handled this can have resulted in some penaltycycles.
6.4 Advantages and disadvantages summary
Using open-source Risc-V processors requires initial engineering work tounderstand the tools and establish a workflow. Depending on the type ofapplication, someRisc-V toolsmay not be fully developed yet. Howmuch timeand resources are needed for this process is hard to determine. Once there is aworking tool flow, a company can use them without any issues. Open-sourceprocessors also provides the flexibility of customization for the application-specific purpose while establishing a working flow. If time constraints are nota hard priority, the initial engineering work will pay off later on.

74 | Discussion
Using an already developed processor like the Arm Cortex M7, may notprovide as many customization options, but one can trust the reliability of theprocessor and its already developed tools and documentation. The setup timebefore using the processors will be shorter than an open-source Risc-V optionbut the processor is built with some limitations. Although the Arm Cortex M7processor is a very flexible and processor that can be used in many differentareas.

Conclusions and Future work | 75
Chapter 7
Conclusions and Future work
In this section, the conclusions from the project are discussed, as well as thelimitations for it’s execution and suggestion for future work .
7.1 ConclusionsThe purpose of this project was to design a test model that could simulateand evaluate how well an open-source Risc-V processor performs packetprocessing compared to an Arm M7 processor. This has been achieved ina way. Even if all sub-goals of the project could not be achieved, the mostimportant ones were and a good ground for future exploration of this topicis set. For example, finding an adequate and reliable open-source Risc-Vprocessor and collecting correct execution performancewas not fully achieved.
However, a test model to analyze packet processing performances ondifferent types of processors was successfully designed. The C test code worksproperly and can be expanded and used for bigger packet sizes or with newadditional functions. The Risc-V architecture technology is very promisingfor the future but open-source Risc-V processors and tools are not sufficientlydeveloped in comparison to Arm processors. There is still room for someimprovement to be done of Risc-V open-source processors before they can bereliably used in bigger applications or industry scenarios as of the writing ofthis report.

76 | Conclusions and Future work
7.2 LimitationsThe underestimation of how challenging some aspects of the project wouldbe based on previous experiences limited the effectiveness of the work. Forexample, the Risc-V open-source processors were more challenging to workwith than expected. Usually, when accessing new tools with documentation,one relies on the provided instructions to work rather smoothly and trusts theinstructions of the documentation to be sufficient. In addition, it was difficultto get in contact with developers, when some issues arose. Sometimes ittook up to 3 weeks to get answers to questions asked on the recommendedcommunication forums.
7.3 Future workDue to the challenges encountered during the project execution, only some ofthe initial goals have been achieved. In this section, we will focus on some ofthe remaining issues that should be addressed in future work.
To begin with, there is more to be explored when it comes to open sourceRisc-V processors. A suggestion for future work would be to investigate theSweRV core processor, which seems to be promising and may not require asmuch additional work as developing a new emulator.
It can also be of interest to explore mapping a Rocket core down to an ,FPGA, or pushing a Rocket core throughVLSI tools. The two later alternativesare described on the Rocket-chip core Github page. It is possible that workingwith Risc-V physical hardware rather than emulator simulation may be easier.The packet processing simulation codeworkswell and the current Risc-VGCCcompilers are fully functional.
When this is done, the rest of the other sub-goals set at the beginning ofthe project can be achieved. These included collecting reliable performancedata, producing a latency and area report, as well as a power estimation of anopen-source Risc-V processor.

REFERENCES | 77
References
[1] R. Giladi, Network processors: architecture, programming, andimplementation. Morgan Kaufmann, 2008.
[2] “Risc-V foundation home page,” https://live-risc-v.pantheonsite.io/,[Accessed : 2020-07-15].
[3] A. S.Waterman, “Design of the risc-v instruction set architecture,” Ph.D.dissertation, UC Berkeley, 2016.
[4] “Cortex M7 Arm user Guide,” https://developer.arm.com/documentation/dui0646/b/introduction/about-the-cortex-m7-processor-and-core-peripherals?lang=en,[Accessed : 2020-11-17].
[5] Y. Wang, M. Wen, C. Zhang, and J. Lin, “Rvnet: A fast and highenergy efficiency network packet processing system on risc-v,” in 2017IEEE 28th International Conference on Application-specific Systems,Architectures and Processors (ASAP), 2017, pp. 107–110.
[6] N. Shah, “Understanding network processors,” Master’s thesis,University of California, Berkeley, 2001.
[7] C. Demerjian, “A long look at how arm licenses chips: Part 1of 2,” semiaccurate. com/2013/08/07/a-long-lookat-how-arm-licenses-chips, 2013.
[8] D. Bhandarkar, “Risc versus cisc: a tale of two chips,” ACM SIGARCHComputer Architecture News, vol. 25, no. 1, pp. 1–12, 1997.
[9] E. Blem, J. Menon, T. Vijayaraghavan, and K. Sankaralingam, “Isa wars:Understanding the relevance of isa being risc or cisc to performance,power, and energy on modern architectures,” ACM Trans. Comput. Syst.,

78 | REFERENCES
vol. 33, no. 1, Mar. 2015. doi: 10.1145/2699682. [Online]. Available:https://doi-org.focus.lib.kth.se/10.1145/2699682
[10] K. Asanović and D. A. Patterson, “Instruction sets should be free: Thecase for risc-v,” EECS Department, University of California, Berkeley,Tech. Rep. UCB/EECS-2014-146, 2014.
[11] “List of Risc-V processors and SOC,” https://riscv.org/exchange/cores-socs/, [Accessed : 2020-08-18].
[12] G. Blanchet and B. Dupouy, Computer architecture. Wiley OnlineLibrary, 2013.
[13] D. A. Patterson and J. L. Hennessy, Computer Organization andDesign RISC-V Edition: The Hardware Software Interface (The MorganKaufmann, the hardware software interface (the morgan kaufmann ed.Morgan Kaufmann, 2018. ISBN 978-0-12-812275-4
[14] J. Catsoulis, Designing Embedded Hardware: Create New Computersand Devices. " O’Reilly Media, Inc.", 2005.
[15] J. Ledin, Modern Computer Architecture and Organization, 1st ed.Packt Publishing, 2020. ISBN 9781838984397
[16] J. A. Langbridge, Professional Embedded ARM Development. JohnWiley & Sons, 2013.
[17] “ARMv7-M Architecture Reference Manual,” https://developer.arm.com/documentation/ddi0403/ed, [Accessed : 2020-11-12].
[18] “Cortex M7 description from Arm,” https://developer.arm.com/ip-products/processors/cortex-m/cortex-m7, [Accessed : 2020-11-17].
[19] S. Payvar, E. Pekkarinen, R. Stahl, D. Mueller-Gritschneder, andT. D. Hämäläinen, “Instruction extension of a risc-v processor modeledwith ip-xact,” in 2019 IEEE Nordic Circuits and Systems Conference(NORCAS): NORCHIP and International Symposium of System-on-Chip(SoC), 2019. doi: 10.1109/NORCHIP.2019.8906975 pp. 1–5.
[20] V. Jain, A. Sharma, and E. A. Bezerra, “Implementation andextension of bit manipulation instruction on risc-v architectureusing fpga,” in 2020 IEEE 9th International Conference onCommunication Systems and Network Technologies (CSNT), 2020.doi: 10.1109/CSNT48778.2020.9115759 pp. 167–172.

REFERENCES | 79
[21] B. Koppelmann, P. Adelt, W. Mueller, and C. Scheytt, “Risc-vextensions for bit manipulation instructions,” in 2019 29th InternationalSymposium on Power and Timing Modeling, Optimization andSimulation (PATMOS), 2019. doi: 10.1109/PATMOS.2019.8862170 pp.41–48.
[22] “Ericsson Patent,” https://wcm-com.ericsson.net/en/about-us,[Accessed : 2020-11-06].
[23] “Ericsson Patent,” https://wcm-com.ericsson.net/en/patents, [Accessed :2020-11-06].
[24] “Veripool website for verilator,” https://www.veripool.org/wiki/verilator, [Accessed : 2020-07-15].
[25] “SweRV core Github repository,” https://github.com/chipsalliance/Cores-SweRV, [Accessed : 2020-08-18].
[26] K. Asanović, R. Avizienis, J. Bachrach, S. Beamer, D. Biancolin,C. Celio, H. Cook, D. Dabbelt, J. Hauser, A. Izraelevitz, S. Karandikar,B. Keller, D. Kim, J. Koenig, Y. Lee, E. Love, M. Maas, A. Magyar,H. Mao, M. Moreto, A. Ou, D. A. Patterson, B. Richards, C. Schmidt,S. Twigg, H. Vo, and A. Waterman, “The rocket chip generator,”EECS Department, University of California, Berkeley, Tech. Rep.UCB/EECS-2016-17, Apr 2016. [Online]. Available: http://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-17.html
[27] “Rocket chip generator git hub website,” https://github.com/chipsalliance/rocket-chip, [Accessed : 2020-11-17].

80 | REFERENCES

Appendix A: Additional Hello world output log | 81
Appendix A
Additional Helloworld output log
Figure A.1: Hello world output log, lines 196-325

82 | Appendix A: Additional Hello world output log
Figure A.2: Hello world output log, lines 341-514

Appendix B: Additional testar output log | 83
Appendix B
Additional testar output log
Figure B.1: Testar output log, cycles 200 to 320

84 | Appendix B: Additional testar output log
Figure B.2: Testar output log, cycles 332 to 500
Figure B.3: Testar output log, cycles from lines 30 000
Appendix B: Additional testar output log | 85
Figure B.4: Testar output log, last cycles

86 | Appendix C: Additional Side by side comparison output log
Appendix C
Additional Side by side comparisonoutput log
Figure C.1: Same packet processed execution side to side comparisonoutputlog snippet

Appendix D: Packet processing code | 87
Appendix D
Packet processing code
1
2
3
4
5 # include <stdio .h>6 # include < string .h>7 # include < stdlib .h>8
9
10 /// Global variable declaration ////////11
12 char stringofbits [8];13 char ptr [8];14 char secondptr [8];15 char divider [8];16 char divident [8];17 int isdatacorrupted ;18 int ethernet_packet_type ;19
20 char preamble [64];21 char macdest [48];22 char macsource [48];23 char ethernetbytes [16];24 char ethernettype [16] ;25 char payload [368];26 char CRC_framecheck [32];27 char macdest_inframe [48];28 char divider [8];29 char divident [8];30 char crc_frame_bitlist [576]; // 72 * 831 char dataframelist [72] ;

88 | Appendix D: Packet processing code
32
33 char check_0 = 0;34 char check_1 = 1;35
36
37
38
39
40
41
42 // list of 50 packets43
44 char dataframelist1 [72]={1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,
45 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
46 0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};47
48
49 char dataframelist2 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,
50 1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,
51 1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};52
53
54 char dataframelist3 [72]={1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
55 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
56 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};57
58
59 char dataframelist4 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
60 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,
61 1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};62
63 char dataframelist5 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
64 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,

Appendix D: Packet processing code | 89
65 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};66
67 char dataframelist6 [72]={1 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
68 1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,
69 1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1};70
71 char dataframelist7 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,
72 1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
73 0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1};74
75 char dataframelist8 [72]={1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,
76 1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
77 1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1};78
79
80 char dataframelist9 [72]={1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,
81 1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,
82 1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0};83
84 char dataframelist10 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
85 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
86 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1};87
88
89 char dataframelist11 [72]={1 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,
90 0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,
91 1 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1};92

90 | Appendix D: Packet processing code
93
94 char dataframelist12 [72]={1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,
95 0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,
96 0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1};97
98 char dataframelist13 [72]={1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,
99 0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,
100 1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1};101
102
103 char dataframelist14 [72]={1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,0 ,
104 1 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,
105 0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,1 ,0};106
107 char dataframelist15 [72]={0 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,
108 1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,
109 1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1};110
111 char dataframelist16 [72]={1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,
112 0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,
113 0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1};114
115 char dataframelist17 [72]={0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
116 0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
117 1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};118
119
120 char dataframelist18 [72]={1 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,

Appendix D: Packet processing code | 91
121 0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,
122 1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1};123
124 char dataframelist19 [72]={0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,
125 1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,
126 1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1};127
128 char dataframelist20 [72]={0 ,1 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
129 1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,
130 1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1};131
132 char dataframelist21 [72]={1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,
133 0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,
134 1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1};135
136 char dataframelist22 [72]={1 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,
137 0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,
138 0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1};139
140
141 char dataframelist23 [72]={1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,
142 0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,
143 1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1};144
145
146 char dataframelist24 [72]={1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,
147 0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,

92 | Appendix D: Packet processing code
148 1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1};149
150
151
152 char dataframelist25 [72]={1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
153 1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,
154 1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1};155
156
157 char dataframelist26 [72]={1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,
158 0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,
159 1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0};160
161
162 char dataframelist27 [72]={1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,
163 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
164 0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,1};165
166
167 char dataframelist28 [72]={1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,
168 0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,
169 1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,0 ,1};170
171
172 char dataframelist29 [72]={1 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
173 0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,
174 1 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0};175
176
177
178 char dataframelist30 [72]={1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,

Appendix D: Packet processing code | 93
179 0 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
180 0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1};181
182
183 char dataframelist31 [72]={1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,1 ,
184 0 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,
185 0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,1};186
187
188
189 char dataframelist32 [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,0 ,0 ,0 ,0 ,
190 1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,
191 1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1};192
193
194 char dataframelist33 [72]={1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,
195 0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,
196 1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,0 ,1 ,0 ,0 ,1};197
198
199 char dataframelist34 [72]={1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,
200 1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,
201 0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1};202
203
204 char dataframelist35 [72]={1 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,
205 1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,
206 0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1};207
208

94 | Appendix D: Packet processing code
209 char dataframelist36 [72]={1 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,
210 1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
211 0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1};212
213
214
215 char dataframelist37 [72]={0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,
216 0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,
217 0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};218
219
220 char dataframelist38 [72]={1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,
221 0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,
222 1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1};223
224
225
226 char dataframelist39 [72]={1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,
227 0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,
228 0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0};229
230
231 char dataframelist40 [72]={1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,
232 1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,
233 1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1};234
235
236
237 char dataframelist41 [72]={1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,
238 0 ,1 ,0 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,

Appendix D: Packet processing code | 95
239 0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1};240
241 char dataframelist42 [72]={1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,
242 0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
243 1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1};244
245
246 char dataframelist43 [72]={1 ,1 ,1 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,
247 1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,
248 0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1};249
250
251 char dataframelist44 [72]={1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,
252 1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,
253 0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,1 ,0};254
255
256 char dataframelist45 [72]={1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
257 1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,
258 0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1};259
260
261 char dataframelist46 [72]={1 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,
262 1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,
263 1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1};264
265
266 char dataframelist47 [72]={0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,
267 0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,

96 | Appendix D: Packet processing code
268 1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1};269
270
271 char dataframelist48 [72]={1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,
272 0 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,
273 0 ,1 ,1 ,0 ,1 ,1 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0 ,1 ,1 ,1};274
275
276 char dataframelist49 [72]={1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,
277 0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,
278 1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,1 ,0};279
280
281 char dataframelist50 [72]={1 ,1 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,
282 1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,0 ,1 ,1 ,0 ,283 1 ,1 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,1 ,0 ,0 ,1 ,0 ,1 ,0 ,1};284
285
286
287 char dataframelist [72]={1 ,1 ,1 ,1 ,1 ,0 ,0 ,1 ,1 ,0 ,1 ,0 ,0 ,0 ,1 ,0 ,1 ,0 ,1 ,0 ,1 ,1 ,1 ,1 ,1 ,
288 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,289 1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,1 ,0 ,0 ,1};290
291
292 void main () {293
294 packet_processing ( dataframelist );295
296
297 }298
299
300
301 void packet_processing ( char packet []) {302
303
304
305 // the codes is design for a packet of size 72

Appendix D: Packet processing code | 97
bytes and can be extended in a way for biggerpackets
306
307
308
309 // this loop takes the first 72 characters fromthe file which represents the 72 bytes of the
frame310 // calculate the bits of every bytes and saves them
in a char list in order for the CRC decoder todecode them
311
312
313
314 for ( int i = 0; i < 72; ++ i)315 {316
317 int current_byte = i * 8 ; //current char byte to be transformed to bits
318 int current_bit ; //variable to use for saving the curent bit tothe frame list .
319
320
321 for ( current_bit = 0; 8 > current_bit ;current_bit ++)
322 {323
324 stringofbits [ current_bit ]= ((dataframelist [i] >> (7 - current_bit ) ) & 0 x01);
325
326 crc_frame_bitlist [ current_byte +current_bit ] = stringofbits [ current_bit ] ;/// list of all bits in the frame
327
328
329 }330
331 }332
333 // printf (" \n" );334 // printf (" The entire data packet in bits =
--- " );335
336 // for ( int d = 0; d < 576; d ++)// Print the entire datapacket in

98 | Appendix D: Packet processing code
bits337 // {338 // printf (" %d",
crc_frame_bitlist [d] );339 // }340 // printf (" ---");341 // printf (" \n" );342
343
344
345
346
347
348 // ///////////// Framing test function ///////////349
350 // this function checks the validity of the datausing some type of CRC algortihm
351
352
353 /// Temporary test code to check that thealgortihms works properly
354 // based on the example in the thesis :355
356 /*357 char divider_test [4];358 char divident_test [9];359
360
361 divident_test [0]=1;362 divident_test [1]=0;363 divident_test [2]=0;364 divident_test [3]=1;365 divident_test [4]=0;366 divident_test [5]=0;367 divident_test [6]=0;368 divident_test [7]=0;369 divident_test [8]=1;370 divident_test [9]=0;371 int l = 1 ;372
373 for ( int i = 0; i < 8; ++i) {374
375 divident [i]= divident_test [i];376
377 }378
379 // set a 4 divider = 1101 ;

Appendix D: Packet processing code | 99
380 divider_test [0] = 1;381 divider_test [1] = 1;382 divider_test [2] = 0;383 divider_test [3] = 1;384
385
386 char temporary_list_test [4];387 printf (" --------------- ");388 printf (" \n" );389 printf (" the example first modulo 2 divison rest =
");390
391
392 for ( int j = 0; j < 4; ++j) {393
394 temporary_list_test [j] = (divident_test [j] ^ divider_test [j]) ;
395
396 }397
398 divident_test [0] = temporary_list_test [1] ;399 divident_test [1] = temporary_list_test [2] ;400 divident_test [2] = temporary_list_test [3] ;401 divident_test [3] = divident_test [4] ;402
403
404 for ( int d = 0; d < 3; d ++) //print the first 3 divisions rest with the next
bit append to the right405 {406 printf (" %d", divident_test
[d] );407 }408 printf (" \n" );409
410 int max_numbertoappend = 6 ;411
412 for ( l; l <= 5 ; l++ ) {413 int ba= l+1 ;414 printf (" \n" );415 printf (" \n" );416 printf (" the rest of the modulo 2
divison nr %i =" , (ba));417
418
419 if ( divident_test [0] == 0 ){ // if thenext divident byte starts with 0, XOR with

100 | Appendix D: Packet processing code
zeros420
421 for ( int i = 0; i < 4; ++i)422 {423 temporary_list_test [i] = (
divident_test [i] ^ 0) ;424 }425
426
427 }428
429
430 else if ( divident_test [0] == 1 ){431
432 for ( int i = 0; i < 4; ++i) //if the next divident byte starts with 1 go inhere
433 {434 temporary_list_test [i] = (
divident_test [i] ^ divider_test [i] ) ;435 }436 }437
438 divident_test [0] = temporary_list_test [1] ;439 divident_test [1] = temporary_list_test [2] ;440 divident_test [2] = temporary_list_test [3] ;441 divident_test [3] = divident_test [4+ l]; //442
443
444 for ( int d = 0; d < 3; d ++) // ska vara 8i s t l l e t f r 4
445 {446 printf (" %d", divident_test [d] );447 }448
449 printf (" \n" );450 printf (" --------------- ");451 printf (" \n" );452 }453
454 /// check if the last divident is 0000 to confirmcorruption of data
455 printf (" \n" );456 printf (" --------------- ");457 printf (" \n" );458 printf (" the last rest is = ");459 // printf (" %d", divident [i] );

Appendix D: Packet processing code | 101
460
461 for ( int i = 0; i < 4; ++i) // Print the last 4bit divider
462 {463 divident_test [i] = temporary_list_test [i]
;464
465 printf (" %d", divident_test [i] );466
467 }468 printf (" \n" );469 printf (" --------------- ");470 printf (" \n" );471
472
473
474 /*475 divident_test [0] = 0;476 divident_test [1] = 1;477 divident_test [2] = 0;478 divident_test [3] = 1;479 */480
481 /*482 char resultchek [1];483 resultchek [0] = 0;484
485
486
487 if ( divident_test [0] == resultchek [0] ) {488
489 if ( divident_test [1] == resultchek [0] ) {490
491 if ( divident_test [2] ==resultchek [0] ) {
492
493 if ( divident_test [3] ==resultchek [0] ) {
494
495 isdatacorrupted =0;
496
497 }498
499
else {500

102 | Appendix D: Packet processing code
isdatacorrupted = 1;501
}502 }503
else {504
isdatacorrupted = 1;505
}506 }507 else {508
isdatacorrupted = 1;509
}510 }511 else {512
isdatacorrupted = 1;513
}514
515 printf (" The variable isthedatacorrupted value= ");
516 printf (" %d", isdatacorrupted );517
518
519
520 */521
522 //---------------------------------------------------------------------------------------
523 /// CRC decoder implementation with an 8 bitdivider ////////
524 //----------------------------------------------------------------------------------------
525
526
527
528 // printf (" \n" );529 // printf ("
---------------------------------------------------------------");
530 // printf (" \n" );

Appendix D: Packet processing code | 103
531
532
533
534 for ( int i = 0; i < 8; ++i) {535
536 divident [i]= crc_frame_bitlist [64+ i]; //start at the mac bits
537
538 }539
540
541 // // set a divider to 8 bits divider 10101011542 divider [0] = 1;543 divider [1] = 0 ;544 divider [2]= 1;545 divider [3] = 0;546 divider [4] = 1;547 divider [5] = 0;548 divider [6] = 1;549 divider [7] = 1;550
551
552 char temporary_list [8]; // temporary list tosave the rest result temporarily
553
554 // printf (" the first division rest are =") ;555 // printf (" \n" );556
557 for ( int j = 0; j < 8; ++j) {558
559 temporary_list [j] = ( divident [j] ^divider [j]) ;
560
561
562
563 }564
565 divident [0] = temporary_list [1] ;566 divident [1] = temporary_list [2] ;567 divident [2] = temporary_list [3] ;568 divident [3] = temporary_list [4] ;569 divident [4] = temporary_list [5] ;570 divident [5] = temporary_list [6] ;571 divident [6] = temporary_list [7] ;572 divident [7] = crc_frame_bitlist [71] ; //
adds a new least significant bit to the newdivident until the end of payload .

104 | Appendix D: Packet processing code
573
574
575 // for ( int d = 0; d < 7; d ++)576 //{577 // printf (" %d", divident [d] ); // print the rest
of the first division578 //}579 // printf (" \n" );580
581
582
583 for ( int l = 1; l < 441 ; l++ ) { // 62 bytes * 8= 496 bits to be divided by Xor ^
584
585 int ba= l+1 ;586
587 // printf (" --------------- ");588 // printf (" \n" );589 // printf (" The modulo 2 divison rest nr %i =" , (ba
));590
591
592
593 if ( divident [0] == 0 ){ // if the nextdivident byte starts with 0, XOR with zeros
594
595 for ( int i = 0; i < 8; ++i)596 {597 temporary_list [i] = (
divident [i] ^ 0) ;598 }599
600
601 }602
603
604 else if ( divident [0] == 1 ){605
606 for ( int i = 0; i < 8; ++i) //if the next divident byte starts with 1 go inhere
607 {608 temporary_list [i] = ( divident [i] ^
divider [i] ) ;609 }610 }611

Appendix D: Packet processing code | 105
612 divident [0] = temporary_list [1] ;613 divident [1] = temporary_list [2] ;614 divident [2] = temporary_list [3] ;615 divident [3] = temporary_list [4] ;616 divident [4] = temporary_list [5] ;617 divident [5] = temporary_list [6] ;618 divident [6] = temporary_list [7] ;619 divident [7] = crc_frame_bitlist [71+ l]; //
we appaned 72 first , than on the first run ofthis loop
620
621 // for ( int d = 0; d < 7; d ++) // print the eachbyte division rest
622 //{623 // printf (" %d", divident [d] );624 //}625 // printf (" --------------- ");626 // printf (" \n" );627
628 }629
630
631 /// check if the last divident is 00000000 toconfirm corruption of data or not
632
633 // printf (" --------------- ");634 // printf (" \n" );635 // printf (" the last modulo2 divison rest is = ");636 // printf (" %d", divident [i] );637
638 for ( int i = 0; i < 7; ++i) // saves and printsthe last rest
639 {640
641 divident [i] = temporary_list [i] ;642
643
644 //645
646 }647 // printf (" \n" );648 // printf (" --------------- ");649 // printf (" \n" );650
651 char resultchek = 0;652
653 if ( divident [0] == resultchek ) {

106 | Appendix D: Packet processing code
654
655 if ( divident [1] == resultchek ) {656
657 if( divident [2] == resultchek ) {658
659 if ( divident [3] ==resultchek ) {
660
661 if ( divident [4] ==resultchek ) {
662
663 if (divident [5] == resultchek ){
664
665 if( divident [6] == resultchek ){
666
667
if ( divident [7] == resultchek ){668
669
isdatacorrupted = 0;670
}671
672
else {673
isdatacorrupted == 1;674
}675 }676
else {677
isdatacorrupted == 1;678
}679 }680 else {681
isdatacorrupted == 1;682
}683 }684 else {

Appendix D: Packet processing code | 107
685
isdatacorrupted == 1;686
}687
688
689
}690
691 else {692
isdatacorrupted = 1;693 }694
695 }696 else {697
isdatacorrupted = 1;698
}699 }700 else {701
isdatacorrupted = 1;702
}703 }704 else {705
isdatacorrupted = 1;706
}707
708
709
710 // printf (" The variableisthedatacorrupted = ");
711 // printf (" %d", isdatacorrupted );712
713
714
715
716
717 //--------------------------------------------------------------------------------------------------------------
718 // //

108 | Appendix D: Packet processing code
PARSING FUNCTION /////719 //
--------------------------------------------------------------------------------------------------------------
720 // codesection for the preamble to be saved as bitcharacters in the preamble list .
721 // This functions take take a frame of 72 bytesfrom the data fram list and splits them into
722 // different categories723
724
725
726
727
728 // preamble / header \\729
730
731 // printf (" \n" );732 // printf (" The First 8 bytes of the
datapacket are = --- " );733 // printf (" \n" );734
735 // for ( int d = 0; d < 64; d ++)// Print the entire datapacket in
bits736 //{737 // printf (" %d",
crc_frame_bitlist [d] );738 //}739
740 // printf (" \n" );741 // printf (" -------");742 // printf (" \n" );743
744
745
746 int b ;747
748 // printf (" The preamble bits are :-----");
749 // printf (" \n" );750
751 for (b = 0; b < 64 ; b ++) {752
753 preamble [b] = crc_frame_bitlist [b] ;754
755 // printf (" %d", preamble [b] );

Appendix D: Packet processing code | 109
756
757 }758
759 // printf (" \n" );760 // printf (" --------------- ");761 // printf (" \n" );762
763
764 // mac destination \\765
766 int mac_destP ;767
768 // printf (" The macdestination bits are : ---");
769 // printf (" \n" );770
771 for ( int mac_destP = 0; mac_destP < 48; ++mac_destP ){
772
773 macdest [ mac_destP ] = crc_frame_bitlist[64+ mac_destP ] ;
774
775 // printf (" %d", macdest [ mac_destP ] );776
777 }778 // printf (" \n" );779 // printf (" --------------- ");780 // printf (" \n" );781
782
783 // mac source address \\784
785 int mac_sourceP ;786
787 // printf (" The mac sourcebits are : ---");
788 // printf (" \n" );789
790 for ( int mac_sourceP = 0; mac_sourceP < 48; ++mac_sourceP ){
791
792 macsource [ mac_sourceP ] =crc_frame_bitlist [112+ mac_sourceP ] ;
793
794 // printf (" %d", macsource [ mac_sourceP]);
795

110 | Appendix D: Packet processing code
796 }797
798
799 // printf (" \n" );800 // printf (" --------------- ");801 // printf (" \n" );802
803
804 // ///// Ethernet type /////////805
806 int Ethernet_type_P ;807
808 // printf (" The macEthernet type bits are : ---");
809 // printf (" \n" );810
811 for ( int Ethernet_type_P = 0; Ethernet_type_P <32; ++ Ethernet_type_P ){
812
813 ethernetbytes [ Ethernet_type_P ] =crc_frame_bitlist [160+ Ethernet_type_P ] ;
814 // printf (" %d", ethernetbytes [Ethernet_type_P ]);
815 }816
817 // printf (" \n" );818 // printf (" --------------- ");819 // printf (" \n" );820
821 // ////// payload ////////822
823 int payloadP ;824
825 // printf (" The mac payloadbits are : ---");
826 // printf (" \n" );827
828 for ( int payloadP = 0; payloadP < 368; ++payloadP ){
829
830 payload [ payloadP ] = crc_frame_bitlist[192 + payloadP ] ;
831
832 // printf (" %d", payload [ payloadP]);
833 }834

Appendix D: Packet processing code | 111
835 // printf (" \n" );836 // printf (" --------------- ");837 // printf (" \n" );838
839 // ///// the CRCframecheck bits are //840
841 int CRCbitsP ;842
843 // printf (" TheCRCframecheck bits are : ---");
844 // printf (" \n" );845
846 for ( int CRCbitsP = 0; CRCbitsP < 32; ++ CRCbitsP)
847
848 {849 CRC_framecheck [ CRCbitsP ] =
crc_frame_bitlist [ CRCbitsP + 560];850
851 // printf (" %d", CRC_framecheck [CRCbitsP ]);
852
853 }854 // printf (" \n" );855 // printf (" --------------- ");856 // printf (" \n" );857
858
859
860 //-----------------------------------------------------------------------------------------------
861 /// functions to find a patternby checking the ethernet type ///
862 //-----------------------------------------------------------------------------------------------
863
864 // there are 3 types of of ethernet 2 that will beused :
865 /// 0 X0800 0000 1000 0000 0000866 /// 0 X0806 0000 1000 0000 0110867 /// 0 X86DD 1000 0110 1101 1101868
869 // printf (" --------------- ");870 // printf (" \n" );871 // printf ( " The search for the ethernet type

112 | Appendix D: Packet processing code
starts ");872 // printf (" \n" );873 // printf (" --------------- ");874 // printf (" \n" );875
876 if ( ( ethernetbytes [0] == check_0 ) && (ethernetbytes [1]== check_0 ) && ( ethernetbytes [2]
== check_0 ) && ( ethernetbytes [3] == check_0 )) {877
878 if (( ethernetbytes [4]== check_1 ) && (ethernetbytes [5] == check_0 ) && ( ethernetbytes[6] == check_0 ) && ( ethernetbytes [7] ==check_0 )){
879
880 if (( ethernetbytes [8] == check_0 )&& ( ethernetbytes [9]== check_0 )&& ( ethernetbytes[10] == check_0 )&& ( ethernetbytes [11]== check_0 )) {
881
882
883 if (( ethernetbytes [12] ==check_0 ) && ( ethernetbytes [13] == check_0 ) && (ethernetbytes [14] == check_0 ) && ( ethernetbytes[15] == check_0 )){
884
885
ethernet_packet_type = 1;886
887 // printf (" ethernetpacket is of type 1 " );
888 // printf ("\ n");889
890 }891
892
893
894 else {895 if (( ethernetbytes
[12] == check_0 ) && ( ethernetbytes [13] ==check_1 )&& ( ethernetbytes [14] == check_1 )&& (ethernetbytes [15] == check_0 )){
896
897
ethernet_packet_type = 2;898
899 // printf (" ethernetpacket is of type 2 " );

Appendix D: Packet processing code | 113
900 // printf ("\ n");901
902 }903
904
905 else {906
ethernet_packet_type = 0;907
908 // printf (" ethernetpacket is unknown " );
909 // printf ("\ n");910
911 }912
913
914
915 }916
917
918 }919
920 else {921
922
ethernet_packet_type = 0;923
924 // printf (" ethernetpacket is unknown " );
925 // printf ("\ n");926 }927
928
929 }930
931 else {932
933
ethernet_packet_type = 0;934
935 // printf (" ethernetpacket is unknown " );
936 // printf ("\ n");937 }938
939
940 }

114 | Appendix D: Packet processing code
941
942
943
944 /// check for type 3945
946 else {947 if ( ( ethernetbytes [0] == check_1 ) && (
ethernetbytes [1] == check_0 ) && ( ethernetbytes[2] == check_0 )&& ( ethernetbytes [3] == check_0 )) {
948 if (( ethernetbytes [4] == check_0 )&& (ethernetbytes [5] == check_1 )&& ( ethernetbytes [6]
== check_1 ) && ( ethernetbytes [7] == 0)){949 if (( ethernetbytes [8] == check_1 )&&
( ethernetbytes [9] == check_1 )&& ( ethernetbytes[10] == check_0 )&& ( ethernetbytes [11] == check_1) ){
950 if (( ethernetbytes [12] ==check_1 ) && ( ethernetbytes [13] == check_1 ) && (ethernetbytes [14] == check_0 ) && ( ethernetbytes[15] == check_1 )){
951
952
ethernet_packet_type = 3;953
954 // printf (" ethernet packetis of type 3 " );
955 // printf ("\ n");956
957 }958 else {959
ethernet_packet_type = 0;960
961 // printf (" ethernetpacket is unknown " );
962 // printf ("\ n");963 }964
965 }966
967 else {968 ethernet_packet_type = 0;969
970 // printf (" ethernetpacket is unknown " );
971 // printf ("\ n");

Appendix D: Packet processing code | 115
972 }973 }974
975 else {976 ethernet_packet_type = 0;977
978 // printf (" ethernetpacket is unknown " );
979 // printf ("\ n");
980 }981
982 }983 else {984 ethernet_packet_type = 0;985
986 // printf (" ethernetpacket is unknown " );
987 // printf ("\ n");988
989 }990 }991
992
993 // --------994
995 // ------------------------------- Modify ethernetframe bytes -------------------
996
997 ethernetbytes [0] = 1 ;998 ethernetbytes [1] = 0 ;999 ethernetbytes [2] = 0 ;
1000 ethernetbytes [3] = 0 ;1001 ethernetbytes [4]= 0;1002 ethernetbytes [5]= 1;1003 ethernetbytes [6]= 1;1004 ethernetbytes [7]= 0;1005 ethernetbytes [8] = 1 ;1006 ethernetbytes [9] = 1 ;1007 ethernetbytes [10] = 0 ;1008 ethernetbytes [11] = 1 ;1009 ethernetbytes [12] = 1 ;1010 ethernetbytes [13] = 1 ;1011 ethernetbytes [14] = 0 ;1012 ethernetbytes [15] = 1 ;1013
1014 // ------

116 | Appendix D: Packet processing code
1015
1016 // recheck the etherneframes again1017
1018 //-----------------------------------------------------------------------------------------------
1019 /// functions to find a patternafter modification by checking the ethernet type
///1020 //
-----------------------------------------------------------------------------------------------
1021
1022 // there are 3 types of of ethernet 2 that will beused :
1023 /// 0 X0800 0000 1000 0000 00001024 /// 0 X0806 0000 1000 0000 01101025 /// 0 X86DD 1000 0110 1101 11011026
1027
1028 // printf (" --------------- ");1029 // printf (" \n" );1030 // printf ( " The search for the modified ethernet
type starts ");1031 // printf (" \n" );1032 // printf (" --------------- ");1033 // printf (" \n" );1034
1035
1036 char check_0 = 0;1037 char check_1 =1;1038
1039 if ( ( ethernetbytes [0] == check_0 ) && (ethernetbytes [1]== check_0 ) && ( ethernetbytes [2]
== check_0 ) && ( ethernetbytes [3] == check_0 )) {1040
1041 if (( ethernetbytes [4]== check_1 ) && (ethernetbytes [5] == check_0 ) && ( ethernetbytes[6] == check_0 ) && ( ethernetbytes [7] ==check_0 )){
1042
1043 if (( ethernetbytes [8] == check_0 )&& ( ethernetbytes [9]== check_0 )&& ( ethernetbytes[10] == check_0 )&& ( ethernetbytes [11]== check_0 )) {
1044
1045

Appendix D: Packet processing code | 117
1046 if (( ethernetbytes [12] ==check_0 ) && ( ethernetbytes [13] == check_0 ) && (ethernetbytes [14] == check_0 ) && ( ethernetbytes[15] == check_0 )){
1047
1048
ethernet_packet_type = 1;1049
1050 // printf (" ethernetpacket is of type 1 " );
1051 // printf ("\ n");1052
1053 }1054
1055
1056
1057 else {1058 if (( ethernetbytes
[12] == check_0 ) && ( ethernetbytes [13] ==check_1 )&& ( ethernetbytes [14] == check_1 )&& (ethernetbytes [15] == check_0 )){
1059
1060
ethernet_packet_type = 2;1061
1062 // printf (" ethernetpacket is of type 2 " );
1063 // printf ("\ n");1064
1065 }1066
1067
1068 else {1069
ethernet_packet_type = 0;1070
1071 // printf (" ethernetpacket is unknown " );
1072 // printf ("\ n");1073
1074 }1075
1076
1077
1078 }1079
1080

118 | Appendix D: Packet processing code
1081 }1082
1083 else {1084
1085
ethernet_packet_type = 0;1086
1087 // printf (" ethernetpacket is unknown " );
1088 // printf ("\ n");1089 }1090
1091
1092 }1093
1094 else {1095
1096
ethernet_packet_type = 0;1097
1098 // printf (" ethernetpacket is unknown " );
1099 // printf ("\ n");1100 }1101
1102
1103 }1104
1105
1106
1107 /// check for type 31108
1109 else {1110 if ( ( ethernetbytes [0] == check_1 ) && (
ethernetbytes [1] == check_0 ) && ( ethernetbytes[2] == check_0 )&& ( ethernetbytes [3] == check_0 )) {
1111 if (( ethernetbytes [4] == check_0 )&& (ethernetbytes [5] == check_1 )&& ( ethernetbytes [6]
== check_1 ) && ( ethernetbytes [7] == 0)){1112 if (( ethernetbytes [8] == check_1 )&&
( ethernetbytes [9] == check_1 )&& ( ethernetbytes[10] == check_0 )&& ( ethernetbytes [11] == check_1) ){
1113 if (( ethernetbytes [12] ==check_1 ) && ( ethernetbytes [13] == check_1 ) && (ethernetbytes [14] == check_0 ) && ( ethernetbytes

Appendix D: Packet processing code | 119
[15] == check_1 )){1114
1115
ethernet_packet_type = 3;1116
1117 // printf (" ethernet packetis of type 3 " );
1118 // printf ("\ n");1119
1120 }1121 else {1122
ethernet_packet_type = 0;1123
1124 // printf (" ethernetpacket is unknown " );
1125 // printf ("\ n");1126 }1127
1128 }1129
1130 else {1131 ethernet_packet_type = 0;1132
1133 // printf (" ethernetpacket is unknown " );
1134 // printf ("\ n");1135 }1136 }1137
1138 else {1139 ethernet_packet_type = 0;1140
1141 // printf (" ethernetpacket is unknown " );
1142 // printf ("\ n");
1143 }1144
1145 }1146 else {1147 ethernet_packet_type = 0;1148
1149 // printf (" ethernetpacket is unknown " );
1150 // printf ("\ n");1151

120 | Appendix D: Packet processing code
1152 }1153 }1154
1155 }1156
1157
1158
1159
1160
1161
Listing D.1: Packet processing code


TRITA-EECS-EX-2021:251
www.kth.se