epidemiology 217 molecular and genetic epidemiology bioinformatics & proteomics john witte, xin...
TRANSCRIPT

Epidemiology 217Molecular and Genetic Epidemiology
Bioinformatics & Proteomics
John Witte, Xin Liu &
Mark Pletcher

Questions on Assignment #4?Coding CC CT TT
Co-dominant 0 1 0
0 0 1
Dominant 0 1 1
Recessive 0 0 1
Log Additive 0 1 2

Post-Genomic Era: Lots of Data!

“The study of genetic and other biological information using computer and statistical techniques.”
A Genome Glossary, Science, Feb 16, 2001

Bioinformatics in Genetic Epi
Some key aspects:• Data management• Candidate regions / genes (selection and
SNP mining)• Genetic Analyses (e.g., genotyping)• Statistical Analyses

Data Management
5/20
Demogr. Database
Laboratory Database Clinical
Database
Health and Habits
DatabaseNutritional Database
Genomic Database
CaP Genes Databases
Hub

Selecting Candidate Genes
• From candidate regions
• Or simply based on a priori information.
• Example:– Chrom 7 linkage for aggressive prostate
cancer. – Region on chrom 7q31-33.– A number of plausible candidates in this
region.

From gene to polymorphisms
Given a gene, how do I…
Find its polymorphisms?Find its polymorphisms?
Find information about those polymorphisms?Find information about those polymorphisms?

• Hands-on guide for browsing and analyzing genomic data.• Contains worked examples, providing:
–overview of the types of data available, –details on how these data can be browsed, and –step-by-step instructions for using many of the most commonly-used tools for sequence based discovery.
www.nature.com/cgi-taf/dynapage.taf?file=/ng/journal/v35/n1s/

Nature Genetics: A User's Guide to the Human Genome
3 of the 13 worked example questions
• How does one find a gene of interest and determine that gene's structure?
• How would one retrieve the sequence of a gene, along with all annotated exons and introns, as well as a certain number of flanking bases for use in primer design?
• A user wishes to find all the single nucleotide polymorphisms that lie between two sequence-tagged sites. Do any of these single nucleotide polymorphisms fall within the coding region of a gene? Where can any additional information about the function of these genes be found?

Look for SNPs in Databases• General databases:
--- dbSNP (http://www.ncbi.nlm.nih.gov/)--- UCSC Genome Bioinformatics (http://genome.ucsc.edu/)--- HapMap (http://www.hapmap.org/)--- The SNP consortium (TSC) (http://snp.cshl.org/)--- Human gene variation base (HGVbase) (http://hgvbase.cgb.ki.se)
• Special databases:--- The UW-FHCRC Variation Discovery Resource (SeattleSNPs)
(http://pga.gs.washington.edu/)--- Cancer Genome Anatomy Project - SNP500Cancer Database
(http://snp500cancer.nci.nih.gov/home_1.cfm)--- InnateImmunity ( (http://innateimmunity.nethttp://innateimmunity.net)--- Drug response (http://pharmgkb.org)
• More….

dbSNP Summary (Build 124, 2005)
Reference SNP(rs) # : 10,054,521
5,054,675 validated SNPs (~50%)

dbSNP search by SNP ID

dbSNP search by gene

dbSNP search by ‘limits’

dbSNP search by ‘limits’ (Cont.)

UCSC Browser
Provides additional information over dbSNP database
Select SNP under the conserved region by comparing sequence across species.
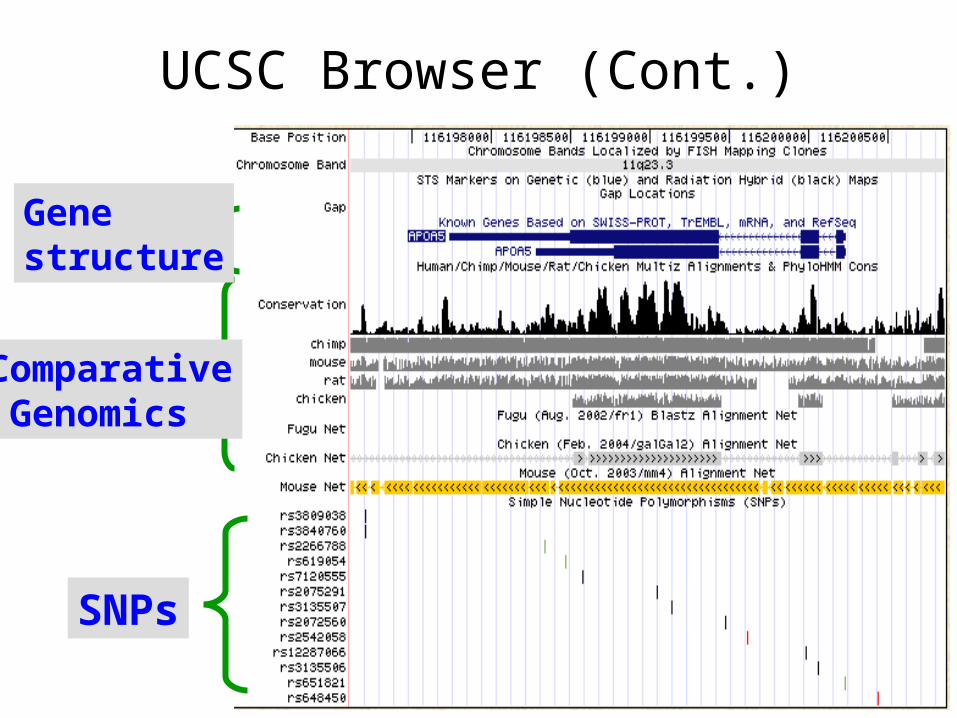
UCSC Browser (Cont.)
Comparative Genomics
SNPs
Gene structure

HapMap
• Four populations:1. CEU: CEPH (Utah residents with ancestry from
northern and western Europe),
2. HCB: Han Chinese in Beijing, China,
3. JPT: Japanese in Tokyo, Japan,
4. YRI: Yoruba in Ibadan, Nigeria
• Find htSNP based on the available genotype data

SeattleSNPs
• Resequencing the complete genomic region of each gene among 24 African-American (AA) subjects and 23 European (CEPH) subjects
– 2000 bp upstream of first exon– 1500 bp downstream of poly-A signal– All exons and introns for genes below 35 kbp
• Summary data (2/18/05)– Number of genes sequenced: 208– Total kilobases sequenced: 4408.78– Number of SNPs found: 23,590– SNPs in AA sample: 20,765– SNPs in CEPH sample: 12,937

SeattleSNPs (cont.)
• It is convenient for tag SNP selection.• Limitations:
--- gene of interest may not be included in this database
--- information is only available for AA and CAU

Summary: selecting SNPs
• If candidate gene is in SeattleSNP database: – tagSNPs for AA and CAU are available from the
website
• If not, or interested in candidate region:– dbSNP: limit on functional class, validation,
heterozygosity, etc.– UCSC: SNPs under the conserved region.– HapMap: htSNPs

5` 3`DNA
Pre-splicing RNA
Post-splicing RNA
Protein
Exon, non-coding (5`UTR, 3`UTR)
Exon, coding Promoter
Enhancer
Intron Poly-adenilation
Anatomy of a gene

From Genomics to Proteomics
• Our ~ 25,000 genes carry the blueprint for making proteins, of which all living matter is made.
• Each protein has a particular shape and function that determine its role in the body.
• Proteomics is the study of protein shape, function, and patterns of expression.

• Characterize proteins derived from genetic code
• Compare variations in their expression levels under different conditions
• Study their interactions
• Identify their functional role.
Proteomics

Proteome Complexity
• Recall that genome is relatively static.• In contrast, many cellular proteins are
continually moving and undergoing changes such as:
1. binding to a cell membrane,2. partnering with another protein,3. gaining or losing a chemical group such as a
sugar, fat, or phosphate, or 4. breaking into two or more pieces.

Size of Proteome?
• > 1 Million Proteins >>> 25,000 genes in humans.
• Large number due to complexity (a given gene can make many different proteins)
• Features such as folds and motifs, allow them to be categorized into groups and families.
• This should help make it easier to undertake proteomic research.
• But no proteome has yet been sequenced.

How to Analyze Proteomes
• Broad range of technologies• Central paradigm:
– 2-D gel electrophoresis (2D-GE), and mass spectrometry (MS).
– 2D-GE is used to separate the proteins by isoelectric point and then by size.
– MS determines their identity and characteristics.

2-D gel electrophoresis
• Large mixtures of proteins separated by electrical charge and size.
• The proteins first migrate through a gel-like substance until they are separated by their charge.
• They are then transferred to a second semi-solid gel and are separated by size.

Mass spectrometry• MS measures two properties:
1. the mass-to-charge ratio (m/z) of a mixture of ions (particles with an electric charge) in the gas phase under vacuum; and
2. the number of ions present at each m/z value. • The end product is a mass spectra (chart) with a
series of spiked peaks, each representing the ion or charged protein fragment present in a given sample.
• The height of the peak is related to the abundance of the protein fragment.
• The size of the peaks and the distance between them are a fingerprint of the sample and provide a clue to its identity.

Bioinformatics in Proteomics
• Creation and maintenance of databases of protein info.
• Development of methods to predict the structure and/or function of newly discovered proteins and structural RNA sequences.
• Clustering protein sequences into families of related sequences and the development of protein models.
• Aligning similar proteins and generating phylogenetic trees to examine evolutionary relationships

Use of Proteomics in Clinical Research
• Example from Mark Pletcher

Final Project
• Describe a genetic, molecular, pharmacogenomic, or proteomic project that you feel would be worth undertaking.
• I.e., based on the current state of the literature (from your reviews).
• One page description, due March 7th by email to me.
• 5-10 minute presentation (informal) in class on March 8th.